分布式开源库 介绍
1.有些系统的功能可能重复
比如reids既是KV数据库,也可以是缓存系统,还可以是 消息分发系统
将来考虑再 以什么样的形式 去合并, 使归纳更准确。
2.将来会做个索引,现在 东西太多,导致看的很麻烦
[集群管理]
mesos
Program against your datacenter like it’s a single pool of resources
Apache Mesos abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to easily be built and run effectively.
What is Mesos?
A distributed systems kernel
Mesos is built using the same principles as the Linux kernel, only at a different level of abstraction. The Mesos kernel runs on every machine and provides applications (e.g., Hadoop, Spark, Kafka, Elastic Search) with API’s for resource management and scheduling across entire datacenter and cloud environments.
Mesos Getting Started
Apache Mesos是一个集群管理器,提供了有效的、跨分布式应用或框架的资源隔离和共享,可以运行Hadoop、MPI、Hypertable、Spark。
特性:
- Fault-tolerant replicated master using ZooKeeper
- Scalability to 10,000s of nodes
- Isolation between tasks with Linux Containers
- Multi-resource scheduling (memory and CPU aware)
- Java, Python and C++ APIs for developing new parallel applications
- Web UI for viewing cluster state
书籍
深入浅出Mesos
深入浅出Mesos(一):为软件定义数据中心而生的操作系统
深入浅出Mesos(二):Mesos的体系结构和工作流
深入浅出Mesos(三):持久化存储和容错
深入浅出Mesos(四):Mesos的资源分配
深入浅出Mesos(五):成功的开源社区
深入浅出Mesos(六):亲身体会Apache Mesos
Apple使用Apache Mesos重建Siri后端服务
Singularity:基于Apache Mesos构建的服务部署和作业调度平台
Autodesk基于Mesos的可扩展事件系统
Myriad项目: Mesos和YARN 协同工作
[RPC]
hprose : github
High Performance Remote Object Service Engine
是一款先进的轻量级、跨语言、跨平台、无侵入式、高性能动态远程对象调用引擎库。它不仅简单易用,而且功能强大。构建分布式应用系统。
protocolbuffer
Protocol Buffers - Google's data interchange format
相关网页
https://github.com/google/protobuf
https://developers.google.com/protocol-buffers/
grpc:github
Overview
Remote Procedure Calls (RPCs) provide a useful abstraction for building distributed applications and services. The libraries in this repository provide a concrete implementation of the gRPC protocol, layered over HTTP/2. These libraries enable communication between clients and servers using any combination of the supported languages.
The Go implementation of gRPC: A high performance, open source, general RPC framework that puts mobile and HTTP/2 first. For more information see the gRPC Quick Start guide.
thrift
The Apache Thrift software framework, for scalable cross-language services development,
combines a software stack with a code generation engine
to build services that work efficiently and seamlessly between C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, OCaml and Delphi and other languages.
Document
Tutorial
Thrift 是一个软件框架(远程过程调用框架),用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引 擎,以构建在 C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, and OCaml 这些编程语言间无缝结合的、高效的服务。
thrift最初由facebook开发,07年四月开放源码,08年5月进入apache孵化器,现在是 Apache 基金会的顶级项目
thrift允许你定义一个简单的定义文件中的数据类型和服务接口,以作为输入文件,编译器生成代码用来方便地生成RPC客户端和服务器通信的无缝跨编程语言。。
著名的 Key-Value 存储服务器 Cassandra 就是使用 Thrift 作为其客户端API的。
[messaging systems分布式消息]
Kafka
Apache Kafka is publish-subscribe messaging rethought(rethink 过去式和过去分词)as a distributed commit log.
- Fast
A single Kafka broker can handle hundreds of megabytes of reads and writes per second from thousands of clients.
- Scalable
Kafka is designed to allow a single cluster to serve as the central data backbone for a large organization.
It can be elastically and transparently expanded without downtime.
Data streams are partitioned and spread over a cluster of machines to allow data streams larger than
the capability of any single machine and to allow clusters of co-ordinated consumers
- Durable
Messages are persisted on disk and replicated within the cluster to prevent data loss. Each broker can handle terabytes of messages without performance impact.
