


图像处理的基础
https://www.zhihu.com/question/39022858
CNN原理
CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显示的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
1. 神经网络
首先介绍神经网络,神经网络的每个单元如下:

其对应的公式如下:
![]()
其中,该单元也可以被称作是Logistic回归模型。当将多个单元组合起来并具有分层结构时,就形成了神经网络模型。下图展示了一个具有一个隐含层的神经网络。

其对应的公式如下:

比较类似的,可以拓展到有2,3,4,5,…个隐含层。
神经网络的训练方法也同Logistic类似,不过由于其多层性,还需要利用链式求导法则对隐含层的节点进行求导,即梯度下降+链式求导法则,专业名称为反向传播。
2 卷积神经网络
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。
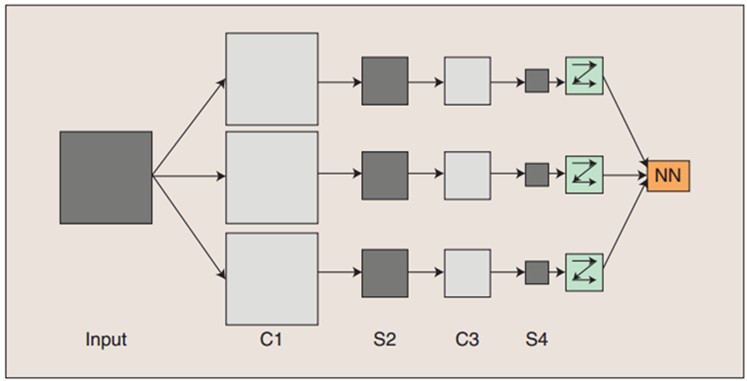
图:卷积神经网络的概念示范:输入图像通过和三个可训练的滤波器和可加偏置进行卷积,卷积后在C1层产生三个特征映射图,然后特征映射图中每组的四个像素再进行求和,加权值,加偏置,通过一个Sigmoid函数得到三个S2层的特征映射图。这些映射图再进过滤波得到C3层。这个层级结构再和S2一样产生S4。最终,这些像素值被光栅化,并连接成一个向量输入到传统的神经网络,得到输出。
一般地,C层为特征提取层,每个神经元的输入与前一层的局部感受野相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来;S层是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数(现在经常被使用的是Relu,还有一种是tanh 见附录1),使得特征映射具有位移不变性。
此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数,降低了网络参数选择的复杂度。卷积神经网络中的每一个特征提取层(C-层)都紧跟着一个用来求局部平均与二次提取的计算层(S-层),这种特有的两次特征提取结构使网络在识别时对输入样本有较高的畸变容忍能力。
2.1 局部感知
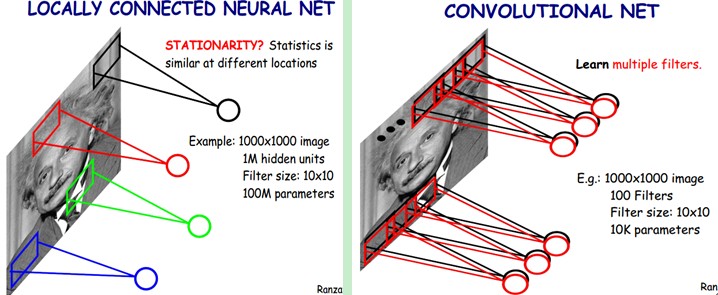
卷积神经网络有两种神器可以降低参数数目,第一种神器叫做局部感知野。一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。如下图所示:左图为全连接,右图为局部连接。

在上右图中,假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的千分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。
2.2 参数共享
但其实这样的话参数仍然过多,那么就启动第二级神器,即权值共享。在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,也就是说每个神经元用的是同一个卷积核去卷积图像。那么参数数目就变为100了,不管隐层的神经元个数有多少,两层间的连接只有100个参数, 这就是权值共享。
怎么理解权值共享呢?我们可以把这100个参数(也就是卷积操作)看成是一种提取特征的方式,该方式与位置无关。类似一种滤波器,提取某个方向的边缘。那么我们需要提取不同的特征,怎么办,加多几种滤波器不就行了吗?对了。所以假设我们加到100种滤波器,每种滤波器的参数不一样,表示它提出输入图像的不同特征,例如不同的边缘。这样每种滤波器去卷积图像就得到对图像的不同特征的放映,我们称之为Feature Map。所以100种卷积核就有100个Feature Map。这100个Feature Map就组成了一层神经元。到这个时候明了了吧。我们这一层有多少个参数了?100种卷积核x每种卷积核共享100个参数=100x100=10K,也就是1万个参数。
如下图所示,展示了一个33的卷积核在55的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。

下图不同的颜色表达不同的滤波器(卷积核)。每个滤波器都会将图像生成为另一幅图像。比如两个滤波器就可以将生成两幅图像,这两幅图像可以看做是一张图像的不同的通道。
2.3隐藏层神经元的个数与权值参数个数之间的关系
刚才说隐藏层的参数个数和隐层的神经元个数无关,只和滤波器的大小和滤波器种类的多少有关。那么隐层的神经元个数怎么确定呢?
