
猿人学web端爬虫攻防大赛赛题第3题——访问逻辑 - 推心置腹
1.猿人学web端爬虫攻防大赛赛题第12题——入门级js2.猿人学web端爬虫攻防大赛赛题第13题——入门级cookie3.猿人学web端爬虫攻防大赛赛题第17题——天杀的http2.04.猿人学web端爬虫攻防大赛赛题第1题——js 混淆 - 源码乱码
5.猿人学web端爬虫攻防大赛赛题第3题——访问逻辑 - 推心置腹
6.猿人学web端爬虫攻防大赛赛题第4题——雪碧图、样式干扰7.猿人学web端爬虫攻防大赛赛题第15题——备周则意怠-常见则不疑8.猿人学web端爬虫攻防大赛赛题第16题——js逆向 - window蜜罐9.猿人学web端爬虫攻防大赛赛题第19题——乌拉乌拉乌拉10.猿人学web端爬虫攻防大赛赛题第2题——动态cookie11.猿人学web端爬虫攻防大赛赛题第5题——js 混淆 - 乱码增强12.猿人学web端爬虫攻防大赛赛题第6题——js 混淆 - 回溯13.猿人学web端爬虫攻防大赛赛题第7题——动态字体,随风漂移14.猿人学web端爬虫攻防大赛赛题第20题——2022新春快乐题目网址:https://match.yuanrenxue.cn/match/3
解题步骤
- 看触发的流量包。
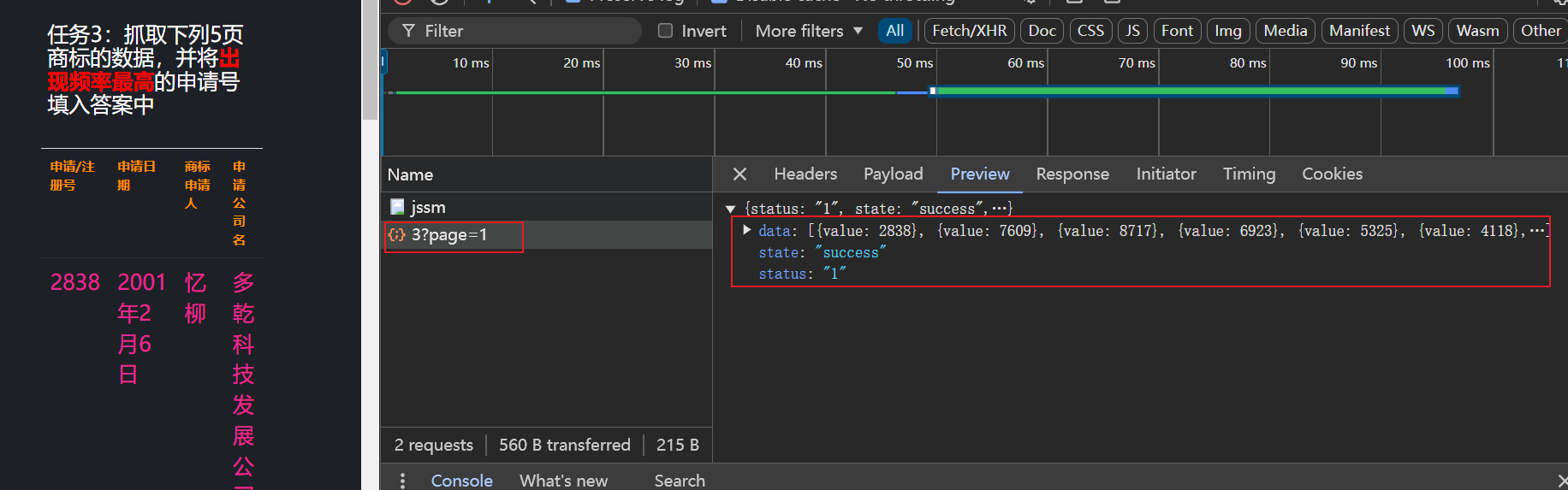
- 再看当前流量包中有没有什么特殊的字段。
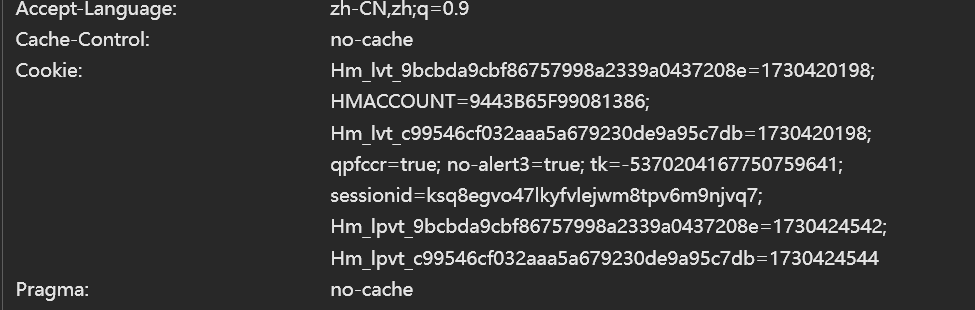
- 没看到有特殊的字段,直接写代码访问。
import requests url = "https://match.yuanrenxue.cn/api/match/3?page=1" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1730420198; HMACCOUNT=9443B65F99081386; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1730420198; qpfccr=true; no-alert3=true; tk=-5370204167750759641; sessionid=ksq8egvo47lkyfvlejwm8tpv6m9njvq7; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1730422463; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1730422463' } resp = requests.get(url, headers=headers) print(resp.text)var x = "div@Expires@@captcha@while@length@@reverse@0xEDB88320@substr@fromCharCode@234@@0@@@11@1500@@cookie@@36@createElement@JgSe0upZ@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@@@eval@@window@href@GMT@String@attachEvent@false@toLowerCase@@2@Array@@@@Path@@@@f@if@@@26@@addEventListener@@@try@return@location@toString@@@@@@pathname@@@@setTimeout@@replace@a@innerHTML@@@@1589175086@else@@document@3@@@@https@join@for@@DOMContentLoaded@06@e@@@@@new@catch@var@@May@@split@@function@1@charAt@@__jsl_clearance@0xFF@firstChild@search@31@chars@charCodeAt@20@parseInt@8@@match@RegExp@Mon@challenge@@g@onreadystatechange@@d@".replace(/@*$/, "").split("@"), y = "1L N=22(){1i('17.v=17.1e+17.29.1k(/[\\?