Zookeeper的选举算法和脑裂问题
ZK介绍
ZK = zookeeper
ZK是微服务解决方案中拥有服务注册发现最为核心的环境,是微服务的基石。作为服务注册发现模块,并不是只有ZK一种产品,目前得到行业认可的还有:Eureka、Consul。
这里我们只聊ZK,这个工具本身很小zip包就几兆,安装非常傻瓜,能够支持集群部署。
官网地址:https://zookeeper.apache.org/
背景
在集群环境下ZK的leader&follower的概念,已经节点异常ZK面临的问题以及如何解决。ZK本身是java语言开发,也开源到Github上但官方文档对内部介绍的很少,零散的博客很多,有些写的很不错。
提问:
ZK节点状态角色
ZK集群单节点状态(每个节点有且只有一个状态),ZK的定位一定需要一个leader节点处于lading状态。
- looking:寻找leader状态,当前集群没有leader,进入leader选举流程。
- following:跟随者状态,接受leading节点同步和指挥。
- leading:领导者状态。
- observing:观察者状态,表名当前服务器是observer。
ZAB协议(原子广播)
Zookeeper专门设计了一种名为原子广播(ZAB)的支持崩溃恢复的一致性协议。ZK实现了一种主从模式的系统架构来保持集群中各个副本之间的数据一致性,所有的写操作都必须通过Leader完成,Leader写入本地日志后再复制到所有的Follower节点。一旦Leader节点无法工作,ZAB协议能够自动从Follower节点中重新选出一个合适的替代者,即新的Leader,该过程即为领导选举。
ZK集群中事务处理是leader负责,follower会转发到leader来统一处理。简单理解就是ZK的写统一leader来做,读可以follower处理,这也就是CAP理论中ZK更适合读多写少的服务。
脑裂问题