它和原图像,也就是输入图像的大小(原矩阵的大小)、滤波器的大小和滤波器在图像中的滑动步长都有关!例如,我的图像是1000x1000像素,而滤波器大小是10x10,假设滤波器没有重叠,也就是步长为10,这样隐藏层的神经元个数就是(1000x1000 )/ (10x10)=100x100个神经元了,假设步长是8,也就是卷积核会重叠两个像素,那么……我就不算了,思想懂了就好。注意了,这只是一种滤波器,也就是一个Feature Map的神经元个数哦,如果100个Feature Map就是100倍了。由此可见,图像越大,神经元个数和需要训练的权值参数个数的差距就越大。
需要注意的一点是,上面的讨论都没有考虑每个神经元的偏置部分。所以权值个数需要加1 。这个也是同一种滤波器共享的。
CNN的第一层一般是卷积层(简写为conv)。一般采用filter(有时称作neuron或者kernel,一般为3*3或者5*5大小的窗口)在整个图像上进行滑动,这个窗口区域就是CNN的感受野(recptive field)。filter一般对应一组数字,也就是权重(weight)或者参数(parameters)。_其中,filter的depth对应输入图像的depth。_filter的结果对应activetion map或者feature map。从高层语义的角度上讲,这些filter可以看作是feature identifiers,比如事物的边缘、颜色、曲线等。
这里面给出另一个了CNN的结构图如下, 来说明一下卷积核应用到feature map上的方式。

1. 关于每一个C层的feature map的个数。
比如C1是6个,C3是16个,这个应该是经验值,或者是通过实验给出的一个比较优的值,这点好多资料都没有说清楚。不过要注意的是,一般后面的要比前面的个数多些。
2. 关于后面的C层。比如S2到C3,并不是一一对应的。
也就是说,并不是对S2中的每一个feature map与后面16个卷积核进行卷积。而是取其中几个。看了下面图应该很容易理解:

纵向是S2层的6个feature map,横向是C3的16个卷积核,X表示两者相连。比如说,第0个卷积核,只用在了前面3个feature map上,把这3个卷积结果加权相加或者平均就得到C3层的第一个(如按照上图标示应该是第0个)feature map。至于这个对应表示怎么来的,也不得而知啊,应该也是经验或者通过大量实验得来的吧。这点还不是很清楚...当然,如果想全部相连也不是不可以,只是对5个相加或者进行加权平均而已(比如第15号卷积核)。
2.4深入理解CNN各层
除了conv层,还有许多其他的辅助层,这些层是为了提供模型的非线性并保持维度,最终提高网络的鲁棒性并减少过拟合风险。经典的CNN结构:
Input -> Conv -> ReLU -> Conv -> ReLU -> Pool -> ReLU -> Conv -> ReLU -> Pool -> Fully Conneted
ConvNets的可视化可以参考Matt Zeiler和Rob Fergus的论文。随着Network越来越深,filter的感受野也越来越大,也就能够量化更大区域的信息。
ReLU (Rectified Linear Units) Layers
在每个conv层后面很容易连接一个非线性层(激活层,activation layer)。激活层的目的是为了在整个系统中引入非线性层(因为conv层是线性操作,只进行了元素间的乘和加运算)。ReLU层能够获得相当于传统的tanh和sigmoid非线性激活函数的精度(详见附录1),而且ReLU计算非常高效,提高了整个网络的训练速度。此外,ReLU能够缓解梯度消失问题(vanishing gradient),这也是导致网络中的低层训练速度非常慢的原因(因为梯度在不同层之间呈现指数形式的下降,可以参考What is the vanishing gradient problem)。ReLU层对输入值应用函数f(x)=max(0,x)函数,相当于抵制了所有的负值。整体上,该层增加了模型的非线性属性,而且整个网络不受conv层感受野的影响。 详细请参考Geoffrey Hinton的paper。
Pooling Layers
ReLU层之后,我们可能会选择连接一个pooling层,也可以看作是降采样层(downsampling)。pooling层有很多种不同类型,最常用的是maxpooling。如下图所示
