nydusd 源码理解(一)
“
尝试通过 nydus[1] 源码理解工作流程。可能由于代码变动导致和本文记录的内容有出入。
1. 环境准备
git clone https://github.com/dragonflyoss/image-service.git
cd image-service
make
编译的目标文件位于 target 文件夹内,默认编译的 debug 版本。

可以看到,项目的二进制文件包含 nydusctl (命令行工具)、nydusd(nydus 主体程序,以守护进程的形式运行)、nydus-image(nydus 镜像文件处理工具)三种。
all: build
# Targets that are exposed to developers and users.
build: .format
${CARGO} build $(CARGO_COMMON)$(CARGO_BUILD_FLAGS)
# Cargo will skip checking if it is already checked
${CARGO} clippy $(CARGO_COMMON) --workspace $(EXCLUDE_PACKAGES) --bins --tests -- -Dwarnings
.format:
${CARGO} fmt -- --check
执行 make编译项目时,会首先使用 cargo fmt -- --check 命令对代码格式进行检查。
本文使用的 nydus 版本:
./target/debug/nydusd --version

2. 代码流程理解
项目的入口函数位于 src/bin 目录下:
分别对应生成的二进制文件 nydusctl、nydusd 和 nydus-image,首先,理解最重要的部分nydusd。
“
Nydusd 是运行在用户态的守护进程,可以通过 nydus-snapshotter 进行管理,主要负责处理 fuse 下发的 I/O 请求,当数据不存在本地缓存时,从 backend(registry,OSS,localfs)获取数据内容。
nydusd启动命令:
mkdir /rafs_mnt
./target/debug/nydusd fuse --thread-num 4 --mountpoint /rafs_mnt --apisock api_sock
2.1 入口函数
src/bin/nydusd/main.rs
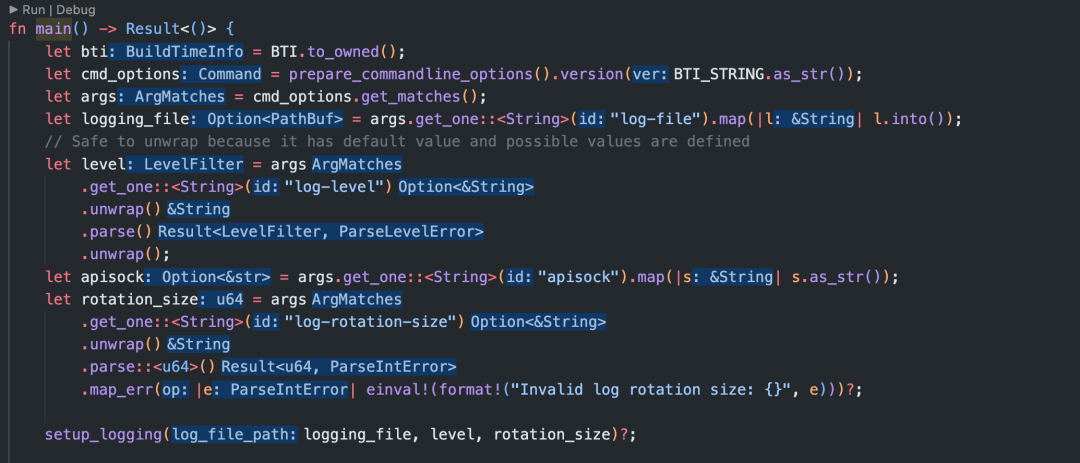
首先,从命令行提取参数值,开启日志。
接下来是解析子命令,nydusd 包括 3 个子命令,分别是 singleton、fuse 和 virtiofs:
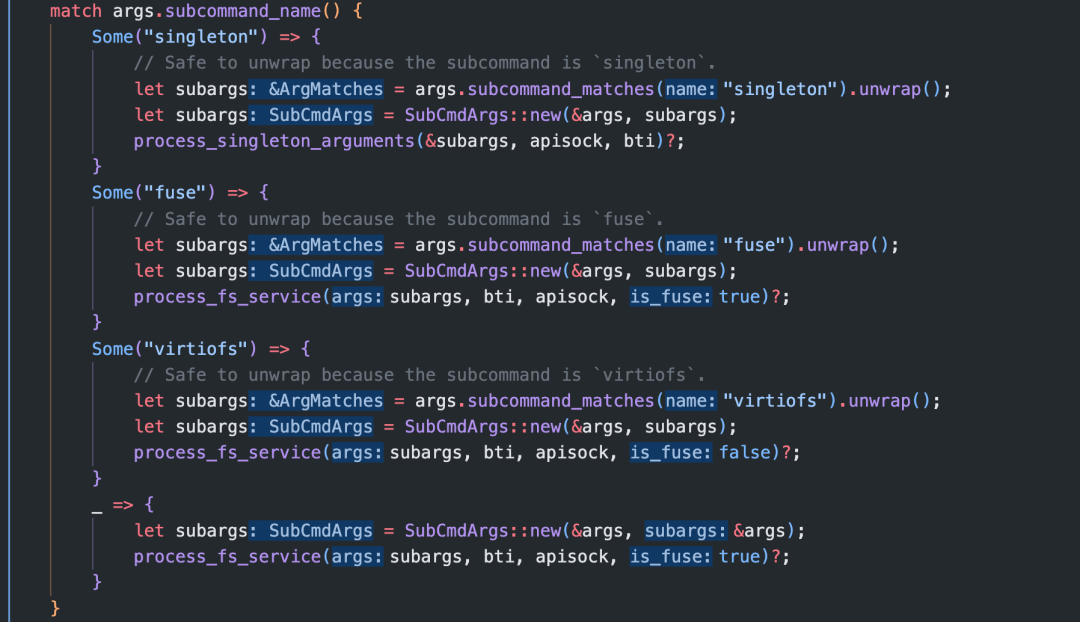
对于每个子命令,都会再次获取对应的命令参数也就是 args 中 subcommand 的参数内容。fuse指定nydusd 作为专门针对 FUSE 的 server 运行,virtiofs指定nydusd专门作为 virtiofs 的 server 运行,singleton指定nydusd作为全局守护进程运行,可以同时为 blobcache/fscache/fuse/virtio-fs 提供服务。

2.2 FUSE subcommand 启动流程
process_default_fs_service(subargs, bti, apisock, true)?;
// 函数声明
fn process_default_fs_service(
args: SubCmdArgs, //提取的子命令参数
bti: BuildTimeInfo, // 编译时信息
apisock: Option<&str>, // api socket 路径
is_fuse: bool, // 是否为 fuse 文件系统
) -> Result<()> { 内容太长,省略 }
该函数初始化默认的文件系统服务。
首先根据三个参数生成挂载命令:

virtual_mnt 是挂载的目录位置。
(1)shared_dir 不为空时
let cmd = FsBackendMountCmd {
fs_type: nydus::FsBackendType::PassthroughFs,
source: shared_dir.to_string(),
config: "".to_string(),
mountpoint: virtual_mnt.to_string(),
prefetch_files: None,
};
(2)bootstrap 不为空(只使用 rafs 文件系统)
检测是否传入localfs-dir参数,如果传入,则根据传入的参数生成配置信息,否则,必须传入config参数。此外,解析传入的 prefetch_files 列表:
let config = match args.value_of("localfs-dir") {
Some(v) => {
format!(
r###"
{{
"device": {{
"backend": {{
"type": "localfs",
"config": {{
"dir": {:?},
"readahead": true
}}
}},
"cache": {{
"type": "blobcache",
"config": {{
"compressed": false,
"work_dir": {:?}
}}
}}
}},
"mode": "direct",
"digest_validate": false,
"iostats_files": false
}}
"###,
v, v
)
}
None => match args.value_of("config") {
Some(v) => std::fs::read_to_string(v)?,
None => {
let e = DaemonError::InvalidArguments(
"both --config and --localfs-dir are missing".to_string(),
);
returnErr(e.into());
}
},
};
let prefetch_files: Option<Vec<String>> = args
.values_of("prefetch-files")
.map(|files| files.map(|s| s.to_string()).collect());
let cmd = FsBackendMountCmd {
fs_type: nydus::FsBackendType::Rafs,
source: b.to_string(),
config: std::fs::read_to_string(config)?,
mountpoint: virtual_mnt.to_string(),
prefetch_files,
};
当生成挂载命令cmd后,接下来会根据 opts 参数新建 vfs 实例。
let vfs = fuse_backend_rs::api::Vfs::new(opts);
let vfs = Arc::new(vfs);
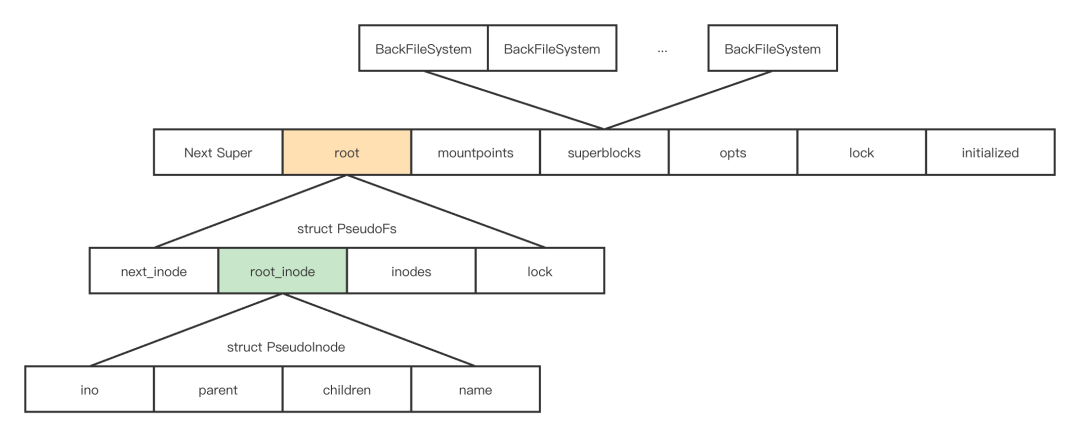
2.3 Vfs 结构体分析
/// A union fs that combines multiple backend file systems.
pubstruct Vfs {
next_super: AtomicU8,
root: PseudoFs,
// mountpoints maps from pseudo fs inode to mounted fs mountpoint data
mountpoints: ArcSwap<HashMap<u64, Arc<MountPointData>>>,
// superblocks keeps track of all mounted file systems
superblocks: ArcSuperBlock,
opts: ArcSwap<VfsOptions>,
initialized: AtomicBool,
lock: Mutex<()>,
}
新建 Vfs 实例的时候:
impl Vfs {
/// Create a new vfs instance
pubfn new(opts: VfsOptions) -> Self {
Vfs {
// 下一个可用的 pseudo index
next_super: AtomicU8::new((VFS_PSEUDO_FS_IDX + 1) asu8),
// 挂载点,是一个 Hashmap
mountpoints: ArcSwap::new(Arc::new(HashMap::new())),
// 超级块,数组
superblocks: ArcSwap::new(Arc::new(vec![None; MAX_VFS_INDEX])),
// root,是一个 PseudoFs 实例
root: PseudoFs::new(),
// 传入的参数
opts: ArcSwap::new(Arc::new(opts)),
// 锁
lock: Mutex::new(()),
// 是否已经初始化
initialized: AtomicBool::new(false),
}
}
...
}
next_super的值初始化为 1,长度为 64 位的 inode number 被拆分为两部分,前 8 位用于标记被挂载的文件系统类型,剩下的 56 位供后端文件系统使用,最大值为VFS_MAX_INO。
/// Maximum inode number supported by the VFS for backend file system
pubconst VFS_MAX_INO: u64 = 0xff_ffff_ffff_ffff;
// The 64bit inode number for VFS is divided into two parts:
// 1. an 8-bit file-system index, to identify mounted backend file systems.
// 2. the left bits are reserved for backend file systems, and it's limited to VFS_MAX_INO.
const VFS_INDEX_SHIFT: u8 = 56;
const VFS_PSEUDO_FS_IDX: VfsIndex = 0;
Vfs结构体中root的类型为PseudoFs:
pubstruct PseudoFs {
// 下一个可用的 inode
next_inode: AtomicU64,
// 根 inode,指向 PseudoInode 类型的指针
root_inode: Arc<PseudoInode>,
// inodes,类行为 Hashmap
inodes: ArcSwap<HashMap<u64, Arc<PseudoInode>>>,
lock: Mutex<()>, // Write protect PseudoFs.inodes and PseudoInode.children
}
PseudoInode类型:
struct PseudoInode {
// 当前 inode
ino: u64,
// parent 的 inode
parent: u64,
// children 的列表(PseudoInode 类型的指针)
children: ArcSwap<Vec<Arc<PseudoInode>>>,
name: String,
}
nydus 中 Vfs 结构体的组成图示:
回到新建 vfs 实例之后的流程。接下来会获取 daemon_id 和 supervisor 参数(在 live-upgrade/failover 的时候需要)。
然后,根据挂载命令创建 NydusDaemon。
2.4 针对 FUSE 的 NydusDaemon
is_fuse 为 true 时,开始创建 daemon:
(1)获取 fuse server 的线程数量值;
(2)获取 mountpoint 参数的值;
(3)创建 daemon
let daemon = {
fusedev::create_fuse_daemon(
mountpoint, // 挂载点路径
vfs, // 创建的 vfs 实例
supervisor,
daemon_id,
threads, // 线程数量
apisock, // api socket 路径
args.is_present("upgrade"),
!args.is_present("writable"),
p, // failover-policy
mount_cmd, // 挂载命令
bti,
)
.map(|d| {
info!("Fuse daemon started!");
d
})
.map_err(|e| {
error!("Failed in starting daemon: {}", e);
e
})?
