
Linux 网络性能tuning向导
本文的目的不完全在于提供调优信息,而是在于告诉读者了解Linux kernel如何处理数据包,从而能够在
自己的实践中发挥Linux 内核协议栈最大的性能
The NIC ring buffer
接收环缓冲区在设备驱动程序和NIC之间共享。 网卡分配发送(TX)和接收(RX)环形缓冲区。 环形缓冲区是一个循环缓冲区,其中溢出只是覆盖现有数据。 应该注意,有两种方式将数据从NIC移动到内核,硬件中断和软件中断(也称为SoftIRQ)。 RX环形缓冲区用于存储传入的数据包,直到它们被设备驱动程序处理。 设备驱动程序通常通过SoftIRQ消费RX环,这将进入的数据包放入称为sk_buff或“skb”的内核数据结构中,以开始其通过内核并到达拥有相关套接字的应用程序。 TX环形缓冲区用于保存发往该线路的输出数据包。 这些环形缓冲器位于堆栈的底部,并且是可能发生分组丢弃的关键点,这又会不利地影响网络性能。
Interrupts and Interrupt Handlers
来自硬件的中断称为“上半部分”中断。 当NIC接收到传入数据时,它使用DMA将数据复制到内核缓冲区中。 NIC通过唤醒硬中断通知内核此数据。 这些中断由中断处理程序处理,这些中断处理程序执行最少的工作,因为它们已经中断了另一个任务,并且不能自行中断。 硬中断在CPU使用方面可能是昂贵的,特别是在持有内核锁时。 硬中断处理程序然后将大部分分组接收留给可以更公平地调度的软件中断或SoftIRQ处理。
硬中断可以在/ proc / interrupts中看到,其中每个队列在分配给它的第一列中有一个中断向量。 当系统引导或加载NIC设备驱动程序模块时,这些初始化。 每个RX和TX队列被分配一个唯一的向量,它通知中断处理程序该中断来自哪个NIC /队列。 列将进入中断的数量表示为计数器值:

SoftIRQs
也称为“下半”中断,软件中断请求(SoftIRQ)是内核线程,其被调度为在其他任务不会被中断的时间运行。 SoftIRQ的目的是消费网络适配器接收环缓冲区。 这些例程以ksoftirqd / cpu-number进程和调用驱动程序特定的代码函数的形式运行。 它们可以在过程监控工具(如ps和top)中看到。 以下调用堆栈,从底部向上读取,是一个SoftIRQ轮询Mellanox卡的示例。 标记为[mlx4_en]的函数是mlx4_en.ko驱动程序内核模块中的Mellanox轮询例程,由内核的通用轮询例程(如net_rx_action)调用。 从驱动程序移动到内核之后,接收到的流量将移动到套接字,准备应用程序使用:

可以如下监视SoftIRQ。 每列代表一个CPU:

NAPI Polling
NAPI或新的API,以使处理传入卡的数据包更有效率。 硬中断是昂贵的,因为它们不能被中断。 即使中断聚合(稍后更详细地描述),中断处理程序也将完全独占CPU核心。 NAPI的设计允许驱动程序进入轮询模式,而不是每次需要的数据包接收都被硬中断。 在正常操作下,引发初始硬中断或IRQ,随后是使用NAPI例程轮询卡的SoftIRQ处理器。 轮询例程具有确定允许代码的CPU时间的预算。 这是防止SoftIRQ独占CPU的必要条件。 完成后,内核将退出轮询例程并重新建立,然后整个过程将重复自身。
Network Protocol Stacks
一旦已经从NIC接收到到内核的业务,则其然后由协议处理器(例如以太网,ICMP,IPv4,IPv6,TCP,UDP和SCTP)处理。最后,数据被传递到套接字缓冲器, 运行接收函数,将数据从内核空间移动到用户空间,并结束内核在接收过程中的参与。
Packet egress in the Linux kernel