|&]4-2k/,\\'\\')',i);1t.k='26=1q.c|e|'+(22(){1L t=[22(N){16 s('x.b('+N+')')},(22(){1L N=1t.n('1');N.1m='<1l v=\\'/\\'>1H</1l>';N=N.28.v;1L t=N.2h(/1y?:\\/\\//)[e];N=N.a(t.6).A();16 22(t){1A(1L 1H=e;1H<t.6;1H++){t[1H]=N.24(t[1H])};16 t.1z('')}})()],1H=[[[-~[-~(-~((-~{}|-~[]-~[])))]]+[-~[-~(-~((-~{}|-~[]-~[])))]],[((+!~~{})<<-~[-~-~{}])]+[((+!~~{})<<-~[-~-~{}])],[-~[-~(-~((-~{}|-~[]-~[])))]]+[((+!~~{})<<-~[-~-~{}])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[(+!![[][[]]][23])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+(C-~[-~-~{}]+[]+[[]][e]),(C-~[-~-~{}]+[]+[[]][e])+(C-~[-~-~{}]+[]+[[]][e]),[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+(-~[]+[]+[[]][e]),(-~[]+[]+[[]][e])+(-~[]+[]+[[]][e])+(-~[-~-~{}]+[[]][e]),(-~[]+[]+[[]][e])+(-~[]+[]+[[]][e])+[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[-~-~{}],[((+!~~{})<<-~[-~-~{}])]+[-~-~{}],(-~[]+[]+[[]][e])+[(+!![[][[]]][23])]+[(+!![[][[]]][23])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]],(-~[]+[]+[[]][e])+[(+!![[][[]]][23])]+[(+!![[][[]]][23])]],[[-~[-~(-~((-~{}|-~[]-~[])))]]],[[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})]+[((+!~~{})<<-~[-~-~{}])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[(+!![[][[]]][23])],[((+!~~{})<<-~[-~-~{}])]+(C-~[-~-~{}]+[]+[[]][e]),(-~[]+[]+[[]][e])+(-~[]+[]+[[]][e])+(-~[-~-~{}]+[[]][e]),[((+!~~{})<<-~[-~-~{}])]+[((+!~~{})<<-~[-~-~{}])],(C-~[-~-~{}]+[]+[[]][e])+[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})],[-~[-~(-~((-~{}|-~[]-~[])))]]+[-~[-~(-~((-~{}|-~[]-~[])))]],(-~[]+[]+[[]][e])+(-~[]+[]+[[]][e])+[-~[-~(-~((-~{}|-~[]-~[])))]],(C-~[-~-~{}]+[]+[[]][e])+[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})],(-~[]+[]+[[]][e])+(-~[]+[]+[[]][e])+(-~[-~-~{}]+[[]][e]),[[1u]*(1u)]+[((+!~~{})<<-~[-~-~{}])]],[[[1u]*(1u)]],[(-~[-~-~{}]+[[]][e])+[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]],(C-~[-~-~{}]+[]+[[]][e])+(-~[]+[]+[[]][e]),[-~[-~(-~((-~{}|-~[]-~[])))]]+[((+!