容器原理之cgroup
 容器原理之cgroup。cgroup(control group)是一个内核特性,用于限制、统计、隔离一组进程的资源(CPU、内存、磁盘、网络等)。
容器原理之cgroup。cgroup(control group)是一个内核特性,用于限制、统计、隔离一组进程的资源(CPU、内存、磁盘、网络等)。
“
以 docker 为代表,轻量、便携的 container 使得打包和发布应用非常容易。系列文章容器原理主要分析 container 用到的核心技术,主要包括 Linux namespace,cgroups,overlayfs,看完这些内容,你将可以手动创建一个和 container 类似的环境。
cgroup(control group)是一个内核特性,用于限制、统计、隔离一组进程的资源(CPU、内存、磁盘、网络等),首字母不要大写。
“
“cgroup” stands for “control group” and is never capitalized.
-
单数形式(cgroup)指所有特性,也可以作为“cgroup controllers”的修饰。
-
复数形式(cgroups)指多个 cgroup。
Google 工程师在 2006 年开始提出这个特性,最早叫“process containers[1]”,为了避免造成歧义,在 2007 年改名为“control group”,在 2008 年 1 月发布的 Linux Kernel 2.6.24 合入主线分支。此后,在此基础上又增加了一系列特性,包括 kernfs(伪文件系统,用于向用户导出内核的设备模型),firewalling(基于预定义的安全规则管理网络流量)和 unified hierarchy[2]。在 Linux Kernel 4.5 版本合入了 cgroup v2[3] 的实现代码。
cgroup 功能
在云原生场景下,可以通过 cgroups 限制每个容器可以使用的资源。例如,对于 kubernetes,可以用于决定是否调度 pod 到某个节点,从而确保每个容器中的应用都有足够的可用资源。
cgroup 主要功能包括:
-
资源限制:限制一组进程的可用资源阈值。
-
资源监控:监控 cgroup 级别的资源使用状态。
-
进程控制:控制(挂起 or 恢复)cgroup 中的所有进程。
-
优先级控制:控制不同 cgroup 的优先级,当资源不足时,优先满足优先级高的 cgroup。
cgroup 模式
目前,cgroups 有两个版本,cgroup V1 和 cgroup V2。V1 功能相对零散,不方便维护,V2 是未来的演进方向。在这种情况下,节点存在以下面 3 种 cgroups 模式:
-
legacy:只支持 cgroup V1
-
hybrid:同时支持 cgroup V1 和 cgroup V2
-
unified:只支持 cgroup V2
在 containerd 中,通过以下方式判断处于哪种模式:
const unifiedMountpoint = "/sys/fs/cgroup"
// Mode returns the cgroups mode running on the host
func Mode() CGMode {
checkMode.Do(func() {
var st unix.Statfs_t
// 没挂载 /sys/fs/cgroup
if err := unix.Statfs(unifiedMountpoint, &st); err != nil {
cgMode = Unavailable
return
}
switch st.Type {
case unix.CGROUP2_SUPER_MAGIC:
// /sys/fs/cgroup 挂载为 cgroup2 文件系统格式
cgMode = Unified
default:
cgMode = Legacy
if err := unix.Statfs(filepath.Join(unifiedMountpoint, "unified"), &st); err != nil {
return
}
// /sys/fs/cgroup/unified 挂载为 cgroup2 文件系统格式
if st.Type == unix.CGROUP2_SUPER_MAGIC {
