
python-简单模块的使用
提示:简单模块了解掌握
@
uuid模块
# uuid用来生成一个全局唯一的id
import uuid
print(uuid.uuid1()) # 32个长度 每一个字符有16个选择 16**32
# print(uuid.uuid2())
# uuid3和uuid5是使用传入的字符串根据指定的算法算出来的,是固定的
print(uuid.uuid3(uuid.NAMESPACE_DNS, 'zhangsan')) # 生成固定的uuid
print(uuid.uuid5(uuid.NAMESPACE_DNS, 'zhangsan')) # 生成固定的uuid
print(uuid.uuid4()) # 使用的最多
calendar日历模块
import calendar
#calendar.serfirstweekday(calendar.SUNDAY)#设置每周起始日期码,周一到周日分别对应0-6
#calendar.firstweekday()#返回当前每周起始日期的位置,默认情况下,首次载入calendar模块时返回0,即星期一
c=calendar.calendar(2019)#生成2019年日历,并且以周日为其日期码
print(c)#打印2019年日历,
time模块
1、时间戳:1646820017.682946 表示从1970年1月1日0时0分0秒到现在的一个秒数,目前可以计算到2038年
- time.time()可以计算时间差
import time
print(time.time())
#计算时间差
start=time.time()
end=time.time()
print("相差:%s"%(end-start))
2、时间字符串:Wed Mar 9 18:06:29 2022
import time
print(time.ctime())
3、时间元组,结构化的时间:time.struct_time(tm_year=2022, tm_mon=3, tm_mday=9, tm_hour=18, tm_min=8, tm_sec=37, tm_wday=2, tm_yday=68, tm_isdst=0)
import time
rse=time.localtime()#结构化的时间,可以单独获取时间的某一部分
print(res)
print(res.tm_year)
print(res.tm_hour)
3.按照某种格式显示的时间: 2014-11-11 11:11, 即:
import time
#按照某种格式显示时间
print(time.strftime('%Y-%m-%d %H:%M-%S '))
print(time.strftime('%Y-%m-%d %H:%M-%S %p'))
print(time.strftime('%Y-%m-%d %X'))
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
4.时间格式的转换
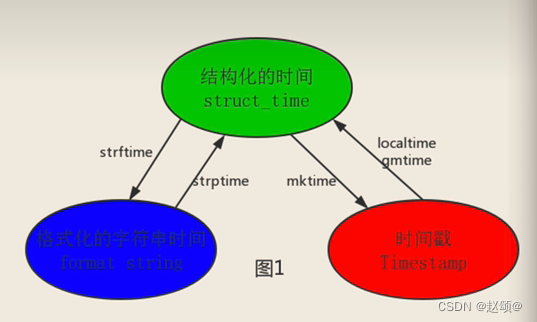
(4.1)结构化时间转成时间戳的形式
import time
s_time=time.localtime()
print(time.mktime(s_time))
(4.2)时间戳转成结构化模式
import time
tp_time=time.time()
print(time.localtime(tp_time))
print(time.gmtime(tp_time))
#licaltime与gmtime唯一的区别就是相差8小时
import time
print(time.localtime())#中国上海的时间
print(time.gmtime())#世界标准时间
#中国上海时间与世界标准时间相差8小时
(4.3)结构化的时间转成格式化字符串的时间
import time
s_time=time.localtime()
print(time.strftime('%Y-%m-%d %H:%M:%S',s_time))
(4.4)格式化时间转成结构化的时间
import time
time.strptime('1988-03-03 11:11:11','%y-%m-%d %H:%M:%S')
(4.5)格式化时间转成时间戳(掌握)
import time
struct_time=time.strptime('1999-09-09 11:10:11','%Y-%m-%d %H:%M:%S')
timestamp=time.mktime(struct_time)
print(timestamp)#转成时间戳
(4.6)时间戳再转成格式化时间
import time
#七天后的秒数
timestamp=time.mktime(struct_time)+7*86400
print(timestamp)
struct_time=time.localtime(timestamp)
format_string=time.strftime('%Y-%m-%d %X',struct_time)
print(format_string)
- sleep()
import time
time.sleep(3)#等待三秒
- asctime()
import time
print(time.asctime())
datetime模块
1.获取当前日期和时间
datetime模块中定义的一个类是datetime类。然后,我们使用now()方法创建一个包含当前本地日期和时间的datetime对象
import datetime
print(datetime.datetime.now())#直接获取到类似于time.strftime('%Y-%m-%d %H:%M:%S')
- 获取当前日期
使用了date类中定义的today()方法来获取一个包含当前本地日期的date对象.
