
pytorch deeplabV3 训练自己的数据集
pytorch deeplabV3 训练自己的数据集
一、Pytorch官方的demo
https://pytorch.org/hub/pytorch_vision_deeplabv3_resnet101/
只需要运行里面的代码就可以对示例图片dog进行语义分割。
预训练模型已在Pascal VOC数据集中存在的20个类别的COCO train2017子集中进行了训练。
二、训练自己的数据集
Pytorch提供的预训练model可以用来Evaluate图像,但是仅有20类图像,如果需要分割自己的目标的话,需要训练自己的数据集。
根据pytorch提供的部分训练代码,我们可以训练自己的数据集。
https://github.com/pytorch/vision/tree/master/references/segmentation
由于提供的train.py中有PASCAL VOC数据集的加载方式。在这里我们需要将数据准备成和PASCAL VOC 2012一样的文件夹目录。

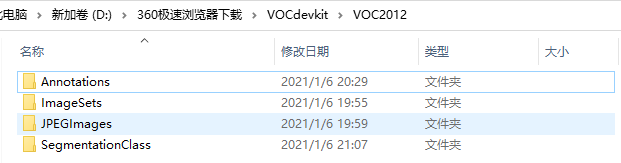
Annotations:存放数据的标记文件
Segentation:train和val分别放对应样本的文件名(不带后缀)
JPEGImages:放jpg的图片,放别的后缀需要改voc.py
SegmentationClass:放标记图片对应的mask.png
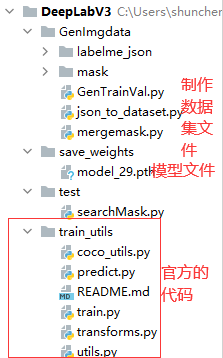
pycharm整个项目的文件架构:
2.1数据集准备
2.1.1首先用lablelme标记自己的数据
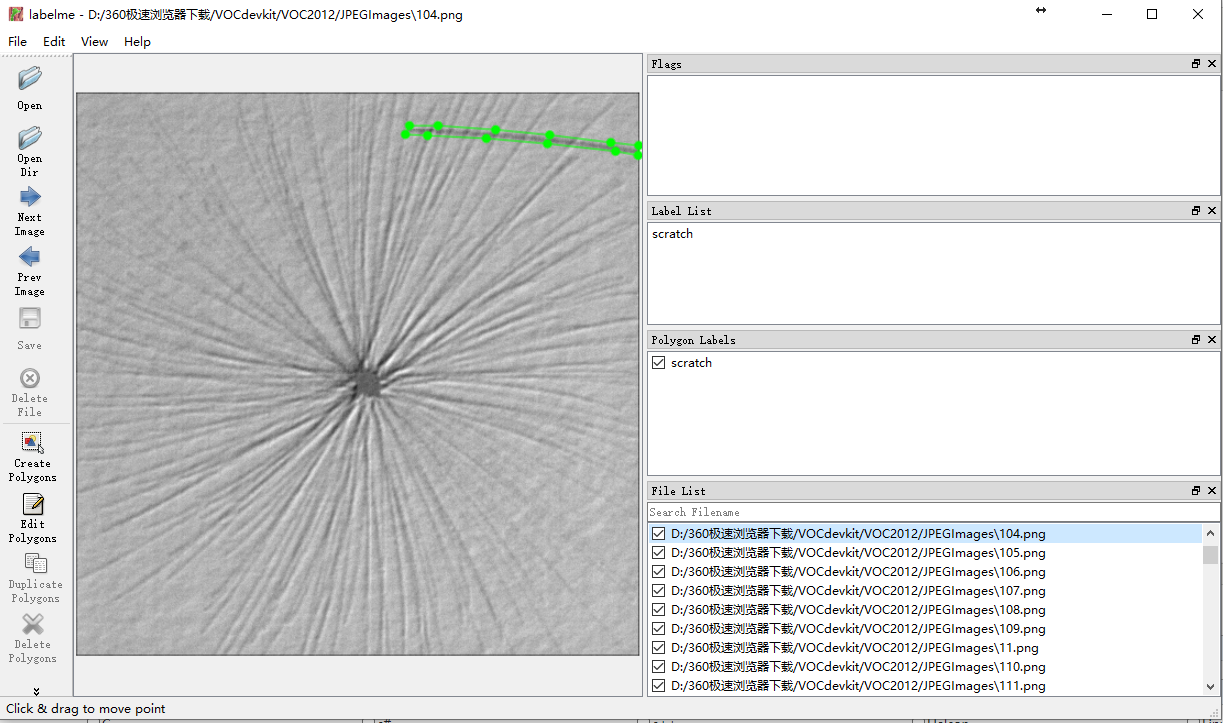
在JPEGImages中放入所有的图片。将所有标记的json放在Annotations中。
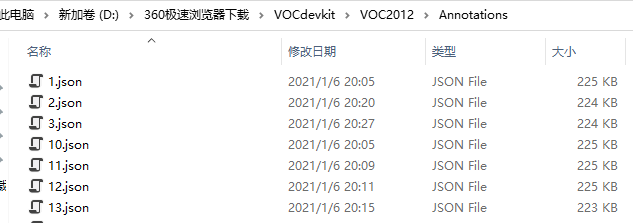
2.1.2根据已标记的json文件名称分配数据集。
生成train.txt和val.txt,可以设置比例
1 ###根据Annotations中文件名,分配train和val数据集 2 import os 3 import random 4 path='D:\\360极速浏览器下载\\VOCdevkit\\Annotations' 5 train_path='D:\\360极速浏览器下载\\VOCdevkit\\ImageSets\\Segmentation\\train.txt' 6 val_path='D:\\360极速浏览器下载\\VOCdevkit\\ImageSets\\Segmentation\\val.txt' 7 8 files=os.listdir(path) 9 val_rate=0.15 10 all_sample=[] 11 val_sample=[] 12 random.seed(0) 13 for file in files: 14 new=file[:-5] 15 all_sample.append(new) 16 val_sample = random.sample(all_sample, k=int(len(all_sample) * val_rate)) 17 print(val_sample) 18 19 t=open(train_path,'w') # r只读,w可写,a追加 20 v=open(val_path,'w') # r只读,w可写,a追加c 21 for sample in all_sample: 22 if sample in val_sample: 23 v.write(sample) 24 v.write("\n") 25 else: 26 t.writelines(sample) 27 t.write("\n") 28 t.close() 29 v.close()
2.1.3根据json文件生成mask图像
1 import argparse 2 import json 3 import os 4 import os.path as osp 5 import warnings 6 import copy 7 8 import numpy as np 9 import PIL.Image 10 from skimage import io 11 import yaml 12 13 from labelme import utils 14 15 NAME_LABEL_MAP = { 16 '_background_': 0, 17 "scratch": 1, 18 } 19 20 21 def main(): 22 parser = argparse.ArgumentParser() 23 #parser.add_argument('json_file') 24 parser.add_argument('-o', '--out', default=None) 25 args = parser.parse_args() 26 27 json_file = "D:\\360极速浏览器下载\\VOCdevkit\\Annotations" 28 29 list = os.listdir(json_file) 30 for i in range(0, len(list)): 31 path = os.path.join(json_file, list[i]) 32 filename = list[i][:-5] # .json 33 if os.path.isfile(path): 34 data = json.load(open(path)) 35 img = utils.image.img_b64_to_arr(data['imageData']) 36 lbl, lbl_names = utils.shape.labelme_shapes_to_label(img.shape, data['shapes']) # labelme_shapes_to_label 37 38 a=np.unique(lbl) 39 40 # modify labels according to NAME_LABEL_MAP 41 lbl_tmp = copy.copy(lbl) 42 for key_name in lbl_names: 43 old_lbl_val = lbl_names[key_name] 44 new_lbl_val = NAME_LABEL_MAP[key_name] 