mysql数据库优化总结
四大优化方面:
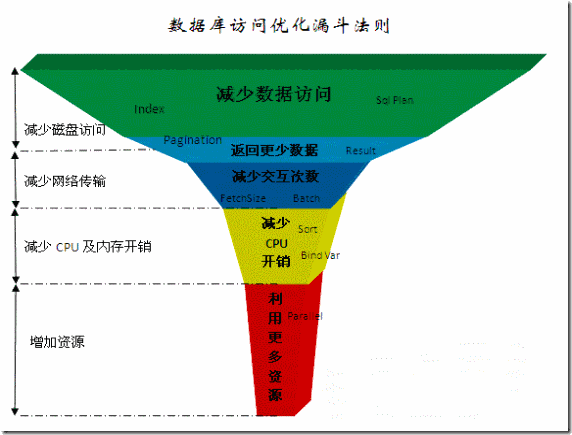
|
减少数据访问 |
减少磁盘访问 |
1. 建表、表字段 |
|
2. 索引 |
||
|
2.1 为什么要用索引 |
||
|
2.2 索引分类 |
||
|
2.3 什么时候用索引 (频繁查询, 关联表字段或外键, 排序) |
||
|
2.4 如何避免索引失效 (<>, like, or, NULL,函数使用) |
||
|
3. 冷热备份 (20%热数据, 80%冷数据) |
||
|
分表分库 |
||
|
读写分离(减少CPU开销) 4. 添加二级缓存 |
||
|
减少交互次数 |
减少网络传输或磁盘访问 |
1. 分页(客户端分页、服务端分页,sql分页) |
|
2. 批量(insert, update, select) |
||
|
3. batch size 或 返回更少数据 |
||
|
减少服务器CPU开销 |
减少CPU及内存开销 |
1. 绑定变量,使用编程语言自封装的DML处理方式 |
|
2. 减少排序 |
||
|
3. 减少比较操作,特别是多个比较操作 |
||
|
4. 大量复杂运算在客户端完成,即避免sql执行大量逻辑运算 |
||
|
5. JOIN 关联(索引处理、大小表操作[小表在前,减少连接数])、 UNION 联合(临时表的生成) |
||
|
利用更多资源 |
增加资源 |
1. 客户端多进程并发 (适当并发) |
|
2. mysql多进程并发 (多索引查询或全表查询) |
https://github.com/jiangsiwei2018/BigData.git
实例代码git仓库地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号