《综合与Design Compiler》笔记
《综合与Design Compiler》笔记
一直没系统的整理过DC这块的东西,这里借助一个挺好的文档《综合与Deisgn Compiler》以及我自己的经验和理解来归总一下。
1. 综合是什么
综合是使用软件的方法来设计硬件,然后将门级电路实现与优化的工作留给综合工具的一种设计方法。它是根据一个系统逻辑功能与性能的要求,在一个包含众多结构、功能、性能均已知的逻辑元件的单元库的支持下,寻找出一个逻辑网络结构的最佳实现方案。即实现在满足设计电路的功能、速度及面积等限制条件下,将行为级描述转化为指定的技术库中单元电路的连接。
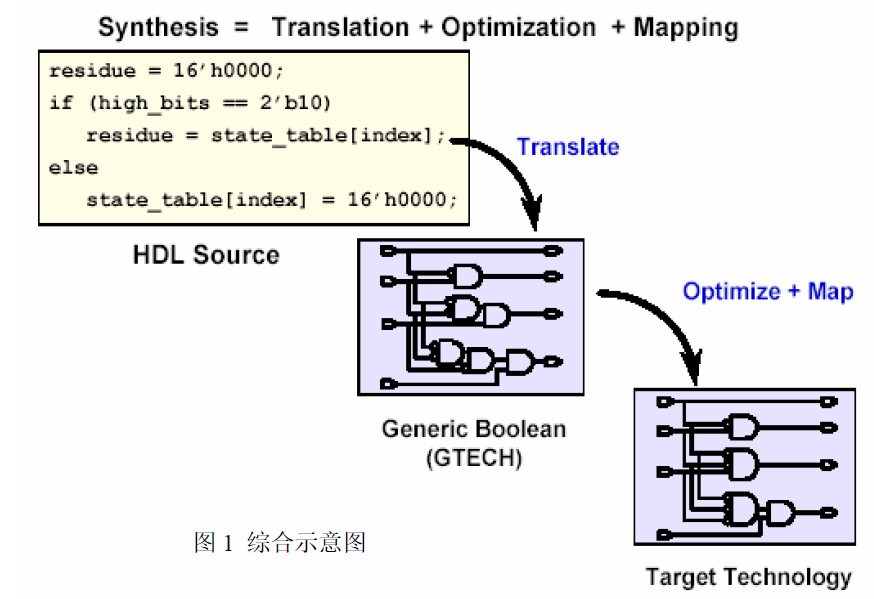
综合分为转换,映射,优化三个阶段,先把HDL描述转换成RTL级网表(此时与工艺库无关),再映射到指定的工艺库形成门级网表,最后根据延时、面积等设计约束进行网表优化。
我们这次讨论的所有综合都是基于Synopsys Design Compiler综合工具。
2. Verilog到网表的映射
Verilog编码会影响综合生成的电路的质量,因此代码编写时需要满足一定的规则,例如要保证代码的可综合性,不使用无法综合的语句;尽量多使用同步逻辑,将同步逻辑和异步逻辑分开处理;注意代码编写的抽象层次,尽量使用RTL级的描述等。
对于一个优秀的设计者来说,清楚的知道自己编写的代码会被综合成何种电路,以及如何控制工具去综合出自己想要的电路是非常重要的。
接下来介绍一些典型Verilog语句到具体电路之间的映射关系。
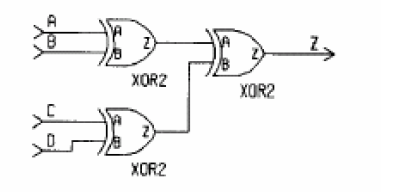
首先是基本的组合逻辑块,Verilog描述的逻辑关系会与实际电路直接映射,例如:
always@(A or B or C or D) begin
Temp1 = A ^ B;
Temp2 = C ^ D;
Z = Temp1 ^ Temp2;
end
生成的电路是:
对于verilog的if语句来说,会产生受条件控制的电路,例如:
always@(Ctrl or A or B) begin
if(Ctrl)
Z = A & B;
else
Z = A | B;
end
产生的电路如下(A,B,Z均为2bit信号):
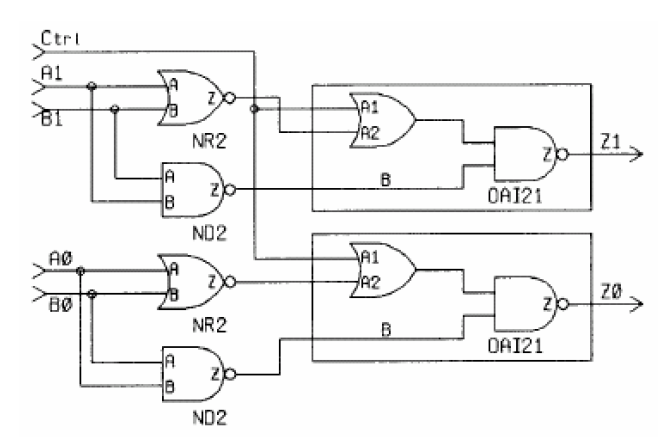
可以看到这里的逻辑选择功能与或门和与非门相关,将方框里或门和与非门组成的OAI21逻辑单元列逻辑表达式:
这里的\(X\)即\(\overline{A+B}\),\(Y\)即\(\overline{A\cdot B}\),如果\(C=1\),那么\(Z=0\cdot\overline{X}+\overline{Y}=\overline{Y}=A\cdot B\),如果\(C=0\),那么\(Z=1\cdot \overline{X}+\overline{Y}=\overline{X}+\overline{Y}=A+B+A\cdot B=A+B\cdot(1+A)=A+B\),因此:
这里利用了输入的性质进行了一些逻辑化简,如果是更一般的情况,我们需要的逻辑表达式是:
因此\(Z=\overline{C}\cdot \overline{X}+C\cdot \overline{Y}\),运用德摩根定律可以得到\(Z=\overline{(C+X)\cdot(\overline{C}+Y)}\),这个电路可以用一个OAI22来实现,只是控制比特\(C\)需要做一个反相。
如果if条件语句没有写全,就会出现latch的问题,例如:
always@(Marks) begin
if(Marks < 5)
Grade = FAIL;
else if((Marks >= 5) & (Marks < 10))
Grade = PASS;
end
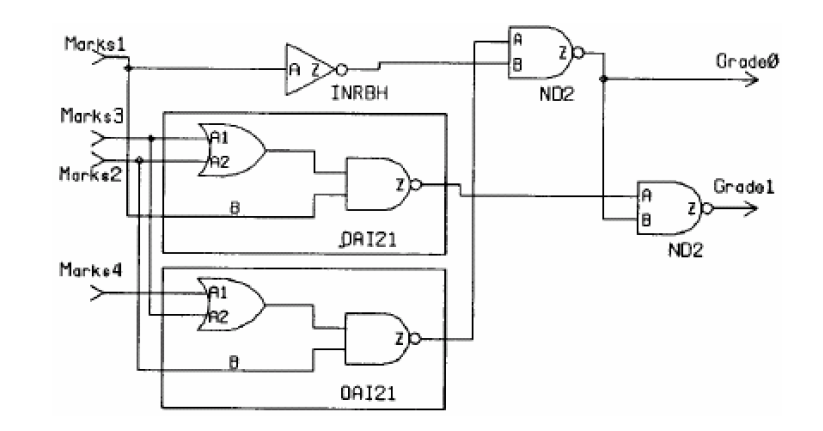
产生的电路如下(Mark为4bit信号,Grade为2bit信号):
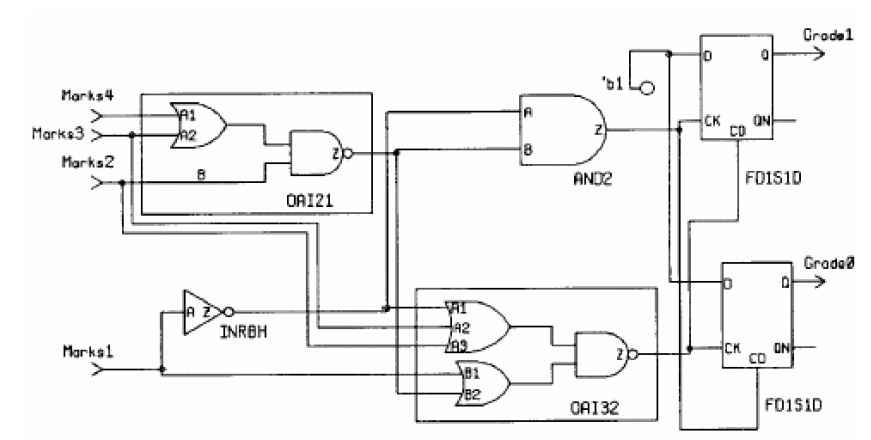
由于对于Marks大于等于10的输入条件没有判断,因此可以当成此时输出不予更新,即输出被锁存,因此此时会生成latch。
latch对于时序分析有非常负面的影响,会导致综合时产生unconstrained point。因此在代码上一定要规避这种情况,直截了当的方式就是补全条件:
always@(Marks) begin
if(Marks < 5)
Grade = FAIL;
else if((Marks >= 5) & (Marks < 10))
Grade = PASS;
else
Grade = ExCELLENT;
end
此时就可以完全规避latch的产生:
这里需要注意的问题是,使用if语句描述的电路是隐含了优先级的,即语句顺序上写在前面的逻辑会被优先判断。而对于case语句来说,如果其是条件互斥的(即不存在同时满足多个条件的情况),那么就不存在优先级的概念。
例如:
always@(Op or A or B) begin
case (Op)
ADD : Z = A + B;
SUB : Z = A - B;
MUL : Z = A * B;
DIV : Z = A / B;
endcase
end
对应的电路为:
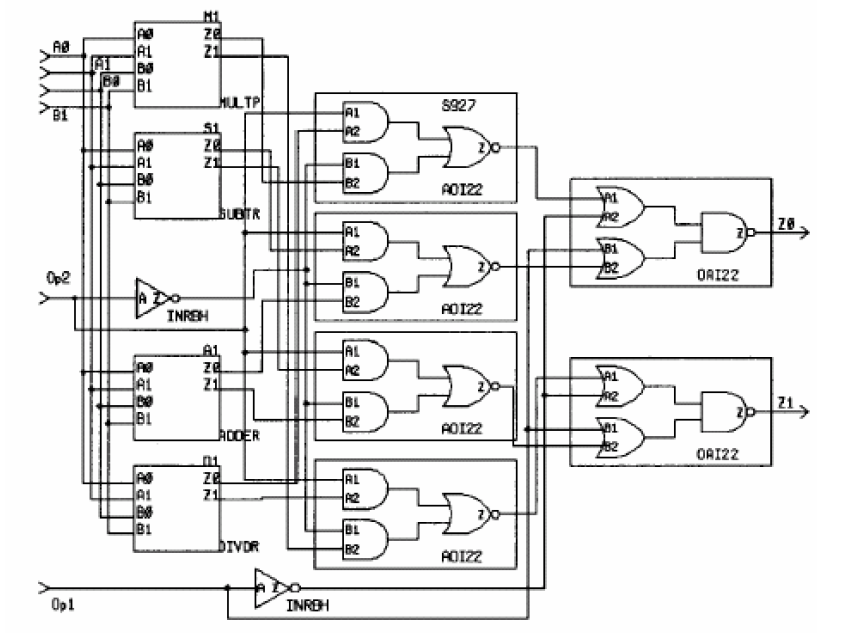
如果使用casex语句可以实现优先级编码,例如:
always@(Toggle) begin
casex(Toggle)
3'bxx1 : NextToggle = 3'b010;
3'bx1x : NextToggle = 3'b110;
3'b1xx : NextToggle = 3'b001;
default: NextToggle = 3'b000;
endcase
endmodule
产生的电路为:
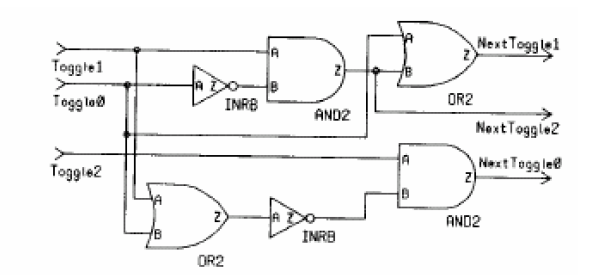
其功能和下面的if语句一致:
if(Toggle[0] == 1'b1)
NextToggle = 3'b010;
else if(Toggle[1] == 1'b1)
NextToggle = 3'b110;
else if(Toggle[2] == 1'b1)
NextToggle = 3'b001;
else
NextToggle = 3'b000;
和if的情况类似,如果没有指出case的全部情况,那么会引入latch,例如:
always@(Toggle) begin
case(Toggle)
2'b01 : NextToggle = 2'b10;
2'b10 : NextToggle = 2'b01;
endcase
end
产生的电路为:
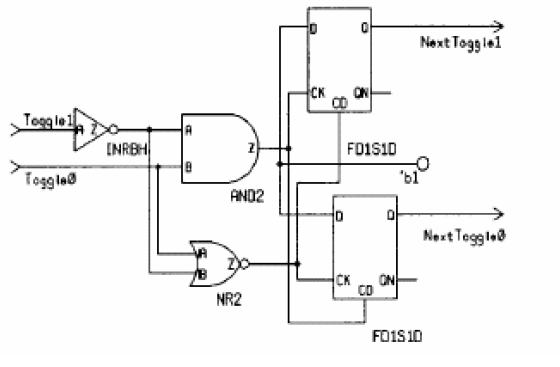
原因和if产生latch的情况类似,如果出现了未被条件分支包含的解决的方案是增加一个default的描述:
always@(Toggle) begin
case(Toggle)
2'b01 : NextToggle = 2'b10;
2'b10 : NextToggle = 2'b01;
default : NextToggle = 2'b01;
endcase
end
对于case语句来说,可以通过综合指令的方式来指定一些特殊情况,例如,如果设计者已经知道除了列出的case之外不会出现其他的条件,而又不想让工具综合出latch,那么可以使用综合指令synopsys full_case来传达,具体来说:
always@(Toggle) begin
case(Toggle) // synopsys full_case
2'b01 : NextToggle = 2'b10;
2'b10 : NextToggle = 2'b01;
endcase
end
但需要注意的两个问题是:
- 加入综合指令会使代码的结果依赖于所用的综合工具,从而降低代码的可移植性
- 加入综合指令后产生的电路网表会和当初的Verilog建模有出入,导致验证的复杂
另一种情况是,假设我们已经知道了case的条件是互斥的(互斥的情况下,case会平行的检查所有可能的情况,而不是先检查第一个再检查第二个),为了实现并行检查,可以加入synopsys parallel_case指令,这样综合工具会理解case项是互斥的,从而避免产生带优先级的电路,而是平行的译码结构(或者MUX),例如:
always@(Toggle) begin
casex(Toggle) // synopsys parallel_case
3'bxx1 : NextToggle = 3'b010;
3'bx1x : NextToggle = 3'b110;
3'b1xx : NextToggle = 3'b001;
default: NextToggle = 3'b000;
endcase
endmodule
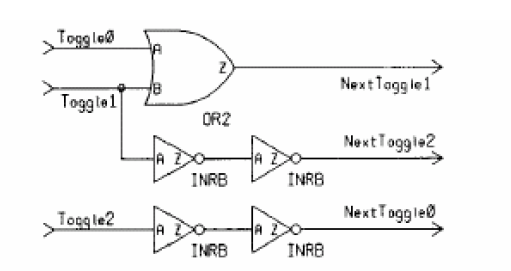
对应的if语句为:
if(Toggle[0] == 1'b1)
NextToggle = 3'b010;
if(Toggle[1] == 1'b1)
NextToggle = 3'b110;
if(Toggle[2] == 1'b1)
NextToggle = 3'b001;
if((Toggle[0] != 1'b1) && (Toggle[1] != 1'b1) && (Toggle[2] != 1'b1))
NextToggle = 3'b000;
值得一提的是,在systemverilog中可以使用unique case来指定互斥的case条件语句(对应并行编码电路),用priority case来指定带有优先级的case条件语句(对应优先级编码电路)
unique case (<case_expression>)
... // case items
endcase
priority case (<case_expression>)
... // case items
endcase
进一步通过systemverilog的always_comb语句可以控制电路综合时不产生latch。因此一个ALU可以写成:
always_comb
unique case (opcode)
2’b00: y = a + b;
2’b01: y = a - b;
2’b10: y = a * b;
2’b11: y = a / b;
endcase
现在的仿真工具和综合工具已经能够支持systemverilog和verilog的混编,因此一些设计需求可以考虑用systemverilog来实现从而解决之前提到的用编译指令带来的影响可移植性和网表与verilog建模不一致的问题。具体内容可以参考以前的博客。
当我们需要重复性的产生电路时,可以使用verilog中的loop语句,最常用的是for-loop语句,具体来说:
integer J;
always@(Address) begin
for(J=3; J>=0; J=J-1) begin
if(Address == J)
Line[J] = 1;
else
Line[J] = 0;
end
end
在这个例子会产生下面的电路:
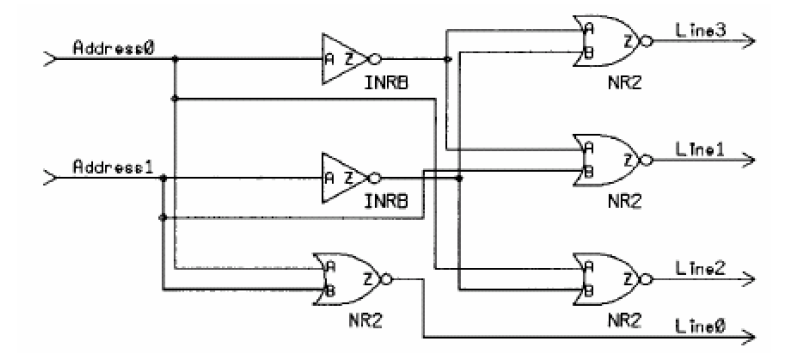
而如果展开编写的话则等效于:
if(Address == 3) Line[3] = 1; else Line[3] = 0;
if(Address == 2) Line[2] = 1; else Line[2] = 0;
if(Address == 1) Line[1] = 1; else Line[1] = 0;
if(Address == 0) Line[0] = 1; else Line[0] = 0;
显然对于多次重复的电路来说,用loop来产生是更高效的做法,基本的for循环语句只可以用于赋值操作。如果涉及例化,常见的做法是用genvar以及generate for来进行,例如:
genvar i;
generate
for(i=0;i<4;i=i+1) begin:half_addr_f
half_addr u_half_addr(
.a (add_a[i] ),
.b (add_b[i] ),
.bin (bin[i] ),
.sum (sum[i] )
);
end
endgenerate
触发器是时序电路的基本元件,当电路中编写边沿触发的时序逻辑块时就会被综合成含触发器的电路,例如:
always@(posedge ClockA) begin
counter <= Counter + 1;
end
这种情况下对应的电路为:
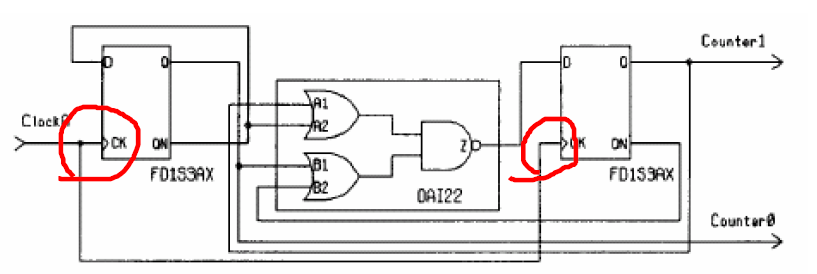
可以看到这里共产生了两个触发器,分别用来处理信号Counter的0比特和1比特,其CK端连接到了ClockA信号上。注意always块里的赋值需要使用非阻塞赋值(Counter <= Counter + 1),这样才可以准确的反映时序电路的行为。
对于算数符号来说,DC会在综合时将其转换成DesignWare库中合适的逻辑电路来实现。例如+,-,×等算术符号,>,<,>=,<=等逻辑符号等。针对同一种运算符,DesignWare可以根据不同的算法选择使用哪种实现方式。DesignWare库可以分为Basic和Foundation,Basic库提供基本的电路,Foundation提供性能较高的电路,但需要额外的License。

3. Design Compiler工作流
Design Compiler的工作过程可以划分为以下四个阶段:
- 预综合过程
- 设计约束过程
- 设计综合过程
- 后综合过程
3.1 预综合过程
综合之前为综合进行准备的步骤,包括了Design Compiler的启动,设置各种库文件,创建启动脚本,读入设计文件,设计对象/各种模块的划分等。
Design Compiler可以通过dc_shell命令来启动,通过-f参数可以直接在启动的同时直接运行tcl脚本,一个常见的做法是将命令集成在makefile中:
#start dc
dc:
../work/dc && dc_shell -f ./scripts/run_dc.tcl | tee ./syn.log
接着进行库文件的设置,可以分为工艺库,链接库,符号库和综合库。
工艺库是综合后电路网表要映射到的库,由代工厂(Foundry)提供,有时Foundry提供的库是.lib的格式,需要通过DC将其转换为DC可以吃入的.db格式,一般也称为标准单元库(Standard Cells Library,StdCells Lib)。
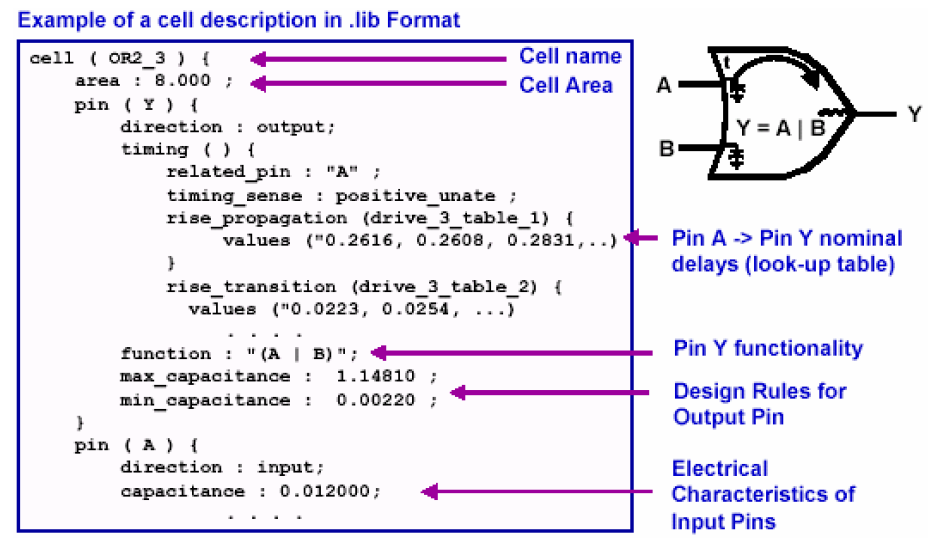
工艺库中包含了各个门级单元的行为、引脚、面积以及时序信息(有的工艺库还有功耗方面的参数),DC在综合时就是根据target_library中给出的单元电路的延迟信息来计算路径的延迟。并根据各个单元延时、面积和驱动能力的不同选择合适的单元来优化电路。可以通过下面的tcl命令来指定工艺库:
set target_library stdcel.db
在一些情况下,我们会将映射目标定为多个库,比如lvt,svt,hvt三个库,那么我们可以这样处理:
# standard cell library
set stdcel_libs "
stdcel_lvt.db
stdcel_svt.db
stdcel_hvt.db
"
set target_library "$stdcel_libs"
链接库link_library设置模块或者单元电路的应用,例如memory,io,ip等。值得注意的一点是:在link_library的设置中必须包含’*’, 表示DC在引用实例化模块或者单元电路时首先搜索已经调进DC memory的模块和单元电路,如果在link library中不包含’*’,DC就不会使用DC memory中已有的模块,因此,会出现无法匹配的模块或单元电路的警告信息(unresolved design reference)。
例如:
# memory library
set mem_libs "
mem.db
"
# io library
set io_libs "
io.db
"
# ip library
set ip_libs "
ip.db
"
set target_library "$stdcel_libs"
set link_library "* $target_library $mem_libs $io_libs $ip_libs"
符号库是定义了单元电路显示的Schematic的库。用户如果想启动design_analyzer或design_vision来查看、分析电路时需要设置symbol_library。符号库的后缀是.sdb,加入没有设置,DC会用默认的符号库取代。符号库对于综合本身没有直接的影响,如果标准单元库内没有找到符号库也不干扰综合的过程。
最后是综合库,在初始化DC的时候,不需要设置标准的DesignWare库standard.sldb用于实现Verilog描述的运算符,对于扩展的DesignWare(即DW Foundation),需要在synthetic_library中设置,同时需要在link_library中设置相应的库以使得在链接的时候DC可以搜索到相应运算符的实现。
具体来说:
set synthetic_library "dw_foundation.sldb"
set link_library "* $target_library dw_foundation.sldb"
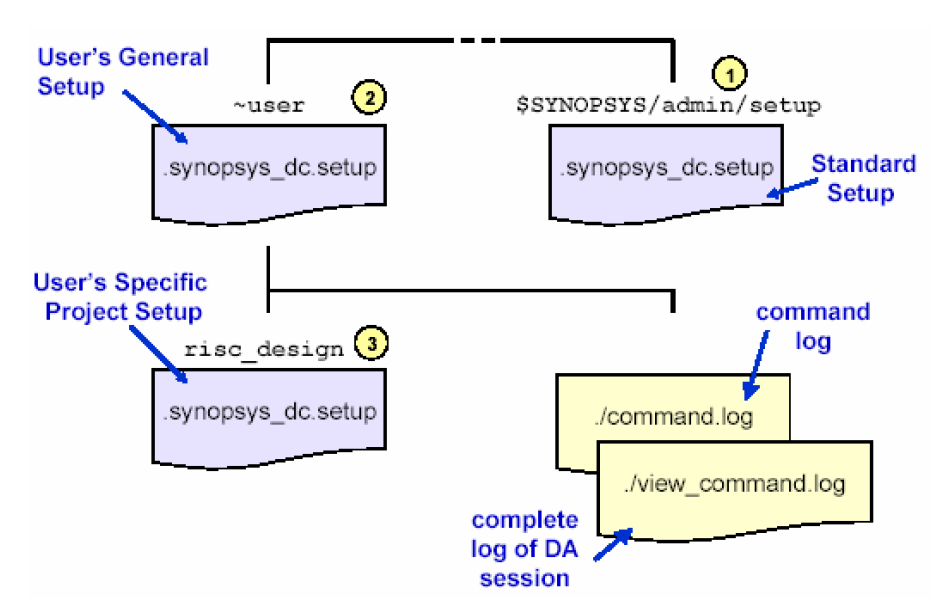
关于启动脚本.synopsys_dc.setup,启动脚本顾名思义,就是DC在启动的时候首先读入的脚本,DC在启动的时候,会自动在三个目录下搜索该脚本(如下图所示),对DC的工作环境进行初始化:
- $SYNOPSYS/admin/setup目录下,DC安装的标准初始化脚本。
- 当前用户的$HOME目录下,一般用于设置一些用户本人使用的变量以及一些个性化设置。
- DC启动所在的目录下,一般用于与所在设计相关的设置。
其中后面的setup脚本可以覆盖前面脚本中的设置。该脚本主要包括库的设置、工作路径的设置以及一些常用命令别名的设置等等。
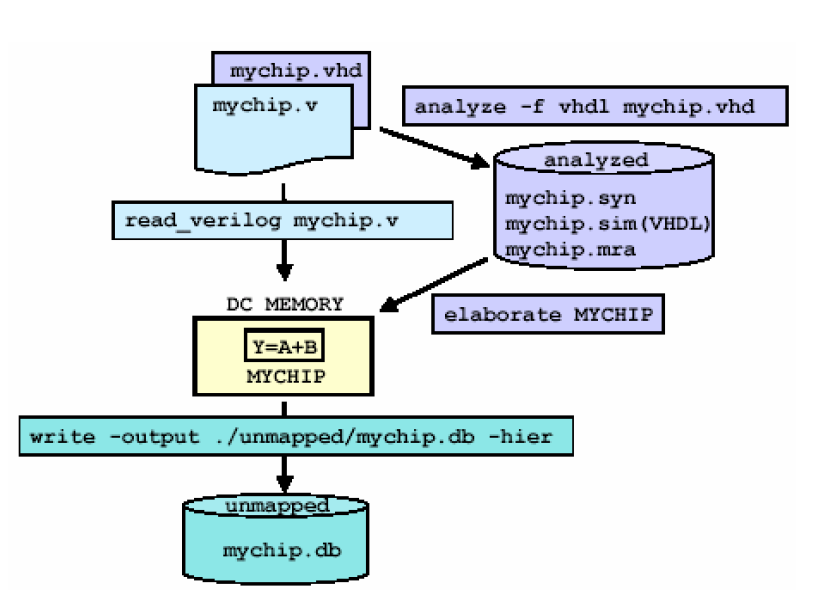
随后进行设计文件的读入,如下图所示,可以读入db(一般是对于ip等黑盒对象),verilog和vhdl文件等。对应的命令为:
read -format verilog[db,vhdl etc.] file
read_db file.db
read_verilog file.v
read_vhdl file.vhd
需要补充的有两个点,第一个是目前DC也可以读入systemverilog,通过下面的命令:
read -format sverilog file.sv
但其实更实用的读入方式是使用analyze:
analyze -f sverilog -vcs "-f ../../prj/filelist.f"
analyze -f verilog -vcs "-f ../../prj/filelist.f"
这样只需要通过filelist.f就可以控制综合时读入的文件,非常的方便。相关的讨论见这篇文章,但后续要配合elaborate指令。analyze是分析HDL的源程序并将分析产生的中间文件存于work(用户也可以自己指定)的目录下;elaborate则在产生的中间文件中生成verilog的模块或者VHDL的实体,缺省情况下,elaborate读取的是work目录中的文件。如下图所示:
当读取完所要综合的模块之后,需要使用link命令将读到Design Compiler存储区中的模块或实体连接起来,如果在使用link命令之后,出现unresolved design reference的警告信息,需要重新读取该模块,例如检查是否添加到了link_library中或者路径是否正确。
我们可以使用current_design来指定设计对象,一般来说设计对象就是我们设计的顶层模块的名字,例如如果顶层为:
module top (
...