};
DAEMON_CONTROLLER.set_daemon(daemon);
在 fusedev::create_fuse_daemon 函数中,主要的逻辑如下:
(1)创建两个 channel
let (trigger, events_rx) = channel::<DaemonStateMachineInput>();
let (result_sender, result_receiver) = channel::<DaemonResult<()>>();
channel 是用于线程间通信,返回值分别为 sender 和 recver,例如:(trigger, events_rx) 中,trigger 为发送者,events_rx 为接收者。
(2)创建 Service 实例
let service = FusedevFsService::new(vfs, &mnt, supervisor.as_ref(), fp, readonly)?;
impl FusedevFsService {
fn new(
vfs: Arc<Vfs>,
mnt: &Path,
supervisor: Option<&String>,
fp: FailoverPolicy,
readonly: bool,
) -> Result<Self> {
// 创建和 FUSE 的 session
let session = FuseSession::new(mnt, "rafs", "", readonly).map_err(|e| eother!(e))?;
let upgrade_mgr = supervisor
.as_ref()
.map(|s| Mutex::new(UpgradeManager::new(s.to_string().into())));
Ok(FusedevFsService {
vfs: vfs.clone(),
conn: AtomicU64::new(0),
failover_policy: fp,
session: Mutex::new(session),
server: Arc::new(Server::new(vfs)),
upgrade_mgr,
backend_collection: Default::default(),
inflight_ops: Mutex::new(Vec::new()),
})
}
...
}
(3)创建 Daemon 实例:
let daemon = Arc::new(FusedevDaemon {
bti,
id,
supervisor,
threads_cnt, // 线程数量
state: AtomicI32::new(DaemonState::INIT asi32),
result_receiver: Mutex::new(result_receiver),
request_sender: Arc::new(Mutex::new(trigger)),
service: Arc::new(service),
state_machine_thread: Mutex::new(None),
fuse_service_threads: Mutex::new(Vec::new()),
});
其中,FusedevFsService::new() 函数会调用FuseSession::new函数,创建和内核 FUSE 通信的 session,只是还没有挂载和连接请求。
FuseSession::new() 为外部 fuse-backend-rs[2] creat,对应代码如下:
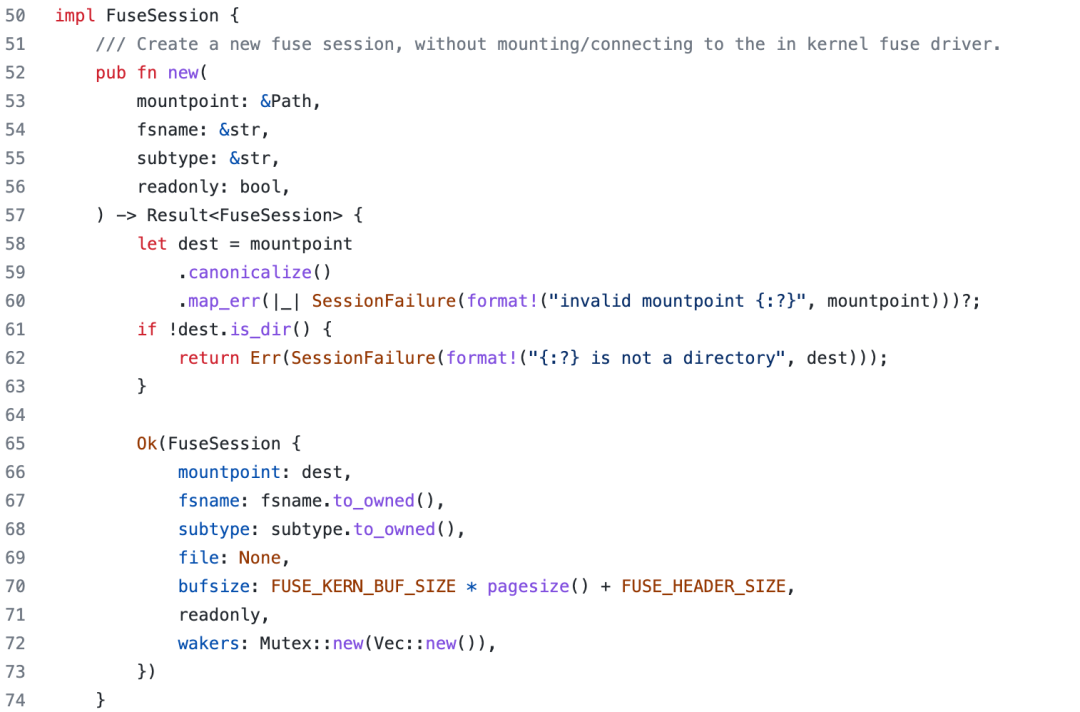
创建好的 session 实例存储在 FusedevFsService 结构体的 session 属性,同时用 Mutex 包裹,只允许互斥访问。
创建好的service 作为 FusedevDaemon 结构体 service 属性的值,使用 Arc 包裹,允许并发访问。
2.5 nydusd 状态机
machine 是 DaemonStateMachineContext 结构体的实例,存储了 daemon 的 PID,指向 daemon 实例的指针,以及接收请求和返回结果的 channel,用于线程间通信。
let machine = DaemonStateMachineContext::new(daemon.clone(), events_rx, result_sender);
nydusd 的状态机用于维护 nydusd 的状态,具体的状态转移策略如下:
state_machine! {
derive(Debug, Clone)
pub DaemonStateMachine(Init)
// Init意味着 nydusd 刚启动,可能已经配置好了,
// 但还没有和内核协商双方的能力,也没有尝试通过
// 挂载 /fuse/dev 来建立fuse会话(如果是fusedev后端)
Init => {
Mount => Ready,
Takeover => Ready[Restore],
Stop => Die[StopStateMachine],
},
// Ready表示 nydusd 已经准备就绪,
// Fuse会话被创建。状态可以转换为 Running 或 Die
Ready => {
Start => Running[StartService],
Stop => Die[Umount],
Exit => Die[StopStateMachine],
},
// Running 意味着 nydusd 已经成功地准备好了
// 作为用户空间 fuse 文件系统所需的内容,
// 但是,必要的 capability 协商可能还没有完成,
// 通过 fuse-rs 来判断
Running => {
Stop => Ready [TerminateService],
},
}
machine.kick_state_machine() 方法用于启动状态机线程。
let machine_thread = machine.kick_state_machine()?;
该线程的名称为state_machine,通过 top -Hp NYDUSD_PID 可以看到:
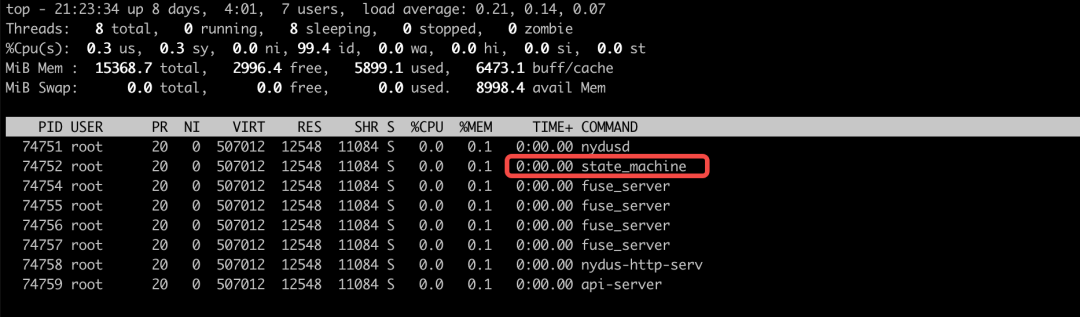
该线程是一个死循环,用于接收来自 channel 消息。(消息从哪发送?)
self.request_receiver.recv()
其中,recv() 函数会阻塞,接收 DaemonStateMachineInput 类型的消息,保存在 event 变量中,self.sm.consume(&event) 方法处理每个 event,完成相应操作,并修改状态为新的值。
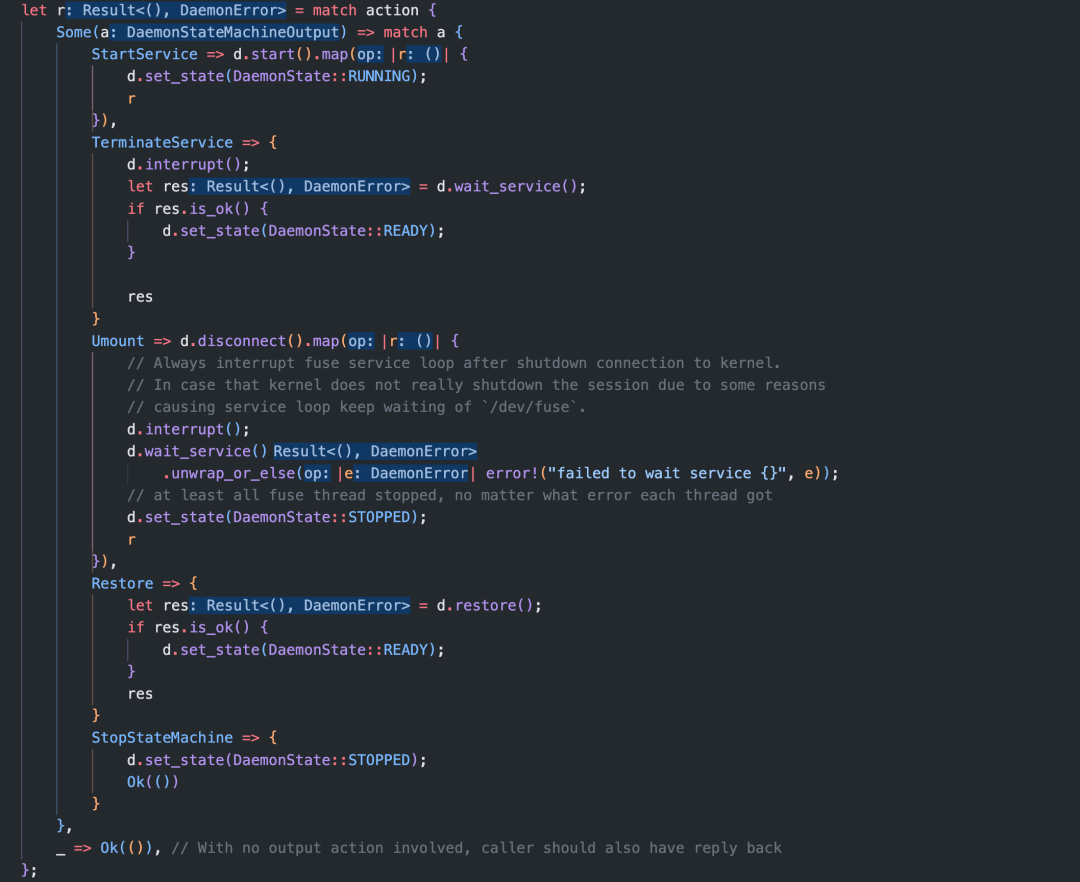
处理完成后,通过 result_sender channel 返回状态消息。(传递给谁?)
然后,会打印日志信息,包括上一次的状态,本次状态,输入和输出。
启动 nydusd 时打印的关于 State machine 的日志信息:

状态机线程接收的消息来自哪里呢?这就需要回到创建 channel的地方:
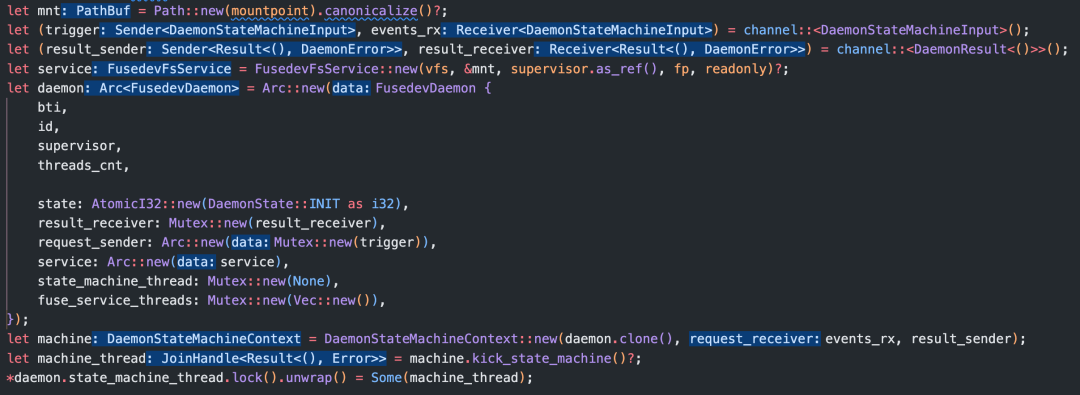
和request_receiver对应的 channel名为trigger,和result_sender对应的channel名为result_receiver,都存储在daemon中:
let daemon = Arc::new(FusedevDaemon {
...
result_receiver: Mutex::new(result_receiver),
request_sender: Arc::new(Mutex::new(trigger)),
...
});
这两个channel 在on_event函数中被使用:
impl DaemonStateMachineSubscriber for FusedevDaemon {
fn on_event(&self, event: DaemonStateMachineInput) -> DaemonResult<()> {
self.request_sender
.lock()
.unwrap()
.send(event)
.map_err(|e| DaemonError::Channel(format!("send {:?}", e)))?;
self.result_receiver
.lock()
.expect("Not expect poisoned lock!")
