
猿人学web端爬虫攻防大赛赛题第19题——乌拉乌拉乌拉
题目网址:https://match.yuanrenxue.cn/match/19
解题步骤
-
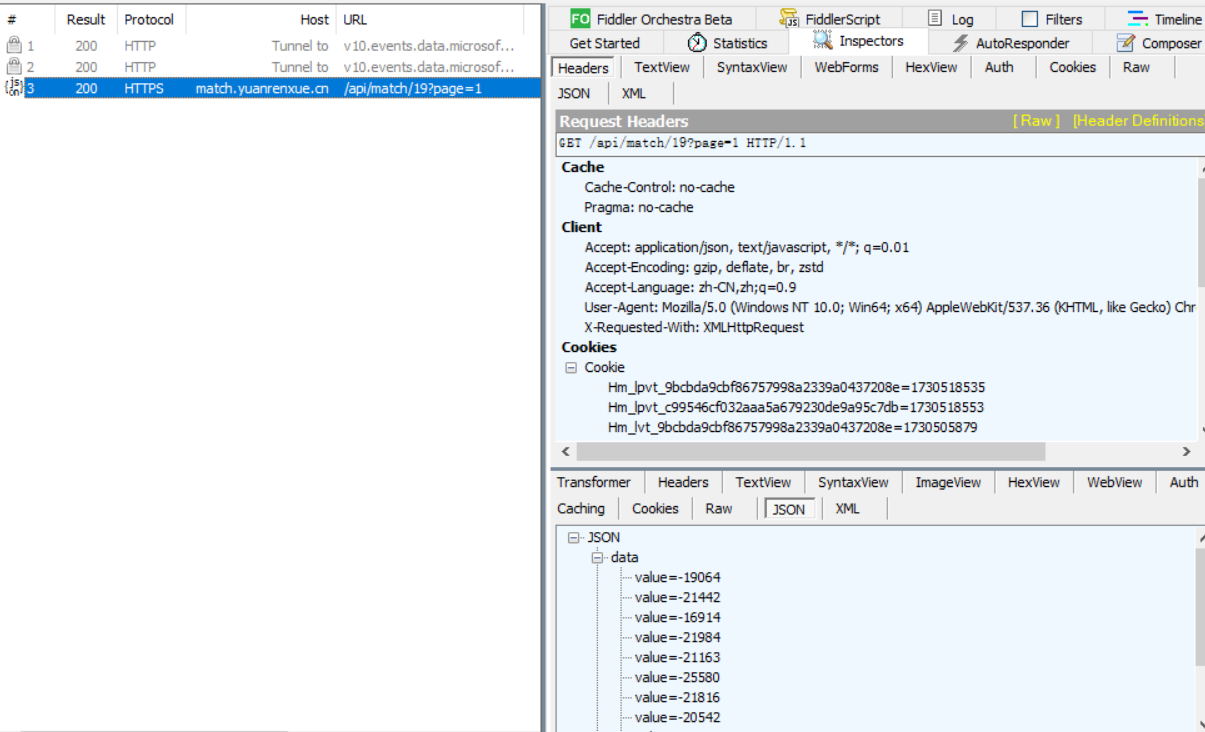
看触发的数据包。
![image]()
![image]()
-
有这么好的事情,没有加密的参数,url非常简单,直接写代码访问。
import requests url = "https://match.yuanrenxue.cn/api/match/19?page=1" headers = {'Host': 'match.yuanrenxue.cn', 'Connection': 'keep-alive', 'Pragma': 'no-cache', 'Cache-Control': 'no-cache', 'sec-ch-ua-platform': '"Windows"', 'X-Requested-With': 'XMLHttpRequest', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'Accept': 'application/json, text/javascript, */*; q=0.01', 'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Dest': 'empty', 'Referer': 'https://match.yuanrenxue.cn/match/16', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1730505879; HMACCOUNT=5B8060E4DC36D34F; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1730505879; qpfccr=true; no-alert3=true; tk=-5370204167750759641; sessionid=39ahw8ftocq8eghmui7twey3qbw7lek8; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1730505890; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1730506377', } resp = requests.get(url, headers=headers) print(resp.text)运行一下,发现啥也获取不到。
![image]()
-
再看数据包,是个http2.0协议,尝试用
httpx库访问。
![image]()
import httpx url = "https://match.yuanrenxue.cn/api/match/19?page=1" headers = {'Host': 'match.yuanrenxue.cn', 'Connection': 'keep-alive', 'Pragma': 'no-cache', 'Cache-Control': 'no-cache', 'sec-ch-ua-platform': '"Windows"', 'X-Requested-With': 'XMLHttpRequest', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'Accept': 'application/json, text/javascript, */*; q=0.01', 'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Dest': 