数据分析 --- 03.数据清洗, 拼接,替换, 映射,排序,分类
一.数据清洗
- 清洗空值
- 清洗重复值
- 清洗异常值
数据的导入与导出:参考博客:
https://www.cnblogs.com/dev-liu/p/pandas_2.html
1.清洗空值
有两种丢失数据:
None
None是Python自带的,其类型为python object。因此,None不能参与到任何计算中。
np.nan(NaN)
np.nan是浮点类型,能参与到计算中。但计算的结果总是NaN。
①.pandas中的None与NaN
pandas中None与np.nan都视作np.nan
创建含空值的数据
from pandas import Series,DataFrame import pandas as pd import numpy as np
df = DataFrame(data=np.random.randint(0,100,size=(10,8))) df.iloc[1,3] = None df.iloc[3,5] = np.nan df.iloc[6,2] = None df.iloc[8,5] = np.nan df

② 删除整行记录
第一种通过判断
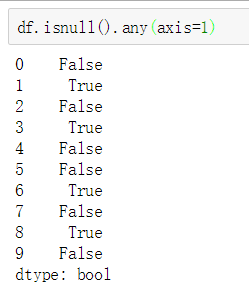

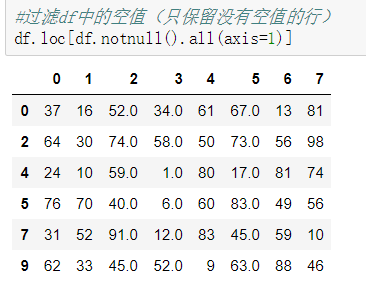
第二种 通过装饰好的内置函数
df.dropna() 可以选择过滤的是行还是列(默认为行):axis中0表示行,1表示的列
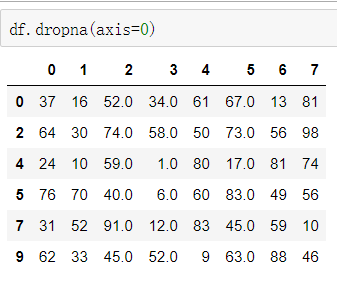
③填充数据
fillna():value和method参数
value : 直接写要填充的值
method: ffill :以前面为基础填充
bfill: 以后面为基础填充
axis: 0 : 列
1 : 行

2.清洗重复值
①创建有重复的数据
import numpy as np import pandas as pd from pandas import Series,DataFrame
df = DataFrame(data=np.random.randint(0,100,size=(8,5)))
df.iloc[2] = [6,6,6,6,6]
df.iloc[4] = [6,6,6,6,6]
df.iloc[6] = [6,6,6,6,6]
df
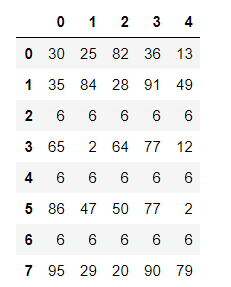
② 使用duplicated 进行去重
参数:
keep:
first:保留第一个
last: 保留最后一个
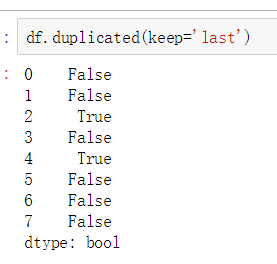

③ 使用drop_duplicates()函数删除重复的行
drop_duplicates(keep='first/last'/False)

3.清洗异常值
①创建数据
df = DataFrame(data=np.random.random(size=(1000,3)),columns=['A','B','C'])
要求:
对df应用筛选条件,去除标准差太大的数据:假设过滤条件为 C列数据大于两倍的C列标准差
std_2 = df['C'].std() * 2 std_2
# 0.5888958710508151
# 取反
~(df['C'] > std_2)

最终:
df.loc[~(df['C'] > std_2)]