Linux内核的另一个重要方面是网络包出口。 虽然比入口逻辑简单,但出口仍然值得确认。 当skbs从协议层传递到核心内核网络例程时,该过程工作。 每个skb包含一个dev字段,其中包含将通过其传输的net_device的地址:

它使用此字段将skb路由到正确的设备:

基于此设备,执行将切换到处理skb的驱动程序,并最终将数据复制到NIC上。 这里主要需要调优的是TX队列入队规则(qdisc)稍后描述。 一些NIC可以有多个TX队列。
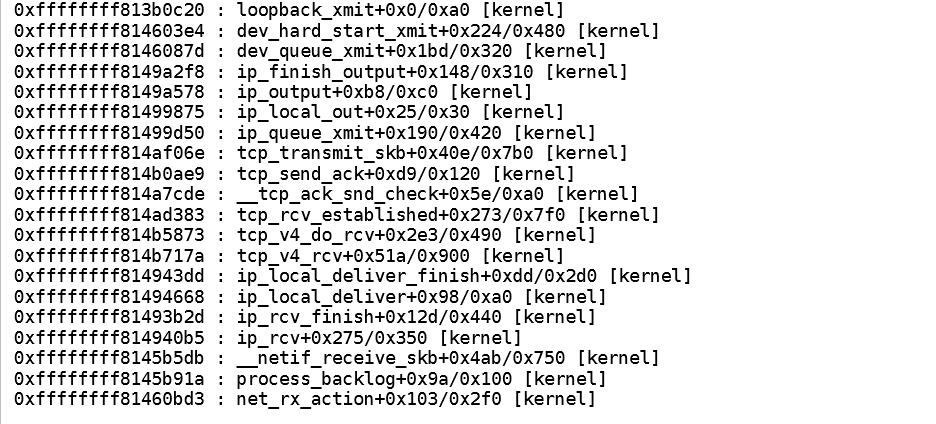
以下是从测试系统获取的示例堆栈跟踪。 在这种情况下,流量是通过环回设备,但这可以是任何NIC模块:
Networking Tools
要正确诊断网络性能问题,可以使用以下工具:
netstat
一个命令行实用程序,可以打印有关打开网络连接和协议栈统计信息。 它从/ proc / net /文件系统检索有关网络子系统的信息。 这些文件包括:
•/ proc / net / dev(设备信息)
•/ proc / net / tcp(TCP套接字信息)
•/ proc / net / unix(Unix域套接字信息)
有关netstat及其引用文件的更多信息 / proc / net /,请参考netstat手册页:man netstat。
dropwatch
监视实用程序,用于监视内核从内存释放的数据包。 有关更多信息,请参阅dropwatch手册页:man dropwatch。
ip
用于管理和监视路由,设备,策略路由和隧道的实用程序。 有关更多信息,请参阅ip手册页:man ip
ethtool
用于显示和更改NIC设置的实用程序。 有关更多信息,请参阅ethtool手册页:man ethtool。
各种工具可用于隔离问题区域。
通过调查以下几点来找到瓶颈:
•适配器固件级别 - 在ethtool -S ethX统计信息中观察丢弃
•适配器驱动程序级别
•Linux内核,IRQ或SoftIRQs - 检查/ proc /中断和/ proc / net / softnet_stat
• 协议层IP,TCP或UDP - 使用netstat -s并查找错误计数器
Performance Tuning
桥零复制发送
零拷贝发送模式减少了发送大数据包时的主机CPU开销
之间的客户网络和外部网络高达15%,而不影响
吞吐量。 红帽企业版Linux 7完全支持桥接零拷贝传输
虚拟机,但默认情况下禁用。
零拷贝发送模式对大数据包大小有效。 它通常会减少主机CPU
当在客户网络和外部网络之间传输大的数据包时,开销将高达15%
网络,而不影响吞吐量。
它不会影响客户机到客户机,客户机到主机或小数据包工作负载的性能。
红帽企业Linux 7虚拟机完全支持网桥零拷贝传输,但是
默认情况下禁用。 要启用零拷贝传输模式,请设置experimental_zcopytx内核
vhost_net模块的模块参数设置为1。
Virtio 网卡
这里面还有一个细节非常影响性能,那就是virtio的feature里面是否enable "rx mergeable",
disable这个feature的才能用到virtio pmd里面最快的rx/tx函数(经过向量指令优化了的),
对应的两个函数是virtio_xmit_pkts_simple()和virtio_recv_pkts_vec()。
SoftIRQ
如果SoftIRQ没有运行足够长的时间,传入数据的速率可能超过内核足够快地耗尽缓冲区的能力。 因此,NIC缓冲区将溢出并且流量将丢失。 有时,有必要增加SoftIRQ允许在CPU上运行的时间。 这被称为netdev_budget。 预算的默认值为300.