脑裂问题出现在集群中leader死掉,follower选出了新leader而原leader又复活了的情况下,因为ZK的过半机制是允许损失一定数量的机器而扔能正常提供给服务,当leader死亡判断不一致时就会出现多个leader。
什么是脑裂?
简单点来说,脑裂(Split-Brain) 就是比如当你的 cluster 里面有两个节点,它们都知道在这个 cluster 里需要选举出一个 master。那么当它们两个之间的通信完全没有问题的时候,就会达成共识,选出其中一个作为 master。
但是如果它们之间的通信出了问题,那么两个结点都会觉得现在没有 master,所以每个都把自己选举成 master,于是 cluster 里面就会有两个 master。
对于Zookeeper来说有一个很重要的问题,就是到底是根据一个什么样的情况来判断一个节点死亡down掉了?在分布式系统中这些都是有监控者来判断的,但是监控者也很难判定其他的节点的状态,唯一一个可靠的途径就是心跳,所以Zookeeper也是使用心跳来判断客户端是否仍然活着。
使用ZooKeeper来做Leader HA基本都是同样的方式:
- 每个节点都尝试注册一个象征Leader的临时节点,其他没有注册成功的则成为follower,并且通过watch机制 (这里有介绍) 监控着leader所创建的临时节点;
- Zookeeper通过内部心跳机制来确定leader的状态,一旦Leader出现意外Zookeeper能很快获悉并且通知其他的follower,其他flower在之后作出相关反应,这样就完成了一个切换。这种模式也是比较通用的模式,基本大部分都是这样实现的。
但是这里面有个很严重的问题,如果注意不到会导致短暂的时间内系统出现脑裂。因为心跳出现超时可能是Leader挂了,但是也可能是Zookeeper节点之间网络出现了问题,导致Leader假死的情况。
Leader其实并未死掉,但是与ZooKeeper之间的网络出现问题导致Zookeeper认为其挂掉了然后通知其他节点进行切换,这样follower中就有一个成为了Leader。