45 lbl_tmp[lbl == old_lbl_val] = new_lbl_val 46 lbl_names_tmp = {} 47 for key_name in lbl_names: 48 lbl_names_tmp[key_name] = NAME_LABEL_MAP[key_name] 49 b=np.unique(lbl_tmp) 50 # Assign the new label to lbl and lbl_names dict 51 lbl = np.array(lbl_tmp, dtype=np.int8) 52 c=np.unique(lbl) 53 lbl_names = lbl_names_tmp 54 55 captions = ['%d: %s' % (l, name) for l, name in enumerate(lbl_names)] 56 57 58 #lbl_viz = utils.draw.draw_label(lbl, img, captions) 59 out_dir = osp.basename(list[i]).replace('.', '_') 60 out_dir = osp.join(osp.dirname(list[i]), out_dir) 61 if not osp.exists(out_dir): 62 os.mkdir(out_dir) 63 64 PIL.Image.fromarray(img).save(osp.join(out_dir, '{}.png'.format(filename))) 65 PIL.Image.fromarray(lbl.astype(np.uint8)).save(osp.join(out_dir, '{}_gt.png'.format(filename))) 66 #PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, '{}_viz.png'.format(filename))) 67 68 with open(osp.join(out_dir, 'label_names.txt'), 'w') as f: 69 for lbl_name in lbl_names: 70 f.write(lbl_name + '\n') 71 72 warnings.warn('info.yaml is being replaced by label_names.txt') 73 info = dict(label_names=lbl_names) 74 with open(osp.join(out_dir, 'info.yaml'), 'w') as f: 75 yaml.safe_dump(info, f, default_flow_style=False) 76 77 print('Saved to: %s' % out_dir) 78 79 80 if __name__ == '__main__': 81 main()
2.1.4将所有的mask合并到一个文件夹中。
1 import os 2 import shutil 3 path='labelme_json' 4 files=os.listdir(path) 5 6 for file in files: 7 jpath=os.listdir(os.path.join(path,file)) 8 new=file[:-5] 9 newnames=os.path.join('mask',new) 10 filename=os.path.join(path,file,jpath[1]) 11 print(filename) 12 print(newnames) 13 shutil.copyfile(filename,newnames+'.png')
2.2.开始训练
训练代码是从train.py中修改得到到,要进行fintune最重要的是将预训练model的21类修改成2类。
可以通过阅读Pytorch实现DeeplabV3的源码去查找要修改的卷积层的位置。
https://github.com/pytorch/vision/blob/master/torchvision/models/segmentation/deeplabv3.py
1 model = torchvision.models.segmentation.deeplabv3_resnet50(num_classes=21, 2 aux_loss=args.aux_loss, 3 pretrained=True) 4 5 6 print(model) 7 from torchvision.models.segmentation.deeplabv3 import DeepLabHead, DeepLabV3 8 from torchvision.models.segmentation.fcn import FCN, FCNHead 9 model.classifier=DeepLabHead(2048,2) 10 model.aux_classifier=FCNHead(1024,2)
train.py
1 import datetime 2 import os 3 import time 4 5 import torch 6 import torch.utils.data 7 from torch import nn 8 import torchvision 9 10 from coco_utils import get_coco 11 import transforms as T 12 import utils 13 14 15 def get_dataset(dir_path, name, image_set, transform): 16 def sbd(*args, **kwargs): 17 return torchvision.datasets.SBDataset(*args, mode='segmentation', **kwargs) 18 paths = { 19 "voc": (dir_path, torchvision.datasets.VOCSegmentation, 2), 20 "voc_aug": (dir_path, sbd, 2), 21 "coco": (dir_path, get_coco, 2) 22 } 23 p, ds_fn, num_classes = paths[name] 24 