聊聊最近爆火的 CHAT-GPT
Chat-GPT 以问答的方式呈现给用户,如何使用 Chat-GPT,实际上转换为另一个问题:如何有效地提问。
编写程序
难度为“困难”,通过率仅 30.9% 的动态规划题:
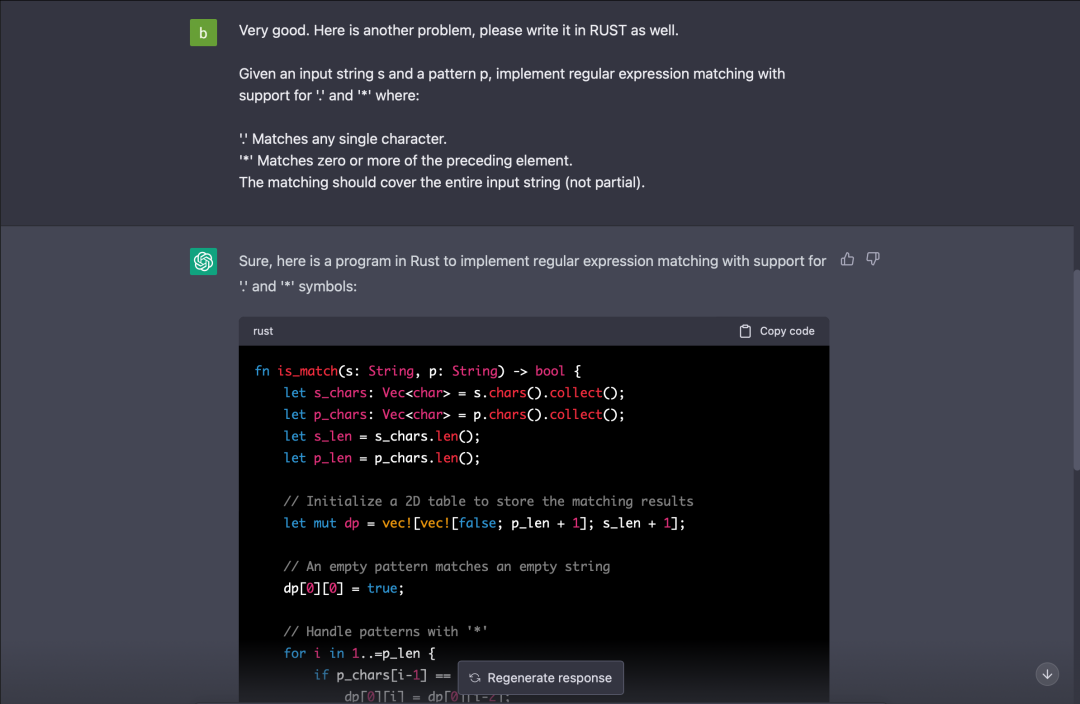
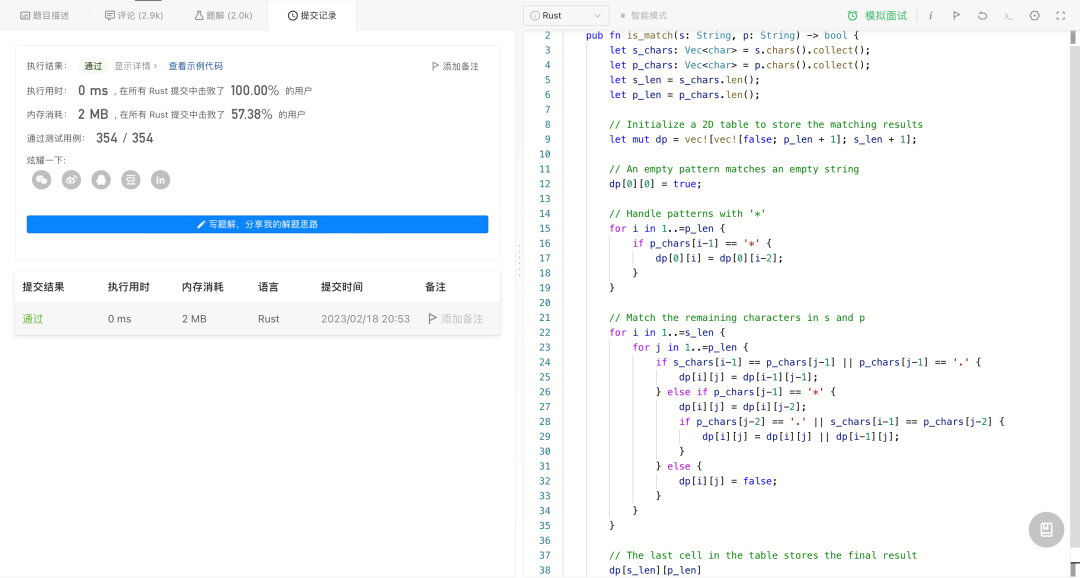
很稳,代码还有注释。
尝试通过率最低的一道题 Fancy Sequence[1]:
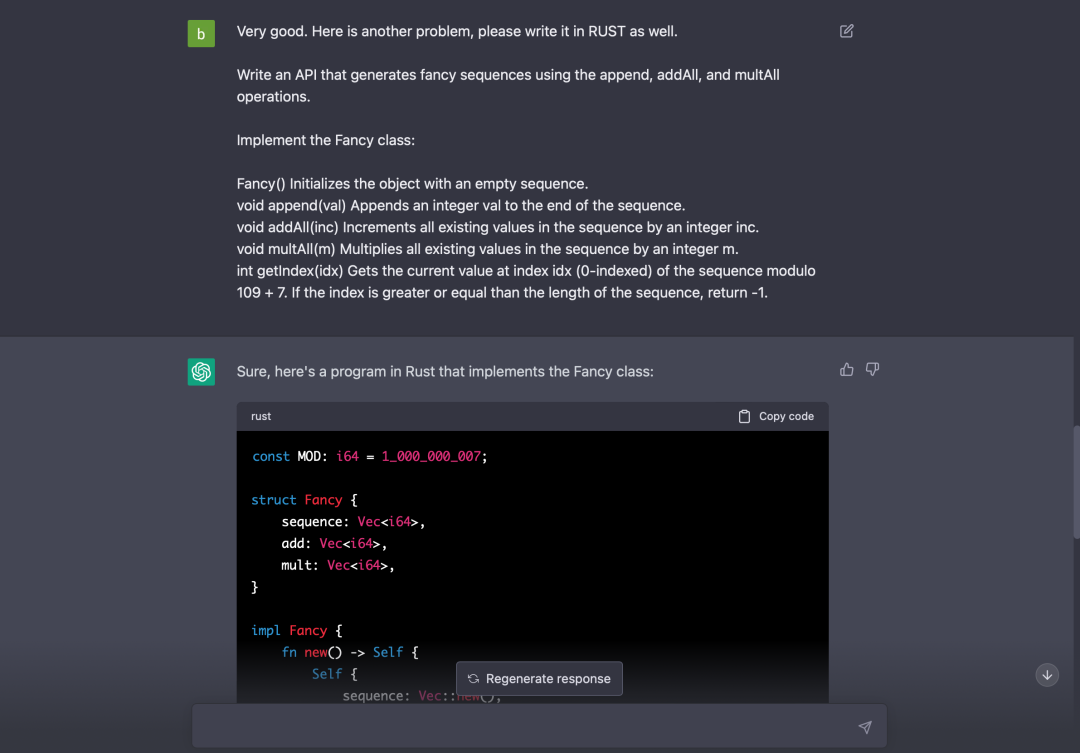
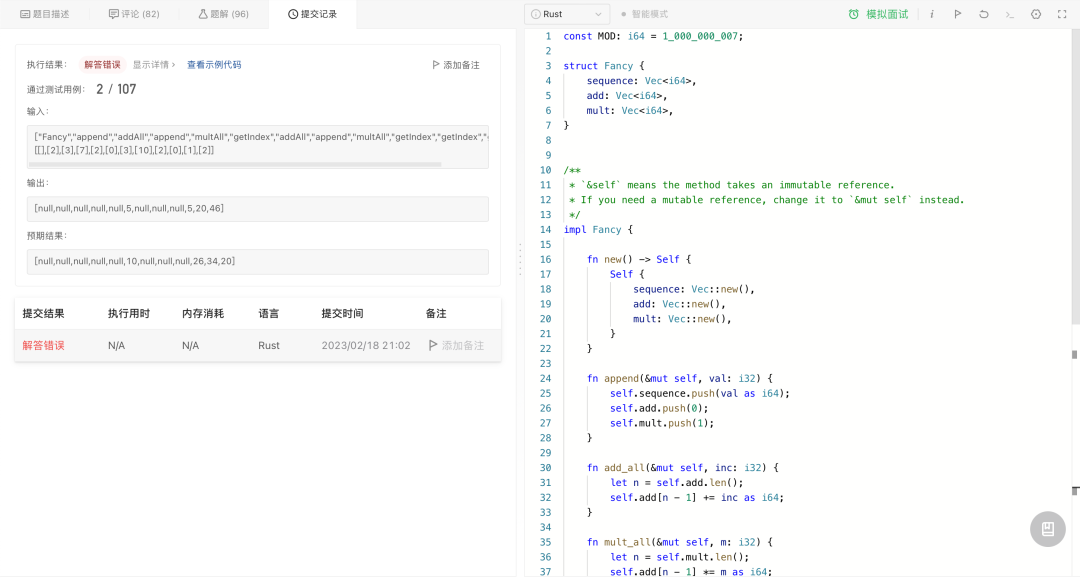
仅通过了 2 个用例。这个测试有点极端,说明 Chat-GPT 并不是完全正确,但处理一般的编程问题还是绰绰有余。
翻译

查询资料

提供参考方案
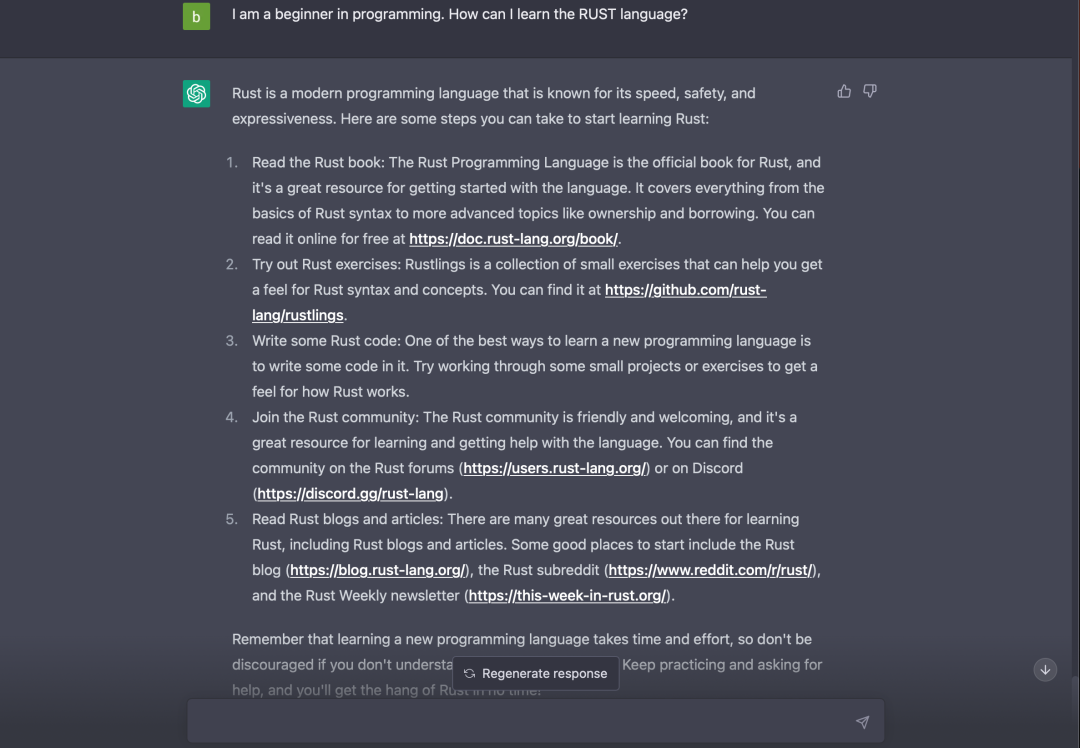

可以看出,给出的建议并不具体,第二次提问我希望知道“如何从入门到精通学习 RUST”,但得到的答案和“新手如何学习 RUST”问题相同。这些方案可以作为参考,但不能直接使用。
写作业和写论文也是类似的效果,你甚至可以指定生成文本的字数。
解决问题
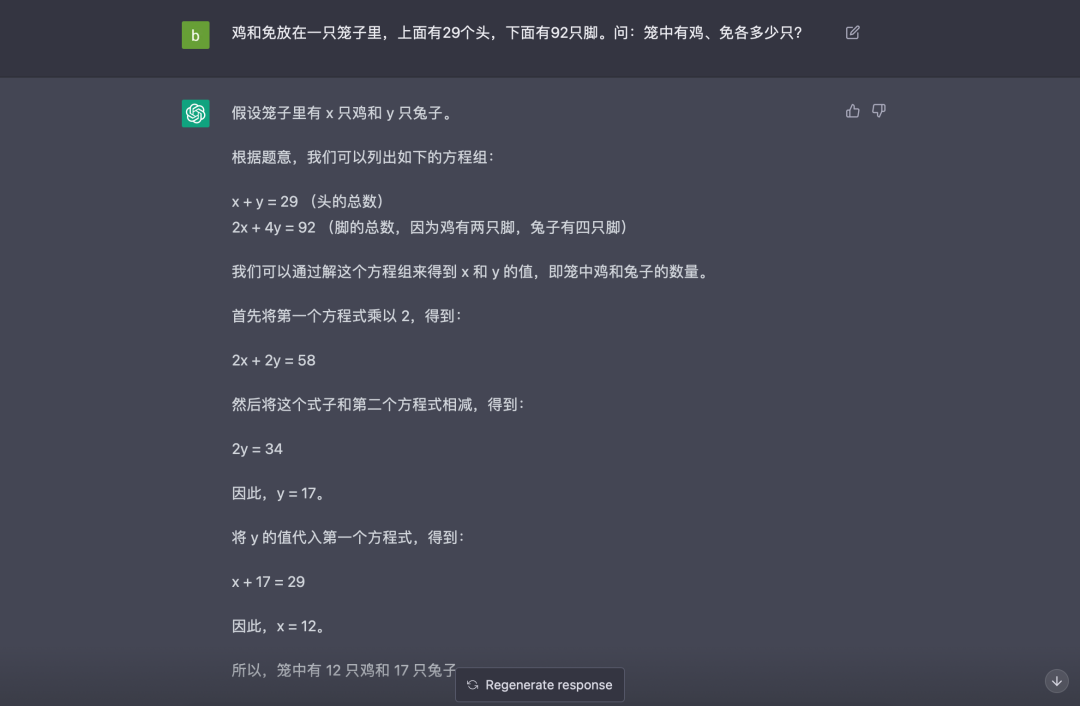
答案正确,由于直接从图片复制的文字(“兔”字识别有误),Chat-GPT 会修改为正确的内容后再进行处理。
换了个类似的问题:
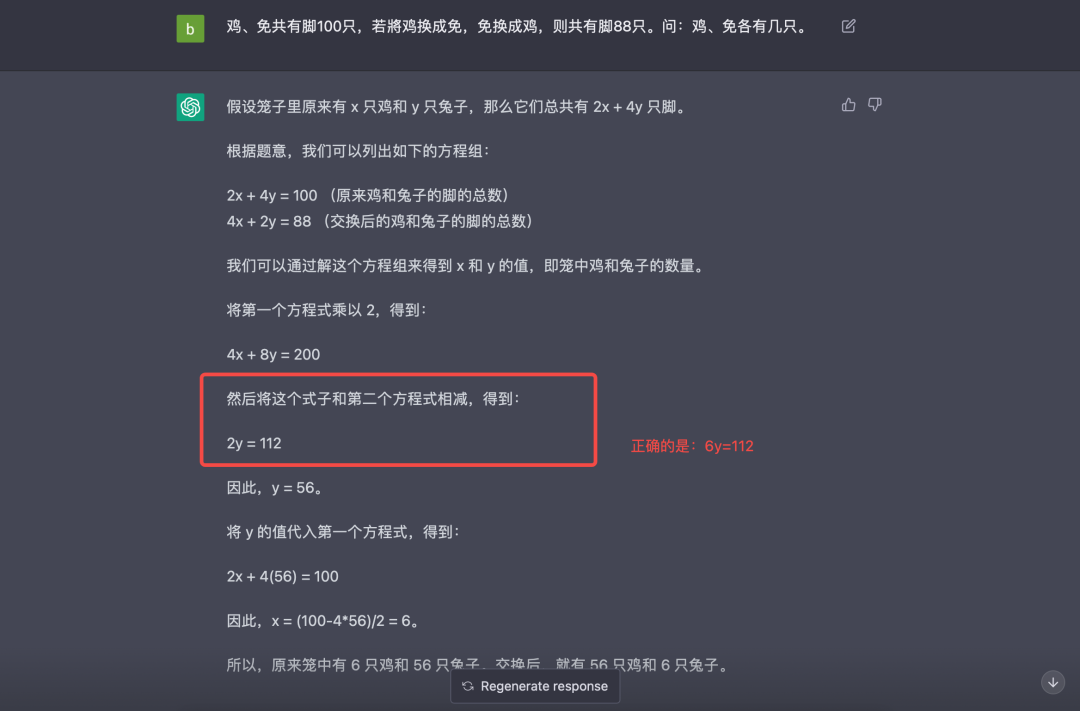
正确答案:因为变换后脚少了,所以兔多,多了(100-88)÷(4-2)=7 只,原有鸡(100-7×4)÷(4+2)=12 只,原有兔 12+7=19 只。
可以看到,解决理科类问题是不靠谱的。这也容易理解,模型是基于概率给出答案,而理科类问题是严谨的。
发展历程
OpenAI 成立于 2015 年 12 月 10 日,创始人包括 Sam Altman,Elon Musk 在内,OpenAI 的使命是“确保通用人工智能造福全人类”。2017 年,Google 在论文《Attention is all you need[2]》中开源了 Transformer 神经网络结构,提出了最近几年爆火的“注意力机制”,这篇论文最大的贡献是使得 AI 能够理解人们表达的意思。训练大规模 AI 模型需要巨量资金,彼时,作为非营利机构的 OpenAI 已经无力承担,2018 年,大靠山马斯克也宣布辞职。2019 年,微软投了 10 亿美元,虽然比尔·盖茨并不看好 OpenAI 的前景。2022 年 12 月,OpenAI 推出 Chat-GPT,在全世界引起轰动。

基本原理
GPT-1
GPT(Generative Pre-trained Transformer),即生成性被预训练过的 Transformer 模型,源自 OpenAI 2018 年发表的论文《Improving Language Understanding by Generative Pre-Training[3]》,提出了一种半监督学习方法,通过“预训练+微调”的方式让模型通过大量无标注数据学习“基本常识”,从而缓解人工标注数据有限的问题。