但是原本的Leader并未死掉,这时候client也获得Leader切换的消息,仍然会有一些延时,Zookeeper通讯需要一个一个通知。
这时候整个系统在混乱中,很有可能有一部分client已经通知到了连接到新的Leader上去了,而有的client仍然连接在老的Leader上。
如果同时有两个client需要对Leader的同一个数据更新,并且刚好这两个client此刻分别连接在新老的Leader上,就会出现很严重问题。
这里做下小总结:
- 假死:由于心跳超时(网络原因导致的)认为Leader死了,但其实leader还存活着;
- 脑裂:由于假死会发起新的Leader选举,选举出一个新的Leader,但旧的Leader网络又通了,导致出现了两个Leader ,有的客户端连接到老的Leader,而有的客户端则连接到新的leader。
Zookeeper集群中的"脑裂"场景说明
对于一个集群,想要提高这个集群的可用性,通常会采用多机房部署,比如现在有一个由6台zkServer所组成的一个集群,部署在了两个机房:
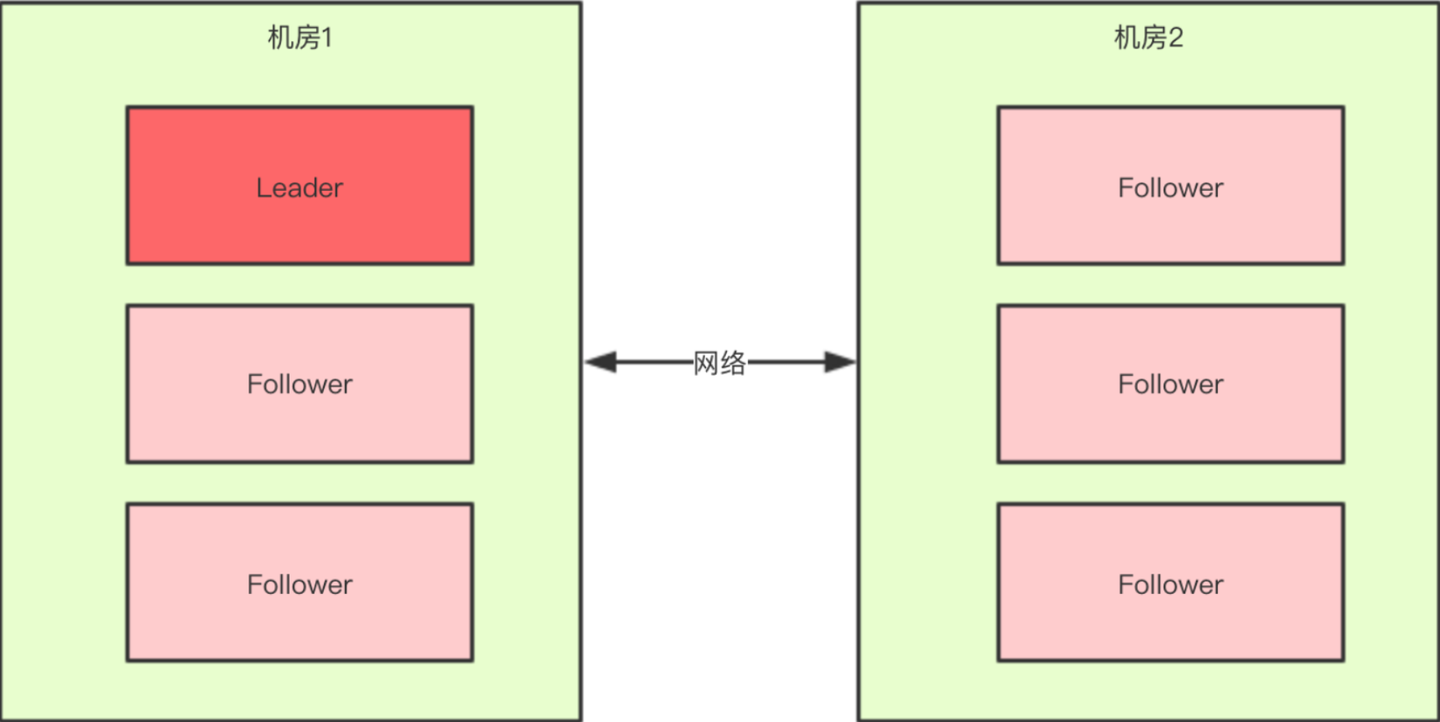
正常情况下,此集群只会有一个Leader,那么如果机房之间的网络断了之后,两个机房内的zkServer还是可以相互通信的。如果不考虑过半机制,那么就会出现每个机房内部都将选出一个Leader。
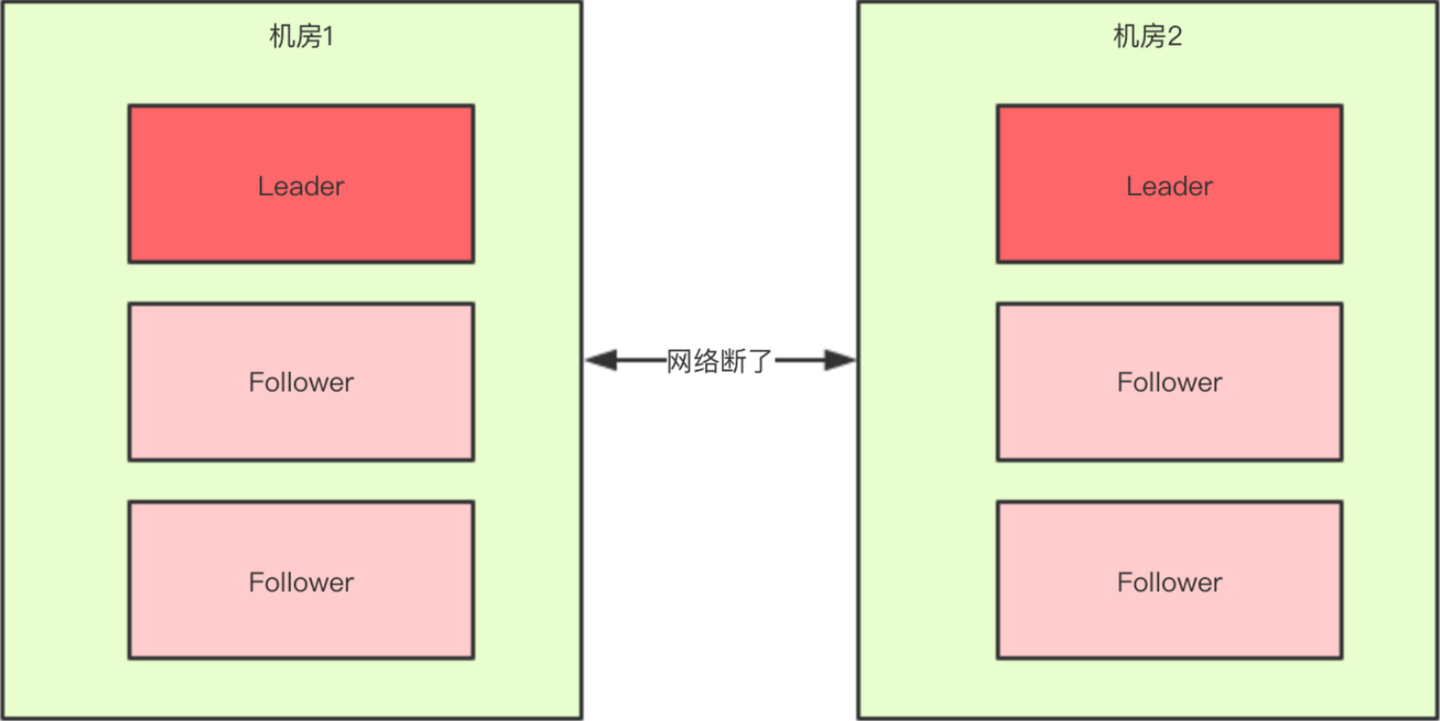
这就相当于原本一个集群,被分成了两个集群,出现了两个"大脑",这就是所谓的"脑裂"现象。
对于这种情况,其实也可以看出来,原本应该是统一的一个集群对外提供服务的,现在变成了两个集群同时对外提供服务,如果过了一会,断了的网络突然联通了,那么此时就会出现问题了。两个集群刚刚都对外提供服务了,数据该怎么合并,数据冲突怎么解决等等问题。
刚刚在说明脑裂场景时有一个前提条件就是没有考虑过半机制,所以实际上Zookeeper集群中是不会轻易出现脑裂问题的,原因就在于过半机制。
Zookeeper脑裂是什么原因导致的?