- Distributed by Design
Kafka has a modern cluster-centric design that offers strong durability and fault-tolerance guarantees.
kafka是一种高吞吐量的分布式发布订阅消息系统,特性如下:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
- 支持通过kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
kafka的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数据。
这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。
这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。
kafka的目的是通过Hadoop的并行加载机 制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
NATS
NATS is an open-source, high-performance, lightweight cloud native messaging system
gnatsd Github:A High Performance NATS Server written in Go.
cnats Github:A C client for the NATS messaging system.
NATS Github:Golang client for NATS, the cloud native messaging system
Cloud Native Infrastructure(基础建设,基础设施). Open Source. Performant(高性能). Simple. Scalable.
NATS acts as a central nervous system for distributed systems at scale, such as mobile devices, IoT networks,
and cloud native infrastructure. **Written in Go**,
NATS powers some of the largest cloud platforms in production today.
Unlike traditional enterprise messaging systems,
NATS has an always-on dial tone that does whatever it takes to remain available.
NATS was created by Derek Collison,
Founder/CEO of Apcera who has spent 20+ years designing, building,
and using publish-subscribe messaging systems.
documentation
NATS is a Docker Official Image
NATS is the most Performant Cloud Native messaging platform available
With gnatsd (Golang-based server), NATS can send up to 6 MILLION MESSAGES PER SECOND.
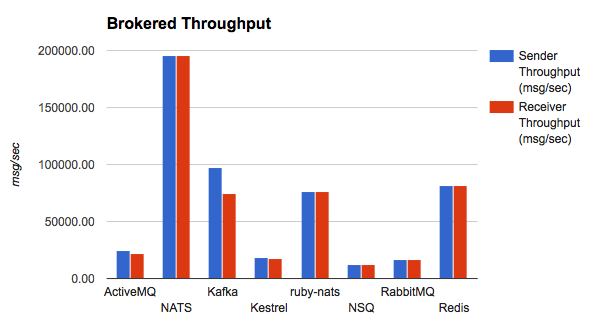
[缓存服务器,代理服务器,负载均衡]
memcached
memcached 是高性能的分布式内存缓存服务器。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态 Web 应用的速度、提高可扩展性。
What is Memcached?
Free & open source, high-performance, distributed memory object caching system, generic in nature, but intended for use in speeding up dynamic web applications by alleviating database load.
Memcached is an in-memory key-value store for small chunks of arbitrary data (strings, objects) from results of database calls, API calls, or page rendering.
Memcached is simple yet powerful. Its simple design promotes quick deployment, ease of development, and solves many problems facing large data caches. Its API is available for most popular languages.
nginx
nginx [engine x] is an HTTP and reverse proxy server, a mail proxy server, and a generic TCP proxy server, originally written by Igor Sysoev. For a long time, it has been running on many heavily loaded Russian sites including Yandex, Mail.Ru, VK, and Rambler. According to Netcraft, nginx served or proxied 23.36% busiest sites in September 2015. Here are some of the success stories: Netflix, Wordpress.com, FastMail.FM.
The sources and documentation are distributed under the 2-clause BSD-like license.
Document
Now with support for HTTP/2, massive performance and security enhancements,
greater visibility into application health, and more.
redis
Redis is an open source (BSD licensed), in-memory data structure store, used as database, cache and message broker(代理人,经纪人).
It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs and geospatial indexes with radius queries.
Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
try redis
[分布式并行计算框架]
mapreduce
MapReduce is a programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster.
Conceptually similar approaches have been very well known since 1995 with the Message Passing Interface standard having reduce and scatter operations.
相关web
https://en.wikipedia.org/wiki/MapReduce
http://www-01.ibm.com/software/data/infosphere/hadoop/mapreduce/
About MapReduce
MapReduce is the heart of Hadoop®. It is this programming paradigm that allows for massive scalability across
hundreds or thousands of servers in a Hadoop cluster.
The MapReduce concept is fairly simple to understand for those who are familiar with clustered scale-out data
processing solutions.
For people new to this topic, it can be somewhat difficult to grasp, because it’s not typically something people have been exposed to previously.
If you’re new to Hadoop’s MapReduce jobs, don’t worry: we’re going to describe it in a way that gets you up
to speed quickly.
The term MapReduce actually refers to two separate and distinct tasks that Hadoop programs perform.
The first is the map job, which takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs).
