车型识别API调用与批量分类车辆图片
版权声明:本文为博主原创文章,转载 请注明出处 https://blog.csdn.net/sc2079/article/details/82189824
9月9日更:博客资源下载:链接: https://pan.baidu.com/s/1AEtQL7uk4_T7TPKa1Q6kFg 提取码: g1n8 永久有效
-
动机
暑假实习,一位做算法的老师让我们一行人将摄像头拍取的车辆照片按车型分类保存。
示例如下:
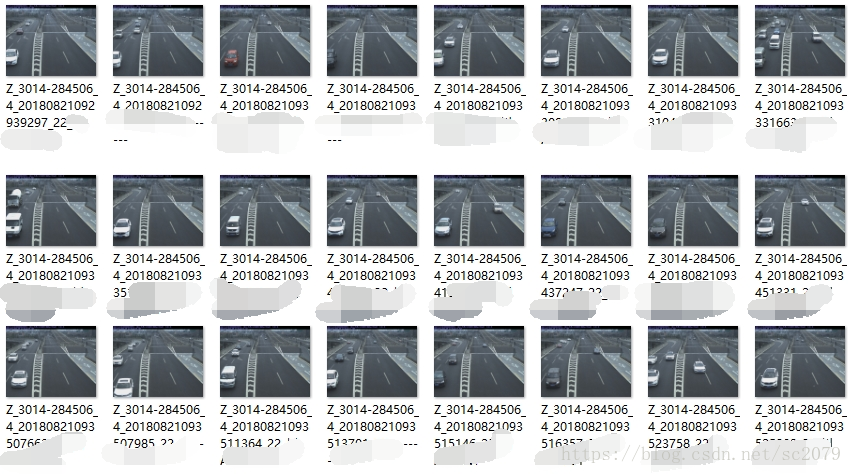
这样的图片共有上万张,且有多个文件夹,人工打开图片、放大,再识别(如果不清楚车辆标志,还需上网查找),并Ctrl+C、Ctrl+V将其保存在相应文件夹下,这着实让人感到无聊与繁琐。
因此,我就萌发了用熟知的python写个脚本,自动化完成工作。
-
开始工作
上面想法很好,但是实际行动起来我还是遇到了很多问题。
首先,技术路线的选取。最简单莫过于直接调用某云上的API接口,但是免费调用次数有限。当然,我最开始也最想采用的是走爬虫路线。有很多网站可以在线上传车辆照片并返回车型结果,我就想利用这一点解决车型识别的问题。然并卵,post请求无法响应,就想向selenium上靠,可是上传文件对话框阻碍了我进一步操作。虽然网上有很多解决对话框的方法,但是碍于时间紧且方法较复杂(短时我无法实现)等种种原因,我不得不采用了最简单直接的方法。PS:如果有做过类似的项目(对话框)的大佬请不吝赐教!
1.环境配置
编译环境:Python3.6,Spyder
依赖模块:shelve,PIL,shutil
2.申请API
打开百度云图像识别的网页链接:https://cloud.baidu.com/product/imagerecognition,创建一个项目,便可以得到API调用的接口。

找到并下载车型识别Python的SDK
车型识别的示例:
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.jpg')
""" 调用车辆识别 """
client.carDetect(image);
""" 如果有可选参数 """
options = {}
options["top_num"] = 3
options["baike_num"] = 5
""" 带参数调用车辆识别 """
client.carDetect(image, options)3.指定目录下所有车型的获得
对API调用返回JSON数据的清洗,提取所需要的信息(取第一个)
car_info=client.carDetect(img)
try:
car_color=car_info['color_result']
except:
car_color='无法识别'
try:
car_name=car_info['result'][0]['name']
car_score=car_info['result'][0]['score']
car_year=car_info['result'][0]['year']
except:
car_name='非车类'
car_score=1
car_year='无年份信息'
car_result=[car_color,car_name,car_score,car_year,file]获取指定目录下的所有车辆照片的车型
path='..'