.recv()
.map_err(|e| DaemonError::Channel(format!("recv {:?}", e)))?
}
}
因此,state_machine 通过 channel接收来自nydusd 的消息,从而改变状态,例如,对于stop操作:
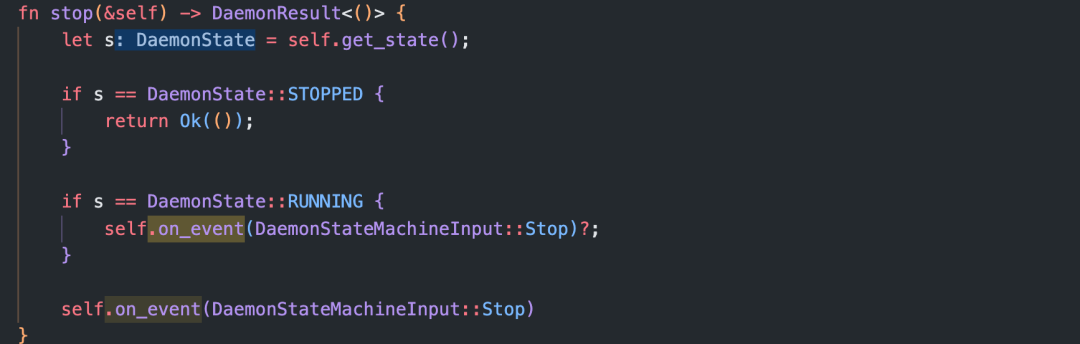
2.5.1 FUSE 启动 service
上面提到,state_machine线程会改变nydusd的状态,对于 StartService 事件,会运行 d.start() 方法,并且在运行成功之后通过 set_state(DaemonState::RUNNING) 将 Daemon 的状态设置为 RUNNING。
let r = match action {
Some(a) => match a {
StartService => d.start().map(|r| {
d.set_state(DaemonState::RUNNING);
r
}),
...
},
_ => Ok(()),
};
不同类型 Daemon 的 d.start() 方法实现不一样,对于 FusedevDaemon,start() 内容如下:
fn start(&self) -> DaemonResult<()> {
info!("start {} fuse servers", self.threads_cnt);
for _ in0..self.threads_cnt {
let waker = DAEMON_CONTROLLER.alloc_waker();
self.kick_one_server(waker)
.map_err(|e| DaemonError::StartService(format!("{:?}", e)))?;
}
Ok(())
}
这里会根据 threads_cnt,开启对应数量的线程。其中,DAEMON_CONTROLLER.alloc_waker() 只是复制了对 DAEMON_CONTROLLER.waker 的引用。
pubfn alloc_waker(&self) -> Arc<Waker> {
self.waker.clone()
}
kick_one_server(waker) 是 FusedevDaemon 结构体的方法:
fn kick_one_server(&self, waker: Arc<Waker>) -> Result<()> {
letmut s = self.service.create_fuse_server()?;
let inflight_op = self.service.create_inflight_op();
let thread = thread::Builder::new()
.name("fuse_server".to_string())
.spawn(move || {
ifletErr(err) = s.svc_loop(&inflight_op) {
warn!("fuse server exits with err: {:?}, exiting daemon", err);
ifletErr(err) = waker.wake() {
error!("fail to exit daemon, error: {:?}", err);
}
}
// Notify the daemon controller that one working thread has exited.
Ok(())
})
.map_err(DaemonError::ThreadSpawn)?;
self.fuse_service_threads.lock().unwrap().push(thread);
Ok(())
}
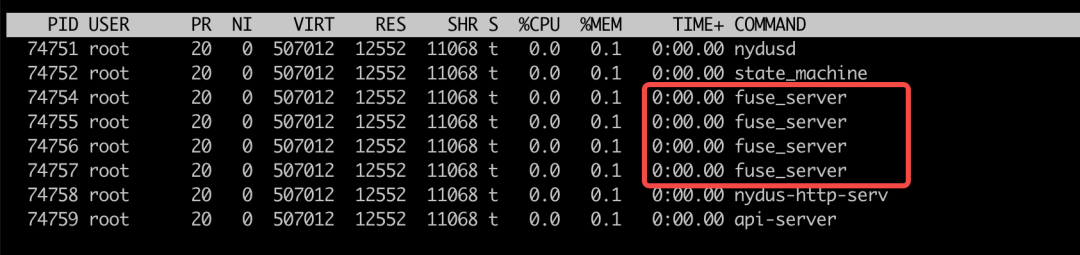
kick_one_server方法启动了名为 fuse_server 的线程,成功启动的线程存储在 FusedevDaemon.fuse_service_threads 中。
2.5.2 FUSE server 线程(处理 FUSE 请求)
在启动线程前,创建了 fuse server 和 inflight operatoins。create_fuse_server() 是 FusedevFsService 结构实现的方法:
fn create_fuse_server(&self) -> Result<FuseServer> {
FuseServer::new(self.server.clone(), self.session.lock().unwrap().deref())
}
create_fuse_server()方法通过 FuseServer::new()方法进行实例化,传入的参数中,self.server.clone() 是对 server 的引用,self.session.lock().unwrap().deref() 是 session 的去引用实例,方法的返回值是 FuseServer 结构的实例。
fn new(server: Arc<Server<Arc<Vfs>>>, se: &FuseSession) -> Result<FuseServer> {
let ch = se.new_channel().map_err(|e| eother!(e))?;
Ok(FuseServer { server, ch })
}
创建 FuseServer 结构的实例之前,首先通过 FuseSession 的 new_channel() 方法创建 fuse channel,并存储在 FuseServer 实例中。
FuseSession 是 fuse-backend-rs 中的结构,new_channel() 方法用于创建新的 channel:
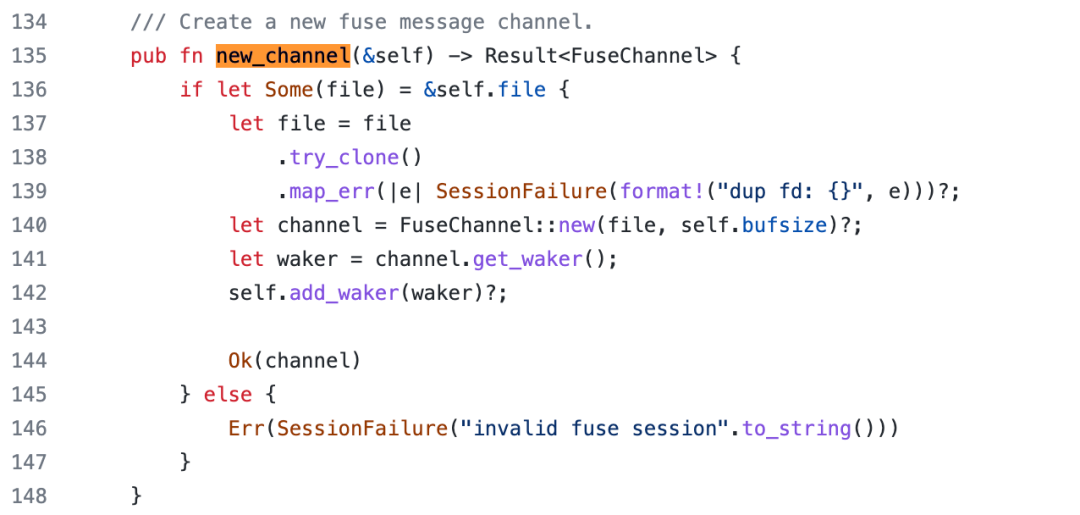
FuseChannel::new()方法如下:
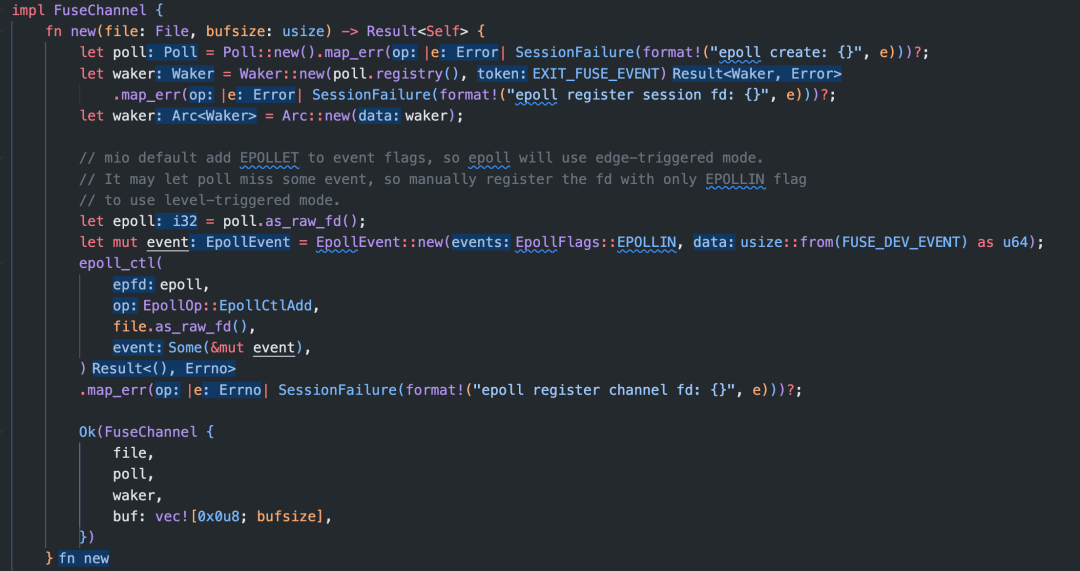
create_inflight_op() 方法也是 FusedevFsService 结构实现的方法,返回的 inflight_op 被添加到 FusedevFsService 结构的 inflight_ops中:
fn create_inflight_op(&self) -> FuseOpWrapper {
let inflight_op = FuseOpWrapper::default();
// "Not expected poisoned lock"
self.inflight_ops.lock().unwrap().push(inflight_op.clone());
inflight_op
}
FuseOpWrapper::default() 方法用于对 FuseOpWrapper 初始化,随后被追加到self.inflight_ops中。
创建好fuse server 和 inflight operatoins之后,启动fuse_server线程。其中,s.svc_loop(&inflight_op) 方法是线程的主要处理逻辑:
fn svc_loop(&mutself, metrics_hook: &dyn MetricsHook) -> Result<()> {
// Given error EBADF, it means kernel has shut down this session.
let _ebadf = Error::from_raw_os_error(libc::EBADF);
loop {
// 通过 channel(epoll)获取 FUSE 请求
ifletSome((reader, writer)) = self.ch.get_request().map_err(|e| {
warn!("get fuse request failed: {:?}", e);
Error::from_raw_os_error(libc::EINVAL)
})? {
ifletErr(e) =
self.server
.handle_message(reader, writer.into(), None, Some(metrics_hook))
{
match e {
fuse_backend_rs::Error::EncodeMessage(_ebadf) => {
returnErr(eio!("fuse session has been shut down"));
}
_ => {
error!("Handling fuse message, {}", DaemonError::ProcessQueue(e));
continue;
}
}
}
} else {
info!("fuse server exits");
break;
}
}
Ok(())
}
这是一个死循环,self.ch.get_request() 也是 fuse-backend-rs 中 FuseChannel 结构的方法,用于通过 channel 从 fuse 内核模块获取(通过 unix socket fd 进行通信) fuse 请求。
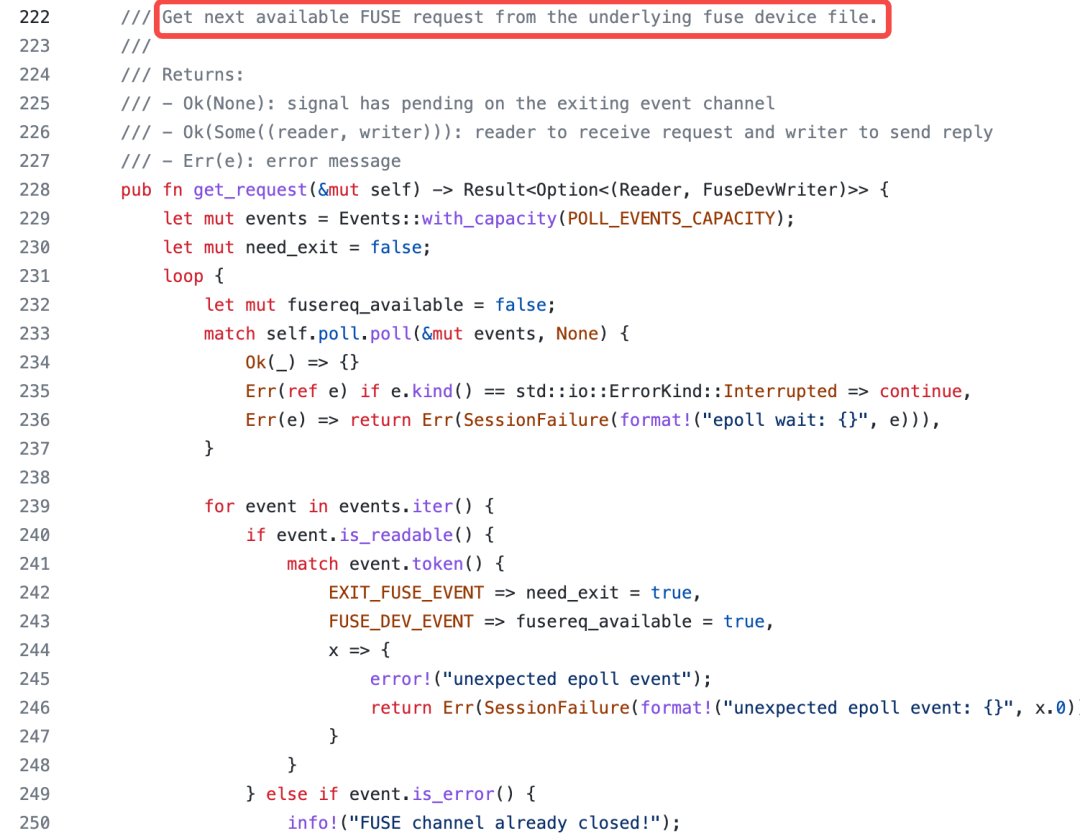
返回的值包括 reader 和 writer,作为方法handle_message() 的参数,同时还会传入metrics_hook用于收集数据。self.server.handle_message() 负责处理每个 fuse 请求,也是 fuse-backend-rs 中 Server 实现的方法:

fuse-backend-rs实现了针对不同Opcode的方法:
let res = match in_header.opcode {
x if x == Opcode::Lookup asu32 => self.lookup(ctx),
x if x == Opcode::Forget asu32 => self.forget(ctx), // No reply.
