

第一次写博客,顺便交作业
一、github项目地址
https://github.com/satandetective/newR
二、PSP表格
| PSP2.1 | PSP 阶段 | 预估耗时 (分钟) | 实际耗时 (分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 1000 | 795 |
| Development | 开发 | 700 | 605 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 45 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 60 | 30 |
| · Coding | · 具体编码 | 500 | 450 |
| · Code Review | · 代码复审 | 15 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| Reporting | 报告 | 120 | 50 |
| · Test Report | · 测试报告 | 120 | 50 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 80 | 85 |
| 合计 | 1000 | 795 |
三、思路
刚开始拿到这个作业,首先大致扫了一眼所有的需求,感觉时间还是挺紧的(所以PSP表格中的估计数字才总体偏大),所以说实话,并没有做一个很好的规划就开始了代码的书写,所以基本上就是从一个功能开始书写,然后在这个基础上继续加功能,以至于最后代码略显冗杂,也没时间做代码优化;
所以,拿到这个作业,我的解题思路就是:
(1)首先实现从文件中获取内容
(2)然后统计文件中的字符数、单词数、行数
(3)接着实现对命令字符串的分析
(4)接着实现输出到文件的功能
(5)实现递归处理文件夹中的文件
(6)统计代码行、注释行、空行
(7)最后实现停用词表的功能
现在看起来,这个思路是真的乱,下次不能直接写代码,还是要好好规划一下呀!!
四、程序设计实现过程
由于最开始并没有做很好的规划而开始写代码,所以代码基本上是从一个功能上“生长”起来的,到最后只有两个类,Statistics类和Main类。还好,在实际写代码中,我看只有这两个类越来越看不惯,所以在Statistics类中的功能函数分的还行,基本分为代码分析函数,文件读取和文件输出函数,递归处理文件夹中的文件的函数这三个主要函数,这样他们的关系就是一目了然的,就是通过代码处理函数的处理结果来启用其他两个函数。
五、代码说明
既然是说明代码,我就以我的原来的解题思路来说明:
首先,是文件读取部分的代码,这里很简单,代码中带了注释:
1 File file=new File(filePath); 2 if(input1&&file.isFile() && file.exists()){ //判断文件是否存在 3 InputStreamReader read = new InputStreamReader(new FileInputStream(file),encoding);//考虑到编码格式 4 BufferedReader bufferedReader = new BufferedReader(read); 5 String lineTxt = null;
接着,就是对文件中的内容的字符数、行数、单词数进行统计,统计的时候我都是逐行处理的,字符数就是每行的数字总和,单词数就是用split进行分开,在进行统计,行数最简单,逐行加一就是了
1 while((lineTxt=bufferedReader.readLine())!= null)//read()=-1代表数据读取完毕 2 { 3 countChar=countChar+lineTxt.length();//字符个数就是字符长度 4 countword += lineTxt.split(",| ").length; 5 String lineWords[]=lineTxt.split(",| "); 6 countLine++; 7 }
然后,就是对命令字符串的分析,随着后续功能的逐渐添加,分析部分的代码也逐渐在添加,此处把命令字符串的分析代码全部写上(其实也不是很多)
1 ArrayList<String> orderSet=new ArrayList<>();//存储指令集 2 Scanner scan=new Scanner(System.in); 3 String str1=scan.nextLine(); 4 String strs[]=str1.split(" ");//将指令分隔存入数组 5 boolean input1=false; 6 for(int i=0;i<strs.length;i++) 7 { 8 orderSet.add(strs[i]); 9 } 10 11 if(orderSet.get(0).equals("wc.exe")) {//判断输入指令是否 12 System.out.println("指令格式输入不正确"); 13 input1=true; 14 } 15 for(int i=0;i<orderSet.size();i++) 16 { 17 if(orderSet.get(i).equals("-c")) 18 count++; 19 if(orderSet.get(i).equals("-w")) 20 count++; 21 if(orderSet.get(i).equals("-l")) 22 count++; 23 if(orderSet.get(i).equals("-s")) 24 { 25 isAll=true; 26 count++; 27 } 28 if(orderSet.get(i).equals("-a")) 29 count++; 30 if(orderSet.get(i).equals("-e")) 31 { 32 isStop=true; 33 stopath=orderSet.get(i+1); 34 count+=2; 35 } 36 }