The reduce job takes the output from a map as input and combines those data tuples into a smaller set of tuples.
As the sequence of the name MapReduce implies, the reduce job is always performed after the map job.
MapReduce Tutorial
spark
Apache Spark™ is a fast and general engine for large-scale data processing.
Document
Programming Guides:
- Quick Start:
a quick introduction to the Spark API; start here! - Spark Programming Guide:
detailed overview of Spark in all supported languages (Scala, Java, Python, R)
Deployment Guides:
- Cluster Overview:
overview of concepts and components when running on a cluster - Submitting Applications:
packaging and deploying applications - Deployment modes:
- Amazon EC2: scripts that let you launch a cluster on EC2 in about 5 minutes
- Standalone Deploy Mode: launch a standalone cluster quickly without a third-party cluster manager
- Mesos: deploy a private cluster using Apache Mesos
- YARN: deploy Spark on top of Hadoop NextGen (YARN)
storm
Why use Storm?
Apache Storm is a free and open source distributed realtime computation system. Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Storm is simple, can be used with any programming language, and is a lot of fun to use!
Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
Storm integrates with the queueing and database technologies you already use. A Storm topology consumes streams of data and processes those streams in arbitrarily complex ways, repartitioning the streams between each stage of the computation however needed. Read more in the tutorial.
Document
Storm (event processor)
Apache Storm is a distributed computation framework written predominantly in the Clojure programming language. Originally created by Nathan Marz[1] and team at BackType,[2] the project was open sourced after being acquired by Twitter.[3] It uses custom created "spouts" and "bolts" to define information sources and manipulations to allow batch, distributed processing of streaming data. The initial release was on 17 September 2011.[4]
A Storm application is designed as a "topology" in the shape of a directed acyclic graph (DAG) with spouts and bolts acting as the graph vertices. Edges on the graph are named streams and direct data from one node to another. Together, the topology acts as a data transformation pipeline. At a superficial level the general topology structure is similar to a MapReduce job, with the main difference being that data is processed in real-time as opposed to in individual batches. Additionally, Storm topologies run indefinitely until killed, while a MapReduce job DAG must eventually end.[5]
Storm became an Apache Top-Level Project in September 2014[6] and was previously in incubation since September 2013.[7][8]
《Storm Applied》书籍
Storm是一个分布式、容错的实时计算系统,最初由BackType开发,后来Twitter收购BackType后将其 开源
hadoop
- hadoop是开源的、可靠、可扩展、 分布式并行计算框架
- 主要组成:分布式文件系统 HDFS 和 MapReduce 算法执行
What Is Apache Hadoop?
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
The project includes these modules:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
Other Hadoop-related projects at Apache include:
- Ambari™: A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster health such as heatmaps and ability to view MapReduce, Pig and Hive applications visually alongwith features to diagnose their performance characteristics in a user-friendly manner.
- Avro™: A data serialization system.
- Cassandra™: A scalable multi-master database with no single points of failure.
- Chukwa™: A data collection system for managing large distributed systems.
- HBase™: A scalable, distributed database that supports structured data storage for large tables.
- Hive™: A data warehouse infrastructure(基础设施)that provides data summarization(概要) and ad hoc querying.
Ad Hoc Query:是指用户根据当时的需求而即刻定义的查询。是一种条件不固定、格式灵活的查询报表,可以提供给用户更多的交互方式。
Hive是基于Hadoop的数据仓库解决方案。由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性。
简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
- Mahout™: A Scalable machine learning and data mining library.
- Pig™: A high-level data-flow language and execution framework for parallel computation.
- Spark™: A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation.
- Tez™: A generalized data-flow programming framework, built on Hadoop YARN, which provides a powerful and flexible engine to execute an arbitrary DAG of tasks to process data for both batch and interactive use-cases. Tez is being adopted by Hive™, Pig™ and other frameworks in the Hadoop ecosystem, and also by other commercial software (e.g. ETL tools), to replace Hadoop™ MapReduce as the underlying execution engine.
- ZooKeeper™: A high-performance coordination service for distributed applications.
