
python爬虫——分析天猫iphonX的销售数据
01.引言
这篇文章是我最近刚做的一个项目,会带领大家使用多种技术实现一个非常有趣的项目,该项目是关于苹果机(iphoneX)的销售数据分析,是网络爬虫和数据分析的综合应用项目。本项目会分别从天猫和京东抓取iphoneX的销售数据(利用 Chrome 工具跟踪 Web 数据),并将这些数据保存到 Mysql 数据库中,然后对数据进行清洗,最后通过 SQL 语句、Pandas 和 Matplotlib 对数据进行数据可视化分析。我们从分析结果中可以得出很多有趣的结果,例如,大家最爱买的颜色是,最喜欢的是多少G内存的iphoneX等等,当然本文介绍的只是一个小的应用,时间够的话如果大家刚兴趣可以进一步进行推广。
废话不多说,马上开始。
02.分析
首先从马云粑粑的天猫“取“点数据,取数据的第一步即使要分析一下 Web 页面中数据是如何来的。也就是说数据,数据是通过何种方式发送到客户端浏览器的。天猫和京东的数据基本上没采用什么有意义的反爬技术,所以抓取数据相对比较容易(针对于复杂的后期会介绍抓包工具以及Scrapy框架自动爬取的方式)。
进到天猫苹果的官方旗舰店后,开始使用 Chrome 浏览器或者火狐都可以,他们都有很方便的调试工具。开始搜索”iphoneX“关键字,然后页面就会弹出iphoneX的商品详情页,浏览商品页面,在页面的右键菜单中点击“检查”菜单项,打开调试窗口,切换到“Network”选项卡,这个选项卡可以实时显示出当前页面向服务端发送的所有请求,以及这些请求的请求头、响应头、响应内容以及其他与调试有关的信息。对于调试和跟踪 Web 应用相当方便。
打开“Network”选项卡后,进到商品评论处,切换到下一页,会看到“Network”选项卡下方出现很多 URL,这就是切换评论页时向服务端新发出的请求。我们要找的东西就在这些 URL 中。至于如何找到具体的 URL,那就要依靠经验了。可以一个一个点击寻找(在右侧的“Preview”选项卡中显示 URL 的响应内容),也可以根据 URL 名判断,一般程序员不会起无意义的名字,这样很不好维护。这里我们找到一个”list_detail_rate.htm?“的URL,点开后,我们发现如图1所示,ratelist中的信息正是一条条的评论信息,所以也正是我们需要的Url。
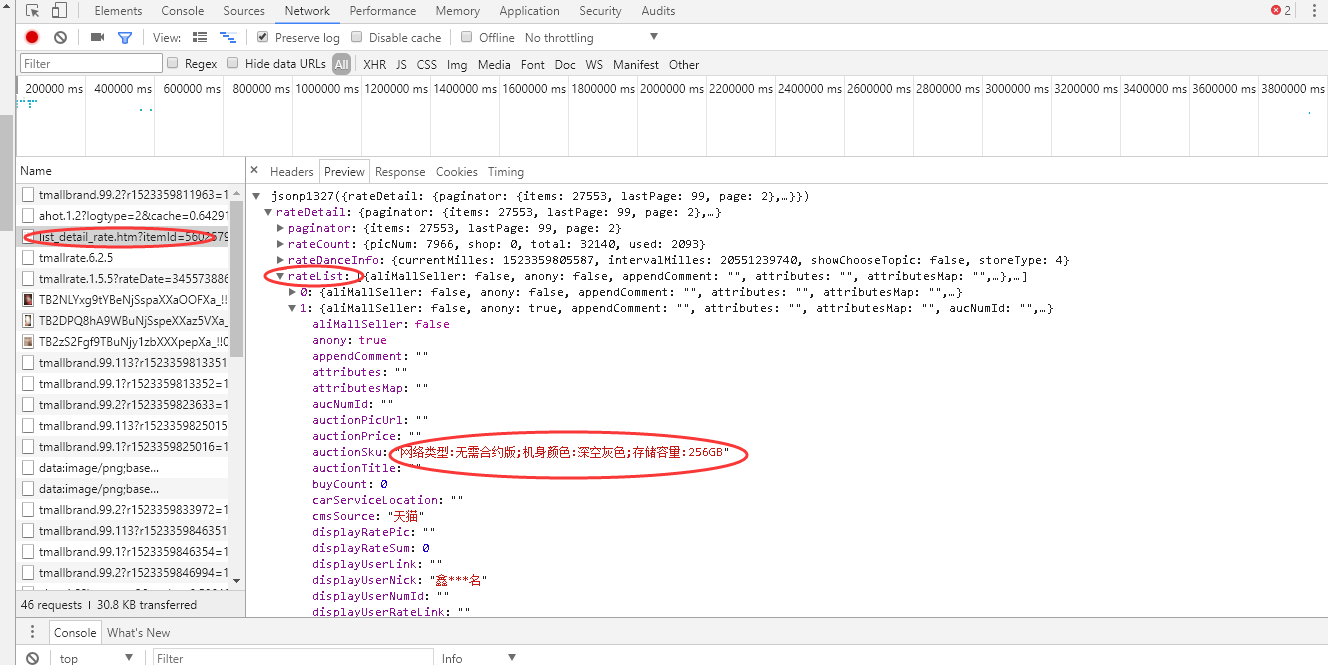
然后右键选中左边”list_detail_rate.htm?“选择保存URL地址,然后用浏览器打开,可以看到如图2所示的内容。

这个 URL 就是iphoneX的某一页的评论(销售)数据,如果要查询所有的评论数据,就需要动态改变 URL 的参数。下面看一下“Headers”选项卡下面的“Query String Parameters”部分,如图3所示,会清楚地了解该 URL 的具体参数值。
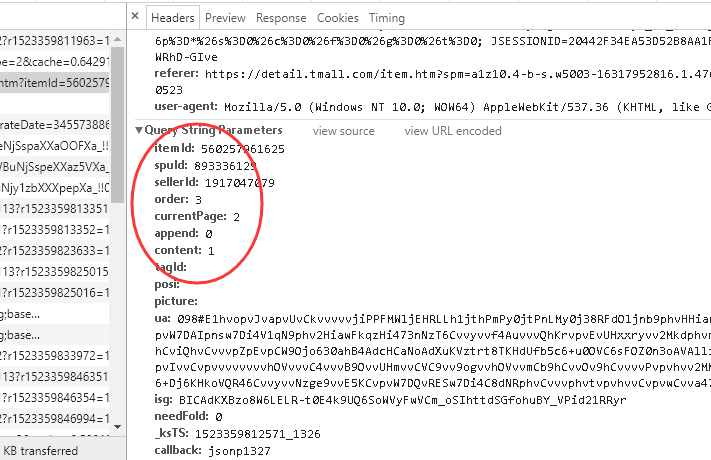
在这些参数中有一部分对我们有用,例如,itemId 表示商品 ID,currentPage 表示当前获取的评论页数,在通过爬虫获取这些评论数据时,需要不断改变这些参数值以获取不同的评论数据。
尽管根据评论数计算(每页20条评论),某些商品的评论页数可能多达数百页,甚至上千页。
03.抓取天猫iphoneX的销售数据
因为本项目抓取指定商品销售数据需要使用 JSON 模块中相应的 API 进行分析,因为返回的销售数据是 JSON 格式的,而从搜索页面抓取的商品列表需要分析 HTML 代码,这里我使用urllib模块。在对数据进行分析整理后,需要将数据保存到 Mysql 数据库中,因此,本例还会使用 mysql.connector 模块,本例使用的其他模块还包括 re正则模块和urllib.error异常处理模块,所以需要在 Python 脚本开头使用下面的代码导入相关模块。
|
1
2
3
4
|
import urllibimport mysql.connectorimport reimport urllib.error |