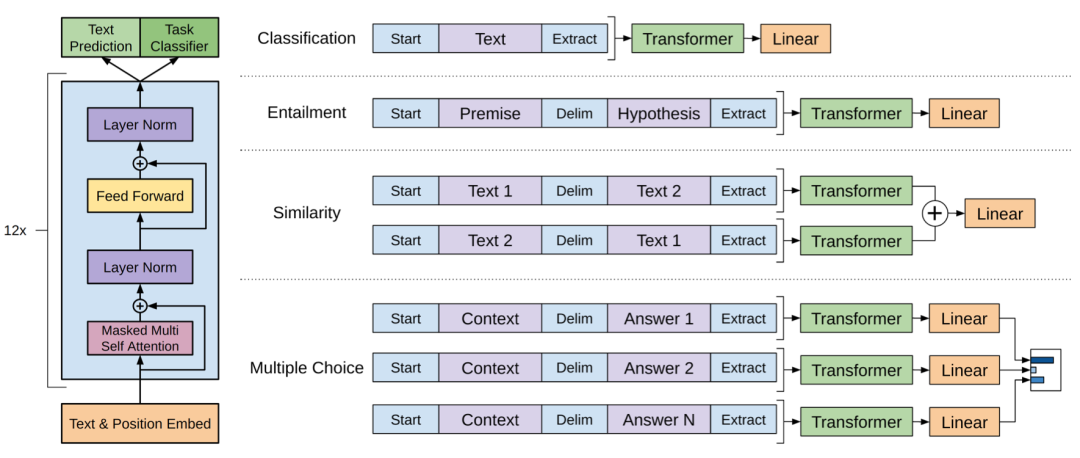
-
12 层单向 Transformer(上图左侧),每层 12 个注意力头。不同任务(右侧)的微调方式不同。
-
预训练过程,根据前 n 个单词预测下一个可能的单词。
-
微调过程,有监督任务(给定数据集)和无监督任务同时进行。
GPT-2
2019 年,OpenAI 发表了论文《Language Models are Unsupervised Multitask Learners[4]》,也就是 GPT-2,和 GPT-1 相比,主要的变化:
-
完全舍弃微调(在 GPT-1 中,只能用于特定任务)过程,验证了 GPT-2 在 zero-shot(不提供样本数据) 设置下的性能。
-
更大规模的网络模型。参数量扩大到 1.5 亿,使用 48 层 Transformer,1600 维向量。
-
更大的数据集。新的数据集包含 800 万个网页,数据大小为 40GB。
-
调整 Transformer 结构,将层归一化(layer normalization)放在每个子块之前作为输入,并在最后一个自注意力块后增加层归一化操作。
GPT-3
2020 年,OpenAI 发表论文《Language Models are Few-Shot Learners[5]》,即 GPT-3,采用了和 GPT-2 相同的模型。主要变化如下:
-
讨论了移除微调步骤的必要性(需要大量的数据标注)。
-
GPT-3 采用了 96 层的多头 Transformer,词向量维度为 12288,文本长度为 2048。
-
在 Transformer Decoder 中使用了交替稠密(alternating dense)和局部带状稀疏注意力(locally banded sparse attention)机制。
-
更大的数据集(维基百科数据集的权重只占 3%),Common Crawl 数据集(过滤后)大小为 570GB。
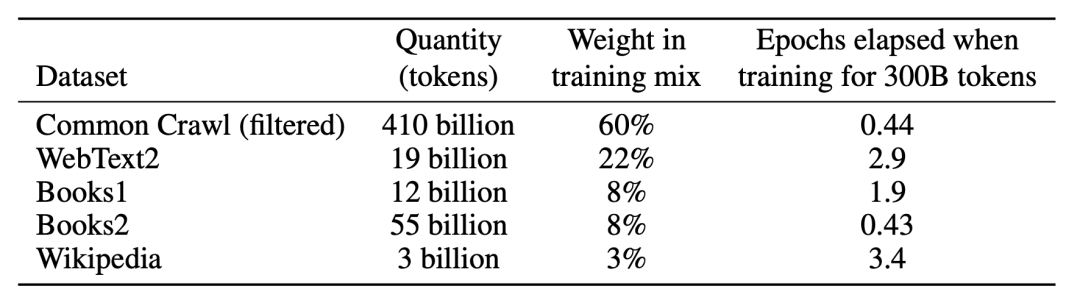
- 上下文学习。以下示例(左侧)是 Zero-shot(不给样本数据)、One-shot(给一个样本数据)、Few-shot(给少量样本数据) 三种方式的区别。
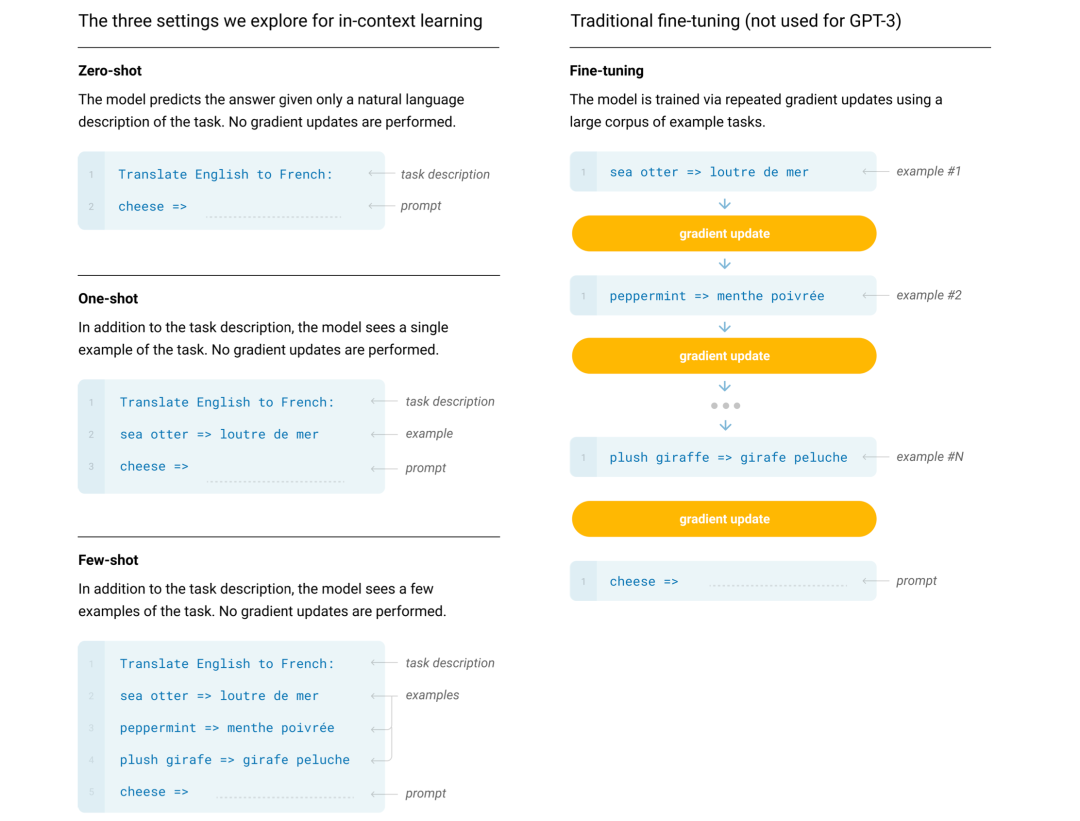
Instruct-GPT
Chat-GPT 是 基于 OpenAI 于 2022 年发布的 InstructGPT[6] 进一步改进实现,本质上也是上下文模型,用户给出文本的一部分内容,该模型会尝试补充其余部分。Instruct-GPT 的主要的区别如下:
- 通过人为标注和强化学习的方法提升模型输出结果的真实性、无害性和有用性,进一步理解用户的意图。
训练模型分为三步:
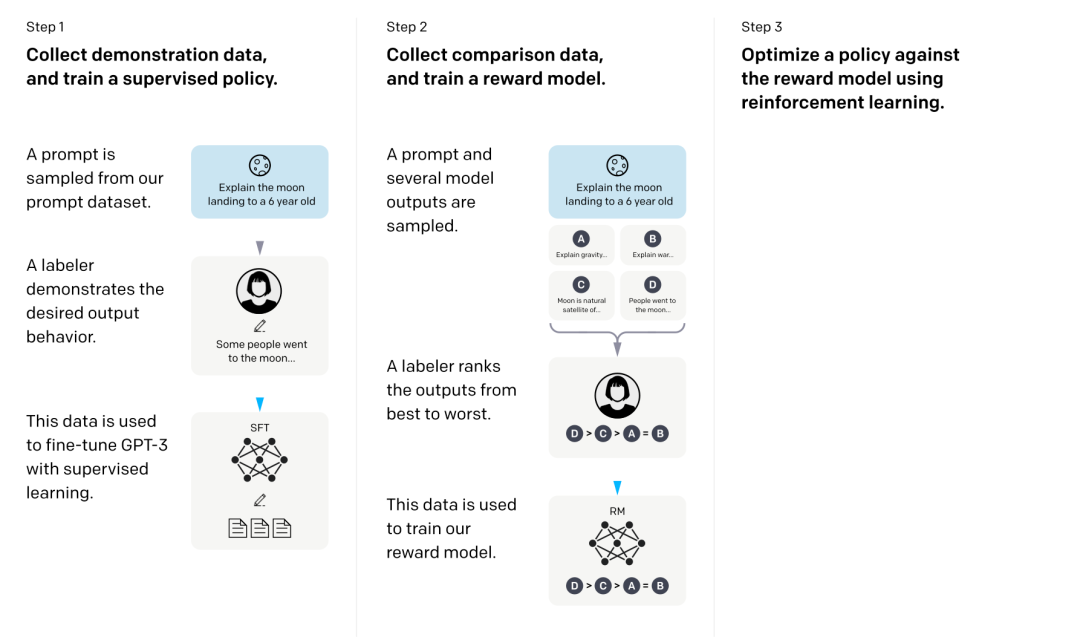