# sysctl net.core.netdev_budget
net.core.netdev_budget = 300
Tuned
Tuned是一个自适应系统调优守护程序。 它可以用于将收集在一起的各种系统设置应用到称为配置文件的集合中。 调整后的配置文件可以包含诸如CPU调度器,IO调度程序和内核可调参数(如CPU调度或虚拟内存管理)的指令。 Tuned还集成了一个监视守护程序,可以控制或禁用CPU,磁盘和网络设备的节能功能。 性能调整的目的是应用能够实现最佳性能的设置。 Tuned可以自动化这项工作的很大一部分。 首先,安装调优,启动调整守护程序服务,并在启动时启用服务:
# yum -y install tuned
# service tuned start
# chkconfig tuned on
列出性能配置文件:
# tuned-adm list
Available profiles:
- throughput-performance
- default
- desktop-powersave
- enterprise-storage
...
可以在/ etc / tune-profiles /目录中查看每个配置文件的内容。 我们关心的是设置性能配置文件,如吞吐量性能,延迟性能或企业级存储
设置配置文件:
# tuned-adm profile throughput-performance
Switching to profile 'throughput-performance'
所选配置文件将在每次调谐服务启动时应用。
virtual-guest-
Based on the
enterprise-storageprofile,virtual-guestalso decreases the swappiness of virtual memory. This profile is available in Red Hat Enterprise Linux 6.3 and later, and is the recommended profile for guest machines. virtual-host-
Based on the
enterprise-storageprofile,virtual-hostalso decreases the swappiness of virtual memory and enables more aggressive writeback of dirty pages. This profile is available in Red Hat Enterprise Linux 6.3 and later, and is the recommended profile for virtualization hosts, including both KVM and Red Hat Enterprise Virtualization hosts.
Numad
与tuned类似,numad是一个守护进程,可以帮助在具有非统一内存访问(NUMA)架构的系统上的进程和内存管理。 Numad通过监视系统拓扑和资源使用情况来实现这一点,然后尝试定位进程以实现高效的NUMA局部性和效率,其中进程具有足够大的内存大小和CPU负载。 numad服务还需要启用cgroups(Linux内核控制组)。
默认情况下,从Red Hat Enterprise Linux 6.5开始,numad将管理使用超过300Mb内存使用率和50%一个核心CPU使用率的任何进程,并尝试使用任何给定的NUMA节点高达85%的容量。 Numad可以使用man numad中描述的指令进行更细致的调整。
CPU Power States
ACPI规范定义了各种级别的处理器功率状态或“C状态”,其中C0是操作状态,C1是停止状态,加上实现各种附加状态的处理器制造商以提供额外的功率节省和相关优点,例如较低的温度。不幸的是,在功率状态之间的转换在延迟方面是昂贵的。由于我们关注使系统的响应性尽可能高,期望禁用所有处理器“深度睡眠”状态,仅保留操作和停止。这必须首先在系统BIOS或EFI固件中完成。应禁用任何状态,如C6,C3,C1E或类似。我们可以通过在GRUB引导加载程序配置中的内核行中添加processor.max_cstate = 1来确保内核从不请求低于C1的C状态。在某些情况下,内核能够覆盖硬件设置,并且必须向具有Intel处理器的系统添加附加参数intel_idle.max_cstate = 0。处理器的睡眠状态可以通过以下方式确认:
cat /sys/module/intel_idle/parameters/max_cstate
0
较高的值表示可以输入附加的睡眠状态。 powertop实用程序的Idle Stats页面可以显示每个C状态花费的时间
使用如下脚本修改各个 CPU 调频(物理机有 16 个物理 CPU)