cgMode = Hybrid
}
}
})
return cgMode
}
- Cgroup
也可以通过以下命令判断:
[ $(stat -fc %T /sys/fs/cgroup/) = "cgroup2fs" ] && echo "unified" || ( [ -e \
/sys/fs/cgroup/unified/ ] && echo "hybrid" || echo "legacy")
通过 Linux 启动参数修改 cgroups 模式。例如,使用 unified 模式(注意cgroup_no_v1=all):
GRUB_CMDLINE_LINUX="cgroup_enable=memory systemd.unified_cgroup_hierarchy=1 \
systemd.legacy_systemd_cgroup_controller=0 cgroup_no_v1=all"
使用 legacy 模式:
GRUB_CMDLINE_LINUX="cgroup_enable=memory systemd.unified_cgroup_hierarchy=0 \
systemd.legacy_systemd_cgroup_controller=1"
使用 hybrid 模式:
GRUB_CMDLINE_LINUX="cgroup_enable=memory systemd.unified_cgroup_hierarchy=1 \
systemd.legacy_systemd_cgroup_controller=1"
cgroup V1
基本概念
cgroup v1 主要包括以下几个概念:
-
subsystem(子系统):内核模块,具体的资源控制器,可以被关联到 cgroup 树。不同资源的控制器不同,例如,内存子系统控制内存资源,CPU 子系统控制 CPU 资源。
-
cgroup(控制组):资源隔离的最小单位,表示一组进程和 cgroup 子系统的关联,例如:通过内存子系统限制一组进程的可用内存资源总量。进程可以加入某个 cgroup,也可以从一个 cgroup 迁移到另一个 cgroup,同一进程不能同时存在同类型的两个 cgroup 中。
-
hierarchy(层级):由一系列 cgroup 按照树状结构排列,每个节点都是一个 cgroup,子 cgroup 默认继承父 cgroup 的参数和配置。系统可以有多个层级(cgroup 树),每个层级可以和不同的 subsystem 关联,每个 subsystem 只能和一个层级关联,同一进程可以属于多个层级,但在每个层级中只能属于一个 cgroup 节点。
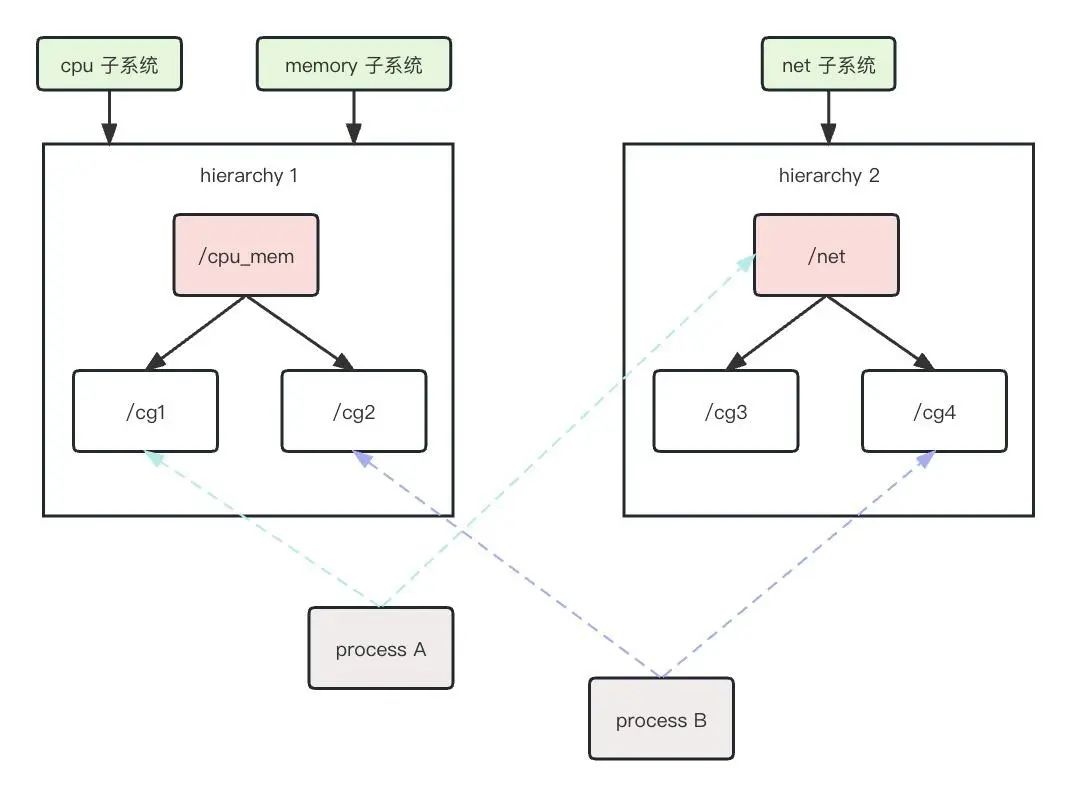
cgroup 类型(subsystem)
cgroup V1 支持的资源类型如下:
❯ ls -l /sys/fs/cgroup
total 0
dr-xr-xr-x 9 root root 0 Jun 12 20:56 blkio
lrwxrwxrwx 1 root root 11 Jun 12 20:56 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 Jun 12 20:56 cpuacct -> cpu,cpuacct
dr-xr-xr-x 10 root root 0 Jun 12 20:56 cpu,cpuacct
dr-xr-xr-x 7 root root 0 Jun 12 20:56 cpuset
dr-xr-xr-x 9 root root 0 Jun 12 20:56 devices
dr-xr-xr-x 7 root root 0 Jun 12 20:56 freezer
dr-xr-xr-x 6 root root 0 Jun 12 20:56 hugetlb
dr-xr-xr-x 10 root root 0 Jun 12 20:56 memory
lrwxrwxrwx 1 root root 16 Jun 12 20:56 net_cls -> net_cls,net_prio
dr-xr-xr-x 7 root root 0 Jun 12 20:56 net_cls,net_prio
lrwxrwxrwx 1 root root 16 Jun 12 20:56 net_prio -> net_cls,net_prio