);
endmodule
那么就要通过current_design top来进行指定。
所以这里的过程一般是:
set design_name "xxx"
# 之前介绍过的读入库操作,set link_library "* $target_library ..."
analyze -f verilog -vcs "-f ../../prj/filelist.f"
elaborate $design_name
current_design $design_name
link
对于一些复杂的设计,可能需要将其划分成几个相对简单的部分,称为设计划分。在平常的电路设计中这是一种普遍使用的方法,一般我们在编写HDL代码之前都需要对所要描述的系统作一个系统划分,根据功能或者其他的原则将一个系统层次化的分成若干个子模块,这些子模块下面再进一步细分。这是一种设计划分,模块(module)就是一个划分的单位。在运用DC作综合的过程中,默认的情况下各个模块的层次关系是保留着的,保留着的层次关系会对DC综合造成一定的影响,比如在优化的过程中,各个子模块的管脚必须保留,这势必影响到子模块边界的优化效果。因此在设计划分时有一些必须要注意的原则。
首先要避免让一个组合逻辑穿越过多的模块,如下图所示就是一个糟糕的设计:
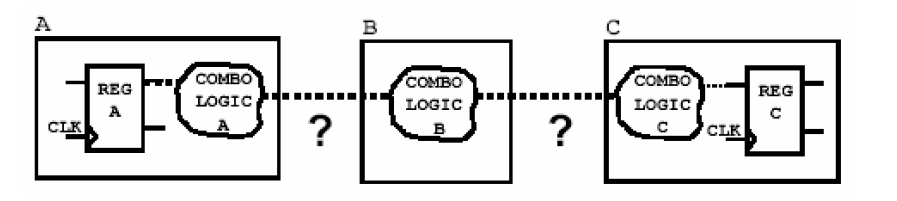
上图中的组合逻辑电路存在于寄存器A与寄存器C之间,它同时穿过了模块A、模块B以及模块C。前面提到了,如果直接将这样的划分交给DC综合,那么综合后的电路将仍旧保持上面的层次关系,即端口定义不会改变。这样的话,DC在作组合电路的优化的时候就会分别针对A、B、C三块电路进行,这样势必会影响到DC的优化能力,不必要的增加了这条路径的延时和面积。
因此一个优化的方式就是将组合逻辑进行集中:
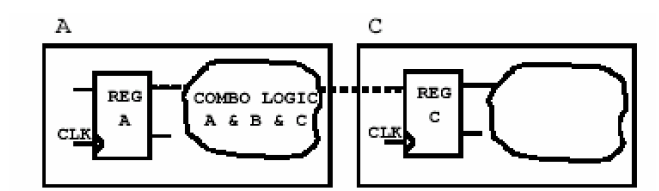
这张图说明了组合电路划分到一个模块之后的电路情况,这样DC就可以充分的施展它的的优化技巧,综合出比较满意的电路来。为什么说它只是一个较好的划分呢?因为它只是考虑到组合电路的最优划分而没有想到时序电路部分。先看下面一张图——
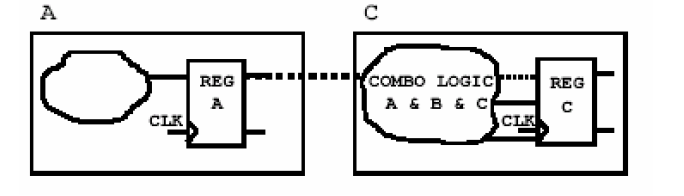
在这张图里,组合逻辑被划到了C模块中,它不仅能保证组合的最佳优化还能保证时序的最佳优化,因为里面的寄存器在优化的过程中可以吸收前面的组合逻辑,从而形成其他形式的时序元件,如由原先的D触发器变成JK触发器、T触发器、带时钟使能端的触发器等等。这样工艺库中的大量的时序单元都可以得到充分的利用了。
因此在设计时,我们需要注意尽力采用寄存器作为模块的输出:

通过前面的讨论,可以知道:在编写代码或者综合的过程中,我们可以把模块尽量写成这样的逻辑结构:将所有的输出寄存起来。其实这样不但是最佳的优化结构,也可以简化时序约束(使得所有模块的输入延时相等)。
就算遵循了输出寄存的原则,我们还是可能犯下面的错误(这是新手经常犯的错误)——
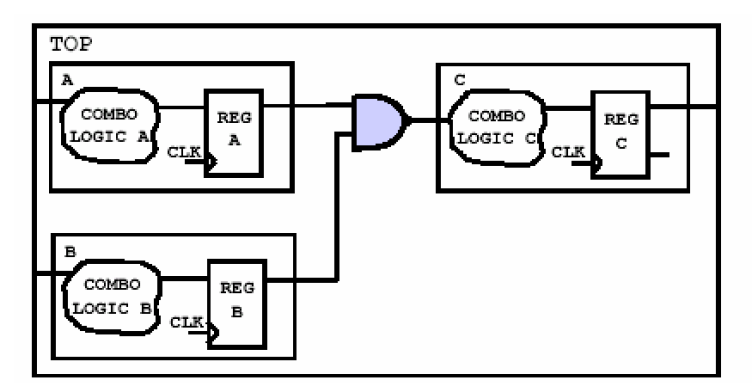
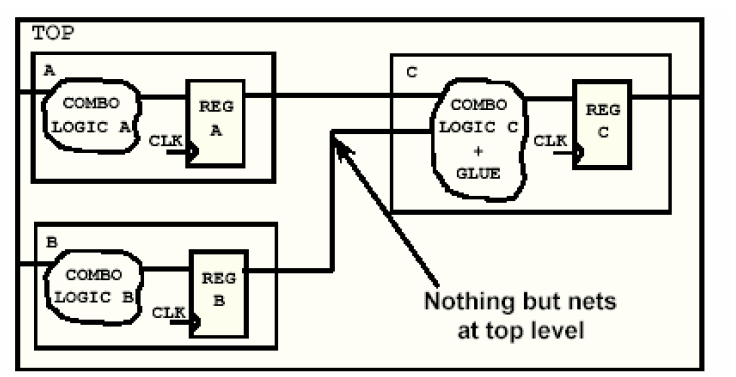
图中可以看到,一个与非门连接了A、B、C三个模块,同样的不难看出来,它也会影响到C的组合逻辑的优化。一般这种情况只会在至下而上的综合策略中才出现。可以通过把与非门吸收到C中的组合逻辑的方法消除粘滞逻辑(如下图),从而使得电路的顶层模块仅仅是将子模块拼接在一起,而没有独立的电路结构,这样的一个另一个好处是可以使得在至下而上的设计策略中不需要编译顶层模块。
此外我们最好根据综合时间长短控制模块的大小,模块的大小一般可以由门数来判断,例如一个坏的划分如下图所示:
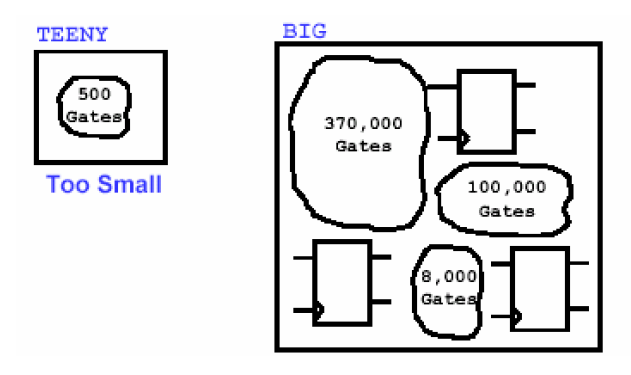
这个例子的模块大小从500门到37万门不等,假设工作站的硬件条件限制最多只能跑30万门的设计,那么上面的这种划分就有一些弊病。首先,TEENY模块太小,不适合优化出最好的结果,可以考虑将它合并到其他模块中。其次,另一个组合模块逻辑太大,这势必使得综合的时间变得不能承受。因此,改进的划分可以如下图所示——
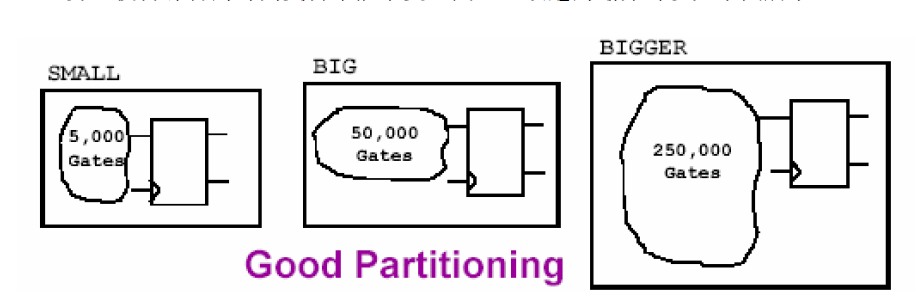
可以看到,虽然各个模块也是大小不一,但却可以取得较前面的划分更好的结果。值得注意的是——Design Compiler软件本身没有模块大小的限制,它完全根据服务器的性能决定,在具体作设计的时候,我们可以在服务器条件允许的条件下编译较大的模块,假如服务器条件的确有限,只能选择小的模块来综合了。
最后,一般要将同步逻辑部分与其他部分分离:
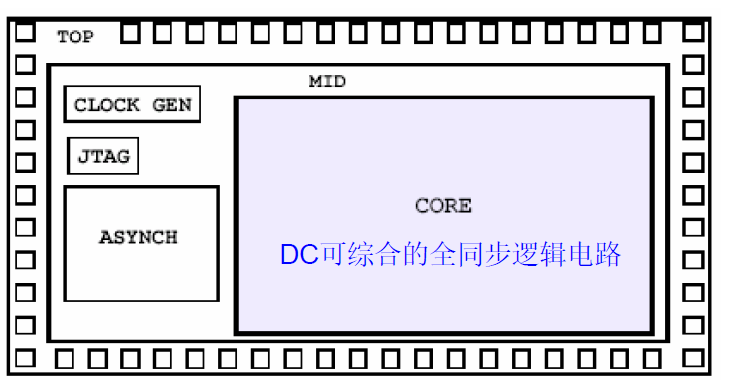
上图是一个芯片的顶层设计,可以看到它被分层了三个层次——最外边是芯片的Pad,Pad是综合工具中没有的,也不是工具能生成的,它由Foundry提供,并由设计者根据芯片外围的环境手工选择;中间一层被分成四个部分,其中最里面那个称为Core,也就是DC可以综合的全同步逻辑电路,另外的三个部分DC不能综合,需要其他的办法来解决:ASYNCH是异步时序部分,不属于DC的范畴;CLOCK GEN是时钟产生模块(可能用到PLL),尽管有一部分同步电路,但也不符合综合的条件;JTAG是边界扫描的产生电路,这一部分可以由Synopsys的另外一个工具BSD Compiler自动生成。
上面我们介绍了四个划分的原则,当然这些原则并不是我们在编写HDL代码的时候就必须遵守的,它只是说明什么样的设计划分对于DC来说是最理想的,能得到最优化的结果。事实上除了通过HDL中的模块体现划分,我们还可以运用DC的两个命令(Group及Ungroup)来调整设计划分。
先看一个例子,调整之前提到的那个划分不好的模块——
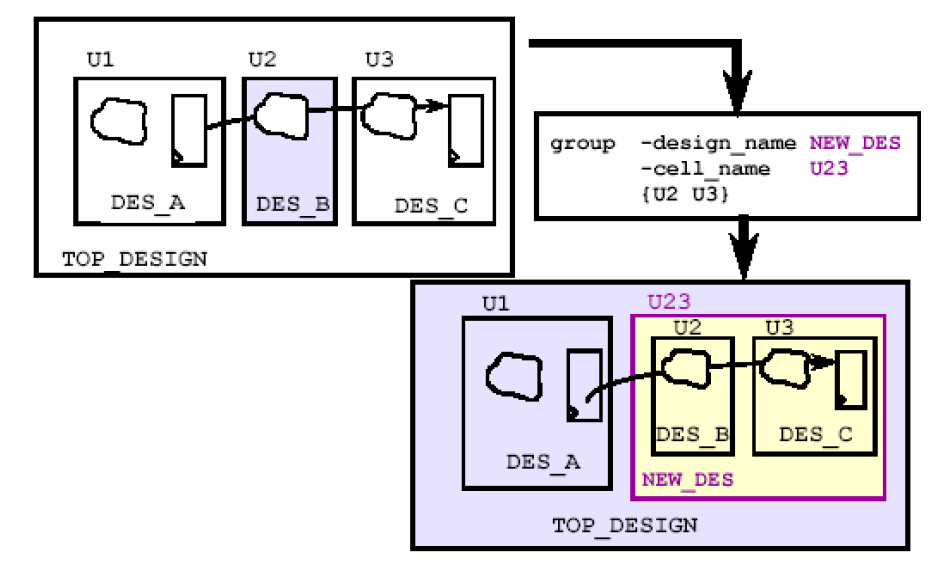
第一步是使用group命令,创建一个新的模块NEW_DES(设计名),单元名为U23,包含了U2和U3,这个命令很直观,很容易看懂。
第二步则是使用ungroup命令,将U23中的U2和U3的边界去掉,使之称为一个整体,如下图所示——
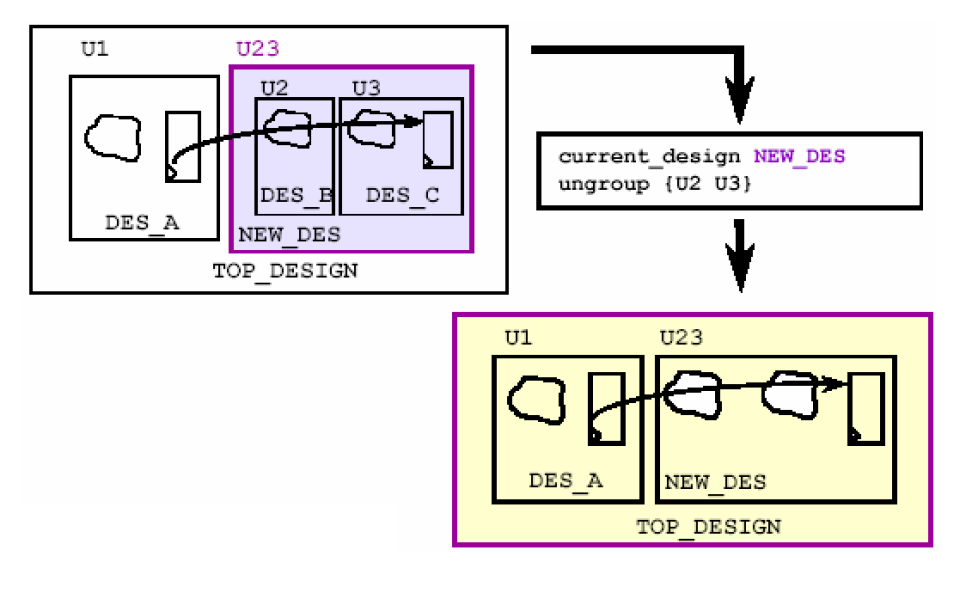
这样原来的U2和U3就成了一个新的整体。这样的指定思路可以帮助Design Compiler取得更理想的综合结果。
至此预综合过程基本就结束了。
3.2 设计约束过程
Design Compiler是一个约束驱动(constrain-driven)的综合工具,它的结果是与设计者施加的约束条件密切相关的。在这一章里,我们主要讨论怎样给电路施加约束条件,这些约束主要包括——时序和面积约束、电路的环境属性、时序和负载在不同模块之间的分配以及时序分析。
首先要明确我们在设计约束时会碰到的一些对象,如下图所示:
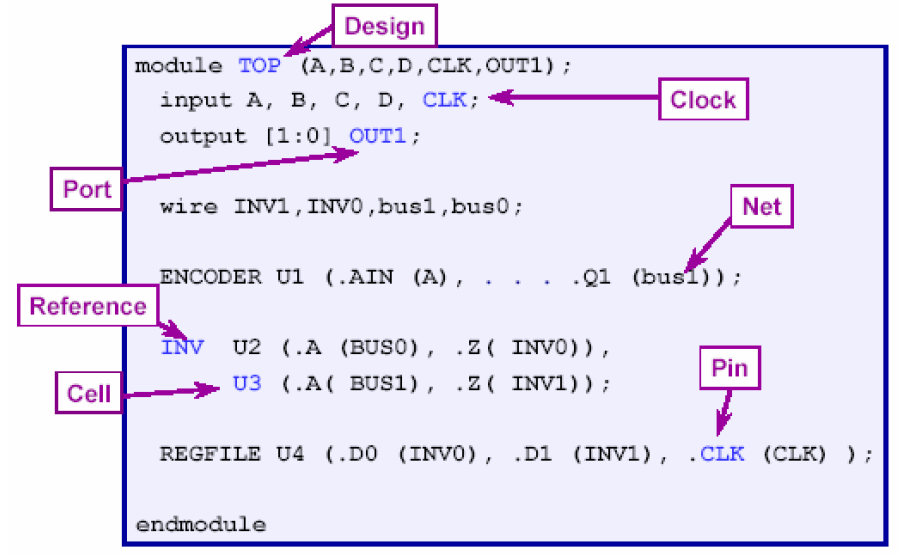
一般顶层模块在Design Compiler中被称作design,可以用current_design一类的命令来进行指定。CLK是时钟驱动信号,一般需要通过create_clock之类的命令来施加约束。顶层的输入和输出端口被称作Port,一般设计约束时需要在port上约束延时,负载,驱动之类的,可以用get_ports的命令来获取端口。内部的连线是Net,例化的来源是Reference,例化出的具体模块电路称为Cell,Cell的端口被称作Pin。
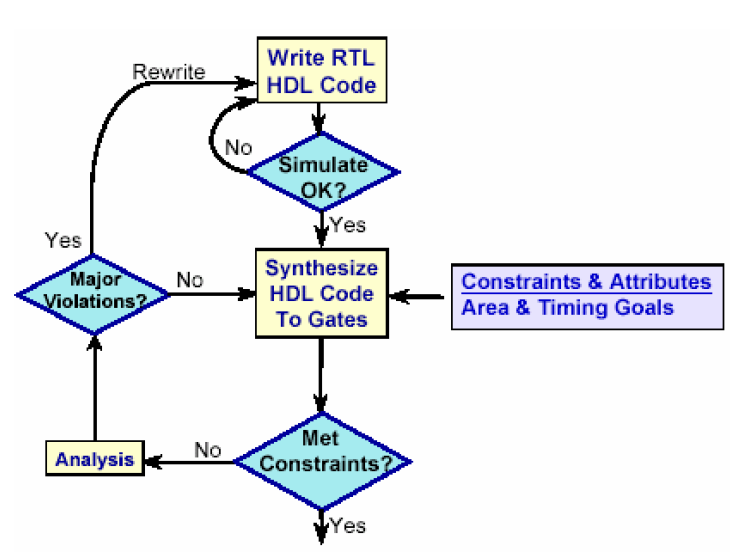
设计约束和设计是一体两面,可以看出在RTL代码仿真通过以后,就开始将它进行综合,综合时需要对他加入约束和设计属性的信息,DC根据这些约束将RTL模块综合成门级网表,然后分析综合出的网表是否满足约束条件,如果不满足就要修改约束条件,甚至重写RTL代码。