二. pandas的拼接操作
1.级联(表的拼接)
pd.concat,
参数:
objs
axis= 0 :列
1 :行
keys
join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),
而inner只会将匹配的项级联到一起,不匹配的不级联
ignore_index=False
pd.append
①创建数据
import numpy as np from pandas import DataFrame,Series import pandas as pd
df1 = DataFrame(data=np.random.randint(0,100,size=(4,4)),index=['A','B','C','D'],columns=['a','b','c','d']) df2 = DataFrame(data=np.random.randint(0,100,size=(4,4)),index=['A','B','C','E'],columns=['a','b','c','e'])
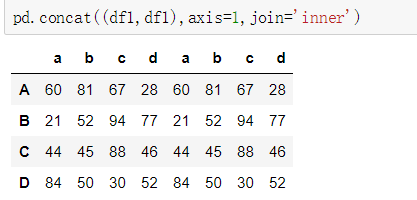
②匹配的级联
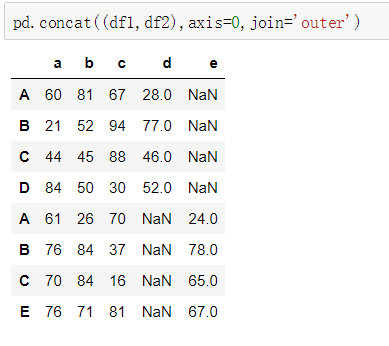
③不匹配的级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有2种连接方式:
外连接:补NaN(默认模式)
内连接:只连接匹配的项
2.合并(数据的拼接)
使用pd.merge()合并
merge与concat的区别在于,merge需要依据某一共同的列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
注意每一列元素的顺序不要求一致
参数:
how:outer取并集 不存在时用 NaN补充, inner取交集, left:以左侧为准, right:以右侧为准
on:当有多列相同的时候,可以使用on来指定使用那一列进行合并,on的值为一个列表
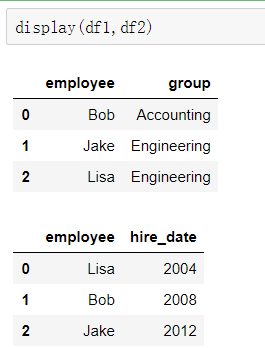
①一对一合并
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
})
df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
})

②多对一合并
df3 = DataFrame({ 'employee':['Lisa','Jake'], 'group':['Accounting','Engineering'], 'hire_date':[2004,2016]})
df4 = DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
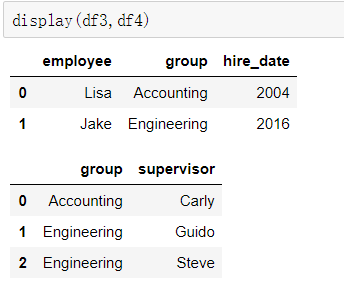
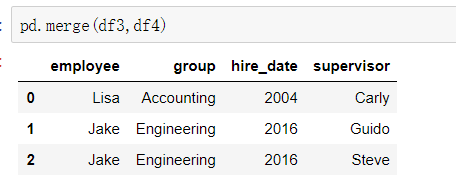
③多对多合并
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df5 = DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
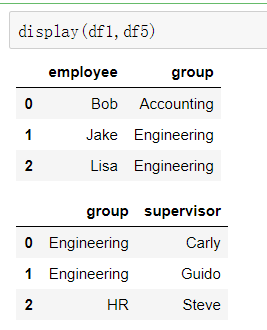
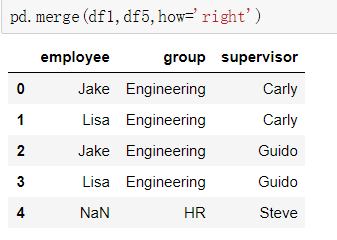
④ key的标准化
第一种:
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名

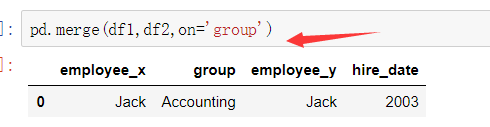
第二种:
当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列


⑤内合并和外合并

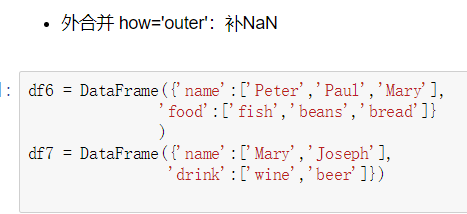
三.替换 (replace)
1.单值替换
普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
按列指定单值替换: to_replace={列标签:替换值}


