大数据学习之路之HBASE
Hadoop之HBASE
一、HBASE简介
HBase是一个开源的、分布式的,多版本的,面向列的,半结构化的NoSql数据库,提供高性能的随机读写结构化数据的能力。它可以直接使用本地文件系统,也可以使用Hadoop的HDFS文件存储系统。不过,为了提高数据的可靠性和系统的健壮性,并且发挥HBase处理大数据的能力,使用HDFS作为文件存储系统才更为稳妥。
HBase存储的数据从逻辑上来看就像一张很大的表,并且它的数据列可以根据需要动态地增加。除此之外,每个单元(cell,由行和列所确定的位置)中的数据又可以具有多个版本(通过时间戳来区别)。从下图可以看出,HBase还具有这样的特点:它向下提供了存储,向上提供了运算。另外,在HBase之上还可以使用Hadoop的MapReduce计算模型来并行处理大规模数据,这也是它具有强大性能的核心所在。它将数据存储与并行计算完美地结合在一起。
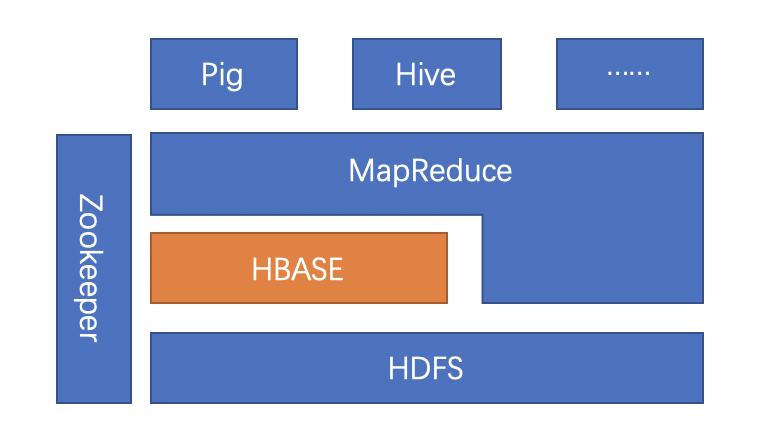
HBase 和 HDFS
| HDFS | HBase |
|---|---|
| HDFS是适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找。 | HBase提供在较大的表快速查找。 |
| 它提供了高延迟批量处理;没有批处理概念。 | 它提供了数十亿条记录低延迟访问单个行记录(随机存取)。 |
| 它提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。 |
二、HBASE表结构
HBASE表具有以下特点:
-
大:一个表可以有上亿行,上百万列
-
面向列:面向列(族)的存储和权限控制,列(族)独立检索。
-
稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
HBase以表的形式存储数据。表有行和列组成。列划分为若干个列族(row family)。下面是HBASE表的逻辑视图:
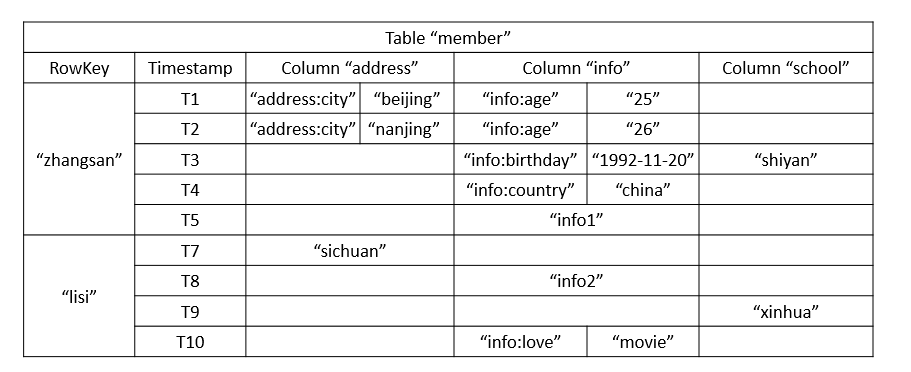
在shell客户端展示:
> scan 'member'
ROW COLUMN+CELL lisi column=address:, timestamp=1567757931802, value=sichuan lisi column=info:, timestamp=1567757982455, value=info2
lisi column=info:love, timestamp=1567758039091, value=movie lisi column=school:, timestamp=1567758005941, value=xinhua zhangsan column=address:city, timestamp=1567755403595, value=beijing zhangsan column=info:, timestamp=1567755827530, value=info1 zhangsan column=info:age, timestamp=1567756662127, value=26
zhangsan column=info:birthday, timestamp=1567755398376, value=1993-11-20 zhangsan column=info:country, timestamp=1567755402535, value=china zhangsan column=school:, timestamp=1567757294341, value=shiyan 2 row(s)
Took 0.0945 seconds
下面依次介绍这些结构:
- Row key:用来检索记录的主键,类似key-value结构的key。访问hbase table的行,只有三种方式:
- 通过单个row key访问;
- 通过row key的range;
- 全表扫描;
- 列族:hbase表中的每个列,都属于某个列族,列族属于表结构(必须在使用表之前定义),列不属于(插入数据的时候可以随时添加列),比如上面的info,address,school这些属于列族,info:age,info:love这些属于列。
- Cell:row key和列以及时间戳唯一确定的单元,用来存储真实的数据,cell中的数据没有类型,全部是字节码形式存储。
- 时间戳:每个cell中保存着同一份数据的多个版本,版本通过时间戳来索引。为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
三、安装运行HBASE
wget http://apache.01link.hk/hbase/2.2.0/hbase-2.2.0-bin.tar.gz
tar -zxvf hbase-2.2.0-bin.tar.gz
cd hbase-2.2.0
vim conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///tmp/hbase-${user.name}/hbase</value>
</property>
</configuration>
# 单机模式运行,使用的是本次文件存储。不依赖Hadoop
./bin/start-hbase.sh
# 查看进程
jps
9758 HMaster
# 启动成功后可以在 http://localhost:16010 访问hbase的web页面
# 停止Hbase服务
./bin/stop-hbase.sh
# 进入HBASE shell
./bin/hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.0, rUnknown, Tue Jun 11 04:30:30 UTC 2019
Took 0.0128 seconds
hbase(main):001:0>
四、shell DDL操作
# 建表
> create 'member','member_id','address','info'
Created table member
Took 1.6592 seconds
=> Hbase::Table - member
# 列出所有表
> list
TABLE
member
1 row(s)
Took 0.1501 seconds
=> ["member"]
# 列出表描述
> describe 'member'
Table member is ENABLED member COLUMN FAMILIES DESCRIPTION {NAME => 'address', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NO