使用 request 方法发送 HTTP 请求时,可以使用 decode() 函数对 GET 字段进行编码。
|
1
|
data=urllib.request.urlopen(url).read().decode('GB18030') |
然后,可以利用正则表达式对data数据进行正则匹配,这里就不仔细描述了,代码如下;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
for currentPage in range(1,100): try: commt_url='https://rate.tmall.com/list_detail_rate.htm?itemId=560257961625&spuId=893336129&sellerId=1917047079&order=3¤tPage='+str(currentPage)+'&append=0&content=1&tagId=&posi=&picture=&' proxy_add="119.183.220.224:8088"#设置代理服务器,具体的大家可以去西刺免费的IP网站选择一个,“人生苦短,我选代理” #------------备用IP----------- #proxy_add="124.128.39.138:8088" #proxy_add="223.241.78.1064:8010" commt_data=use_proxy_2(commt_url,proxy_add) #爬取网页的评论内容 #正则匹配目标参数:网络类型、机身颜色、存储容量、购买途径、评价、评论日期 pat='"aliMallSeller":.*?auctionSku":"(.*?)","auctionTitle.*?"cmsSource":"(.*?)","displayRatePic.*?"rateContent":"(.*?)","rateDate":"(.*?)","reply.*?":""}' list_detail=re.compile(pat).findall(commt_data) except urllib.error.URLError as e: if hasattr(e,"code"): print(e.code) if hasattr(e,"reason"): print(e.reason) |
正则匹配后的数据一个list,而且所有的数据都在一起,如下所示:

所以需要对数据进行拆分,生成不同的字段,分别为‘type#网络类型’,‘color#机身颜色’,‘rom #存储容量’,‘source #来源购买途径’,‘discuss #评论’,‘time #评论日期’。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
for i in range(len(list_detail)):#i表示每页第i条评论 data=list(list_detail[i]) #print(data) item_data=data[0] m = re.split('[:;]',item_data) #print(m) type = m[1]#网络类型 color = m[3]#机身颜色 rom = m[5]#存储容量 source = data[1]#来源购买途径 discuss = data[2]#评论 time = data[3]#评论日期 |
然后就是将数据存入数据库中,利用python将数据存入数据库的方法有很多,这里我用的是mysql.connector模块。这里在插入数据库前,我们可以先在本地的数据库建好表,如下我用的是MySQL-Front可视化操作工作,比较直观反应。
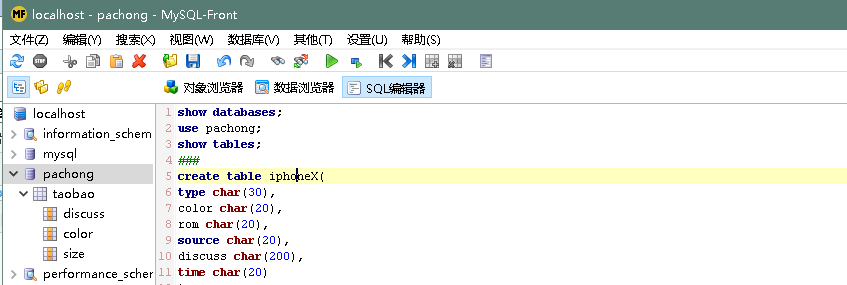
然后开始将爬到的数据插入数据库,代码:
#插入mysql数据库
#连接数据库,这里注意端口号port的值是int类型,不能写成字符型,我第一次的时候就是吃了苦头
conn = mysql.connector.connect(