首先可以通过set_max_area和set_max_leakage_power对面积和漏电功耗进行约束。在综合时工具会尽量去满足这两个约束。set_max_area的值的单位需要根据lib的情况来,具体单位是由Foundry规定的,定义这个单位有三种可能的标准:一种是将一个二输入与非门的大小作为单位1;第二种是以晶体管的数目规定单位;第三种则是根据实际的面积(平方微米等等)。至于设计者具体用的是哪种单位,可以通过下面的一个小技巧得到——即先综合一个二输入与非门,用report_area看他的面积是多少,如果是1,则是按照第一种标准定义的;如果是4,则是第二种标准;如果是其他的值,则为第三种标准。可以用report_power看功耗的情况,synopsys的功耗分析其实比较复杂,简单的来说Design Compiler(准确的说是集成在DC中的Power Compiler)会假定一定的翻转率(默认是0.5),然后估计各个电路的内部功耗,开关功耗和漏电功耗,如果使用PrimeTime PX工具的话,可以进一步结合VCD文件来更加精确的分析功耗。一般来说为了最小化leakage power,工具会尽量在满足时序的前提下使用高阈值的器件。
一般在sdc文件中对这两个属性做如下约束:
set_max_leakage_power 0
set_max_area 0
然后就是时序约束了,这是非常重要的部分。需要设计者对设计的时序要求建立深刻的理解。
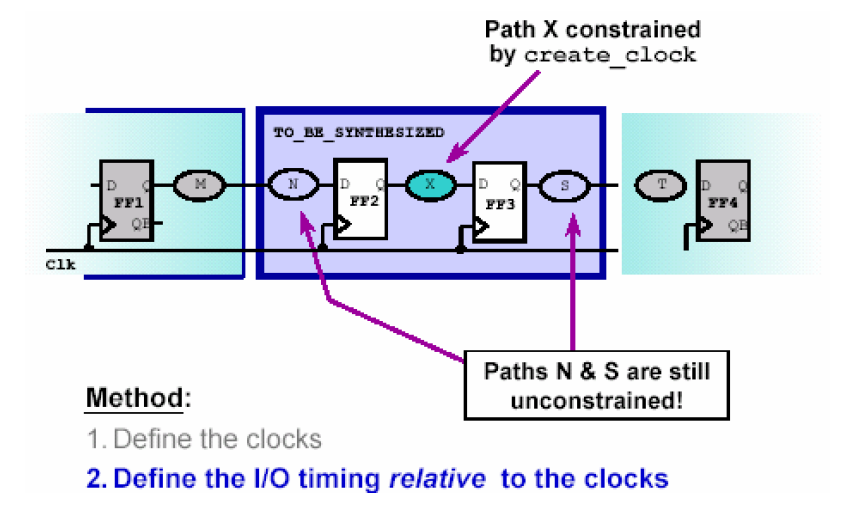
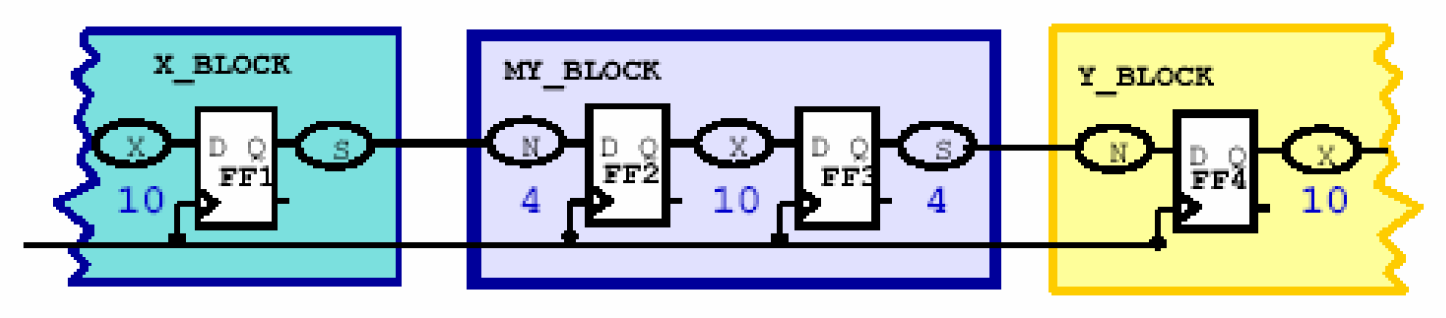
同步时序电路是DC综合的前提,因此这里有必要先讨论一下同步时序电路的特点及目标。这里所讨论的同步时序电路的特点是——电路中的信号从一个受时钟控制的寄存器触发,到达另一个受时钟控制的寄存器。而我们要达到的目标是——约束电路中所有的时序路径,这些时序路径可以分为三类:输入到寄存器的路径 、寄存器到寄存器之间的路径以及寄存器到输出的路径。他们分别对应与下图所示的标号为N、X和S的电路。
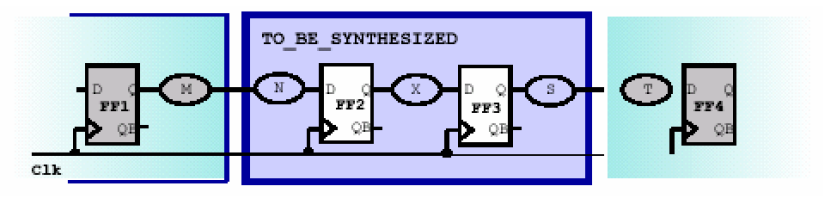
假设在上面的电路中,我们要控制触发器FF2到FF3之间的时序,即X电路的延时,那要通过什么方式让DC知道呢?显然一个直观的办法就是定义系统的时钟Clk,如果我们定义好了Clk的周期,那么DC会自动的尽量保证从FF2触发的信号能在一个周期内到达FF3寄存器。假如周期是10ns,FF3触发器的建立时间(setup time)是1ns,那么留给X电路的延时最大只能有10-1=9ns。
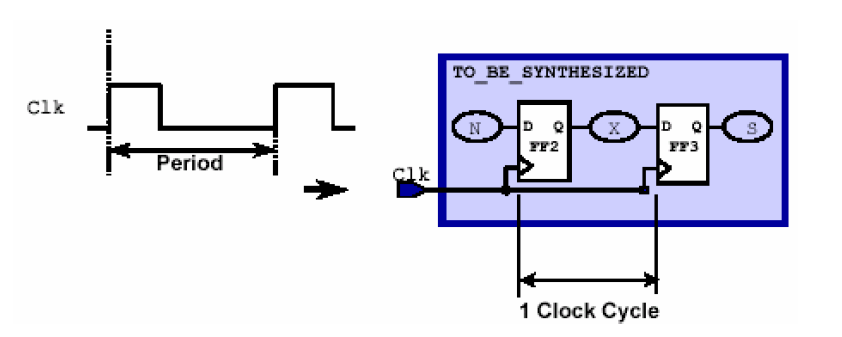
在电路综合的过程中,所有时序电路以及组合电路的优化都是以时钟为基准来计算路径延迟的,因此,一般都要在综合的时候指定时钟,作为估计路径延迟的基准。定义时钟的时候我们必须定义它的时钟源(Clock source),时钟源可以是端口也可以是管脚;另外还必须定义时钟的周期。另外有一些可选项,比如占空比(Duty Cycle)、时钟偏差(Clock Skew)和时钟名字(Clock Name)。定义时钟采用一个语句create_clock完成——
例如:
create_clock -period 10 [get_ports Clk]
set_dont_touch_network [get_clocks Clk]
第一句定义了一个周期为10ns的时钟,它的时钟源是一个称为Clk的端口。
第二句对所有定义的时钟网络设置为dont_touch,即综合的时候不对Clk信号优化。如果不加这句,DC会根据Clk的负载自动对他产生Buffer,而在实际的电路设计中,时钟树(Clock Tree)的综合有自己特别的方法,它需要考虑到实际布线后的物理信息,所以DC不需要在这里对它进行处理,就算处理了也不会符合要求。
可以看到,定义了系统时钟后,图44中的X电路已经被约束起来了,但是电路的输入输出两块还没有施加约束,这可以通过DC的另外两个命令来完成——
首先是约束输入路径。
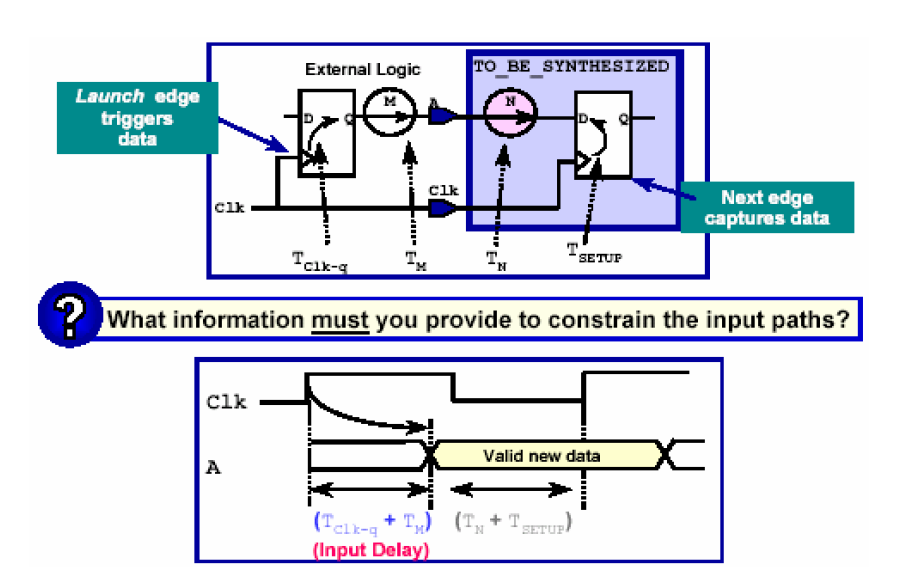
从上图可以看出,我们所要定义的输入延时是指被综合模块外的寄存器触发的信号在到达被综合模块之前经过的延时,在上图中就是外围触发器的clk-q的延时加上M电路的延时。当确定这段延时之后,被综合模块内部的电路延时的范围也可以确定下来了。加入时钟周期是20ns,输入延时是4ns,内部触发器的建立时间为1.0ns,那么就可以推断出要使电路正常工作,N电路的延时最大不能超过20-4-1.0=15.0ns。
设置输入延时是通过DC的set_input_delay命令完成的——
set_input_delay -max 4 -clock Clk [get_ports A]
如上面的语句指出了被综合模块的端口A的最大输入延时为4ns。-max选项是指明目前设置的是输入的最大延迟,为了满足时序单元建立时间(setup time)的要求。另外还有一个选项是-min,它是针对保持时间的约束使用的。-clk是指出这个端口受哪个时钟周期的约束。
定义了输入延时之后,相对应的还要设置电路的输出延时。
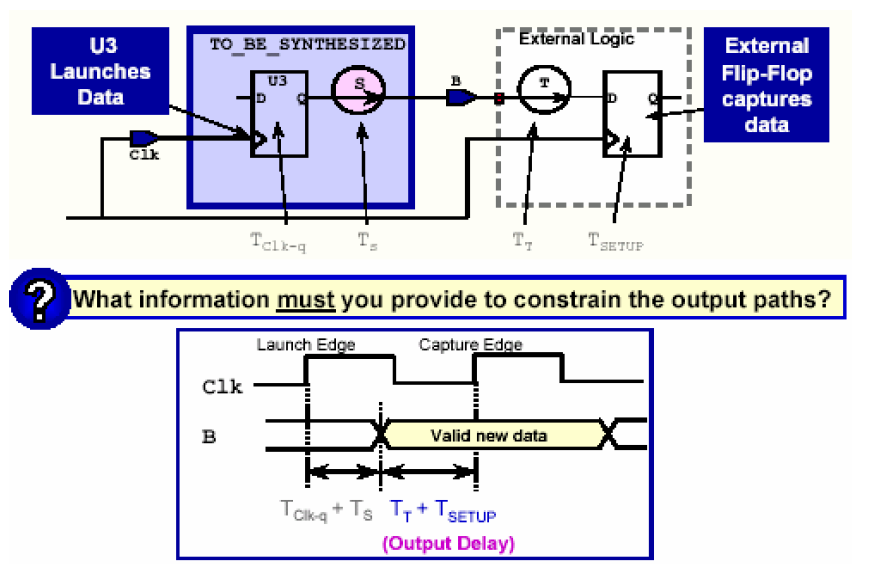
上图中,信号在被综合模块的触发器U3里触发,被外围的一个触发器接收。对外围电路而言,它有一个T电路延时和外围触发器的建立时间。当确定了他们的延时之后,被综合模块内部的输出路径延时范围也就确定下来了。假如,时钟周期20ns,输出延时5.4ns,U3触发器的clk-q延时为1.0ns,那么输入路径S的最大延时就是20-5.4-1.0=13.6ns。
设置输入延时是通过DC的set_output_delay命令完成的——
set_output_delay -max 5.4 -clock Clk [get_ports B]
上面的语句指出了被综合模块的输出端口B的最大输出延时为5.4ns。-max选项是指明目前设置的是输入的最大延迟;-clk是指出这个端口受哪个时钟周期的约束。
至此,模块的面积、时钟、输入输出延时都施加了相应的约束。
设计的约束情况可以利用Spyglass工具来检查,也可以通过DC内的report_clock(报告时钟的约束),report_port -verbose(报告输入输出端口属性和施加的约束值)等指令来检查,这里需要注意的问题有几个点,首先一定要有全面的约束,漏约束一定会导致综合出现问题;其次即使全面的定义时钟,并对端口都进行了约束,仍然可能由于不规范的写法导致内部综合出了latch,或者是写了逻辑回环等方式导致出现了内部出现unconstriant point,这种情况需要修改设计;最后在进行约束时,一般会进行一定的过约束,即比实际情况设置的更加严格一些,这样可以更好的确保电路可用。
3.2.1 进阶的时钟约束
此外针对时钟来说,还有一些更深入的设置问题。
首先我们需要考虑时钟的两个非理想因素,时钟本身的抖动和偏差问题,时钟源到时钟引脚的延时问题以及时钟的转换时间(上升时间和下降时间)问题,如下图所示:
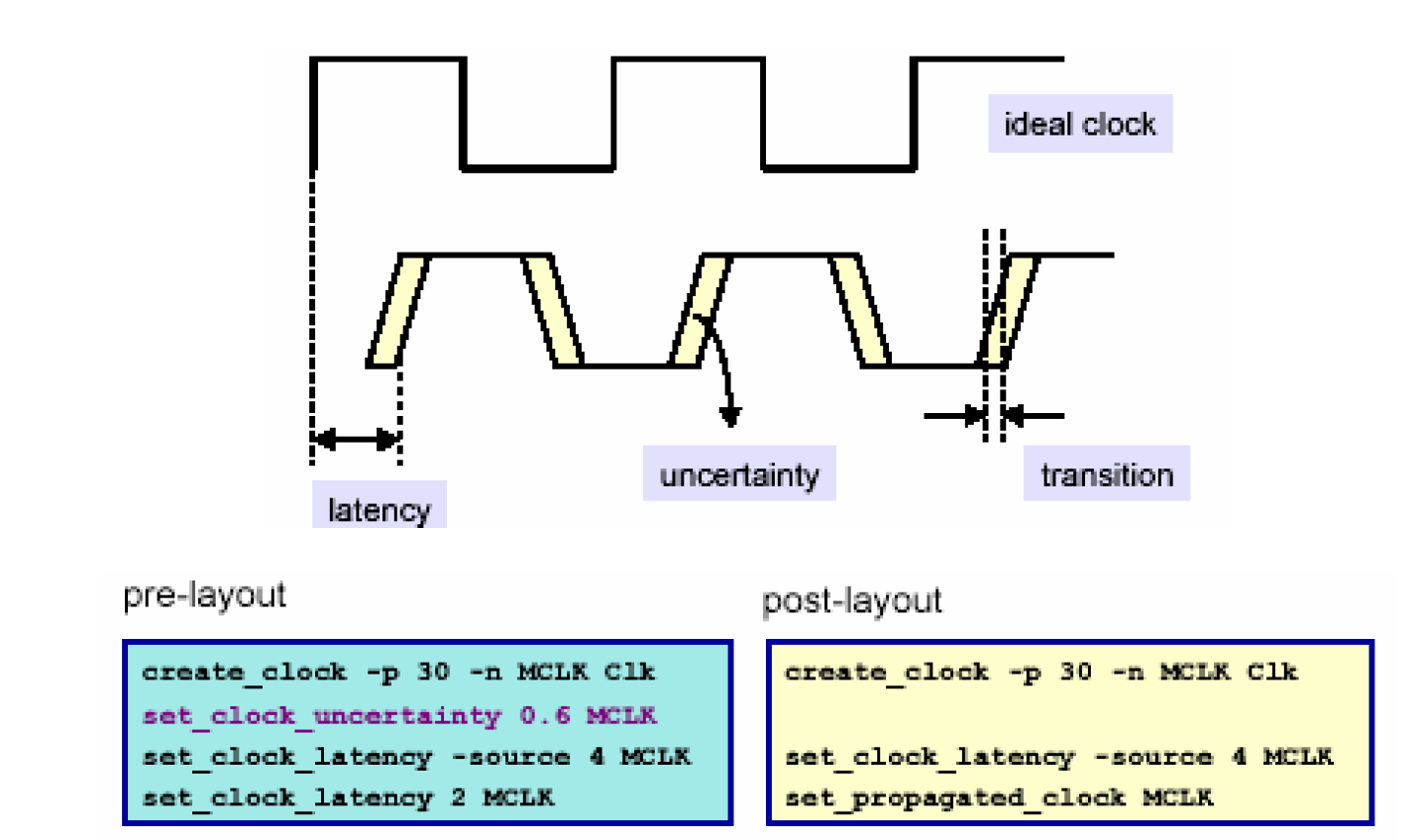
实际的时钟达到各个触发器的时间不是一样的,它们之间有一个偏差,称为时钟偏差(Clock Skew),为了反映这个偏差,我们在综合的时候可以用一个命令来模拟它,即set_clock_uncertainty,下面是一个例子——
create_clock -period 10 [get_ports CLK]
set_clock_uncertainty 0.5 [get_clocks CLK]
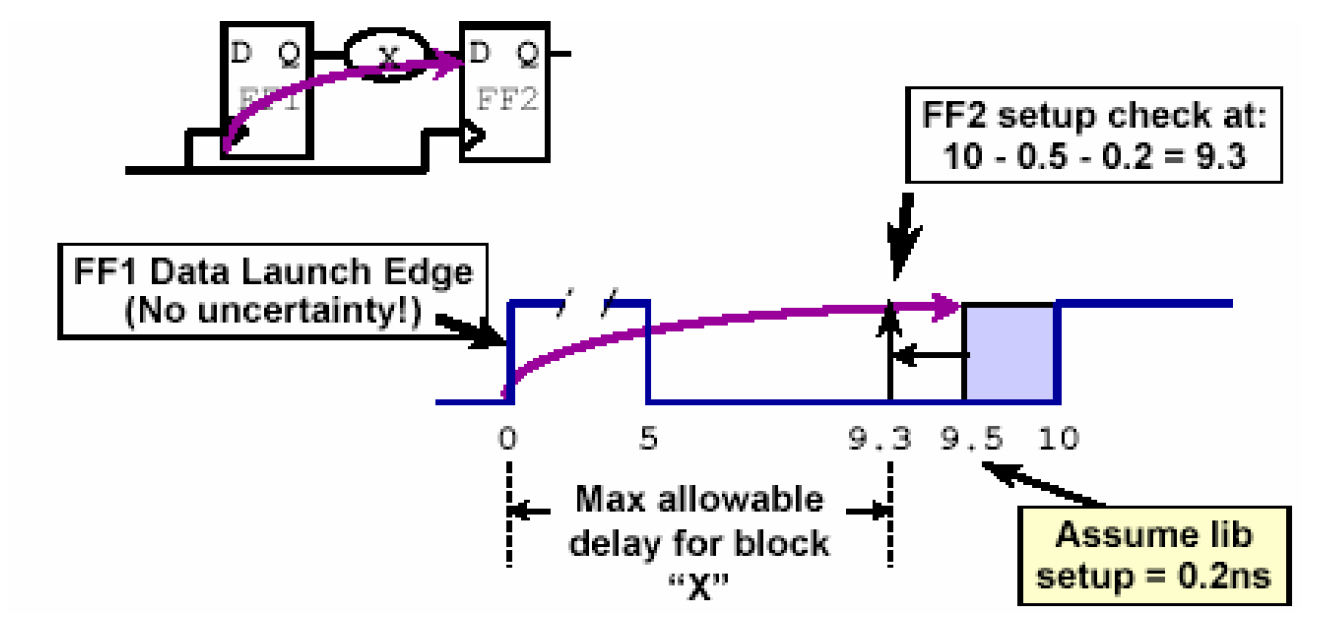
假设时钟周期是10ns,FF2的建立时间为0.2ns,预先估计时钟偏差为0.5ns,从FF1触发的数据必须在一个周期之内到达FF2,当引入时钟偏差以后,所谓的一个周期就不再是10ns,而可能最短为10-0.5=9.5ns,再减去0.2的建立时间,实际留给X路径的延时最大只能有9.3ns。
除了时钟偏差(Clock Skew)之外,还有两个命令值得注意,这就是set_clock_latency,和set_propagated_clock,如下图所示——
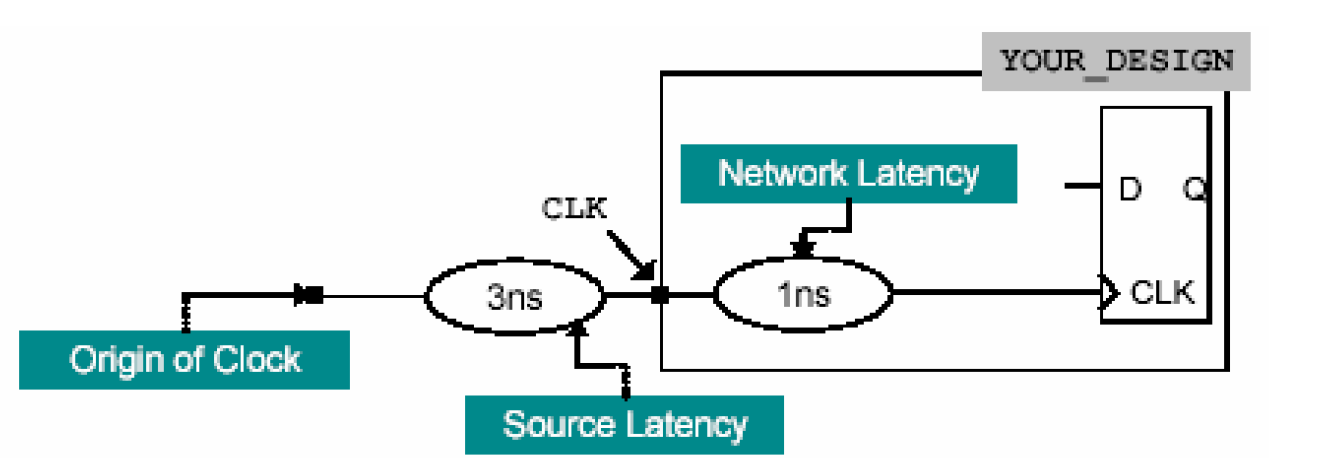
一般而言,时钟都是由一个专门的模块(Clock_gen)来生成的,这里称为时钟源(Clock Source),时钟产生之后,必定要经过一段网络延时才能到达被综合的模块,这段延时称为时钟源延时(Source Latency),到达模块的端口后,要到达内部的触发器,也要经过一定的延时,这个延时称为网络延时(Network Latency)。这分别通过set_clock_latency –source 和set_clock_latency来描述。另外,set_propagated_clock主要用在布局之后(post-layout)的综合上,意思是说,此时的网络延时已经可以由时钟树上的buffer确切的推断出来。