NE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLO
CKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'info', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE'
, TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS
_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'member_id', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => '
NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_B
LOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
3 row(s)
QUOTAS
0 row(s)
Took 0.6478 seconds
# 删除一个列族,alter,disable,enable
> alter 'member',{NAME=>'member_id',METHOD=>'delete'}
# 在用describe 查看表会发现只有两个列族了
# 删除一个表,首先要先disable这个表
> disable 'member'
> drop 'member'
# 表是否存在
> exists 'member'
# 判断表是否enable
> is_enabled 'member'
# 判断表是否disable
> is_disabled 'member'
五、shell DML操作
# 插入数据
put'member','zhangsan','info:age','24'
put'member','zhangsan','info:birthday','1993-11-20'
put'member','zhangsan','info:country','china'
put'member','zhangsan','address:city','beijing'
put'member','lisi','info:birthday','1998-09-09'
put'member','lisi','info:favotite','movie'
put'member','lisi','address:city','beijing'
# 获取一个id的所有数据
> get'member','zhangsan'
COLUMN CELL address:city timestamp=1567754003312, value=beijing info:age timestamp=1567753903167, value=24 info:birthday timestamp=1567753950339, value=1993-11-20 info:country timestamp=1567753964169, value=china 1 row(s)
Took 0.1351 seconds
# 获取一个id,一个列族的所有数据
> get'member','zhangsan','info'
COLUMN CELL info:age timestamp=1567753903167, value=24 info:birthday timestamp=1567753950339, value=1993-11-20 info:country timestamp=1567753964169, value=china 1 row(s)
Took 0.0455 seconds
# 获取一个id,一个列族中一个列的所有数据
> get'member','zhangsan','info:age'
COLUMN CELL info:age timestamp=1567753903167, value=24 1 row(s)
Took 0.0364 seconds
# 更新一条记录
> put'member','zhangsan','info:age','25'
> get'member','zhangsan','info:age'
COLUMN CELL info:age timestamp=1567754315161, value=25 1 row(s)
Took 0.0491 seconds
# 通过timestamp来获取指定版本的数据
> get'member','zhangsan',{COLUMN=>'info:age',TIMESTAMP=>1567753903167}
COLUMN CELL info:age timestamp=1567753903167, value=24 1 row(s)
Took 0.0342 seconds
# 全表扫描
> scan 'member'
ROW COLUMN+CELL
lisi column=address:city, timestamp=1567754078391, value=beijing lisi column=info:birthday, timestamp=1567754038812, value=1998-09-09 lisi column=info:favotite, timestamp=1567754057750, value=movie zhangsan column=address:city, timestamp=1567754003312, value=beijing zhangsan column=info:age, timestamp=1567754315161, value=25 zhangsan column=info:birthday, timestamp=1567753950339, value=1993-11-20 zhangsan column=info:country, timestamp=1567753964169, value=china 2 row(s)
Took 0.1000 seconds
# 删除指定字段
> delete'member','zhangsan','info:age'
# 这个很有意思,如果有两个版本的数据,那么只会删除最新的一个版本,当再次查询的时候结果就是上一个版本的
> get'member','zhangsan','info:age'
COLUMN CELL info:age timestamp=1567753903167, value=24 1 row(s)
Took 0.0454 seconds