user='root',
password='111111',
host='127.0.0.1',
port=3306,
database='pachong'
)
#获取游标
cursor = conn.cursor()
#插入数据
cursor.execute("INSERT INTO iphoneX(type,color,rom,source,discuss,time) VALUES ('"+type+"','"+color+"','"+rom+"','"+source+"','"+discuss+"','"+time+"')")
print('第'+str(currentPage)+'页,第'+str(i)+'条数据')
print('************** 数据保存成功 **************')
#提交数据
conn.commit()
#关闭连接
cursor.close()

保存成功后,再取数据库中查看,如图所示;
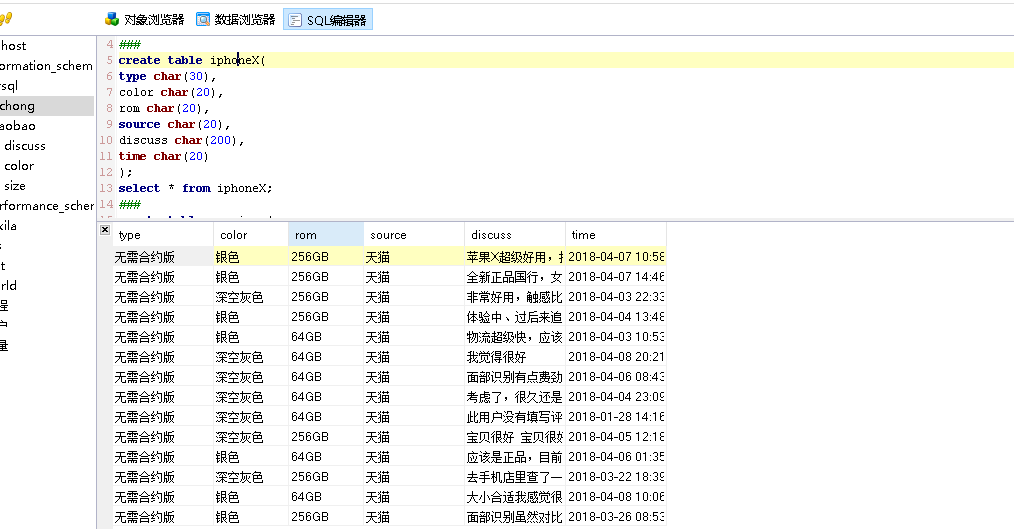
下面看一下完整的实现代码

import urllib
import mysql.connector
import re
import urllib.error
#设置请求头headers
headers=("user-agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36")
opener=urllib.request.build_opener()
opener.addheaders=[headers]#添加报头
urllib.request.install_opener(opener)#设置opner全局化
#设置代理服务器
def use_proxy_1(url,proxy_add):
proxy=urllib.request.ProxyHandler({'http':proxy_add})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(url).read().decode('utf-8')
return data
def use_proxy_2(url,proxy_add):
proxy=urllib.request.ProxyHandler({'http':proxy_add})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(url).read().decode('GB18030')#用GB18030格式转码
return data
for currentPage in range(1,30):
try:
commt_url='https://rate.tmall.com/list_detail_rate.htm?itemId=560257961625&spuId=893336129&sellerId=1917047079&order=3¤tPage='+str(currentPage)+'&append=0&content=1&tagId=&posi=&picture=&'
proxy_add="119.183.220.224:8088"#设置代理服务器,具体的大家可以去西刺免费的IP网站选择一个,“人生苦短,我选代理”
#------------备用IP-----------
#proxy_add="124.128.39.138:8088"
#proxy_add="223.241.78.1064:8010"
commt_data=use_proxy_2(commt_url,proxy_add) #爬取网页的评论内容
#正则匹配目标参数:网络类型、机身颜色、存储容量、购买途径、评价、评论日期
pat='"aliMallSeller":.*?auctionSku":"(.*?)","auctionTitle.*?"cmsSource":"(.*?)","displayRatePic.*?"rateContent":"(.*?)","rateDate":"(.*?)","reply.*?":""}'