在布局前正因为没有buffer,才需要用网络延时和时钟偏移来模拟布局后的情况。
一些情况下,我们需要使用同步多时钟网络:
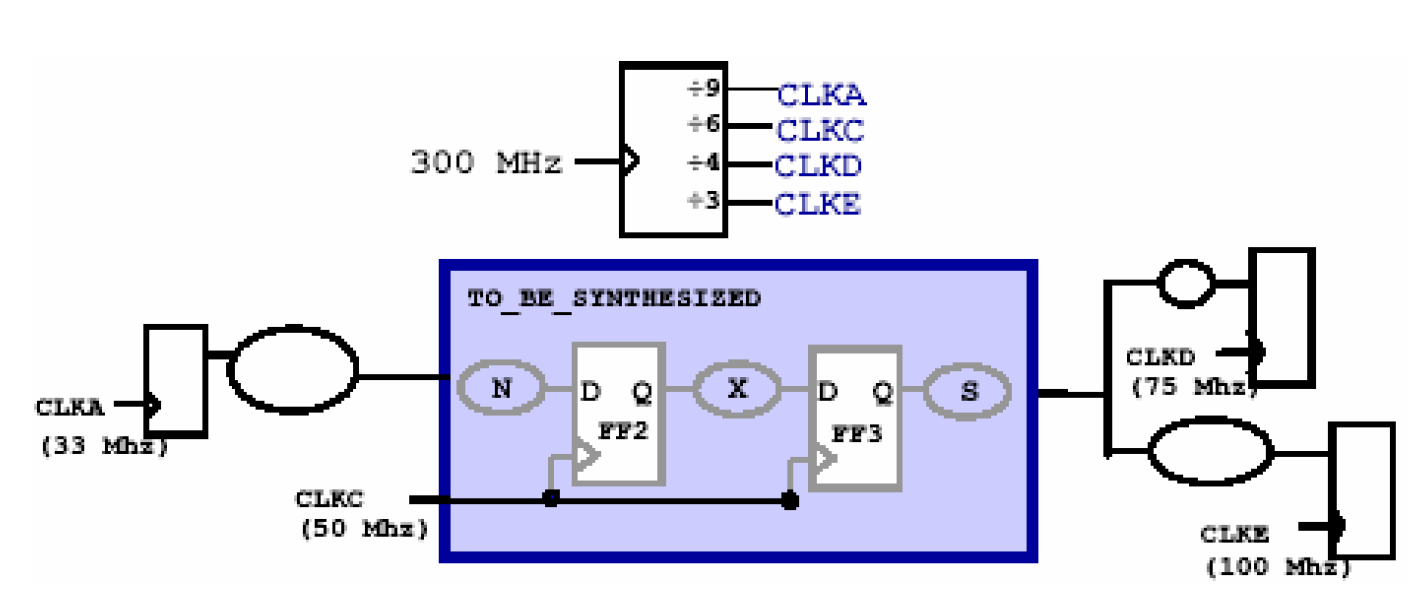
上图是一个同步多时钟网络,中间的模块是我们要综合的模块,内部只有一个CLKC,但是输入和输出都是由不同周期的时钟控制的,也就是说,它们属于不同的路径组(Path Group),但是这些时钟CLKA-CLKE都是从一个时钟分频得到的,因此称为同步多时钟。
观察被综合模块的输入端口,它同时受两个时钟的约束,由于它们周期不同,所以CLKA触发的信号到达FF2的时间也不是固定的。
对于这样的时钟网络,我们需要用到虚拟时钟的概念(Virtual Clock)。对上图要综合的模块而言,除了CLKC之外的其他时钟都可以称为虚拟时钟,它们有如下要求——
- 在顶层模块之内的其他模块内定义的时钟
- 在当前的被综合模块(current_design)内不包含虚拟时钟驱动的触发器
- 作为当前模块的输入输出延时参考
定义虚拟时钟和定义时钟的命令差不多,只是不要指定虚拟时钟的端口或者管脚,另外必须指定时钟的名字——
create_clock -name vTEMP_CLOCK -period 20
如上述语句指定了一个周期为20ns的虚拟时钟vTEMP_CLK。
定义了虚拟时钟之后,我们就可以描述上图的电路时序了,先设定输入延时(set_input_delay),从图中看出,CLKA和CLKC的周期分别为30ns和20ns,假设IN1端口的输入延时为5.5ns,可以设定如下——
create_clock -period 30 -name CLKA
create_clock -period 20 [get_ports CLKC]
set_dont_touch_network [get_ports CLKC]
set_input_delay 5.5 -clock CLKA -max [get_ports IN1]
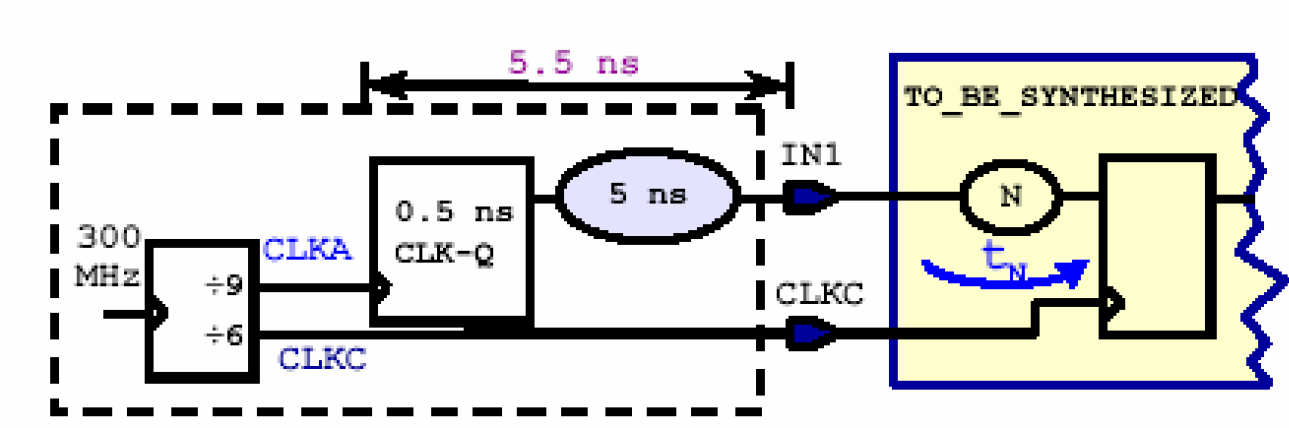
值得注意的就是先定义虚拟时钟CLKA,然后在set_input_delay的驱动时钟开关中选择CLKA。在设定完输入延时之后,Design Compler就会在CLKA和CLKC的所有情况中找到其中最短的周期,作为对这段路径的约束——
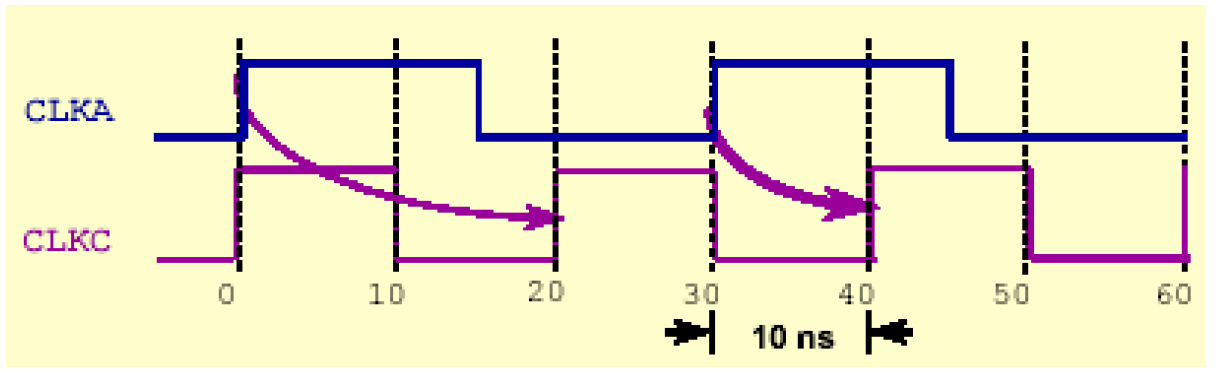
寻找最小周期的过程如下:先计算CLKA和CLKC的最小公约数(30和20的公约数)为60ns,即两个CLKA的周期,然后分别以这两个上升沿为触发沿,计算此时的最短捕捉(被CLKC接收)的时间,最后对比这两个时间,取其中最小的一个。如下图计算出的最短捕捉时间为10ns,因此留下给路径N的延时为——
按照上面同样的方法,我们也可以得出图86的输出延时(set_output_delay),如下图所示——
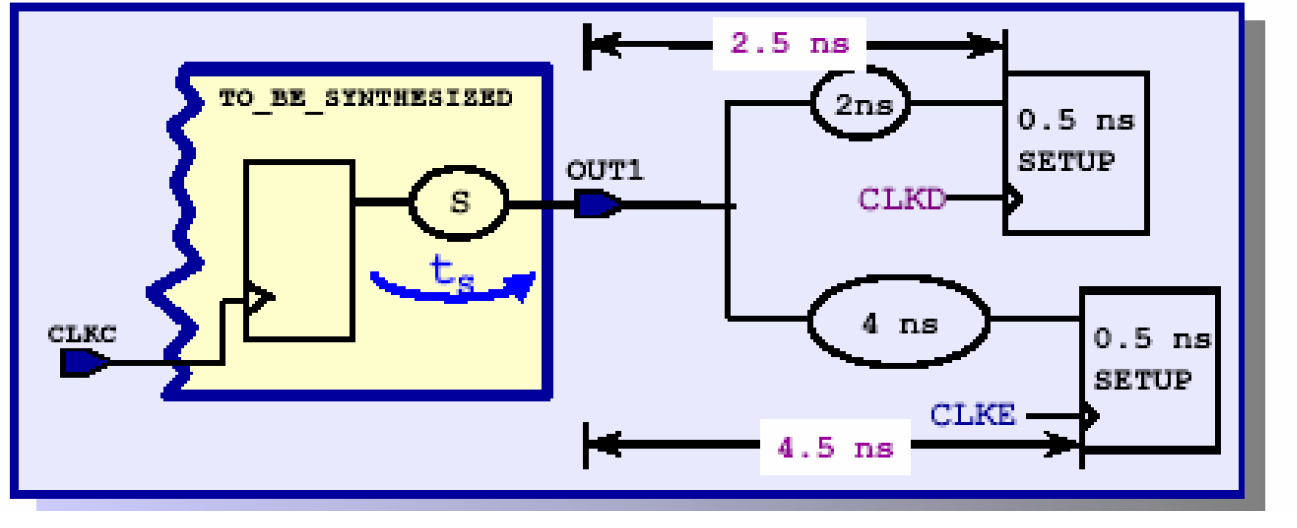
create_clock -period [expr 1.0/75*1000] -name CLKD
create_clock -period 10 -name CLKE
create_clock -period 20 [get_ports CLKC]
set_dont_touch_network [get_ports CLKC]
set_output_delay -max 2.5 -clock CLKD [get_ports OUT1]
set_output_delay -max 4.5 -clock CLKE -add_delay [get_ports OUT1]
值得注意的是:这里的输出同时驱动两个虚拟时钟电路CLKD和CLKE,因此描述第二个延时的时候需要加入-add_delay的开关,否则将覆盖前一条路径的约束。
这里的各时钟波形关系如下所示——
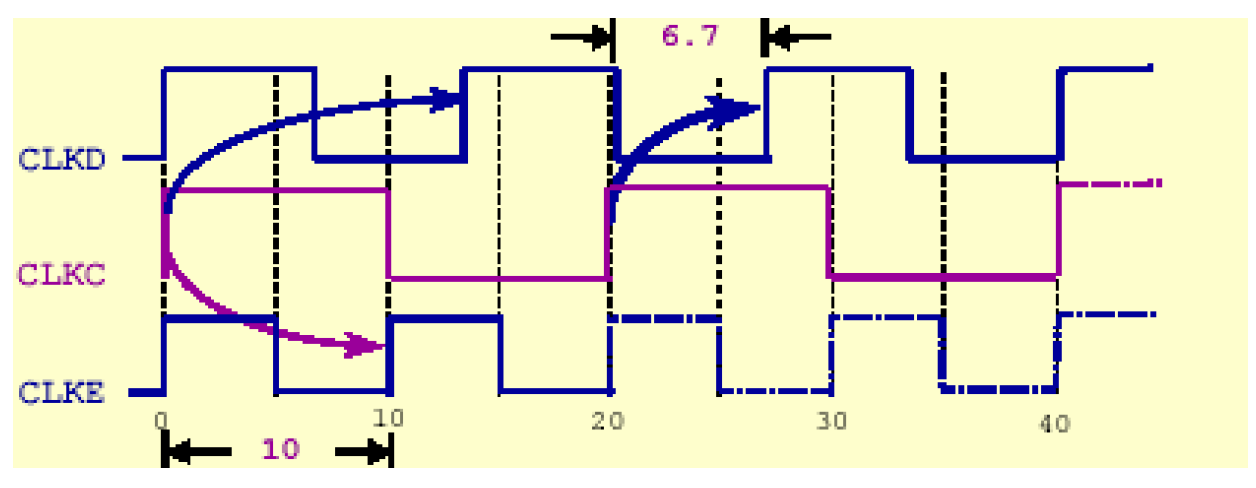
可见,CLKC到CLKD的最小捕捉时间为6.7ns,到CLKE的最小捕捉周期为10ns。因此输出最小周期为6.7ns和10ns,对应的输出电路的延时必须满足下面的条件:
从前面的推导过程可以看出,DC是在各个相关时钟周期的最小公约数的基础上计算最小输入/输出时间的,因此我们在定义时钟的时候尽量选用整数,不要加上小数点(比如20ns和30.1ns),避免不必要的麻烦。
异步多时钟网络和同步多时钟网络的结构类似,只是它的各个时钟CLKA-CLKE不是从同一个时钟源中分频产生的,而可能是不同的两个晶振,如下图所示——
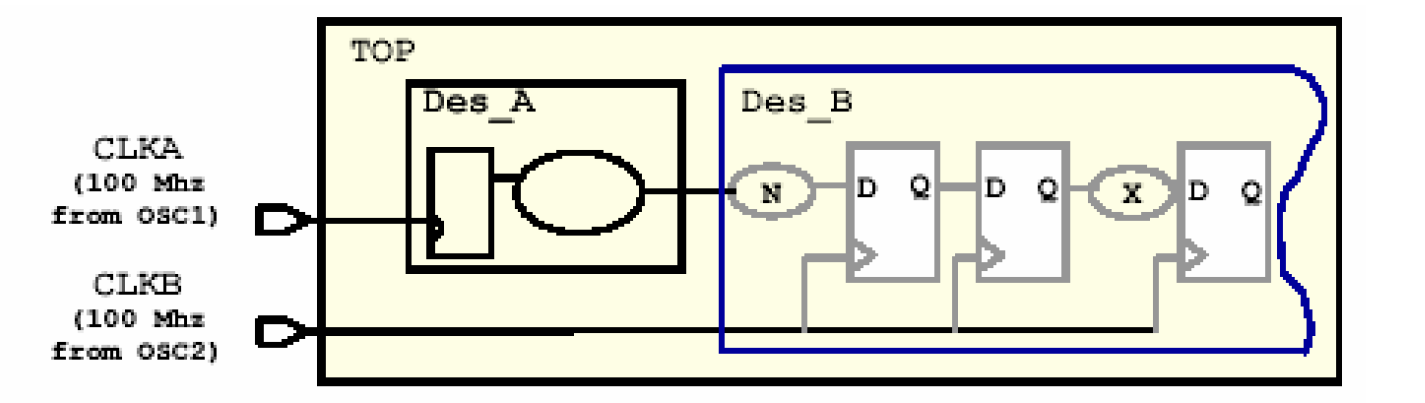
由于是不同的晶振产生的时钟,它们之间的就不存在最小公约数的关系,但是在默认情况下,DC并不知道,它会认为它们是同步的时钟网络而尽量去找两个时钟之间的最小捕捉时间,不但浪费了时间而且会产生出不符合要求的电路。在这种情况下,我们需要告诉DC不要管两个时钟之间路径的时序,这里需要用到一个命令——set_false_path
False Path(伪路径)是指电路中的一些不需要考虑时序约束的路径,它一般出现在异步逻辑之中。上面的例子设置伪路径的语句如下——
current_design TOP
create_clock -period 10 [get_ports CLKA]
create_clock -period 10 [get_ports CLKB]
set_false_path -from [get_clocks CLKA] - to [get_clocks CLKB]
set_false_path -from [get_clocks CLKB] - to [get_clocks CLKA]
compile
这样,所有的从CLKA到CLKB和CLKB到CLKA的路径都被认为是伪路径。
在前面的讨论中,我们默认所有组合路径的延时都是一个周期,然而实际电路中也可能存在超过一个周期的路径,如下图所示——
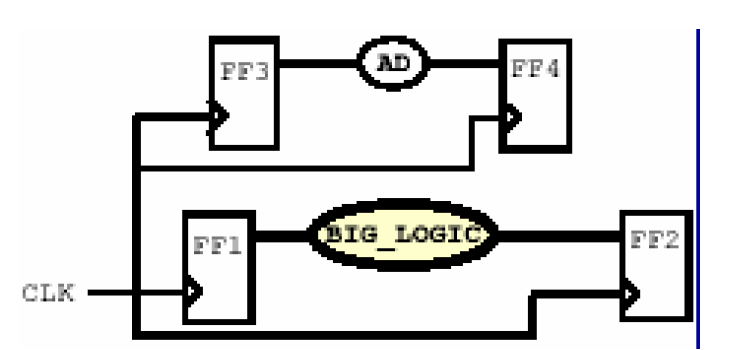
在FF1和FF2之前,存在一个BIG_LOGIC,假设我们允许它的延时在两个周期之内,那么因该怎样把这个信息告诉Design Compiler呢?这里就需要用到DC的一个设置多周期路径的命令——set_multicycle_path
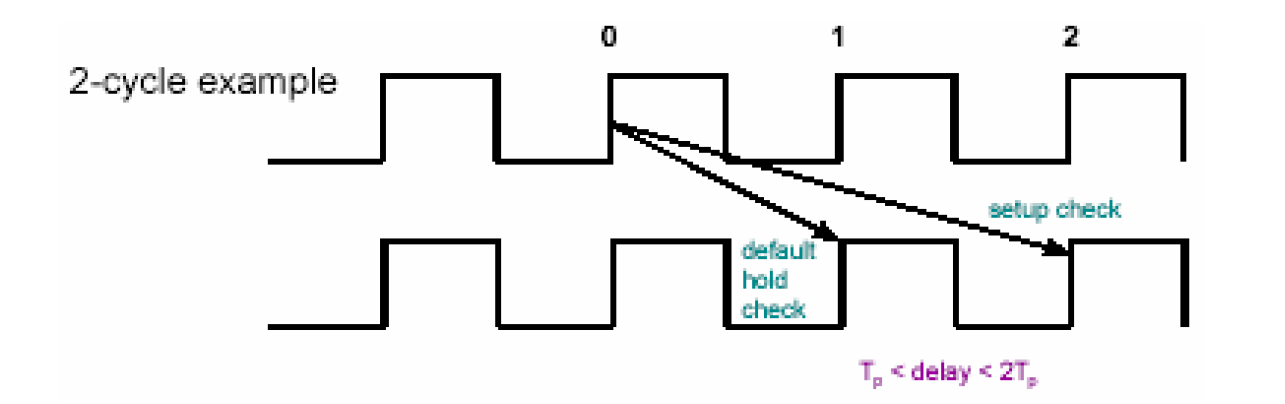
set_multicycle_path 2 -setup -from [get_cells FF1] -to [get_cells FF2]
set_multicycle_path 1 -hold -from [get_cells FF1] -to [get_cells FF2]
第一个语句说明建立时间是在FF1触发后的第二个周期后检查,第二个语句说明保持时间在FF1触发后的第一个周期检查。可得此时的波形图如下——
3.2.2 环境属性约束
前面我们主要讨论了怎样电路中加入时序约束,如设置clock周期、设置输入输出延时等,但是仅仅靠这些约束还是不够的,因为还要考虑到被综合模块周围环境的变化,举个例子说,如果当外界的温度变化,或者电路的供电电压发生变化时,延时会相应的改变,所以这些方面也是必须考虑到的。类似的上一节仅仅约束了输入输出的延时,而没有考虑到他们的电平转化时间(transition time),这些是有输入输出的外围电路的驱动能力和负载大小决定的。另外,电路内部的互连线的延时也没有估计在内。这一节我们主要讨论怎样给电路施加这些环境属性。
设置环境属性的命令如下图所示——
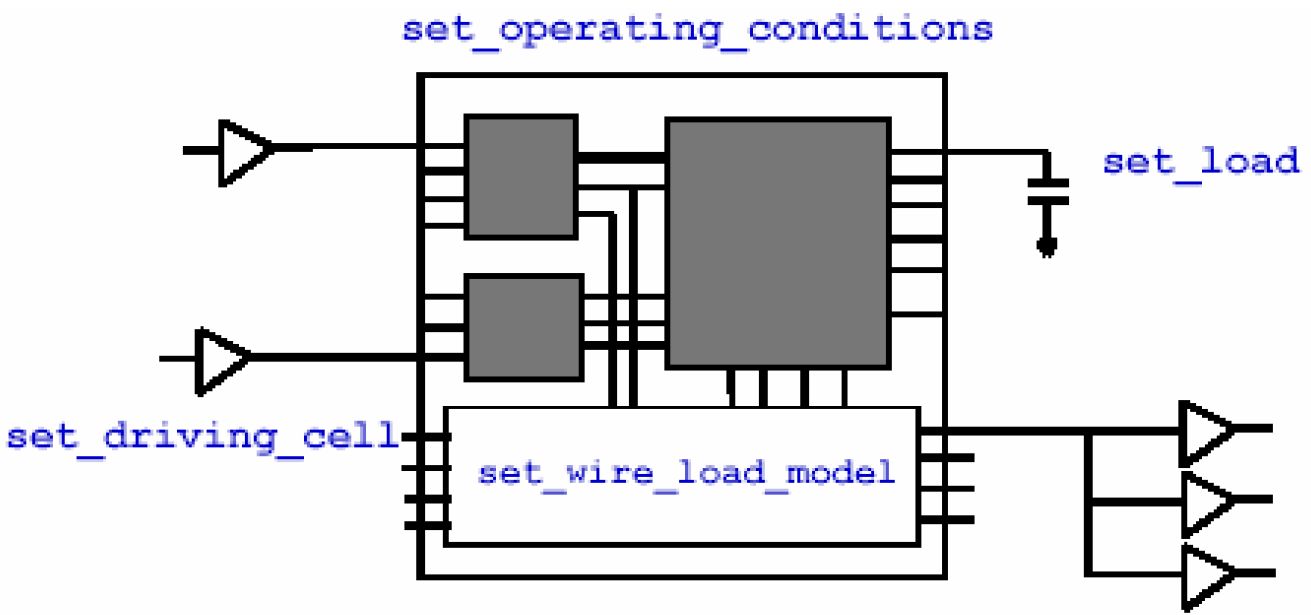
总共包括工作环境set_operating_conditions,驱动单元set_driving_cell,连线模型set_wire_load_model以及负载模型set_load。
首先讨论负载的设置。为了更加准确的估计模块输出的时序,除了知道它的输出延时之外还要知道输出所接电路的负载情况,如果输出负载过大会加大电路的transition time,影响时序特性。另外,由于DC默认输出负载为0,即相当于不接负载的情况,这样综合出来的电路时序显然过于乐观,不能反映实际工作情况。