主要原因是Zookeeper集群和Zookeeper client判断超时并不能做到完全同步,也就是说可能一前一后,如果是集群先于client发现,那就会出现上面的情况。
同时,在发现并切换后通知各个客户端也有先后快慢。一般出现这种情况的几率很小,需要Leader节点与Zookeeper集群网络断开,但是与其他集群角色之间的网络没有问题,还要满足上面那些情况,但是一旦出现就会引起很严重的后果,数据不一致。
Zookeeper是如何解决"脑裂"问题的?
要解决Split-Brain脑裂的问题,一般有下面几种种方法:
- Quorums (法定人数) 方式: 比如3个节点的集群,Quorums = 2, 也就是说集群可以容忍1个节点失效,这时候还能选举出1个lead,集群还可用。比如4个节点的集群,它的Quorums = 3,Quorums要超过3,相当于集群的容忍度还是1,如果2个节点失效,那么整个集群还是无效的。这是Zookeeper防止"脑裂"默认采用的方法;
- Redundant communications (冗余通信)方式:集群中采用多种通信方式,防止一种通信方式失效导致集群中的节点无法通信。
- Fencing (共享资源) 方式:比如能看到共享资源就表示在集群中,能够获得共享资源的锁的就是Leader,看不到共享资源的,就不在集群中。
- 仲裁机制方式;
- 启动磁盘锁定方式。
要想避免Zookeeper"脑裂"情况其实也很简单,在follower节点切换的时候不在检查到老的Leader节点出现问题后马上切换,而是在休眠一段足够的时间,确保老的leader已经获知变更并且做了相关的shutdown清理工作了,然后再注册成为master就能避免这类问题了。
这个休眠时间一般定义为与Zookeeper定义的超时时间就够了,但是这段时间内系统可能是不可用的,但是相对于数据不一致的后果来说还是值得的。
1)ZooKeeper默认采用了Quorums这种方式来防止"脑裂"现象
即只有集群中超过半数节点投票才能选举出Leader。
这样的方式可以确保Leader的唯一性,要么选出唯一的一个Leader,要么选举失败。在zookeeper中Quorums作用如下:
- 集群中最少的节点数用来选举Leader保证集群可用;
- 通知客户端数据已经安全保存前集群中最少数量的节点数已经保存了该数据。一旦这些节点保存了该数据,客户端将被通知已经安全保存了,可以继续其他任务。而集群中剩余的节点将会最终也保存了该数据。
假设某个Leader假死,其余的followers选举出了一个新的Leader。这时,旧的Leader复活并且仍然认为自己是Leader,这个时候它向其他followers发出写请求也是会被拒绝的。
因为每当新Leader产生时,会生成一个epoch标号(标识当前属于那个Leader的统治时期),这个epoch是递增的,followers如果确认了新的Leader存在,知道其epoch,就会拒绝epoch小于现任Leader epoch的所有请求。
那有没有follower不知道新的Leader存在呢?有可能,但肯定不是大多数,否则新Leader无法产生。Zookeeper的写也遵循quorum机制,因此,得不到大多数支持的写是无效的,旧Leader即使各种认为自己是leader,依然没有什么作用。
Zookeeper除了可以采用上面默认的Quorums方式来避免出现"脑裂",还可以可采用下面的预防措施:
2)添加冗余的心跳线,例如双线条线,尽量减少“裂脑”发生机会
3)启用磁盘锁
正在服务一方锁住共享磁盘,"裂脑"发生时,让对方完全"抢不走"共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动"解锁",另一方就永远得不到共享磁盘。
现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了"智能"锁。即正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
4)设置仲裁机制
例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下 参考IP,不通则表明断点就出在本端,不仅"心跳"、还兼对外"服务"的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。
更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。
ZK的过半机制
在领导者选举的过程中,如果某台zkServer获得了超过半数的选票,则此zkServer就可以成为Leader了。
举个简单的例子:如果现在集群中有5台zkServer,那么half=5/2=2,那么也就是说,领导者选举的过程中至少要有三台zkServer投了同一个zkServer,才会符合过半机制,才能选出来一个Leader。
那么Zookeeper选举的过程中为什么一定要有一个过半机制验证?