list_detail=re.compile(pat).findall(commt_data)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
#print(list_detail)
#返回的结果是list形式,通过循环进行遍历
#考虑到爬取的数据量比较大,还是来一个异常处理,这个东西是必要的,省很多不必要的麻烦
for i in range(len(list_detail)):#i表示每页第i条评论
data=list(list_detail[i])
#print(data)
item_data=data[0]
m = re.split('[:;]',item_data)
#print(m)
type = m[1]#网络类型
color = m[3]#机身颜色
rom = m[5]#存储容量
source = data[1]#来源购买途径
discuss = data[2]#评论
time = data[3]#评论日期
#print(type,color,rom,source,discuss,time)
try:
#插入mysql数据库
#连接数据库,这里注意端口号port的值是int类型,不能写成字符型,我第一次的时候就是吃了苦头
conn = mysql.connector.connect(
user='root',
password='111111',
host='127.0.0.1',
port=3306,
database='pachong'
)
#获取游标
cursor = conn.cursor()
#插入数据
cursor.execute("INSERT INTO iphoneX(type,color,rom,source,discuss,time) VALUES ('"+type+"','"+color+"','"+rom+"','"+source+"','"+discuss+"','"+time+"')")
print('第'+str(currentPage)+'页,第'+str(i)+'条数据')
print('************** 数据保存成功 **************')
#提交数据
conn.commit()
#关闭连接
cursor.close()
except Exception as e:
print(e)
print('第'+str(currentPage)+'页,第'+str(i)+'条数据')
print('*************!!!! 保存失败!!!! **************')
04 数据分析
如果说抓取数据是数据分析的第1步,那么数据清洗就是数据分析的第2步,至于为什么要进行数据清洗呢?如何进行数据清洗呢?本文就不具体描述了,下面具体对我们抓取的天猫商城iphoneX的销售数据进行分析。
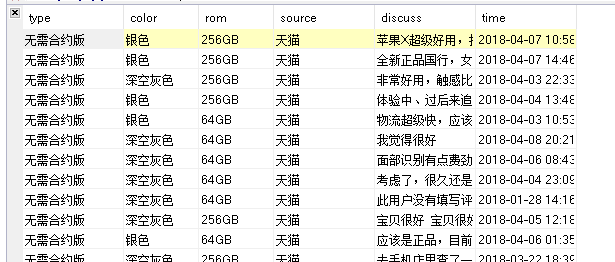
从销售数据可以看出,网络爬虫抓取了‘type#网络类型’,‘color#机身颜色’,‘rom #存储容量’,‘source #来源购买途径’,‘discuss #评论’,‘time #评论日期六类数据,当然还可以抓取更多的数据。这里我们主要是对颜色color和内存rom进行分析,下面利用SQl语句和Pandas库对数据进行基本的分析。
用 SQL 语句分析IphoneX(按颜色)销售比例
既然销售数据都保存在Mysql数据库中,那么我们不妨先用 SQL 语句做一下统计分析,本节将对iphoneX的销售量做一个销售比例统计分析。我们要统计的是某一个颜色的销售数量占整个销售数量的百分比,这里需要统计和计算如下3类数据。
- 某一个颜色的iphoneX销售数量
- iphoneX销售总数量
第1类数据和第2类数据的差值(百分比)
用 Pandas 和 Matplotlib 分析对胸罩销售比例进行可视化分析