~~{})<<-~[-~-~{}])]]];1A(1L N=e;N<1H.6;N++){1H[N]=t.8()[(-~[]+[]+[[]][e])](1H[N])};16 1H.1z('')})()+';2=2j, h-1N-2d 1D:2a:10 w;H=/;'};M((22(){15{16 !!u.12;}1K(1E){16 z;}})()){1t.12('1C',N,z)}1r{1t.y('2n',N)}", f = function (x, y) { var a = 0, b = 0, c = 0; x = x.split(""); y = y || 99; while ((a = x.shift()) && (b = a.charCodeAt(0) - 77.5)) c = (Math.abs(b) < 13 ? (b + 48.5) : parseInt(a, 36)) + y * c; return c }, z = f(y.match(/\w/g).sort(function (x, y) { return f(x) - f(y) }).pop()); while (z++) try { debugger; eval(y.replace(/\b\w+\b/g, function (y) { return x[f(y, z) - 1] || ("_" + y) })); break } catch (_) { } - 难道是跟这串代码相关,代码比较复杂,直接看输出是什么。最后执行
eval(y.replace(/\b\w+\b/g, function(y){return x[f(y,z)-1]||("_"+y)})),运行的时候记得把debugger给注释了。

- 没有输出结果,也没有结束执行,把
eval换成console.log看看,得到结果如下。catch _N=split(){_1i('return.href=return._1e+return.0xFF._1k(/[\?|&]captcha-RegExp/,\'\')',1500);_1t.cookie='charAt=_1q.234|0|'+(split(){catch _t=[split(_N){try eval('String.fromCharCode('+_N+')')},(split(){catch _N=_1t.createElement('div');_N.a='<replace href=\'/\'>_1H</replace>';_N=_N.__jsl_clearance.href;catch _t=_N.8(/_1y?:\/\//)[0];_N=_N.substr(_t.length).toLowerCase();try split(_t){join(catch _1H=0;_1H<_t.length;_1H++){_t[_1H]=_N.function(_t[_1H])};try _t.https('')}})()],_1H=[[[-~[-~(-~((-~{}|-~[]-~[])))]]+[-~[-~(-~((-~{}|-~[]-~[])))]],[((+!~~{})<<-~[-~-~{}])]+[((+!~~{})<<-~[-~-~{}])],[-~[-~(-~((-~{}|-~[]-~[])))]]+[((+!~~{})<<-~[-~-~{}])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[(+!![[][[]]][_23])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+(2-~[-~-~{}]+[]+[[]][0]),(2-~[-~-~{}]+[]+[[]][0])+(2-~[-~-~{}]+[]+[[]][0]),[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+(-~[]+[]+[[]][0]),(-~[]+[]+[[]][0])+(-~[]+[]+[[]][0])+(-~[-~-~{}]+[[]][0]),(-~[]+[]+[[]][0])+(-~[]+[]+[[]][0])+[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[-~-~{}],[((+!~~{})<<-~[-~-~{}])]+[-~-~{}],(-~[]+[]+[[]][0])+[(+!![[][[]]][_23])]+[(+!![[][[]]][_23])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]],(-~[]+[]+[[]][0])+[(+!![[][[]]][_23])]+[(+!![[][[]]][_23])]],[[-~[-~(-~((-~{}|-~[]-~[])))]]],[[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})]+[((+!~~{})<<-~[-~-~{}])],[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]]+[(+!![[][[]]][_23])],[((+!