2.多值替换

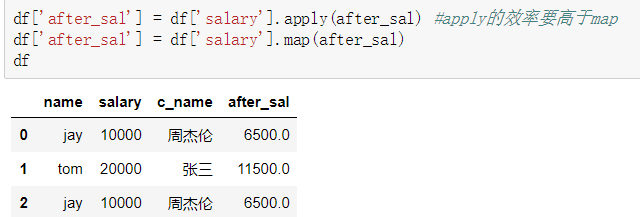
四. 映射(map)
map()可以映射新一列数据
map()中可以使用lambd表达式
map()中可以使用方法,可以是自定义的方法
eg:map({to_replace:value})
注意 map()中不能使用sum之类的函数,for循环

map当做一种运算工具,至于执行何种运算,是由map函数的参数决定的(参数:lambda,函数)
#超过3000部分的钱缴纳50%的税 def after_sal(s): return s - (s - 3000)*0.5
五.排序(随机抽样)
使用.take()函数排序 - take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序 - eg:df.take([1,3,4,2,5])
可以借助np.random.permutation()函数随机排序
np.random.permutation(x)可以生成x个从0-(x-1)的随机数列
df.take(axis=1,indices=np.random.permutation(3)).take(axis=0,indices=np.random.permutation(1000)) df.take(axis=1,indices=np.random.permutation(3)).take(axis=0,indices=np.random.permutation(1000))[0:100]
六. 数据分类处理(重点)
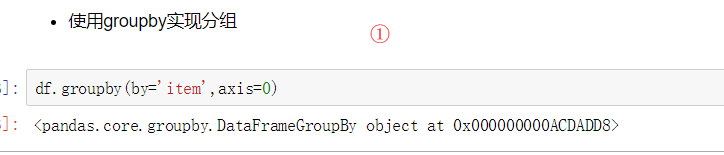
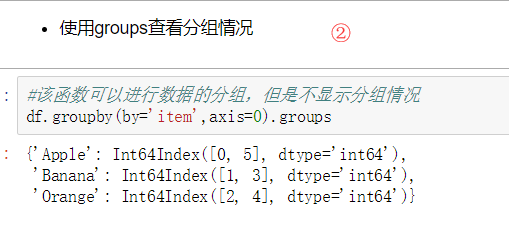
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。 数据分类处理: - 分组:先把数据分为几组 - 用函数处理:为不同组的数据应用不同的函数以转换数据 - 合并:把不同组得到的结果合并起来 数据分类处理的核心: - groupby()函数 - groups属性查看分组情况 - eg: df.groupby(by='item').groups
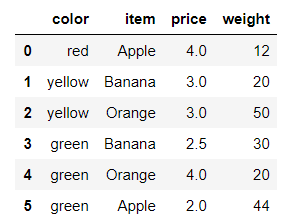
from pandas import DataFrame,Series
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})
df
七.高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
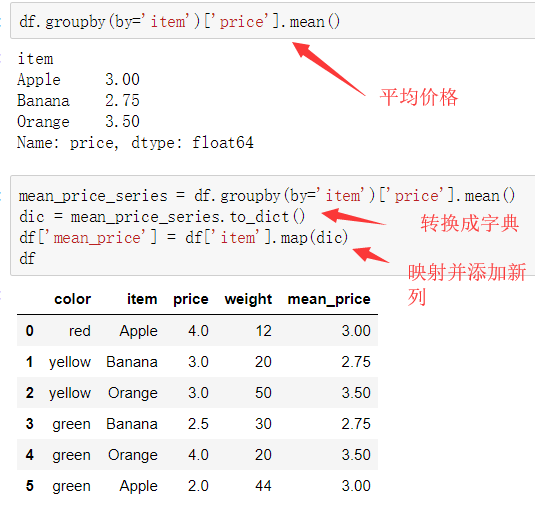
df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum) transform和apply都会进行运算,在transform或者apply中传入函数即可 transform和apply也可以传入一个lambda表达式
# 函数
def fun(s): sum = 0 for i in s: sum+=i return sum/s.size
1. apply

2. transform(可以直接合并,更加方便)