#!/bin/bashfor a in {0..15};do echo $a;echo 'performance' > /sys/devices/system/cpu/cpu$a/cpufreq/scaling_governorcat /sys/devices/system/cpu/cpu$a/cpufreq/scaling_governordoneBIOS 中修改
禁用物理机超线程
TurboBoost Disabled
Power Technology: Performance
Manual balancing of interrupts
对于高性能来说要关闭irqbalance,同时将irq于cpu进行绑定
Ethernet Flow Control (a.k.a. Pause Frames)
暂停帧是适配器和交换机端口之间的以太网级流量控制。当RX或TX缓冲器变满时,适配器将发送“暂停帧”。开关将以毫秒级或更小的时间间隔停止数据流动。这通常足以允许内核排出接口缓冲区,从而防止缓冲区溢出和随后的数据包丢弃或超限。理想地,交换机将在暂停时间期间缓冲输入数据。然而,重要的是认识到这种级别的流控制仅在开关和适配器之间。如果丢弃分组,则较高层(例如TCP)或者在UDP和/或多播的情况下的应用应当启动恢复。需要在NIC和交换机端口上启用暂停帧和流控制,以使此功能生效。有关如何在端口上启用流量控制的说明,请参阅您的网络设备手册或供应商。
在此示例中,禁用流量控制:
# ethtool -a eth3 Pause parameters for eth3:
Autonegotiate:off
RX: off
TX: off
开启流量控制:
# ethtool -A eth3 rx on
# ethtool -A eth3 tx on
要确认流量控制已启用:
# ethtool -a eth3 Pause parameters for eth3:
Autonegotiate:off
RX: on
TX: on
Interrupt Coalescence (IC)
中断聚合是指在发出硬中断之前,网络接口将接收的流量或接收流量后经过的时间。中断太快或太频繁会导致系统性能不佳,因为内核停止(或“中断”)正在运行的任务以处理来自硬件的中断请求。中断太晚可能导致流量没有足够快地从NIC中取出。更多的流量可能到达,覆盖以前的流量仍然等待被接收到内核中,导致流量丢失。大多数现代的NIC和驱动程序支持IC,许多驱动程序允许驱动程序自动调节硬件产生的中断数。 IC设置通常包括2个主要组件,时间和数据包数量。时间是在中断内核之前NIC将等待的微秒数(u-sec),并且数字是在中断内核之前允许在接收缓冲器中等待的最大数据包数。 NIC的中断聚合可以使用ethtool -c ethX命令查看,并使用ethtool -C ethX命令进行调整。自适应模式使卡能够自动调节IC。在自适应模式下,驱动程序将检查流量模式和内核接收模式,并在运行中估计合并设置,以防止数据包丢失。当接收到许多小数据包时,这是有用的。更高的中断聚结有利于带宽超过延迟。 VOIP应用(等待时间敏感)可能需要比文件传输协议(吞吐量敏感)少的聚结。不同品牌和型号的网络接口卡具有不同的功能和默认设置,因此请参阅适配器和驱动程序的制造商文档。
在此系统上,默认启用自适应RX:
# ethtool -c eth3 Coalesce parameters for eth3:
Adaptive RX: on TX: off
stats-block-usecs: 0
sample-interval: 0
pkt-rate-low: 400000
pkt-rate-high: 450000
rx-usecs: 16
rx-frames:44
rx-usecs-irq: 0
rx-frames-irq: 0
以下命令关闭自适应IC,并通知适配器在接收到任何流量后立即中断内核:
# ethtool -C eth3 adaptive-rx off rx-usecs 0 rx-frames 0
比较理想的设置是允许至少一些分组在NIC中缓冲,并且在中断内核之前至少有一些时间通过。 有效范围可以从1到数百,取决于系统能力和接收的流量
The Adapter Queue
netdev_max_backlog是Linux内核中的队列,其中流量在从NIC接收之后但在由协议栈(IP,TCP等)处理之前存储。 每个CPU核心有一个积压队列。 给定核心的队列可以自动增长,包含的数据包数量可达netdev_max_backlog设置指定的最大值。 netif_receive_skb()内核函数将为数据包找到相应的CPU,并将数据包排入该CPU的队列。 如果该处理器的队列已满并且已达到最大大小,则将丢弃数据包。 要调整此设置,首先确定积压是否需要增加。 / proc / net / softnet_stat文件在第2列中包含一个计数器,该值在netdev backlog队列溢出时递增。 如果此值随时间增加,则需要增加netdev_max_backlog。
softnet_stat文件的每一行代表一个从CPU0开始的CPU内核:
第一列是中断处理程序接收的帧数。 第2列是由于超过netdev_max_backlog而丢弃的帧数。 第三列是ksoftirqd跑出netdev_budget或CPU时间的次数。