x if x == Opcode::Getattr asu32 => self.getattr(ctx),
x if x == Opcode::Setattr asu32 => self.setattr(ctx),
x if x == Opcode::Readlink asu32 => self.readlink(ctx),
x if x == Opcode::Symlink asu32 => self.symlink(ctx),
x if x == Opcode::Mknod asu32 => self.mknod(ctx),
x if x == Opcode::Mkdir asu32 => self.mkdir(ctx),
x if x == Opcode::Unlink asu32 => self.unlink(ctx),
x if x == Opcode::Rmdir asu32 => self.rmdir(ctx),
x if x == Opcode::Rename asu32 => self.rename(ctx),
x if x == Opcode::Link asu32 => self.link(ctx),
x if x == Opcode::Open asu32 => self.open(ctx),
x if x == Opcode::Read asu32 => self.read(ctx),
x if x == Opcode::Write asu32 => self.write(ctx),
x if x == Opcode::Statfs asu32 => self.statfs(ctx),
x if x == Opcode::Release asu32 => self.release(ctx),
x if x == Opcode::Fsync asu32 => self.fsync(ctx),
x if x == Opcode::Setxattr asu32 => self.setxattr(ctx),
x if x == Opcode::Getxattr asu32 => self.getxattr(ctx),
x if x == Opcode::Listxattr asu32 => self.listxattr(ctx),
x if x == Opcode::Removexattr asu32 => self.removexattr(ctx),
x if x == Opcode::Flush asu32 => self.flush(ctx),
x if x == Opcode::Init asu32 => self.init(ctx),
x if x == Opcode::Opendir asu32 => self.opendir(ctx),
x if x == Opcode::Readdir asu32 => self.readdir(ctx),
x if x == Opcode::Releasedir asu32 => self.releasedir(ctx),
x if x == Opcode::Fsyncdir asu32 => self.fsyncdir(ctx),
x if x == Opcode::Getlk asu32 => self.getlk(ctx),
x if x == Opcode::Setlk asu32 => self.setlk(ctx),
x if x == Opcode::Setlkw asu32 => self.setlkw(ctx),
x if x == Opcode::Access asu32 => self.access(ctx),
x if x == Opcode::Create asu32 => self.create(ctx),
x if x == Opcode::Bmap asu32 => self.bmap(ctx),
x if x == Opcode::Ioctl asu32 => self.ioctl(ctx),
x if x == Opcode::Poll asu32 => self.poll(ctx),
x if x == Opcode::NotifyReply asu32 => self.notify_reply(ctx),
x if x == Opcode::BatchForget asu32 => self.batch_forget(ctx),
x if x == Opcode::Fallocate asu32 => self.fallocate(ctx),
x if x == Opcode::Readdirplus asu32 => self.readdirplus(ctx),
x if x == Opcode::Rename2 asu32 => self.rename2(ctx),
x if x == Opcode::Lseek asu32 => self.lseek(ctx),
#[cfg(feature = "virtiofs")]
x if x == Opcode::SetupMapping asu32 => self.setupmapping(ctx, vu_req),
#[cfg(feature = "virtiofs")]
x if x == Opcode::RemoveMapping asu32 => self.removemapping(ctx, vu_req),
// Group reqeusts don't need reply together
x => match x {
x if x == Opcode::Interrupt asu32 => {
self.interrupt(ctx);
Ok(0)
}
x if x == Opcode::Destroy asu32 => {
self.destroy(ctx);
Ok(0)
}
_ =>ctx.reply_error(io::Error::from_raw_os_error(libc::ENOSYS)),
},
};
在每个方法中,调用了self.fs.xxx()方法完成操作,以mkdir为例:
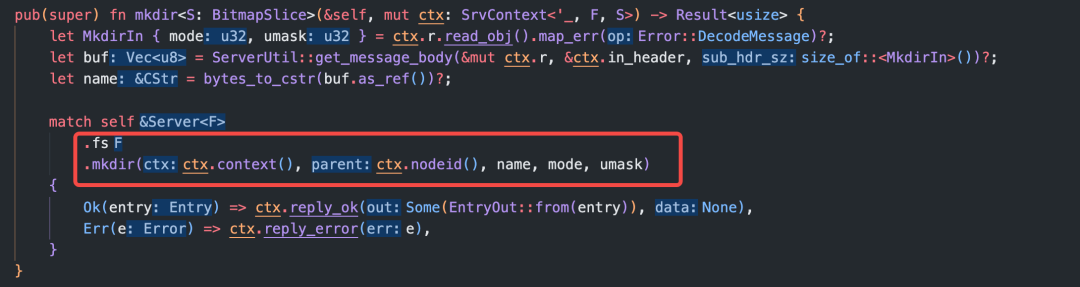
这个fs指的是什么呢?在Server结构体定义中看到,fs是实现了FileSystem + Sync的 trait:
/// Fuse Server to handle requests from the Fuse client and vhost user master.
pubstruct Server<F: FileSystem + Sync> {
fs: F,
vers: ArcSwap<ServerVersion>,
}
还记得创建FuseServer的时候吗?
struct FuseServer {
server: Arc<Server<Arc<Vfs>>>,
ch: FuseChannel,
}
impl FuseServer {
fn new(server: Arc<Server<Arc<Vfs>>>, se: &FuseSession) -> Result<FuseServer> {
let ch = se.new_channel().map_err(|e| eother!(e))?;
Ok(FuseServer { server, ch })
}
...
}
这里FuseServer结构体中server类型Arc<Server<Arc<Vfs>>>中的Server就是Server结构体,因此,fs的类型是Arc<Vfs>。
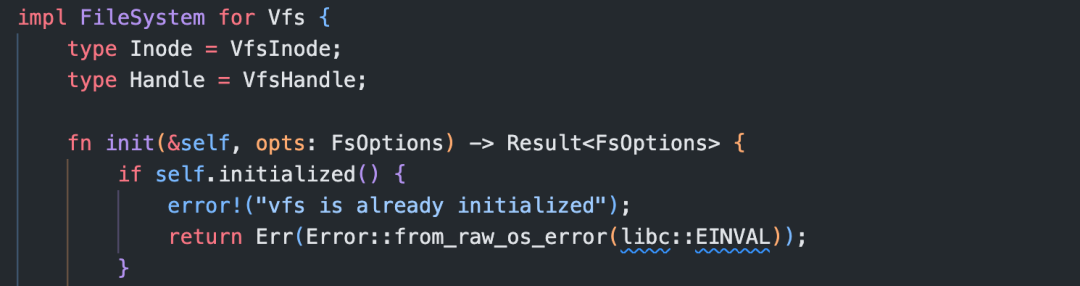
在 fuse-backend-rs中对 Vfs 实现了 FileSystem trait:
fuse_server 线程可以通过top -Hp NYDUSD_PID 看到:
日志信息:

2.5.3 FUSE 终止 service
状态机收到TerminateService事件时,先执行d.interrupt(),然后等待线程结束,最后设置状态。
TerminateService => {
d.interrupt();
let res = d.wait_service();
if res.is_ok() {
d.set_state(DaemonState::READY);
}
res
}
interrupt() 方法:
fn interrupt(&self) {
let session = self
.service
.session
.lock()
.expect("Not expect poisoned lock.");
ifletErr(e) = session.wake().map_err(DaemonError::SessionShutdown) {
error!("stop fuse service thread failed: {:?}", e);
}
}
wait_service() 方法:
fn wait_service(&self) -> DaemonResult<()> {
loop {
let handle = self.fuse_service_threads.lock().unwrap().pop();
ifletSome(handle) = handle {
handle
.join()
.map_err(|e| {
DaemonError::WaitDaemon(
*e.downcast::<Error>()
.unwrap_or_else(|e| Box::new(eother!(e))),
)
})?
.map_err(DaemonError::WaitDaemon)?;
} else {
// No more handles to wait
break;
}
}
Ok(())
}
2.5.4 FUSE Umount 操作
Umount 事件和 TerminateService 事件的操作几乎一样,只是会在执行d.interrupt()之前先断开和 fuse 内核模块的连接:
Umount => d.disconnect().map(|r| {
// Always interrupt fuse service loop after shutdown connection to kernel.
// In case that kernel does not really shutdown the session due to some reasons
// causing service loop keep waiting of `/dev/fuse`.
d.interrupt();
d.wait_service()
.unwrap_or_else(|e| error!("failed to wait service {}", e));
// at least all fuse thread stopped, no matter what error each thread got
d.set_state(DaemonState::STOPPED);
r
}),
断开连接的d.disconnect() 方法:
fn disconnect(&self) -> DaemonResult<()> {
self.service.disconnect()
}
最终调用了session.umount() 方法:
fn disconnect(&self) -> DaemonResult<()> {
let mutsession = self.session.lock().expect("Not expect poisoned lock.");
session.umount().map_err(DaemonError::SessionShutdown)?;
session.wake().map_err(DaemonError::SessionShutdown)?;
Ok(())
}
fuse-backend-rs 中umount方法的实现:
/// Destroy a fuse session.
pub fnumount(&mutself) -> Result<()> {
ifletSome(file) =self.file.take() {
ifletSome(mountpoint) =self.mountpoint.to_str() {
fuse_kern_umount(mountpoint, file)
} else {
Err(SessionFailure("invalid mountpoint".to_string()))
}
} else {
Ok(())
}
}
此外,还有 Restore 和 StopStateMachine 事件:
Restore => {
let res = d.restore();
if res.is_ok() {
d.set_state(DaemonState::READY);
}
res
}
StopStateMachine => {
d.set_state(DaemonState::STOPPED);
Ok(())
}
Daemon 的状态为 STOPPED 时会结束此进程:
if d.get_state() == DaemonState::STOPPED {
break;
}
状态机的功能到此结束。
回到create_fuse_daemon函数,到目前为止,已经创建了daemon对象并启动了状态机线程,状态机线程存储在daemon中:
2.6 Mount FUSE 文件系统
如果不是热升级和 failover 操作,会向 FUSE 内核模块发起 mount 操作请求:
// 1. api_sock 已经存在,但不是热升级操作,也不是 failover
// 2. api_sock 不存在
if (api_sock.as_ref().is_some() && !upgrade && !is_crashed(&mnt, api_sock.as_ref().unwrap())?)
|| api_sock.is_none()
{
ifletSome(cmd) = mount_cmd {
daemon.service.mount(cmd)?;
}
daemon.service.session.lock().unwrap()
.mount()
.map_err(|e| eother!(e))?;
daemon.on_event(DaemonStateMachineInput::Mount)
.map_err(|e| eother!(e))?;
daemon.on_event(DaemonStateMachineInput::Start)
.map_err(|e| eother!(e))?;
daemon.service.conn
.store(calc_fuse_conn(mnt)?, Ordering::Relaxed);
}
如果mount_cmd不为 None,则通过daemon.service.mount(cmd)挂载后端文件系统:
// NOTE: This method is not thread-safe, however, it is acceptable as
// mount/umount/remount/restore_mount is invoked from single thread in FSM
fn mount(&self, cmd: FsBackendMountCmd) -> DaemonResult<()> {
ifself.backend_from_mountpoint(&cmd.mountpoint)?.is_some() {
returnErr(DaemonError::AlreadyExists);
}
let backend = fs_backend_factory(&cmd)?;
let index = self.get_vfs().mount(backend, &cmd.mountpoint)?;
info!("{} filesystem mounted at {}", &cmd.fs_type, &cmd.mountpoint);
self.backend_collection().add(&cmd.mountpoint, &cmd)?;
// Add mounts opaque to UpgradeManager
ifletSome(mutmgr_guard) = self.upgrade_mgr() {
upgrade::add_mounts_state(&mutmgr_guard, cmd, index)?;
}
Ok(())
}
首先通过self.backend_from_mountpoint(&cmd.mountpoint)方法检查传入的路径是否已经被挂载。如果已经存在,则返回错误。
backend_from_mountpoint方法调用了Vfs的get_rootfs方法,首先得到传入path的inode,然后查看对应inode是否存在mountpoints Hashmap 中:
/// Get the mounted backend file system alongside the path if there's one.
pubfn get_rootfs(&self, path: &str) -> VfsResult<Option<Arc<BackFileSystem>>> {
// Serialize mount operations. Do not expect poisoned lock here.
let _guard = self.lock.lock().unwrap();
let inode = matchself.root.path_walk(path).map_err(VfsError::PathWalk)? {
Some(i) => i,
None => returnOk(None),
};
ifletSome(mnt) = self.mountpoints.load().get(&inode) {
Ok(Some(self.get_fs_by_idx(mnt.fs_idx).map_err(|e| {
VfsError::NotFound(format!("fs index {}, {:?}", mnt.fs_idx, e))
})?))