##### [Getting Started]
##### [Learn about Hadoop by reading the documentation.](http://hadoop.apache.org/docs/current/)
```c
简而言之,Hadoop 提供了一个稳定的共享存储和分析系统。存储由 HDFS 实现,分析由 MapReduce 实现。纵然 Hadoop 还有其他功能,但这些功能是它的核心所在。
1.3.1 关系型数据库管理系统
为什么我们不能使用数据库加上更多磁盘来做大规模的批量分析?为什么我们需要MapReduce?
这个问题的答案来自于磁盘驱动器的另一个发展趋势:寻址时间的提高速度远远慢于传输速率的提高速度。寻址就是将磁头移动到特定位置进行读写操作的工序。它的特点是磁盘操作有延迟,而传输速率对应于磁盘的带宽。
如果数据的访问模式受限于磁盘的寻址,势必会导致它花更长时间(相较于流)来读或写大部分数据。
另一方面,在更新一小部分数据库记录的时候,传统的 B 树(关系型数据库中使用的一种数据结构,受限于执行查找的速度)效果很好。
但在更新大部分数据库数据的时候,B 树的效率就没有 MapReduce 的效率高,因为它需要使用排序/合并来重建数据库。
在许多情况下,MapReduce 能够被视为一种 RDBMS(关系型数据库管理系统)的补充。(两个系统之间的差异见表 1-1)。
MapReduce 很适合处理那些需要分析整个数据集的问题,以批处理的方式,尤其是 Ad Hoc(自主或即时)分析。
RDBMS 适用于点查询和更新(其中,数据集已经被索引以提供低延迟的检索和短时间的少量数据更新。
MapReduce适合数据被一次写入和多次读取的应用,而关系型数据库更适合持续更新的数据集。
表 1-1:关系型数据库和 MapReduce 的比较
| 传统关系型数据库 | MapReduce | |
|---|---|---|
| 数据大小 | GB | PB |
| 访问 | 交互型和批处理 | 批处理 |
| 更新 | 多次读写 | 一次写入多次读取 |
| 结构 | 静态模式 | 动态模式 |
| 集成度 | 高 | 低 |
| 伸缩性 | 非线性 | 线性 |
MapReduce 和关系型数据库之间的另一个区别是它们操作的数据集中的结构化数据的数量。结构化数据是拥有准确定义的实体化数据,具有诸如 XML 文档或数据库表定义的格式,符合特定的预定义模式。这就是 RDBMS 包括的内容。
另一方面,半结构化数据比较宽松,虽然可能有模式,但经常被忽略,所以它只能用作数据结构指南。例如,一张电子表格,其中的结构便是单元格组成的网格,尽管其本身可能保存任何形式的数据。
非结构化数据没有什么特别的内部结构,例如纯文本或图像数据。MapReduce 对于非结构化或半结构化数据非常有效,因为它被设计为在处理时间内解释数据。
换句话说:MapReduce 输入的键和值并不是数据固有的属性,它们是由分析数据的人来选择的。
关系型数据往往是规范的,以保持其完整性和删除冗余。规范化为 MapReduce 带来问题,因为它使读取记录成为一个非本地操作,并且 MapReduce 的核心假设之一就是,它可以进行(高速)流的读写。
MapReduce 是一种线性的可伸缩的编程模型。程序员编写两个函数 map()和Reduce()每一个都定义一个键/值对集映射到另一个。
这些函数无视数据的大小或者它们正在使用的集群的特性,这样它们就可以原封不动地应用到小规模数据集或者大的数据集上。
更重要的是,如果放入两倍的数据量,运行的时间会少于两倍。但是如果是两倍大小的集群,一个任务仍然只是和原来的一样快。这不是一般的 SQL 查询的效果。
随着时间的推移,关系型数据库和 MapReduce 之间的差异很可能变得模糊。关系型数据库都开始吸收 MapReduce 的一些思路(如 ASTER DATA 的和 GreenPlum 的数据库),
另一方面,基于 MapReduce 的高级查询语言(如 Pig 和 Hive)使 MapReduce 的系统更接近传统的数据库编程人员。
[NoSQL数据库 + KeyValue数据库]
ScyllaDB
NoSQL data store using the seastar framework, compatible with Apache Cassandra
http://scylladb.com
http://blog.jobbole.com/93027/
ScyllaDB:用 C++ 重写后的 Cassandra ,性能提高了十倍
最核心的两项技术: Intel的DPDK驱动框架和Seastar网络框架
cassandra
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. Cassandra's support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
Cassandra's data model offers the convenience of column indexes with the performance of log-structured updates, strong support for denormalization and materialized views, and powerful built-in caching.