import datetime
print(datetime.date.today)
可以使用dir()函数来获取包含模块所有属性的列表
import datetime
print(dir(datetime))
输出结果如下:
['__add__', '__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__radd__', '__reduce__', '__reduce_ex__', '__repr__', '__rsub__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', 'astimezone', 'combine', 'ctime', 'date', 'day', 'dst', 'fold', 'fromisocalendar', 'fromisoformat', 'fromordinal', 'fromtimestamp', 'hour', 'isocalendar', 'isoformat', 'isoweekday', 'max', 'microsecond', 'min', 'minute', 'month', 'now', 'replace', 'resolution', 'second', 'strftime', 'strptime', 'time', 'timestamp', 'timetuple', 'timetz', 'today', 'toordinal', 'tzinfo', 'tzname', 'utcfromtimestamp', 'utcnow', 'utcoffset', 'utctimetuple', 'weekday', 'year']
2.获取一段时间后的时间
import datetime
print(datetime.datetime.now() + datetime.timedelta(weeks=3))#三周后的时间
print(datetime.datetime.now() + datetime.timedelta(days=4))#四天后的时间
print(datetime.datetime.now() + datetime.timedelta(days=-4))#四天前的时间
print(datetime.datetime.now() - datetime.timedelta(days=4))#四天前的时间
datetime模块中常用的类:
- date类
- time类
- datetime类
- timedelta类
datetime.date类
(1) 获取当前日期 - 可以使用一个名为today()的类方法来创建一个包含当前日期的date对象
from datetime import date
today=date.today()
print(today)
(2):从时间戳获取日期
- Unix时间戳是特定日期到UTC的1970年1月1日之间的秒数。可以使用fromtimestamp()方法将时间戳转换为日期
from datetime import date
timestamp = date.fromtimestamp(1576244364)
print("日期 =", timestamp)
(3) 打印今天的年,月和日
from datetime import date
today=date.today()
print('当前年份:',today.year)
print('当前月份:',today.month)
print('当前日期:',today.day)
os模块
(1) os.getcwd()
- 作用:获取当前的工作路径
(2) os.listdir(path)
- 作用:传入任意一个path路径,返回的是该路径下所有文件和目录组成的列表
(3)os.path.exists(path)
- 判断指定path是否存在,存在返回True,否则返回False
(4)os.mkdir(path)
- 作用:创建单个(单层)文件
- 注意:如果文件夹存在就报错,因此再创建文件前,需要使用os.path.exists(path)来判断文件是否存在
import os
path1=os.getcwd()
path2=path1 + '\\shabi'
os.mkdir(path2)
(5)os.makedirs(path)
- 生成一个递归的文件夹
- 注意:如果文件存在,就报错,因此再创建文件前,需要使用os.path.exists(path)来判断文件是否存在
(6)os.rmdir(path)
- 删除指定路径下的文件夹
- 注意:该方法只能删除空文件夹,删除非空文件夹报错
(7)os.path.join(path1,path2)
- 传入两个路径,将该路径拼接起来,形成一个新的完整路径
(8) os.path.split(path)
- 传入一个完成 的路径,将其分为
绝对路径和文件名两部分呢
import os
path2=r"C:\Users\zjap\Desktop\publish\os模块\a.jpg"
os.path.split(path2)
#返回一个元组,
(9) os.path.dirname(path)
- 传入完整路径,只获取绝对路径
(10) os.path.basename(path)
- 传入一个完成路径,只获取文件名
(11)os .path.isdir(path)
- 判断是否是文件夹
(12)os.path.isfile(path)
- 判断是否是文件
(13)os.path.sep
- 返回当前操作系统的路径分隔符
(14)os.path.getsize(path)
- 返回该路径的大小
(15)os.path.abspath(file)
- 获取绝对路径
import os
print(os.path.abspath(__file__))
sys模块
random模块
import random
print(random.random()) # 范围(0,1)
print(random.uniform(5, 9)) # 随机小数,范围自定义,大于5小于9
print(random.randint(3, 8)) # 随机整数 两边都能取到
print(random.randrange(1,3)) #[1,3)大于等于1小于3
lst = ["张无忌", "周街路", "战无极", "赵四"]
print(random.choice(lst)) # 随机选择一个
lst1 = ["屠龙刀", "倚天剑", "500金币", "溜溜球"]
# 每次随机爆出2个装备
print(random.sample(lst1, 2))
item=[1,3,5,7,9]
random.shuffle(item)#打乱item的顺序,相当于'洗牌'
print(item)
json和pickle模块
序列化
- 把对象(变量)从内存中变成可存储或传输的过程称为序列化,在Python中叫pickling
序列化优点: - 持久保存状态:内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前的一段数据(有结构)都被清空了,但是在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于后期程序执行能够从文件中载入之前的数据,然后继续执行
- 跨平台数据数据交互:序列化时不仅可以把序列化后的内容写到磁盘,还可以通过网络传输到别的机器上,如果收发双方约定好使用一种序列化格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台的数据交互
json
json序列化并不是PYthon独有的,json序列化在Java等语言中也会涉及到,因此使用json序列化能够达到跨平台交互的目的

- 序列化
import json
#序列化
json_res = json.dumps([1, 'aaa', True, False])
