
人工智能 01. 语音合成,语音识别,相似度,图灵机器人,智能对话
一.准备工作(基于百度ai)
1.创建应用
①
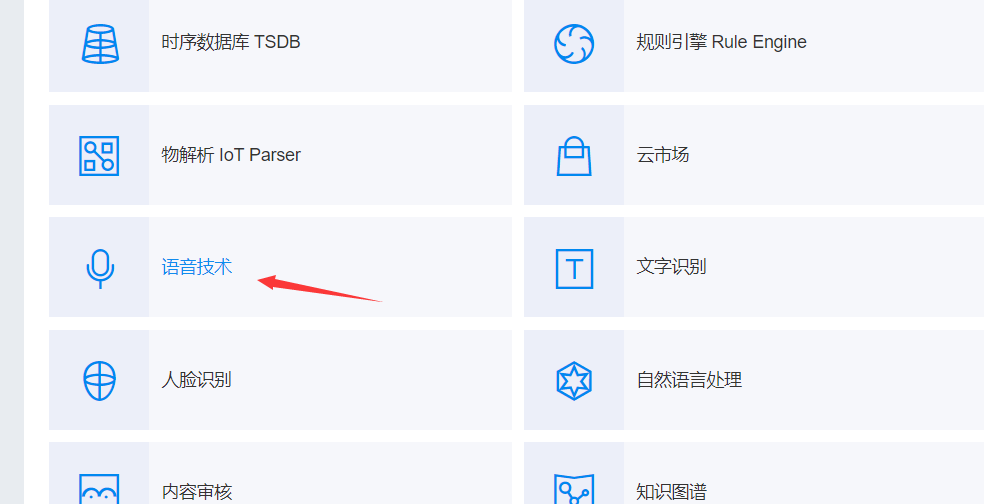
②

③
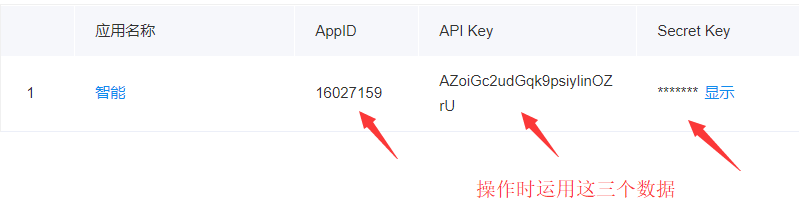
④
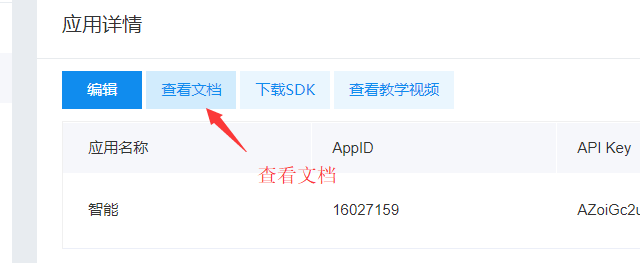
2.用python时,下载模块 baidu-aip

二.语音合成
将 文本 转换成 音频
1.基本框架
from aip import AipSpeech """ 你的 APPID AK SK """ # 接口信息 APP_ID = '16027159' API_KEY = 'AZoiGc2udGqk9psiylinOZrU' SECRET_KEY = '9pa87qO9kkLiCxFjp2vCp9MRvM5LUPgV' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('人的一切痛苦,本质都是对自己无能的愤怒', 'zh', 1, { 'vol': 8, "spd": 4, "pit": 6, "per": 3 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: # 将合成数据放入 auido.mp3 文件中 f.write(result)
2.参数