} else {
// Pseudo fs dir inode exists, but that no backend is ever mounted
// is a normal case.
Ok(None)
}
}
然后,通过fs_backend_factory(&cmd)方法获取文件系统后端,该方法的返回值是实现了BackendFileSystem+Sync+Sendtrait 的结构体。
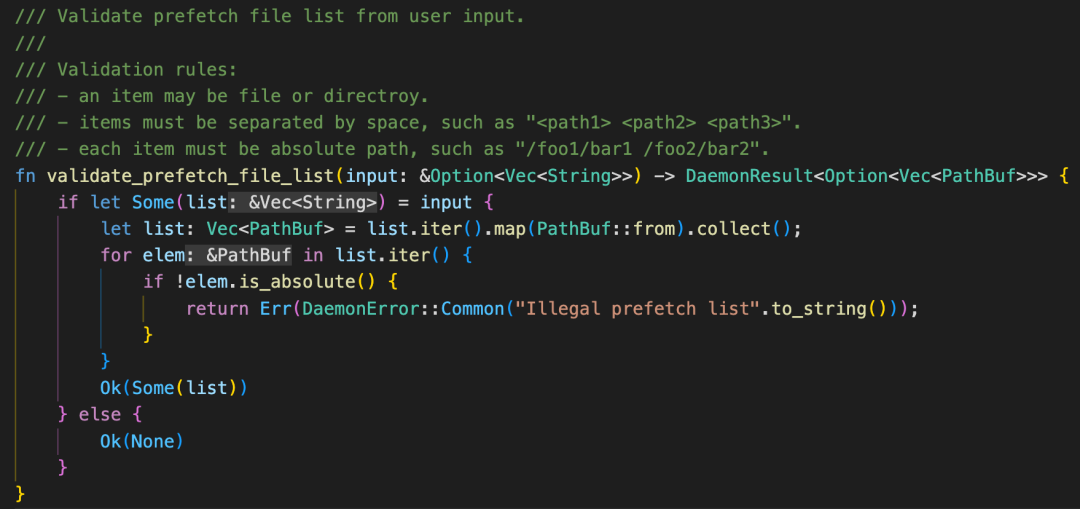
在fs_backend_factory方法中,首先验证预取文件列表:
然后根据传入的fs_type分别进行实例化,目前支持两种类型:
pubenum FsBackendType {
Rafs,
PassthroughFs,
}
2.6.1 初始化 RAFS backend
首先,解析从cmd传入的config内容,并根据传入的bootstrap文件路径,打开用于(从 bootstrap 中)读取文件系统的元数据信息的reader,绑定到bootstrap变量。接下来创建 rafs 实例,传入参数包括配置信息、挂载路径、bootstrap文件对应的reader:
FsBackendType::Rafs => {
let rafs_config = RafsConfig::from_str(cmd.config.as_str())?;
let mutbootstrap = <dyn RafsIoRead>::from_file(&cmd.source)?;
let mutrafs = Rafs::new(rafs_config, &cmd.mountpoint, &mutbootstrap)?;
rafs.import(bootstrap, prefetch_files)?;
info!("RAFS filesystem imported");
Ok(Box::new(rafs))
}
通过Rafs::new(rafs_config, &cmd.mountpoint, &mut bootstrap)方法创建 rafs 实例。
首先,准备配置信息storage_conf,并通过传入的conf参数创建RafsSuper实例。创建RafsSuper只是初始化配置信息,包括 RafsMode(有 Direct 和 Cached 两种可选)。接下来,通过sb.load(r)方法从bootstarp加载 RAFS 超级块的信息。RAFS V5 和 V6 两个版本的加载方式不同,try_load_v6方法:
pub(crate) fntry_load_v6(&mutself,r: &mut RafsIoReader) -> Result<bool> {
let end =r.seek_to_end(0)?;
r.seek_to_offset(0)?;
// 创建 RAFSV6SuperBlock 实例
let mutsb = RafsV6SuperBlock::new();
// 读取 RAFS V6 的超级块信息
// offset 1024,length 128
ifsb.load(r).is_err() {
returnOk(false);
}
if !sb.is_rafs_v6() {
returnOk(false);
}
sb.validate(end)?;
// 设置 RAFS 超级块的 meta 信息
self.meta.version = RAFS_SUPER_VERSION_V6;
self.meta.magic =sb.magic();
self.meta.meta_blkaddr =sb.s_meta_blkaddr;
self.meta.root_nid =sb.s_root_nid;
// 创建 RafsV6SuperBlockExt 实例
let mutext_sb = RafsV6SuperBlockExt::new();
// 读取 RAFS V6 的扩展超级块信息
// offset 1024 + 128,length 256
ext_sb.load(r)?;
ext_sb.validate(end)?;
// 设置 RAFS 超级块的 meta 信息
self.meta.chunk_size =ext_sb.chunk_size();
self.meta.blob_table_offset =ext_sb.blob_table_offset();
self.meta.blob_table_size =ext_sb.blob_table_size();
self.meta.chunk_table_offset =ext_sb.chunk_table_offset();
self.meta.chunk_table_size =ext_sb.chunk_table_size();
self.meta.inodes_count =sb.inodes_count();
self.meta.flags = RafsSuperFlags::from_bits(ext_sb.flags())
.ok_or_else(|| einval!(format!("invalid super flags {:x}",ext_sb.flags())))?;
info!("rafs superblock features: {}",self.meta.flags);
// 设置 RAFS 超级块 meta 中的预取列表信息
self.meta.prefetch_table_entries =ext_sb.prefetch_table_size() / size_of::<u32>() asu32;
self.meta.prefetch_table_offset =ext_sb.prefetch_table_offset();
trace!(
"prefetch table offset {} entries {} ",
self.meta.prefetch_table_offset,
self.meta.prefetch_table_entries
);
matchself.mode {
// 如果 RAFS 模式是 Direct,还需要创建
// DirectSuperBlockV6 实例并读取相关信息
RafsMode::Direct => {
let mutsb_v6 = DirectSuperBlockV6::new(&self.meta);
sb_v6.load(r)?;
self.superblock = Arc::new(sb_v6);
Ok(true)
}
RafsMode::Cached => Err(enosys!("Rafs v6 does not support cached mode")),
}
}
RAFS 超级块信息加载后,获取blob信息,然后创建rafs实例:
pubfn new(conf: RafsConfig, id: &str,r: &mut RafsIoReader) -> RafsResult<Self> {
let storage_conf = Self::prepare_storage_conf(&conf)?;
let mutsb = RafsSuper::new(&conf).map_err(RafsError::FillSuperblock)?;
sb.load(r).map_err(RafsError::FillSuperblock)?;
// 获取 super block 之后,从中获取 blob 信息(BlobInfo)
let blob_infos =sb.superblock.get_blob_infos();
// 根据配置信息和 blobs 信息,遍历每条 blob_info,
// 创建 BlobDevice 的实例
let device =
BlobDevice::new(&storage_conf, &blob_infos).map_err(RafsError::CreateDevice)?;
// 创建 rafs 实例
let rafs = Rafs {
id: id.to_string(),
device, // BlobDevice
ios: metrics::FsIoStats::new(id),
sb: Arc::new(sb),
initialized: false, // 还未初始化
digest_validate: conf.digest_validate,
fs_prefetch: conf.fs_prefetch.enable, // 支持预取
amplify_io: conf.amplify_io,
prefetch_all: conf.fs_prefetch.prefetch_all,
xattr_enabled: conf.enable_xattr, // 开启 xattr
i_uid: geteuid().into(), // uid
i_gid: getegid().into(), // gid
i_time: SystemTime::now()
.duration_since(SystemTime::UNIX_EPOCH)
.unwrap()
.as_secs(),
};
// Rafs v6 does must store chunk info into local file cache. So blob cache is required
if rafs.metadata().is_v6() {
if conf.device.cache.cache_type != "blobcache" {
returnErr(RafsError::Configure(
"Rafs v6 must have local blobcache configured".to_string(),
));
}
if conf.digest_validate {
returnErr(RafsError::Configure(
"Rafs v6 doesn't support integrity validation yet".to_string(),
));
}
}
rafs.ios.toggle_files_recording(conf.iostats_files);
rafs.ios.toggle_access_pattern(conf.access_pattern);
rafs.ios
.toggle_latest_read_files_recording(conf.latest_read_files);
Ok(rafs)
}
关于 rafs 文件系统(以 v6 为例)元数据在 bootstrap 文件中的分布,在 rafs/src/metadata/layout/v6.rs 中有详细定义:
/// EROFS metadata slot size.
pubconst EROFS_INODE_SLOT_SIZE: usize = 1 << EROFS_INODE_SLOT_BITS;
/// EROFS logical block size.
pubconst EROFS_BLOCK_SIZE: u64 = 1u64 << EROFS_BLOCK_BITS;
/// EROFS plain inode.
pubconst EROFS_INODE_FLAT_PLAIN: u16 = 0;
/// EROFS inline inode.
pubconst EROFS_INODE_FLAT_INLINE: u16 = 2;
/// EROFS chunked inode.
pubconst EROFS_INODE_CHUNK_BASED: u16 = 4;
/// EROFS device table offset.
pub constEROFS_DEVTABLE_OFFSET: u16 =
EROFS_SUPER_OFFSET + EROFS_SUPER_BLOCK_SIZE + EROFS_EXT_SUPER_BLOCK_SIZE;
pubconst EROFS_I_VERSION_BIT: u16 = 0;
pubconst EROFS_I_VERSION_BITS: u16 = 1;
pubconst EROFS_I_DATALAYOUT_BITS: u16 = 3;
// Offset of EROFS super block.
pub constEROFS_SUPER_OFFSET: u16 = 1024;
// Size of EROFS super block.
pubconst EROFS_SUPER_BLOCK_SIZE: u16 = 128;
// Size of extended super block, used for rafs v6 specific fields
const EROFS_EXT_SUPER_BLOCK_SIZE: u16 = 256;
// Magic number for EROFS super block.
const EROFS_SUPER_MAGIC_V1: u32 = 0xE0F5_E1E2;
// Bits of EROFS logical block size.
const EROFS_BLOCK_BITS: u8 = 12;
// Bits of EROFS metadata slot size.
const EROFS_INODE_SLOT_BITS: u8 = 5;
创建rafs实例后,通过rafs.import(bootstrap, prefetch_files)方法初始化(导入bootstrap和prefetch信息):
/// Import an rafs bootstrap to initialize the filesystem instance.
pub fnimport(
&mutself,
r: RafsIoReader,
prefetch_files: Option<Vec<PathBuf>>,
) -> RafsResult<()> {
ifself.initialized {
returnErr(RafsError::AlreadyMounted);
}
ifself.fs_prefetch {
// Device should be ready before any prefetch.
self.device.start_prefetch();
self.prefetch(r, prefetch_files);
}
self.initialized = true;
Ok(())
}
主要是开启prefetch线程,self.prefetch(r, prefetch_files)方法传入两个参数,r是 bootstrap 文件的 reader,prefetch_files是已经从 bootstrap 读取的预取文件列表:
fn prefetch(&self, reader: RafsIoReader, prefetch_files: Option<Vec<PathBuf>>) {
let sb = self.sb.clone();
let device = self.device.clone();
let prefetch_all = self.prefetch_all;
let root_ino = self.root_ino();
let _ = std::thread::spawn(move || {
Self::do_prefetch(root_ino, reader, prefetch_files, prefetch_all, sb, device);
});
}
在do_prefetch方法中,首先设置每个blob对应device的状态为允许prefetch,然后,根据prefetch_files进行预取:
pub fnimport(
&mutself,
r: RafsIoReader,
prefetch_files: Option<Vec<PathBuf>>,
) -> RafsResult<()> {
ifself.initialized {
returnErr(RafsError::AlreadyMounted);
}
ifself.fs_prefetch {
// Device should be ready before any prefetch.
self.device.start_prefetch();
self.prefetch(r, prefetch_files);
}
self.initialized = true;
Ok(())
}
在self.prefetch(r, prefetch_files)方法中,开启了预取线程:
fn prefetch(&self, reader: RafsIoReader, prefetch_files: Option<Vec<PathBuf>>) {
let sb = self.sb.clone();
let device = self.device.clone();
let prefetch_all = self.prefetch_all;
let root_ino = self.root_ino();
let _ = std::thread::spawn(move || {
Self::do_prefetch(root_ino, reader, prefetch_files, prefetch_all, sb, device);
});
}
线程中运行do_prefetch方法,按 chunk 粒度进行预取:
fn do_prefetch(
root_ino: u64,
mutreader: RafsIoReader, // bootstrap 对应的 reader
prefetch_files: Option<Vec<PathBuf>>,
prefetch_all: bool,
sb: Arc<RafsSuper>,
device: BlobDevice,
) {
// First do range based prefetch for rafs v6.