其他列可能会根据版本Red Hat Enterprise Linux而有所不同。 使用以下示例,CPU0和CPU1的以下计数器是前两行:
# cat softnet_stat
0073d76b 00000000 000049ae 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000000d2 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 0000015c 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 0000002a 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
For CPU0
Total droppedno_budget lock_contention
0073d76b 00000000 000049ae 00000000
For CPU1
Total droppedno_budget lock_contention
000000d2 00000000 00000000 00000000
Adapter RX and TX Buffer Tuning
Adapter Transmit Queue Length
vpp2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::14f7:b8ff:fe72:a52f prefixlen 64 scopeid 0x20<link>
ether 16:f7:b8:72:a5:2f txqueuelen 1000 (Ethernet)
RX packets 15905 bytes 1534810 (1.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 15905 bytes 1534810 (1.4 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0

Adapter Offloading
卸载设置由ethtool -K ethX管理。
常用设置包括:
•GRO:通用接收卸载
•LRO:大型接收卸载
•TSO:TCP分段卸载
•RX校验和=接收数据完整性处理
•TX校验和=发送数据完整性处理(TSO所需)
Jumbo Frames
默认802.3以太网帧大小为1518字节,或1522字节带有VLAN标记。 以太网报头使用此字节的18个字节(或22个带VLAN标记的字节),留下1500字节的有效最大有效载荷。 巨型帧是对以太网的非正式扩展,网络设备供应商已经做出了事实上的标准,将有效载荷从1500增加到9000字节。
对于常规的以太网帧,每个放置在线路上的1500字节数据有18字节的开销,或者1.2%的开销。使用巨帧,每个9000字节的数据放置在线上有18字节的开销,或0.2%的开销。以上计算假设没有VLAN标签,然而这样的标签将向开销增加4个字节,使得效率增益更加理想。当传输大量连续数据时,例如在两个系统之间发送大文件,可以通过使用巨帧获得上述效率。当传输少量数据(例如通常低于1500字节的web请求)时,可能没有从使用较大帧大小看到的增益,因为通过网络的数据将被包含在小帧内。对于要配置的巨帧,网络段(即广播域)中的所有接口和网络设备必须支持巨帧并启用增加的帧大小。
TCP Timestamps
TCP时间戳是TCP协议的扩展,定义在RFC 1323 - TCP Extensions for High Performance - http://tools.ietf.org/html/rfc1323
TCP时间戳提供单调递增计数器(在Linux上,计数器是自系统引导以来的毫秒),其可以用于更好地估计TCP对话的往返时间,导致更准确的TCP窗口和缓冲器计算。最重要的是,TCP时间戳还提供防止包装序列号,因为TCP报头将序列号定义为32位字段。给定足够快的链路,该TCP序列号可以包装。这导致接收器相信具有包装数的段实际上比其先前段更早到达,并且不正确地丢弃该段。在1吉比特每秒链路上,TCP序列号可以在17秒内换行。在10吉比特每秒的链路上,这被减少到少至1.7秒。在快速链路上,启用TCP时间戳应视为强制。 TCP时间戳提供了一种替代的非循环方法来确定段的年龄和顺序,防止包装的TCP序列号成为问题。
Ensure TCP Timestamps are enabled:
# sysctl net.ipv4.tcp_timestamps net.ipv4.tcp_timestamps = 1
If the above command indicates that tcp_timestamps = 0, enable TCP Timestamps:
# sysctl -w net.ipv4.tcp_timestamps=1
TCP SACK