这里必须要说一嘴,这里的count变量是用来寻找命令中文件的名称的位置,以便于进一步分析所引入的一个变量
接下来,就是输出到文件中的功能:
if(orderSet.get(i).equals("-o")) { PrintStream out = System.out;// 保存原输出流 System.out.println("指令正确,结果已存入相应文件"); PrintStream ps=new PrintStream(orderSet.get(orderSet.size()-1));// 创建文件输出流1 System.setOut(ps);// 设置使用新的输出流 }
这里只是改了输出流,至于输出只需要一句System.out.println();
之后,根据需求继续,也就是对命令中“-s”的处理,还是那个原因,规划没有做好,所以处理新命令就要处理两部分,先处理命令,再处理递归,由于处理命令和之前是异曲同工的,下面就写上递归处理文件的代码:
1 public void traverseFolder2(String path)//递归处理文件 2 { 3 File file = new File(path); 4 if (file.exists()) { 5 File[] files = file.listFiles(); 6 for (File file2 : files) { 7 if (file2.isDirectory()) { 8 traverseFolder2(file2.getAbsolutePath()); 9 } else { 10 if(file2.getName().endsWith(".c")) { 11 wjList.add(file2);//存储符合条件的文件 12 } 13 } 14 } 15 } 16 17 }
这里还要说一句,这里只处理.c文件,其他文件并没有处理
接下来就是代码行,注释行,空行的统计,这个最大的问题就是对于这三种行的定义是怎样的,下面的代码处理如下:
(1)空行是字符数<=1的
(2)注释行就是这一行中有“//”,“/*”,“*/”都统计为注释行
(3)其他的都为代码行
if(lineTxt.length()<=1) noneLine1++; else if((lineTxt.indexOf("//")!=-1)||(lineTxt.indexOf("/*")!=-1)||(lineTxt.indexOf("*/")!=-1)) noteLine1++; else codeLine1++;
接下来就是最后一个功能,停用词表,这其实就是对前面的东西的一个活用,将停用词表中的内容进行分隔存入数组,在将文件中的内容分隔存入数组,相同即将词语减去:
1 ArrayList<String> stopSet=new ArrayList<>();//存储停用词 2 boolean isStop=false;//用来判断是否有“-e”命令 3 if(isStop)//存在“-e”命令 4 { 5 File file=new File(stopath); 6 InputStreamReader read = new InputStreamReader(new FileInputStream(file),encoding);//考虑到编码格式 7 BufferedReader bufferedReader = new BufferedReader(read); 8 String lineTxt = null; 9 while((lineTxt=bufferedReader.readLine())!= null)//read()=-1代表数据读取完毕 10 { 11 String stops[]=lineTxt.split(" "); 12 for(int i=0;i<stops.length;i++) 13 { 14 stopSet.add(stops[i]); 15 } 16 } 17 } 18 19 20 if(isStop) 21 { 22 for(int i=0;i<stopSet.size();i++) 23 { 24 for(int m=0;m<lineWords.length;m++) { 25 if (stopSet.get(i).equals(lineWords[m])) 26 countword--; 27 } 28 } 29 }
六、测试设计过程
代码已经写好了,下面就是开始对代码进行测试了。我的测试用例设计主要是根据功能需求进行单元测试,话不多说,我们开始进行测试:
(1)首先,是单独功能的测试,即-c,-w,-l,-o+文件,-s,-a,-e的单独测试:
-c 命令
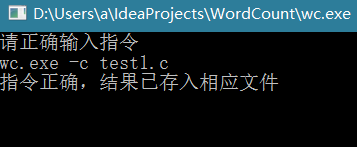



