Rust实战系列-深入理解数据
本文是《Rust in action》学习总结系列的第五部分,更多内容请看已发布文章:
“
主要学习数据在计算机中的表示方法,如何构建 CPU 模拟器,创建自定义数字数据类型和浮点数的工作原理。
本章主要理解如何通过 0 和 1 存储复杂的数据类型,如文本、图像和声音,还包括计算机底层如何运算,通过模拟具有 CPU、内存和自定义函数的计算机,设计只占用 1 个字节的自定义数据类型。此外,介绍了一些术语(对没经过系统训练的程序员可能会不熟悉),如无符号数、整数溢出。
1. Bit 模式和类型
高级语言中类型系统是对现实中事务的抽象,当开始探索计算机底层如何工作时,理解 bit 模式非常重要。
以下实例在计算机底层是相同的 bit 模式,但可以表示不同的数据:
a: 1100001111000011 50115
b: 1100001111000011 -15421
打印数据的函数代码:
fn main() {
let a: u16 = 50115;
let b: i16 = -15421;
println!("a: {:016b} {}", a, a); // <1>
println!("b: {:016b} {}", b, b); // <1>
}
- 这两个值的二进制表示相同,但数据类型不同
二进制表示和对应数值解释了“二进制”文件和“文本”文件的区别。“文本”文件也是“二进制”文件,碰巧遵循二进制串和字符之间的映射,这种映射被称为编码。
如果将二进制串以其他类型输出会发生什么呢?以下是示例代码:
fn main() {
let a: f32 = 42.42;
let frankentype: u32 = unsafe { std::mem::transmute(a) }; // <1>
println!("{}", frankentype); // <2>
println!("{:032b}", frankentype); // <3>
let b: f32 = unsafe { std::mem::transmute(frankentype) }; // <4>
println!("{}", b); // <4>
}
-
注意,这里 {} 中的最后没有分号,希望值可以在 {} 以外的作用域使用
-
将 42.42_f32 的 二进制串 作为整数类型
-
{:032b} 表示格式化输出为为 32 位二进制串(通过 std::fmt::Binary 特征),不够 32 位时在左边填充 0,如果没有 032(直接是 {:b}),左边的 0 不会被输出
-
确保操作的值是正确的
程序的运行结果:

可以看到,同一个数以不同的类型打印,得到的结果完全不同。
要将一个值打印成二进制串,值的类型必须实现 fmt::Binary 特征。整数类型实现了 fmt::Binary,f32 类型没有。i32 和 u32 这两种整数类型占用和 f32 相同的 bit 位数,因此,使用这两种整数类型得到的结果一样,示例代码中用的 u32 类型。接下来,需要一个在不影响底层数据情况下将 f32 类型数据当成 u32 数据使用的方法,这就是 std::mem::transmute() 方法,它允许程序员告诉编译器将值当成指定的类型使用。
⚠️ 注意:关键词 unsafe 并是说代码本身不安全,而是表示编译器无法保证程序内存的安全。
⚠️ 警告:unsafe 意味着程序员要对程序的完整性负全责。在不安全代码块内可以使用的函数很难验证安全性,例如,std::mem::transmute() 函数是最不安全的函数之一,打破了 Rust 的类型安全。因此,尽量不这样使用。
在程序中混用不同数据类型本来就是不安全的,因此需要放在在 unsafe 代码块中,不安全的 Rust 和安全的 Rust 实际上是完全一样的,只是没有编译器的检查。当我们查看数据的二进制序列时,需要用到 unsafe 代码块。
2. 整数的生命周期
前面已经讨论了整数作为 i32 或 u8 或 usize 的含义。整数就像娇嫩的鱼,如果让它们离开大自然范围,将会很快死去。整数也有范围,在计算机中,每个类型会占用固定的二进制长度。和浮点数不同,它不能通过牺牲精度来扩大能表示的范围,一旦将可用的长度填满,就不能继续表示更大的数值。16 位二进制长度可以表示 0 到 65536(2^16,即 16 位全为 1)之间的数字,如果需要表示的值大于 65536,会发生什么呢?这类问题的专业术语叫整数溢出。如果持续执行递增操作将会导致整数溢出,以下是示例代码:
fn main() {
letmut i: u16 = 0;
print!("{}..", i);
loop {
i += 1000;
print!("{}..", i);
if i % 10000 == 0 {
print!{"\n"}
}
}
}
程序的输出结果:
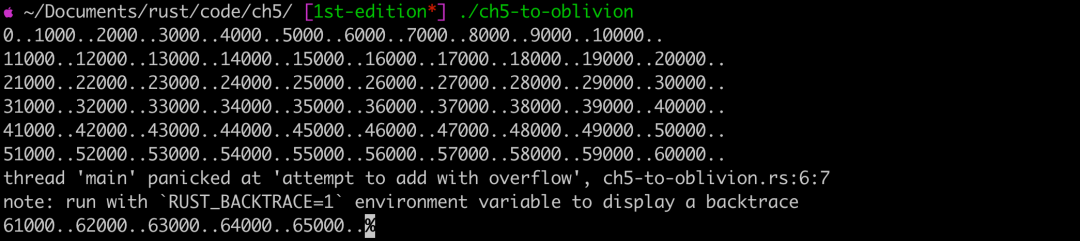
可以看到,程序提示 add 操作将会导致溢出。
panic 表示程序员要执行一个不可能的操作,程序不知道怎么做,于是结束了程序。继续看看到底发生了什么,以下的示例程序会打印 6 个用二进制序列表示的数字。
fn main() {
let zero: u16 = 0b0000_0000_0000_0000;
let one: u16 = 0b0000_0000_0000_0001;
let two: u16 = 0b0000_0000_0000_0010;
// ...
let sixty5_533: u16 = 0b1111_1111_1111_1101;
let sixty5_534: u16 = 0b1111_1111_1111_1110;
let sixty5_535: u16 = 0b1111_1111_1111_1111; // <1>
print!("{}, {}, {}, ..., ", zero, one, two);
println!("{}, {}, {}", sixty5_533, sixty5_534, sixty5_535);
}
- 当 16 位二进制位都用完时,会发生什么?为什么不能用 u16 表示 65,536?
还有更简单的方法使程序崩溃:将 400 转换为 u8 类型(u8 类型最大只能表示 255)。
#[allow(arithmetic_overflow)]// <1>
fn main() {
let (a, b) = (200, 200);
let c: u8 = a + b; // <2>
println!("200 + 200 = {}", c);
}
-
需要添加这个声明才能编译程序,因为 Rust 编译器很容检测到这种情况会溢出
-
类型声明很重要,Rust 不会完成这种不可能的转换
编译运行会得到如下结果:

如果 rustc 编译时添加 -O 标签,会得到错误的执行结果:

“
有两点需要注意:
(1)了解类型能表示的范围非常重要
(2)虽然 Rust 很健壮,但也能编写会出错的程序
处理整数溢出是系统程序员区别于其它程序员的一个方面,使用动态编程语言的程序员不可能遇到整数溢出的情况,因为语言会检查整数表达式的结果能否被正确表示,如果不能,将会自动调整为能表示更大范围的数据类型。
在开发高性能的关键代码时,可以选择调整类型。使用固定大小的数据类型存在整数溢出的风险,可以通过检查来避免。也可以使用能表示范围更大的数据类型,但会浪费存储空间。如果想要更灵活,就需要使用能表示任意范围的整数类型,这会带来额外的性能开销。
- 理解字节顺序(大小端)
在计算机中,CPU 表示整数有两种编码方式(通常称为大端和小端),一种是将整数的二进制位从左往右排列(先存储高位,称为大端),另一种是从右往左排列(先存储低位,称为小端),这也是将可执行程序复制到另一台计算机而不能正常运行的一个原因。
考虑一个占 32 个二进制位的整数:AA、BB、CC、DD(十六进制表示,AA 占用 8 个二进制位),以下示例代码借助 sys::mem::transmute() 方法演示字节顺序的重要性:
use std::mem;
fn main() {
let big_endian: [u8; 4] = [0xAA, 0xBB, 0xCC, 0xDD];
let little_endian: [u8; 4] = [0xDD, 0xCC, 0xBB, 0xAA];
let a: i32 = unsafe { mem::transmute(big_endian) }; // <1>
let b: i32 = unsafe { mem::transmute(little_endian) }; // <1>
println!("{} vs {}", a, b);
}
- mem::transmute() 方法告诉编译器将右边的值解释为左边指定的类型
大部分计算机运行程序会得到如下结果:
-573785174 vs -1430532899
也有些会得到如下结果:
-1430532899 vs -573785174
这个术语来源于序列中字节的“重要性”。回到学加法的时候,123 可以用 3 部分来表示:

将 3 部分相加,将会得到原始数据,100 被标记为“最重要的”。用传统的方式来表示,123 就是 123,这是大端方式。如果改成逆序,会把 123 表示为 321,这是小端方式。二进制数字也是类似的,每个数字都是 2 的幂(20,21,22,...,2n),而不是 10 的幂(100,101,102,...,10n)。
上世纪 90 年代末之前,字节顺序是个很大的问题,特别是服务器市场。Sun Microsystems、Cray、Motorola 和 SGI 掩盖了处理器可以支持双端表示的事实。ARM 决定开发支持双端的架构,英特尔只使用了小端模式。最终,因特尔胜出,大部分整数都是用小端顺序存储的。
除了多个字节之间的序列问题,在一个字节(一个字节表示 8 个二进制位)也存在问题。u8 类型的 3 应该表示成 0000_0011 还是 1100_0000?计算机对单个二进制位的顺序称为位标号或位字节性,这种内部顺序不太可能影响日常编程,可以通过“最重要位”的位置来查看。
3. 十进制数
了解二进制模式有利于压缩数据,接下来将学习如何从浮点数中提取二进制位并存储在自定义类型中。
问题的背景是这样的,进行机器学习时需要存储和分发大型模型,模型中的数字通常位于 0...1 或-1...1 范围内,这就不需要 f32 或 f64 能表示的整个范围。由于已经知道这些数字所在的范围,可以通过十进制数字格式来模拟。
首先,需要了解计算机内部如何表示十进制数的浮点类型。
- 关于浮点类型
在内存中,浮点数都是通过科学计数法表示的。如果不熟悉科学计数法,这有个例子。科学家将木星的质量描述为 1.898×10^27 千克,蚂蚁的质量描述为 3.801×10^(-4)千克。
通过科学记数法,只需要相同的字符就可以表示不同大小的数值。通过这种方法,计算机科学家设计了二进制位宽度固定的格式,用于表示广泛的数值范围。
科学记数法中的每个二进制位代表不同的角色:
(1)符号,在上面的两个例子中,正数的符号(+号)是隐式的,对负数(-)要显示表示
(2)尾数,也称为有效位(1.898 和 3.801)
(3)底数,也称为基数(两个例子中都是 10)
(4)指数,在例子中是 27 和-4
浮点数也由三部分组成:
(1)符号位
(2)指数
(3)尾数
底数呢?定义所有的浮点类型底数为 2,因此,允许在二进制模式中省略底数,
为了将浮点数中的二进制位转化为数字,需要完成三件事(代码在下面的实例中)。
(1)提取这些值的二进制位(deconstruct_f32() 函数)
(2)将每个值从二进制位转换为真实数值
(3)计算,将科学计数法表示的数字变换为普通数字
第一个任务是将每个值从二进制位中提取出来,这个步骤有点麻烦,因为这些值不是字节对齐的,主要用到了三种方法:
(1)右移(n >> m),其中 n 和 m 都是整数。这个操作是将二进制序列向右移动,并将左侧空出来的二进制位填充 0,得到的值本身是一个整数。这种方法可以用来分离符号位和尾数。
(2)AND 掩码(n & m),这个操作可以当成过滤器使用,可以通过调整 m 的值来选择需要保留的二进制位。
(3)左移(n<m),n 通常为 1,这个操作通常用来创建用于 AND 掩码的 m 值。随着程序运行,可以调整 m 值来动态过滤二进制位。
以下是示例代码:
const BIAS: i32 = 127; // <1>
const RADIX: f32 = 2.0; // <1>
fn main() { // <2>
let n: f32 = 42.42;
let (signbit, exponent, fraction) = deconstruct_f32(n); // <3>
let (sign, exponent, mantissa) = decode_f32_parts(signbit, exponent, fraction); // <4>
let reconstituted_n = f32_from_parts(sign, exponent, mantissa); // <5>
println!("{} -> [sign:{}, exponent:{}, mantissa:{:?}] ->
{}", n, signbit, exponent, mantissa, reconstituted_n);
}
fn deconstruct_f32(n: f32) -> (u32, u32, u32) {
let n_: u32 = unsafe { std::mem::transmute(n) };
let sign = (n_ >> 31) & 1; // <6>
let exponent = (n_ >> 23) & 0xff; // <7>
let fraction = 0b00000000_01111111_11111111_11111111 & n_; // <8>
(sign, exponent, fraction) // <9>
}
fn decode_f32_parts(sign: u32, exponent: u32, fraction: u32) -> (f32, f32, f32) {
let signed_1 = (-1.0_f32).powf(sign asf32); // <10>
let exponent = (exponent asi32) - BIAS; // <11>
let exponent = RADIX.powf(exponent asf32); // <11>
letmut mantissa: f32 = 1.0; // <12>
for i in0..23_u32 { // <13>
let one_at_bit_i = 1 << i; // <14>
if (one_at_bit_i & fraction) != 0 { // <15>
mantissa += 2_f32.powf((i asf32) - 23.0); // <16>
}
}
(signed_1, exponent, mantissa)
}
fn f32_from_parts(sign: f32, exponent: f32, mantissa: f32) -> f32 { // <17>
sign * exponent * mantissa
}
-
类似的常数可以通过 std::f32 模块访问
-
main() 函数可以存在文件开头
-
这里提取了组成 n 的三个部分,每部分都是一段二进制序列
-
将每个部分解析为数值
-
由这些数值计算原始值
-
右移 31 个二进制位,得到符号位
-
右移 23 个二进制位,再取低 8 位,相当于提取符号位之后 8 个二进制位
-
通过 AND 掩码提取最低的 23 个二进制位(相当于剩下的 23 个二进制位)
-
尾数被称为分数(fraction),解码之后就是尾数
-
将符号位转换为 1.0 或-1.0,需要为 -1.0_f32 添加括号以明确运算符的优先级,因为方法调用比“-”的优先级高
-
为了防止减去 BIAS 得到一个负数,需要将 exponent 转变为 i32 类型,作为指数使用时,需要再次转为 f32 类型。
-
将 mantissa 的默认值设置为 1
-
提供具体的类型,确保由掩码产生的二进制序列是有效的
-
每次迭代,产生一个提取指定二进制位(从右往左为 0...23 位)的掩码
-
结果非 0 时,意味着对应二进制位为 1(对应二进制位掩码为 1 时,需要数据中的对应位也为 1 才会得到非 0 结果)
-
为了得到第 i 个二进制位对应的十进制值,通过 2^(i-23)计算,-23 意味着当 i 越接近 0 时,得到的值越小
-
在中间步骤中使用了 f32 类型
理解如何从二进制位中解析数据能够更好处理网络中的数据。
程序运行结果:

- 深入理解 f32 类型
下图是浮点数二进制位的三部分表示,对应于 Rust 中的 f32 类型,在 IEEE 754-2019 和 IEEE 754-2008 标准中被称为 binary32,其前身为 IEE 754-1985 的 single 类型。

f32 类型 42.42 的二进制位表示为 01000010001010011010111000010100,更简洁的表示为 0x4229AE14(每 4 位二进制位表示为 1 个十六进制位)。以下是三个字段的值和所代表的内容:

- 符号位
符号位是一个二进制位,表示十进制数的正负。
(1)注意:- (+1)代表负数,0 代表正数
(2)特殊情况 :- (+ (-0))和 0 在内存中的二进制位序列不同,但值是相等的
‼️ 如何得到符号位:
去掉其它二进制位,对于 f32 类型,需要右移 31 位(>>31)步骤如下:
(1)将 f32 类型转为 u32 类型,方便移位操作
let n: u32 = unsafe { std::mem::transmute(42.42_f32) };

(2)将 n 右移 31 位(右移后第 32 位处于第 0 位,高位补 0)
let sign_bit = n >> 31;
- 关于指数
(1)注意:将二进制位当成整数处理,从结果中减去 127 得到指数,127 称为指数偏移值。至于为什么是减去 127,可以查阅 IEEE_754[1] 中对浮点数格式的定义。
“
指数偏移值(exponent bias):浮点数表示法中指数部分的值等于指数的实际值加上某个固定的值,这个固定的值就是偏移值。IEEE 754 标准规定该固定值为 2^(e-1)-1,其中的 e 为存储指数的二进制位长度。以单精度浮点数为例,指数占 8 个二进制位,则固定偏移值是为 2^(8-1)-1=128-1=127。
单精度浮点数指数部分的实际取值范围是 [-126,127](-127 和 128 被用作特殊值)。例如:指数实际值为 17,单精度浮点数中的指数部分的值为 17+127=144。通过这种方式,可以用长度为 e 的二进制位表示所有指数(主要是负指数)的值,在比较两个浮点数大小的时候更方便。
(2)特殊情况:
-
0x00 (0b00000000) 表示尾数应该视为“特殊的数”,可以表示更多接近 0 的浮点数。
-
0xFF (0b11111111)表示正无穷大(∞)、负无穷大(-∞)或“非数字”,“非数字”表示在数学上没有定义的特殊情况,如 0÷0 或其他无效的情况。得到“非数字”值的操作可以通过直觉判断,不能比较两个“非数字”值的大小,即使二进制位相同。
‼️ 如何得到指数:
将二进制位的第 31-22 位右移(第 22 位移至第 0 位),然后用 AND 掩码去掉符号位,将剩下的 8 位解析为整数,再减去偏差(127),得到指数。步骤如下:
(1)将 f32 类型转位 u32 类型,方便进行移位操作
let n: u32 = unsafe { std::mem::transmute(42.42_f32) };

(2)向右移位
let exponent_: n >> 23;

(3)通过 AND 掩码过滤掉符号位,保留和掩码中非零位相同位置的二进制位
let exponent_: exponent_ & 0b00000000_00000000_00000000_11111111

(4)按照标准规定,减去指数偏移值 127
let exponent: (exponent_ asi32) - 127; // <1>
- 将指数转换为 i32 类型,可以表示负数
- 关于尾数
每个二进制位都代表一个浮点标准(例如 IEEE_754)定义的值。计算尾数时要遍历每个二进制位,当第 i 位(从右往左数)等于 1 时,将 2^(i-23)的值累加到临时变量。这些位代表 0.5(2^-1,即 1/2),0.25(2^-2,即 1/4),直到 0.00000011920928955078125(2^-23)。代表 1.0(2^-0,即 i=23)的第 24 位在特殊情况下才会使用。
(1)特殊情况:指数的状态可以触发对尾数的特殊处理
-
当指数为 255(0b11111111)时,尾数中的 0 代表无穷(∞),其它二进制位都代表“非数字”(f32::NAN)。
-
当指数为 0(0b00000000)时,尾数中的零用 0 表示,每个非零位将第 24 个二进制位转换为 0.0。
‼️ 如何得到尾数:
从右往左遍历尾数二进制位,将值累加到初始化为第 24 个二进制位(1.0)的尾数变量。特殊情况不在下面的步骤处理,但可能会提前返回无穷大、无穷小、非数字或从尾数变量中减去 1.0。
(1)将 f32 类型转换为 u32 类型,方便进行移位操作
let n: u32 = unsafe { std::mem::transmute(42.42_f32) };
(2)创建类型为 f32 的可修改变量,初始化为 1.0(即 2^-0)
letmut mantissa: f32 = 1.0;
(3)从右到左遍历尾数,将每位对应的值累加到 mantissa 变量
for i in0..23_u32 { // <1>
let one_at_bit_i = 1 << i; // <2>
if (one_at_bit_i & fraction) != 0 {
let i_ = i asf32;
mantissa += 2_f32.powf( i_ - 23.0 );
}
}
-
指定类型(u32)可以使移位操作按照指定的位置进行
-
语法 1<<i 创建一个二进制位,在第 i 位为 1,其它地方都为 0。当 i 等于 5 时,得到的二进制位为 0b00000000_00000000_00000000_00100000
对 1 进行左移的效果(黑色块代表 1,白色块代表 0):

