
猿人学web端爬虫攻防大赛赛题第15题——备周则意怠-常见则不疑
1.猿人学web端爬虫攻防大赛赛题第12题——入门级js2.猿人学web端爬虫攻防大赛赛题第13题——入门级cookie3.猿人学web端爬虫攻防大赛赛题第17题——天杀的http2.04.猿人学web端爬虫攻防大赛赛题第1题——js 混淆 - 源码乱码5.猿人学web端爬虫攻防大赛赛题第3题——访问逻辑 - 推心置腹6.猿人学web端爬虫攻防大赛赛题第4题——雪碧图、样式干扰
7.猿人学web端爬虫攻防大赛赛题第15题——备周则意怠-常见则不疑
8.猿人学web端爬虫攻防大赛赛题第16题——js逆向 - window蜜罐9.猿人学web端爬虫攻防大赛赛题第19题——乌拉乌拉乌拉10.猿人学web端爬虫攻防大赛赛题第2题——动态cookie11.猿人学web端爬虫攻防大赛赛题第5题——js 混淆 - 乱码增强12.猿人学web端爬虫攻防大赛赛题第6题——js 混淆 - 回溯13.猿人学web端爬虫攻防大赛赛题第7题——动态字体,随风漂移14.猿人学web端爬虫攻防大赛赛题第20题——2022新春快乐题目网址:https://match.yuanrenxue.cn/match/15
解题步骤
-
看触发的数据包。
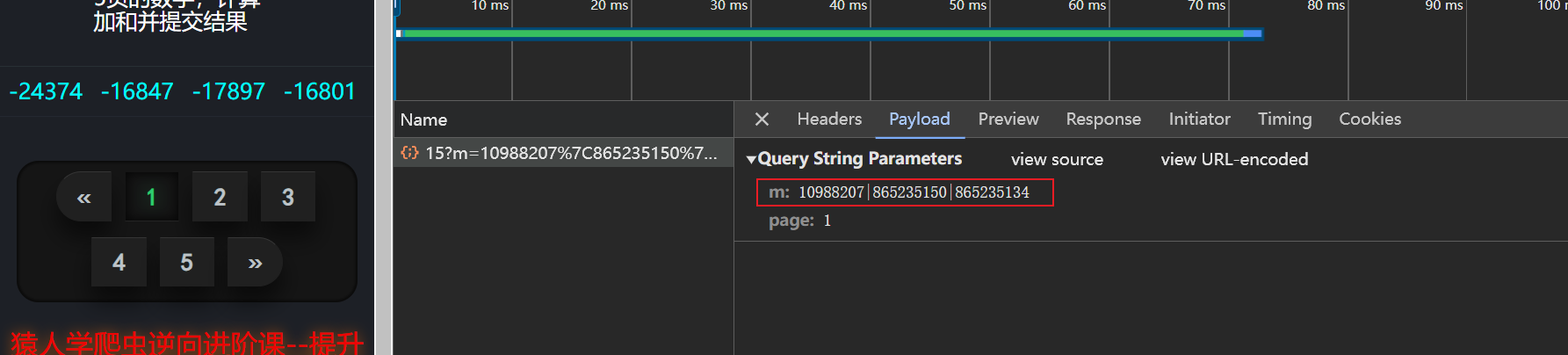

-
有个
m参数,一看就是经过处理的,我们得知道m是如何组成的。看Initiator模块。
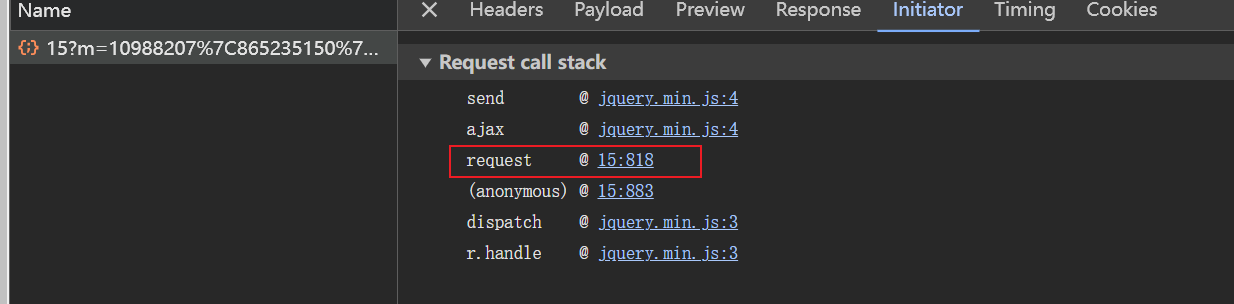
-
还是看
request函数,往上一看就看到了m的赋值操作。
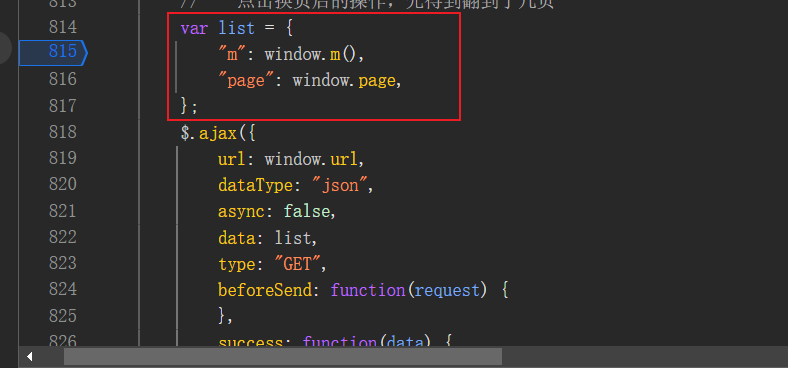
-
打断点,触发。
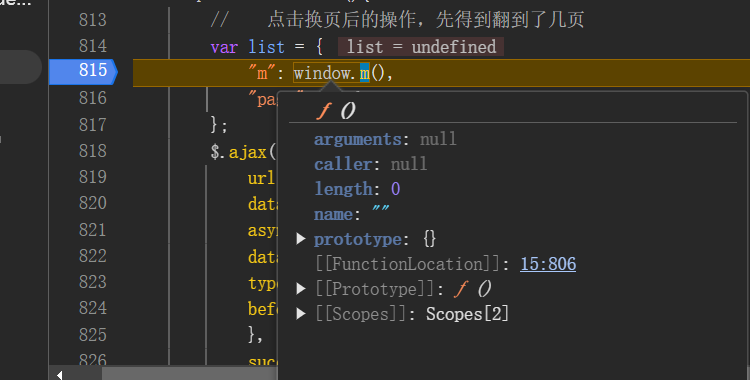
-
看下
window.m()的定义。