基本TCP确认(ACK)仅允许接收器通知发送器已经接收到哪些字节。 当丢包发生时,这要求发送方从丢失点重传所有字节,这可能是低效的。 SACK允许发送方指定哪些字节已经丢失以及哪些字节已经被接收,因此发送方只能重传丢失的字节。 在网络社区有一些研究表明启用高带宽链路上的SACK可能导致不必要的CPU周期用于计算SACK值,降低TCP连接的整体效率。 这项研究意味着这些链路是如此之快,重传少量数据的开销小于作为选择性确认的一部分计算提供的数据的开销。 除非有高延迟或高数据包丢失,最有可能更好地保持SACK关闭在高性能网络。 SACK可以使用内核可调参数关闭:
# sysctl -w net.ipv4.tcp_sack=0
TCP Window Scaling
在原始TCP定义中,TCP段报头仅包含用于TCP窗口大小的8位值,这对于现代计算的链路速度和存储器能力是不足的。 引入了TCP Window Scaling扩展以允许更大的TCP接收窗口。 这是通过向在TCP报头之后添加的TCP选项添加缩放值来实现的。 真实的TCP接收窗口向左移位缩放因子值的值,最大大小为1,073,725,440字节,或接近1千兆字节。 TCP窗口缩放是在打开每个TCP对话的三次TCP握手(SYN,SYN + ACK,ACK)期间协商的。 发送方和接收方都必须支持“窗口缩放”窗口缩放选项才能工作。 如果一个或两个参与者在它们的握手中不公布窗口缩放能力,则会话回退到使用原始的8位TCP窗口大小。
默认情况下,在Red Hat Enterprise Linux上启用TCP窗口缩放。 窗口缩放的状态可以使用命令确认:
# sysctl net.ipv4.tcp_window_scaling
net.ipv4.tcp_window_scaling = 1
TCP窗口缩放协商可以通过捕获打开对话的TCP握手的数据包来查看。 在数据包捕获中,检查三个握手数据包的TCP选项字段。 如果任一系统的握手数据包不包含TCP窗口缩放选项,则可能需要在该系统上启用TCP窗口缩放。
TCP Buffer Tuning
一旦从网络适配器处理网络流量,就尝试直接接收到应用中。 如果不可能,数据在应用程序的套接字缓冲区上排队。 套接字中有3个队列结构
sk_rmem_alloc = { counter = 121948 },
sk_wmem_alloc = { counter = 553 },
sk_omem_alloc = { counter = 0
sk_rmem_alloc是接收队列
sk_wmem_alloc是发送队列
sk_omem_alloc是无序队列,不在当前TCP窗口内的skbs被放置在此队列中
还有sk_rcvbuf变量,它代表scoket可以接受的字节数。
例如:
当sk_rcvbuf = 125336
# netstat -sn | egrep “prune|collap”; sleep 30; netstat -sn | egrep “prune|collap”
17671 packets pruned from receive queue because of socket buffer overrun
18671 packets pruned from receive queue because of socket buffer overrun
如果在此间隔期间数字增加,则需要调整。 第一步是增加网络和TCP接收缓冲区设置。 这是检查应用程序是否调用setsockopt(SO_RCVBUF)的好时机。 如果应用程序调用此函数,这将覆盖默认设置,并关闭套接字自动调整其大小的能力。 接收缓冲区的大小将是应用程序指定的大小。 考虑从应用程序中删除setsockopt(SO_RCVBUF)函数调用,并允许缓冲区大小自动调整。
Tuning tcp_rmem
套接字内存可调参数有三个值,描述最小值,默认值和最大值(以字节为单位)。 大多数Red Hat Enterprise Linux版本的默认最大值为4MiB。 要查看这些设置,请将其增加4倍:
# sysctl net.ipv4.tcp_rmem
4096 87380 4194304
# sysctl -w net.ipv4.tcp_rmem=“16384 349520 16777216”
# sysctl net.core.rmem_max 4194304
# sysctl -w net.core.rmem_max=16777216
如果应用程序无法更改为删除setsockopt(SO_RCVBUF),则增加最大套接字接收缓冲区大小,这可以使用SO_RCVBUF套接字选项设置。 仅当更改tcp_rmem的中间值时,才需要重新启动应用程序。 更改tcp_rmem的第3个和最大值不需要重新启动应用程序,因为这些值是通过自动调整动态分配的。
TCP Listen Backlog
当TCP套接字由处于LISTEN状态的服务器打开时,该套接字具有其可以处理的最大数量的未接受的客户端连接。 如果应用程序在处理客户端连接时速度很慢,或者服务器快速获得许多新连接(通常称为SYN Flood),则新连接可能丢失,或者可能会发送称为“SYN cookie”的特制回复包。 如果系统的正常工作负载使得SYN cookie经常被输入到系统日志中,则应调整系统和应用程序以避免它们。