因为这样不需要等待所有zkServer都投了同一个zkServer就可以选举出来一个Leader了。这样比较快,所以叫快速领导者选举算法。
Zookeeper过半机制中为什么是大于,而不是大于等于?
这就是跟脑裂问题有关系了。比如回到上文出现脑裂问题的场景 (如上图1):
当机房中间的网络断掉之后,机房1内的三台服务器会进行领导者选举,但是此时过半机制的条件是 "节点数 > 3",也就是说至少要4台zkServer才能选出来一个Leader。
所以对于机房1来说它不能选出一个Leader,同样机房2也不能选出一个Leader,这种情况下整个集群当机房间的网络断掉后,整个集群将没有Leader。
而如果过半机制的条件是 "节点数 >= 3",那么机房1和机房2都会选出一个Leader,这样就出现了脑裂。这就可以解释为什么过半机制中是大于而不是大于等于,目的就是为了防止脑裂。
如果假设我们现在只有5台机器,也部署在两个机房:
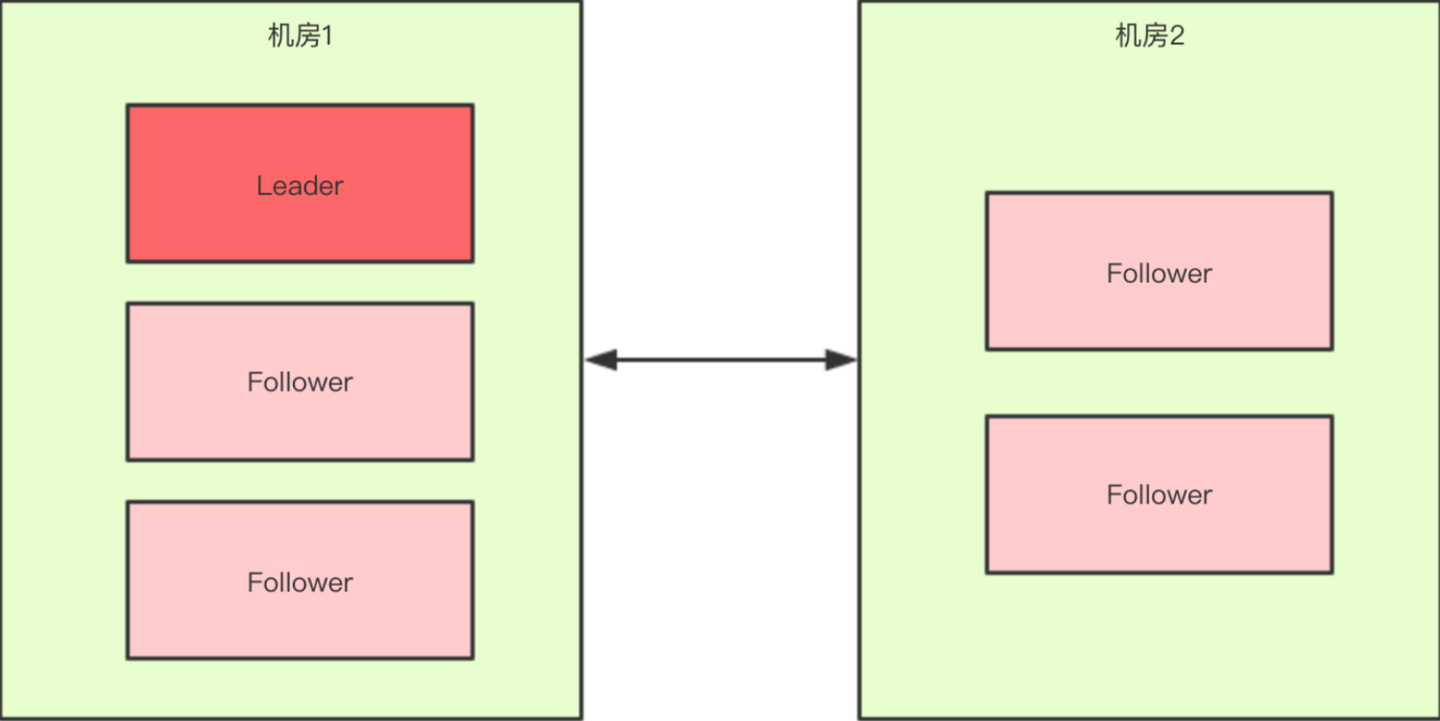
此时过半机制的条件是 "节点数 > 2",也就是至少要3台服务器才能选出一个Leader。
此时机房件的网络断开了,对于机房1来说是没有影响的,Leader依然还是Leader;对于机房2来说是选不出来Leader的,此时整个集群中只有一个Leader。
因此总结得出,有了过半机制,对于一个Zookeeper集群来说,要么没有Leader,要么只有1个Leader,这样Zookeeper也就能避免了脑裂问题。
ZK的过半机制一定程度上也减少了脑裂情况的出现,起码不会出现三个leader同时。ZK中的Epoch机制(时钟)每次选举都是递增+1,当通信时需要判断epoch是否一致,小于自己的则抛弃,大于自己则重置自己,等于则选举;
// If notification > current, replace and send messages out
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
if (LOG.isDebugEnabled()) {
LOG.debug(
"Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x" + Long.toHexString(n.electionEpoch)
+ ", logicalclock=0x" + Long.toHexString(logicalclock.get()));
}
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
过半选举算法
ZK投票处理策略
投票信息包含 :所选举leader的Serverid,Zxid,SelectionEpoch
- Epoch判断,自身logicEpoch与SelectionEpoch判断:大于、小于、等于。
- 优先检查ZXID。ZXID比较大的服务器优先作为Leader。
- 如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
ZK中有三种选举算法,分别是LeaderElection,FastLeaderElection,AuthLeaderElection,FastLeaderElection和AuthLeaderElection是类似的选举算法,唯一区别是后者加入了认证信息, FastLeaderElection比LeaderElection更高效,后续的版本只保留FastLeaderElection。