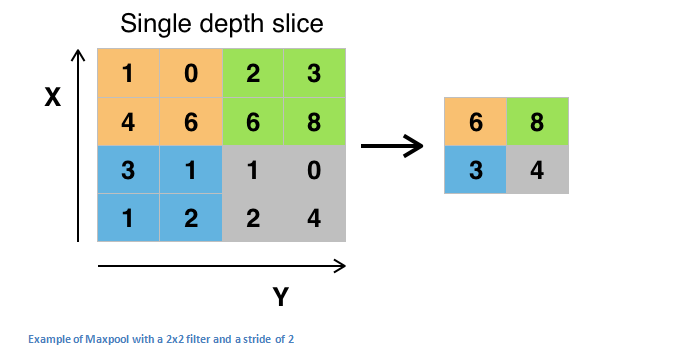
其他类型的pooling层如average pooling和L2-norm pooling。pooling层背后的含义是:一旦确定了原始输入的具体特征,那么其具体位置就没有其相对于其他特征的位置那么重要了。pooling操作彻底降低了空间维度(仅限于长度和宽度,不包括深度)。其主要意义包括:一是参数或者说是权重系数的数量减少了75%,从而减少了计算量;另外一个是有效控制过拟合风险。这一项主要用于模型过于拟合训练样本,针对验证集和测试集泛化能力不足的情况。
Dropout Layers
Dropout层是Neural Network中有着特征功能的层,主要针对过拟合问题。dropout层从一些层中随机丢弃掉一些激活神经元(在Forward pass的过程中设置这些集合为0)。这样的目的主要是强制增加网络的冗余性,也就是说使得模型能够在一些激活神经元丢失的情况下仍然保持分类的正确性。从而使得模型不会对训练数据过于拟合,减少过拟合问题。注意:dropout层只应用于训练阶段,而不用于测试阶段。详细参考Geoffrey Hinton的论文。
Network in Network Layers
Network in network层指的是一个filter为1*1大小的conv层,主要是针对深度信息(比如一个1*1*N的卷积,N表示filter的数量)。详细参考Min Lin的论文。
Fully Connected Layer
conv层以及pool和ReLU层提取高层特征,而CNN网络最后的全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。FC层的输入是conv、pool或者ReLU层的输出,其输出则是一个N维向量,N的大小对应类别的个数。FC层鉴别与高层特征最相关的类别,最终其权重用于得到不同类别的正确概率。
- 如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为h x w的全局卷积,h和w分别为前层卷积结果的高和宽。
- 目前由于全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),近期一些性能优异的网络模型如ResNet和GoogLeNet等均用全局平均池化(global average pooling,GAP)取代FC来融合学到的深度特征,最后仍用softmax等损失函数作为网络目标函数来指导学习过程。需要指出的是,用GAP替代FC的网络通常有较好的预测性能。
下图中连线最密集的2个地方就是全连接层,这很明显的可以看出全连接层的参数的确很多。在前向计算过程,也就是一个线性的加权求和的过程,全连接层的每一个输出都可以看成前一层的每一个结点乘以一个权重系数W,最后加上一个偏置值b得到,即 。如下图中第一个全连接层,输入有50*4*4个神经元结点,输出有500个结点,则一共需要50*4*4*500=400000个权值参数W和500个偏置参数b。
Training
CNN的训练也就是每一层工作的原理,而每层filter值(权重)用到的训练方法就是人工神经网络中常用算法反向传播(Backpropagation)。CNN网络最初的权重(filter值)是随机的,采用Backpropagation算法对权重进行调整。Backpropagation算法主要分为4个部分:Forward pass、Loss function、Backward pass和Weight update。在Forward pass阶段,最初的filter是无法提取有效特征的;Loss function则计算Forward pass阶段预测结果与真实标签之间的误差大小,一般采用MSE(mean squared error),也就是(真实值 - 预测值)平方的一半。Backward pass确定重要的权重并调整权重减小模型整体误差。最后采用梯度下降法完成weight update。
Testing
对于训练好的模型,测试采用不同的数据集进行训练,统计CNN输出结果与GT之间的误差。
How Companies Use CNNs
数据、数据、数据,重要的事情说三遍。训练数据越多,训练的迭代次数越多,权重的更新越多,CNN模型的精度就越高。
Transfer Learning
