时序数据简介
1 什么是时序数据
生活中,我们经常会接触到需要对某些指标或者状态按时间序列进行统计和分析的场景,典型的如股票大盘走势、气象变化、内存监控等。
这些依赖于时间而变化,可以用数值来反映其变化程度的数据就叫时序数据。时序数据具有两个关键的指标:监测时间和监测数值。
2 时序数据模型
时序数据按照其数据组织形式可以分为单值模型和多值模型两种。
2.1 单值模型
单值模型一条监测记录只对应一个指标的数据,如下表所示,每行数据为一条监测记录,每条记录只能反映一个监测指标的信息。
| metric | timestamp | tags | value | |
|---|---|---|---|---|
| server | city | |||
| cpu | 2017-09-27T16:55:01Z | server1 | hangzhou | 0.1 |
| memory | 2017-09-27T16:57:12Z | server2 | shanghai | 0.2 |
2.2 多值模型
多值模型一条监测记录可以对应多个指标的数据,如下表所示,每行数据为一条监测记录,每条记录可以反映不同监测指标的信息。
| timestamp | tags | metrics | ||
|---|---|---|---|---|
| server | city | cpu | memory | |
| 2017-09-27T16:55:01Z | server1 | hangzhou | 0.1 | 0.2 |
| 2017-09-27T16:57:12Z | server2 | shanghai | 0.2 | 0.3 |
2.3 小结