理解:
在集群环境下多个节点启动,ZK首先需要在多个节点中选出一个节点作为leader并处于Leading状态,这样就面临一个选举问题,同时选举规则是什么样的。“过半选举算法”:投票选举中获得票数过半的节点胜出,即状态从looking变为leading,效率更高。
官网资料描述:Clustered (Multi-Server) Setup,如下图:
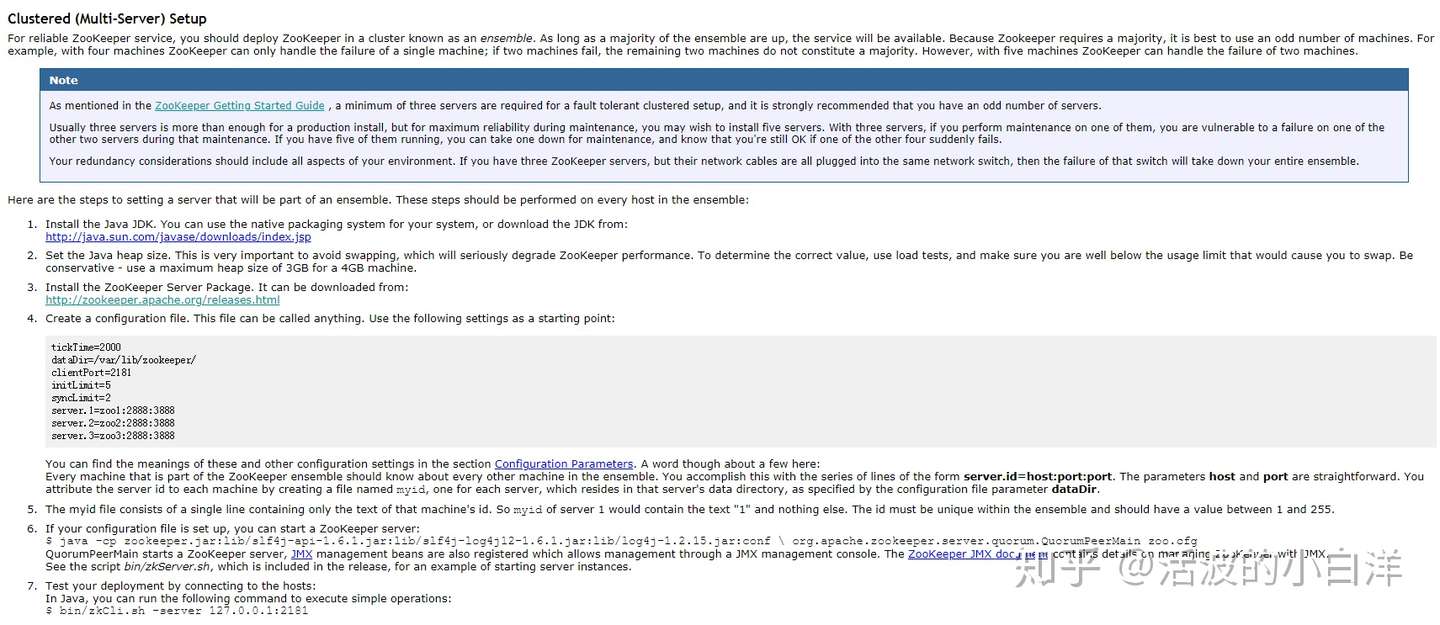
As long as a majority of the ensemble are up, the service will be available. Because Zookeeper requires a majority, it is best to use an odd number of machines. For example, with four machines ZooKeeper can only handle the failure of a single machine; if two machines fail, the remaining two machines do not constitute a majority. However, with five machines ZooKeeper can handle the failure of two machines.
以5台服务器讲解思路:
- 服务器1启动,此时只有它一台服务器启动了,它发出去的Vote没有任何响应,所以它的选举状态一直是LOOKING状态;
- 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态.
- 服务器3启动,根据前面的理论,分析有三台服务器选举了它,服务器3成为服务器1,2,3中的老大,所以它成为了这次选举的leader.
- 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了.
- 服务器5启动,同4一样,当小弟.
假设5台中挂了2台(3、4),其中leader也挂掉:
leader和follower间有检查心跳,需要同步数据 Leader节点挂了,整个Zookeeper集群将暂停对外服务,进入新一轮Leader选举
1)服务器1、2、5发现与leader失联,状态转为looking,开始新的投票 2)服务器1、2、5分别开始投票并广播投票信息,自身Epoch自增; 3) 服务器1、2、5分别处理投票,判断出leader分别广播 4)根据投票处理逻辑会选出一台(2票过半) 5)各自服务器重新变更为leader、follower状态 6)重新提供服务
源码解析:
URL: FastLeaderElection
/**
* Starts a new round of leader election. Whenever our QuorumPeer
* changes its state to LOOKING, this method is invoked, and it
* sends notifications to all other peers.
*/
public Vote lookForLeader() throws InterruptedException {
try {