dr-xr-xr-x 7 root root 0 Jun 12 20:56 perf_event
dr-xr-xr-x 9 root root 0 Jun 12 20:56 pids
dr-xr-xr-x 10 root root 0 Jun 12 20:56 systemd
-
blkio:限制块设备的 IO
-
cpu:通过调度程序控制可用 CPU 资源总量
-
cpuacct:CPU 资源的使用情况
-
cpuset:控制进程可用的 CPU 和内存
-
devices:控制对设备的访问
-
freezer:挂起或恢复 cgroup 中的进程
-
hugetlb:控制进程可用的大页内存
-
memory:控制进程可用的内存总量,同时统计内存使用情况
-
net_cls:将 cgroup 中的网络包分类
-
net_prio:控制网络流量的优先级
-
perf_event:监控 cgroup 的性能
-
pids:控制可创建的进程总数
Cgroup 子系统运行在内核态,不能直接和用户交互,因此,需要通过文件系统提供和终端用户的接口。在 Linux 中,表现为 Cgroup 子系统挂载的文件系统目录,用户操作这些文件就可以直接和内核中的 Cgroup 对象交互。
不同的子系统对应的文件系统目录包含不同的文件,但以下文件是所有子系统都有的:
cgroup.clone_children
cgroup.procs
notify_on_release
tasks
- cgroup.clone_children
控制子 cgroup 是否继承父 cgroup 的配置,只对 cpuset 子系统有效[4],并且在 cgroup V2 中已经移除[5]。
- cgroup.procs
位于当前 cgroup 的 TGID(线程组 ID),TGID 是进程组中第一个进程的 PID。该文件是可写的,向该文件写入 TGID 即将对应线程组加入 cgroup,不保证文件中的 TGID 有序和不重复。
- tasks
位于当前 cgroup 中 task 的 TID(线程 ID),即进程组中的所有线程的 ID。该文件是可写的,将任务的 TID 写入这个文件表示将其加入对应 cgroup,如果该任务的 TGID 在另一个 cgroup,会在 cgroup.procs 记录该任务的 TGID,进程组中的其它 task 不受影响。不保证文件中的 TID 有序和不重复。
⚠️ 注意:如果向 cgroup.procs 写入 TGID,系统会自动更新 tasks 文件中的内容为该线程组中所有任务的 TID。
> cat cgroup.procs
> cat tasks
> echo 40790 > cgroup.procs
> cat tasks
40791
40792
40793
40794
40795
向 tasks 文件中写入 TID,cgroup.procs 中的值也会更新为对应 TGID,但是并不影响该线程组中的其它任务。
> echo 45345 > tasks
> cat cgroup.procs
45340
> cat tasks
45345
- notify_on_release
是否开启 release agent,如果该文件中的值为 1,当 cgroup 中不包含任何 task 时(tasks 中的 TID 被全部移除),kernel 会执行 release_agent 文件(位于 root cgroup 的 release_agent 文件,例如/sys/fs/cgroup/memory/release_agent)的内容。所有非 root cgroup 从父 cgroup 继承该值。
cgroup V2
基本概念
在 cgroup v2 中,去掉了层级(hierarchy)的概念,只有一个层级,所有 cgroup 在该层级中以树形的方式组织,每个 cgroup 可以管理多种资源。
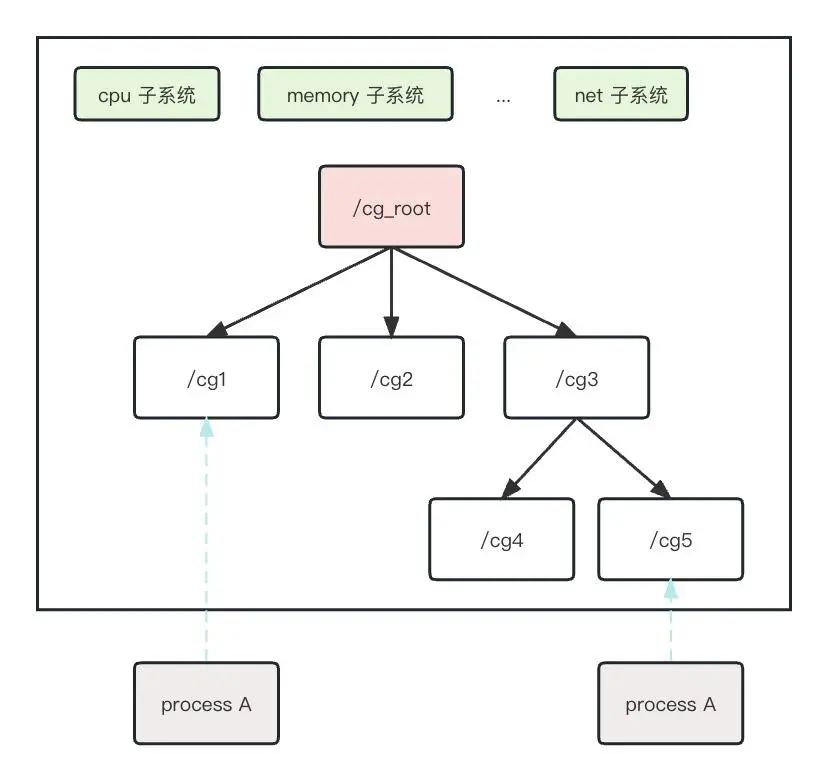
cgroup v2 不需要单独挂载每个子系统。
❯ findmnt -R /sys/fs/cgroup
TARGET SOURCE FSTYPE OPTIONS
/sys/fs/cgroup cgroup2 cgroup2 rw,nosuid,nodev,noexec,relatime,nsdelegate