单值模型和多值模型在数据表示上可以进行相互转化,如多值模型可以用多条记录的单值模型来表示,同时多值模型也可以退化为只记录一项指标。因此,不管是单值模型还是多值模型都可以解决实际当中时序数据相关的问题。但是需要指出的是,两种模型在具体实现上还是有一些差异的,需要根据实际的业务场景选择合适的时序数据库。
3 时序数据的处理
时序数据在实际的业务需求中一般降采样、插值、聚合三种方式。
3.1 降采样
时序数据在实际当中是连续的数据,理论上给定任意的时刻都能查询得到其对应的值,但是计算机在存储数据的时候只能按照一定精度进行采样,存储采样到的离散的数值。
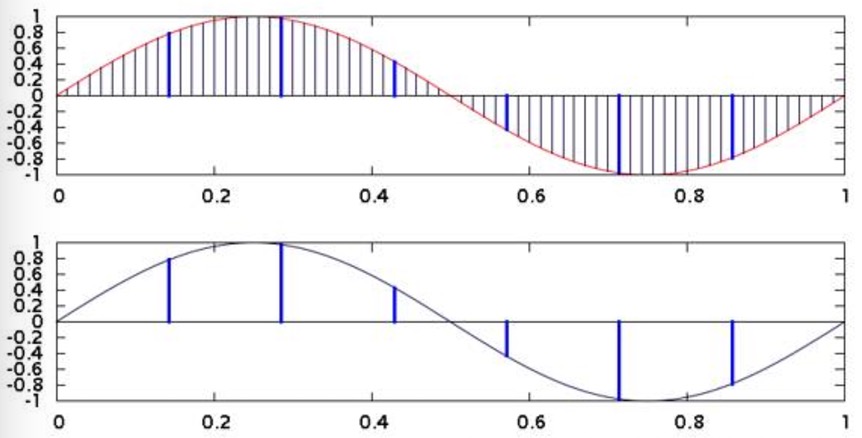
降采样的示意如上图所示。在具体的业务场景当中,我们也往往不需要太高的精度,比如查看一年的股票走势,我们把精度下降到天为单位就能满足需求,同时也能提高处理速度。
3.2 插值
时序数据可能会因为采样精度和存储过程中的错误导致丢失部分业务需要的数据,这个时候我们可以利用时许数据的特点对其进行插值,来近似获取这部分丢失的数据。
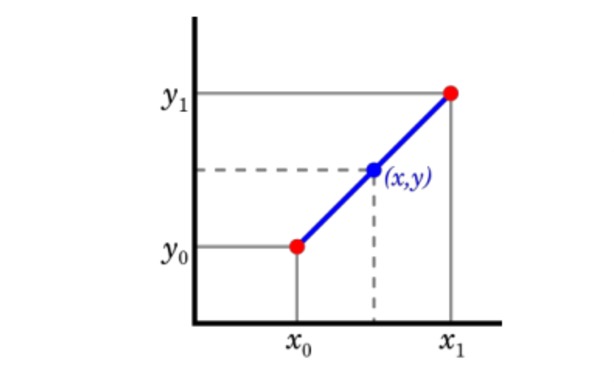
如上图所示,利用线性插值来计算时间点为x的监测值得。
3.3 聚合
很多业务场景常常需要对时序数据进行聚合处理,常用的聚合方法如求和、均值、最大值、最小值、计数等。与普通数据库的聚合不同的是,时序数据库的聚合针对的是抽象的时间线。
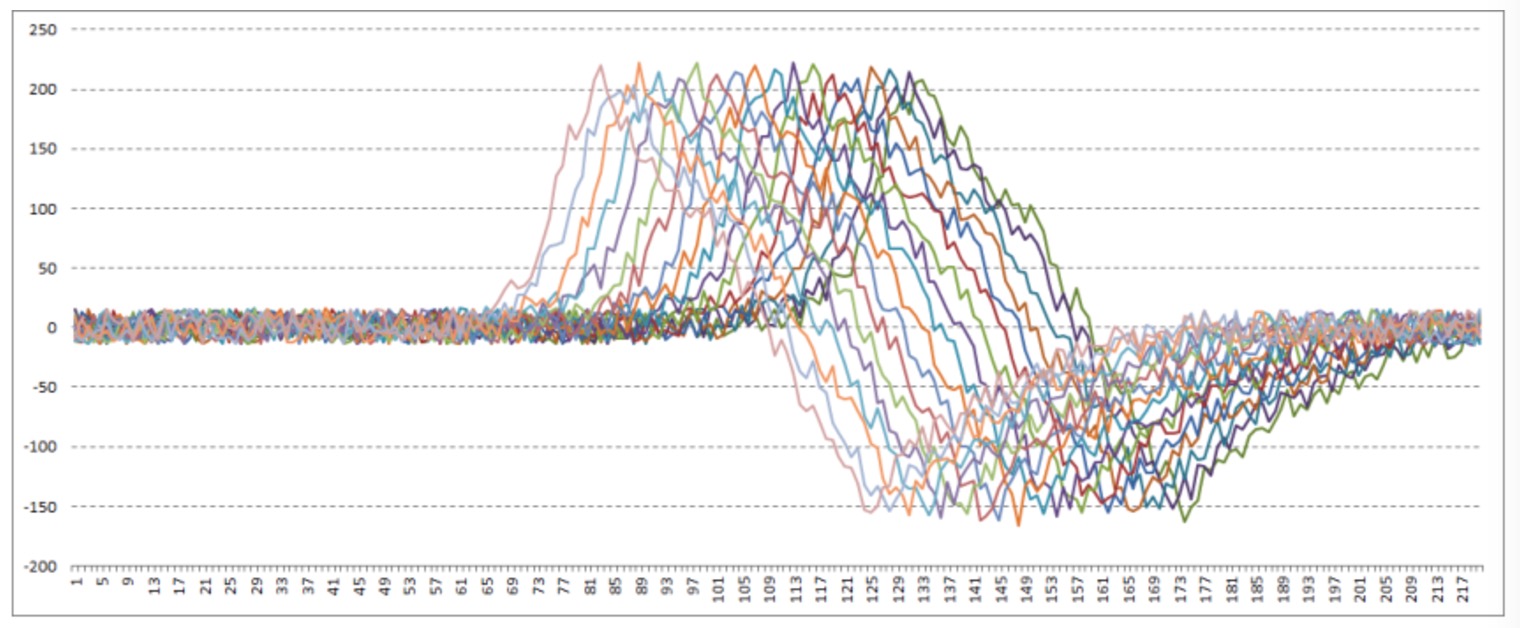
如上图所示,不同监测项或者同一个监测项不同标签可以按时间序列抽象出不同的时间线,对其进行聚合可以得到新的时间线。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号