# 再次执行delete就能把当前版本删除
> delete'member','zhangsan','info:age'
> get'member','zhangsan','info:age'
COLUMN CELL 0 row(s)
Took 0.0166 seconds
# 删除整行
> deleteall'member','lisi'
Took 0.0235 seconds
# 查询表中有多少行
> count'member'
1 row(s)
Took 0.3753 seconds => 1
# 给"zhangsan"这个id增加'info:age'字段,并使用counter实现递增
> incr 'member','zhangsan','info:age'
COUNTER VALUE = 1
Took 0.0948 seconds
> get 'member','zhangsan','info:age'
COLUMN CELL info:age timestamp=1567755056584, value=\x00\x00\x00\x00\x00\x00\x00\x01 1 row(s)
Took 0.0504 seconds
> incr 'member','zhangsan','info:age'
COUNTER VALUE = 2
Took 0.0211 seconds
> get 'member','zhangsan','info:age'
COLUMN CELL info:age timestamp=1567755133527, value=\x00\x00\x00\x00\x00\x00\x00\x02 1 row(s)
Took 0.0479 seconds
# 获取当前count的值
> get_counter'member','zhangsan','info:age'
COUNTER VALUE = 2
Took 0.0145 seconds
# 清空整张表
> truncate 'member'
Truncating 'member' table (it may take a while):
Disabling table...
Truncating table...
Took 2.1687 seconds
# 如何查看多个版本的数据,首先需要更新表结构,因为默认只保存一个版本数据,我们将保存的版本数设置为3
> alter'member',{NAME=>'info',VERSIONS=>3}
> put'member','zhangsan','info:age','26'
> scan 'member',{COLUMN=>'info:age',VERSIONS=>3}
ROW COLUMN+CELL zhangsan column=info:age, timestamp=1567756662127, value=26 zhangsan column=info:age, timestamp=1567756297089, value=25 1 row(s)
Took 0.0361 seconds
> get 'member','zhangsan',{COLUMN=>'info',VERSIONS=>3}
COLUMN CELL info: timestamp=1567755827530, value=info1 info:age timestamp=1567756662127, value=26 info:age timestamp=1567756297089, value=25 info:birthday timestamp=1567755398376, value=1993-11-20 info:country timestamp=1567755402535, value=china 1 row(s)
Took 0.0622 seconds
六、遇到的问题
问题1:
运行hbase shell时报错:
./bin/hbase shell
2019-09-06 11:03:21,079 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.0, rUnknown, Tue Jun 11 04:30:30 UTC 2019
Took 0.0080 seconds
NotImplementedError: fstat unimplemented unsupported or native support failed to load; see http://wiki.jruby.org/Native-Libraries
initialize at org/jruby/RubyIO.java:1013
open at org/jruby/RubyIO.java:1154
initialize at uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/irb/input-method.rb:141
initialize at uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/irb/context.rb:70
initialize at uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/irb.rb:426
initialize at /home/wangjun/software/hbase-2.2.0/lib/ruby/irb/hirb.rb:47
start at /home/wangjun/software/hbase-2.2.0/bin/../bin/hirb.rb:207
<main> at /home/wangjun/software/hbase-2.2.0/bin/../bin/hirb.rb:219
解决方案:
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable这个问题只需要修改conf/hbase-env.sh,加入:
export LD_LIBRARY_PATH=${hadoop_home}/lib/native:$LD_LIBRARY_PATH
${hadoop_home}为你的hadoop的安装路径。
NotImplementedError: fstat unimplemented unsupported or native support failed to load这个问题的解决方案:
sudo apt-get install jruby -y
sudo apt-get install asciidoctor -y
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号