Python-RabbitMQ消息队列
python中的线程queue可以实现不同线程间的通信,进程queue可以实现python不同进程间的通信
RabbitMQ消息队列就相当于中间人,可以实现独立进程间的通信,也可以实现在不同编程语言中进行通信
windows环境下安装完成RabbitMQ后,输入cmd命令services.msc,然后在服务中开启RabbitMQ的服务,使用RabbitMQ要安装Erlang语言环境
Ubuntu环境下安装RabbitMQ
sch01ar@ubuntu:~$ sudo apt install rabbitmq-server sch01ar@ubuntu:~$ sudo rabbitmq-server start
RabbitMQ默认的监听端口为5672
credentials = pika.PlainCredentials('root', 'root') # RabbitMQ的账号密码
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.220.144',5672,'/',credentials))
连接其它机器上的RabbitMQ服务
发送消息端
# -*- coding:utf-8 -*-
__author__ = "MuT6 Sch01aR"
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1')) # 建立一个socket
channel = connection.channel() # 声明一个管道,在管道里进行通信
channel.queue_declare(queue='q') # 在管道里声明一个名为q的queue
channel.basic_publish( # 发送消息
exchange='',
routing_key='q', # queue名字
body='Hello World!', # 要发送的消息
)
print('数据发送完成')
connection.close() # 关闭队列
接收消息端
# -*- coding:utf-8 -*-
__author__ = "MuT6 Sch01aR"
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1'))
channel = connection.channel() # 声明一个管道,在管道里进行通信
channel.queue_declare(queue='q') # 多声明一个queue,防止当此程序比发送消息端先启动时报错
def callback(ch, method, properties, body):
print(ch, method, properties, body)
# ch为管道的内存地址,method为关于queue队列的一些信息,body为消息内容
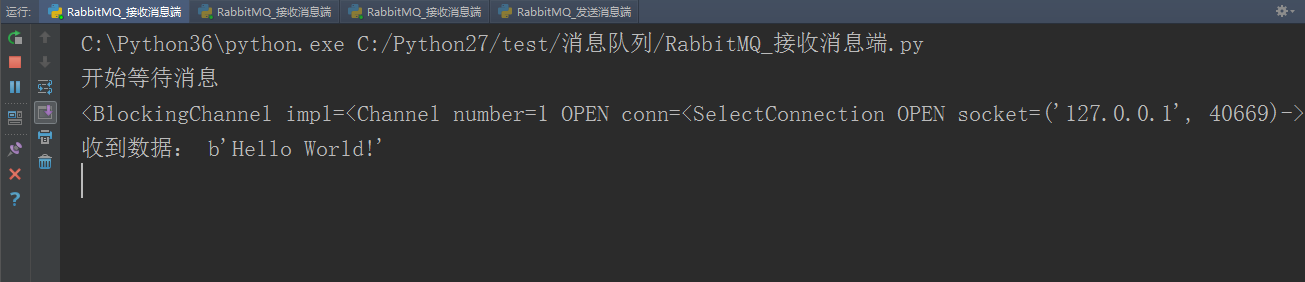
print('收到数据:', body)
channel.basic_consume( # basic_consume开始消费消息
callback, # 如果收到消息就调用callback函数来处理消息
queue='q', # 从q队列里接收消息
no_ack=True, # 是否不确认消息是否处理完,默认为False
)
print('开始等待消息')
channel.start_consuming() # 开始接收消息,如果没有消息就会卡在这,直到有消息
开启三个接收消息端

发送消息端发送一个消息,最先开启的接收消息端先收到消息
发送消息端再发送消息的话,接收消息的就是第二开启的接收消息端,然后是第三个接收消息端,之后再是第一个
RabbitMQ会轮询发消息
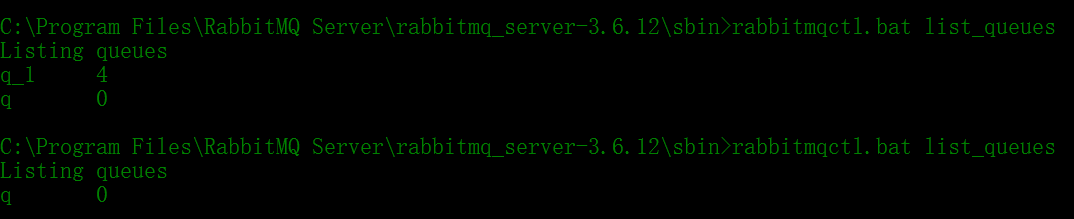
RabbitMQ安装目录下的skin目录里rabbitmqctl.bat可以查看当前队列情况
rabbitmqctl.bat list_queues