if sb.meta.is_v6() {
// 生成 BlobPrefetchRequest,按 chunk 为粒度的请求
let mutprefetches = Vec::new();
for blob in sb.superblock.get_blob_infos() {
let sz = blob.prefetch_size();
if sz > 0 {
let mutoffset = 0;
whileoffset < sz {
// 按 chunk 为粒度生成请求
let len = cmp::min(sz -offset, RAFS_DEFAULT_CHUNK_SIZE);
prefetches.push(BlobPrefetchRequest {
blob_id: blob.blob_id().to_owned(),
offset,
len,
});
offset+= len;
}
}
}
if !prefetches.is_empty() {
// 通过 device 的 prefetch 进行预取
device.prefetch(&[], &prefetches).unwrap_or_else(|e| {
warn!("Prefetch error, {:?}", e);
});
}
}
let fetcher = |desc: &mut BlobIoVec, last: bool| {
ifdesc.size() asu64 > RAFS_MAX_CHUNK_SIZE
||desc.len() > 1024
|| (last &&desc.size() > 0)
{
trace!(
"fs prefetch: 0x{:x} bytes for {} descriptors",
desc.size(),
desc.len()
);
device.prefetch(&[desc], &[]).unwrap_or_else(|e| {
warn!("Prefetch error, {:?}", e);
});
desc.reset();
}
};
let mutignore_prefetch_all = prefetch_files
.as_ref()
.map(|f| f.len() == 1 && f[0].as_os_str() == "/")
.unwrap_or(false);
// Then do file based prefetch based on:
// - prefetch listed passed in by user
// - or file prefetch list in metadata
let inodes = prefetch_files.map(|files| Self::convert_file_list(&files, &sb));
let res = sb.prefetch_files(&device, &mutreader, root_ino, inodes, &fetcher);
match res {
Ok(true) =>ignore_prefetch_all = true,
Ok(false) => {}
Err(e) => info!("No file to be prefetched {:?}", e),
}
// Last optionally prefetch all data
if prefetch_all && !ignore_prefetch_all {
let root = vec![root_ino];
let res = sb.prefetch_files(&device, &mutreader, root_ino, Some(root), &fetcher);
ifletErr(e) = res {
info!("No file to be prefetched {:?}", e);
}
}
}
生成预取请求列表后,通过device的prefetch方法进行预取:
/// Try to prefetch specified blob data.
pubfn prefetch(
&self,
io_vecs: &[&BlobIoVec],
prefetches: &[BlobPrefetchRequest],
) -> io::Result<()> {
for idx in0..prefetches.len() {
// 根据 blob_id 获取 blob 信息
ifletSome(blob) = self.get_blob_by_id(&prefetches[idx].blob_id) {
// 通过 blob 的 prefetch 方法进行预取
let _ = blob.prefetch(blob.clone(), &prefetches[idx..idx + 1], &[]);
}
}
for io_vec in io_vecs.iter() {
ifletSome(blob) = self.get_blob_by_iovec(io_vec) {
// Prefetch errors are ignored.
let _ = blob
.prefetch(blob.clone(), &[], &io_vec.bi_vec)
.map_err(|e| {
error!("failed to prefetch blob data, {}", e);
});
}
}
Ok(())
}
根据 blob_id获取 blob 后,调用prefetch方法:
fn prefetch(
&self,
blob_cache: Arc<dyn BlobCache>,
prefetches: &[BlobPrefetchRequest],
bios: &[BlobIoDesc],
) -> StorageResult<usize> {
// Handle blob prefetch request first, it may help performance.
for req in prefetches {
// 生成异步预取请求消息
let msg = AsyncPrefetchMessage::new_blob_prefetch(
blob_cache.clone(),
req.offset asu64,
req.len asu64,
);
// 将请求消息通过 channel 传递给 worker
let _ = self.workers.send_prefetch_message(msg);
}
// Then handle fs prefetch
let max_comp_size = self.prefetch_batch_size();
let mutbios = bios.to_vec();
bios.sort_by_key(|entry| entry.chunkinfo.compressed_offset());
self.metrics.prefetch_unmerged_chunks.add(bios.len() asu64);
BlobIoMergeState::merge_and_issue(
&bios,
max_comp_size,
max_comp_size asu64 >> RAFS_MERGING_SIZE_TO_GAP_SHIFT,
|req: BlobIoRange| {
// 生成异步预取请求消息
let msg = AsyncPrefetchMessage::new_fs_prefetch(blob_cache.clone(), req);
let _ = self.workers.send_prefetch_message(msg);
},
);
Ok(0)
}
接收预取消息并进行处理的函数:
asyncfn handle_prefetch_requests(mgr: Arc<AsyncWorkerMgr>, rt: &Runtime) {
// Max 1 active requests per thread.
mgr.prefetch_sema.add_permits(1);
whileletOk(msg) = mgr.prefetch_channel.recv().await {
mgr.handle_prefetch_rate_limit(&msg).await;
let mgr2 = mgr.clone();
match msg {
AsyncPrefetchMessage::BlobPrefetch(blob_cache, offset, size) => {
let token = Semaphore::acquire_owned(mgr2.prefetch_sema.clone())
.await
.unwrap();
if blob_cache.is_prefetch_active() {
rt.spawn_blocking(move || {
let _ = Self::handle_blob_prefetch_request(
mgr2.clone(),
blob_cache,
offset,
size,
);
drop(token);
});
}
}
AsyncPrefetchMessage::FsPrefetch(blob_cache, req) => {
let token = Semaphore::acquire_owned(mgr2.prefetch_sema.clone())
.await
.unwrap();
if blob_cache.is_prefetch_active() {
rt.spawn_blocking(move || {
let _ = Self::handle_fs_prefetch_request(mgr2.clone(), blob_cache, req);
drop(token)
});
}
}
AsyncPrefetchMessage::Ping => {
let _ = mgr.ping_requests.fetch_add(1, Ordering::Relaxed);
}
AsyncPrefetchMessage::RateLimiter(_size) => {}
}
mgr.prefetch_inflight.fetch_sub(1, Ordering::Relaxed);
}
}
目前,有两种预取的方法:Blob 模式和 Fs 模式。
(1) Blob 模式预取
对应的处理函数为handle_blob_prefetch_request:
fn handle_blob_prefetch_request(
mgr: Arc<AsyncWorkerMgr>,
cache: Arc<dyn BlobCache>,
offset: u64,
size: u64,
) -> Result<()> {
trace!(
"storage: prefetch blob {} offset {} size {}",
cache.blob_id(),
offset,
size
);
if size == 0 {
returnOk(());
}
// 获取 blob object
ifletSome(obj) = cache.get_blob_object() {
// 获取 (offset, offset + size) 范围内的内容
ifletErr(e) = obj.fetch_range_compressed(offset, size) {
warn!(
"storage: failed to prefetch data from blob {}, offset {}, size {}, {}, will try resend",
cache.blob_id(),
offset,
size,
e
);
ASYNC_RUNTIME.spawn(asyncmove {
let mutinterval = interval(Duration::from_secs(1));
interval.tick().await;
// 如果失败,重新发起预取消息
let msg = AsyncPrefetchMessage::new_blob_prefetch(cache.clone(), offset, size);
let _ = mgr.send_prefetch_message(msg);
});
}
} else {
warn!("prefetch blob range is not supported");
}
Ok(())
}
其中,主要的处理函数为obj.fetch_range_compressed(offset, size):
fn fetch_range_compressed(&self, offset: u64, size: u64) -> Result<()> {
let meta = self.meta.as_ref().ok_or_else(|| einval!())?;
let meta = meta.get_blob_meta().ok_or_else(|| einval!())?;
let mutchunks = meta.get_chunks_compressed(offset, size, self.prefetch_batch_size())?;
ifletSome(meta) = self.get_blob_meta_info()? {
chunks = self.strip_ready_chunks(meta, None,chunks);
}
ifchunks.is_empty() {
Ok(())
} else {
self.do_fetch_chunks(&chunks, true)
}
}
meta.get_chunks_compressed方法用于获取包含(offset, offset + size)范围的chunk列表:
pubfn get_chunks_compressed(
&self,
start: u64,
size: u64,
batch_size: u64,
) -> Result<Vec<Arc<dyn BlobChunkInfo>>> {
let end = start.checked_add(size).ok_or_else(|| {
einval!(einval!(format!(
"get_chunks_compressed: invalid start {}/size {}",
start, size
)))
})?;
if end > self.state.compressed_size {
returnErr(einval!(format!(
"get_chunks_compressed: invalid end {}/compressed_size {}",
end, self.state.compressed_size
)));
}
let batch_end = if batch_size <= size {
end
} else {
std::cmp::min(
start.checked_add(batch_size).unwrap_or(end),
self.state.compressed_size,
)
};
self.state
.get_chunks_compressed(start, end, batch_end, batch_size)
}
BlobMetaChunkArray::V2版本的self.state.get_chunks_compressed方法实际的处理函数内容如下:
fn _get_chunks_compressed<T: BlobMetaChunkInfo>(
state: &Arc<BlobMetaState>,
chunk_info_array: &[T],
start: u64,
end: u64,
batch_end: u64,
batch_size: u64,
) -> Result<Vec<Arc<dyn BlobChunkInfo>>> {
let mutvec = Vec::with_capacity(512);
let mutindex = Self::_get_chunk_index_nocheck(chunk_info_array, start, true)?;
let entry = Self::get_chunk_entry(state, chunk_info_array,index)?;
// Special handling of ZRan chunks
if entry.is_zran() {
let zran_index = entry.get_zran_index();
let pos = state.zran_info_array[zran_index asusize].in_offset();
let mutzran_last = zran_index;
whileindex > 0 {
let entry = Self::get_chunk_entry(state, chunk_info_array,index - 1)?;
if !entry.is_zran() {
returnErr(einval!(
"inconsistent ZRan and non-ZRan chunk information entries"
));
} elseif entry.get_zran_index() != zran_index {
// reach the header chunk associated with the same ZRan context.
break;
} else {
index-= 1;
}
}
let mutvec = Vec::with_capacity(128);
for entry in &chunk_info_array[index..] {
entry.validate(state)?;
if !entry.is_zran() {
returnErr(einval!(
"inconsistent ZRan and non-ZRan chunk information entries"
));
}
if entry.get_zran_index() !=zran_last {
let ctx = &state.zran_info_array[entry.get_zran_index() asusize];
if ctx.in_offset() + ctx.in_size() asu64 - pos > batch_size
&& entry.compressed_offset() > end
{
returnOk(vec);
}
zran_last = entry.get_zran_index();
}
vec.push(BlobMetaChunk::new(index, state));
}
returnOk(vec);
}
vec.push(BlobMetaChunk::new(index, state));
let mutlast_end = entry.compressed_end();
iflast_end >= batch_end {
Ok(vec)
} else {
whileindex + 1 < chunk_info_array.len() {
index+= 1;
let entry = Self::get_chunk_entry(state, chunk_info_array,index)?;
// Avoid read amplify if next chunk is too big.
iflast_end >= end && entry.compressed_end() > batch_end {
returnOk(vec);
}
vec.push(BlobMetaChunk::new(index, state));
last_end = entry.compressed_end();
iflast_end >= batch_end {
returnOk(vec);
}
}
Err(einval!(format!(
"entry not found index {} chunk_info_array.len {}",
index,
chunk_info_array.len(),
)))
}
}
获取包含的chunks之后,通过self.strip_ready_chunks方法分离这些chunks(具体含义未深究):
fn strip_ready_chunks(
&self,
meta: Arc<BlobMetaInfo>,
old_chunks: Option<&[Arc<dyn BlobChunkInfo>]>,
mutextended_chunks: Vec<Arc<dyn BlobChunkInfo>>,
) -> Vec<Arc<dyn BlobChunkInfo>> {
ifself.is_zran {
let mutset = HashSet::new();
for c inextended_chunks.iter() {
if !matches!(self.chunk_map.is_ready(c.as_ref()), Ok(true)) {
set.insert(meta.get_zran_index(c.id()));
}
}
let first = old_chunks.as_ref().map(|v| v[0].id()).unwrap_or(u32::MAX);
let mutstart = 0;
whilestart <extended_chunks.len() {
let id =extended_chunks[start].id();
if id == first ||set.contains(&meta.get_zran_index(id)) {
break;
}
start+= 1;
}
let last = old_chunks
.as_ref()
.map(|v| v[v.len() - 1].id())
.unwrap_or(u32::MAX);
let mutend =extended_chunks.len() - 1;
whileend >start {
let id =extended_chunks[end].id();
if id == last ||set.contains(&meta.get_zran_index(id)) {
break;
}
end-= 1;
}
assert!(end >=start);
ifstart == 0 &&end ==extended_chunks.len() - 1 {
extended_chunks
} else {
extended_chunks[start..=end].to_vec()
}
} else {
while !extended_chunks.is_empty() {
let chunk = &extended_chunks[extended_chunks.len() - 1];
if matches!(self.chunk_map.is_ready(chunk.as_ref()), Ok(true)) {
extended_chunks.pop();
} else {
break;
}
}
extended_chunks
}
}
然后,通过self.do_fetch_chunks(&chunks, true)方法获取chunks的数据:
fn do_fetch_chunks(&self, chunks: &[Arc<dyn BlobChunkInfo>], prefetch: bool) -> Result<()> {
// Validate input parameters.
assert!(!chunks.is_empty());
if chunks.len() > 1 {
for idx in0..chunks.len() - 1 {
assert_eq!(chunks[idx].id() + 1, chunks[idx + 1].id());
}
}
// Get chunks not ready yet, also marking them as in-flight.