设置输出负载是通过DC的set_load命令完成的——
该命令有两种用法,一种是直接给端口赋一个具体的值,另外则结合另一个命令load_of指出它的负载相当于工艺库中的哪个单元的负载值。
例如下图,OUT1端口设了一个负载为5的值。这里的单位也是由Foundry提供,具体的单位,可以通过report_lib命令查看,一般而言是pf:

set_load 5 [get_ports OUT1]
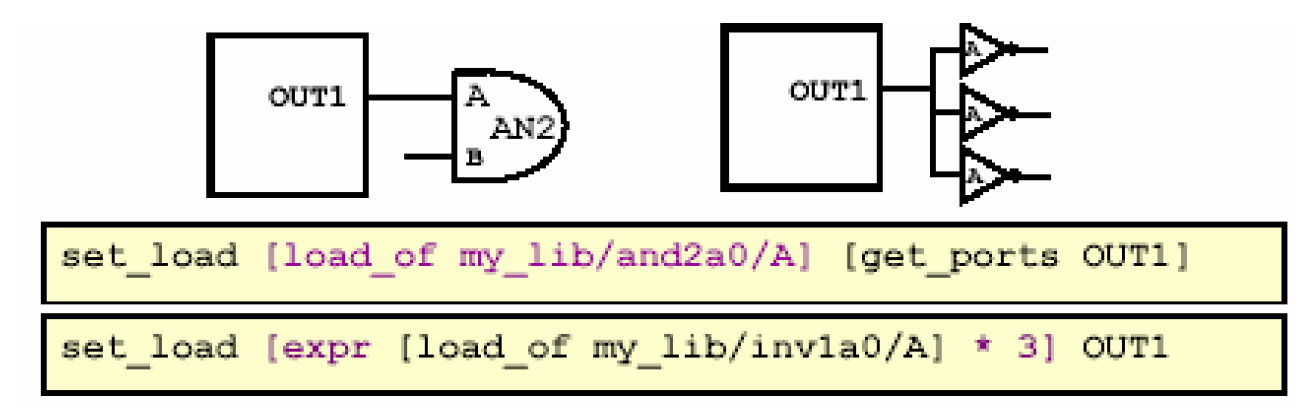
上图中的方案则采用了load_of的方法,,从图中可以看出,第一条语句说明OUT1端口接的负载值是my_lib中and2a0单元的A管脚的负载值。第二条语句则多用了TCL语言的表达式的语法,它说的是,OUT1相当于接了三个inv1a0单元的A管脚的负载值。一般后面的这种方法用的多些。
与设置输出负载类似,为了更加准确的估计模块输入的时序,我们同样需要知道输入端口所接单元的驱动能力。在默认的情况下,DC认为驱动输入的单元的驱动能力为无穷大,也就是说,transition time为0。
设置输入驱动是通过DC的set_driving_cell命令完成的。set_driving_cell是指定使用库中的某一个单元来驱动输入端口。该命令是在输入端口之前假想一个驱动单元,然后按照该单元的输出电阻来计算transition time,从而计算输入端口到门单元电路的延迟——
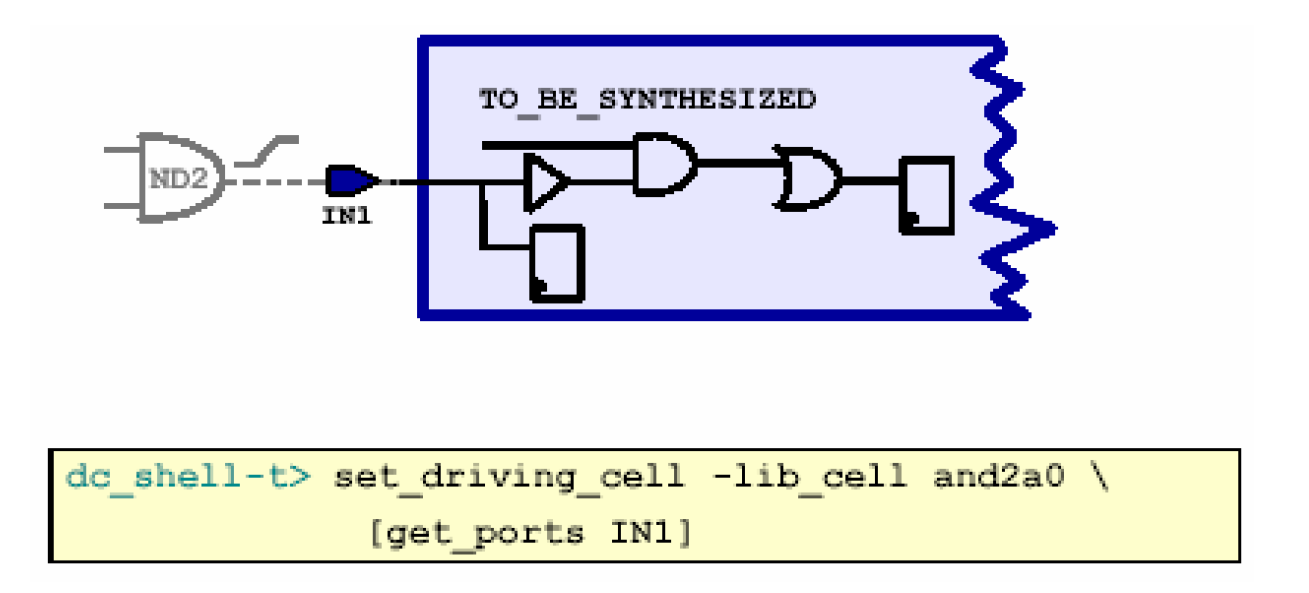
set_driving_cell -lib_cell and2a0 [get_ports IN1]
如上图所示,它设置了模块输入端口IN1的驱动单元是工艺库中的and2a0。
工作条件包括三方面的内容——温度、电压以及工艺。在Foundry提供的工艺库里,它的各个单元的延时是在一个“标准”(nominal)条件下得到的,比如说温度25.0度、工艺参数1.0和工作电压1.8V。一旦工作条件发生了改变,电路的时序特性也必将收到影响,以上三方面的因素对电路时序的影响如下所示——
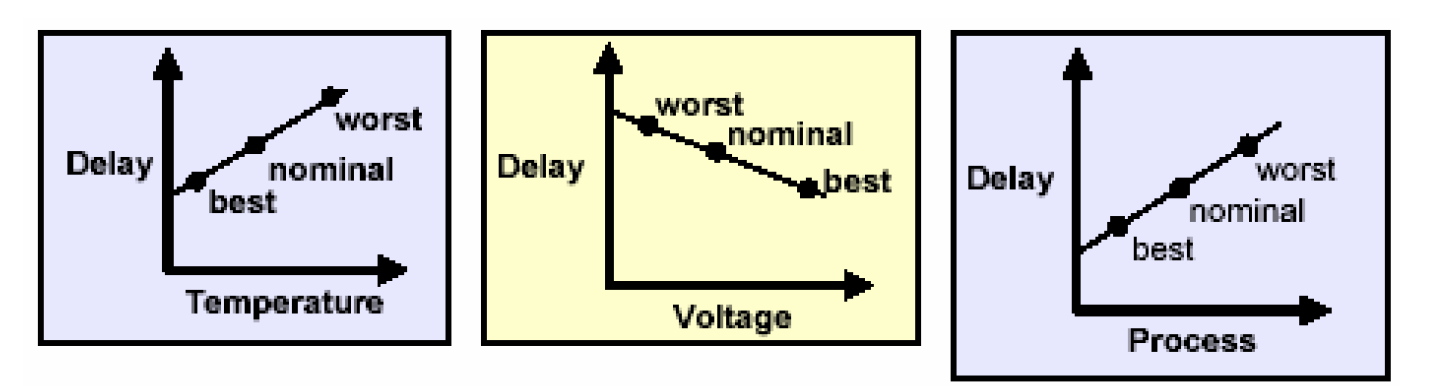
从图中可以看出,单元的延时会随着温度的上升而增加;随着电压的上升而减小;随着工艺尺寸的增大而增大。以上的这些工作条件的变化,Foundry在建库的时候已经考虑到了,因此它在工艺库中提供了几种工作条件的模型(operating condition model)以供设计者选择。这些工作条件一般分为三种:最好情况(best case)、典型情况(typical case)以及最差情况(worst case)。我们为了以后能使电路正常的工作在上面的三种情况下,在综合的时候就必需要将他们考虑进来。一般综合只要考虑到最差和最好两种情况,最差情况用于作基于建立时间(setup time)的时序分析,最好情况用于作基于保持时间(hold time)的时序分析。
在默认情况下,Design Compiler不会自动指定工作条件,我们可以先通过report_lib命令来列出在当前的工艺库里提供了哪几种工作条件——
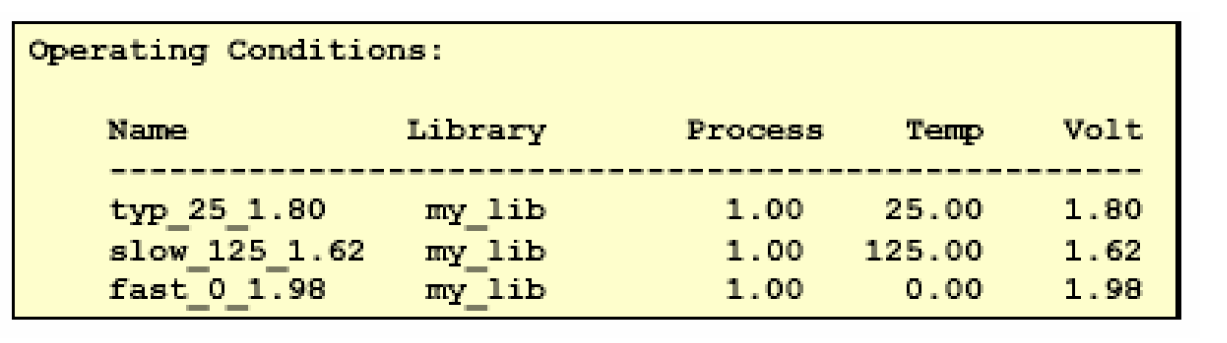
然后指定需要用到的工作条件,在做建立时间分析的时候需要用到最差情况的条件——
set_operating_conditions -max "slow_125_1.62"
如果我们既要分析建立时间,又要分析保持时间那么就要同时指定最差和最好情况——
set_min_library core_slow.db -min_version core_fast.db
set_operating_conditions -max "slow_125_1.62" -min "fast_0_1.98"
其中core_slow.db和core_fast.db分别是最差和最好条件下的工艺库文件,第一句话先用set_min_library设定作保持时间检查的库,第二句话则分别对应了两种时间检查需要用到的工作条件。
DC综合的过程中,连线延时是通过设置连线负载模型(wire load model)确定的。连线负载模型基于连线的扇出,估计它的电阻电容等寄生参数,它是也是由Foundry提供的。Foundry根据其他用这个工艺流片的芯片的连线延时进行统计,从而得到这个值。
下面是一个负载模型的例子——

这个例子可以通过命令report_lib得到,它是ssc_core_slow这个工作条件下的一个名为160KGATES的负载模型。其中时间单位为1ns,电容负载单位为1pf,电阻单位为1kΩ。从图中可以看出单位长度的电阻以及电容值,DC在估算连线延时时,会先算出连线的扇出,然后根据扇出查表,得出长度,再在长度的基础上计算出它的电阻和电容的大小。若扇出值超出表中的值(假设为7),那么DC就要根据扇出和长度的斜率(Slop)推算出此时的连线长度来。
事实上,在每一种工作条件下都会有很多种负载模型,各种负载模型对应不同大小的模块的连线,如上图的模型近似认为是160K门大小的模块适用的。可以认为,模块越小,它的单位长度的电阻及电容值也越小,负载模型对应的参数也越小。
设置输入驱动是通过DC的set_wire_load_model命令完成的。
set_current_design addtwo
set_wire_load_model -name 160KGATES
如上面的语句,则设置了addtwo这个模块的连线负载模型为160KGATES。
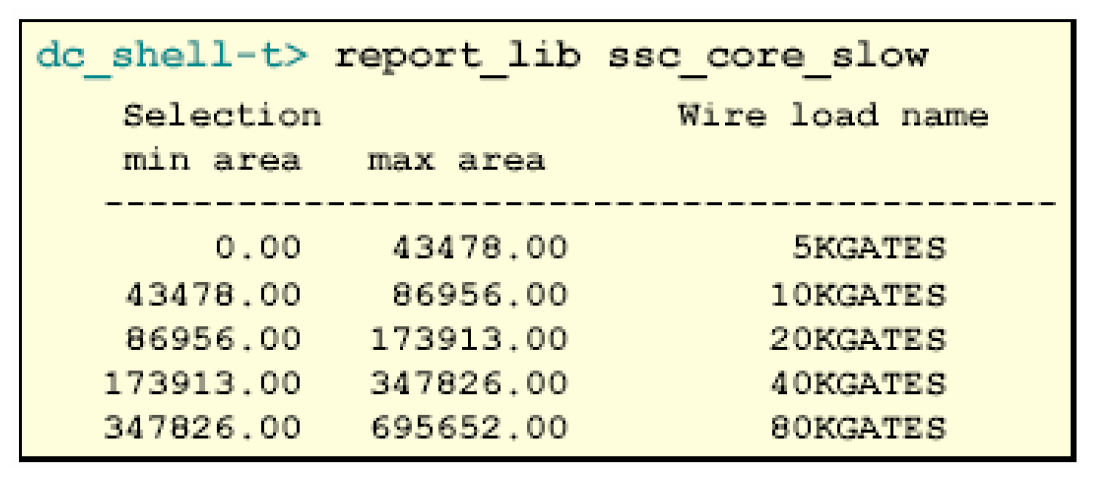
另外我们也可以让DC自动根据综合出来的模块的大小选择负载模型,这个选项在默认下是打开的。如下图所示,当综合出的电路的面积小于43478.00时,使用5KGATES的模型,属于43478.00和86956.00之间时,使用10KGATES的模型。
以上讨论的情况是一个模块内部连线的负载模型的估计。如果连线连接的是不同的模块,那么它的负载模型又将怎么估计呢?这就要用到连线负载模式(set_wire_load_mode)这个命令了。
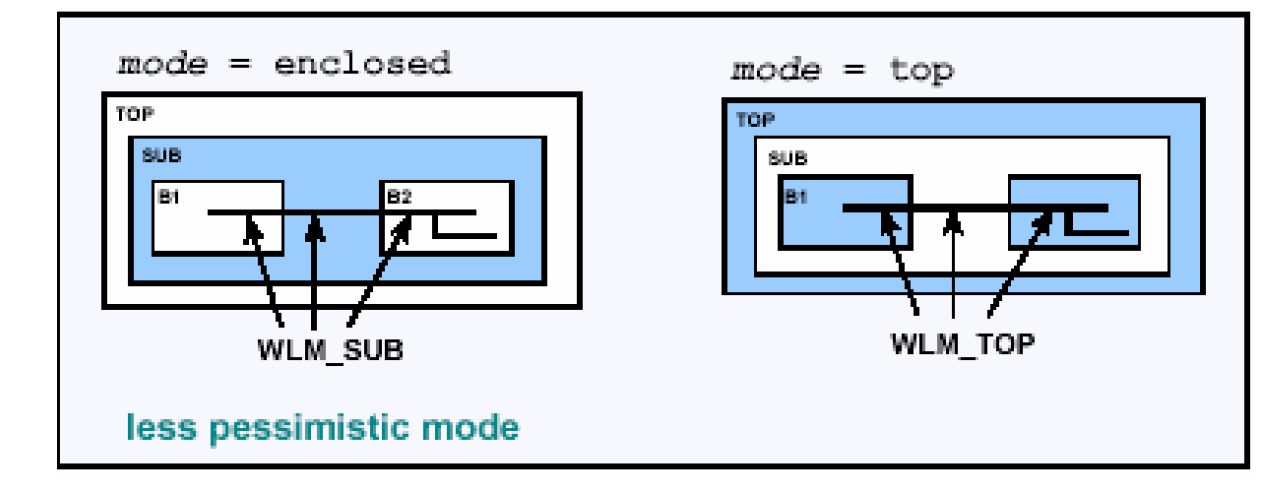
连线负载模式一共有3种,围绕(enclosed)、顶层(top)以及分段(segmented)。如上图所示,一根连线连接了B2和B2两个模块,这两个模块都位于TOP下的SUB这个子模块中,围绕模式是指连接B1和B2的连线的负载模型用围绕它们的模块的负载模型代替,即用SUB的负载模型;顶层模式是指用顶层模块的负载模型代替;分段模式顾名思义,分别根据穿过的三段的模型相加得到。如果要设置成围绕模式,可以使用如下命令——
set_wire_load_model enclosed
在定义完环境属性之后,我们可以使用下面的几个命令检查约束是否施加成功——
-
check_timing
检查设计是否有路径没有加入约束
-
check_design
检查设计中是否有悬空管脚或者输出短接的情况
-
write_script
将施加的约束和属性写出到一个文件中,可以检查这个文件看看是否正确
3.2.3 时序与负载计算
前面的两节里我们讨论了怎样给一个被综合的电路模块施加时序约束以及设置环境属性,大家学习完之后可能有这样一个疑问:模块的输入输出延时、负载和驱动单元的具体的值是怎样确定下来的呢?也就是说怎样在综合模块之前先给它的时序和负载作一个预算,一般而言,这个工作是由项目的体系设计者(Achitecture Designer)完成,当他先确定好各个模块外围的时序和负载预算之后,再由具体的模块设计者(Module Designer)完成模块的综合。
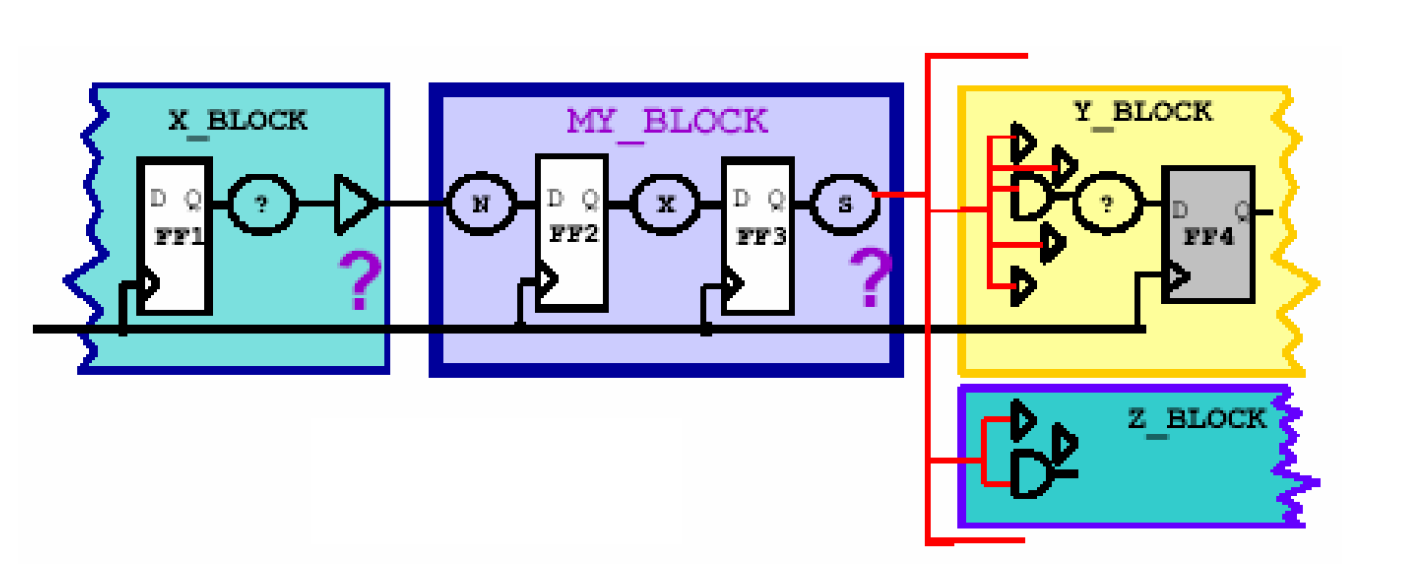
先看时序预算,假设电路中有三个模块X_BLOCK、MY_BLOCK和Y_BLOCK,时钟周期是10ns。如果要先综合MY_BLOCK模块,我们可以看到它的输入部分的N电路必须和X_BLOCK中的S电路共享一个周期的延时,同样输出部分的S电路也必须和Y_BLOCK的N电路共享一个周期的延时。我们可以作这样一个估计,认为处于两个模块交界部分的S和N电路只能分别占用40%的周期延时(如下图所示),也就是说限定所有的S和N电路的延时为最大为4ns,这样可以看出S+N的延时总共只有8ns,小于10ns,因此这是一种保守的预算方法,预留的2ns的延时可以在电路不满足时序的时候再加上。经过预算之后的MY_BLOCK模块的约束如下——