img_path=path+'\\car_img'
#调用API获取指定目录下所有文件的车型,并将数据保存
m_files=os.listdir(img_path)
for i in range(len(m_files)):
results=[]
files_path=img_path+'\\'+m_files[i]
imgs=os.listdir(files_path)
for j in range(len(imgs)):
#out_path,img=img_cut(m_files[i],imgs[j])
result=get_info(out_path,img)
results.append(result)
data_path=path+'\\'+'data'+'\\'+m_files[i]
shelf_save(results,data_path)实际操作中,发现有些图片识别不出来,便裁剪一下,保留下半部分,竟然发现它能识别了。因此,在上传图片时首先对图片进行了裁剪。
#图片裁剪
def img_cut(file,img):
img_read = Image.open(path+'\\car_img\\'+file+'\\'+img)
a = [0,1300,3310,2600]
box = (a)
roi = img_read.crop(box)
out_path = path+'\\图片处理\\'+file
if not os.path.exists(out_path):
os.mkdir(out_path)
roi.save(out_path+'\\'+img)
return out_path,img我这里使用了shelve模块将每个文件夹数据进行保存与调用
def shelf_load(path):
shelfFile = shelve.open(path)
results=shelfFile['results']
shelfFile.close()
return results
def shelf_save(results,path):
shelfFile = shelve.open(path)
shelfFile['results'] = results
shelfFile.close() 4.根据车型分类建立文件夹
话不多说,直接上代码
#按车型分类建立文件夹
for i in range(len(m_datas)):
_path=path+'\\data\\'+m_datas[i]
datas=shelf_load(_path)
for j in range(len(datas)):
ori_path=img_path+'\\'+m_datas[i]+'\\'+datas[j][4]
if datas[j][1]=='非车类':
if not os.path.exists(path+'\\results\\未知'):
os.mkdir(path+'\\results\\未知')
now_path=path+'\\results\\未知\\'+datas[j][4]
shutil.copy(ori_path,now_path)
continue
for brand in brands:
if brand in datas[j][1]:
if not os.path.exists(path+'\\results\\'+brand):
os.mkdir(path+'\\results\\'+brand)
now_path=path+'\\results\\'+brand+'\\'+datas[j][4]
shutil.copy(ori_path,now_path)
break
if brand=='其他':
if not os.path.exists(path+'\\results\\未知'):
os.mkdir(path+'\\results\\未知')
now_path=path+'\\results\\未知\\'+datas[j][4]
shutil.copy(ori_path,now_path)-
运行结果
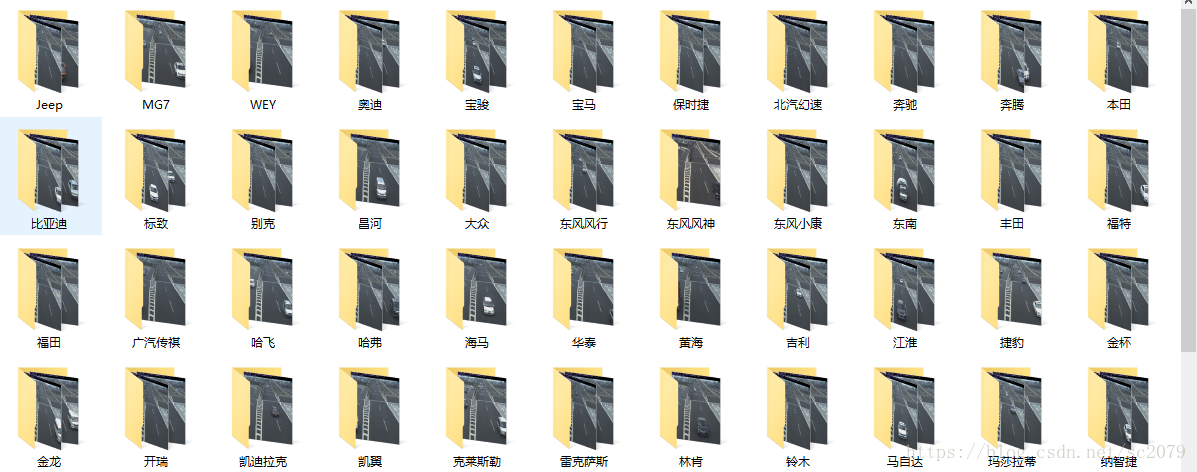
由于调用次数限制,我跑了480张图片,仅有几张无法识别,识别率还可以。至于准确率,我简单翻看了一些目录下的照片,虽然有个别车型识别错误,但大多还可以的。这里仅展示已经自动分类好的文件。
-
结语
由于时间仓促,代码还没整理好。另外其他细节(如存储车型brands数组,获得shelve数据、根文件夹下子文件下有哪些等)这里就不一一展示了。如果实在需要,过段时间我发个Github 链接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号