接收消息端处理消息时要跟服务器端确认消息处理的情况,以防止接收消息端在处理消息时突然停止运行导致消息丢失
发送消息端
# -*- coding:utf-8 -*-
__author__ = "MuT6 Sch01aR"
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1')) # 建立一个socket
channel = connection.channel() # 声明一个管道,在管道里进行通信
channel.queue_declare(queue='q') # 在管道里声明一个名q为queue
channel.basic_publish( # 发送消息
exchange='',
routing_key='q', # queue名字
body='Hello World!', # 要发送的消息
)
print('数据发送完成')
connection.close() # 关闭队列
接收消息端
# -*- coding:utf-8 -*-
__author__ = "MuT6 Sch01aR"
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1'))
channel = connection.channel() # 声明一个管道,在管道里进行通信
channel.queue_declare(queue='q') # 多声明一个queue,防止当此程序比生产者程序先启动时报错
def callback(ch, method, properties, body):
print(ch, method, properties, body)
# ch为管道的内存地址,method为关于queue队列的一些信息,body为消息内容
time.sleep(20)
print('收到数据:', body)
ch.basic_ack(delivery_tag=method.delivery_tag) # 跟服务器端确认消息已经处理完成
print('消息处理完成')
channel.basic_consume( # basic_consume开始消费消息
callback, # 如果收到消息就调用callback函数来处理消息
queue='q', # 从q队列里接收消息
)
print('开始等待消息')
channel.start_consuming() # 开始接收消息,如果没有消息就会卡在这,直到有消息
开启3个消息接收端,1个发送消息端

开启3个接收消息端,等待接收消息

发送消息端发送消息,第一个启动的接收消息端接收到消息

然后关掉第一个接收消息端,第二个启动的接收消息端收到消息

然后是第三个,第三个之后还是第一个,除非消息处理完成
消息持久化
如果接收消息端正在接收消息的时候,服务器端(RabbitMQ)断了,接收消息端就会报错,消息就会丢失
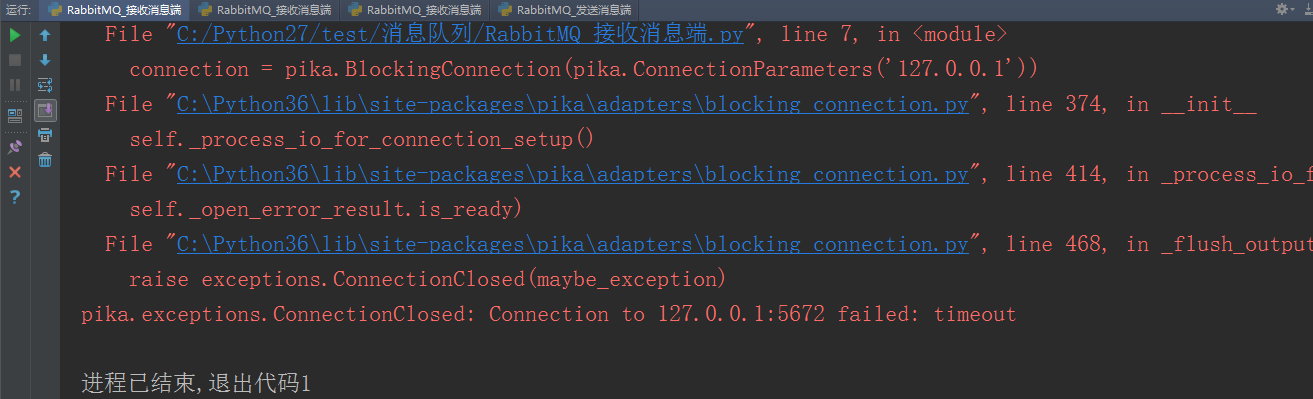
如果不想服务器端突然断开而导致消息丢失,可以使消息持久化
发送消息端
# -*- coding:utf-8 -*-
__author__ = "MuT6 Sch01aR"
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1')) # 建立一个socket
channel = connection.channel() # 声明一个管道,在管道里进行通信
channel.queue_declare(queue='q', durable=True) # 在管道里声明一个名q为queue,durable为队列持久化
channel.basic_publish( # 发送消息
exchange='',
routing_key='q', # queue名字
body='Hello World!', # 要发送的消息
properties=pika.BasicProperties(delivery_mode=2) # 使消息持久化,为1的话为非持久化
)
print('数据发送完成')
connection.close() # 关闭队列
接收消息端
# -*- coding:utf-8 -*-
__author__ = "MuT6 Sch01aR"
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1'))
channel = connection.channel() # 声明一个管道,在管道里进行通信
channel.queue_declare(queue='q',durable=True) # durable为队列持久化
def callback(ch, method, properties, body):
print(ch, method, properties, body)
# ch为管道的内存地址,method为关于queue队列的一些信息,body为消息内容
time.sleep(20)
print('收到数据:', body)
ch.basic_ack(delivery_tag=method.delivery_tag) # 跟服务器端确认消息已经处理完成
print('消息处理完成')
channel.basic_consume( # basic_consume开始消费消息
callback, # 如果收到消息就调用callback函数来处理消息
queue='q', # 从q队列里接收消息
)
print('开始等待消息')
channel.start_consuming() # 开始接收消息,如果没有消息就会卡在这,直到有消息
这样的话,即使服务器端断开了,队列和消息也还会在