对于DL一个常见的错觉是:没有像Google这样拥有大型的数据集,就无法构建有效的深度学习模型。当然,数据是Network中关键的部分,但transfer learning能够帮助减少这种对数据的依赖。迁移学习是一个利用预训练模型(网络的权重系数或者大部分的权重系数均已在其他数据集下训练完成)和“fine tuning”对自己数据建模的过程。思路主要:将预训练模型当作特征提取算子,将网络的最后一层换成自己的分类器(主要取决于问题空间),再固定其他层的权重并训练整个网络。
对于预训练的网络(如ImageNet数据集),其网络的低层特征主要对应于边缘和曲线。与其随机初始化权重,可以直接采用预训练模型的权重(固定一些低层的权重值),训练更关注于重要的层(一些高层)。如果数据集与ImageNet非常不同,可以只固定网络一些低层的权重。
具体可以参考Yoshua Bengio的论文、Ali Sharif Razavian的论文、Jeff Donahue的论文。
附录1:




第一个问题:为什么引入非线性激励函数?
正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释balabala)。
第二个问题:为什么引入Relu呢?
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进,具体的大家可以找相关的paper看。
多加一句,现在主流的做法,会多做一步batch normalization,尽可能保证每一层网络的输入具有相同的分布[1]。而最新的paper[2],他们在加入bypass connection之后,发现改变batch normalization的位置会有更好的效果。大家有兴趣可以看下。
[2] He, Kaiming, et al. "Identity Mappings in Deep Residual Networks." arXiv preprint arXiv:1603.05027 (2016).
附录 2:
这一部分主要介绍近年来发表最主要的论文,其中前半部分(AlexNet to ResNet)主要关注通用的网络架构,后半部分则一些其他领域有趣的论文。
AlexNet (2012)
Deep Learning的开端之作(尽管很多人认为1998年Yann LeCun的论文是真正的先驱)。 这篇论文“ImageNet Classification with Deep Convolutional Networks”是这个领域只有影响力的论文之一。Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton提出一种深度卷积神经网络并赢得了 2012 ILSVRC (ImageNet Large-Scale Visual Recognition Challenge)的冠军。
这篇论文主要讨论了AlexNet的架构,主要包括5个conv层、max-pooling层、dropout层和3个fully connected层,架构用于1000个类别的分类。
主要观点:
- 在ImageNet数据集(15million张图像,22000个类别)训练网络;
- 采用ReLU作为非线性函数(相对于传统函数大大减少了训练时间);
- 采用数据augmentation技术(image translations, horizontal reflections, and patch extractions);
- 实现dropout技术减少训练数据的过拟合风险;
- 采用批随机梯度下降法训练模型,并指定具体的momentum和weight decay值;
- 采用GTX 580 GPUs训练5-6天
ZF Net(2013)
ILSVRC 2013的决胜者,由NYU的Matthew Zeiler and Rob Fergus提出的ZF Net,错误率降低为11.2%。这篇论文是对AlexNet的扩展,但同时也有很多独到之处,如作者提出一些提升性能的关键点,关于ConvNet背后机理的一些理解以及如何正确地可视化filter和权重。
论文题目“Visualizing and Understanding Convolutional Neural Networks”,其主要观点:
- 与AlexNet非常相似,但也有一些改进;