-w 命令

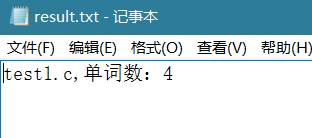
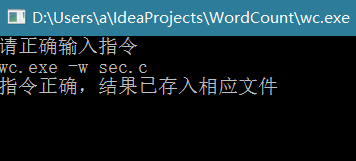

-l 命令


-s 命令

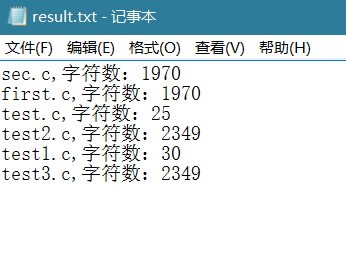
-a 命令
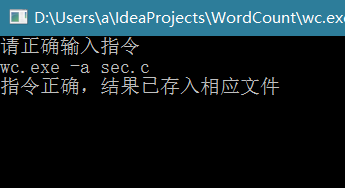

停用词表功能
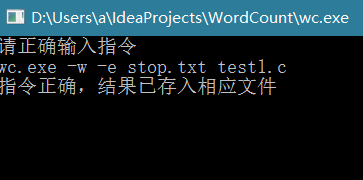


由于文件中存在两个停用词,haha和h;,test1.c中有三个词是停用词,所以单词数变为1,测试正确
(2)现在,我们测试命令的组合使用:
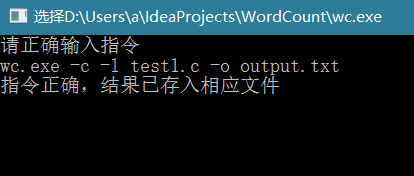

现在我们将命令的顺序进行调换,看看是否显示正确规定的顺序:
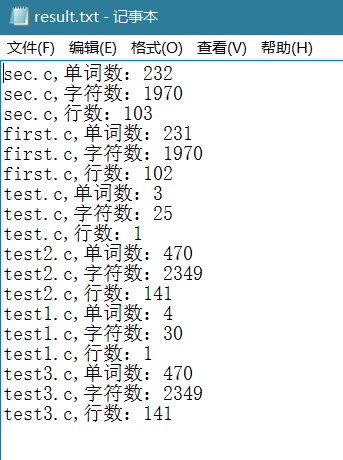
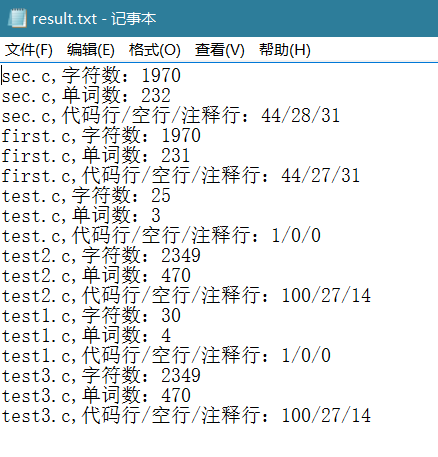
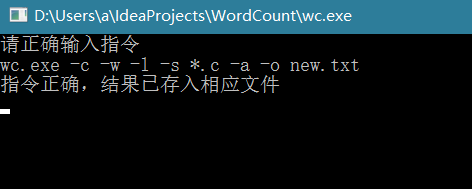
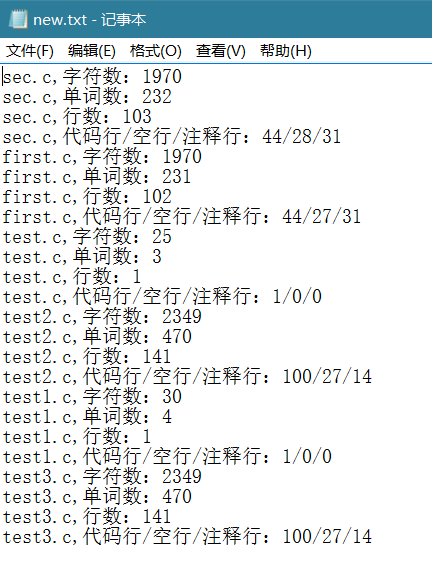
这里需要说明一点,为了测试递归处理是否有用,我在项目文件中加了一个test文件夹,然后将一些文件加入了这个文件夹,看是否能够处理,这里有些数据相同的原因是,我直接将项目文件中的一些文件改了名字就放进了test文件夹,也就是说有些文件名字不同,里面的东西是一样的。

七、不足
(1)首先,写代码之前没有花要多时间规划,使代码结构不是很清晰,略显冗杂,并且由于时间略紧,没有及时作出代码优化
(2)只能手动在控制台进行输入,而且只能输入一个正确命令,完成一次输出后需关闭在进入才能输入下一个指令
(3)没有书写具体的错误指令识别代码,只对开头是否为“wc.exe”做了判断
八、总结
这次最让我感触深的一点就是它提醒了我,提前规划的重要性,记得刚开始学习编码的时候遇到过这种问题,没想到现在居然又犯了这种错误,以后无论怎样都要提前规划好,否则会给后面的编码工作带来很多麻烦。
九、参考网站
http://blog.csdn.net/ben_wind/article/details/78180583
http://blog.csdn.net/ycy0706/article/details/45457311
http://blog.csdn.net/baidu_31657889/article/details/52328430