25 ds = ds_fn(p, image_set=image_set, transforms=transform) 26 return ds, num_classes 27 28 29 def get_transform(train): 30 base_size = 520 31 crop_size = 480 32 33 min_size = int((0.5 if train else 1.0) * base_size) 34 max_size = int((2.0 if train else 1.0) * base_size) 35 transforms = [] 36 transforms.append(T.RandomResize(min_size, max_size)) 37 if train: 38 transforms.append(T.RandomHorizontalFlip(0.5)) 39 transforms.append(T.RandomCrop(crop_size)) 40 transforms.append(T.ToTensor()) 41 transforms.append(T.Normalize(mean=[0.485, 0.456, 0.406], 42 std=[0.229, 0.224, 0.225])) 43 44 return T.Compose(transforms) 45 46 47 def criterion(inputs, target): 48 losses = {} 49 for name, x in inputs.items(): 50 losses[name] = nn.functional.cross_entropy(x, target, ignore_index=255) 51 52 if len(losses) == 1: 53 return losses['out'] 54 55 return losses['out'] + 0.5 * losses['aux'] 56 57 58 def evaluate(model, data_loader, device, num_classes): 59 model.eval() 60 confmat = utils.ConfusionMatrix(num_classes) 61 metric_logger = utils.MetricLogger(delimiter=" ") 62 header = 'Test:' 63 with torch.no_grad(): 64 for image, target in metric_logger.log_every(data_loader, 100, header): 65 image, target = image.to(device), target.to(device) 66 output = model(image) 67 output = output['out'] 68 69 confmat.update(target.flatten(), output.argmax(1).flatten()) 70 71 confmat.reduce_from_all_processes() 72 73 return confmat 74 75 76 def train_one_epoch(model, criterion, optimizer, data_loader, lr_scheduler, device, epoch, print_freq): 77 model.train() 78 metric_logger = utils.MetricLogger(delimiter=" ") 79 metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value}')) 80 header = 'Epoch: [{}]'.format(epoch) 81 for image, target in metric_logger.log_every(data_loader, print_freq, header): 82 image, target = image.to(device), target.to(device) 83 output = model(image) 84 loss = criterion(output, target) 85 86 optimizer.zero_grad() 87 loss.backward() 88 optimizer.step() 89 90 lr_scheduler.step() 91 92 metric_logger.update(loss=loss.item(), lr=optimizer.param_groups[0]["lr"]) 93 94 95 def main(args): 96 if args.output_dir: 97 utils.mkdir(args.output_dir) 98 99 utils.init_distributed_mode(args) 100 print(args) 101 102 device = torch.device(args.device) 103 104 dataset, num_classes = get_dataset(args.data_path, args.dataset, "train", get_transform(train=True)) 105 dataset_test, _ = get_dataset(args.data_path, args.dataset, "val", get_transform(train=False)) 106 107 if args.distributed: 108 train_sampler = torch.utils.data.distributed.DistributedSampler(dataset) 109 test_sampler = torch.utils.data.distributed.DistributedSampler(dataset_test) 110 else: 111 train_sampler = torch.utils.data.RandomSampler(dataset) 112 test_sampler = torch.utils.data.SequentialSampler(dataset_test) 113 114 