create_clock -period 10 [get_ports CLK]
set_dont_touch_network [get_clocks CLK]
set_input_delay -max 6 -clock CLK [all_inputs]
remove_input_delay [get_ports CLK]
set_output_delay -max 6 -clock CLK [all_outputs]
同样的方法,我们也可以得出另外两个模块的时序约束——
create_clock -period 10 [get_ports CLK]
set_dont_touch_network [get_clocks CLK]
set_input_delay -max 6 -clock CLK [all_inputs]
remove_input_delay [get_ports CLK]
set_output_delay -max 6 -clock CLK [all_outputs]
负载预算也是在实际综合编译之前体系设计者根据模块将来可能的工作情况认为估计出来的,一般它的估计有几个原则:
- 保守起见,假设驱动模块的单元的驱动能力较弱
- 限制每一个输入端内部的负载电容
- 估计每一个输出端口最多可以驱动几个相同的模块
请看下面这个负载运算的例子——
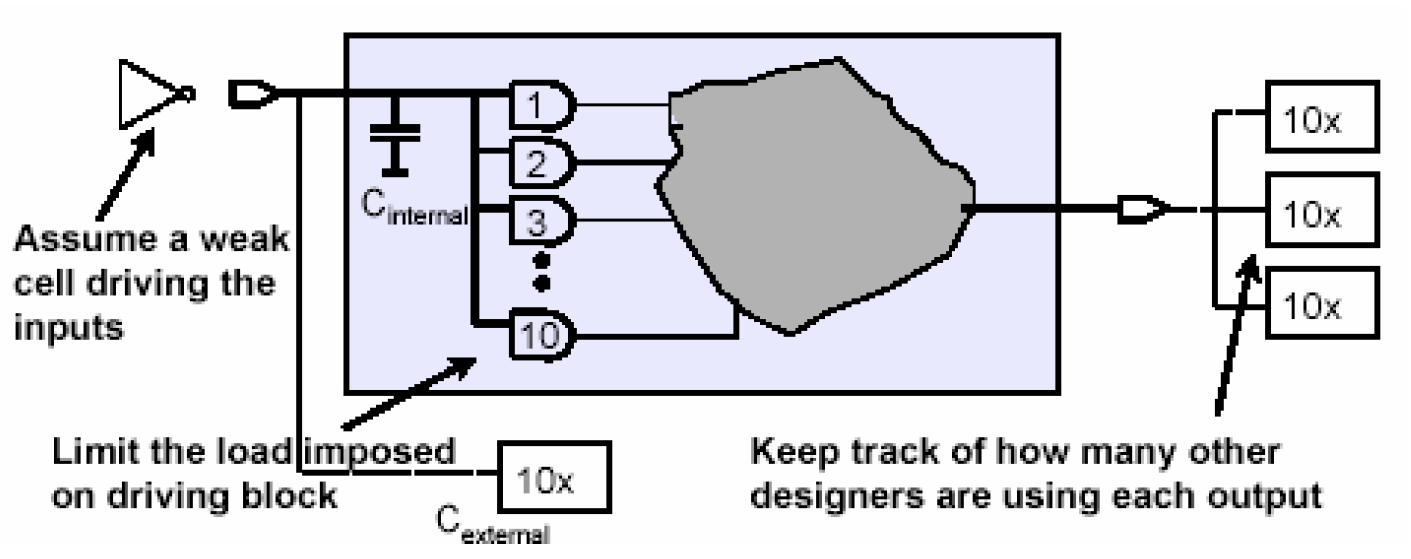
current_design myblock
link
source timing_budget.tcl
set_driving_cell -lib_cell inv1a0 [all_inputs]
remove_driving_Cell [get_ports Clk]
set MAX_INPUT_LOAD [expr [load_of tech_lib/and2a0/A] * 10]
set_max_capacitance $MAX_INPUT_LOAD [all_inputs]
remove_attribute [get_ports Clk] max_capacitance
set_load [expr $MAX_INPUT_LOAD * 3] [all_outputs]
在这个例子中,我们假设输入的驱动单元是一个inv1a0的反相器,然后限制了最大的输入负载,即每个输入端口的负载最大不得超过10个二输入与非门的负载大小,同时也规定了一个模块最多能同时驱动三个同样大小的其他模块。
3.2.4 时序分析
Design Compiler是一个约束驱动(Constraint-driven)的综合工具,约束中最重要的就是时序约束,前面我们已经讨论了怎样在设计中施加时序约束,但是综合出来的电路能否满足这些约束条件却是另一个重要的问题。在这一章里,我们主要将着重介绍Design Compiler内嵌的一个时序分析引擎Design Time,并分析它是怎样根据工艺库中的单元延时信息和连线负载模型分析电路的静态时序的,并介绍调用Design Time的命令report_timing。
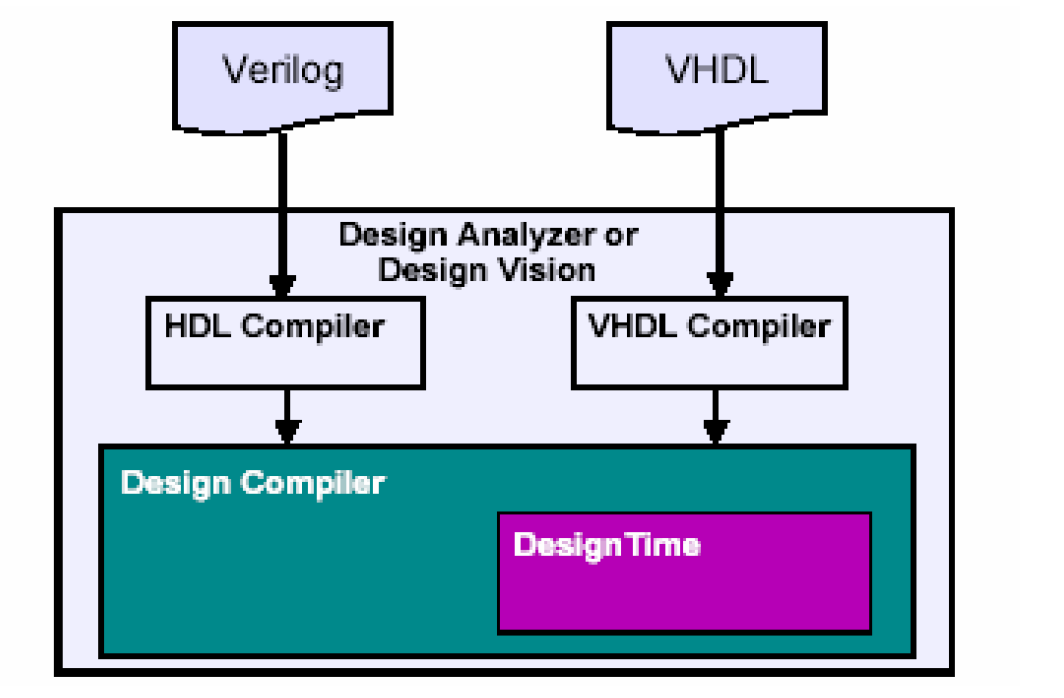
Design Time是DC的一个内嵌的静态时序分析引擎,DC就是依靠它来计算电路的延时情况。DesignTime和PrimeTime都是静态时序分析的工具,但是两者并不完全相同,PrimeTime是在DesignTime的基础上发展起来的独立的专业的时序工具,而且效率和应用范围更高。
静态时序分析(STA)是进行电路时序分析的一种方法,它的主要特点是分析不需要通过动态仿真,并且对电路的覆盖率更高。动态仿真(比如VCS)需要给电路施加一个激励,并检查输出信号,与理想信号比较,这种办法速度较慢,而且不一定能覆盖到所有的逻辑。
静态时序分析的分为三个步骤——
- 将电路分解成不同的时序路径(timing paths)
- 计算每段路径的延时
- 检查所有路径的延时,看是否能满足时序要求
下面我们就按照这三个步骤详细介绍DC是怎样分析电路的时序的。
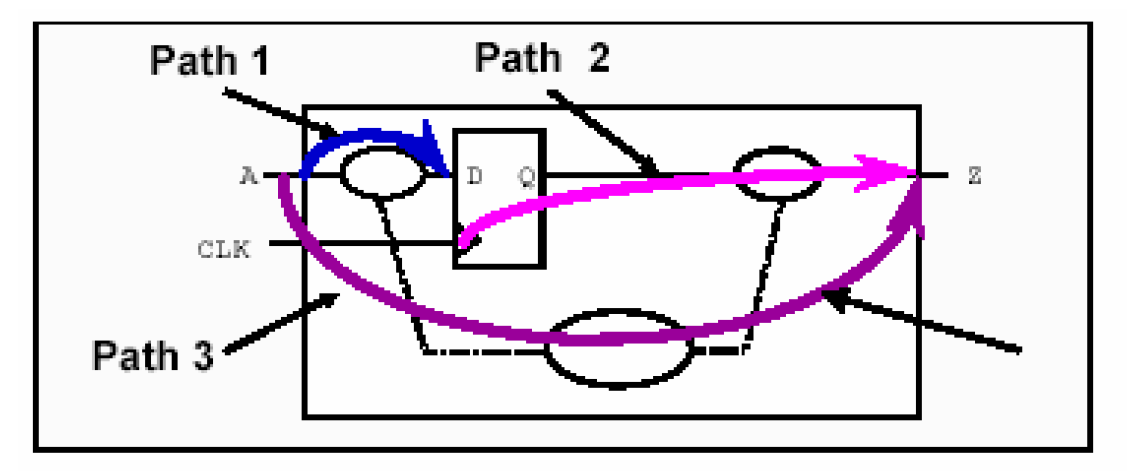
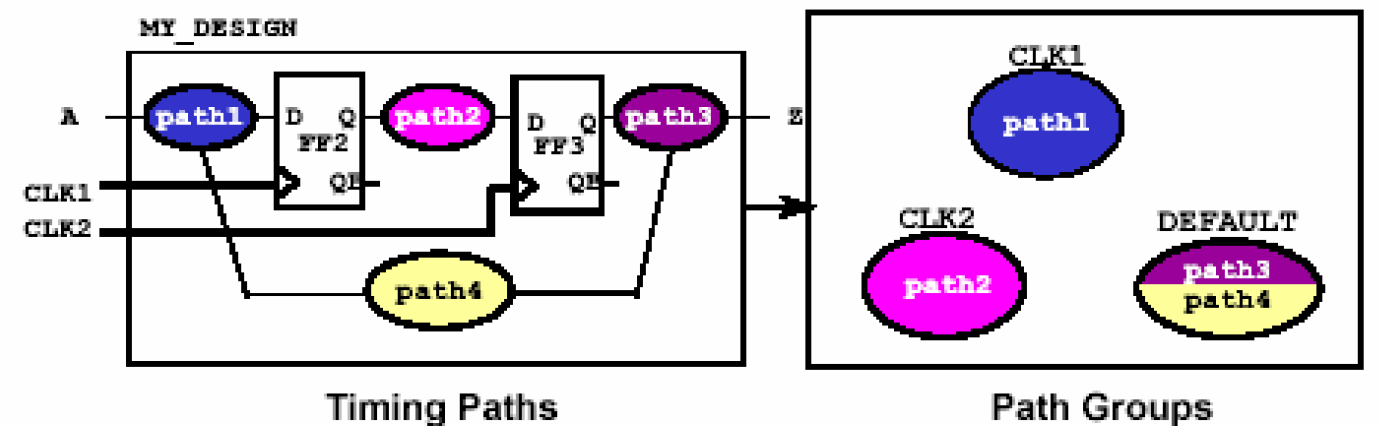
DesignTime对时序路径的分解是根据时序路径的起点和终点的位置来决定的。每一条时序路径都有一条起点和终点,起点是输入端口或者触发器的时钟输入端;终点是输出端口或者触发器的数据输入端,如下图就有三条时序路径。另外根据终点所在的触发器的时钟不同还可以对这些时序路径进行分组(Path Group),如下图电路中存在4条时序路径,3个路径组,CLK1和CLK2组分别表示他们的终点是受CLK1和CLK2控制的,DEFAULT组则说明他们的终点不受任何一个时钟控制。
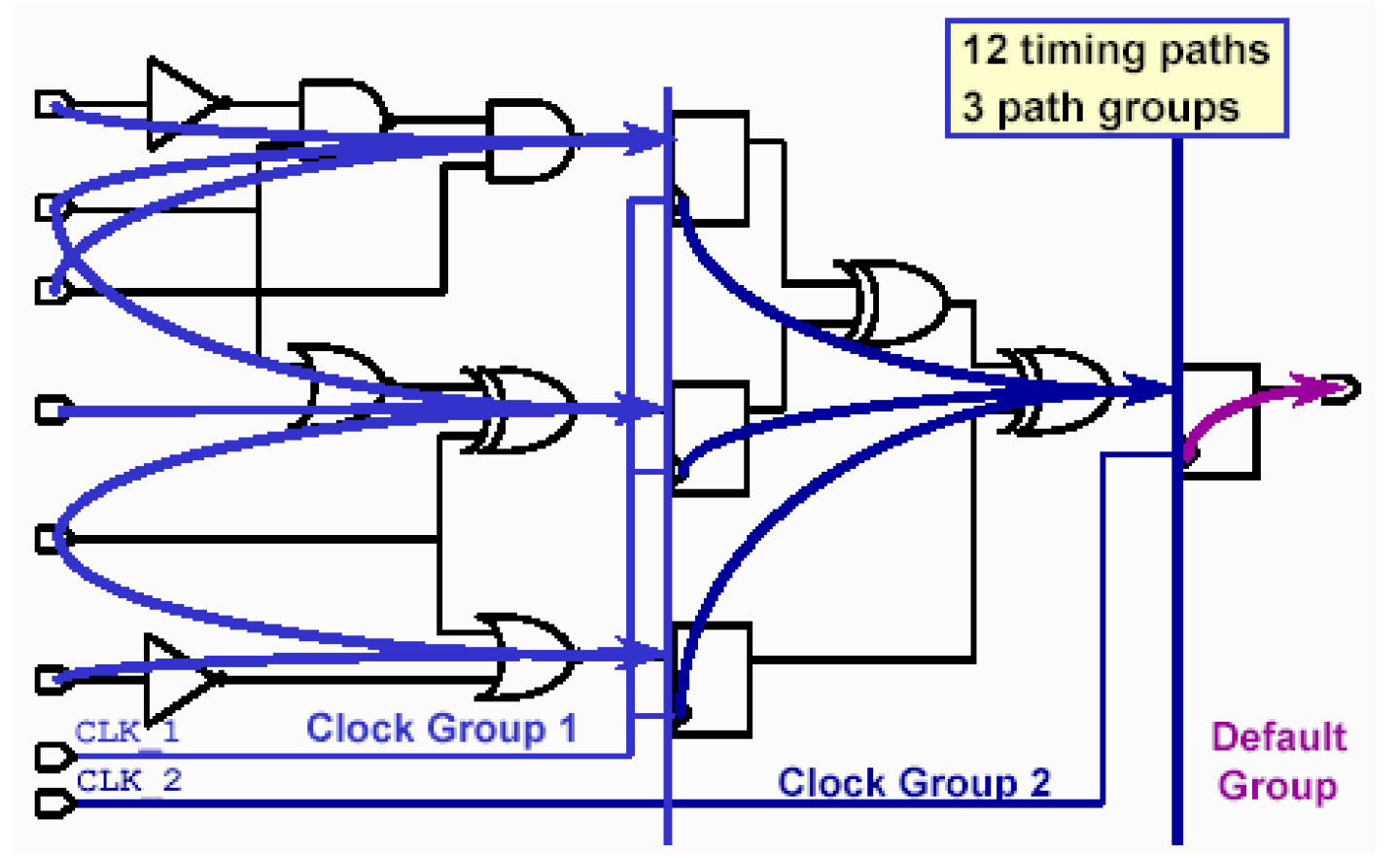
再例如下面的一个电路,一共有12条时序路径和3条路径组。
时序路径的延时包含单元延时和连线延时,为了便于观察,我们将上图的时序路径进一步划分,得到如下图所示——
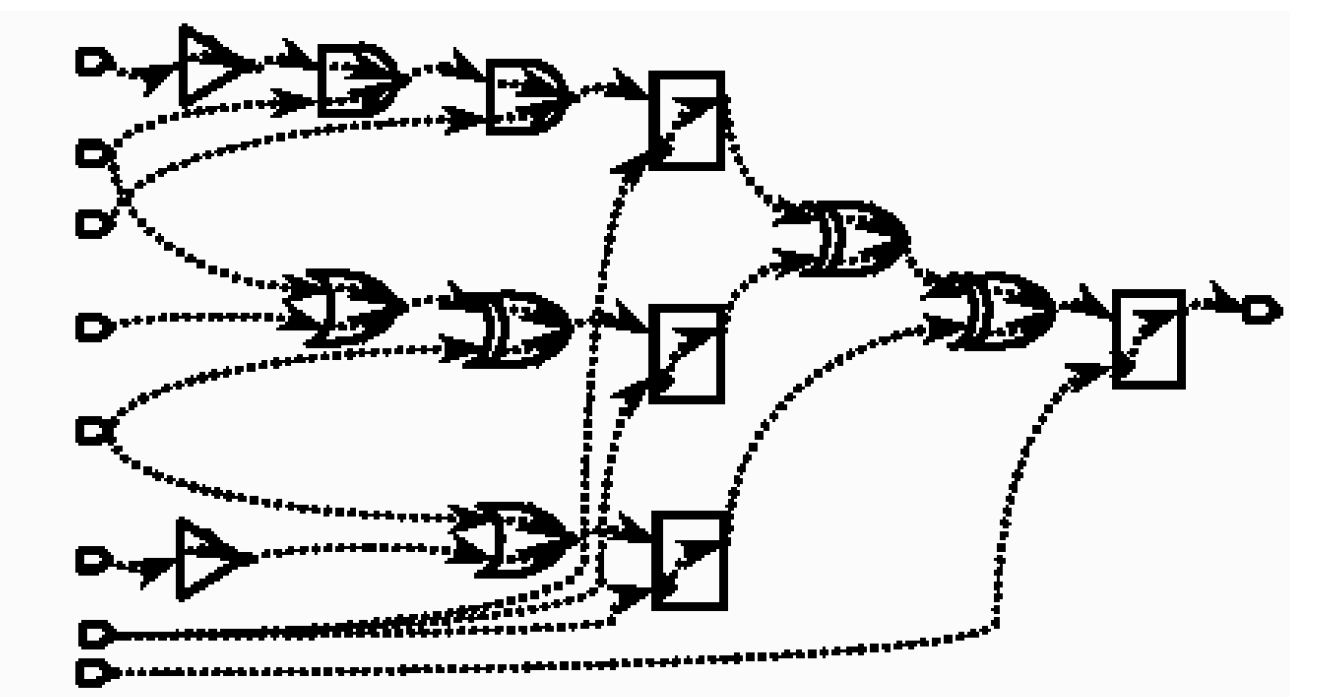
可以看出,每条时序路径被分割成了一段段的时序弧(timing arc),每条时序弧代表的不是一个单元延时就是一段连线的延时。下一步的工作就是计算出它们的值。
单元延时的计算是根据单元延时模型进行的,这里介绍两种单元延时模型,线性延时模型(Linear Delay Model)和非线性延时模型(Nonlinear Delay Model),他们的计算方法如下图所示——
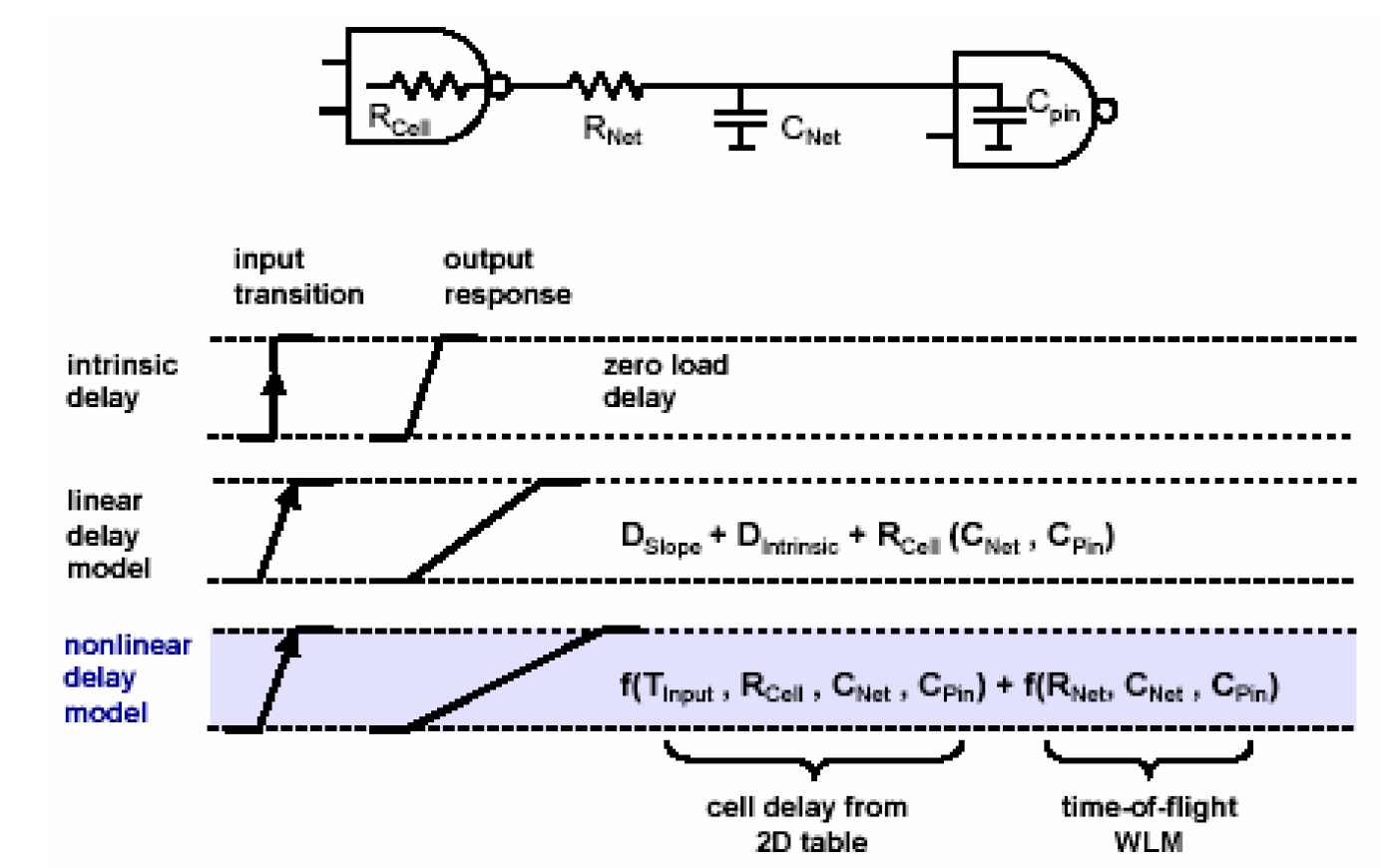
线性模型由三部分组成:\(D_{slope}\)表示单元输入信号的延时、\(D_{intrinsic}\)表示单元的固有延时、\(R_{cell}(C_{Net},C_{pin})\)(表示输出的管脚电容和连线电容对单元的附加延时。
非线性模型是DC计算单元延时的主要模型。它分为两部分:单元的输入延时(transition time)和输出负载的函数。与线性模型不同的是,它是通过查找表的方式得到的,请看下面一个例子——
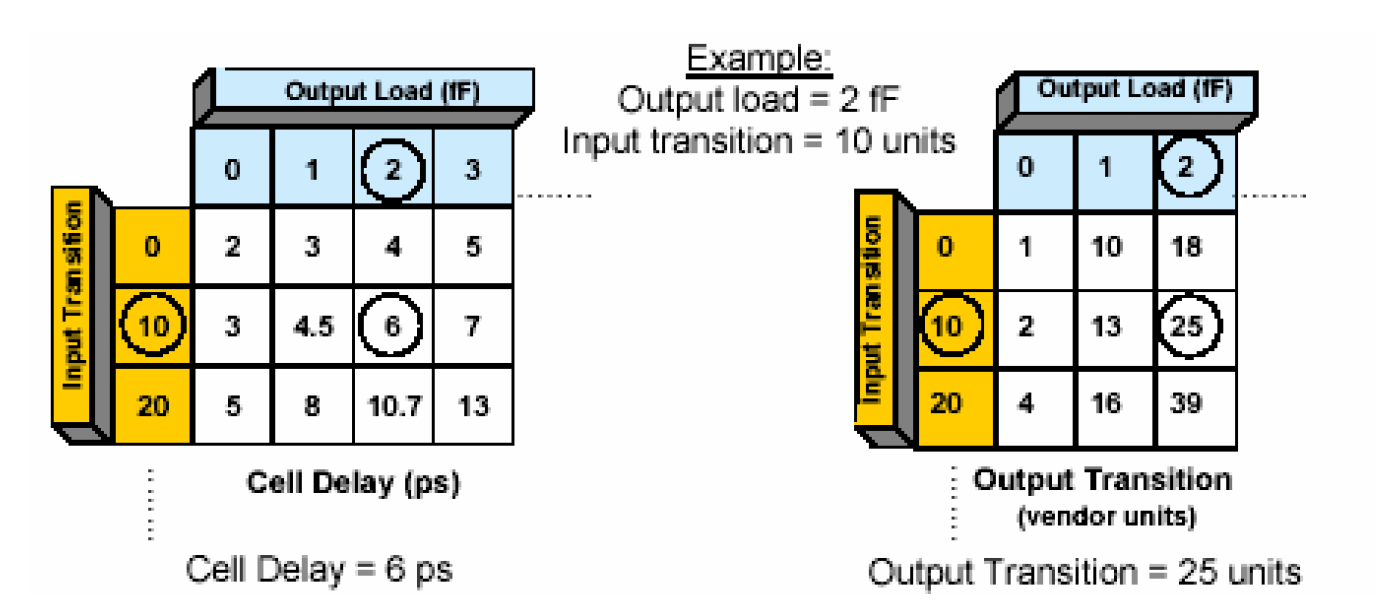
对于一个单元来说,它有两张查找表,一张用于计算单元延时,另一张用于计算输出延时,并作为下一级单元的输入。在这个例子中,通过查表可以得到,单元延时为6ps,输出的transition time为25个单位,这个单位又作为下一级的输入。
不难看出,非线性的模型的计算类似波浪的传播,从上一个单元的延时得出下一个单元的延时,并以此类推,对于一个较大规模的电路来说,计算量是比较大的,但也能得到比较准确的结果。
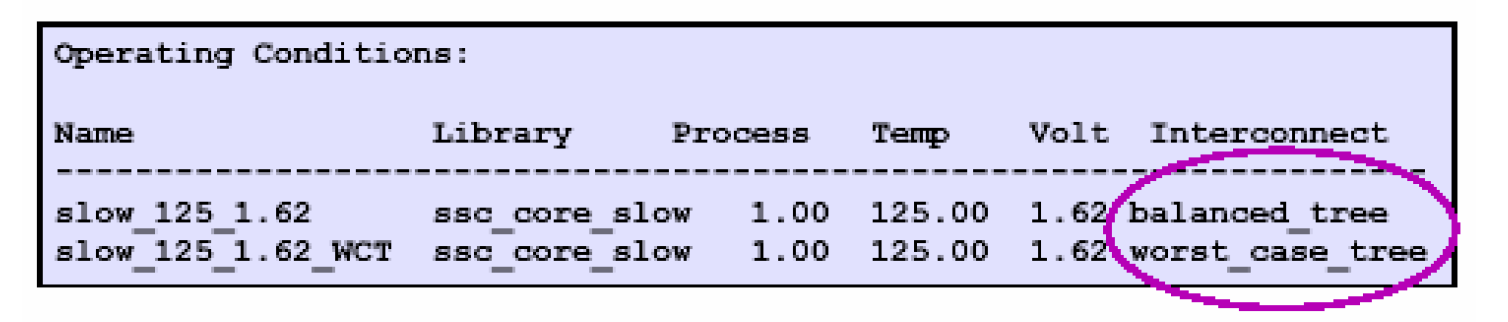
在设置环境属性这一节中我们讲到了连线负载模型,通过连线负载模型我们可以得到一条连线上的电阻和电容的值,但是仅仅有RC值并不能得到连线的延时,还需要知道这些RC的分布,RC分布有三种情况——

-
best_case_tree是一种理想情况,它假设连线的电阻为零,平常很少使用
-
balanced_tree认为连线的RC均匀的分布在各条负载支路上
-
worst_case_tree假设RC值全部集中在负载共有的连线上,因此它的延时是最大的
连线的不同拓扑结构是通过工作条件的不同体现出来的,工作条件不但影响连线的延时,还通过温度、电压和工艺的变化影响单元延时的计算。
DesignTime计算完所有的路径延时之后的下一步工作就是根据这些延时,找出电路中延时最大或者最小的路径来。对于设计者而言,他们或许不关心每个单元的延时而更加关注到底电路是不是满足了设定的时序约束的要求。例如下图,有两个触发器FF1和FF2,它们之间是一个很多单元组成的组合逻辑云,当作建立时间检查的时候,设计者就需要知道这个逻辑云的最大延时是否满足建立时间,即最大延时加上FF2的建立时间是否小于一个周期的时钟周期。
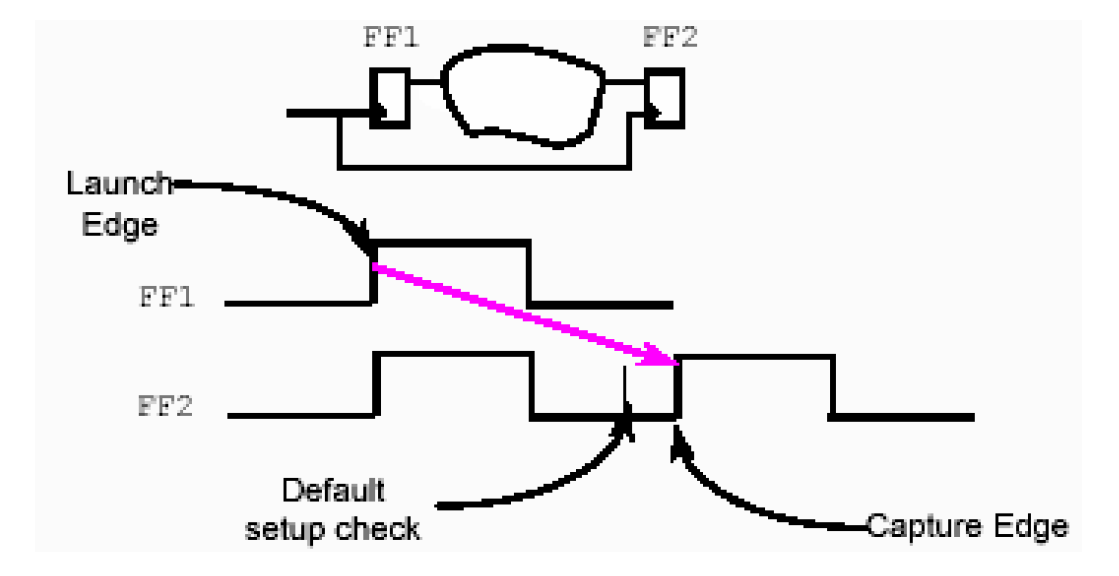
那么怎样计算整条路径的最大延时呢?是不是把这条路径上的所有单元和连线的最大延时简单相加得到的呢?答案是否定的,因为这里涉及到一个时钟边沿敏感性(Edge Sensitivity)的问题。