-
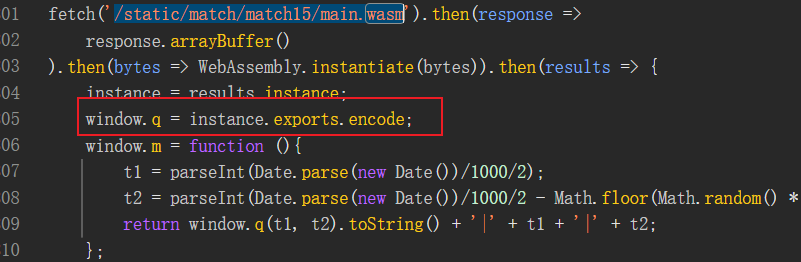
比较好理解的,
t1和t2就是对时间戳做相应的处理,关键是window.q函数,定位一下。

-
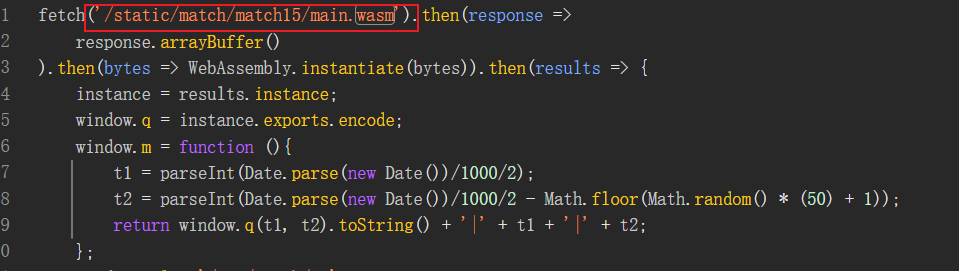
定位的一头雾水,啥也没有呀。回到刚刚的地方,发现它加载了
/static/match/match15/main.wasm文件,可能window.q函数在文件里面定义的。
-
先写代码获取
/static/match/match15/main.wasm文件的内容。
这里需要利用python的第三方库:pywasm
安装:pip install pywasm==1.0.8一开始安装pywasm库的时候没有指定版本,导致我的程序一直报错,后来指定版本为1.0.8后报错消失。
import pywasm wasm_url = "https://match.yuanrenxue.cn/static/match/match15/main.wasm" resp1 = requests.get(wasm_url) with open("main.wasm", mode="wb") as file: file.write(resp1.content)wasm文件:WASM(WebAssembly)是一种为浏览器设计的二进制指令格式,它使得开发者能够以一种安全、快速和跨平台的方式在Web上运行高性能代码。 WASM 是一种编译目标,类似于机器码,但它是为Web设计的,旨在解决C、C++、Rust等编程语言在Web上运行的问题。
-
尝试调用wasm文件中的encode函数来完成
m的生成。
import requests import time import random import math import pywasm wasm_url = "https://match.yuanrenxue.cn/static/match/match15/main.wasm" resp1 = requests.get(wasm_url) with open("main.wasm", mode="wb") as file: file.write(resp1.content) t1 = int(time.time() / 2) t2 = int(time.time() / 2 - math.floor(random.random() * 50 + 1)) module = pywasm.load('./main.wasm') result = module.exec('encode', [t1, t2]) m = "{}|{}|{}".format(result, t1, t2) print(m)运行得到如下结果,形式与数据包中一致。

-
编写最终代码。
import requests import time import random import math import pywasm import re wasm_url = "https://match.yuanrenxue.cn/static/match/match15/main.wasm" resp1 = requests.get(wasm_url) with open("main.wasm", mode="wb") as file: file.write(resp1.content) res_sum = 0 for i in range(1, 6): t1 = int(time.time() / 2) t2 = int(time.time() / 2 - math.floor(random.random() * 50 + 1)) module = pywasm.load('./main.wasm') result = module.exec('encode', [t1, t2]) m = "{}|{}|{}".format(result, t1, t2) url = "https://match.yuanrenxue.cn/api/match/15?m={}&page={}".format(m, i) headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 " "Safari/537.36", "cookie": "Hm_lvt_9bcbda9cbf86757998a2339a0437208e=xxxx; HMACCOUNT=xxxx; " "Hm_lvt_c99546cf032aaa5a679230de9a95c7db=xxxx; no-alert3=true; tk=-xxxx; " "sessionid=xxxx; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=xxxx; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=xxxx", } resp = requests.get(url, headers=headers) string = resp.text pattern = '{"value": (.*?)}' findall = re.findall(pattern, string) for item in findall: res_sum += int(item) print(res_sum)运行得到最终结果。

-
提交结果,成功通过。

合集:
猿人学爬虫攻防刷题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】