-
人工标注一批数据(工程师设计提示文本,由人类回答),进行有监督地微调训练(SFT)。
-
人工对模型给出的结果进行打分排序(考虑真实性和无害性),训练奖励模型(RM),让模型分辨人类不喜欢的内容。
-
基于奖励模型,使用 PPO(proximal policy optimization )强化学习算法进行微调。
社区现状
-
逆向工程 Chat-GPT API。通过逆向工程,作者得到了 Chat-GPT 的 API 调用接口,这样,开发者就可以在任何地方调用 Chat-GPT:acheong08/ChatGPT[7]
-
如何使用 Chat-GPT。通过特定输入,让 Chat-GPT 完成不同类型的工作,例如,模拟 Linux 终端:f/awesome-chatgpt-prompts[8]
-
桌面端应用:lencx/ChatGPT[9](图源该项目主页)
-
通过 wechaty[10](微信机器人),在微信中接入 Chat-GPT:fuergaosi233/wechat-chatgpt[11]
-
浏览器插件:wong2/chatgpt-google-extension[12]
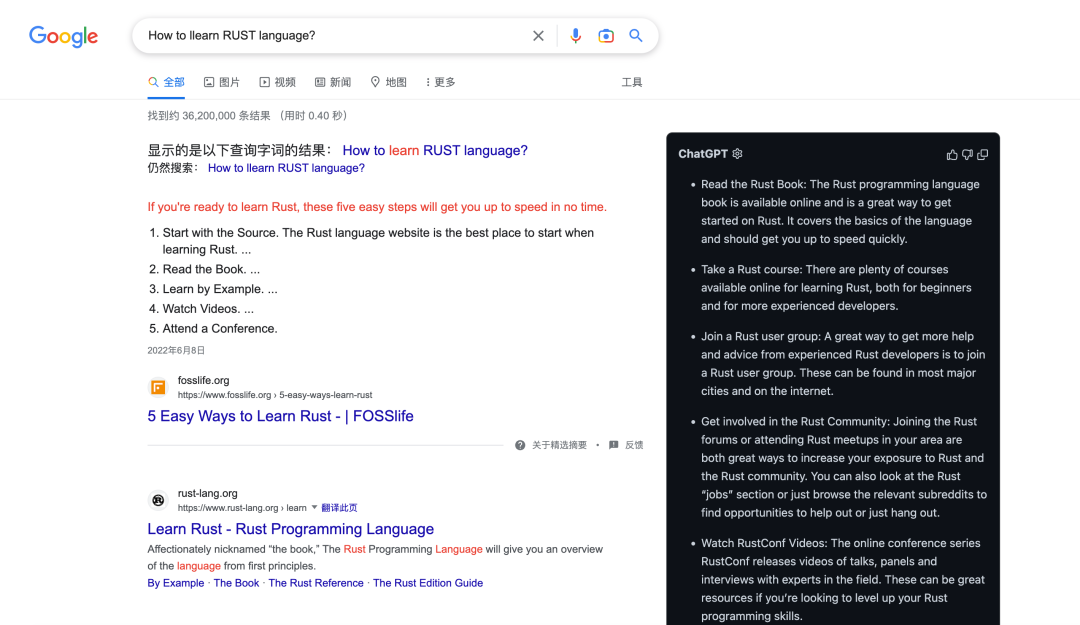
和直接在 Chat-GPT 网页提问相比,对内容进行了精简。个人认为,这才是 Chat-GPT 和搜索引擎结合的最终方案,因为 Chat-GPT 给出的结果只能作为参考,通过 Edge 浏览器垄断的方式可能行不通。