with open('test.json','wt',encoding='utf-8')as fp:
fp.write(json_res)
print(json_res)
print(type(json_res))
#结果如下:
"""
[1, "aaa", true, false]
<class 'str'>
"""
序列化简单方法
#将序列化的结果写入文件的简单方法
with open('test.json','wt',encoding='utf-8')as fp:
json.dump([1, 'aaa', True, False],fp)
- 反序列化
import json
l = json.loads(json_res)#反序列化
print(l, type(l))
with open('test.json','rt',encoding='utf-8') as fp:
l=json.loads(fp.read())#反序列化
print(l,type(l))
反序列化简单方法
with open('test.json','rt',encoding='utf-8') as fp:
l=json.load(fp)
print(l,type(l))
pickle模块
pickle模块只能用于python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存不重要的数据。
pickle的好处是,可以 存储python中的所有数据类型,包括对象,而json不可以

- 序列化
import pickle
struct_data={'name':'zhao','age':22,'hobby':'JayChou'}
res=pickle.dumps(struct_data)
print(res,type(res))
#结果如下
"""
b'\x80\x04\x95-\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x04zhao\x94\x8c\x03age\x94K\x16\x8c\x05hobby\x94\x8c\x07JayChou\x94u.' <class 'bytes'>
"""
- 反序列化
s=pickle.loads(res)
print(s,type(s))
#结果如下
"""
{'name': 'zhao', 'age': 22, 'hobby': 'JayChou'} <class 'dict'>
"""
#序列化
"""pickle模块需要使用二进制存储,即wb模式存储"""
with open('Pickle序列化对象.pkl','wb')as fw:
pickle.dump(struct_data,fw)
#反序列化
with open('Pickle序列化对象.pkl','rb')as fr:
data=pickle.load(fr)
print(data)
hashlib模块
hash是一种算法,python3中,hashlib模块代替了md5模块和sha模块,主要提供SHA1、SHA224、SHA256、 SHA512、MD5算法,该算法接受传入的内容,经过运算得到了一串hash值
hash值特点:
- 只要传如的内容一样,得到的hash值一样,可用于非明文加密传输时密码校验
- 不能由hash值返解成内容,即可以保证非明文密码的安全性
- 只要使用hash算法不变,无论校验的内容有多大,得到的hash值长度都是固定的,可以用于对文本的哈希处理
import hashlib
m = hashlib.md5()
m.update('hello'.encode('utf-8'))
m.update('world'.encode('utf-8'))
res=m.hexdigest()#拿到hello world的哈希校验结果
print(res)
#结果
"""
fc5e038d38a57032085441e7fe7010b0
"""
m2=hashlib.md5('he'.encode('utf-8'))
m2.update('llo'.encode('utf-8'))
m2.update('w'.encode('utf-8'))
m2.update('orld'.encode('utf-8'))
data=m2.hexdigest()
print(data)
"""
#结果同上
fc5e038d38a57032085441e7fe7010b0
"""
- 模拟密码撞库
# 模拟撞库
cryptograph = 'cbc9c56cda61e656686b2013f665571a'
# 制作密码字典
passwds = [
'walej777',
'lisi12',
'wangeu124@',
'zhangsan232'
]
dic = {}
import hashlib
for p in passwds:
res = hashlib.md5(p.encode('utf-8'))
dic[p] = res.hexdigest()
print(dic)
# 模拟撞库得到密码
for key, value in dic.items():
if value == cryptograph:
print(f'撞库成功,明文密码是:{key}')
break
- 密码加盐
# 提升撞库的成本==>密码加盐
import hashlib
m=hashlib.md5()
m.update('好好学习'.encode('utf-8'))
m.update('dsb520'.encode('utf-8'))
m.update('天天向上'.encode('utf-8'))
print(m.hexdigest())
configparser模块
- 加载某种特定格式的配置文件
- 该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)
#文件名为text.ini的配置文件
# 注释1
; 注释2
[section1]
k1=v1
k2:v2
age=22
user=zhao
is_admin=true
salary=32.5
[section2]
k1=v1
import configparser
#加载某种特定格式的配置文件
config=configparser.ConfigParser()
config.read('text.ini')
#1获取所有的section
print(config.sections())
#2获取某一个sections下的配置项option
print(config.options(('section1')))
#3获取items
print(config.items('section1'))
#4获取指定的数据
print(config.get('section1','user'))
print(config.getint('section1','age'))
res=config.getboolean('section1','is_admin')
print(res,type(res))
print(config.getfloat('section1','salary'))
subprocess模块
#执行系统命令
#子进程
import subprocess
obj= subprocess.Popen('dir',shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
print(obj)
res=obj.stdout.read()
err_res=obj.stderr.read()
print(res.decode('gbk'))
print(err_res.decode('gbk'))
本文来自博客园,作者:ExpiredSaury,转载请注明原文链接:https://www.cnblogs.com/saury/p/16739201.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号