3.错误时

三.语音识别
将音频 转换成 文本
1.基本框架
from aip import AipSpeech import os """ 你的 APPID AK SK """ APP_ID = '16027159' API_KEY = 'AZoiGc2udGqk9psiylinOZrU' SECRET_KEY = '9pa87qO9kkLiCxFjp2vCp9MRvM5LUPgV' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() # 识别本地文件 res = client.asr(get_file_content('name.pcm'), 'pcm', 16000, { 'dev_pid': 1536, }) print(res.get("result")[0])
2.需要转换格式时
①安装ffmpeg
②配置环境变量
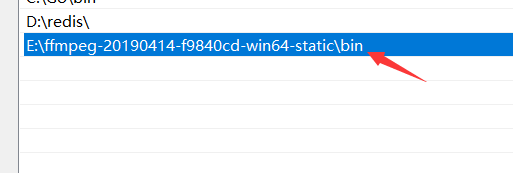
③基本结构
import os from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '16027154' API_KEY = '5a8u0aLf2SxRGRMX3jbZ2VH0' SECRET_KEY = 'UAaqS13z6DjD9Qbjd065dAh0HjbqPrzV' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm")
# 格式转换命令 with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() res = client.asr(get_file_content('name.wav'), 'pcm', 16000, { #pcm格式进行识别率高 'dev_pid': 1536, }) print(res.get("result")[0])
3.先识别,再合成
import os from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '16027159' API_KEY = 'AZoiGc2udGqk9psiylinOZrU' SECRET_KEY = '9pa87qO9kkLiCxFjp2vCp9MRvM5LUPgV' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) def text2audio(text): #⑥ result = client.synthesis(text, 'zh', 1, { 'vol': 8, "spd": 4, "pit": 6, "per": 3 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result) return "auido.mp3" def audio2text(filepath): #② res = client.asr(get_file_content('name.wav'), 'pcm', 16000, { 'dev_pid': 1536, }) return res.get("result")[0] def get_file_content(filePath): #③ os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() text= audio2text('name.wav') # ① if text == "你叫什么": #④ filname = text2audio("我的名字是张三") #⑤ os.system(filname) #⑦
四.相似度
import os from aip import AipSpeech,AipNlp #导入模块 """ 你的 APPID AK SK """ APP_ID = '16027159' API_KEY = 'AZoiGc2udGqk9psiylinOZrU' SECRET_KEY = '9pa87qO9kkLiCxFjp2vCp9MRvM5LUPgV' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) client_nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) #定义新对象 def text2audio(text): result = client.synthesis(text, 'zh', 1, { 'vol': 8, "spd": 4, "pit": 6, "per": 3 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result) return "auido.mp3" def audio2text(filepath): res = client.asr(get_file_content('name.wav'), 'pcm', 16000, { 'dev_pid': 1536, }) return res.get("result")[0] def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() text= audio2text('name.wav') score = client_nlp.simnet("你的名字是什么",text).get('score') # 比较俩个对象,获取相似度 print(score) if score >= 0.58: # 0.58 是分界线(是不是一个意思) filname = text2audio("我的名字是张三") os.system(filname) else: print('结束')
五.图灵机器人
1.创建机器人
①
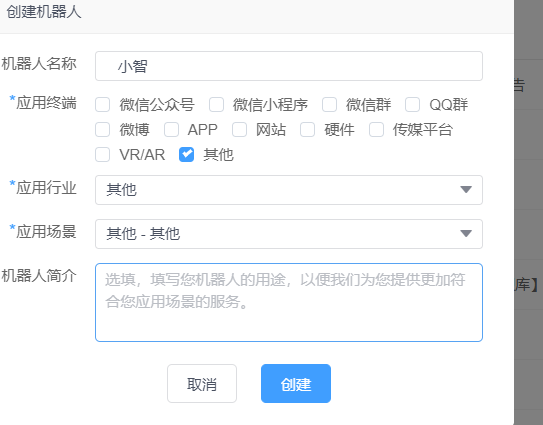
②

③
2.请求示例
{ "reqType":0, "perception": { "inputText": { "text": "附近的酒店" }, "inputImage": { "url": "imageUrl" }, "selfInfo": { "location": { "city": "北京", "province": "北京", "street": "信息路" } } }, "userInfo": { "apiKey": "", "userId": "" } }
3.参数说明
①必填