如果没有使队列和消息持久化的话,服务器端重启后,队列和消息就没了
不同的服务器处理消息的效率不同,RabbitMQ可以使消息公平化,即根据接收消息端的消息处理情况来分配发送消息
两个接收消息端,如果第一个接收消息端的消息没处理完的话,发送消息端发送的消息就只被第二个接收消息端接收,直到第一个接收消息端处理完消息
发送消息端
# -*- coding:utf-8 -*-
__author__ = "MuT6 Sch01aR"
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1'))
channel = connection.channel()
channel.queue_declare(queue='q', durable=True)
channel.basic_publish(
exchange='',
routing_key='q',
body='Hello World!',
)
print('数据发送完成')
connection.close()
接收消息端
# -*- coding:utf-8 -*-
__author__ = "MuT6 Sch01aR"
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1'))
channel = connection.channel()
channel.queue_declare(queue='q', durable=True)
def callback(ch, method, properties, body):
print(ch, method, properties, body)
time.sleep(20)
print('收到数据:', body)
ch.basic_ack(delivery_tag=method.delivery_tag)
print('消息处理完成')
channel.basic_qos(prefetch_count=1) # 使消息公平发送
channel.basic_consume(
callback,
queue='q',
)
print('开始等待消息')
channel.start_consuming()
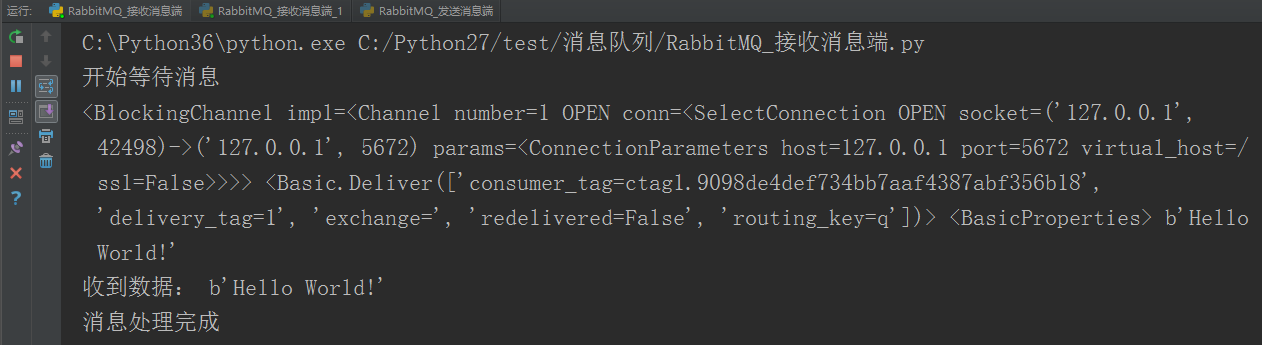
开启2个接收消息端,1个处理消息的时候睡眠20秒,另一个处理消息的时候没有睡眠
运行结果

第一条消息被第一个接收消息端接收并处理
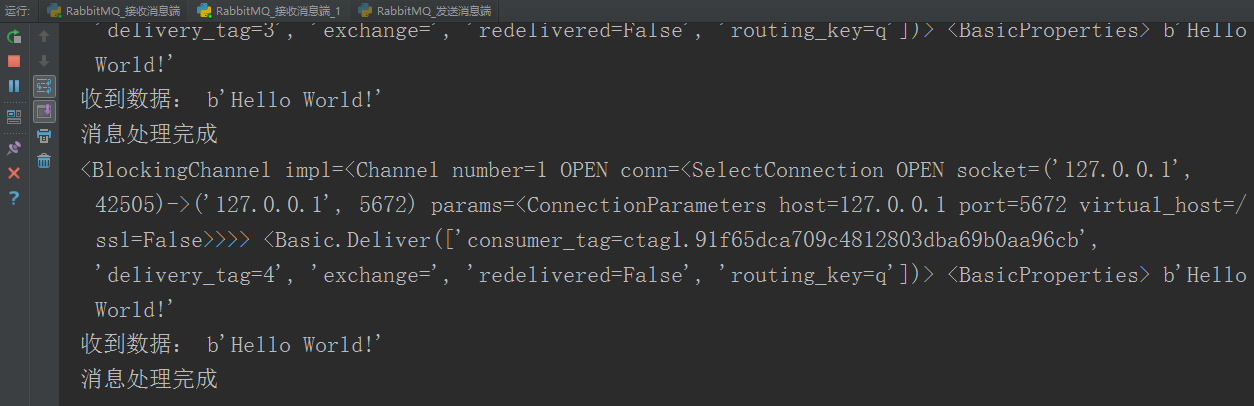
第一个接收消息端处理消息时睡眠20秒,发送消息端之后发送的消息都被第二个接收消息端接收,直到20秒后

 浙公网安备 33010602011771号
浙公网安备 33010602011771号