GettingStarted
About Apache Cassandra
This guide provides information for developers and administrators on installing, configuring, and using the features and capabilities of Cassandra.
What is Apache Cassandra?
Apache Cassandra™ is a massively scalable open source NoSQL database. Cassandra is perfect for managing large amounts of structured, semi-structured, and unstructured data across multiple data centers and the cloud. Cassandra delivers continuous availability, linear scalability, and operational simplicity across many commodity servers with no single point of failure, along with a powerful dynamic data model designed for maximum flexibility and fast response times.
How does Cassandra work?
Cassandra’s built-for-scale architecture means that it is capable of handling petabytes of information and thousands of concurrent users/operations per second.
http://www.ibm.com/developerworks/cn/opensource/os-cn-cassandra/index.html
Apache Cassandra 是一套开源分布式 Key-Value 存储系统。它最初由 Facebook 开发,用于储存特别大的数据。 Cassandra 不是一个数据库,它是一个混合型的非关系的数据库,类似于 Google 的 BigTable。
本文主要从以下五个方面来介绍 Cassandra:Cassandra 的数据模型、安装和配制 Cassandra、常用编程语言使用 Cassandra 来存储数据、Cassandra 集群搭建。
http://docs.datastax.com/en/cassandra/2.0/cassandra/gettingStartedCassandraIntro.html
etcd
etcd是一个用于配置共享和服务发现的高性能的键值存储系统。
A highly-available key value store for shared configuration and service discovery
Overview
etcd is a distributed key value store that provides a reliable way to store data across a cluster of machines. It’s open-source and available on GitHub. etcd gracefully handles master elections during network partitions and will tolerate machine failure, including the master.
Your applications can read and write data into etcd. A simple use-case is to store database connection details or feature flags in etcd as key value pairs. These values can be watched, allowing your app to reconfigure itself when they change.
Advanced uses take advantage of the consistency guarantees to implement database master elections or do distributed locking across a cluster of workers.
Getting Started with etcd
ceph
Ceph is a distributed object store and file system designed to provide excellent performance, reliability and scalability.
- Object Storage
Ceph provides seamless access to objects using native language bindings or radosgw, a REST interface that’s compatible with applications written for S3 and Swift.
- Block Storage
Ceph’s RADOS Block Device (RBD) provides access to block device images that are striped and replicated across the entire storage cluster.
- File System
Ceph provides a POSIX-compliant network file system that aims for high performance, large data storage, and maximum compatibility with legacy applications.
#### [Document](http://docs.ceph.com/docs/v0.80.5/)
Ceph uniquely delivers object, block, and file storage in one unified system.
#### [Intro to Ceph](http://docs.ceph.com/docs/v0.80.5/start/intro/)
Whether you want to provide Ceph Object Storage and/or Ceph Block Device services to Cloud Platforms,
deploy a Ceph Filesystem or use Ceph for another purpose,all Ceph Storage Cluster deployments begin with setting up each Ceph Node, your network and the Ceph Storage Cluster.
A Ceph Storage Cluster requires at least one Ceph Monitor and at least two Ceph OSD Daemons.
The Ceph Metadata Server is essential when running Ceph Filesystem clients.
Ceph的主要目标是设计成基于POSIX的没有单点故障的分布式文件系统,使数据能容错和无缝的复制。2010年3 月,Linus Torvalds将Ceph client合并到内 核2.6.34中。IBM开发者园地的一篇文章 探讨了Ceph的架构,它的容错实现和简化海量数据管理的功能。
[网络框架]
seastar
High performance server-side application framework(c++开发),是[scylla](https://github.com/scylladb/scylla)的网络框架
SeaStar is an event-driven framework allowing you to write non-blocking, asynchronous code in a relatively straightforward manner (once understood). It is based on futures.
POCO : github
POCO C++ Libraries-Cross-platform C++ libraries with a network/internet focus.
POrtable COmponents C++ Libraries are:
- A collection of C++ class libraries, conceptually similar to the Java Class Library, the .NET Framework or Apple’s Cocoa.
- Focused on solutions to frequently-encountered practical problems.
- Focused on ‘internet-age’ network-centric applications.