- AlexNet采用15million图像训练,ZF Net仅采用了1.3million图像训练;
- ZF Net采用7*7(AlexNet采用11*11大小)的首层filter大小,并降低了stride的大小。主要能够保持更多原始像素信息,而11*11大小则忽略了很多相关信息,尤其是在第一层;
- Network的增长,需要采用更多的filters;
- 激活函数采用ReLUs,误差函数采用cross-entropy损失,采用批随机梯度下降训练网络;
- 采用GTX 580 GPU训练12天;
- 开发了一种可视化技术(Deconvolutional Network),主要用于检查不同特征激活函数以及和输入空间之间的关系。”deconvnet“主要是由于其将特征映射为像素(与convolutional层的作用相反)
DeConvNet
DeConvNet的工作原理:在训练CNN的每层后面连接一层”deconvnet“,增加一条退回到像素的路径。假如要观察4th conv层的某个特征的激活情况,则可以存储这个feature map对应的activations,设置这个层的其他activations为0,将该feature map做为deconvnet的输入,deconvnet和原始CNN的filters相同,然后对每个前面的层作一系列的unpool(reverse maxpooling)、rectify、以及filter操作,直到输入空间。
整个处理过程的机理:我们想要观察什么类型的结构能够激活给定的feature map,比如第一层和第二层(如下图所示):
 ConvNet的第一层通常是一个低层特征检测器,通常检测简单的边缘和特殊情况下的颜色,第二层则检测更多的圆形特征,第三、四、五层如下图所示:
ConvNet的第一层通常是一个低层特征检测器,通常检测简单的边缘和特殊情况下的颜色,第二层则检测更多的圆形特征,第三、四、五层如下图所示:
 这几层则可以看到更多更高层的特征,比如狗的脸或者花朵。需要注意一点:第一层conv层之后一般会跟一个pooling层对图像进行降采样,这使得第二层能够看到原始图像更广的范围。deconvnet的详情可以参考Zeiler相关的presenting(为了方便访问视频已在云盘中共享)。
这几层则可以看到更多更高层的特征,比如狗的脸或者花朵。需要注意一点:第一层conv层之后一般会跟一个pooling层对图像进行降采样,这使得第二层能够看到原始图像更广的范围。deconvnet的详情可以参考Zeiler相关的presenting(为了方便访问视频已在云盘中共享)。
重要提示:ZF Net不仅仅是ILSVRC 2013的冠军,而且提供了更多关于CNNs的理解以及提升性能的一些技巧。可视化的方法不仅有助于解释CNNs的工作机理,而且提供了network架构提升的一些思路。deconv可视化操作和相关的实验都使得论文非常有趣。
VGG Net(2014)
Simplicity and depth。在ILSVRC 2014中将错误率降低为7.3%。University of Oxford的Karen Simonyan and Andrew Zisserman构建一个19层的CNN,严格按照3*3大小的filter、stride和pad设置为1、2*2大小的maxpooling层其stride为2。其要点如下:
- 采用3*3大小的filter(与AlexNet和ZF Net不同),作者的解释是:两个3*3大小的conv层能够拥有5*5大小的感受野,按顺序就可以模拟更大的filter并保持较小filter的优点。其中一个优点就是能够有效减少参数个数;
- 3个conv层连接就能够拥有7*7大小的感受野;
- 每一层输入的空间大小减小,则其对应的深度增大了(因为filter的数量增多了);
- 每个maxpool层后面的filters数量翻倍;
- 适用于图像分类和目标检测,作者将localization看作是驾照操作(参考paper的第10页);
- 采用Caffe构建模型;
- 采用scale jittering作data augmentation技术;
- 每个conv层后面接ReLU层,采用批梯度下降法训练模型;
- 采用4个Nvidia Titan Black GPU训练2-3周
重点:VGG Net的影响体现在其进一步强化了CNNs需要深层网络的观点。Kepp it deep. Kepp it simple.