data_loader = torch.utils.data.DataLoader( 115 dataset, batch_size=args.batch_size, 116 sampler=train_sampler, num_workers=args.workers, 117 collate_fn=utils.collate_fn, drop_last=True) 118 119 data_loader_test = torch.utils.data.DataLoader( 120 dataset_test, batch_size=1, 121 sampler=test_sampler, num_workers=args.workers, 122 collate_fn=utils.collate_fn) 123 124 model = torchvision.models.segmentation.deeplabv3_resnet50(num_classes=21, 125 aux_loss=args.aux_loss, 126 pretrained=True) 127 128 129 print(model) 130 from torchvision.models.segmentation.deeplabv3 import DeepLabHead, DeepLabV3 131 from torchvision.models.segmentation.fcn import FCN, FCNHead 132 model.classifier=DeepLabHead(2048,2) 133 model.aux_classifier=FCNHead(1024,2) 134 135 model.to(device) 136 if args.distributed: 137 model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model) 138 139 model_without_ddp = model 140 if args.distributed: 141 model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu]) 142 model_without_ddp = model.module 143 144 if args.test_only: 145 confmat = evaluate(model, data_loader_test, device=device, num_classes=num_classes) 146 print(confmat) 147 return 148 149 params_to_optimize = [ 150 {"params": [p for p in model_without_ddp.backbone.parameters() if p.requires_grad]}, 151 {"params": [p for p in model_without_ddp.classifier.parameters() if p.requires_grad]}, 152 ] 153 if args.aux_loss: 154 params = [p for p in model_without_ddp.aux_classifier.parameters() if p.requires_grad] 155 params_to_optimize.append({"params": params, "lr": args.lr * 10}) 156 optimizer = torch.optim.SGD( 157 params_to_optimize, 158 lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay) 159 160 lr_scheduler = torch.optim.lr_scheduler.LambdaLR( 161 optimizer, 162 lambda x: (1 - x / (len(data_loader) * args.epochs)) ** 0.9) 163 164 if args.resume: 165 checkpoint = torch.load(args.resume, map_location='cpu') 166 model_without_ddp.load_state_dict(checkpoint['model']) 167 optimizer.load_state_dict(checkpoint['optimizer']) 168 lr_scheduler.load_state_dict(checkpoint['lr_scheduler']) 169 args.start_epoch = checkpoint['epoch'] + 1 170 171 start_time = time.time() 172 for epoch in range(args.start_epoch, args.epochs): 173 if args.distributed: 174 train_sampler.set_epoch(epoch) 175 train_one_epoch(model, criterion, optimizer, data_loader, lr_scheduler, device, epoch, args.print_freq) 176 confmat = evaluate(model, data_loader_test, device=device, num_classes=num_classes) 177 print(confmat) 178 utils.save_on_master( 179 { 180 'model': model_without_ddp.state_dict(), 181 'optimizer': optimizer.state_dict(), 182 'lr_scheduler': lr_scheduler.state_dict(), 183 'epoch': epoch, 184 'args': args 185 }, 186 os.path.join("../save_weights/", 'model_{}.pth'.format(epoch))) 187 188 total_time = time.time() - start_time 