常见的缓存算法
常见的缓存算法
- LRU (Least recently used) 最近最少使用,如果数据最近被访问过,那么将来被访问的几率也更高。
- LFU (Least frequently used) 最不经常使用,如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小。
- FIFO (Fist in first out) 先进先出, 如果一个数据最先进入缓存中,则应该最早淘汰掉。
一、LRU缓存
像浏览器的缓存策略、memcached的缓存策略都是使用LRU这个算法,LRU算法会将近期最不会访问的数据淘汰掉。LRU如此流行的原因是实现比较简单,而且对于实际问题也很实用,良好的运行时性能,命中率较高。下面谈谈如何实现LRU缓存:
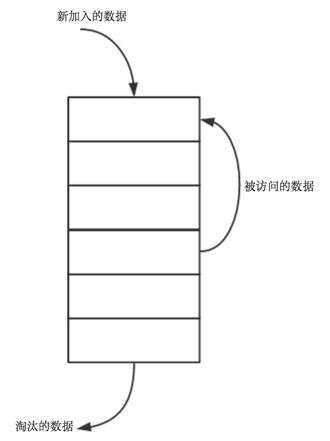
- 新数据插入到链表头部
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部
- 当链表满的时候,将链表尾部的数据丢弃
LRU Cache具备的操作:
- set(key,value):如果key在hashmap中存在,则先重置对应的value值,然后获取对应的节点cur,将cur节点从链表删除,并移动到链表的头部;若果key在hashmap不存在,则新建一个节点,并将节点放到链表的头部。当Cache存满的时候,将链表最后一个节点删除即可。
- get(key):如果key在hashmap中存在,则把对应的节点放到链表头部,并返回对应的value值;如果不存在,则返回-1。
1. LRU的c++实现
LRU实现采用双向链表 + Map 来进行实现。这里采用双向链表的原因是:如果采用普通的单链表,则删除节点的时候需要从表头开始遍历查找,效率为O(n),采用双向链表可以直接改变节点的前驱的指针指向进行删除达到O(1)的效率。使用Map来保存节点的key、value值便于能在O(logN)的时间查找元素,对应get操作。
双链表节点的定义:
struct CacheNode {
int key; // 键
int value; // 值
CacheNode *pre, *next; // 节点的前驱、后继指针
CacheNode(int k, int v) : key(k), value(v), pre(NULL), next(NULL) {}
};
对于LRUCache这个类而言,构造函数需要指定容量大小
LRUCache(int capacity)
{
size = capacity; // 容量
head = NULL; // 链表头指针
tail = NULL; // 链表尾指针
}
双链表的节点删除操作:
void remove(CacheNode *node)
{
if (node -> pre != NULL)
{
node -> pre -> next = node -> next;
}
else
{
head = node -> next;
}
if (node -> next != NULL)
{
node -> next -> pre = node -> pre;
}
else
{
tail = node -> pre;
}
}
将节点插入到头部的操作:
void setHead(CacheNode *node)
{
node -> next = head;
node -> pre = NULL;
if (head != NULL)
{
head -> pre = node;
}
head = node;
if (tail == NULL)
{
tail = head;
}
}
get(key)操作的实现比较简单,直接通过判断Map是否含有key值即可,如果查找到key,则返回对应的value,否则返回-1;
int get(int key)
{
map<int, CacheNode *>::iterator it = mp.find(key);
if (it != mp.end())
{
CacheNode *node = it -> second;
remove(node);
setHead(node);
return node -> value;
}
else
{
return -1;
}
}
set(key, value)操作需要分情况判断。如果当前的key值对应的节点已经存在,则将这个节点取出来,并且删除节点所处的原有的位置,并在头部插入该节点;如果节点不存在节点中,这个时候需要在链表的头部插入新节点,插入新节点可能导致容量溢出,如果出现溢出的情况,则需要删除链表尾部的节点。
void set(int key, int value)
{
map<int, CacheNode *>::iterator it = mp.find(key);
if (it != mp.end())
{
CacheNode *node = it -> second;
node -> value = value;
remove(node);
setHead(node);
}
else
{
CacheNode *newNode = new CacheNode(key, value);
if (mp.size() >= size)
{
map<int, CacheNode *>::iterator iter = mp.find(tail -> key);
remove(tail);
mp.erase(iter);
}
setHead(newNode);
mp[key] = newNode;
}
}
二、LFU
LRU和LFU的区别
LRU是最近最少使用页面置换算法(Least Recently Used),也就是首先淘汰最长时间未被使用的页面!
LFU是最近最不常用页面置换算法(Least Frequently Used),也就是淘汰一定时期内被访问次数最少的页!
举例说明
比如,第二种方法的时期T为10分钟,如果每分钟进行一次调页,主存块为3,若所需页面走向为2 1 2 1 2 3 4
注意,当调页面4时会发生缺页中断
若按LRU算法,应换页面1(1页面最久未被使用) 但按LFU算法应换页面3(十分钟内,页面3只使用了一次)
可见LRU关键是看页面最后一次被使用到发生调度的时间长短,
而LFU关键是看一定时间段内页面被使用的频率!