接下来将使用 Pandas 完成与前面相同的数据分析,并使用 Matplotlib 将分析结果以图形化方式展现出来。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
# 打开iphoneX数据库#数据分析 from pandas import *from matplotlib.pyplot import *import mysql.connectorimport matplotlibimport matplotlib.pyplot as pltconn = mysql.connector.connect( user='root', password='111111', host='127.0.0.1', port=3306, database='pachong' )cur=conn.cursor() # 对color进行分组,并统计每一组的记录数# 对color进行分组,并统计每一组的记录数try: cur.execute("select count(*) from iphoneX;") alldata = cur.fetchall() #color统计 cur.execute("select count(*) from iphoneX where color='银色';") y_color= cur.fetchall()[0] cur.execute("select count(*) from iphoneX where color='深空灰色';") h_color= cur.fetchall()[0] #rom统计 cur.execute("select count(*) from iphoneX where rom='64GB';") rom64 = cur.fetchall()[0] cur.execute("select count(*) from iphoneX where rom='256GB';") rom256 = cur.fetchall()[0]except: print("Select is failed")# 数据可视化# 饼图要显示的文本labels1 = [u'y_color',u'h_color']labels2 = [u'64_rom',u'256_rom']# 用饼图绘制销售比例X1=[y_color,h_color] X2=[rom64,rom256]fig = plt.figure()#解决不能显示中文的方法plt.pie(X1,labels=labels1,autopct='%.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点)zhfont1 = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc')plt.title("颜色比例图",fontproperties=zhfont1)plt.show()plt.pie(X2,labels=labels2,autopct='%.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点)zhfont1 = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc')plt.title("内存比例图",fontproperties=zhfont1)plt.show() |
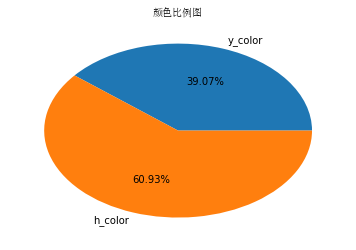
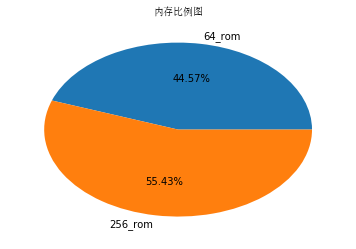
从上图的分析结果可以看出,iphoneX的“深空灰色”销售比例都很大,同时买256GB内存的要比64GB内存的比例大,基本上和我个人的判断差不多。今天就介绍到这里了,时间有限,后期会不断更新,大家也可以爬取不同商品的不同信息,进行更加具体的分析。
每天学习一点点 编程PDF电子书、视频教程免费下载:
http://www.shitanlife.com/code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号