八.案例:
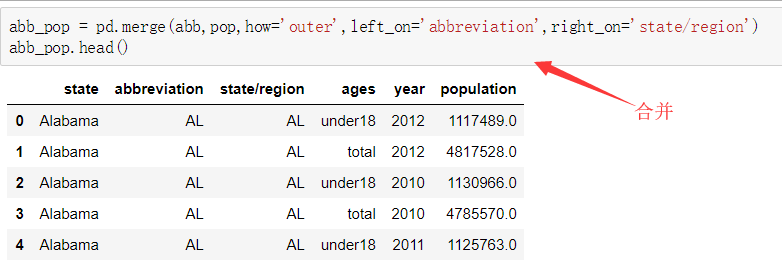
1. 美国各州人口数据分析
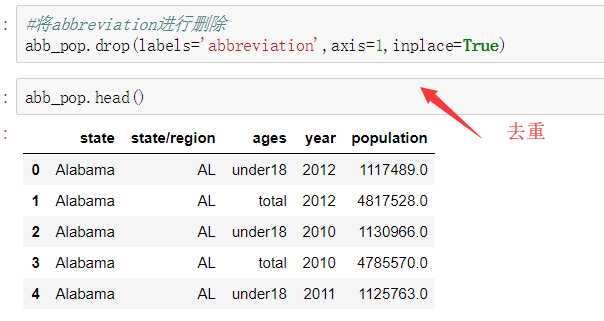
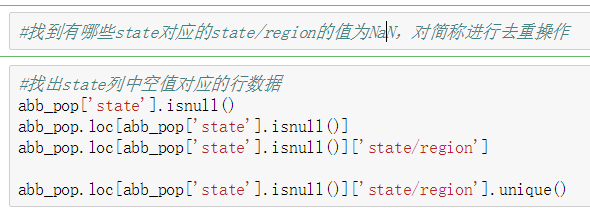
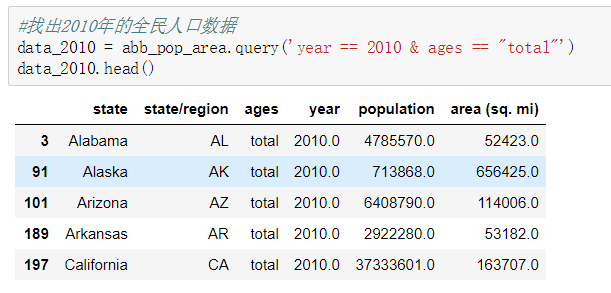
需求: 导入文件,查看原始数据 将人口数据和各州简称数据进行合并 将合并的数据中重复的abbreviation列进行删除 查看存在缺失数据的列 找到有哪些state/region使得state的值为NaN,进行去重操作 为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN 合并各州面积数据areas 我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行 去除含有缺失数据的行 找出2010年的全民人口数据 计算各州的人口密度 排序,并找出人口密度最高的五个州 df.sort_values()