如何查看 cgroup 开启了哪些 controller(和 cgroup v1 子系统的概念类似)呢?在 cgroup v2 中,每个 cgroup 目录下有个名为cgroup.controllers的可读文件,记录了当前 cgroup 启用的 controller。根目录下cgroup.controllers文件的内容记录了当前系统支持的所有 controller。
❯ cat cgroup.controllers
cpuset cpu io memory pids
新建子 cgroup 时,cgroup.controllers 继承父 cgroup 的 cgroup.subtree_control 值,子 cgroup 的 cgroup.subtree_control为空,表示在该子 cgroup 下再次创建子 cgroup 时,默认不会启用 controller。
创建一个testcgroup,此时,cgroup.subtree_control的值为空:
❯ pwd
/sys/fs/cgroup
❯ mkdir test
❯ cat cgroup.subtree_control
cgroup.controllers的值和父 cgroup 的cgroup.subtree_control值相同:
# 父 cgroup 的 cgroup.subtree_control
❯ cat cgroup.subtree_control
cpuset cpu io memory pids
# test cgroup 的 cgroup.controllers
❯ cat test/cgroup.controllers
cpuset cpu io memory pids
在test下再创建一个子 cgroup child,此时,child的cgroup.controllers的内容为空:
❯ mkdir test/child
❯ cat test/child/cgroup.controllers
子 cgroup child中的文件:
cgroup.controllers cgroup.max.descendants cgroup.threads io.pressure
cgroup.events cgroup.procs cgroup.type memory.pressure
cgroup.freeze cgroup.stat cpu.pressure
cgroup.max.depth cgroup.subtree_control cpu.stat
修改父 cgroup 的 cgroup.subtree_control,增加 cgroup controller:
❯ echo "+memory" > test/cgroup.subtree_control
❯ cat test/child/cgroup.controllers
memory
- 与此同时,子 cgroup
child中增加了 memory 相关的文件:
❯ ls test/child
cgroup.controllers cpu.stat memory.oom.group
cgroup.events io.pressure memory.pressure
cgroup.freeze memory.current memory.reclaim
cgroup.max.depth memory.drop_cache memory.stat
cgroup.max.descendants memory.events memory.swap.current
cgroup.procs memory.events.local memory.swap.events
cgroup.stat memory.high memory.swap.max
cgroup.subtree_control memory.low
cgroup.threads memory.max
cgroup.type memory.min
cpu.pressure memory.numa_stat
删除子 cgroup 中的 controller,也通过修改父 cgroup 的cgroup.subtree_control实现:
❯ echo "-memory" > test/cgroup.subtree_control