'empty', 'Referer': 'https://match.yuanrenxue.cn/match/16', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1730505879; HMACCOUNT=5B8060E4DC36D34F; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1730505879; qpfccr=true; no-alert3=true; tk=-5370204167750759641; sessionid=39ahw8ftocq8eghmui7twey3qbw7lek8; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1730505890; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1730506377', } client = httpx.Client(http2=True) resp = client.get(url, headers=headers) print(resp.text)运行发现还是啥都获取不到。
![image]()
-
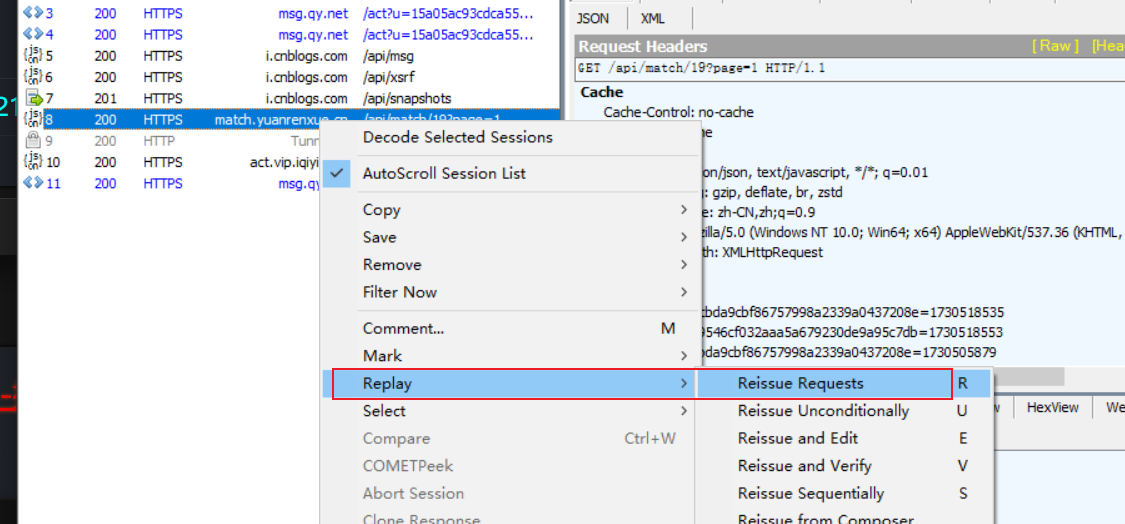
真无厘头啊,尝试用fiddler工具抓包。
![image]()
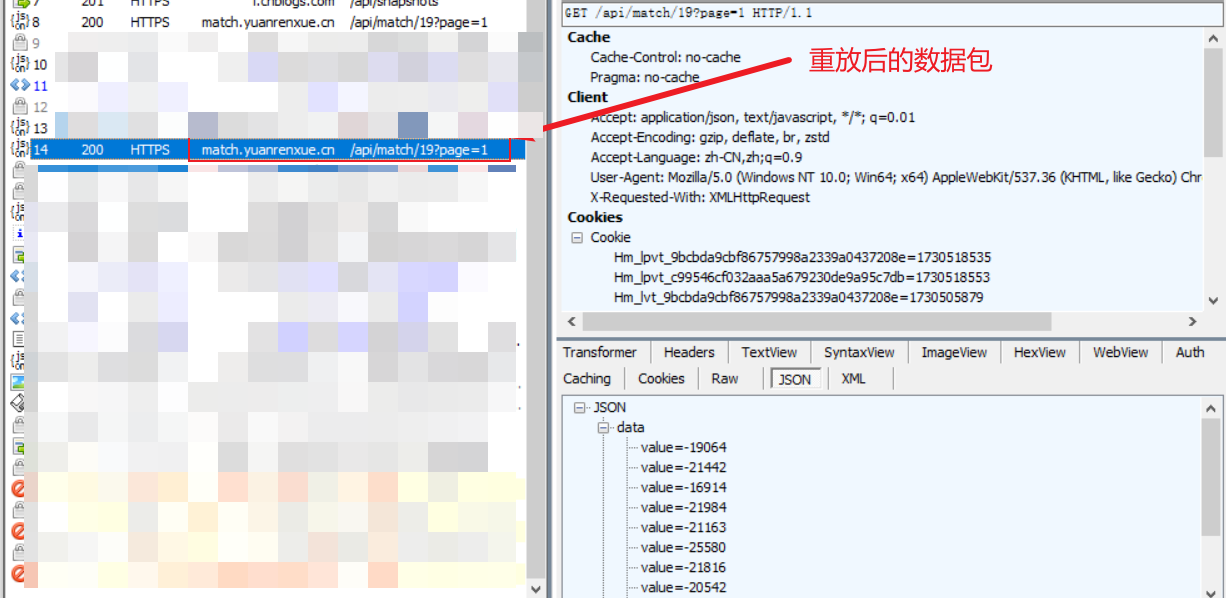
也只有一个数据包,重放一下,发现还是可以正常获取数据。
![image]()
![image]()
-
经过查资料,大概这里是判断了tls指纹。
tls指纹可参考https://developer.baidu.com/article/details/3348512
python中可以通过安装
curl_cffi库来模拟浏览器的tls指纹(在请求时指定 impersonate 关键字参数即可)
安装命令:pip install curl_cffi
![image]()
-
编写代码尝试获取第一页的数据。
from curl_cffi import requests url = "https://match.yuanrenxue.cn/api/match/19?page=1" headers = {'Host': 'match.yuanrenxue.cn', 'Connection': 'keep-alive', 'Pragma': 'no-cache', 'Cache-Control': 'no-cache', 'sec-ch-ua-platform': '"Windows"', 'X-Requested-With': 'XMLHttpRequest', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'Accept': 'application/json, text/javascript, */*; q=0.01', 'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Dest': 'empty', 'Referer': 