- Written in efficient, modern, 100% ANSI/ISO Standard C++.
- Based on and complementing the C++ Standard Library/STL.
- Highly portable and available on many different platforms.
- Open Source, licensed under the Boost Software License.
对于c++11 STL支持线程 + string支持UTF8, 跨平台已经不是梦了。我看好这个。
[分布式文件系统 + 存储 ]
hbase
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store
When Would I Use Apache HBase?
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
ceph
Ceph is a scalable distributed storage system
Ceph is a distributed object, block, and file storage platform
Ceph的主要目标是设计成基于POSIX的没有单点故障的分布式文件系统,使数据能容错和无缝的复制。
2010年3 月,Linus Torvalds将Ceph client合并到内 核2.6.34中。
IBM开发者园地的一篇文章 探讨了Ceph的架构,它的容错实现和简化海量数据管理的功能。
gcsfuse
A user-space file system for interacting with Google Cloud Storage。
使用 Go 编写,基于 [Google Cloud Storage](https://cloud.google.com/storage/) 接口的 File系统。
目前是beta版本,可能有潜伏bug,接口修改 不向下兼容。
[Seafile]( windows.location #Seafile)
使用 c 编写, 云存储平台
Seafile is an open source cloud storage system with features on privacy protection and teamwork.
Goofys
Goofys 是使用 Go 编写,基于 [S3](https://aws.amazon.com/s3/) 接口的 Filey 系统。
Goofys 允许你挂载一个 s3 bucket 作为一个 Filey 系统。为什么是 Filey 系统而不是 File 系统?因为 goofys 优先考虑性能而不是 POSIX
[其他]
HDFS和KFS 比较
两者都是GFS的开源实现,而HDFS 是Hadoop 的子项目,用Java实现,为Hadoop上层应用提供高吞吐量的可扩展的大文件存储服务。
Kosmos filesystem(KFS) is a high performance distributed filesystem for web-scale applications such as,
storing log data, Map/Reduce data etc.
It builds upon ideas from Google‘s well known Google Filesystem project. 用C++实现
TFS : 淘宝自己都不用了,2011年就停止更新了
FastDFS is an open source high performance distributed file system (DFS).
It's major functions include: file storing, file syncing and file accessing, and design for high capacity and load balance.
FastDFS是一款类Google FS的开源分布式文件系统,它用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。
它只能通过专有API对文件进行存取访问,不支持POSIX接口方式,不能mount使用。
准确地讲,Google FS以及FastDFS、mogileFS、HDFS、TFS等类Google FS都不是系统级的分布式文件系统,
而是应用级的分布式文件存储服务。
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,
功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。
特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
gcsfuse
gcsfuse is a user-space file system for interacting with Google Cloud Storage.
GCS Fuse
GCS Fuse is an open source Fuse adapter that allows you to **mount Google Cloud Storage buckets as file systems on Linux or OS X systems**.
GCS Fuse can be run anywhere with connectivity to Google Cloud Storage (GCS) including Google Compute Engine VMs or on-premises systems.
GCS Fuse provides another means to access Google Cloud Storage objects in addition to the XML API,
JSON API, and the gsutil command line,
allowing even more applications to use Google Cloud Storage and take advantage of its immense scale, high availability, rock-solid durability,
exemplary performance, and low overall cost. GCS Fuse is a Google-developed and community-supported open-source tool, written in Go and hosted on GitHub.
GCS Fuse is open-source software, released under the Apache License.
It is distributed as-is, without warranties or conditions of any kind.
Best effort community support is available on Server Fault with the google-cloud-platform and gcsfuse tags.
Check the previous questions and answers to see if your issue is already answered. For bugs and feature requests, file an issue.
Technical Overview
GCS Fuse works by translating object storage names into a file and directory system, interpreting the “/” character in object names as a directory separator so that objects with the same common prefix are treated as files in the same directory. Applications can interact with the mounted bucket like any other file system, providing virtually limitless file storage running in the cloud, but accessed through a traditional POSIX interface.
While GCS Fuse has a file system interface, it is not like an NFS or CIFS file system on the backend.
GCS Fuse retains the same fundamental characteristics of Google Cloud Storage, preserving the scalability of Google Cloud Storage in terms of size and aggregate performance while maintaining the same latency and single object performance. As with the other access methods, Google Cloud Storage does not support concurrency and locking. For example, if multiple GCS Fuse clients are writing to the same file, the last flush wins.