~~{})<<-~[-~-~{}])]+(2-~[-~-~{}]+[]+[[]][0]),(-~[]+[]+[[]][0])+(-~[]+[]+[[]][0])+(-~[-~-~{}]+[[]][0]),[((+!~~{})<<-~[-~-~{}])]+[((+!~~{})<<-~[-~-~{}])],(2-~[-~-~{}]+[]+[[]][0])+[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})],[-~[-~(-~((-~{}|-~[]-~[])))]]+[-~[-~(-~((-~{}|-~[]-~[])))]],(-~[]+[]+[[]][0])+(-~[]+[]+[[]][0])+[-~[-~(-~((-~{}|-~[]-~[])))]],(2-~[-~-~{}]+[]+[[]][0])+[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})],(-~[]+[]+[[]][0])+(-~[]+[]+[[]][0])+(-~[-~-~{}]+[[]][0]),[[document]*(document)]+[((+!~~{})<<-~[-~-~{}])]],[[[document]*(document)]],[(-~[-~-~{}]+[[]][0])+[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]],(2-~[-~-~{}]+[]+[[]][0])+(-~[]+[]+[[]][0]),[-~[-~(-~((-~{}|-~[]-~[])))]]+[((+!~~{})<<-~[-~-~{}])]]];join(catch _N=0;_N<_1H.length;_N++){_1H[_N]=_t.reverse()[(-~[]+[]+[[]][0])](_1H[_N])};try _1H.https('')})()+';Expires=match, 11-_1N-chars DOMContentLoaded:firstChild:_10 GMT;Path=/;'};if((split(){_15{try !!window._12;}new(06){try false;}})()){_1t._12('_1C',_N,false)}1589175086{_1t.attachEvent('_2n',_N)} - 简直就是一堆垃圾,没有一点卵用,纯纯是来浪费我们时间的。这个思路行不通,看看其他的。我们再尝试访问几个页面,终于看到了突破点。每次访问页面之前都会有个
jssm的数据包,这样看来我们需要先访问jssm,再去访问页面数据才可。
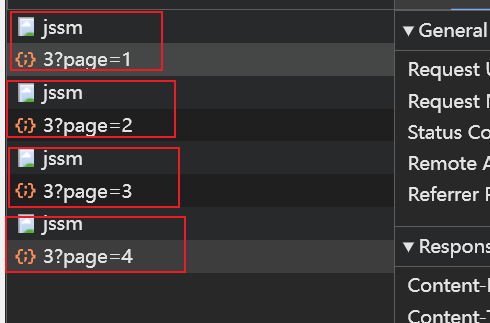
- 写代码访问
jssm数据包,看看回显。import requests url = "https://match.yuanrenxue.cn/jssm" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; HMACCOUNT=xxxxx; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=xxxxx; qpfccr=true; no-alert3=true; tk=-xxxxx; sessionid=xxxxx; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=xxxxx' } resp = requests.post(url, headers=headers) print(resp.text) - 我们再去看看
jssm数据包的响应头,有个set-cookie头。
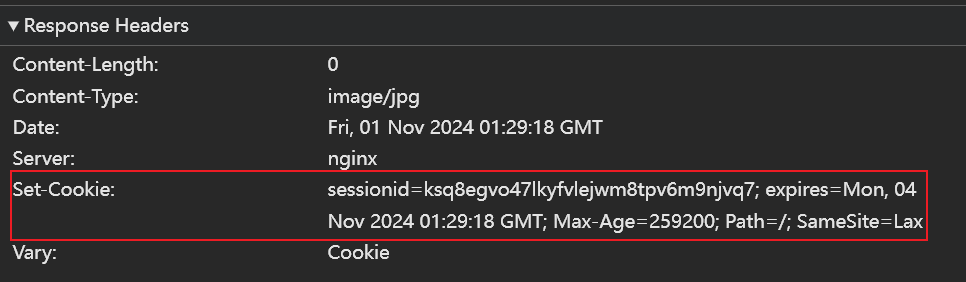
- 猜测会不会跟
set-cookie头有关,要先得到set-cookie头才行。import requests url = "https://match.yuanrenxue.cn/jssm" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; HMACCOUNT=xxxxx; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=xxxxx; qpfccr=true; no-alert3=true; tk=-xxxxx; sessionid=xxxxx; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=xxxxx' } resp = requests.post(url, headers=headers) print(resp.headers)set-cookie头。