189 total_time_str = str(datetime.timedelta(seconds=int(total_time))) 190 print('Training time {}'.format(total_time_str)) 191 192 193 def parse_args(): 194 import argparse 195 parser = argparse.ArgumentParser(description='PyTorch Segmentation Training') 196 197 parser.add_argument('--data-path', default='D:/360极速浏览器下载', help='dataset path') 198 parser.add_argument('--dataset', default='voc', help='dataset name') 199 parser.add_argument('--model', default='deeplabv3_resnet50', help='model') 200 parser.add_argument('--aux-loss', action='store_true', help='auxiliar loss') 201 parser.add_argument('--device', default='cuda', help='device') 202 parser.add_argument('-b', '--batch-size', default=2, type=int) 203 parser.add_argument('--epochs', default=30, type=int, metavar='N', 204 help='number of total epochs to run') 205 206 parser.add_argument('-j', '--workers', default=0, type=int, metavar='N', 207 help='number of data loading workers (default: 16)') 208 parser.add_argument('--lr', default=0.01, type=float, help='initial learning rate') 209 parser.add_argument('--momentum', default=0.9, type=float, metavar='M', 210 help='momentum') 211 parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float, 212 metavar='W', help='weight decay (default: 1e-4)', 213 dest='weight_decay') 214 parser.add_argument('--print-freq', default=10, type=int, help='print frequency') 215 parser.add_argument('--output-dir', default='.', help='path where to save') 216 parser.add_argument('--resume', default='', help='resume from checkpoint') 217 parser.add_argument('--start-epoch', default=0, type=int, metavar='N', 218 help='start epoch') 219 parser.add_argument( 220 "--test-only", 221 dest="test_only", 222 help="Only test the model", 223 action="store_true", 224 ) 225 parser.add_argument( 226 "--pretrained", 227 dest="pretrained", 228 help="Use pre-trained models from the modelzoo", 229 action="store_true", 230 ) 231 # distributed training parameters 232 parser.add_argument('--world-size', default=1, type=int, 233 help='number of distributed processes') 234 parser.add_argument('--dist-url', default='env://', help='url used to set up distributed training') 235 236 args = parser.parse_args() 237 return args 238 239 240 if __name__ == "__main__": 241 args = parse_args() 242 main(args)
predict.py
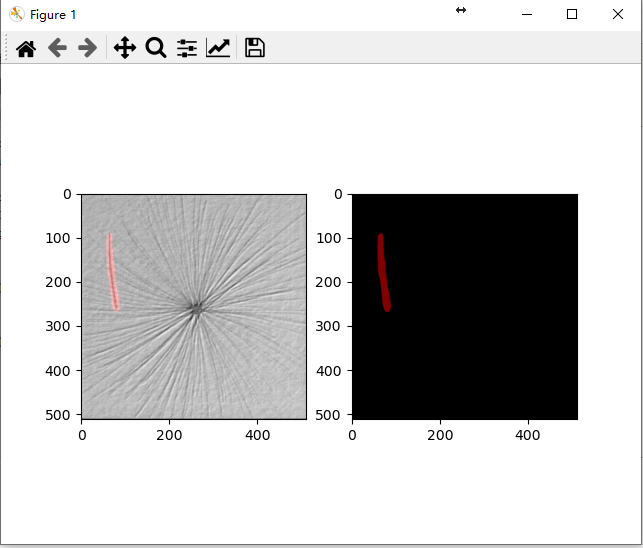
比较详细的预测及可视化脚本
1 import torchvision 2 import os 3 from PIL import Image 4 import matplotlib.pyplot as plt 5 import torch 6 # Apply the transformations needed 7 #import torchvision.transforms as T 8 import train_utils.transforms as T 9 import numpy as np 10 import datetime 11 import os 12 import time 13 14 import torch 15 import torch.utils.data 16 from torch import nn 17 import torchvision 18 from torchvision import transforms 19 import cv2 20 