For more information about using GCS Fuse or to file an issue, go to the Google Cloud Platform GitHub repository.
In the repository, we recommend you review README, semantics, installing, and mounting.
When to use GCS Fuse
GCS Fuse is a utility that helps you make better and quicker use of Google Cloud Storage by allowing file-based applications to use Google Cloud Storage without need for rewriting their I/O code. It is ideal for use cases where Google Cloud Storage has the right performance and scalability characteristics for an application and only the POSIX semantics are missing.
For example, GCS Fuse will work well for genomics and biotech applications, some media/visual effects/rendering applications, financial services modeling applications, web serving content, FTP backends, and applications storing log files (presuming they do not flush too frequently).
support
GCS Fuse is supported in Linux kernel version 3.10 and newer. To check your kernel version, you can use uname -a.
Current status
Please treat gcsfuse as beta-quality software. Use it for whatever you like, but be aware that bugs may lurk(潜伏), and that we reserve(保留)the right to make small backwards-incompatible changes.(保留权力 做不向后兼容的修改)
The careful user should be sure to read semantics.md for information on how gcsfuse maps file system operations to GCS operations, and especially on surprising behaviors. The list of open issues may also be of interest.
Goofys
Goofys is a Filey-System interface to [S3](https://aws.amazon.com/s3/)
Overview
Goofys allows you to mount an S3 bucket as a filey system.
It's a Filey System instead of a File System because goofys strives for performance first and POSIX second. Particularly things that are difficult to support on S3 or would translate into more than one round-trip would either fail (random writes) or faked (no per-file permission). Goofys does not have a on disk data cache, and consistency model is close-to-open.
Seafile : github
Seafile is an open source cloud storage system with features on privacy protection and teamwork. Collections of files are called libraries, and each library can be synced separately. A library can also be encrypted with a user chosen password. Seafile also allows users to create groups and easily sharing files into groups.
Introduction Build Status
Seafile is an open source cloud storage system with features on privacy protection and teamwork. Collections of files are called libraries, and each library can be synced separately. A library can also be encrypted with a user chosen password. Seafile also allows users to create groups and easily sharing files into groups.
Feature Summary
Seafile has the following features:
File syncing
- Selective synchronization of file libraries. Each library can be synced separately.
Correct handling of file conflicts based on history instead of timestamp. - Only transfering contents not in the server, and incomplete transfers can be resumed.
- Sync with two or more servers.
- Sync with existing folders.
- Sync a sub-folder.
File sharing and collaboration
- Sharing libraries between users or into groups.
- Sharing sub-folders between users or into groups.
- Download links with password protection
- Upload links
- Version control with configurable revision number.
- Restoring deleted files from trash, history or snapshots.
Privacy protection
- Library encryption with a user chosen password.
- Client side encryption when using the desktop syncing.
Internal
Seafile's version control model is based on Git, but it is simplified for automatic synchronization does not need Git installed to run Seafile. Each Seafile library behaves like a Git repository. It has its own unique history, which consists of a list of commits. A commit points to the root of a file system snapshot. The snapshot consists of directories and files. Files are further divided into blocks for more efficient network transfer and storage usage.
Differences from Git:
- Automatic synchronization.
- Clients do not store file history, thus they avoid the overhead of storing data twice. Git is not efficient for larger files such as images.
- Files are further divided into blocks for more efficient network transfer and storage usage.
- File transfer can be paused and resumed.
- Support for different storage backends on the server side.
- Support for downloading from multiple block servers to accelerate file transfer.
- More user-friendly file conflict handling. (Seafile adds the user's name as a suffix to conflicting files.)
- Graceful handling of files the user modifies while auto-sync is running. Git is not designed to work in these cases.
《流式大数据处理的三种框架:Storm,Spark和Samza》
许多分布式计算系统都可以实时或接近实时地处理大数据流。
本文将对三种Apache框架分别进行简单介绍,然后尝试快速、高度概述其异同。
Cloudera 将发布新的开源储存引擎 Kudu ,大数据公司 Cloudera 正在开发一个大型的开源储存引擎 Kudu,用于储存和服务大量不同类型的非结构化数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号