应用程序可以请求的最大积压由net.core.somaxconn内核可调参数决定。 应用程序可以总是请求更大的积压,但它只会得到一个大到这个最大值的积压。 可以如下检查和更改此参数
# sysctl net.core.somaxconn net.core.somaxconn = 128
# sysctl -w net.core.somaxconn=2048 net.core.somaxconn = 2048
# sysctl net.core.somaxconn net.core.somaxconn = 2048
更改最大允许积压量后,必须重新启动应用程序才能使更改生效。 此外,在更改最大允许积压之后,必须修改应用程序以在其侦听套接字上实际设置较大的积压。 下面是一个在C语言中增加套接字积压所需的更改的示例:
- rc = listen(sockfd, 128);
+ rc = listen(sockfd, 2048);
if (rc < 0) {
perror("listen() failed");
close(sockfd);
exit(-1);
}
上述更改将需要从源代码重新编译应用程序。 如果应用程序设计为积压是一个可配置的参数,这可以在应用程序的设置中更改,并且不需要重新编译。
Advanced Window Scaling
您可能会看到“修剪”错误继续增加,无论上述设置如何。在Red Hat Enterprise Linux 6.3和6.4中,有一个提交被添加到收取skb共享结构到套接字的成本,在内核更新日志中描述为[net]更准确的skb truesize。这种改变具有更快地填充TCP接收队列的效果,因此更快地击中修剪条件。此更改已在Red Hat Enterprise Linux 6.5中恢复。如果接收缓冲区增加并且修剪仍然发生,则参数net.ipv4.tcp_adv_win_scale决定分配给数据的接收缓冲区与被通告为可用TCP窗口的缓冲区的比率。 Red Hat Enterprise Linux 5和6上的默认值为2,等于分配给应用程序数据的缓冲区的四分之一。在RedHat Enterprise Linux 7版本上,此默认值为1,导致一半的空间被通告为TCP窗口。在Red Hat Enterprise Linux 5和6上将此值设置为1将会减少通告的TCP窗口的影响,可能会阻止接收缓冲区溢出,从而阻止缓冲区修剪。
# sysctl net.ipv4.tcp_adv_win_scale 2
# sysctl -w net.ipv4.tcp_adv_win_scale=1
UDP Buffer Tuning
UDP是一个比TCP简单得多的协议。 由于UDP不包含会话可靠性,因此应用程序有责任识别和重新传输丢弃的数据包。 没有窗口大小的概念,并且协议不恢复丢失的数据。 唯一可用的调谐包括增加接收缓冲区大小。 但是,如果netstat -us报告错误,另一个潜在的问题可能会阻止应用程序排空其接收队列。 如果netstat -us显示“数据包接收错误”,请尝试增加接收缓冲区并重新测试。 该统计量还可以由于其他原因而递增,诸如有效载荷数据小于UDP报头建议的短分组或者其校验和计算失败的损坏分组,因此如果缓冲区调谐不需要,则可能需要更深入的调查 解决UDP接收错误。 UDP缓冲区可以以类似于最大TCP缓冲区的方式调整:
# sysctl net.core.rmem_max
124928
# sysctl -w net.core.rmem_max=16777216
更改最大大小后,需要重新启动应用程序以使新设置生效。
RSS: Receive Side Scaling
RSS由许多常见的网络接口卡支持。 在接收数据时,NIC可以将数据发送到多个队列。 每个队列可以由不同的CPU服务,允许有效的数据检索。 RSS充当驱动程序和卡固件之间的API,以确定数据包如何跨CPU核心分布,其想法是将流量引导到不同CPU的多个队列允许更快的吞吐量和更低的延迟。 RSS控制哪些接收队列获得任何给定的分组,无论卡是否侦听特定的单播以太网地址,它侦听的多播地址,哪个队列对或以太网队列获得多播分组的副本等。
RSS Considerations
驱动程序是否允许配置队列数量
某些驱动程序将根据硬件资源自动生成引导期间的队列数。 对于其他,它可以通过ethtool -L进行配置。
•系统有多少个内核应配置RSS,以便每个队列转到不同的CPU内核。
RPS: Receive Packet Steering
接收数据包转向是RSS的内核级软件实现。 它驻留在驱动程序上方的网络堆栈的较高层。 RSS或RPS应该是互斥的。 默认情况下禁用RPS。 RPS使用保存在数据包定义的rxhash字段中的2元组或4元组哈希,用于确定应该处理给定数据包的CPU队列。
RFS: Receive Flow Steering
接收流转向在引导分组时考虑应用局部性。 这避免了当流量到达运行应用程序的不同CPU核心时的高速缓存未命中。