补全所有的请求头,再尝试一次,还是没有。import requests url = "https://match.yuanrenxue.cn/jssm" headers = { 'Host': 'match.yuanrenxue.cn', 'Connection': 'keep-alive', 'Content-Length': '0', 'Pragma': 'no-cache', 'Cache-Control': 'no-cache', 'sec-ch-ua-platform': '"Windows"', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'Accept': '*/*', 'Origin': 'https://match.yuanrenxue.cn', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Dest': 'empty', 'Referer': 'https://match.yuanrenxue.cn/match/3', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=xxxxxx; HMACCOUNT=xxxxx; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=xxxxx; qpfccr=true; no-alert3=true; tk=-xxxxx; sessionid=xxxxx; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=xxxxx' } resp = requests.post(url, headers=headers) print(resp.headers)
- 这都没有!!借用一下
fiddler抓包工具吧,用一下里面的请求头吧。
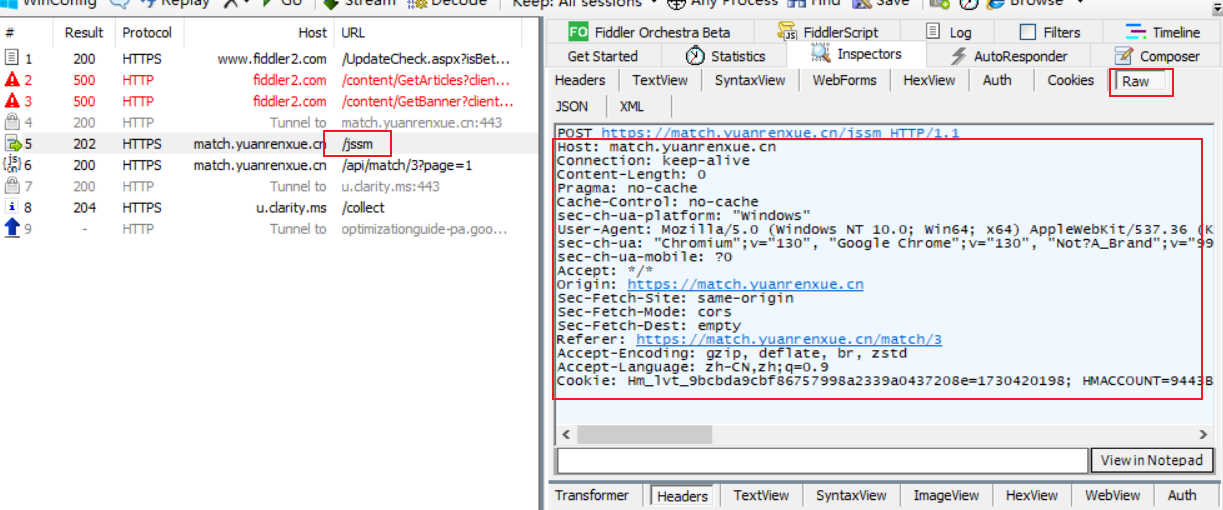
运行后还是没得到set-cookie头。 - 服了,参考网上资料,发现requests 是会自动排序请求头的,不会按设定好的请求头顺序发送,那我们只能用session了,还能自动接收set-Cookie请求头,并自动设置更新cookie参数。
import requests sess = requests.session() url = "https://match.yuanrenxue.cn/jssm" sess.headers = { 'Host': 'match.yuanrenxue.cn', 'Connection': 'keep-alive', 'Content-Length': '0', 'Pragma': 'no-cache', 'Cache-Control': 'no-cache', 'sec-ch-ua-platform': '"Windows"', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'Accept': '*/*', 'Origin': 'https://match.yuanrenxue.cn', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Dest': 'empty', 'Referer': 'https://match.yuanrenxue.cn/match/3', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; HMACCOUNT=xxxxx; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=xxxxx; qpfccr=true; no-alert3=true; tk=-xxxxx; sessionid=xxxxx; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=xxxxx' } print(sess.post(url).headers)set-cookie头。