21 # Define the helper function 22 def decode_segmap(image, nc=2): 23 label_colors = np.array([(0, 0, 0), # 0=background 24 # 1=scratch 25 (128, 0, 0)]) 26 27 r = np.zeros_like(image).astype(np.uint8) 28 g = np.zeros_like(image).astype(np.uint8) 29 b = np.zeros_like(image).astype(np.uint8) 30 31 for l in range(0, nc): 32 idx = image == l 33 r[idx] = label_colors[l, 0] 34 g[idx] = label_colors[l, 1] 35 b[idx] = label_colors[l, 2] 36 37 rgb = np.stack([r, g, b], axis=2) 38 return rgb 39 40 def segment(net, path, show_orig=True): 41 dev=torch.device("cuda:0" if torch.cuda.is_available() else "cpu") 42 net.to(dev) 43 img = Image.open(path) 44 if show_orig: plt.imshow(img); plt.axis('off'); plt.show() 45 # Comment the Resize and CenterCrop for better inference results 46 trf = T.Compose([ 47 T.ToTensor(), 48 T.Normalize(mean = [0.485, 0.456, 0.406], 49 std = [0.229, 0.224, 0.225])]) 50 result=None 51 trf(img,target=result) 52 53 out = net(result) 54 out=out['out'] 55 t=out.squeeze() 56 om = torch.argmax(t, dim=0).detach().cpu().numpy() 57 58 a=np.unique(om) 59 rgb = decode_segmap(om) 60 plt.imshow(rgb); plt.axis('off'); plt.show() 61 62 63 def main(): 64 # get devices 65 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") 66 print("using {} device.".format(device)) 67 68 #load model 69 model = torchvision.models.segmentation.deeplabv3_resnet50(num_classes=2,pretrained=False) 70 train_weights = "../save_weights/model_29.pth" 71 assert os.path.exists(train_weights), "{} file dose not exist.".format(train_weights) 72 model.load_state_dict(torch.load(train_weights, map_location=device)["model"],strict=False) 73 print(model) 74 model.to(device) 75 model.eval() 76 77 path="D:\\360极速浏览器下载\\VOCdevkit\\VOC2012\\JPEGImages\\" 78 files=os.listdir(path) 79 for file in files: 80 # sample execution (requires torchvision) 81 filename=os.path.join(path,file) 82 input_image = Image.open(filename).convert('RGB') 83 preprocess = transforms.Compose([ 84 transforms.ToTensor(), 85 transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), 86 ]) 87 88 input_tensor = preprocess(input_image) 89 input_batch = input_tensor.unsqueeze(0).to(device) # create a mini-batch as expected by the model 90 91 92 with torch.no_grad(): 93 output = model(input_batch)['out'][0] 94 output_predictions = output.argmax(0) 95 96 out=output_predictions.detach().cpu().numpy() 97 rgb=decode_segmap(out) 98 99 cv_img = cv2.cvtColor(np.asarray(input_image), cv2.COLOR_RGB2BGR) 100 #cv_img = cv2.cvtColor(cv_img, cv2.COLOR_BGR2RGB) 101 cv_img = cv2.addWeighted(cv_img, 1, rgb, 0.5, 0) 102 103 plt.figure() 104 plt.subplot(1, 2, 1) 105 plt.imshow(cv_img) 106 107 plt.subplot(1, 2, 2) 108 plt.imshow(rgb) 109 plt.show() 110 111 if __name__ == '__main__': 112 main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号