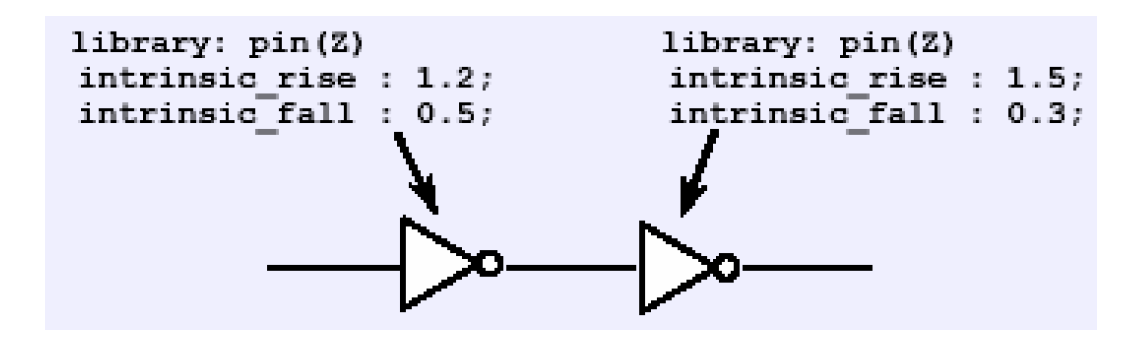
如上图,一条路径上有两个不同的反相器,他们的固有上升时间和下降时间都不同,要计算他们的最大最小延时,需要弄清楚他们的工作过程——当第一个反相器的输入在时钟上升沿时,它的延时是1.2,同时第二个反相器处于时钟的下降沿,延时为0.3;反之,当第一个反相器输入为时钟下降沿时,它们的延时分别为0.5和1.5。因此,最大路径延时不是简单的1.2+1.5,而是分别检查0.5+1.5,在输入为时钟下降沿得到。实际上,DesignTime在计算每条路径的时候,都会考虑边沿敏感性,即分别根据上升下降沿计算两次。
上面几节讲的是DesignTime作静态时序分析的基本原理和步骤,这节介绍介入DesignTime的命令——report_timing。
report_timing命令的具体参数如下,具体信息请查看DC的man页。

默认的时候report_timing报告每一条路径组中的最长路径。报告一共分为4个部分——
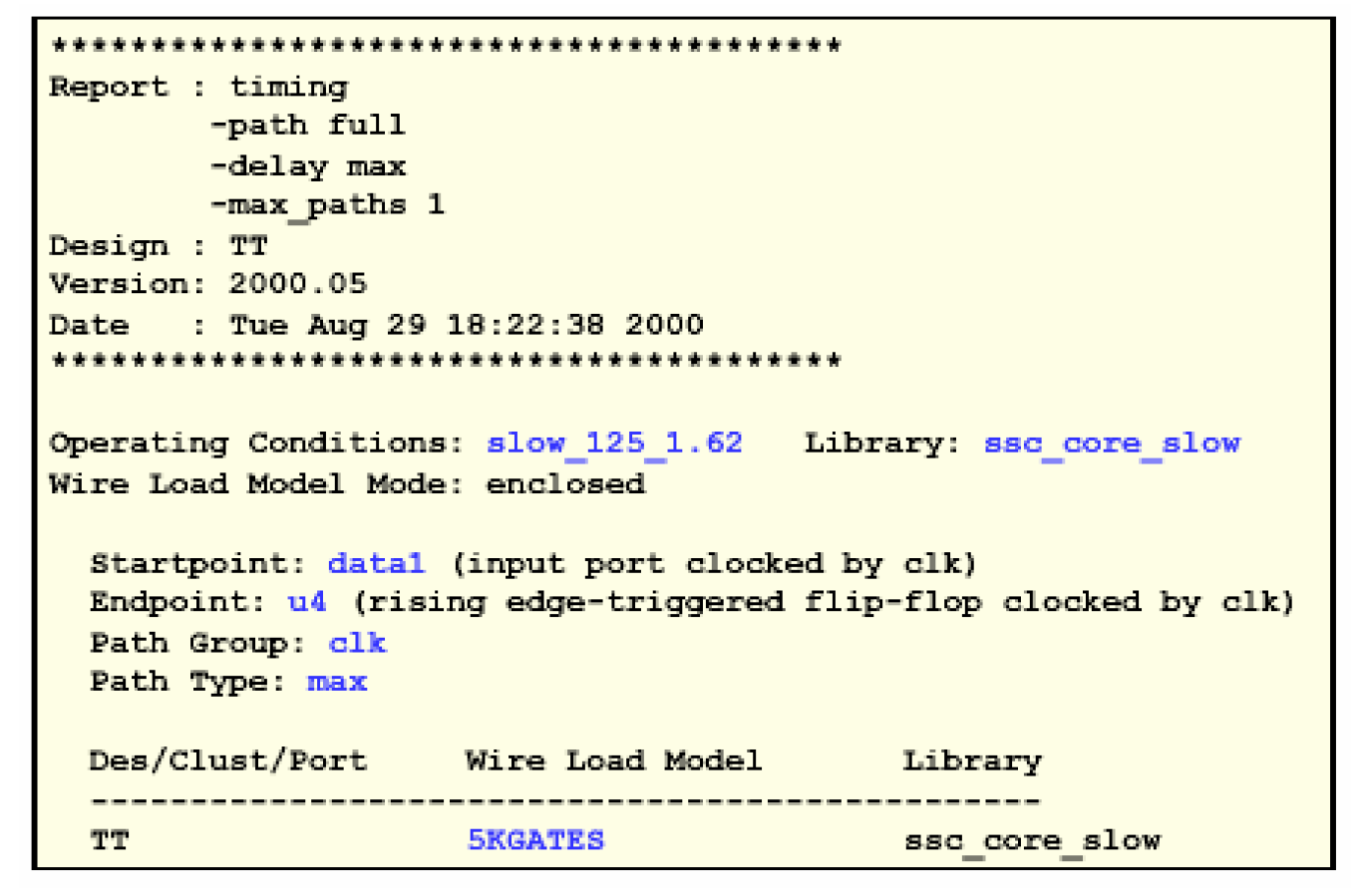
第一部分显示了路径的基本信息——工作状态是slow_125_1.62,工艺库名称为ssc_core_slow,连线负载模式是enclosed。接下来指出这条最长路径的起点是data1(输入端口),终点是u4(上升沿触发的触发器),属于clk路径组,做的检查是建立时间检查(max)。这一部分的最后还报告了电路的连线负载模型。

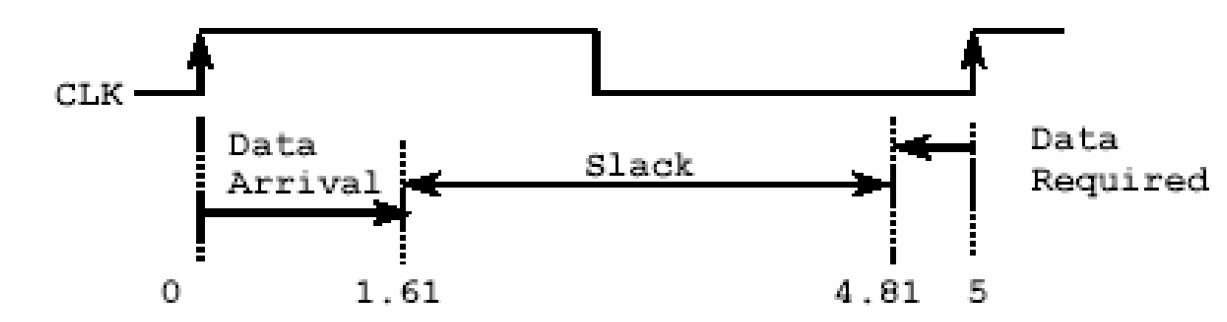
第二部分列出了这条最长路径所经过的各个单元的延时情况,分成三列:第一列说明的是各个节点名称,第二列说明各个节点的延时,第三列说明路径的总延时,后面所接的f或者r则暗示了这个延时是单元的哪个时钟边沿。例如图中的路径经过了一个反相器,一个二输入与非门,一个二输入MUX,最后到达D触发器。其中反相器的延时为0.12ns,路径总延时为1.61ns。
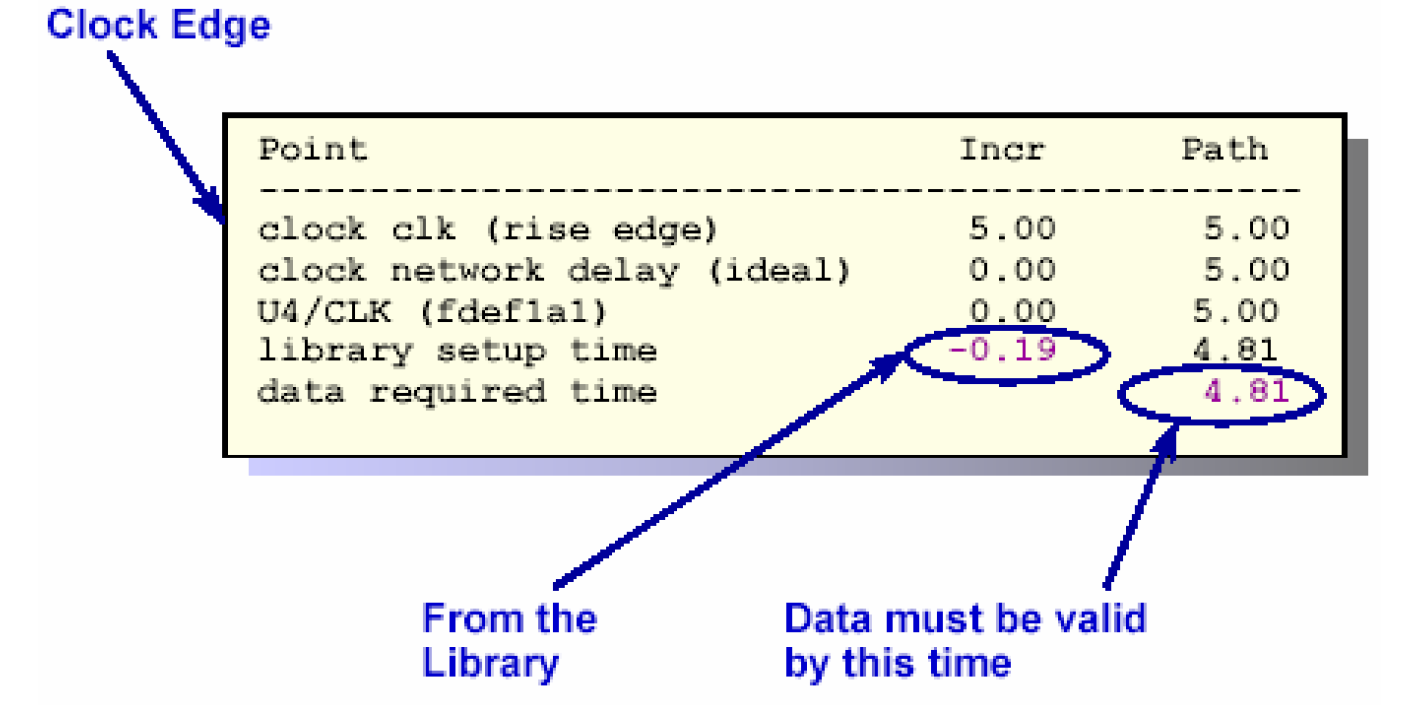
第三部分说明了这条路径所要求的延时,它是设计者通过时序约束施加的。例如时钟周期为5ns,触发器的建立时间为0.19(从工艺库中得到),要满足建立时间的要求,组合路径延时必须在4.81ns之内。
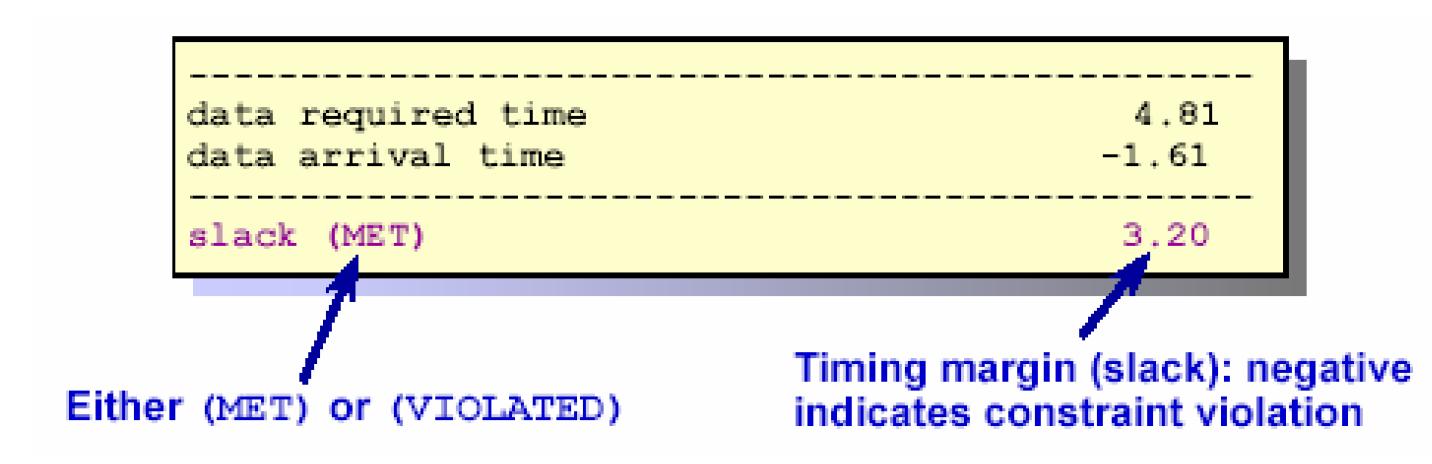
第四部分为时序报告的结论,它把允许的最大时间减去实际的到达时间,得到一个差值,这个差值称为时序裕量(Timing margin),如果为正数,则说明实际电路满足时序要求,为负数则说明有时序违反。上图的裕量为3.20,说明最长路径满足建立时间的要求,且有3.20ns的裕量。暗含的意思是所有这个clk组的路径都满足建立时间的要求,并且裕量大于3.20ns。
report_timing除了报告电路综合后的时序之外,还可以帮助我们诊断综合电路中存在的时序问题,下面是一个例子——

这个例子仅仅列出了报告的第二部分,报告的右边有四头鲸,它们分别指出了电路中存在的四个问题:
第一个问题出现在input external delay一栏,这一栏对应的就是时序约束中施加的input_delay,它的值为22.4ns,假设时钟周期为30ns,那么可以看出这个input_delay就已经占据了整个周期的70%多,因此留给下面单元的裕量就很少了。需要考虑是不是需要设置这么大的input_delay。
第二个问题出现在路径中的6个串连的buffer上,它们对应的单元分别是INVF、NBF、BF、BF、NBF以及NBF。就逻辑功能来看,6个显得多余,而且产生了不必要的延时。
第三个问题是由一个延时为10.72的或门造成的。其他的单元延时一般不超过2ns,一个10.72的单元是不是因为负载过重引起的呢?值得仔细审查。
最后一个问题反映在这条路径穿过的层次上。从设计分层那一节可以知道,要使延时最小,应该把组合路径全部放在一个模块内。而这条组合逻辑同时穿过了u_proc、u_proc/u_dcl、u_proc/u_ctl以及u_init四个层次,可以通过group/ungroup命令把层次重新组织一下。
至此我们讨论忘了综合时设计约束的全部过程,现在我们知道了,对于设计约束来说,基本的约束涉及时钟约束和输入延时和输出延时约束。为了更精确的进行约束,我们需要进行环境属性约束,包括工作条件,线负载模型,输入驱动,以及输出负载等。在规划约束时,需要设计者进行提前的考量,并为约束留出裕度,即进行一定程度的过约束(约束条件比实际条件设置的更加严格一些)。此外我们还介绍了DC工具如何对时序进行分析,以及我们如何产生timing report,并对其反映的约束以及设计问题进行分析。
3.3 设计综合过程
在前面一章介绍完施加约束之后,接下来要做的工作就是将设计进行综合编译(compile),这一章我们将主要讨论综合编译的过程。这一章主要分为这样几个部分——
- 优化的三个阶段及其特点
- 编译的策略
- 编译层次化的设计
3.3.1 优化
这一节我们介绍Design Compiler进行优化的三个阶段:结构级、逻辑级以及门级,在不同的阶段,DC运用的方法和优化余地是不一样的,通过这一节的学习,你将对这几个阶段的特点和优化方法有一个比较清楚的了解,其中有一些方法我们在前面的章节中已经提及过,这里一起归纳一下,希望能加深大家的认识。
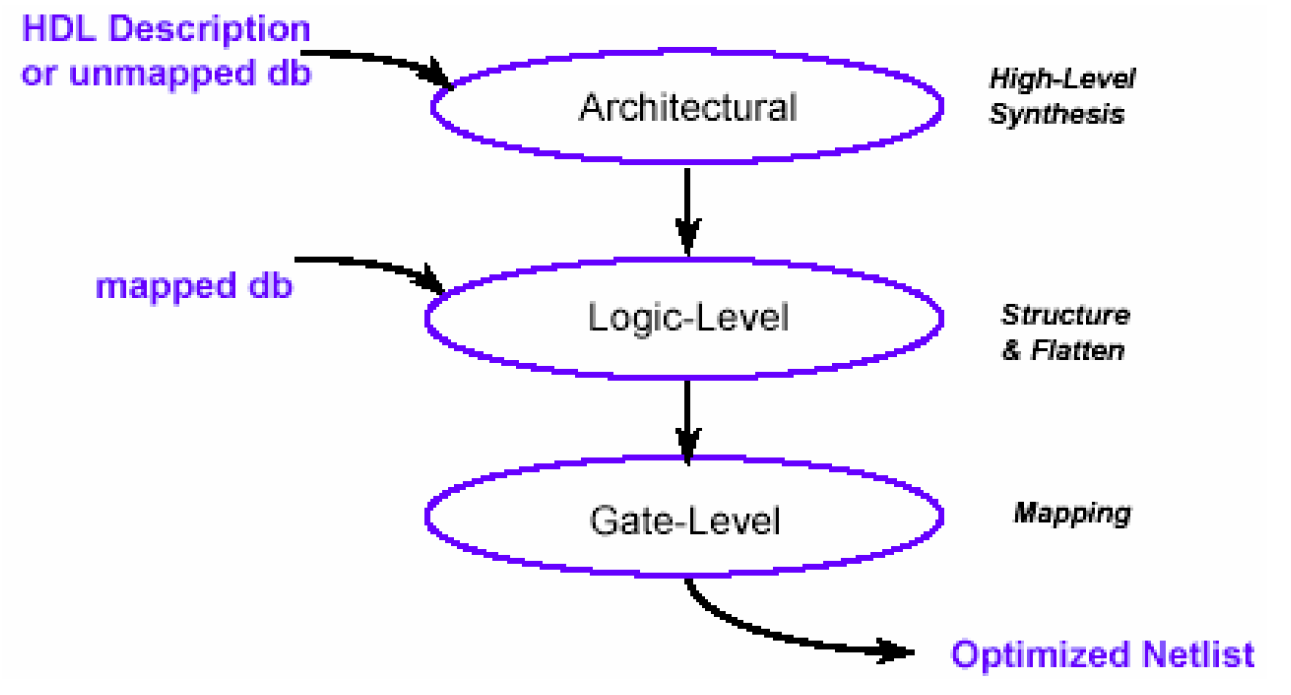
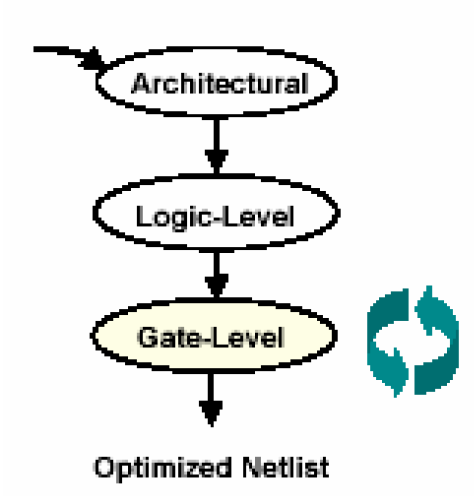
上图是这三个阶段的关系图,可以看到,结构级属于最高的抽象层次,当读入Verilog代码或者没有经过映射的db文件后,DC的优化从这个阶段层次开始,可以说,结构级是优化的最高层次,所以对DC来说,这个层次的综合可以称为高层次综合(High-Level Synthesis)。结构层的下一个优化阶段是逻辑级阶段,也是读入映射过的db文件的DC的初始优化阶段。再往下一个阶段是门级阶段,也是优化的最后阶段,这里所要作的工作主要就是GTECH到工艺库的映射。
因为结构级是优化过程中层次最高的一级,因此它也是DC可以采用的优化方法最多的一级,它的主要优化方法如下图所示——
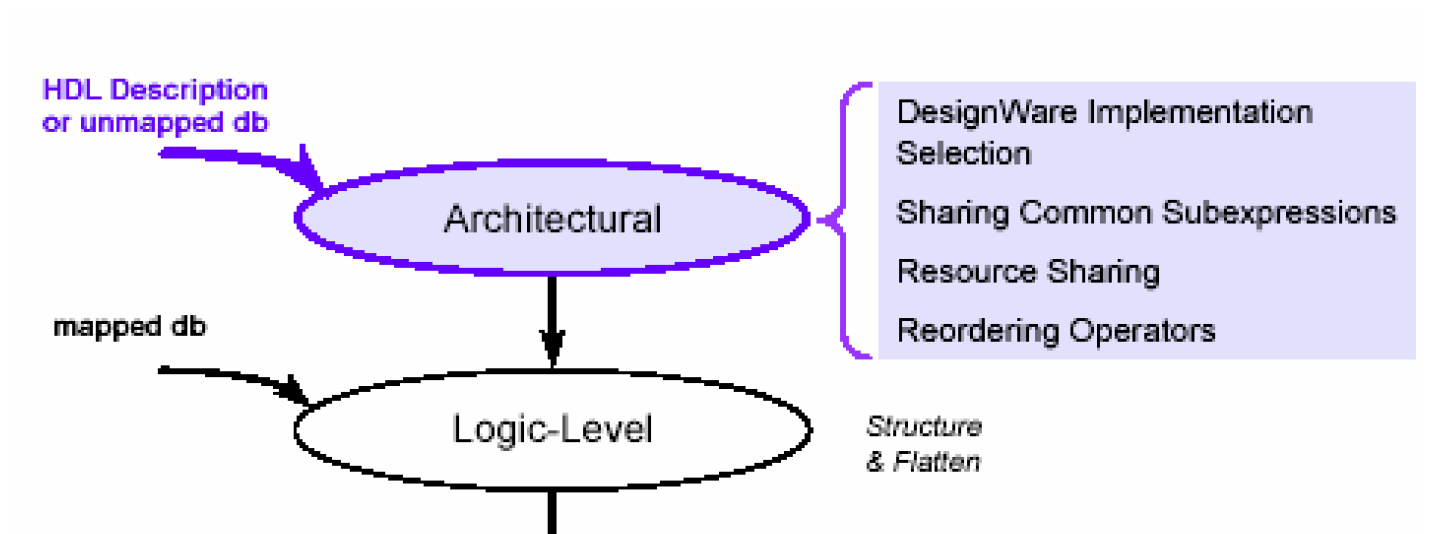
DW选择是结构级优化的一个很主要的特点,在这个阶段DC能够根据设计者施加的时序或者面积的约束在DW的不同实现方式中找到它认为最佳的实现方案。比如加法器的实现方式一共有如下几种——
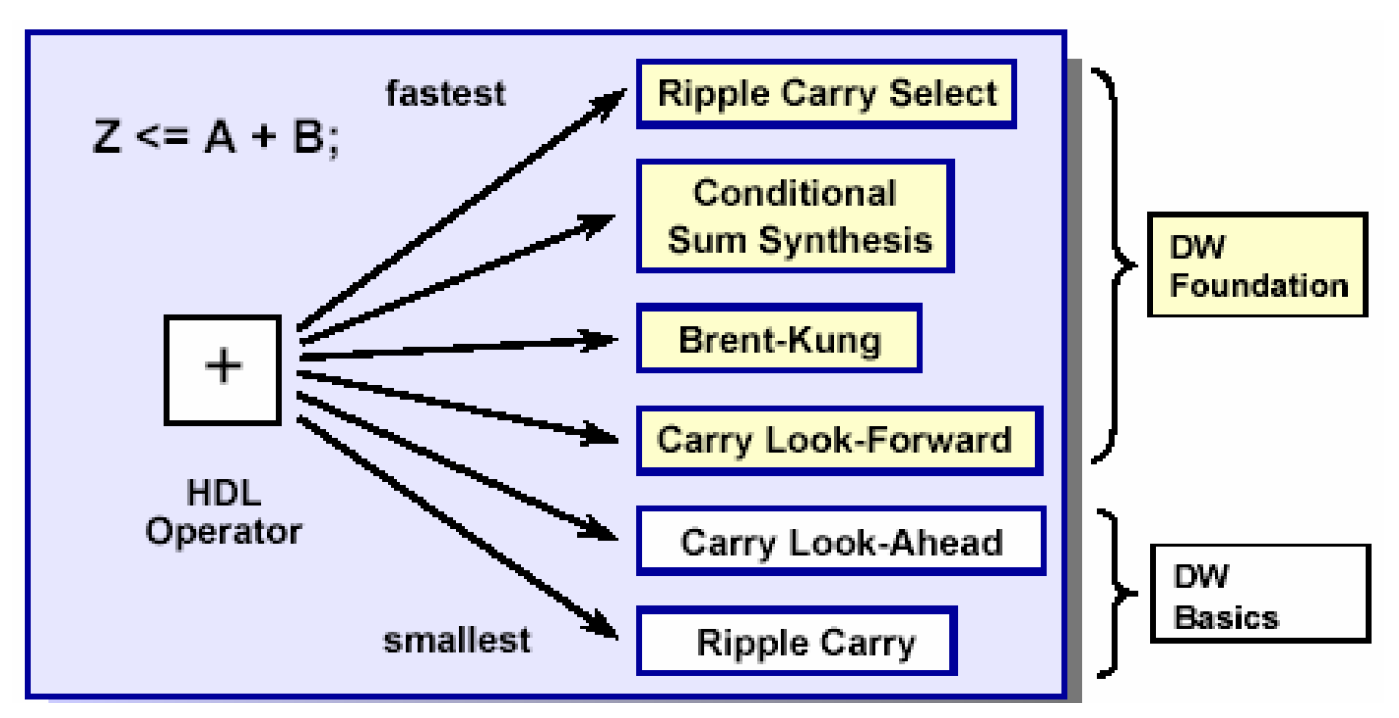
其中DW Foundation需要有专门的license,而且使用之前还要设置综合库(synthetic library)。
第一个优化方法是共享子表达式(Sub-Expressions),这里的子表达式主要是指数学表达式,比如下面这个例子,如果按照原来的语句综合,会包含6个加法器,但是如果表达式之间的公共项提取出来,便可以大大的减小面积,如下图——
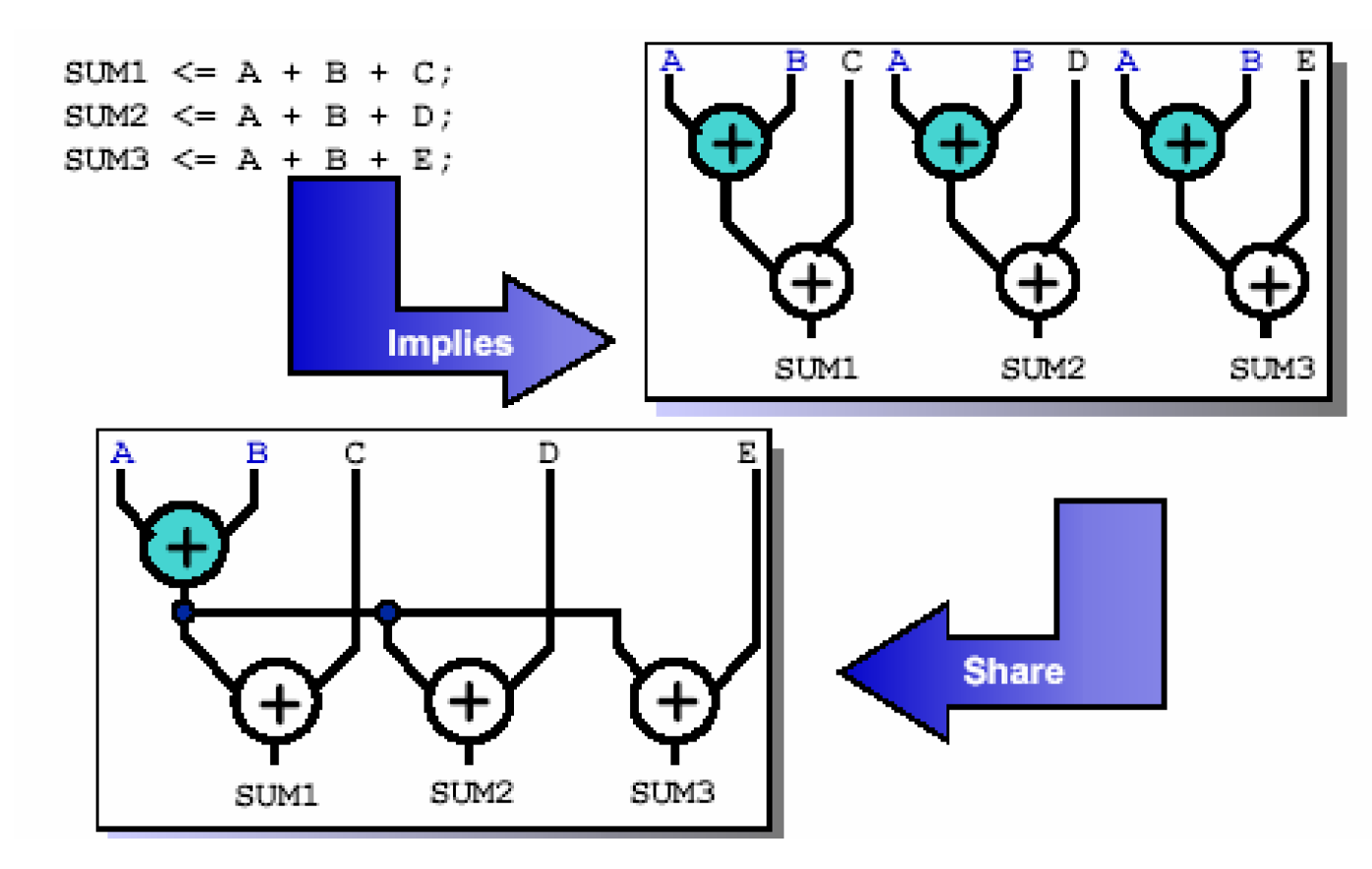
如果要直接综合出共享后的电路,可以在编写RTL代码的时候强制指定共享项——
temp <= A + B;
SUM1 <= temp + C;
SUM2 <= temp + D;
SUM3 <= temp + E;
第二个是资源共享(Resource Sharing), 资源共享的原理与共享子表达式类似,只不过这里指的所谓资源是一些HDL的运算符和表达式,比如加(+)、减(-)、乘(*)、除(/)以及大于(>)、大于等于(>=)、小于(<)、小于等于(<=)。这里举的例子,在前面的章节里也见过,比如给定一个语句——
if (SEL = 1)
SUM <= A + B;
else
SUM <= C + D;
它可能有下面两种电路实现:
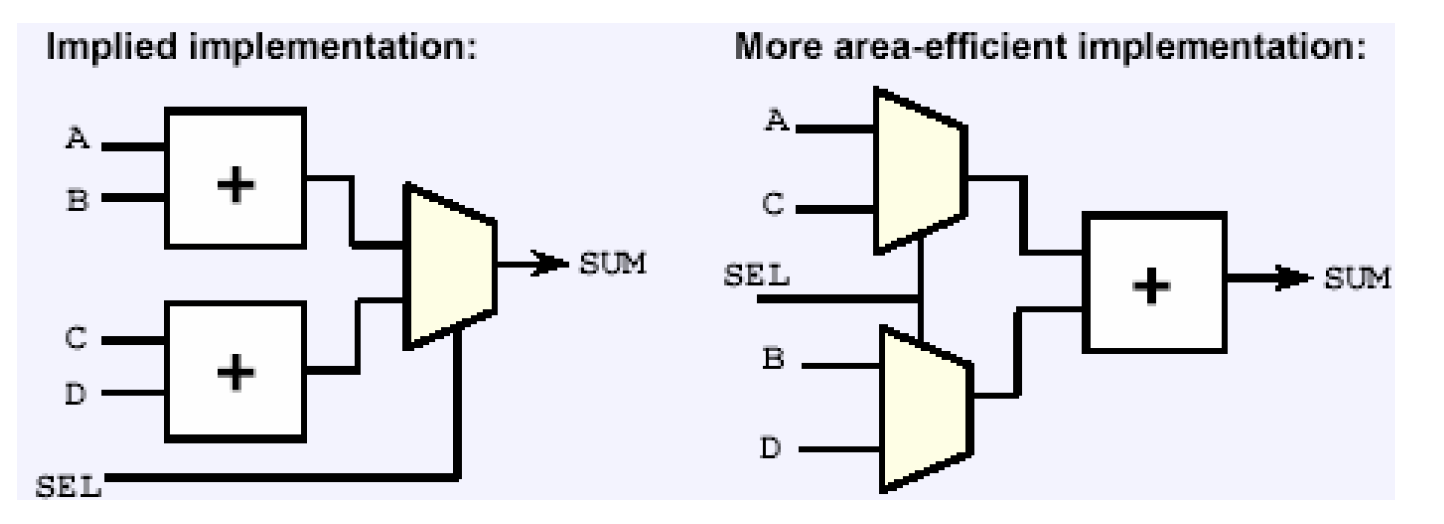
DC会根据具体的约束条件综合出最符合要求的结构来。
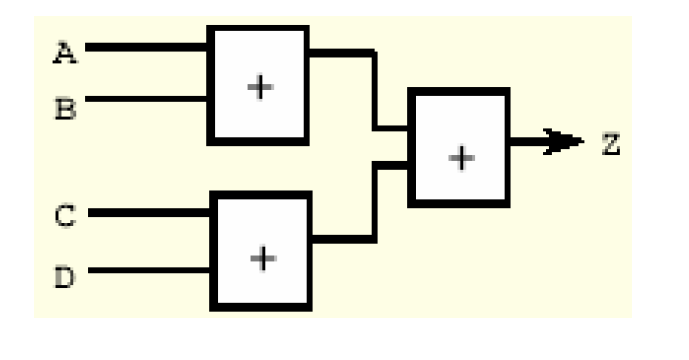
此外还有运算符排序(Operator Reordering)。对于下面这个表达式Z <= A + B + C + D(输出Z是施加了一定时序约束),DC最初是按照从左至右的顺序计算的,也就是说它最初的排序如下——