❯ cat test/child/cgroup.controllers
对一个 cgroup,如果 cgroup.procs的值不为空,不能设置 cgroup.subtree_control的值。
❯ cat cgroup.procs
49347
❯ echo "+memory" > cgroup.subtree_control
echo: write error: device or resource busy
此时,需要将 cgroup 中的进程移动到其它子 cgroup,确保当前 cgroup 中cgroup.procs的值为空:
❯ mkdir tmp
❯ echo 49347 > tmp/cgroup.procs
❯ echo "+memory" > cgroup.subtree_control
❯ cat child/cgroup.controllers
memory
未开启任何 controller 时,cgroup 中包含以下文件:
❯ ls test/child
cgroup.controllers
cgroup.events
cgroup.freeze
cgroup.max.depth
cgroup.max.descendants
cgroup.procs
cgroup.stat
cgroup.subtree_control
cgroup.threads
cgroup.type
cpu.pressure
cpu.stat
io.pressure
memory.pressure
-
cgroup.controllers:当前 cgroup 开启的 controller 列表。
-
cgroup.events:存在于非 root cgroup 中,包括两个字段:populated 和 frozen。
❯ cat cgroup.events
populated 0
frozen 0
populated:如果当前 cgroup 和子层级中没有存活的进程,populated 值为 0,否则为 1。值改变时会触发 poll 和 notify 事件。考虑以下 cgroup 层级(括号中的数字代表 cgroup 中的进程数量):
A(4) - B(0) - C(1)
\ D(0)
A,B 和 C 的 populated 值都为 1,D 的 populated 值为 0,如果 C 中对进程退出,则 B 和 C 中的 populated 值将变为 0,并且会生成cgroup.events文件被修改的事件。
frozen:如果当前 cgroup 处于 frozen 状态,值为 1,否则为 0。
- cgroup.freeze:可读可写,可以通过向该文件写入 1 将 cgroup 设置为 freeze 状态。默认值为 0。
❯ cat cgroup.freeze
0
❯ echo 1 > cgroup.freeze
❯ cat cgroup.freeze
1
❯ cat cgroup.events
populated 0
frozen 1
-
cgroup.max.depth:当前 cgroup 允许创建子 cgroup 最大深度,如果实际深度大于或等于该值,尝试创建新的子 cgroup 会失败。默认值 max 不限制。
-
cgroup.max.descendants:当前 cgroup 允许创建子 cgroup 的最大数量,如果实际子 cgroup 数量大于该值,尝试创建新的 cgroup 会失败。默认值 max 不限制。
cgroup.max.depth 和 cgroup.max.descendants 的区别:
cgroup.max.descendants 限制当前 cgroup 下所有子 cgroup 的总和(包括所有子 cgroup)。
❯ cat cgroup.max.descendants
2
❯ mkdir test1
❯ mkdir test2
❯ mkdir test3
mkdir: cannot create directory ‘test3’: Resource temporarily unavailable
cgroup.max.depth 限制 cgroup 树的深度:
❯ cat cgroup.max.depth
2
❯ mkdir test1
❯ mkdir test1/test2
❯ mkdir test1/test2/test3