GoogLeNet(2015)
GoogLeNet是一个22层的CNN并赢得了ILSVRC 2014的冠军,top 5的误差降到了6.7%。GoogLeNet首次提出一种不同于传统CNN中conv和pooling层顺序结构的架构。从下图可以看出,GoogLeNet中所有部分并不是完全按照顺序发生的。其中一部分network可以同时执行。

框中的部分称作Inception module,具体如下图所示。其主要思想是让不同的操作可以同时进行,这也是作者的思想来源。
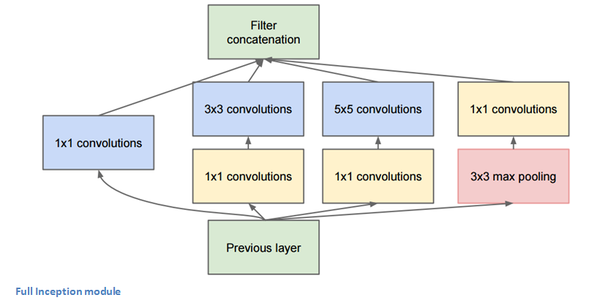
要点:
- 整个架构包括9个Inception modules,超过100层;
- 没有全连接层,而是采用average pool替代,将7*7*1024大小的volume转化为1*1*1024大小的volume,从而节省大量的参数;
- 相对于AlexNet,参数少了12倍;
- 测试阶段同一幅图像采用多种不同的裁剪作为输入,softmax probabilities的均值作为最终解;
- 采用R-CNN的思想作目标检测;
- Inception module不同的更新版本(version 6和7)
- 采用少量高端GPU训练一周
重点:GoogleNet首次提出无需顺序连接的思想,采用Inception module的思想,这种创新型的架构能够有效地提升性能和计算有效性。
Microsoft ResNet (2015)
ResNet是2015年提出的一个152层的网络架构,并赢得了ILSVRC 2015年的冠军,错误率降低到了3.6%(人类的错误率大概在5-10%)。ResNet的重点是Residual Block,其主要思想是让输入经过一系列的conv-relu-conv。给定一些F(x),然后输出结果加上原始输入x,也就是H(x)=F(X)+x。下图是一个计算”delta"(微小变化)的mini模型,传统的CNN网络从x到F(x),而F(x)+x则可以得到其变化,ResNet就是输出微小变化的一种表达。作者认为:相对于原始没有参照的映射,residual映射的优化更容易一些。
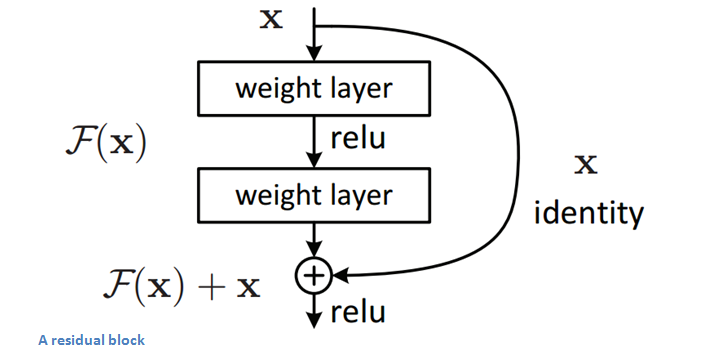
ResNet的residual block高效的另一个原因是其backpropagation的后向传导,由于增加了梯度分散(distribute)操作,其梯度非常容易传导。ResNet的要点:
- 极端深度(ultra-deep),152层——Yann LeCun
- 前两层之后,输入的空间大小从224*224压缩到56*56
- 对于普通的网络增加naive层会导致错误率提升
- 团队训练了一个1202层的网络,却得到更差的精度,可能是由于过拟合
- 在一个8GPU机器上训练2-3周
重点:可以推断在top层增加层数并不总能提升精度,无疑需要提出新的架构。
Bonus:ResNets inside of ResNets.