2.美国2012年总统候选人政治献金数据分析
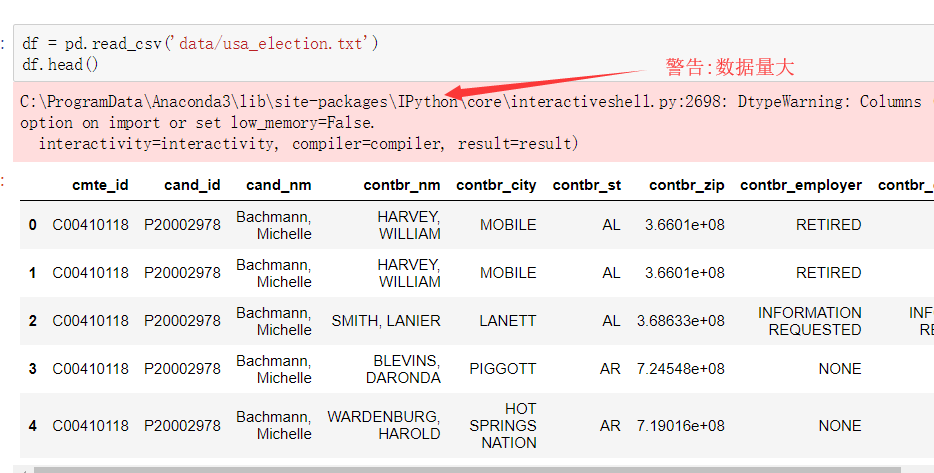
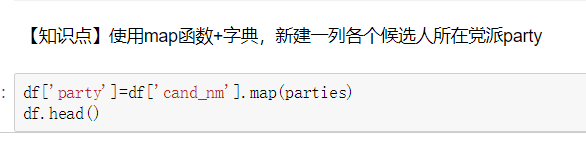
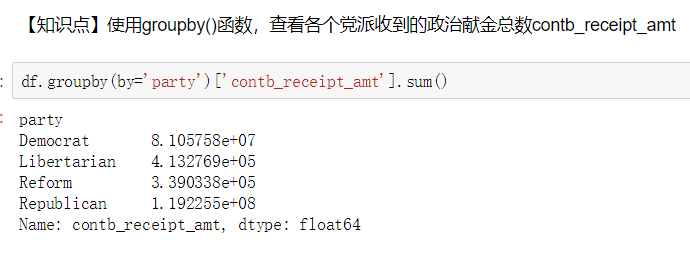
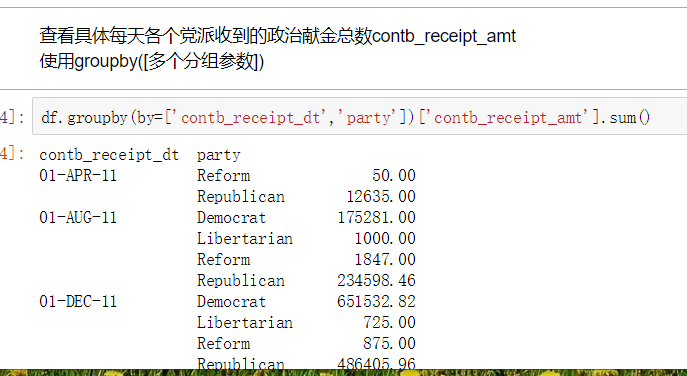
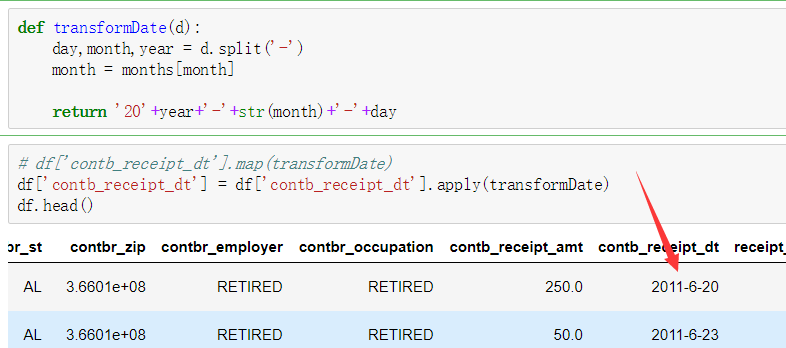
1.读取文件usa_election.txt 2.查看文件样式及基本信息 3.【知识点】使用map函数+字典,新建一列各个候选人所在党派party 4.使用np.unique()函数查看colums:party这一列中有哪些元素 5.使用value_counts()函数,统计party列中各个元素出现次数,value_counts()是Series中的,无参,返回一个带有每个元素出现次数的Series 6.【知识点】使用groupby()函数,查看各个党派收到的政治献金总数contb_receipt_amt 7.查看具体每天各个党派收到的政治献金总数contb_receipt_amt 。使用groupby([多个分组参数]) 8. 将表中日期格式转换为'yyyy-mm-dd'。日期格式,通过函数加map方式进行转换 9.得到每天各政党所收政治献金数目。 考察知识点:groupby(多个字段) 10.【知识点】使用unstack()将上面所得数据中的party行索引变成列索引 11.查看老兵(捐献者职业)DISABLED VETERAN主要支持谁 :查看老兵们捐赠给谁的钱最多 12.把索引变成列,Series变量.reset_index() 13.找出各个候选人的捐赠者中,捐赠金额最大的人的职业以及捐献额 .通过query("查询条件来查找捐献人职业")
import numpy as np import pandas as pd from pandas import Series,DataFrame
months = {'JAN' : 1, 'FEB' : 2, 'MAR' : 3, 'APR' : 4, 'MAY' : 5, 'JUN' : 6,
'JUL' : 7, 'AUG' : 8, 'SEP' : 9, 'OCT': 10, 'NOV': 11, 'DEC' : 12}
of_interest = ['Obama, Barack', 'Romney, Mitt', 'Santorum, Rick',
'Paul, Ron', 'Gingrich, Newt']
parties = {
'Bachmann, Michelle': 'Republican',
'Romney, Mitt': 'Republican',
'Obama, Barack': 'Democrat',
"Roemer, Charles E. 'Buddy' III": 'Reform',
'Pawlenty, Timothy': 'Republican',
'Johnson, Gary Earl': 'Libertarian',
'Paul, Ron': 'Republican',
'Santorum, Rick': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Huntsman, Jon': 'Republican',
'Perry, Rick': 'Republican'
}
读取数据