python魔法方法-比较相关
在python2.x的版本中,支持不同类型的比较,其比较原则如下:
内置类型:
1.同一类型:
1.1)数字类型:包含int、float、long、complex、bool(bool类型是int的子类,且True=1, False=0)。就按照数字的大小进行比较,例如:

1.2)非数字类型:
1.2.1)如果类型中定义了如__cmp__、__gt__等魔法方法,就按照其魔法方法的返回值进行比较,具体如何就是这篇文章接下来要讨论的内容。
1.2.2)如果没有定义上述的魔法方法,就按照 id 函数的返回值进行比较,由于 id 函数返回的是 int,所以返回值按照数字的规则进行比较。
2.不同类型:
2.1)如果比较的对象中含有数字类型,例如:int 和 str 进行比较。数字类型将小于其他任何类型,也就是说“数字类型是最小的”(不包括None,None比数字类型还小,所以应该说是None最小,但很少会使用None类型比较,所以这里忽略None,得出数字类型最小的结论)。
2.2)如果比较的对象中不含有数字类型,例如 dict 和 str 进行比较。那么就按类名进行比较,所以 {} < '' 相当于 'dict' < 'str' ,即将类名转换为字符串,然后按字符串的原则进行比较。

这里有几点要补充的:
虽然内置类型基本都实现了__eq__、__ge__、__gt__等内置方法,但是这里有必要对相同类型实例直接的比较进行总结说明:
1.序列的比较:
序列的比较是按照索引顺序取出元素进行比较,如果不两个系列不等长,则可以看作是在短的序列后面填充 None ,直到两个序列等长。
在 tuple 和 list 的讨论中,我使用了打擂台的比喻。两个比较的序列相当于按照索引顺序派出选手,比赛采用的是残酷的赛制,一旦某个选手失败,那么那个队伍就会输掉。也就是说一旦某个元素小于对面,那么整个序列都会小于另一个序列。
当然这里说的是同一类型的序列,例如 str、list、tuple之间的比较是属于不同内置类型的比较,按照上面的原则,就是按照类名进行比较。所以这里讨论的是 str和 str 的比较;list 和 list 的比较;tuple 和 tuple的比较。
str 和 str 之间的比较:首先按照序列顺序排出元素,而 str 中的元素就是单个字符,然后字符之间的比较是通过将其转换为 acsll 码后进行数字之间的比较的。python 中提供了一个内置的函数 ord 来进行这项工作:

还有一个反函数 chr 用来将数字转换成字符:

所以,当字符串 'abc' 和字符串 'abe' 进行比较时,前两个字符相等,而 'e' > 'c' ,所以 'abe' > 'abc'。
如果两者不等长时,例如:'abc' 和 'ab' 进行比较,前两字符相等,而 'c' 相对于和 None 比,None又最小,所以 'abc' > 'ab' 。
其他序列也遵循这个逐项比较的原则,例如:[1, 2, 3] 和 [1, [2], 3] 比较时,第一个元素相等,所以比第二个元素。第二元素是不同类型的,其中一个是数字,数字除None外最小,所以第二个列表比较大。如果一直比较下去都相等的话,那么就判断两个元素相等(== )。但是这并不意味着两个元素是同一个对象,所以 is 判断不一定为 True。
另外,中文是按照编码的字符串进行比较的,例如:

'd' > 'b' 所以 '一' > '二'。但字符串的编码是会根据编码声明而改变的,例如 # coding: utf-8 和 # coding= gbk 的字符串编码就不一样,所以比较会有差异性。但是也很少会进行中文之间的比较。
集合和序列的比较方法类似。
2.字典间的比较:
字典其实也类似于序列,也是逐个比较,但字典比较的是键不是值,而且字典是无序的,所以比较的顺序难以预测,所以无论如何,不建议字典间的比较。
版本差异:
由于不同内置类型之间的比较不符合人的直觉,而且行为怪异,难以估计。所以python3.x中取消了不同内置类型之间比较的支持,例如:在python3.x中进行 int 和 str 之间的比较时会直接抛出异常。
自定义的类:
1.继承自基本类型且没有重写相关的魔法方法,那么就按照上面内置类型的原则进行比较。
2.自定义的类,但没有重写相关魔法方法。那么 新式类 > 经典类;新式类之间按类名进行比较;经典类之间按 id 函数的返回值进行比较。
3.只要重写了相应的魔法方法,那么就按照魔法方法的返回值作为结果。不管是否继承自基本类型。
相关魔法方法:
__cmp__(self, other) :对应于python的内置函数 cmp ,在self > other 时应该返回 正整数;self == other时,返回 0;当self < other时应该返回一个 负整数。(这个方法因为和下面的方法存在冗余,所以在python3.x中被删除了。)
例子:
class Foo(str): def __new__(cls, word): return str.__new__(cls, word) def __cmp__(self, other): if ('scolia' in self) and ('scolia' in other): return 0 elif 'scolia' in self: return 1 else: return -1 a = Foo('scolia') b = Foo('scolia123') c = Foo('good') d = Foo('Good') print cmp(a, b) print cmp(b, c) print cmp(c, d)

在这个例子中,我定义凡是两个字符串中都有子串'scolia'的,都返回0;当个只有一个有,且有的那个作为第一个参数时,返回1;两个都没有,不管是什么都返回-1。
也就是说cmp函数的第一个参数就是 self ,第二个参数就是 other。
当然 cmp 还有一个隐藏特性, 当两个参数为同一对象的时候,直接返回0而不管内部的__cmp__逻辑如果,例如:
c = Foo('good') d = c print cmp(c, d)
本来按照自己写的代码的逻辑的话,c 和 d 都不含字串 'scolia' ,应该返回-1才对,但是实际上得到的却是0。说明cmp函数对于同一对象是直接给出结果而不理魔法方法的。
-
__eq__(self, other)
-
定义相等符号的行为,==
-
__ne__(self,other)
-
定义不等符号的行为,!=
-
__lt__(self,other)
-
定义小于符号的行为,<
-
__gt__(self,other)
-
定义大于符号的行为,>
-
__le__(self,other)
-
定义小于等于符号的行为,<=
-
__ge__(self,other)
-
定义大于等于符号的行为,>=
以上魔法方法都必须返回一个布尔值。
例如:
class Foo(str): def __new__(cls, word): return str.__new__(cls, word) def __eq__(self, other): if ('scolia' in self ) and ('scolia' in other): return True else: return False a = Foo('scolia') b = Foo('scolia123') print a == b

所以,这些魔法方法其实就是重载了相应的符号而已,例如这里的 == ,左边的相当于 self,右边的相当于 other。你可以根据自己的需要进行逻辑编排。
又例如:
class Foo(str): def __new__(cls, word): return str.__new__(cls, word) def __gt__(self, other): return len(self) > len(other) def __lt__(self, other): return len(self) < len(other) def __ge__(self, other): return len(self) >= len(other) def __le__(self, other): return len(self) <= len(other)
这里重载了多个比较符,是核心是按照字符串的长度进行比较,越长的越大。这里看似返回的是一个表达式,但是函数在真正返回的时候会将这个表达式计算出来,也就是说最终返回的其实还是布尔值。
而没有重载的比较符,如这里没有重载 __eq__ 即 == ,将自动调用其父类的方法,这也很符合我们继承的概念。
如果和基本类型比较呢:
class Foo(str): def __new__(cls, word): return str.__new__(cls, word) def __eq__(self, other): if ('scolia' in self ) and ('scolia' in other): return True else: return False b = Foo('scolia') a = 'scolia123' print a == b print b == a

貌似是以我们自己写的方法为准,不管 == 两边的顺序如何。
如果两个自定义的类冲突呢:
class Foo(str): def __new__(cls, word): return str.__new__(cls, word) def __eq__(self, other): if ('scolia' in self ) and ('scolia' in other): return True else: return False class Boo(str): def __new__(cls, word): return str.__new__(cls, word) def __eq__(self, other): if ('scolia' in self ) and ('scolia' in other): return False else: return True a = Foo('scolia') b = Boo('scolia') print a == b print b == a
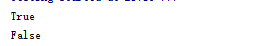
此时,谁在 == 号的左边,就运用谁的规则。
关于比较的魔法方法就讨论到这里,欢迎大家交流。
相关的参考资料:戳这里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号