Region Based CNNs (R-CNN - 2013, Fast R-CNN - 2015, Faster R-CNN - 2015)
R-CNNs的目的是解决目标检测问题,其处理过程可以划分为两个部分:region proposal和classification。作者注解任何agnostic region proposal方法均适合,RCNN中应用了Selective Search。Selective Search能够产生2000个最有可能拥有目标的不同区域,这些proposals可以“warped”为已训练CNNs(比如AlxeNet)对应的图像大小,提取每个区域的特征,这些特征向量用于一系列线性SVMs的输入,训练每个类别并输出分类结果。这些向量作为bounding box regressor的输入并获取精确坐标。非极大值抑制用于抑制那些彼此之间有显著重叠的bounding box。
Fast R-CNN
针对原始模型的3个主要问题进行改进。训练的几个步骤(ConvNets到SVMs到bounding box回归)计算量大,而且非常慢(RCNN每张图像需要53s),Fast R-CNN解决速度问题主要是对不同proposals间的conv层计算共享,并交替产生region proposals,然后运行CNN。
Faster R-CNN
Faster R-CNN在最后的卷积层插入一个region proposal network(RPN),这个network能够只关注最后一层convolutional feature map,并从中产生region proposal。之后的步骤和R-CNN相同(ROI pooling, FC, and then classification and regression heads)。
Generative Adversarial Networks (2014)
据Yann LeCun据说,这种Network可能是下一个大的发展方向。我们先举一些adversarial的例子,比如在ImageNet数据集训练一个CNN,我们对一个样本图像增加一些扰动或者微小的变化,这样会导致预测的误差增大。尽管图像本身看起来非常相似,但预测类别却产生了变化。从最高层上来讲,adversarial样本指是是能够欺骗ConvNets的图像。
Adversarial样本(论文)也顺其自然地成为了研究的热点。我们先来探讨一下generative adversarial network,假设有两个模型,一个generative模型和一个discriminative模型,discriminative模型用来判别给定图像是natural(来源于数据集)还是人工生成的,generative模型则生成图像能够让discirminator得到正确的输出。随着模型的训练,两个模型均得到提升直到无法区分“真实图像”和“伪造图像”。
重点:看上去比较简单,但就像Yann LeCun在Quora的post中所说的那样,由于discriminator经过了理解真实图像和伪造图像之间区别的训练,discriminator具备了提取数据内在表达的能力。因此discriminator可以做为CNN,Plus的特征提取算子,而generative能够生成非常natural的人工图像。
Generating Image Descriptions (2014)
Andrej Karpathy and Fei-Fei Li合作的论文,合并CNNs和bidirectional RNNs(Recurrent Neural Networks)生成不同图像区域的自然语言描述。相当于输入一张图像,输出下图示例。

模型主要包括两个部分:Alignment Model和Generation Model。Alignment Model主要负责排列视觉数据和文字数据(图像及其对应的文字描述)。Generation Model则创建一个数据集生成图像区域集合(RCNN搜索)及其对应的文字描述(BRNN)。
Spatial Transformer Networks (2015)
这篇论文是由Google的Deepmind小组所著,其主要贡献是引入了Spatial Transformer module。其基本思想是该模块变换输入图像使其分类变得容易。与其对CNN的架构进行改进,作者则是考虑在图像输入至某些conv层之前对其进行变换。module主要从2个方面对图像进行改进,pose normalization(scenarios where the object is tilted or scaled)和spatial attention(bringing attention to the correct object in a crowded image)。
传统的CNN中使模型具有尺度和旋转不变性通常需要大量的样本训练模型的这些属性。传统CNN模型处理空间不变性主要在maxpooling层,其主要原理是原始输入中特有的特征,其提取的位置没有其相对于其他特征的位置那么重要。而这种新的spatial transformer能够为每幅输入图像动态产生不同的行为(不同的distortions/transformations),而不是传统的maxpool中预定义的简单变换。module主要包括:
- 采用localization network能够接收输入并输出spatial transformation的参数,参数(theta)指的是仿射变换的6维向量
- localization network中提出一种sampling grid,是对规则格网采用仿射变换(theta)之后的结果
- sampler的目的是对输入的feature map进行warping
这种module可以放入到CNN网络中的任意点,帮助网络学习如何变换feature map从而减小网络误差。
重点:这种篇论文的意义在于其不需要对网络结构进行大的改进就能够提高精度。论文采用简单的思想对输入图像进行仿射变换,从而使得模型具有translation, scale, and rotation的不变性。这里还有一些视频(云盘)和Quora的讨论可以参考。
https://www.zhihu.com/question/39022858
http://blog.csdn.net/zouxy09/article/details/8781543
http://blog.csdn.net/zhoubl668/article/details/24801183
http://dataunion.org/11692.html
https://www.zhihu.com/question/27239198
https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/