mkdir: cannot create directory ‘test1/test2/test3’: Resource temporarily unavailable
- cgroup.procs:可读可写,处于当前 cgroup 中的所有进程,每行一个 PID,没有顺序,并且可能存在重复(进程被移走后再次加入当前 cgroup)。向该文件中写入 PID 可以将进程加入 cgroup。
❯ cat cgroup.procs
❯ echo 34256 > cgroup.procs
❯ cat cgroup.procs
34256
- cgroup.threads:可读可写,处于当前 cgroup 中的所有线程,每行一个 TID,没有顺序,并且可能存在重复。
向cgroup.procs中写入 PID 后,cgroup 会向cgroup.threads文件中追加进程中所有线程的 TID。
❯ cat cgroup.threads
34256
34257
34258
34259
34260
34261
- cgroup.stat:只读文件,展示当前 cgroup 的状态,包括以下字段:
❯ cat cgroup.stat
nr_descendants 2
nr_dying_descendants 0
nr_descendants:当前 cgroup 下子 cgroup 的总数。
mkdir test2
❯ cat cgroup.stat
nr_descendants 3
nr_dying_descendants 0
nr_dying_descendants:当前 cgroup 下正在被删除的子 cgroup 数量。
- cgroup.subtree_control:可读可写,当前 cgroup 的子 cgroup 启用的 controller 列表。向该文件写入以“+”或“-”为前缀的 controller 名称列表为子 cgroup 启用或禁用 controller。
❯ cat cgroup.subtree_control
❯ echo "+memory" > cgroup.subtree_control
❯ cat test1/cgroup.controllers
memory
当前 cgroup 中存在进程时,写入不会成功:
❯ echo "+memory" > cgroup.subtree_control
echo: write error: device or resource busy
写入当前 cgroup 没有启用的 controller 时,不会成功:
❯ cat cgroup.controllers
memory
❯ echo "+cpu" > cgroup.subtree_control
echo: write error: no such file or directory
当同时写入多个 controller 时,要么全成功,要么全失败,不存在部分成功的情况:
❯ echo "+memory +cpu" > cgroup.subtree_control
echo: write error: no such file or directory
❯ cat test1/cgroup.controllers
虽然启用 memory controller 可以成功,但是启用 cpu controller 的时候失败了,所以 memory controller 也没有启用。
- cgroup.type:可读可写,存在于非 root cgroup 中。可选的值:
“domain”:正常的有效 domain cgroup,默认类型。
“domain threaded”:threaded 类型 domain cgroup,作为 threaded 子树的根结点。
“domain invalid”:无效的 cgroup,不能启用 controller,不能加入进程。可以转换为 threaded 类型的 cgroup。
“threaded”:threaded 类型 cgroup,位于 threaded 子树中。
❯ cat cgroup.type
domain
- cpu.pressure
当前 cgroup 的 CPU 压力情况,基于 PSI[6](Pressure Stall Information)实现,这是 kernel 引入的一种评估系统压力的机制。内容如下:
❯ cat cpu.pressure