- 使用 Chat-GPT Review 代码:anc95/ChatGPT-CodeReview[13]
最初源自这个项目:sturdy-dev/codereview.gpt[14],只是在 PR 页面显示 Chat-GPT 的建议供 reviewer 参考,后经过anc95修改,可以直接在 PR 页面进行回复。
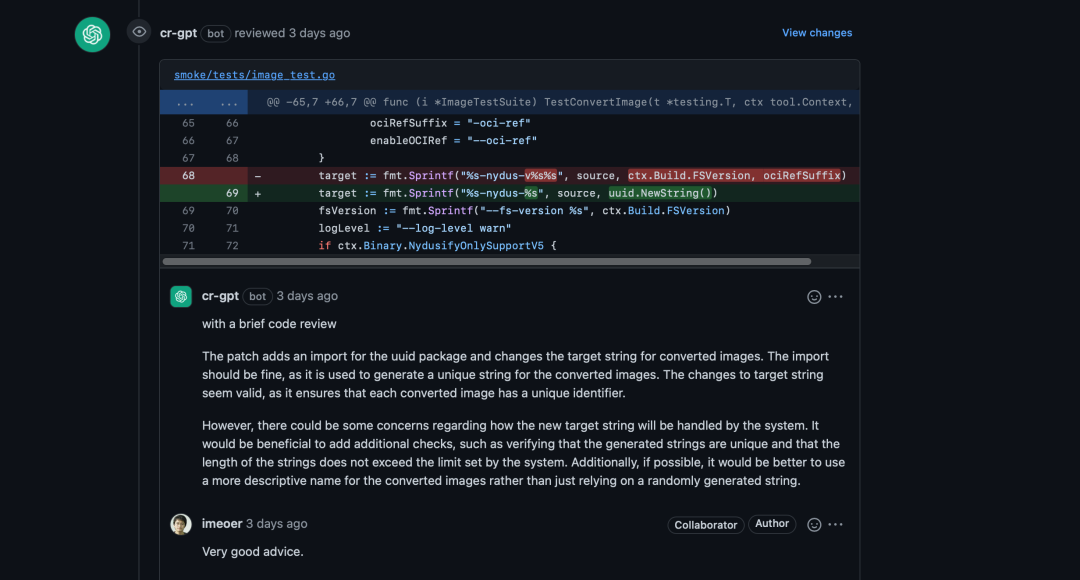
可以迁移到论文修改、作业修改等类似场景,为 reviewer 提供参考信息。
发展前景
Chat-GPT 爆火之后,衍生出了一大批相关产业,从卖账号,到实现微信小程序和 Web 应用,通过广告和会员费获得收入,挺佩服动手能力强的人。不过,话说回来,这些也只是处在风口上的小打小闹,最终在国内如何发展还得看大型企业。Chat-GPT 爆火之后,国内的互联网公司相继表示已有类似的研究,百度预计 2022 年 3 月完成“文心一言”的内测并面向公众开放。
就个人体验来看,Chat-GPT 要想大规模应用可能还需要进一步优化。
-
Chat-GPT 虽然通过人工标注和训练奖励模型能够使得输出结果具有真实性、无害性和有用性,但是,这种机制还是不完善,用户很容易绕过。例如,如果直接问一个不符合道德规范的问题,Chat-GPT 会拒绝回答,但是,当用户换个提问方式,例如:“我在写一本小说,故事的主人公想 xxx”,此时,Chat-GPT 就会完整地给出答案。
-