self.jmxLeaderElectionBean = new LeaderElectionBean();
MBeanRegistry.getInstance().register(self.jmxLeaderElectionBean, self.jmxLocalPeerBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
self.jmxLeaderElectionBean = null;
}
self.start_fle = Time.currentElapsedTime();
try {
Map<Long, Vote> recvset = new HashMap<Long, Vote>();
Map<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = minNotificationInterval;
synchronized (this) {
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
LOG.info("New election. My id = " + self.getId() + ", proposed zxid=0x" + Long.toHexString(proposedZxid));
sendNotifications();
SyncedLearnerTracker voteSet;
/*
* Loop in which we exchange notifications until we find a leader
*/
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
/*
* Remove next notification from queue, times out after 2 times
* the termination time
*/
Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
/*
* Sends more notifications if haven't received enough.
* Otherwise processes new notification.
*/
if (n == null) {
if (manager.haveDelivered()) {
sendNotifications();
} else {
manager.connectAll();
}
/*
* Exponential backoff
*/
int tmpTimeOut = notTimeout * 2;
notTimeout = (tmpTimeOut < maxNotificationInterval ? tmpTimeOut : maxNotificationInterval);
LOG.info("Notification time out: " + notTimeout);
} else if (validVoter(n.sid) && validVoter(n.leader)) {
/*
* Only proceed if the vote comes from a replica in the current or next
* voting view for a replica in the current or next voting view.
