
猿人学web端爬虫攻防大赛赛题第17题——天杀的http2.0
1.猿人学web端爬虫攻防大赛赛题第12题——入门级js2.猿人学web端爬虫攻防大赛赛题第13题——入门级cookie
3.猿人学web端爬虫攻防大赛赛题第17题——天杀的http2.0
4.猿人学web端爬虫攻防大赛赛题第1题——js 混淆 - 源码乱码5.猿人学web端爬虫攻防大赛赛题第3题——访问逻辑 - 推心置腹6.猿人学web端爬虫攻防大赛赛题第4题——雪碧图、样式干扰7.猿人学web端爬虫攻防大赛赛题第15题——备周则意怠-常见则不疑8.猿人学web端爬虫攻防大赛赛题第16题——js逆向 - window蜜罐9.猿人学web端爬虫攻防大赛赛题第19题——乌拉乌拉乌拉10.猿人学web端爬虫攻防大赛赛题第2题——动态cookie11.猿人学web端爬虫攻防大赛赛题第5题——js 混淆 - 乱码增强12.猿人学web端爬虫攻防大赛赛题第6题——js 混淆 - 回溯13.猿人学web端爬虫攻防大赛赛题第7题——动态字体,随风漂移14.猿人学web端爬虫攻防大赛赛题第20题——2022新春快乐题目网址: https://match.yuanrenxue.cn/match/17
解题步骤:
- 老方法,看触发的数据包。

- 只有一个数据包,再看cookie中有没有特殊的字段。

- 没有遇到第13题的特殊字段,直接访问。
import requests
url = "https://match.yuanrenxue.cn/api/match/17?page=1"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 "
"Safari/537.36",
"cookie": "sessionid=1zl8qqmuijewpn1pxji9epmjvoaz5ipi; Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1729915594,1729937930,1729945496,1730034166; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1730284775"}
resp = requests.get(url, headers=headers)
print(resp.text)
运行却得不到页面上的数字。

4. 到底哪里出了问题呢,再结合题目http2.0,难道要用http2.0协议,先查看当前流量包的协议。这里以chrome浏览器为例,右击流量包,选择Header Options然后选择Protocol,就会显示协议号。
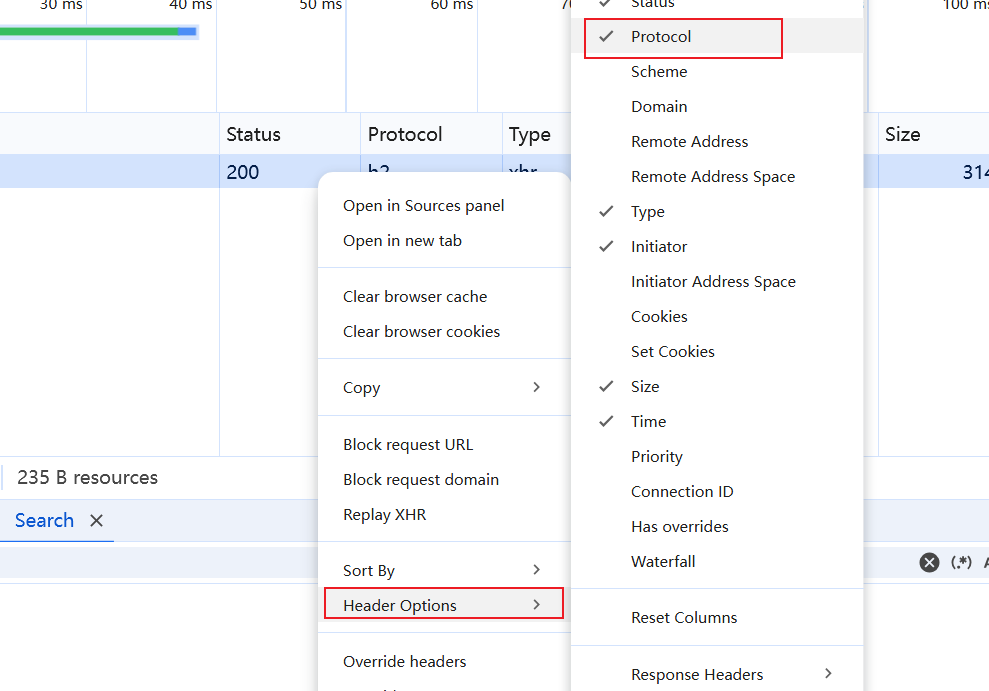

5. 确定是http2.0协议了。根据官方说明,requests只支持http1.1协议,所以这里就不能能用requests库了。

6. 经过网上搜索,Hyper和Httpx两个库支持http2.0。
hyper的话,不是很适用,因为很多功能跟requests库没法类比,所以这里选用httpx。
httpx的安装:pip install httpx[http2] # 这样写才能装上支持http2的httpx,不写的话默认是不支持http2的
7. 用httpx库尝试去访问一下,用法与requests库差不多。
import httpx
import re
client = httpx.Client(http2=True)
sum_num = 0
for i in range(1, 6):
url = "https://match.yuanrenxue.cn/api/match/17?page={}".format(i)
# print(url)
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 "
"Safari/537.36",
"cookie": "sessionid=1zl8qqmuijewpn1pxji9epmjvoaz5ipi; Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1729915594,1729937930,1729945496,1730034166; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1730284775"}
resp = client.get(url, headers=headers)
pattern = r'{"value": (?P<num>.*?)}'
findall = re.findall(pattern, resp.text)
for item in findall:
# print(item)
sum_num += int(item)
print(sum_num)
运行结果如下。

8. 提交结果,成功通关。

合集:
猿人学爬虫攻防刷题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】