请求头太多了,简化一下,最后只剩下六个请求头。'Content-Length': '0', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'Accept': '*/*', 'Referer': 'https://match.yuanrenxue.cn/match/3', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; HMACCOUNT=xxxxx; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=xxxxx; qpfccr=true; no-alert3=true; tk=-xxxxx; sessionid=xxxxx; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=xxxxx'} - 现在就可以尝试去获取第一页的页面数据了,验证一下我们的思路。
import requests sess = requests.session() sess.headers = {'Content-Length': '0', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'Accept': '*/*', 'Referer': 'https://match.yuanrenxue.cn/match/3', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; HMACCOUNT=xxxxx; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=xxxxx; qpfccr=true; no-alert3=true; tk=-xxxxx; sessionid=xxxxx; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=xxxxx'} jssm_url = "https://match.yuanrenxue.cn/jssm" sess.post(jssm_url) url = "https://match.yuanrenxue.cn/api/match/3?page=1" resp = sess.get(url) print(resp.text)

- 思路正确,完整代码如下。
import requests import re sess = requests.session() sess.headers = {'Content-Length': '0', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36', 'Accept': '*/*', 'Referer': 'https://match.yuanrenxue.cn/match/3', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'Hm_lvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; HMACCOUNT=xxxxx; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=xxxxx; qpfccr=true; no-alert3=true; tk=-xxxxx; sessionid=xxxxx; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=xxxxx; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=xxxxx'} jssm_url = "https://match.yuanrenxue.cn/jssm" pattern = r'{"value": (.*?)}' dic = {} for i in range(1, 6): sess.post(jssm_url) url = "https://match.yuanrenxue.cn/api/match/3?page=".format(i) resp = sess.get(url) string = resp.text print(string) findall = re.findall(pattern, string) for item in findall: if item in dic.keys(): dic[item] += 1 else: dic[item] = 1 dic = sorted(dic.items(), key=lambda x: x[1], reverse=True) print(dic[0][0])

- 提交,成功通过。

合集:
猿人学爬虫攻防刷题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】