'https://match.yuanrenxue.cn/match/16', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1730505879; HMACCOUNT=5B8060E4DC36D34F; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1730505879; qpfccr=true; no-alert3=true; tk=-5370204167750759641; sessionid=39ahw8ftocq8eghmui7twey3qbw7lek8; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1730505890; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1730506377', } resp = requests.get(url, headers=headers, impersonate="chrome110") print(resp.text)运行成功获取到页面数据。
![image]()
-
看来我们的思路没错,完整爬虫代码如下。
from curl_cffi import requests import re res_sum = 0 pattern = '{"value": (.*?)}' for i in range(1, 6): url = "https://match.yuanrenxue.cn/api/match/19?page={}".format(i) headers = {'Host': 'match.yuanrenxue.cn', 'Connection': 'keep-alive', 'Pragma': 'no-cache', 'Cache-Control': 'no-cache', 'sec-ch-ua-platform': '"Windows"', 'X-Requested-With': 'XMLHttpRequest', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'Accept': 'application/json, text/javascript, */*; q=0.01', 'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Dest': 'empty', 'Referer': 'https://match.yuanrenxue.cn/match/16', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1730505879; HMACCOUNT=5B8060E4DC36D34F; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1730505879; qpfccr=true; no-alert3=true; tk=-5370204167750759641; sessionid=39ahw8ftocq8eghmui7twey3qbw7lek8; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1730505890; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1730506377', } resp = requests.get(url, headers=headers, impersonate="chrome110") string = resp.text findall = re.findall(pattern, string) for item in findall: res_sum += int(item) print(res_sum)运行得到结果。
![image]()
-
提交结果,成功通过。
![image]()









 浙公网安备 33010602011771号
浙公网安备 33010602011771号