let bitmap = self
.chunk_map
.as_range_map()
.ok_or_else(|| einval!("invalid chunk_map for do_fetch_chunks()"))?;
let chunk_index = chunks[0].id();
let count = chunks.len() asu32;
let pending = match bitmap.check_range_ready_and_mark_pending(chunk_index, count)? {
None => returnOk(()),
Some(v) => v,
};
let mutstatus = vec![false; count asusize];
let (start_idx, end_idx) = ifself.is_zran {
for chunk_id in pending.iter() {
status[(*chunk_id - chunk_index) asusize] = true;
}
(0, pending.len())
} else {
let mutstart = u32::MAX;
let mutend = 0;
for chunk_id in pending.iter() {
status[(*chunk_id - chunk_index) asusize] = true;
start = std::cmp::min(*chunk_id - chunk_index,start);
end = std::cmp::max(*chunk_id - chunk_index,end);
}
ifend <start {
returnOk(());
}
(start asusize,end asusize)
};
let start_chunk = &chunks[start_idx];
let end_chunk = &chunks[end_idx];
let (blob_offset, blob_end, blob_size) =
self.get_blob_range(&chunks[start_idx..=end_idx])?;
trace!(
"fetch data range {:x}-{:x} for chunk {}-{} from blob {:x}",
blob_offset,
blob_end,
start_chunk.id(),
end_chunk.id(),
chunks[0].blob_index()
);
// 从 backend 读取数据
matchself.read_chunks_from_backend(
blob_offset,
blob_size,
&chunks[start_idx..=end_idx],
prefetch,
) {
Ok(mutbufs) => {
ifself.is_compressed {
let res =
Self::persist_cached_data(&self.file, blob_offset,bufs.compressed_buf());
for idx in start_idx..=end_idx {
ifstatus[idx] {
self.update_chunk_pending_status(chunks[idx].as_ref(), res.is_ok());
}
}
} else {
for idx in start_idx..=end_idx {
let mutbuf = matchbufs.next() {
None => returnErr(einval!("invalid chunk decompressed status")),
Some(Err(e)) => {
for idx in idx..=end_idx {
ifstatus[idx] {
bitmap.clear_range_pending(chunks[idx].id(), 1)
}
}
returnErr(e);
}
Some(Ok(v)) => v,
};
ifstatus[idx] {
ifself.dio_enabled {
self.adjust_buffer_for_dio(&mutbuf)
}
self.persist_chunk_data(chunks[idx].as_ref(),buf.as_ref());
}
}
}
}
Err(e) => {
for idx in0..chunks.len() {
ifstatus[idx] {
bitmap.clear_range_pending(chunks[idx].id(), 1)
}
}
returnErr(e);
}
}
if !bitmap.wait_for_range_ready(chunk_index, count)? {
if prefetch {
returnErr(eio!("failed to read data from storage backend"));
}
// if we are in on-demand path, retry for the timeout chunks
for chunk in chunks {
matchself.chunk_map.check_ready_and_mark_pending(chunk.as_ref()) {
Err(e) => returnErr(eio!(format!("do_fetch_chunks failed, {:?}", e))),
Ok(true) => {}
Ok(false) => {
info!("retry for timeout chunk, {}", chunk.id());
let mutbuf = alloc_buf(chunk.uncompressed_size() asusize);
self.read_chunk_from_backend(chunk.as_ref(), &mutbuf)
.map_err(|e| {
self.update_chunk_pending_status(chunk.as_ref(), false);
eio!(format!("read_raw_chunk failed, {:?}", e))
})?;
ifself.dio_enabled {
self.adjust_buffer_for_dio(&mutbuf)
}
self.persist_chunk_data(chunk.as_ref(), &buf);
}
}
}
}
Ok(())
}
其中self.read_chunks_from_backend方法实现从 backend 读取数据:
fn read_chunks_from_backend<'a, 'b>(
&'aself,
blob_offset: u64,
blob_size: usize,
chunks: &'b [Arc<dyn BlobChunkInfo>],
prefetch: bool,
) -> Result<ChunkDecompressState<'a, 'b>>
where
Self: Sized,
{
// Read requested data from the backend by altogether.
let mutc_buf = alloc_buf(blob_size);
let start = Instant::now();
let nr_read = self
.reader()
.read(c_buf.as_mut_slice(), blob_offset)
.map_err(|e| eio!(e))?;
if nr_read != blob_size {
returnErr(eio!(format!(
"request for {} bytes but got {} bytes",
blob_size, nr_read
)));
}
let duration = Instant::now().duration_since(start).as_millis();
debug!(
"read_chunks_from_backend: {} {} {} bytes at {}, duration {}ms",
std::thread::current().name().unwrap_or_default(),
if prefetch { "prefetch" } else { "fetch" },
blob_size,
blob_offset,
duration
);
let chunks = chunks.iter().map(|v| v.as_ref()).collect();
Ok(ChunkDecompressState::new(blob_offset, self, chunks,c_buf))
}
self.reader().read方法是对 backend 的抽象,每个请求失败后会重试retry_count次:
fn read(&self,buf: &mut [u8], offset: u64) -> BackendResult<usize> {
let mutretry_count = self.retry_limit();
let begin_time = self.metrics().begin();
loop {
matchself.try_read(buf, offset) {
Ok(size) => {
self.metrics().end(&begin_time,buf.len(), false);
returnOk(size);
}
Err(err) => {
ifretry_count > 0 {
warn!(
"Read from backend failed: {:?}, retry count {}",
err,retry_count
);
retry_count-= 1;
} else {
self.metrics().end(&begin_time,buf.len(), true);
ERROR_HOLDER
.lock()
.unwrap()
.push(&format!("{:?}", err))
.unwrap_or_else(|_| error!("Failed when try to hold error"));
returnErr(err);
}
}
}
}
}
不同 backend 的try_read方法实现不同,目前,nydus分别实现了localfs、registry、OSS三种 backend。
(2) Fs 模式预取
对应的处理函数为handle_fs_prefetch_request:
fn handle_fs_prefetch_request(
mgr: Arc<AsyncWorkerMgr>,
cache: Arc<dyn BlobCache>,
req: BlobIoRange,
) -> Result<()> {
let blob_offset = req.blob_offset;
let blob_size = req.blob_size;
trace!(
"storage: prefetch fs data from blob {} offset {} size {}",
cache.blob_id(),
blob_offset,
blob_size
);
if blob_size == 0 {
returnOk(());
}
// Record how much prefetch data is requested from storage backend.
// So the average backend merged request size will be prefetch_data_amount/prefetch_mr_count.
// We can measure merging possibility by this.
mgr.metrics.prefetch_mr_count.inc();
mgr.metrics.prefetch_data_amount.add(blob_size);
ifletSome(obj) = cache.get_blob_object() {
obj.prefetch_chunks(&req)?;
} else {
cache.prefetch_range(&req)?;
}
Ok(())
}
Fs 模式的预取有两种情况,(1)如果有缓存的blob时:
fn prefetch_chunks(&self, range: &BlobIoRange) -> Result<()> {
let chunks_extended;
let mutchunks = &range.chunks;
ifletSome(v) = self.extend_pending_chunks(chunks, self.prefetch_batch_size())? {
chunks_extended = v;
chunks = &chunks_extended;
}
let mutstart = 0;
whilestart <chunks.len() {
// Figure out the range with continuous chunk ids, be careful that `end` is inclusive.
let mutend =start;
whileend <chunks.len() - 1 &&chunks[end + 1].id() ==chunks[end].id() + 1 {
end+= 1;
}
self.do_fetch_chunks(&chunks[start..=end], true)?;
start =end + 1;
}
Ok(())
}
准备好chunks后,也是调用了do_fetch_chunks方法,和 Blob 模式相同。
(2)如果没有缓存blob,则使用cache.prefetch_range(&req)方法:
fn prefetch_range(&self, range: &BlobIoRange) -> Result<usize> {
let mutpending = Vec::with_capacity(range.chunks.len());
if !self.chunk_map.is_persist() {
let mutd_size = 0;
for c in range.chunks.iter() {
d_size = std::cmp::max(d_size, c.uncompressed_size() asusize);
}
let mutbuf = alloc_buf(d_size);
for c in range.chunks.iter() {
ifletOk(true) = self.chunk_map.check_ready_and_mark_pending(c.as_ref()) {
// The chunk is ready, so skip it.
continue;
}
// For digested chunk map, we must check whether the cached data is valid because
// the digested chunk map cannot persist readiness state.
let d_size = c.uncompressed_size() asusize;
matchself.read_file_cache(c.as_ref(), &mutbuf[0..d_size]) {
// The cached data is valid, set the chunk as ready.
Ok(_v) => self.update_chunk_pending_status(c.as_ref(), true),
// The cached data is invalid, queue the chunk for reading from backend.
Err(_e) =>pending.push(c.clone()),
}
}
} else {
for c in range.chunks.iter() {
ifletOk(true) = self.chunk_map.check_ready_and_mark_pending(c.as_ref()) {
// The chunk is ready, so skip it.
continue;
} else {
pending.push(c.clone());
}
}
}
let muttotal_size = 0;
let mutstart = 0;
whilestart <pending.len() {
// Figure out the range with continuous chunk ids, be careful that `end` is inclusive.
let mutend =start;
whileend <pending.len() - 1 &&pending[end + 1].id() ==pending[end].id() + 1 {
end+= 1;
}
let (blob_offset, _blob_end, blob_size) = self.get_blob_range(&pending[start..=end])?;
matchself.read_chunks_from_backend(blob_offset, blob_size, &pending[start..=end], true)
{
Ok(mutbufs) => {
total_size+= blob_size;
ifself.is_compressed {
let res = Self::persist_cached_data(
&self.file,
blob_offset,
bufs.compressed_buf(),
);
for c inpending.iter().take(end + 1).skip(start) {
self.update_chunk_pending_status(c.as_ref(), res.is_ok());
}
} else {
for idx instart..=end {
let buf = matchbufs.next() {
None => returnErr(einval!("invalid chunk decompressed status")),
Some(Err(e)) => {
forchunk in &mutpending[idx..=end] {
self.update_chunk_pending_status(chunk.as_ref(), false);
}
returnErr(e);
}
Some(Ok(v)) => v,
};
self.persist_chunk_data(pending[idx].as_ref(), &buf);
}
}
}
Err(_e) => {
// Clear the pending flag for all chunks in processing.
forchunk in &mutpending[start..=end] {
self.update_chunk_pending_status(chunk.as_ref(), false);
}
}
}
start =end + 1;
}
Ok(total_size)
}
明确需要获取的数据 range 后,直接调用read_chunks_from_backend从 backend 读取内容。
2.6.2 初始化 PassthroughFs backend
创建 fs 配置信息实例,根据配置信息创建 PassthroughFs 实例:
let fs_cfg = Config {
root_dir: cmd.source.to_string(),
do_import: false,
writeback: true,
no_open: true,
xattr: true,
..Default::default()
};
// TODO: Passthrough Fs needs to enlarge rlimit against host. We can exploit `MountCmd`
// `config` field to pass such a configuration into here.
let passthrough_fs =
PassthroughFs::<()>::new(fs_cfg).map_err(DaemonError::PassthroughFs)?;
passthrough_fs
.import()
.map_err(DaemonError::PassthroughFs)?;
info!("PassthroughFs imported");
Ok(Box::new(passthrough_fs))
创建 PassthroughFs 实例:
/// Create a Passthrough file system instance.
pubfn new(cfg: Config) -> io::Result<PassthroughFs<S>> {
// Safe because this is a constant value and a valid C string.
let proc_self_fd_cstr = unsafe { CStr::from_bytes_with_nul_unchecked(PROC_SELF_FD_CSTR) };
// 打开 /proc/self/fd 文件
let proc_self_fd = Self::open_file(
libc::AT_FDCWD,
proc_self_fd_cstr,
libc::O_PATH | libc::O_NOFOLLOW | libc::O_CLOEXEC,
0,
)?;
Ok(PassthroughFs {
inode_map: InodeMap::new(),
next_inode: AtomicU64::new(fuse::ROOT_ID + 1),
handle_map: HandleMap::new(),
next_handle: AtomicU64::new(1),
mount_fds: MountFds::new(),
proc_self_fd,
writeback: AtomicBool::new(false),
no_open: AtomicBool::new(false),
no_opendir: AtomicBool::new(false),
killpriv_v2: AtomicBool::new(false),
no_readdir: AtomicBool::new(cfg.no_readdir),
perfile_dax: AtomicBool::new(false),
cfg,
phantom: PhantomData,
})
}
passthrough_fs.import() 初始化文件系统。
/// Initialize the Passthrough file system.
pubfn import(&self) -> io::Result<()> {
let root = CString::new(self.cfg.root_dir.as_str()).expect("CString::new failed");
let (file_or_handle, st, ids_altkey, handle_altkey) = Self::open_file_or_handle(
self.cfg.inode_file_handles,
libc::AT_FDCWD,
&root,
&self.mount_fds,
|fd, flags, _mode| {
let pathname = CString::new(format!("{}", fd))
.map_err(|e| io::Error::new(io::ErrorKind::InvalidData, e))?;
Self::open_file(self.proc_self_fd.as_raw_fd(), &pathname, flags, 0)
},
)
.map_err(|e| {
error!("fuse: import: failed to get file or handle: {:?}", e);
e
})?;
// Safe because this doesn't modify any memory and there is no need to check the return
// value because this system call always succeeds. We need to clear the umask here because
// we want the client to be able to set all the bits in the mode.
unsafe { libc::umask(0o000) };
// Not sure why the root inode gets a refcount of 2 but that's what libfuse does.
self.inode_map.insert(
fuse::ROOT_ID,
InodeData::new(
fuse::ROOT_ID,
file_or_handle,
2,
ids_altkey,
st.get_stat().st_mode,
),
ids_altkey,
handle_altkey,
);
Ok(())
}
初始化 backend 文件系统完成。
回到daemon.service.mount(cmd)方法。接下来,通过self.get_vfs().mount(backend, &cmd.mountpoint)方法挂载 backend 文件系统:
/// Mount a backend file system to path
pubfn mount(&self, fs: BackFileSystem, path: &str) -> VfsResult<VfsIndex> {
let (entry, ino) = fs.mount().map_err(VfsError::Mount)?;
if ino > VFS_MAX_INO {
fs.destroy();
returnErr(VfsError::InodeIndex(format!(
"Unsupported max inode number, requested {} supported {}",
ino, VFS_MAX_INO
)));
}
// Serialize mount operations. Do not expect poisoned lock here.
let _guard = self.lock.lock().unwrap();
ifself.initialized() {
let opts = self.opts.load().deref().out_opts;
fs.init(opts).map_err(|e| {
VfsError::Initialize(format!("Can't initialize with opts {:?}, {:?}", opts, e))
})?;
}
let index = self.allocate_fs_idx().map_err(VfsError::FsIndex)?;
self.insert_mount_locked(fs, entry, index, path)
.map_err(VfsError::Mount)?;
Ok(index)
}
首先,通过fs.mount()方法获取 backend 文件系统root inode的entry和最大的inode,对于 RAFS:
impl BackendFileSystem for Rafs {
fn mount(&self) -> Result<(Entry, u64)> {
let root_inode = self.sb.get_inode(self.root_ino(), self.digest_validate)?;
self.ios.new_file_counter(root_inode.ino());
let e = self.get_inode_entry(root_inode);
// e 为 root inode 的 entry,第二个参数是支持的最大 inode 值
Ok((e, self.sb.get_max_ino()))
}
...