⚠️ 注意:Rust 的数字有方法,虽然使用很方便,但由于运算符 - 的优先级比方法调用低,这可能会导致意想不到的数学错误。
计算-1^0 的正确方法是使用圆括号告诉编译器-1 是整体:
(-1.0_f32).powf(0.0)
而不是这样使用:
-1.0_f32.powf(0.0)
这样编译器将会解析为-(1^0)。
- 用定点数类型表示十进制数
为了在单个字节(8 个二进制位)表示数字,需要使用由德州仪器公司为嵌入式设备开发的“Q 格式”。这是一种定点数格式,与浮点数不同,不会通过移动小数点的位置来适应不同数据范围。
要实现的“Q 格式”具体版本为 Q7,表明有 7 个二进制位用于表示数字,另外 1 个是符号位。通过 i8 类型的 7 个二进制位来隐藏类型的十进制特性,意味着 Rust 编译器能够协助跟踪值的符号。此外,还将派生出 PartialEq 和 Eq 特性为类型提供比较运算符。
格式的定义:
#[derive(Debug,Clone,Copy,PartialEq,Eq)]
pubstruct Q7(i8); // <1>
- 这种形式 struct 被称为“元组结构”,只有匿名字段
Q7 仅仅是一种存储和传输的数据类型,最重要的作用是在不同浮点类型之间转换。下面是与 f64 的转换:
implFrom<f64> for Q7 { // <1>
fn from (n: f64) -> Self {
// assert!(n >= -1.0); // <2>
// assert!(n <= 1.0); // <2>
if n >= 1.0 { // <3>
Q7(127)
} elseif n <= -1.0 {
Q7(-128)
} else {
Q7((n * 128.0) asi8)
}
}
}
implFrom<Q7> forf64 { // <4>
fn from(n: Q7) -> f64 {
(n.0asf64) * 2f64.powf(-7.0) // <5>
}
}
-
从 f64 转换为 Q7,From 或者 std::convert::From 方法是 Rust 中默认可用的方法,除非主动禁用
-
当输入的值越界时,可以选择让程序退出
-
越界的数字会被强制转换为 Q7 范围的最大值
-
将 Q7 转换为 f64 类型
-
在数学上等同于遍历每个二进制位并将其乘以权重,和对浮点尾数进行解码的操作相同
也有和 f32 类型之间的转换,利用 Rust 自带的机制来完成:
implFrom<f32> for Q7 {
fn from (n: f32) -> Self {
Q7::from(n asf64) // <1>
}
}
implFrom<Q7> forf32 {
fn from(n: Q7) -> f32 {
f64::from(n) asf32// <2>
}
}
-
从 f32 类型转换为 f64 类型是安全的,如果数字可以用 32 位来表示,肯定也可以用 64 位表示
-
通常,将 f64 类型转换为 f32 类型有可能损失精度,在这个示例中,不存在这个风险,因为转换的数字都位于-1 和 1 之间
现在,和两种浮点类型(f32 和 f64)的转换都已经实现,如何检测这些代码是否真的有效呢?Rust 的 cargo 工具能够很好地支持单元测试。
以下是完整代码:
#[derive(Debug,Clone,Copy,PartialEq,Eq)]
pubstruct Q7(i8);
implFrom<f64> for Q7 {
fn from (n: f64) -> Self {
if n >= 1.0 {
Q7(127)
} elseif n <= -1.0 {
Q7(-128)
} else {
Q7((n * 128.0) asi8)
}
}
}
implFrom<Q7> forf64 {
fn from(n: Q7) -> f64 {
(n.0asf64) * 2f64.powf(-7.0)
}
}
implFrom<f32> for Q7 {
fn from (n: f32) -> Self {
Q7::from(n asf64)
}
}
implFrom<Q7> forf32 {
fn from(n: Q7) -> f32 {
f64::from(n) asf32
}
}
#[cfg(test)]
mod tests { // <1>
use super::*; // <2>
#[test]
fn out_of_bounds() {
assert_eq!(Q7::from(10.), Q7::from(1.));
assert_eq!(Q7::from(-10.), Q7::from(-1.));
}
#[test]
fn f32_to_q7() {
let n1: f32 = 0.7;
let q1 = Q7::from(n1);
let n2 = -0.4;
let q2 = Q7::from(n2);
let n3 = 123.0;
let q3 = Q7::from(n3);
assert_eq!(q1, Q7(89));
assert_eq!(q2, Q7(-51));
assert_eq!(q3, Q7(127));
}
#[test]
fn q7_to_f32() {
let q1 = Q7::from(0.7);
let n1 = f32::from(q1);
assert_eq!(n1, 0.6953125);
let q2 = Q7::from(n1);
let n2 = f32::from(q2);
assert_eq!(n1, n2);
}
}
-
在当前文件中定义一个子模块
-
将父模块导入子模块,在该子模块内能访问被导入模块中标记为 pub 的内容
通过 cargo 进行单元测试:
cargo test
运行结果:
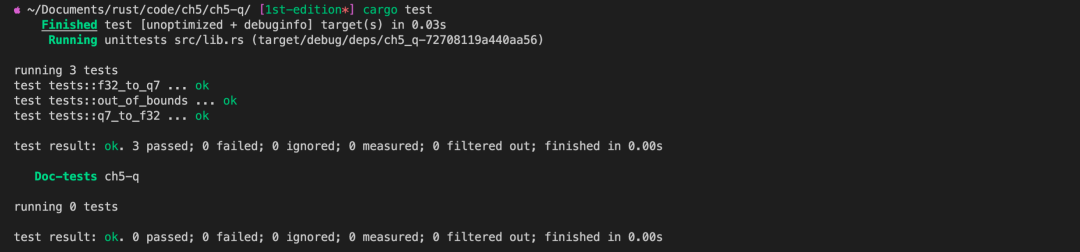
通过 cargo test 命令,运行 tests 模块下的所有单元测试函数。
“
Rust 中的模块系统:
Rust 包括强大的、符合人体工程学的模块系统。为了保持简单,示例代码没有过多的使用模块。以下是一些基本的概念:
(1)模块(mod)组成 crates。
(2)模块可以通过项目的目录结构来定义,当 src 下的子目录包含 mod.rs 文件时,该子目录就是一个模块。
(3)在文件中,模块也可以用 mod 关键字定义
(4)模块可以任意嵌套
(5)模块的所有成员,包括其子模块,默认是私有的。私有内容可以在该模块和任意子模块中被访问,希望公开的内容可以用 pub 关键字作为前缀。
(6)pub 关键字有一些特殊情况
pub(crate) 将内容暴露给 crate 中的其他模块
pub(super) 将内容项目暴露给父模块
pub(in path) 将内容项目暴露给路径中模块。
(7)使用 use 关键字将其它模块的 pub 内容导入到当前模块范围。
4. 从随机字节生成位于 0 和 1 之间的 f32 类型值
这是一个有的有趣示例,想象一下,你希望将一个字节的随机值转换为 0 到 1 之间的浮点数,如果直接通过 mem::transmute 方法把传入的字节解释为 f32/f64 类型会导致结果不正确。通过除法操作可以实现,但性能不好,也许有比除以单个字节能表的最大数字更快的方法。以下是通过除法实现的代码:
fn mock_rand(n: u8) -> f32 {
(n asf32) / 255.0// <1>
}
- 255 是 u8 类型能表示的最大值
假设有一个固定的指数值,然后将传入的二进制位移位得到尾数,从而得到位于 0 和 1 之间的数。以下是示例代码,指数为-1(表示 126,二进制序列 0b01111110),字节本身能表示的范围是 0.5 到 0.998,可以通过减法和乘法归一化为 0.0 到 0.996 之间。
fn mock_rand(n: u8) -> f32 {
let base: u32 = 0b0_01111110_00000000000000000000000; // <1>
let large_n = (n asu32) << 15; // <2>
let f32_bits = base | large_n; // <3>
let m = f32::from_bits(f32_bits); // <4>
2.0 * ( m - 0.5 ) // <5>
}
-
“下划线”表示符号、尾数、指数的分界
-
将输入的字节 n 转为 32 位二进制位,并向左移动 15 位以增加数值
-
将 base 和输入的字节按位进行或(OR)操作
-
将 f32_bits(类型为 u32)转换为 f32 类型
-
对返回值的范围进行归一化(0.0 到 0.996 之间)
很容易对以上函数的进行测试:
fn mock_rand(n: u8) -> f32 {
let base: u32 = 0b0_01111110_00000000000000000000000;
let large_n = (n asu32) << 15;
let f32_bits = base | large_n;
let m = f32::from_bits(f32_bits);
2.0 * ( m - 0.5 )
}
fn main() {
println!("max of input range: {:08b} -> {:?}", 0xff, mock_rand(0xff));
println!("mid of input range: {:08b} -> {:?}", 0x7f, mock_rand(0x7f));
println!("min of input range: {:08b} -> {:?}", 0x00, mock_rand(0x00));
}
程序输出结果:

5. 实现 CPU,理解函数也是数据
关于计算,有一个耐人寻味的细节:指令也是数据。操作(operation)和被操作的数据使用相同的数据编码方式,这意味着可以通过软件模拟其他计算机的指令集。接下来会通过代码进行模拟,了解计算机底层是如何工作的,包括函数如何运行和“指针”的含义。模拟过程不会用到汇编语言(实际上是使用十六进制进行编程),还会介绍其他可能接触到的术语,如“堆栈”。
将要实现的是二十世纪七十年代面向消费者的计算机子系统,称为 CHIP-8,它得到了很多制造商的支持,但即使以当时的标准来看也是相当原始的(为了编写游戏而创建,而不是为了商业或科学应用)。其中的一个设备是 COSMAC VIP,有一个分辨率为 64x32(0.0002 百万像素)的单色显示屏,2KB 内存,1.76 Mhz 的 CPU,售价 275 美元。这台电脑需要手动组装,还包括世界上第一位女性游戏开发者(Joyce Weisbecker[2])编写的游戏。
- CPU 1:加法器
接下来从一个最小的核心部件开始理解,建立一个支持单一指令的模拟器:加法器。为了理解示例代码,需要先理解三个内容:
(1)新的术语
(2)如何解析操作码
(3)了解主循环
与 CPU 模拟器有关的术语词汇:
(1)操作(通常简称为 op):是指系统本身支持的程序。进一步理解,可能还会遇到类似的短语,如“基于硬件实现”、“内在操作”。
(2)寄存器:存储 CPU 可直接访问数据的容器。对于大多数操作,必须将操作数移到寄存器中才能使用。对于 CHIP-8,每个寄存器是 u8 类型。(3)操作码:映射到操作的数字。在 CHIP-8 平台上,操作码包括操作和操作数的寄存器。
定义 CPU:
支持的第一个操作是加法。该操作以两个寄存器(x 和 y)为操作数,将存储在 y 中的值加到 x 中。使用尽可能少的代码实现,初始的 CPU 只包含 2 个寄存器和 1 个操作码空间。
struct CPU {
current_operation: u16, // <1>
registers: [u8; 2], // <2>
}
-
CHIP-8 的所有操作码都是 u16 类型
-
两个寄存器已经足够用来实现加法
到目前为止,CPU 是惰性的。完成加法需要以下步骤:
(1)初始化一个 CPU
(2)将 u8 类型的值加载到寄存器中
(3)将加法运算的操作码加载到 current_operation 中
(4)执行操作
还不能将数据存储在内存中。
将值加载进寄存器:
“启动” CPU 包括对 CPU 结构的字段赋值:
fn main() {
letmut cpu = CPU {
current_operation: 0,
registers: [0; 2],
};
cpu.current_operation = 0x8014; // <1>
cpu.registers[0] = 5; // <2>
cpu.registers[1] = 10; // <2>
}
-
涉及两个寄存器的操作码以 8 开头,0x8014 是寄存器(0)和寄存器(1)进行加法的操作码,4 表示加法
-
寄存器只能存储 u8 类型的值
理解模拟器的主循环:
现在,数据已经加载完成,CPU 可以完成一些工作了。run() 方法模拟 CPU 周期,执行模拟器的大部分工作,工作模式如下:
(1)读取操作码(最终是从内存中读取)
(2)解码指令
(3)将解码后的指令与已知的操作码进行匹配
(4)将操作分配给特定函数完成
impl CPU {
fn read_opcode(&self) -> u16 { // <1>
self.current_operation // <1>
} // <1>
fn run(&mut self) {
// loop { // <2>
let opcode = self.read_opcode();
let c = ((opcode & 0xF000) >> 12) as u8; // <3>
let x = ((opcode & 0x0F00) >> 8) as u8; // <3>
let y = ((opcode & 0x00F0) >> 4) as u8; // <3>
let d = ((opcode & 0x000F) >> 0) as u8; // <3>
match (c, x, y, d) {
(0x8, _, _, 0x4) => self.add_xy(x, y), // <4>
_ => todo!("opcode {:04x}", opcode), // <5>
}
// } // <2>
}
fn add_xy(&mut self, x: u8, y: u8) {
self.registers[x as usize] += self.registers[y as usize];
}
}
-
当 read_opcode() 从内存读取数据时会变得更复杂
-
暂时避免使用 loop 循环
-
操作码的解码过程将在下一节介绍
-
将任务分派给负责执行的“硬件电路”
-
完整的模拟器包含几十个操作
如何解析 CHIP-8 操作码:
对于 CPU 来说,解析操作码(0x8014)是非常重要的,接下来对本章使用的操作码解析过程和变量命名规格进行介绍。
CHIP-8 的操作码是由 4 个 nibble 组成的 u16 类型值,一个 nibble 占用半个字节(4 个二进制位)。由于 Rust 中没有 4 个二进制位的类型,将 u16 类型值拆分成这些部分也很麻烦。更复杂的是,nibble 通常会根据上下文被重新组合成 8 位或 12 位的值。
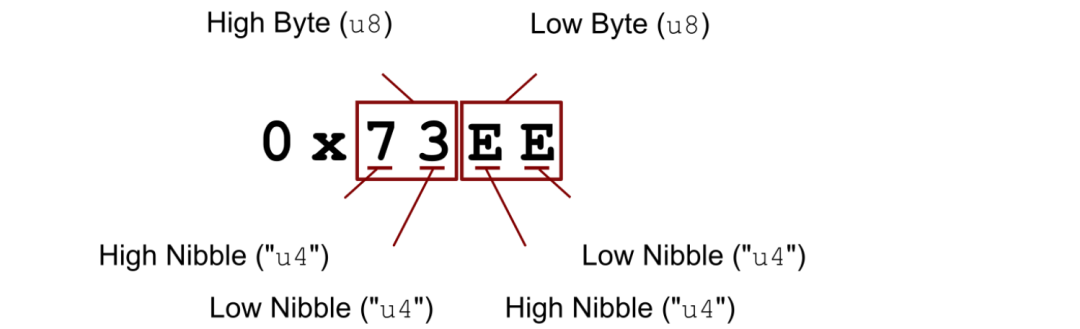
为了简化对每个操作码的讨论,先介绍一些标准术语。每个操作码由两个字节(16 个二进制位)组成,高(位于左边)字节和低(位于右边)字节,而每个字节由两个 nibble 组成,分别是高 nibble 和低 nibble,下图是一个说明:
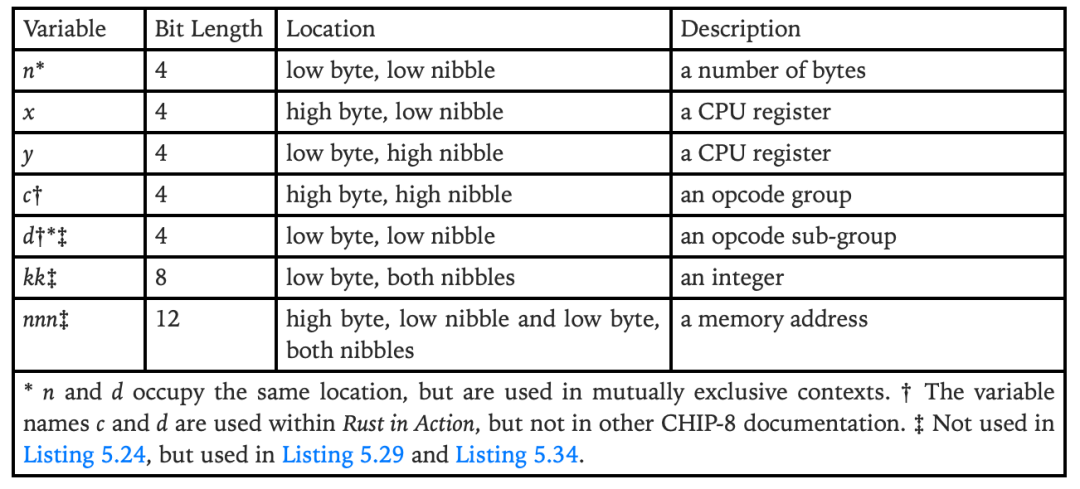
CHIP-8 的操作手册介绍了这几个变量,包括 kk、nnn、x 和 y,下表是详细信息:
主要有 3 种形式的操作码,如下图所示。解码过程包括匹配第一个字节的高 nibble ,然后从三种策略中选一种。