Redis缓存淘汰策略与Redis键的过期删除策略
Redis缓存淘汰策略与Redis键的过期删除策略并不完全相同,前者是在Redis内存使用超过一定值的时候(一般这个值可以配置)使用的淘汰策略;而后者是通过定期删除+惰性删除两者结合的方式进行内存淘汰的。
这里参照官方文档的解释重新叙述一遍过期删除策略:当某个key被设置了过期时间之后,客户端每次对该key的访问(读写)都会事先检测该key是否过期,如果过期就直接删除;但有一些键只访问一次,因此需要主动删除,默认情况下redis每秒检测10次,检测的对象是所有设置了过期时间的键集合,每次从这个集合中随机检测20个键查看他们是否过期,如果过期就直接删除,如果删除后还有超过25%的集合中的键已经过期,那么继续检测过期集合中的20个随机键进行删除。这样可以保证过期键最大只占所有设置了过期时间键的25%。
ZERO、Redis内存不足的缓存淘汰策略
- noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
- allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
- volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
- allkeys-random:加入键的时候如果过限,从所有key随机删除
- volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
- volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
- volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
- allkeys-lfu:从所有键中驱逐使用频率最少的键
Java中的LRU实现方式
在Java中LRU的实现方式是使用HashMap结合双向链表,HashMap的值是双向链表的节点,双向链表的节点也保存一份key value。
- 新增key value的时候首先在链表结尾添加Node节点,如果超过LRU设置的阈值就淘汰队头的节点并删除掉HashMap中对应的节点。
- 修改key对应的值的时候先修改对应的Node中的值,然后把Node节点移动队尾。
- 访问key对应的值的时候把访问的Node节点移动到队尾即可。
Redis中LRU的实现
- Redis维护了一个24位时钟,可以简单理解为当前系统的时间戳,每隔一定时间会更新这个时钟。每个key对象内部同样维护了一个24位的时钟,当新增key对象的时候会把系统的时钟赋值到这个内部对象时钟。比如我现在要进行LRU,那么首先拿到当前的全局时钟,然后再找到内部时钟与全局时钟距离时间最久的(差最大)进行淘汰,这里值得注意的是全局时钟只有24位,按秒为单位来表示才能存储194天,所以可能会出现key的时钟大于全局时钟的情况,如果这种情况出现那么就两个相加而不是相减来求最久的key。
struct redisServer {
pid_t pid;
char *configfile;
//全局时钟
unsigned lruclock:LRU_BITS;
...
};
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
/* key对象内部时钟 */
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;
-
Redis中的LRU与常规的LRU实现并不相同,常规LRU会准确的淘汰掉队头的元素,但是Redis的LRU并不维护队列,只是根据配置的策略要么从所有的key中随机选择N个(N可以配置)要么从所有的设置了过期时间的key中选出N个键,然后再从这N个键中选出最久没有使用的一个key进行淘汰。
-
下图是常规LRU淘汰策略与Redis随机样本取一键淘汰策略的对比,浅灰色表示已经删除的键,深灰色表示没有被删除的键,绿色表示新加入的键,越往上表示键加入的时间越久。从图中可以看出,在redis 3中,设置样本数为10的时候能够很准确的淘汰掉最久没有使用的键,与常规LRU基本持平。

Redis中LFU的实现
LFU是在Redis4.0后出现的,LRU的最近最少使用实际上并不精确,考虑下面的情况,如果在|处删除,那么A距离的时间最久,但实际上A的使用频率要比B频繁,所以合理的淘汰策略应该是淘汰B。LFU就是为应对这种情况而生的。
A~~A~~A~~A~~A~~A~~A~~A~~A~~A~~~|
B~~~~~B~~~~~B~~~~~B~~~~~~~~~~~B|
-
LFU把原来的key对象的内部时钟的24位分成两部分,前16位还代表时钟,后8位代表一个计数器。16位的情况下如果还按照秒为单位就会导致不够用,所以一般这里以时钟为单位。而后8位表示当前key对象的访问频率,8位只能代表255,但是redis并没有采用线性上升的方式,而是通过一个复杂的公式,通过配置两个参数来调整数据的递增速度。
下图从左到右表示key的命中次数,从上到下表示影响因子,在影响因子为100的条件下,经过10M次命中才能把后8位值加满到255.
# +--------+------------+------------+------------+------------+------------+ # | factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits | # +--------+------------+------------+------------+------------+------------+ # | 0 | 104 | 255 | 255 | 255 | 255 | # +--------+------------+------------+------------+------------+------------+ # | 1 | 18 | 49 | 255 | 255 | 255 | # +--------+------------+------------+------------+------------+------------+ # | 10 | 10 | 18 | 142 | 255 | 255 | # +--------+------------+------------+------------+------------+------------+ # | 100 | 8 | 11 | 49 | 143 | 255 | # +--------+------------+------------+------------+------------+------------+uint8_t LFULogIncr(uint8_t counter) { if (counter == 255) return 255; double r = (double)rand()/RAND_MAX; double baseval = counter - LFU_INIT_VAL; if (baseval < 0) baseval = 0; double p = 1.0/(baseval*server.lfu_log_factor+1); if (r < p) counter++; return counter; }lfu-log-factor 10 lfu-decay-time 1 -
上面说的情况是key一直被命中的情况,如果一个key经过几分钟没有被命中,那么后8位的值是需要递减几分钟,具体递减几分钟根据衰减因子lfu-decay-time来控制
unsigned long LFUDecrAndReturn(robj *o) { unsigned long ldt = o->lru >> 8; unsigned long counter = o->lru & 255; unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0; if (num_periods) counter = (num_periods > counter) ? 0 : counter - num_periods; return counter; }lfu-log-factor 10 lfu-decay-time 1 -
上面递增和衰减都有对应参数配置,那么对于新分配的key呢?如果新分配的key计数器开始为0,那么很有可能在内存不足的时候直接就给淘汰掉了,所以默认情况下新分配的key的后8位计数器的值为5(应该可配资),防止因为访问频率过低而直接被删除。
-
低8位我们描述完了,那么高16位的时钟是用来干嘛的呢?目前我的理解是用来衰减低8位的计数器的,就是根据这个时钟与全局时钟进行比较,如果过了一定时间(做差)就会对计数器进行衰减。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号