
git --- 2. 分支,tag, 忽略文件, openpyxl
一.分支
常用指令:
git branch 查看分支 git branch name 创建分支 git checkout name 切换分支 git checkout -b name 创建并切换分支 git branch -d 删除分支 git branch dev origin/dev 创建dev分支并以线上的为蓝本下载 git checkout dev 下载完成要切换 git checkout -b dev origin/dev 下载线上分支并求换到该分支 git merge name 在合并到的分支上做merge
二.tag(标签,版本)
常用指令:
git tag 查看tag git tag -a tagv -m "v2.0" 以当前的位置创建 git tag -a tagv -m "v2.0" hash值 以某次提交为蓝本创建 git tag -d v2.0 删除tag git push origin :refs/tags/tagv 删除远程的tag git push origin --tags 上传所有的tag git pull 下载
三.忽略文件
忽略文件的原则是:
忽略操作系统自动生成的文件,比如缩略图等;
忽略编译生成的中间文件、可执行文件等,也就是如果一个文件是通过另一个文件自动生成的,
那自动生成的文件就没必要放进版本库,比如Java编译产生的.class文件;
忽略你自己的带有敏感信息的配置文件,比如存放口令的配置文件。
①
②
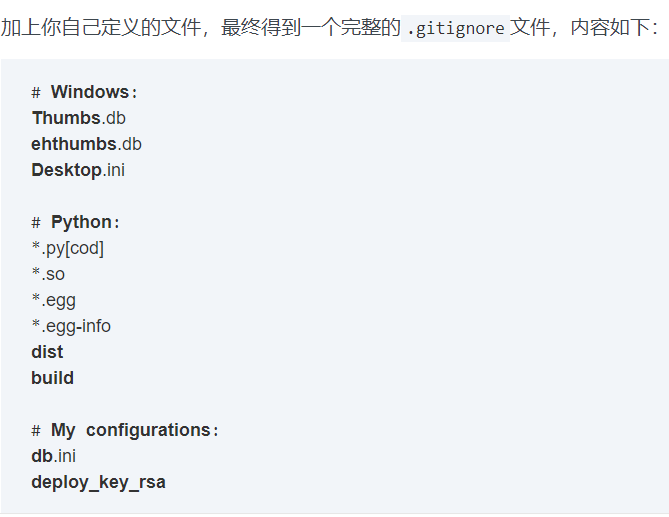
③匹配语法
.gitignore忽略规则的匹配语法 在 .gitignore 文件中,每一行的忽略规则的语法如下: 1)空格不匹配任意文件,可作为分隔符,可用反斜杠转义
2)以“#”开头的行都会被 Git 忽略。即#开头的文件标识注释,可以使用反斜杠进行转义。
3)可以使用标准的glob模式匹配。所谓的glob模式是指shell所使用的简化了的正则表达式。
4)以斜杠"/"开头表示目录;"/"结束的模式只匹配文件夹以及在该文件夹路径下的内容,
但是不匹配该文件;"/"开始的模式匹配项目跟目录;如果一个模式不包含斜杠,则它匹配相对于当前
.gitignore 文件路径的内容,如果该模式不在 .gitignore 文件中,则相对于项目根目录。
5)以星号"*"通配多个字符,即匹配多个任意字符;使用两个星号"" 表示匹配任意中间目录,
比如`a//z`可以匹配 a/z, a/b/z 或 a/b/c/z等。
6)以问号"?"通配单个字符,即匹配一个任意字符;
7)以方括号"[]"包含单个字符的匹配列表,即匹配任何一个列在方括号中的字符。
比如[abc]表示要么匹配一个a,要么匹配一个b,要么匹配一个c;如果在方括号
中使用短划线分隔两个字符,表示所有在这两个字符范围内的都可以匹配。
比如[0-9]表示匹配所有0到9的数字,[a-z]表示匹配任意的小写字母)。
8)以叹号"!"表示不忽略(跟踪)匹配到的文件或目录,即要忽略指定模式以外的文件或目录,
可以在模式前加上惊叹号(!)取反。需要特别注意的是:如果文件的父目录已经被前面的规则排除掉了,
那么对这个文件用"!"规则是不起作用的。也就是说"!"开头的模式表示否定,该文件将会再次被包含,
如果排除了该文件的父级目录,则使用"!"也不会再次被包含。可以使用反斜杠进行转义。
四. openpyxl (操作excel)
pip install openpyxl
1.写文件
from openpyxl import Workbook wb=Workbook() #创建工作簿 # wb1=wb.create_sheet("index") # index 可以指定位置 wb1=wb.create_sheet("index",0)
#修改名称 # wb1.title="test" #添加数据 wb1["A3"]=4 wb1["A4"]=6 # 添加函数 wb1["A5"]='=sum(A3:A4)'
#添加数据的第二种方式 # wb1.cell(row=3,column=4,value=5)
#添加一行数据 # wb1.append(["姓名","年龄","ah","addr"]) #添加一个空行 # wb1.append([]) #添加一行数据 # wb1.append(["alex","","nan","shahe"]) wb.save("1.xlsx")
2.读文件
from openpyxl import load_workbook wb=load_workbook("1.xlsx",data_only=True) #获取工作簿的名称 # print(wb.sheetnames) wb1=wb["index"]
#读方式1 # print(wb1["A3"].value) #读函数的时候,初始化的时候要加data_only=True,要手动的修改并保存 # print(wb1["A5"].value)
#读的第二种方法 # print(wb1.cell(row=3,column=1).value)
# 获取所有行的数据 # for row in wb1.rows: # #获取每一个单元格的数据 # for c in row: # print(c.value)
# 获取所有列的数据 # for column in wb1.columns: # #获取每一个单元格数据 # for r in column: # print(r.value)
#获取最大的行数 print(wb1.max_row) #获取最大的列数 print(wb1.max_column)