}
然后,通过self.allocate_fs_idx()方法分配可用的index:
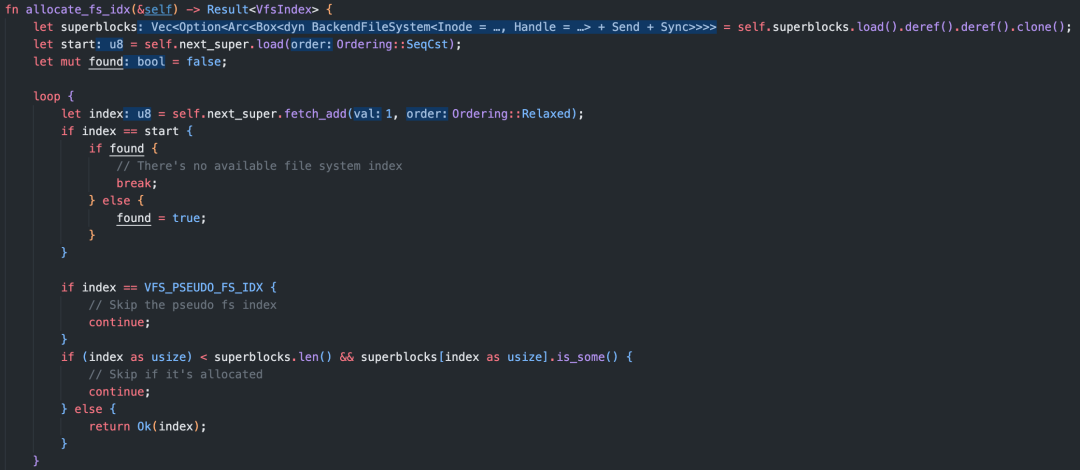
由于nydus通过index区分不同的pseudofs文件系统(具体来说,长度为 64 位的 inode 中前 8 位),因此,最多可以有 256 个pseudofs文件系统。
接下来,通过self.insert_mount_locked(fs, entry, index, path)方法挂载path,并且将index和新建pseudofs的entry关联起来:
fn insert_mount_locked(
&self,
fs: BackFileSystem,
mutentry: Entry,
fs_idx: VfsIndex,
path: &str,
) -> Result<()> {
// The visibility of mountpoints and superblocks:
// superblock should be committed first because it won't be accessed until
// a lookup returns a cross mountpoint inode.
let mutsuperblocks = self.superblocks.load().deref().deref().clone();
let mutmountpoints = self.mountpoints.load().deref().deref().clone();
// 挂载 path,得到 inode
let inode = self.root.mount(path)?;
let real_root_ino =entry.inode;
// 根据 index 对 inodes 进行 hash
entry.inode = self.convert_inode(fs_idx,entry.inode)?;
// 如果已经存在 mountpoint,先设置为 None
// Over mount would invalidate previous superblock inodes.
ifletSome(mnt) =mountpoints.get(&inode) {
superblocks[mnt.fs_idx asusize] = None;
}
superblocks[fs_idx asusize] = Some(Arc::new(fs));
self.superblocks.store(Arc::new(superblocks));
trace!("fs_idx {} inode {}", fs_idx, inode);
let mountpoint = Arc::new(MountPointData {
fs_idx,
ino: real_root_ino,
root_entry:entry,
_path: path.to_string(),
});
// 将新的 mount 添加到 self.mountpoints
mountpoints.insert(inode, mountpoint);
self.mountpoints.store(Arc::new(mountpoints));
Ok(())
}
其中,self.root.mount(path)方法创建新的pseudofs,如果path对应的pseudofs已经存在,则直接返回,否则,创建新的pseudofs:
// mount creates path walk nodes all the way from root
// to @path, and returns pseudo fs inode number for the path
pubfn mount(&self, mountpoint: &str) -> Result<u64> {
let path = Path::new(mountpoint);
if !path.has_root() {
error!("pseudo fs mount failure: invalid mount path {}", mountpoint);
returnErr(Error::from_raw_os_error(libc::EINVAL));
}
letmut inodes = self.inodes.load();
letmut inode = &self.root_inode;
'outer: for component in path.components() {
trace!("pseudo fs mount iterate {:?}", component.as_os_str());
match component {
Component::RootDir => continue,
Component::CurDir => continue,
Component::ParentDir => inode = inodes.get(&inode.parent).unwrap(),
Component::Prefix(_) => {
error!("unsupported path: {}", mountpoint);
returnErr(Error::from_raw_os_error(libc::EINVAL));
}
Component::Normal(path) => {
let name = path.to_str().unwrap();
// Optimistic check without lock.
for child in inode.children.load().iter() {
if child.name == name {
inode = inodes.get(&child.ino).unwrap();
continue'outer;
}
}
...
// 没找到对应 name 的 node,新建
let new_node = self.create_inode(name, inode);
inodes = self.inodes.load();
inode = inodes.get(&new_node.ino).unwrap();
}
}
}
// Now we have all path components exist, return the last one
Ok(inode.ino)
}
self.convert_inode(fs_idx, entry.inode)方法将pseudofs的 inode 根据 index 进行偏移,避免多个pseudofs的 inode 相同:
// 1. Pseudo fs 的根 inode 不进行 hash
// 2. 由于 Index 总是大于 0,因此 pseudo fs 的 inodes 不受影响(也会进行 hash)
// 3. 其它 inodes通过 (index << 56 | inode) 进行 hash
fn convert_inode(&self, fs_idx: VfsIndex, inode: u64) -> Result<u64> {
// Do not hash negative dentry
if inode == 0 {
returnOk(inode);
}
if inode > VFS_MAX_INO {
returnErr(Error::new(
ErrorKind::Other,
format!(
"Inode number {} too large, max supported {}",
inode, VFS_MAX_INO
),
));
}
let ino: u64 = ((fs_idx asu64) << VFS_INDEX_SHIFT) | inode;
trace!(
"fuse: vfs fs_idx {} inode {} fuse ino {:#x}",
fs_idx,
inode,
ino
);
Ok(ino)
}
挂载 backend 文件系统结束。
根据mount_cmd准备好文件系统后端(例如,RAFS backend),接下来通过 FUSE 进行挂载。daemon.service.session.lock().unwrap().mount()函数是fuse-backend-rs中FuseSession结构体的方法:
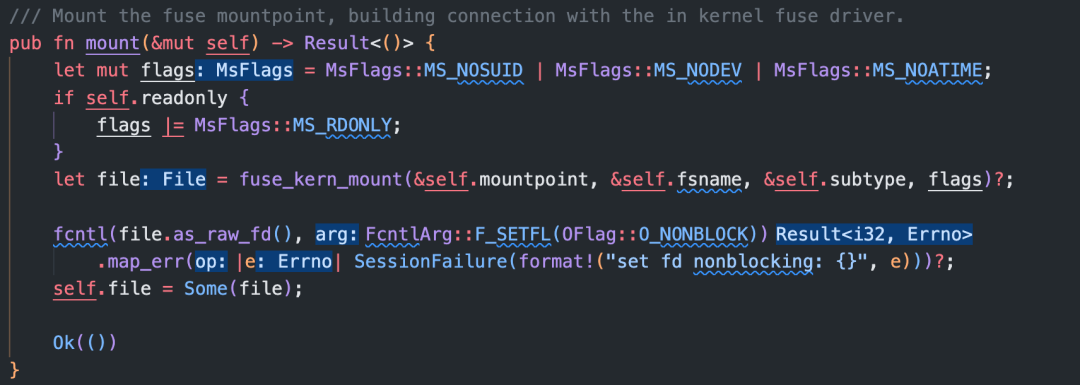
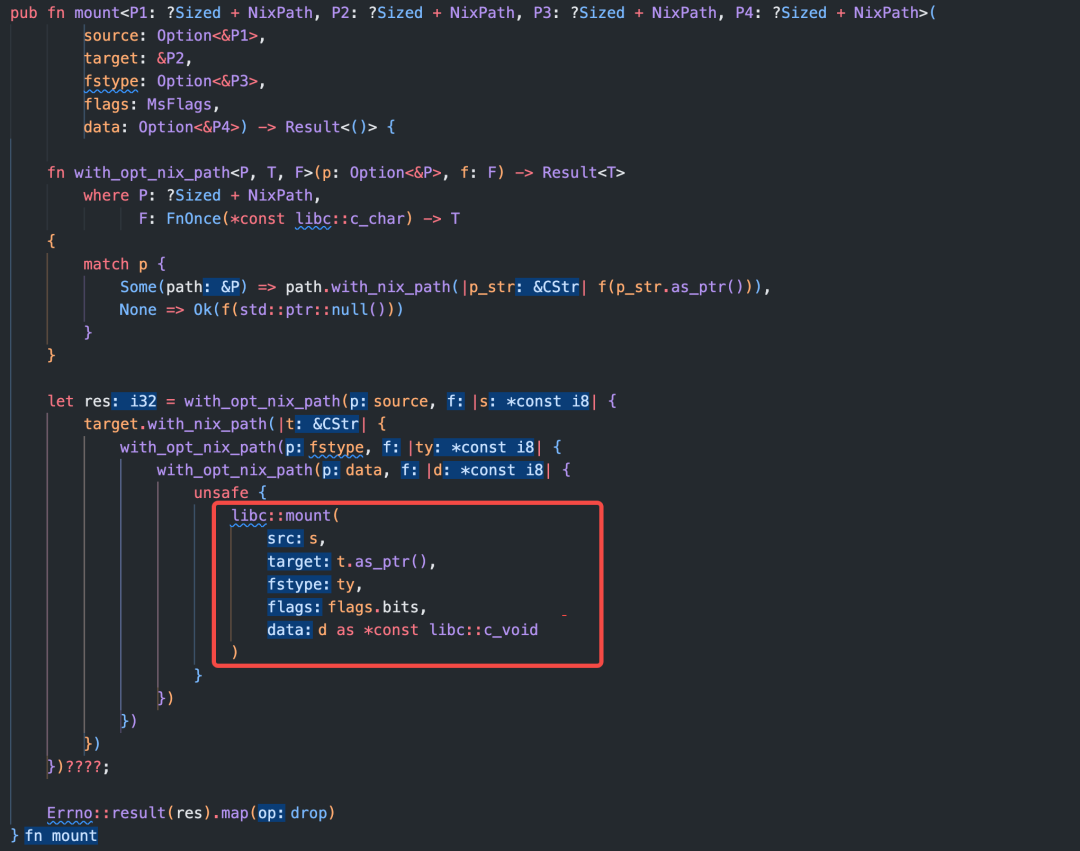
在fuse_kern_mount方法中,准备好需要的参数后,会调用nix crate 中的mount方法,这个方法最终调用了libc中的mount函数:
接下来,会向状态机线程发送Mount和Start两个事件,状态机的变化如下:

当状态转换为StartService时,会执行上面分析的d.start()方法,最终将状态修改为RUNNING:
StartService => d.start().map(|r| {
d.set_state(DaemonState::RUNNING);
r
}),
“
nydusd 在运行期间有 8 个线程,到目前为止,我们已经启动了其中的 6 个线程(fuse_server 的数量可以配置),接下来,还要启动两个线程 nydus-http-server 和 api-server。
最后,获取挂载点的 major 和 minor 信息,存储在元数据中。
create_fuse_daemon() 方法执行完成后,如果成功会打印如下日志信息:
参考资料
[1] nydus: https://github.com/dragonflyoss/image-service.git
[2] fuse-backend-rs: https://github.com/cloud-hypervisor/fuse-backend-rs


 浙公网安备 33010602011771号
浙公网安备 33010602011771号