为了从字节中提取 nibble,需要使用右移(>>)和按位与(&)操作,以下是示例代码:
fn main() {
let opcode: u16 = 0x71E4; // <1>
let c = (opcode & 0xF000) >> 12; // <2>
let x = (opcode & 0x0F00) >> 8; // <2>
let y = (opcode & 0x00F0) >> 4; // <2>
let d = (opcode & 0x000F) >> 0; // <2>
assert_eq!(c, 0x7); // <1>
assert_eq!(x, 0x1); // <1>
assert_eq!(y, 0xE); // <1>
assert_eq!(d, 0x4); // <1>
let nnn = opcode & 0x0FFF; // <3>
let kk = opcode & 0x00FF; // <3>
assert_eq!(nnn, 0x1E4);
assert_eq!(kk, 0xE4);
}
-
操作码中的 4 个 nibble 在处理后可作为单独的变量使用。
-
可以用 AND 运算符(&)来选择单个 nibble,以得到应该保留的二进制位,然后通过移位操作移到字节的最低有效位。这些操作通过十六进制符号很方便,因为每个十六进制数字代表 4 位,1 个 0xF 值即可选择一个 nibble 的所有位。
-
通过增加过滤器的宽度(F 的数量)来选择多个 nibble,这里需要提取最低位的值,因此不需要右移。
能够解码指令,下一步是实际执行这些指令。
- 第一个可用的模拟器
以下是原始模拟器(加法器)的完整代码:
struct CPU {
current_operation: u16,
registers: [u8; 2],
}
impl CPU {
fn read_opcode(&self) -> u16 {
self.current_operation
}
fn run(&mutself) {
// loop {
let opcode = self.read_opcode();
let c = ((opcode & 0xF000) >> 12) asu8;
let x = ((opcode & 0x0F00) >> 8) asu8;
let y = ((opcode & 0x00F0) >> 4) asu8;
let d = ((opcode & 0x000F) >> 0) asu8;
match (c, x, y, d) {
(0x8, _, _, 0x4) => self.add_xy(x, y),
_ => todo!("opcode {:04x}", opcode),
}
// }
}
fn add_xy(&mutself, x: u8, y: u8) {
self.registers[x asusize] += self.registers[y asusize];
}
}
fn main() {
letmut cpu = CPU {
current_operation: 0,
registers: [0; 2],
};
cpu.current_operation = 0x8014;
cpu.registers[0] = 5;
cpu.registers[1] = 10;
cpu.run();
assert_eq!(cpu.registers[0], 15);
println!("5 + 10 = {}", cpu.registers[0]);
}
执行结果:

- CPU2:累加器(乘法器)
CPU 1 可以执行一条指令,对于 CPU 2,通过增加主循环和 position_in_memory 变量,能够依次执行多条指令,position_in_memory 保存着 CPU 下一条指令的内存地址。
需要对代码做以下修改:
(1)增加 4kb 的内存。
(2)加入完整的主循环和终止条件。在每次循环中,访问 position_in_memory 存储的内存地址指向的值,解析成操作码,然后 position_in_memory 会递增为下一个内存地址,操作码被执行。CPU 将一直运行,直到遇到终止条件(操作码为 0x0000)。
(3)删除 CPU 结构的 current_instruction 字段,由主循环中从内存解析字节的部分取代。
(4)操作码被写进内存。
扩展 CPU 以支持内存:
上面示例的 CPU 定义只能处理一条指令,为了完成更多工作,需要做一些修改,最主要的是增加内存:
struct CPU {
registers: [u8; 16], // <1>
position_in_memory: usize, // <2>
memory: [u8; 4096], // <3>
}
-
16 个寄存器意味着 1 个十六进制数字(0 到 F)可以对它们进行寻址
-
这是 1 个特殊的寄存器,通常被称为“程序计数器”(Program Counter Register,简称 PC)。这里使用一个更容易理解的名称,usize 类型用于在以后索引内存时保存一些类型转换。
-
CHIP-8 有 4 KiB 的 RAM(十六进制的 0x100,即 12 个二进制位,用于管理 2^12=4096 个字节的内存),规定前 512 个字节是为系统保留的,其他字节可供程序使用。这里没做限制。
从内存中读取操作码:
随着 CPU 内存的增加,read_opcode() 方法需要更新:
fn read_opcode(&self) -> u16 {
let p = self.position_in_memory;
let op_byte1 = self.memory[p] asu16;
let op_byte2 = self.memory[p + 1] asu16;
op_byte1 << 8 | op_byte2 // <1>
}
- 为了得到 u16 类型的操作码,两个来自内存的值(字节,u8 类型)通过逻辑 OR 操作进行拼接,在这之前需要先将每个值转换为 u16 类型,否则左移操作会把所有二进制位都变为 0。
处理整数溢出:
在 CHIP-8 内部,最后一个寄存器被用作 carry 标志,当设置这个标志时,表示操作已经溢出了寄存器能表示的 u8 类型大小。
以下代码展示了 CHIP-8 如何处理整数溢出:
fn add_xy(&mutself, x: u8, y: u8) {
let arg1 = self.registers[x asusize];
let arg2 = self.registers[y asusize];
let (val, overflow_detected) = arg1.overflowing_add(arg2); // <1>
self.registers[x asusize] = val;
if overflow_detected {
self.registers[0xF] = 1;
} else {
self.registers[0xF] = 0;
}
}
- u8 类型的 overflowing_add() 方法返回(u8, bool),当检测到溢出时,bool 为真。
第二个可用的模拟器:
完整代码:
struct CPU {
registers: [u8; 16],
position_in_memory: usize,
memory: [u8; 0x1000],
}
impl CPU {
fn read_opcode(&self) -> u16 {
let p = self.position_in_memory;
let op_byte1 = self.memory[p] asu16;
let op_byte2 = self.memory[p + 1] asu16;
op_byte1 << 8 | op_byte2
}
fn run(&mutself) {
loop { // <1>
let opcode = self.read_opcode();
self.position_in_memory += 2; // <2>
let c = ((opcode & 0xF000) >> 12) asu8;
let x = ((opcode & 0x0F00) >> 8) asu8;
let y = ((opcode & 0x00F0) >> 4) asu8;
let d = ((opcode & 0x000F) >> 0) asu8;
match (c, x, y, d) {
(0, 0, 0, 0) => { return; }, // <3>
(0x8, _, _, 0x4) => self.add_xy(x, y),
_ => todo!("opcode {:04x}", opcode),
}
}
}
fn add_xy(&mutself, x: u8, y: u8) {
let arg1 = self.registers[x asusize];
let arg2 = self.registers[y asusize];
let (val, overflow_detected) = arg1.overflowing_add(arg2);
self.registers[x asusize] = val;
if overflow_detected {
self.registers[0xF] = 1;
} else {
self.registers[0xF] = 0;
}
}
}
fn main() {
letmut cpu = CPU {
registers: [0; 16],
memory: [0; 4096],
position_in_memory: 0,
};
cpu.registers[0] = 5;
cpu.registers[1] = 10;
cpu.registers[2] = 10; // <4>
cpu.registers[3] = 10; // <4>
cpu.memory[0] = 0x80; cpu.memory[1] = 0x14; // <5>
cpu.memory[2] = 0x80; cpu.memory[3] = 0x24; // <6>
cpu.memory[4] = 0x80; cpu.memory[5] = 0x34; // <7>
cpu.run();
assert_eq!(cpu.registers[0], 35);
println!("5 + 10 + 10 + 10 = {}", cpu.registers[0]);
}
-
在处理一条指令之后继续执行
-
递增 position_in_memory 以指向下一条指令。每次操作会使用两个值,+2 表示指向下一次操作用到两个值的起始位置
-
当遇到操作码为 0x0000 时,直接 return 以终止函数的执行
-
初始化几个寄存器的值
-
将操作码 0x8014 加载到内存,0x8014 表示“将寄存器1中的值加到寄存器0中”
-
将操作码 0x8024 加载到内存中,0x8024 表示“将寄存器2中的值加到寄存器0中”
-
将操作码 0x8034 加载到内存中,0x8034 表示“将寄存器3中的值加到寄存器0中”
程序运行结果:

- CPU3:添加函数
目前,几乎已经实现所有的模拟器机制,接下来,继续增加调用函数的能力。没有编程语言的支持,仍然需要用二进制编写程序。除了实现函数,本节还尝试验证“函数也是数据”的说法。
扩展 CPU 以支持堆栈:
为了构建函数功能,还需要实现一些额外的操作码:
(1)CALL 操作码(0x2nnn,其中 nnn 是一个内存地址):将 position_in_memory 的值设置为 nnn,也就是函数的地址。
(2)RETURN 操作码(0x00EE):将 position_in_memory 的值设置为前一个 CALL 的内存地址。
为了使这些操作码协同工作,CPU 需要有一些专门的内存来存储这些地址,这就是所谓的 “堆栈”。每个 CALL 都会在堆栈中增加一个地址,通过增加堆栈指针并将 nnn 写到堆栈的堆顶位置实现。每个 RETURN 都会通过递减堆栈指针来删除堆顶的地址。
包括堆栈的 CPU 结构:
struct CPU {
registers: [u8; 16],
position_in_memory: usize,
memory: [u8; 4096],
stack: [u16; 16], // <1>
stack_pointer: usize, // <2>
}
-
堆栈的最大高度是 16,在调用 16 个嵌套函数后,将会导致堆栈溢出错误
-
设置 stack_pointer 的类型为 usize,使其更容易被用于堆栈的索引值
以下伪代码说明 main 函数中发生了什么,这些函数既没有名称、参数,也没有变量,都是以十六进制的形式出现。到目前为止,我们只实现了一个操作码,能完成的操作非常有限,将一个值添加到一个寄存器中两次已经足够(实现 n*2 的乘法操作)。
fn add_twice(register_1: u8, register_2: u8) {
// 0x8014;
register_1 += register_2;
// 0x8014;
register_1 += register_2;
// 0x00EE;
return;
}
实现 CALL 和 RETURN:
调用函数有三个步骤:
(1)在堆栈中存储当前用到的内存位置
(2)递增堆栈指针(指向栈顶第一个没使用的位置)
(3)将当前内存位置设置为目标内存地址
从函数中返回涉及的内容与调用过程相反:
(1)递减堆栈指针
(2)从堆栈中找回调用函数的内存地址
(3)将当前内存位置设置为目标内存地址
以下代码实现 call() 和 ret() 方法:
fn call(&mutself, addr: u16) {
let sp = self.stack_pointer;
let stack = &mutself.stack;
if sp > stack.len() {
panic!("Stack overflow!")
}
stack[sp] = self.position_in_memory asu16; // <1>
self.stack_pointer += 1; // <2>
self.position_in_memory = addr asusize; // <3>
}
fn ret(&mutself) {
ifself.stack_pointer == 0 {
panic!("Stack underflow");
}
self.stack_pointer -= 1;
self.position_in_memory = self.stack[self.stack_pointer] asusize; // <4>
}
-
将当前的 position_in_memory 添加到堆栈。这个内存地址比调用位置的地址高两个字节,因为在 run() 方法中已经被增加。
-
递增 self.stack_pointer,防止存储在堆栈中 self.position_in_memory 的值被覆盖,直到在函数返回时被再次访问。
-
修改 self.position_in_memory 的效果是跳转到该值对应的地址。
-
跳转到内存中之前发起函数调用的位置。
第三个可用的模拟器:
已经完成了所有准备工作,将它们组成程序,能够计算一个(硬编码的)数学表达式:
5 + (10 * 2) + (10 * 2) = 45
以下是完整代码:
struct CPU {
registers: [u8; 16],
position_in_memory: usize,
memory: [u8; 4096],
stack: [u16; 16],
stack_pointer: usize,
}
impl CPU {
fn read_opcode(&self) -> u16 {
let p = self.position_in_memory;
let op_byte1 = self.memory[p] asu16;
let op_byte2 = self.memory[p + 1] asu16;
op_byte1 << 8 | op_byte2
}
fn run(&mutself) {
loop {
let opcode = self.read_opcode();
self.position_in_memory += 2;
let c = ((opcode & 0xF000) >> 12) asu8;
let x = ((opcode & 0x0F00) >> 8) asu8;
let y = ((opcode & 0x00F0) >> 4) asu8;
let d = ((opcode & 0x000F) >> 0) asu8;
let nnn = opcode & 0x0FFF;
// let kk = (opcode & 0x00FF) as u8;
match (c, x, y, d) {
( 0, 0, 0, 0) => { return; },
( 0, 0, 0xE, 0xE) => self.ret(),
(0x2, _, _, _) => self.call(nnn),
(0x8, _, _, 0x4) => self.add_xy(x, y),
_ => todo!("opcode {:04x}", opcode),
}
}
}
fn call(&mutself, addr: u16) {
let sp = self.stack_pointer;
let stack = &mutself.stack;
if sp > stack.len() {
panic!("Stack overflow!")
}
stack[sp] = self.position_in_memory asu16;
self.stack_pointer += 1;
self.position_in_memory = addr asusize;
}
fn ret(&mutself) {
ifself.stack_pointer == 0 {
panic!("Stack underflow");
}
self.stack_pointer -= 1;
self.position_in_memory = self.stack[self.stack_pointer] asusize;
}
fn add_xy(&mutself, x: u8, y: u8) {
let arg1 = self.registers[x asusize];
let arg2 = self.registers[y asusize];
let (val, overflow_detected) = arg1.overflowing_add(arg2);
self.registers[x asusize] = val;
if overflow_detected {
self.registers[0xF] = 1;
} else {
self.registers[0xF] = 0;
}
}
}
fn main() {
letmut cpu = CPU {
registers: [0; 16],
memory: [0; 4096],
position_in_memory: 0,
stack: [0; 16],
stack_pointer: 0,
};
cpu.registers[0] = 5;
cpu.registers[1] = 10;
cpu.memory[0x000] = 0x21; cpu.memory[0x001] = 0x00; // <1>
cpu.memory[0x002] = 0x21; cpu.memory[0x003] = 0x00; // <2>
cpu.memory[0x004] = 0x00; cpu.memory[0x005] = 0x00; // <3>
cpu.memory[0x100] = 0x80; cpu.memory[0x101] = 0x14; // <4>
cpu.memory[0x102] = 0x80; cpu.memory[0x103] = 0x14; // <5>
cpu.memory[0x104] = 0x00; cpu.memory[0x105] = 0xEE; // <6>
cpu.run();
assert_eq!(cpu.registers[0], 45);
println!("5 + (10 * 2) + (10 * 2) = {}", cpu.registers[0]);
}
-
操作码 0x2100:CALL 0x100 处的函数
-
操作码 0x2100:CALL 0x100 处的函数
-
操作码 0x0000:隐式执行 HALT
-
操作码 0x8014:将寄存器 1 的值累加到寄存器 0 中
-
运算代码 0x8014:将寄存器 1 的值累加到寄存器 0 中
-
操作码 0x00EE:RETURN
程序执行结果:

- CPU4:添加其余内容
只需要再实现一些额外的操作码,就可以在 CPU 中实现乘法和更多的函数。
可以查看本书附带的源代码[3],特别是 ch5/ch5-cpu4 的例子以了解 CHIP-8 规范的更完整实现。
学习 CPU 和数据的最后一步是了解控制流如何工作。在 CHIP-8 中,控制流通过比较寄存器中的值来工作,然后根据结果修改 position_in_memory 的值。在 CPU 中没有 while 或 for 循环,在编程语言中有这些循环是编译器作者的功劳。
参考资料
[1] IEEE_754: https://zh.wikipedia.org/zh-cn/IEEE_754
[2] Joyce Weisbecker: https://en.wikipedia.org/wiki/Joyce_Weisbecker
[3] 源代码: https://github.com/rust-in-action/code


 浙公网安备 33010602011771号
浙公网安备 33010602011771号