②至少有一个

③ 可不写
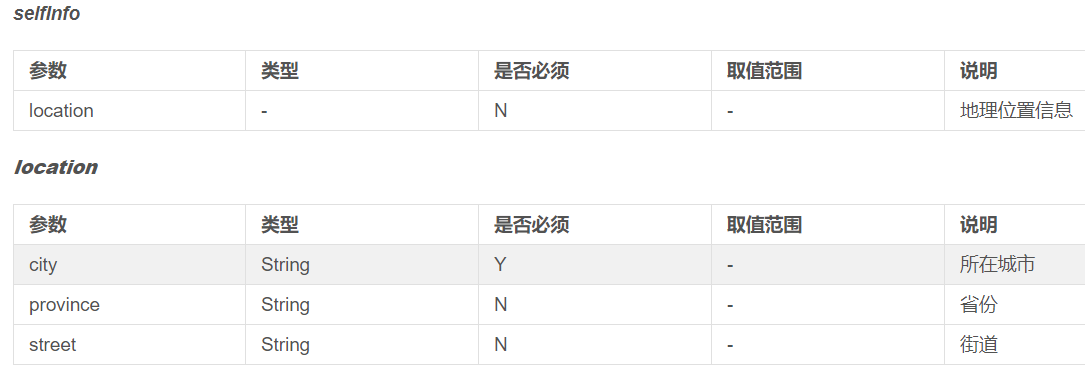
④ 必填
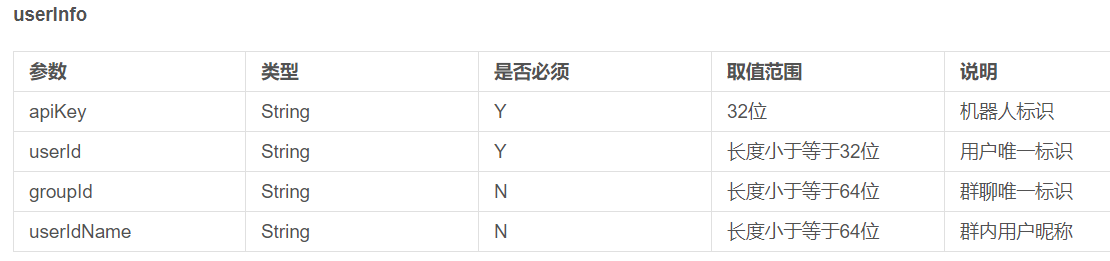
4.示例
URL = "http://openapi.tuling123.com/openapi/api/v2" import requests data = { "perception": { "inputText": { "text": "你叫什么" } }, "userInfo": { "apiKey": "2acbb36ddfcc41b5ae0deb65428eea84", "userId": "123" } } res = requests.post("http://openapi.tuling123.com/openapi/api/v2",json=data) # print(res.content) # print(res.text) print(res.json())
六. 识别+合成+图灵
import os from aip import AipSpeech,AipNlp """ 你的 APPID AK SK """ APP_ID = '16027159' API_KEY = 'AZoiGc2udGqk9psiylinOZrU' SECRET_KEY = '9pa87qO9kkLiCxFjp2vCp9MRvM5LUPgV' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) client_nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) def text2audio(text): result = client.synthesis(text, 'zh', 1, { 'vol': 8, "spd": 4, "pit": 6, "per": 3 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result) return "auido.mp3" def audio2text(filepath): res = client.asr(get_file_content('name.wav'), 'pcm', 16000, { 'dev_pid': 1536, }) return res.get("result")[0] def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def goto_tl(text,uid): URL = "http://openapi.tuling123.com/openapi/api/v2" import requests data = { "perception": { "inputText": { "text": "天气怎样" } }, "userInfo": { "apiKey": "2acbb36ddfcc41b5ae0deb65428eea84", "userId": "123" } } data["perception"]["inputText"]["text"] = text # 替换请求信息 data["userInfo"]["userId"] = uid # 替换标识 res = requests.post(URL, json=data) # print(res.content) # print(res.text) print(res.json()) return res.json().get("results")[0].get("values").get("text") text= audio2text('name.wav') score = client_nlp.simnet("今天天气怎样",text).get('score') print(score) if score >= 0.58: filname = text2audio("我的名字是张三") os.system(filname) answer = goto_tl(text,"qiaoxiaoqiang") # 相似度小于0.58 时走图灵机器人 filename = text2audio(answer) os.system(filename)
七.智能对话
①导入三个文件