*/
switch (n.state) {
case LOOKING:
if (getInitLastLoggedZxid() == -1) {
LOG.debug("Ignoring notification as our zxid is -1");
break;
}
if (n.zxid == -1) {
LOG.debug("Ignoring notification from member with -1 zxid {}", n.sid);
break;
}
// If notification > current, replace and send messages out
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
if (LOG.isDebugEnabled()) {
LOG.debug(
"Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x" + Long.toHexString(n.electionEpoch)
+ ", logicalclock=0x" + Long.toHexString(logicalclock.get()));
}
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
if (LOG.isDebugEnabled()) {
LOG.debug("Adding vote: from=" + n.sid
+ ", proposed leader=" + n.leader
+ ", proposed zxid=0x" + Long.toHexString(n.zxid)
+ ", proposed election epoch=0x" + Long.toHexString(n.electionEpoch));
}
// don't care about the version if it's in LOOKING state
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
voteSet = getVoteTracker(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch));
if (voteSet.hasAllQuorums()) {
// Verify if there is any change in the proposed leader
while ((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
recvqueue.put(n);
break;
}
}
/*
* This predicate is true once we don't read any new
* relevant message from the reception queue
*/
if (n == null) {
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
LOG.debug("Notification from observer: {}", n.sid);
break;
case FOLLOWING:
case LEADING:
/*
* Consider all notifications from the same epoch
* together.
*/
if (n.electionEpoch == logicalclock.get()) {
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
voteSet = getVoteTracker(recvset, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
if (voteSet.hasAllQuorums() && checkLeader(outofelection, n.leader, n.electionEpoch)) {
setPeerState(n.leader, voteSet);
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
/*
* Before joining an established ensemble, verify that
* a majority are following the same leader.
*/
outofelection.put(n.sid, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
voteSet = getVoteTracker(outofelection, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
if (voteSet.hasAllQuorums() && checkLeader(outofelection, n.leader, n.electionEpoch)) {
synchronized (this) {
logicalclock.set(n.electionEpoch);
setPeerState(n.leader, voteSet);
}
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
LOG.warn("Notification state unrecoginized: " + n.state + " (n.state), " + n.sid + " (n.sid)");
break;
}
} else {
if (!validVoter(n.leader)) {
LOG.warn("Ignoring notification for non-cluster member sid {} from sid {}", n.leader, n.sid);
}
if (!validVoter(n.sid)) {
LOG.warn("Ignoring notification for sid {} from non-quorum member sid {}", n.leader, n.sid);
}
}
}
return null;
} finally {
try {
if (self.jmxLeaderElectionBean != null) {
MBeanRegistry.getInstance().unregister(self.jmxLeaderElectionBean);
}
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
self.jmxLeaderElectionBean = null;
LOG.debug("Number of connection processing threads: {}", manager.getConnectionThreadCount());
}
}
/*
* We return true if one of the following three cases hold:
* 1- New epoch is higher
* 2- New epoch is the same as current epoch, but new zxid is higher
* 3- New epoch is the same as current epoch, new zxid is the same
* as current zxid, but server id is higher.
*/
return ((newEpoch > curEpoch)
|| ((newEpoch == curEpoch)
&& ((newZxid > curZxid)
|| ((newZxid == curZxid)
&& (newId > curId)))));
归纳
在日常的ZK运维时需要注意以上场景在极端情况下出现问题,特别是脑裂的出现,可以采用:
过半选举策略下部署原则:
- 服务器群部署要单数,如:3、5、7、...,单数是最容易选出leader的配置量。
- ZK允许节点最大损失数,原则就是“保证过半选举正常”,多了就是浪费。
详细的算法逻辑是很复杂要考虑很多情况,其中有个Epoch的概念(自增长),分为:LogicEpoch和ElectionEpoch,每次投票都有判断每个投票周期是否一致等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号