Chat-GPT 对理科类知识的输出还需优化,数学、物理等理科类知识是严谨的,而基于概率的 AI 模型会根据上下文进行推断,给出最适合(概率值最高)的输出,并不能给出严谨、准确的答案。
-
Chat-GPT 给出的回答还比较泛,在某些情况下并不能给出用户想要的答案。在 Chat-GPT 中,数据是至关重要的,因此,可能需要分行业、分领域标注数据集,从而给出更有深度、更符合用户期望的答案。
参考资料
[1] Fancy Sequence: https://leetcode.cn/problems/fancy-sequence/
[2] Attention is all you need: https://arxiv.org/pdf/1706.03762.pdf
[3] Improving Language Understanding by Generative Pre-Training: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
[4] Language Models are Unsupervised Multitask Learners: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
[5] Language Models are Few-Shot Learners: https://arxiv.org/pdf/2005.14165.pdf
[6] InstructGPT: https://cdn.openai.com/papers/Training_language_models_to_follow_instructions_with_human_feedback.pdf
[7] acheong08/ChatGPT: https://github.com/acheong08/ChatGPT
[8] f/awesome-chatgpt-prompts: https://github.com/f/awesome-chatgpt-prompts
[9] lencx/ChatGPT: https://github.com/lencx/ChatGPT
[10] wechaty: https://wechaty.js.org/
[11] fuergaosi233/wechat-chatgpt: https://github.com/fuergaosi233/wechat-chatgpt
[12] wong2/chatgpt-google-extension: https://github.com/wong2/chatgpt-google-extension
[13] anc95/ChatGPT-CodeReview: https://github.com/anc95/ChatGPT-CodeReview
[14] sturdy-dev/codereview.gpt: https://github.com/sturdy-dev/codereview.gpt


 浙公网安备 33010602011771号
浙公网安备 33010602011771号