② webtoy.html 文件中
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>我是玩具</title> </head> <body> <audio controls id="player" autoplay></audio> <p></p> <button onclick="start_reco()">录音</button> <button onclick="stop_reco()">发送录音</button> </body> <script type="text/javascript" src="/static/Recorder.js"></script> <script type="text/javascript" src="/static/jquery-3.3.1.min.js"></script> <script type="text/javascript"> var serv = "http://127.0.0.1:9527"; var reco = null; var audio_context = new AudioContext();//音频内容对象 navigator.getUserMedia = (navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia); navigator.getUserMedia({audio: true}, create_stream, function (err) { console.log(err) }); function create_stream(user_media) { // audio 麦克风和扬声器 var stream_input = audio_context.createMediaStreamSource(user_media);//媒体流容器 reco = new Recorder(stream_input); } function start_reco() { reco.record(); } function stop_reco() { reco.stop(); reco.exportWAV(function (wav_file) { console.log(wav_file); // Blob 对象 var formdata = new FormData(); // form 表单 {key:value} formdata.append("reco",wav_file); // form - input type="file" name="reco" formdata.append("username","Alexander.DSB.Li"); // form input type="text / password 编辑框" name="username" value = "Alexander.DSB.Li" $.ajax({ url: serv + "/uploader", type: 'post', processData: false, contentType: false, data: formdata, dataType: 'json', success: function (data) { console.log(data); document.getElementById("player").src = serv + "/getaudio/" +data.filename; } }) });//异步 reco.clear(); } </script> </html>
③调用文件 app.py
import os from flask import Flask,render_template,jsonify,request,send_file from uuid import uuid4 # from flask_cors import CORS from FAQ import audio2text, client_nlp, text2audio, goto_tl app = Flask(__name__) # CORS(app) @app.route("/") def webtoy(): return render_template("WebToy.html") @app.route("/uploader",methods=["POST","GET"]) def uploader(): filename = f"{uuid4()}.wav" file = request.files.get("reco") file.save(filename) text = audio2text(filename) # 自然语言处理 LowB score = client_nlp.simnet("你叫什么名字", text).get("score") print(score) if score >= 0.75: filename = text2audio("我的名字叫银角大王八") else: answer = goto_tl(text, "qiaoxiaoqiang") filename = text2audio(answer) return jsonify({"code":0,"msg":"文件上传成功","filename":filename}) @app.route("/getaudio/<filename>") def getaudio(filename): return send_file(filename) if __name__ == '__main__': app.run("127.0.0.1",9527,debug=True)
④ 调用文件用到的函数存在 FAQ.py文件中
import os from uuid import uuid4 from aip import AipSpeech,AipNlp """ 你的 APPID AK SK """ APP_ID = '16027154' API_KEY = '5a8u0aLf2SxRGRMX3jbZ2VH0' SECRET_KEY = 'UAaqS13z6DjD9Qbjd065dAh0HjbqPrzV' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) client_nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) # res = client_nlp.simnet("你叫什么名字","你的名字是什么") # print(res) def text2audio(text): filename = f"{uuid4()}.mp3" result = client.synthesis(text, 'zh', 1, { "spd": 4, 'vol': 5, "pit": 8, "per": 4 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open(filename, 'wb') as f: f.write(result) return filename def audio2text(filepath): res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) print(res) return res.get("result")[0] def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def goto_tl(text,uid): URL = "http://openapi.tuling123.com/openapi/api/v2" import requests data = { "perception": { "inputText": { "text": "你叫什么名字" } }, "userInfo": { "apiKey": "be41cf8596a24aec95b0e86be895cfa9", "userId": "123" } } data["perception"]["inputText"]["text"] = text data["userInfo"]["userId"] = uid res = requests.post(URL, json=data) # print(res.content) # print(res.text) print(res.json()) return res.json().get("results")[0].get("values").get("text")