some avg10=0.00 avg60=0.00 avg300=0.00 total=0
full avg10=0.00 avg60=0.00 avg300=0.00 total=0
pressure值分为两行,avg10、avg60、avg300 分别表示 10s、60s、300s 时间周期内阻塞(stall)时间的百分比。total 是累计时间,单位 ms。
some行表示只有有一个任务在 cpu 资源上阻塞。full 行表示所有非 idle 状态任务同时在 cpu 资源上阻塞,此时,cpu 资源完全浪费,严重影响性能。
在以下示例中,每个格子代表 10s,有颜色的格子代表在这段时间(为了方便,以 10s 为单位)内 cpu 处于阻塞状态。
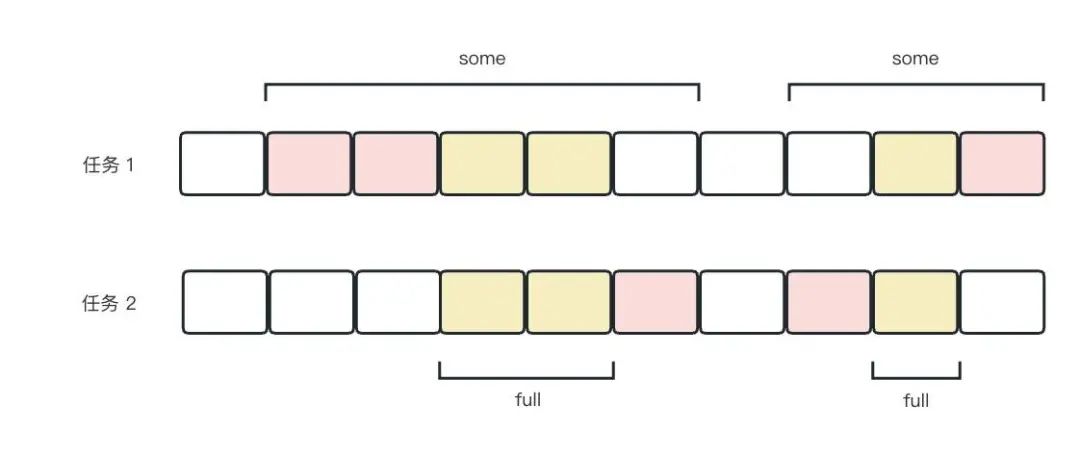
some 阻塞时间的百分比为 80s/100s=80%,full 阻塞时间的百分比为 30/100=30%。
- io.pressure
和cpu.pressure类似,表示当前 cgroup 内 io 资源阻塞时间的占比。
❯ cat io.pressure
some avg10=0.00 avg60=0.00 avg300=0.00 total=0
full avg10=0.00 avg60=0.00 avg300=0.00 total=0
- memory.pressure
和cpu.pressure类似,表示当前 cgroup 内 memory 资源阻塞时间的占比。
❯ cat cpu.pressure
some avg10=0.00 avg60=0.00 avg300=0.00 total=0
full avg10=0.00 avg60=0.00 avg300=0.00 total=0
- cpu.stat:统计当前 cgroup 中 cpu 资源的使用情况。
❯ cat cpu.stat
usage_usec 2400
user_usec 0
system_usec 2400
usage_usec:总的 cpu 时间。
user_usec:用户态进程占用 cpu 的时间。
system_usec:内核态进程占用 cpu 的时间。
V1 和 V2 主要区别
参考 facebook Chris Down 提到的例子[7]。
在 cgroup v1 中,每种资源一个层级。对于 bg 和 adhoc 两个 cgroup,bg 需要限制 blkio 和 memory 两种资源,adhoc 需要限制 memory 和 pids 两种资源。cgroup v1 场景的视图如下:
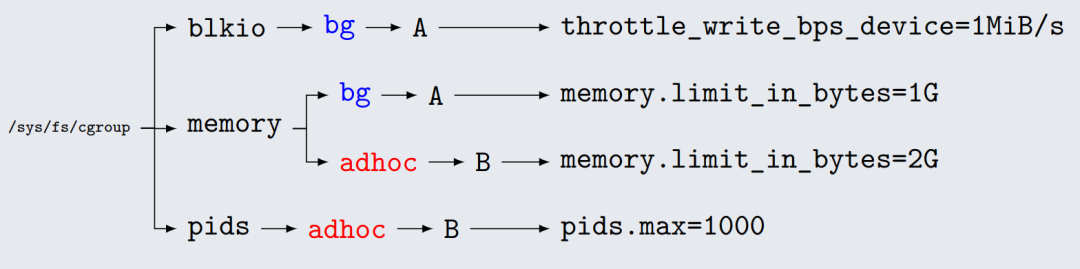
对于 cgroup v2,由于所有资源都在同一个 cgroup 下管理,通过 cgroup.sub_controller 控制子 cgroup 启用的 controller,这样一来,视图以 cgroup 为单位,更加清晰和便于管理。

参考资料
[1] process containers: https://lwn.net/Articles/236038/
[2] unified hierarchy: https://lkml.org/lkml/2014/3/13/503
[3] cgroup v2: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/diff/Documentation/cgroup-v2.txt?id=v4.5&id2=v4.4
[4] 只对 cpuset 子系统有效: https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt
[5] 在 cgroup V2 中已经移除: https://www.kernel.org/doc/Documentation/cgroup-v2.txt
[6] PSI: https://docs.kernel.org/accounting/psi.html#psi
[7] Chris Down 提到的例子: https://chrisdown.name/talks/cgroupv2/cgroupv2-fosdem.pdf


 浙公网安备 33010602011771号
浙公网安备 33010602011771号