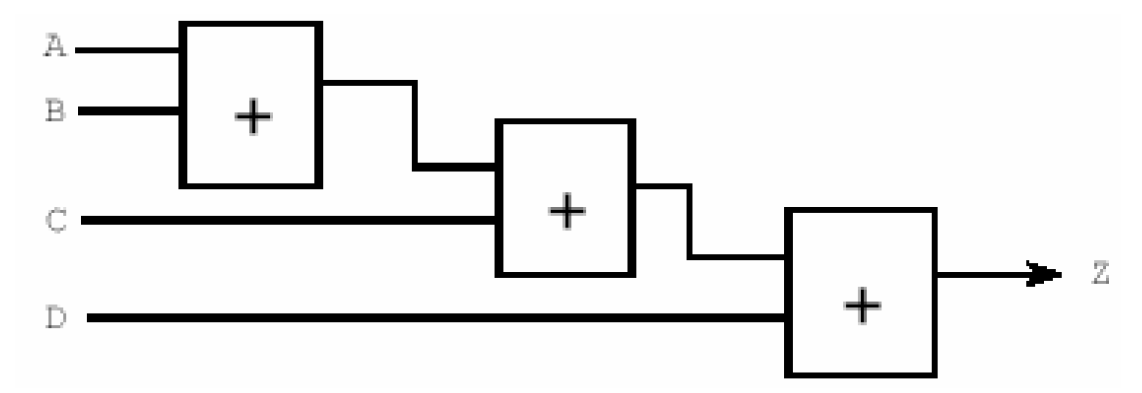
如果几个输入信号到达的时间相同,DC会通过运算符排序优化成下图的平衡的结构,减小延时——
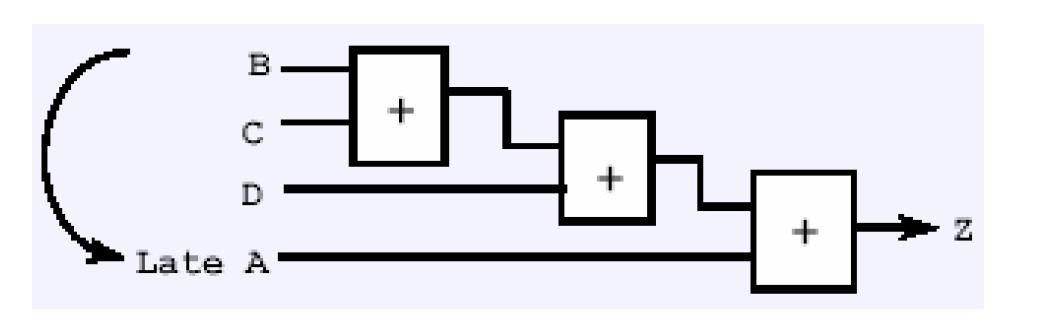
如果A信号较迟到达,则综合出的电路结构会如下——
在经过结构级优化之后,电路被转化成了工艺无关的GTECH库的形式,这级也称为逻辑级,对于逻辑级优化来说,只有一个方法,那就是——结构化 (structure)或者扁平化(flatten)。
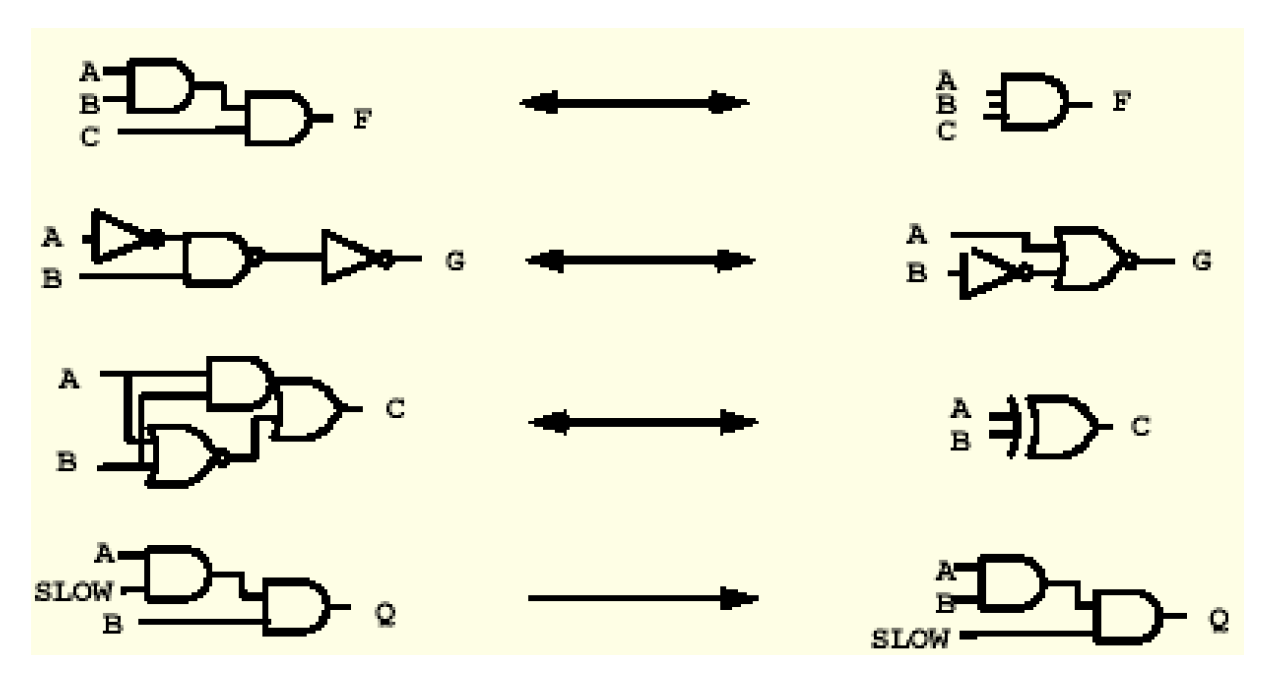
结构化是DC在逻辑级的默认的优化方法,它是指:使用电路的一些中间项构成一个多级的电路结构。如下图的电路一共有三级逻辑,下一级的输入是上一级的输出,使用这种优化方法一般情况下能综合出兼顾时序和面积的电路来。
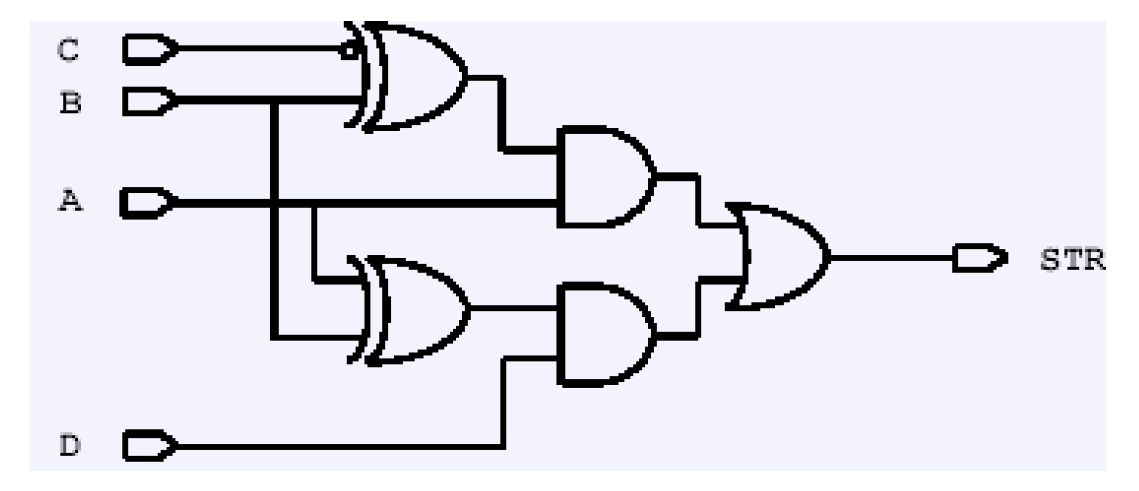
结构化电路的典型是奇偶校验电路。
扁平化是将所有的组合逻辑打平成乘积项和(SOP)的两级结构,类似与可编程阵列逻辑(PAL)。使用这种结构的特点由于没有利用中间项,综合后电路面积将会变得很大,但是却不一定能取得较好的时序。
扁平化结构的电路和设置扁平化的DC命令如下所示——
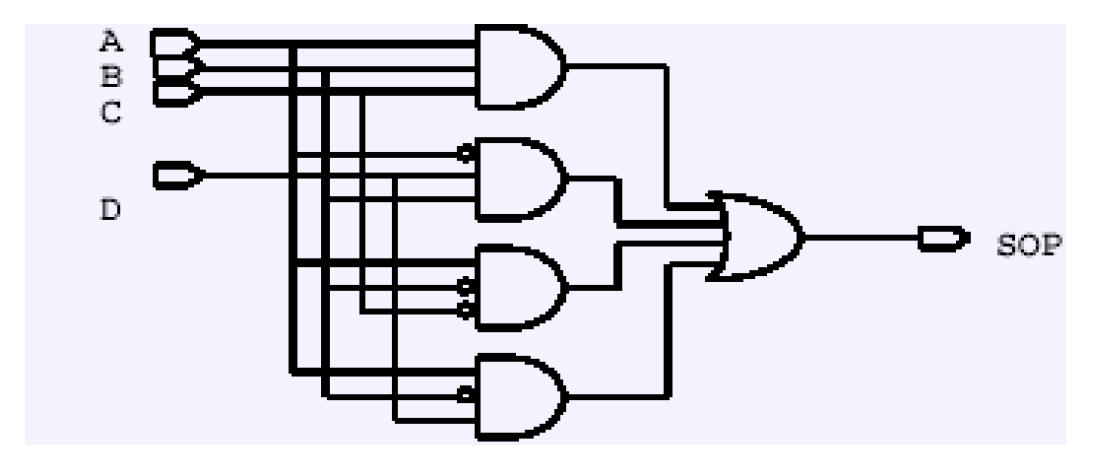
set_flatten true -effort low | medium | high
综合结构化和扁平化的特点,可以归纳如下——


由于DC默认是用结构化的方式综合逻辑级电路,而且这种方式可以得到兼顾时序和面积的结果,因此我们可以先用这种方式优化。在优化后的电路中找出关键路径,看看关键路径上有没有符合使用SOP电路的模块,再将这些方便使用SOP的模块set_flatten,以便取得最佳的效果。
门级优化是优化的最后阶段,它所要完成的任务就是将GTECH的电路映射到最终的工艺库中,并且保证映射后的电路不违反设计规则(Design Rule)。
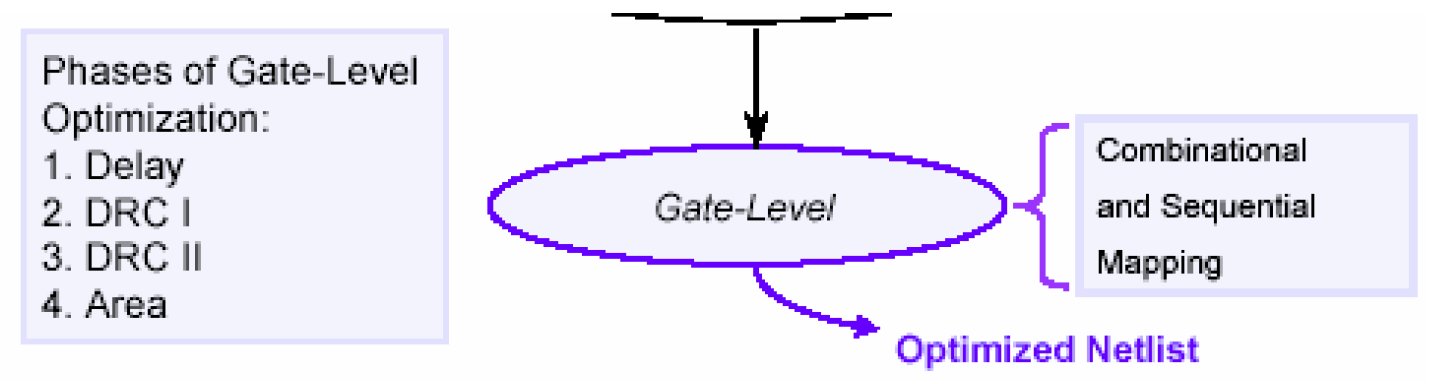
工艺映射包括组合逻辑映射和时序逻辑映射。组合逻辑映射是指DC使用工艺库中的各种门替换GTECH单元,并选择能实现相同逻辑的符合时序及面积要求的单元——
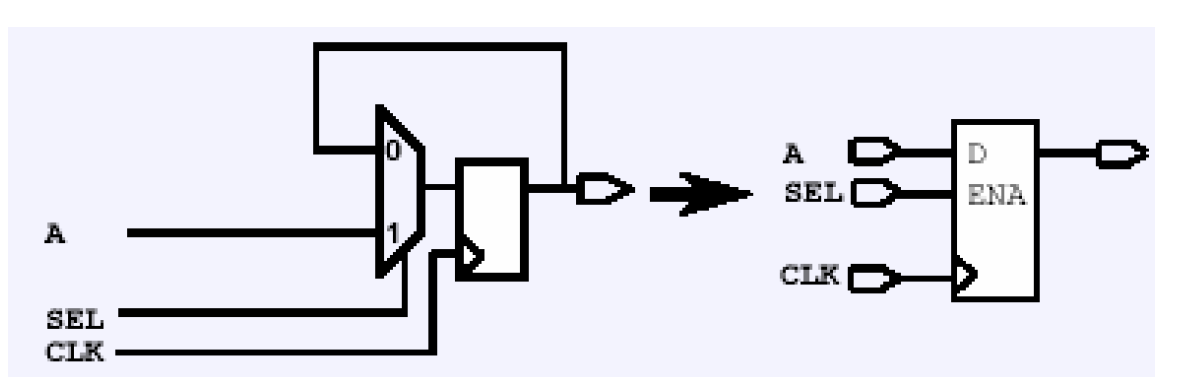
时序逻辑映射的方法和组合逻辑相类似,也是出于速度和面积的考虑,尽量使用复杂的时序单元吸收一部分组合逻辑。
对于工艺库的单元而言,Foundry都指定了每个单元的工作条件的限制,比如最大电容(max_capacitance)等等,这些限制也可以称为设计规则(Design Rule),在设计规则限定的范围内,Foundry提供的参数才有实际的意义。比如一个单元允许的最大电容为5pf,而实际工作电路中出现的电容值为10pf,那么这时,便违反了设计规则,单元的参数也就不能确保是准确的了。
因此,DC在作门级优化的时候,在映射的过程中也会检查电路的设计规则,一般的做法是在单元中插入buffer增加驱动能力,或者将小驱动的单元替换为大单元。设计规则检查分为两个过程——DRC I 和DRC II。
DRC I是指Design Compiler在不影响电路的时序和面积的前提下修正违反规则的一些单元,如果在这个前提下不能完全修正,则要进行下一步的检查,即DRC II,这一步的修正必然是以牺牲一部分时序和面积为代价的。
3.3.2 编译
编译过程是指设计经过三个阶段的优化,最终形成门级网表的过程,在这一节里,我们主要就编译的策略,它包含如下几方面的内容——
- 中断编译的方法
- 从报告中检查时序,调整策略
- 修正保持时间违反(Hold time violations)
在DC-Tcl的界面下,当我们键入compile命令时,DC就开始了编译,也就是优化的过程。优化是在设计规则的条件下,运用不同的算法,综合最终出满足时序和面积的电路。优化首先是时序驱动(timing-driven)的一个过程,其次再是面积。如果找到了一个满足时序和面积等约束的电路,编译将会停止;如果通过种种编译仍不能满足时序,编译也会停止下来;另外,我们也可以人为的中断编译。
人为中断编译的方法是键入Ctrl-C,经过一段时间的等待后(有可能时间会很长),优化过程暂停。
DC在编译的过程中,会自动打印出一个报表,报告编译的总时间,设计的面积,关键路径的时序违反和总共时序违反情况,我们可以根据需要更改打印的列项目——
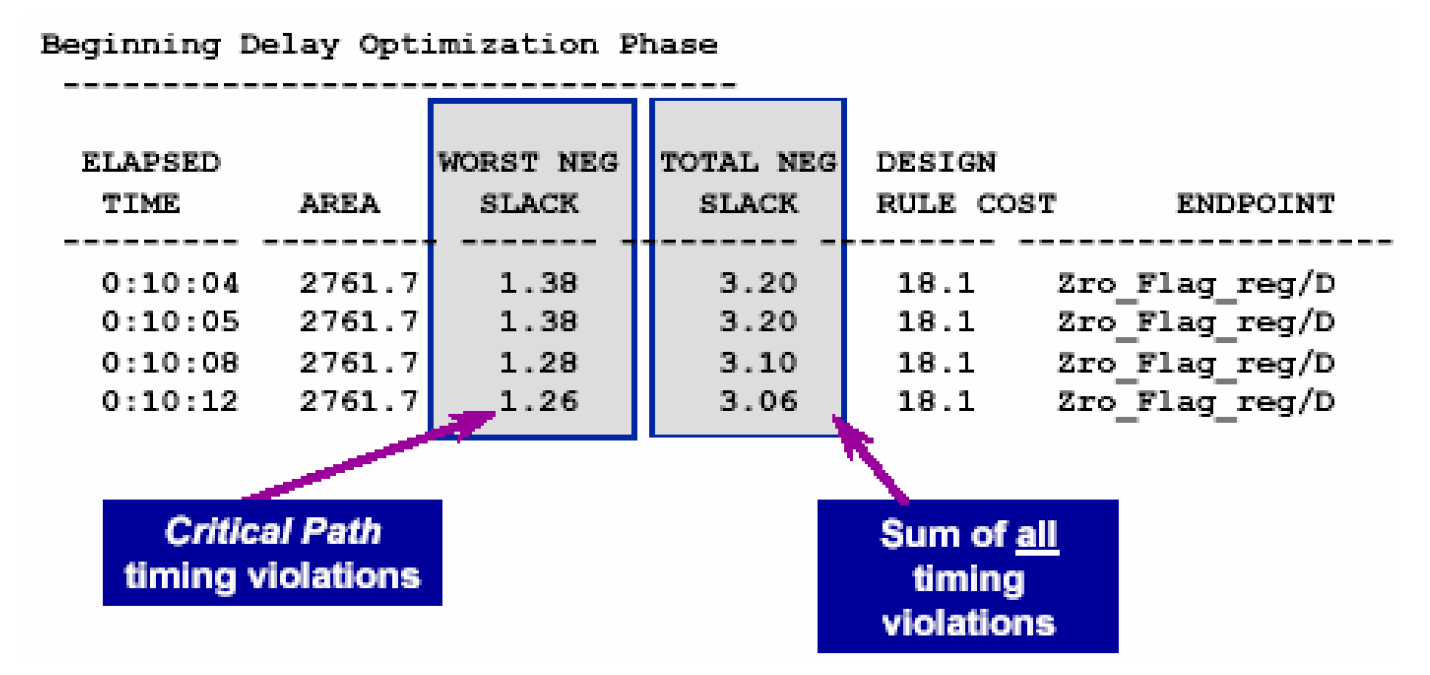
一般情况下,我们先作一个默认的编译,这样一般可以取得既快又准确的结果,然后在编译完成后使用一些报告时序的命令,并分析它们的输出结果,使用的命令主要有——
-
report_constraint –all_violators报告电路中所有没有满足的约束条件,包括设计规则、建立时间、保持时间以及面积。通常这应该是最先执行的命令。
-
report_timing –delay max报告基于建立时间检查的关键路径,每一个路径组的关键路径都被报告出来。
-
report_timing –delay min报告基于保持时间检查的关键路径,每一个路径组的关键路径都被报告出来。
从这些报告中,我们可以看到电路中是否有违反的约束,如果有,那么它是什么类型,还有电路中的最大负裕量(worst negative slack)是多少,等等。下面我们就几个常见的约束违反情况,谈谈纠正它的综合策略——
较大的时序违反:请看下面这个例子——
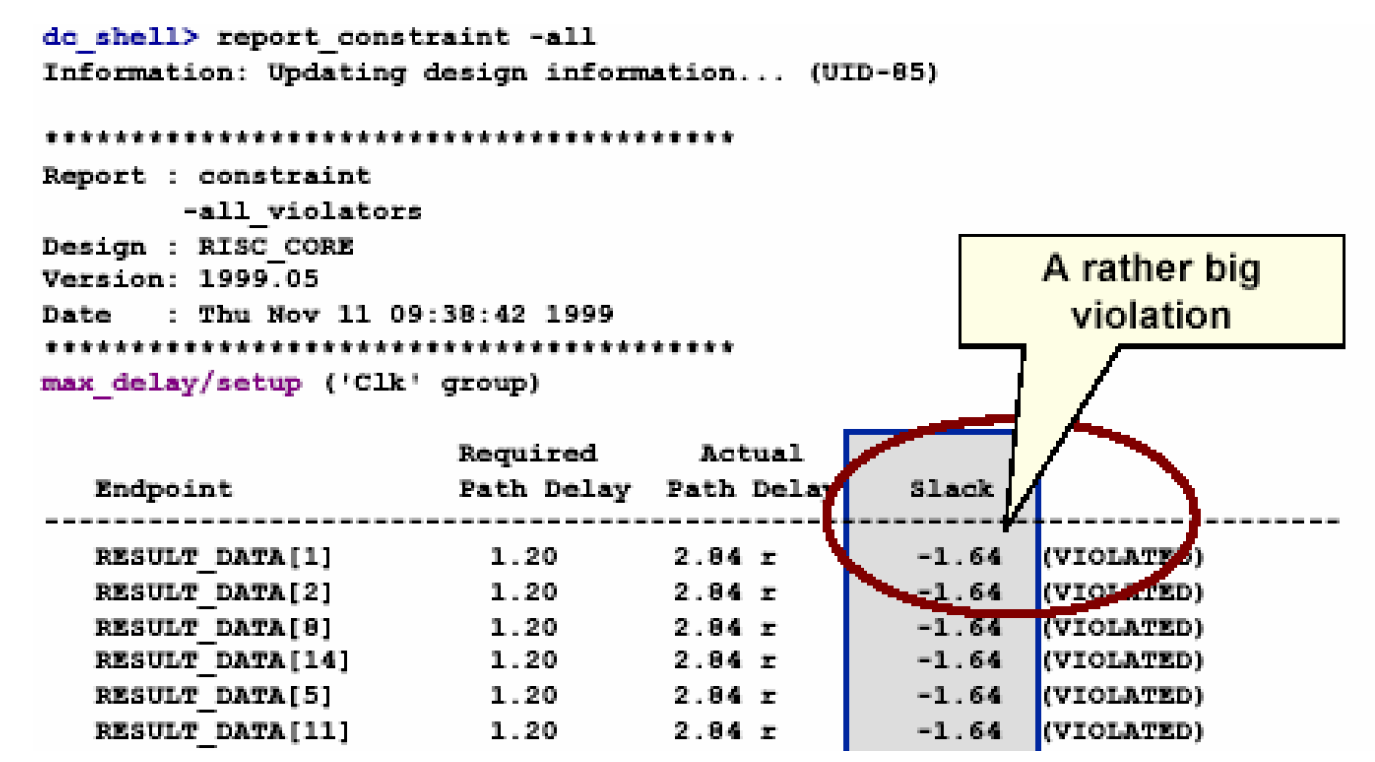
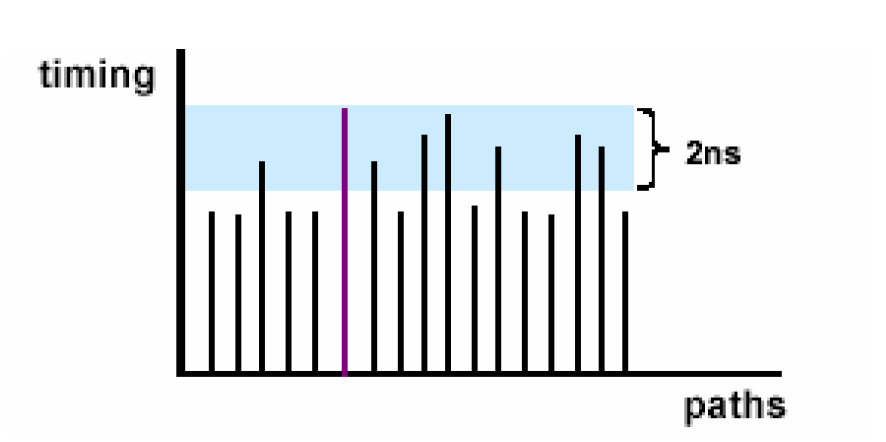
从report_constraint –all这个命令的报告可以看出,需要到达的时间是1.20ns,而实际到达为2.84ns,违反了1.64ns。之所以判断它是一个较大时序违反的情况,并不是因为1.64这个绝对值很大,而是相比较需要时间而言,1.64是一个较大的值。一般而言,如果电路中的最大负裕量(简称WNS)所占时钟周期的15%以上的话,可以认为电路存在较大的时序违反。
确认存在较大时序违反之后,下一步就是找出原因,消除违反情况。可供参考的步骤有下面几种——
- 检查约束条件,看是否有疏漏或错误
- 检查模块划分,看组合逻辑是否穿过多个模块
- 重新编译优化后的网表
- 修改RTL代码
下面详细讨论后面的三种情况——
重新编译(Re-Compile)
当重新读入映射后的网表进行重新编译时,DC会自动将门级的网表重新返回到GTECH的结构,相当于逻辑级。然后分别进行逻辑级和门级的优化,但是同时也可以进行DesignWare的替换。
如果设计者仅仅将映射后的网表拿来再做一次compile,编译后的结果并不会不一定会比原来的好,无非把以前做过的优化再跑一遍。因此,重新编译之前会改变一些参数,如——改变设计约束、改变set_structure和set_flatten参数以及改变编译的map_effort。
改变map_effort重新编译
对设计进行编译的时候,有三种编译级别可以选择,它们分别时低级、中级和高级。
compile -map_effort (low | medium | high)
不同的级别编译要求的编译时间和编译结果都各不相同,compile –map_effort low编译时间最短,但是结果不一定好,它一般用于设计预估(Design Exploration),不用在重新编译环节。
compile –map_effort medium是DC默认的编译级别,大多能在一定的时间内得到较为满意的结果。这也是我们推荐的初始编译级别。
compile –map_effort high 编译的过程中会使用前面的级别中没有的算法,因此它所要求的时间是最多的,结果也是相对最好的。这种级别一般用在重新编译的阶段。
修改RTL代码:修改源代码所能取得的效果是最直接的,同时也是代价最高的。修改代码后,DC会从最上层的结构级开始优化,前面也讨论过,越上层次的优化方法越多。所以通常这样得到的结果也越满意。但是,修改代码也不一定放之四海皆准的方法,因此并不是所有的设计我们都能获得源代码,同时也不是可以随便修改的。
较小的时序违反:请看下面这个例子——
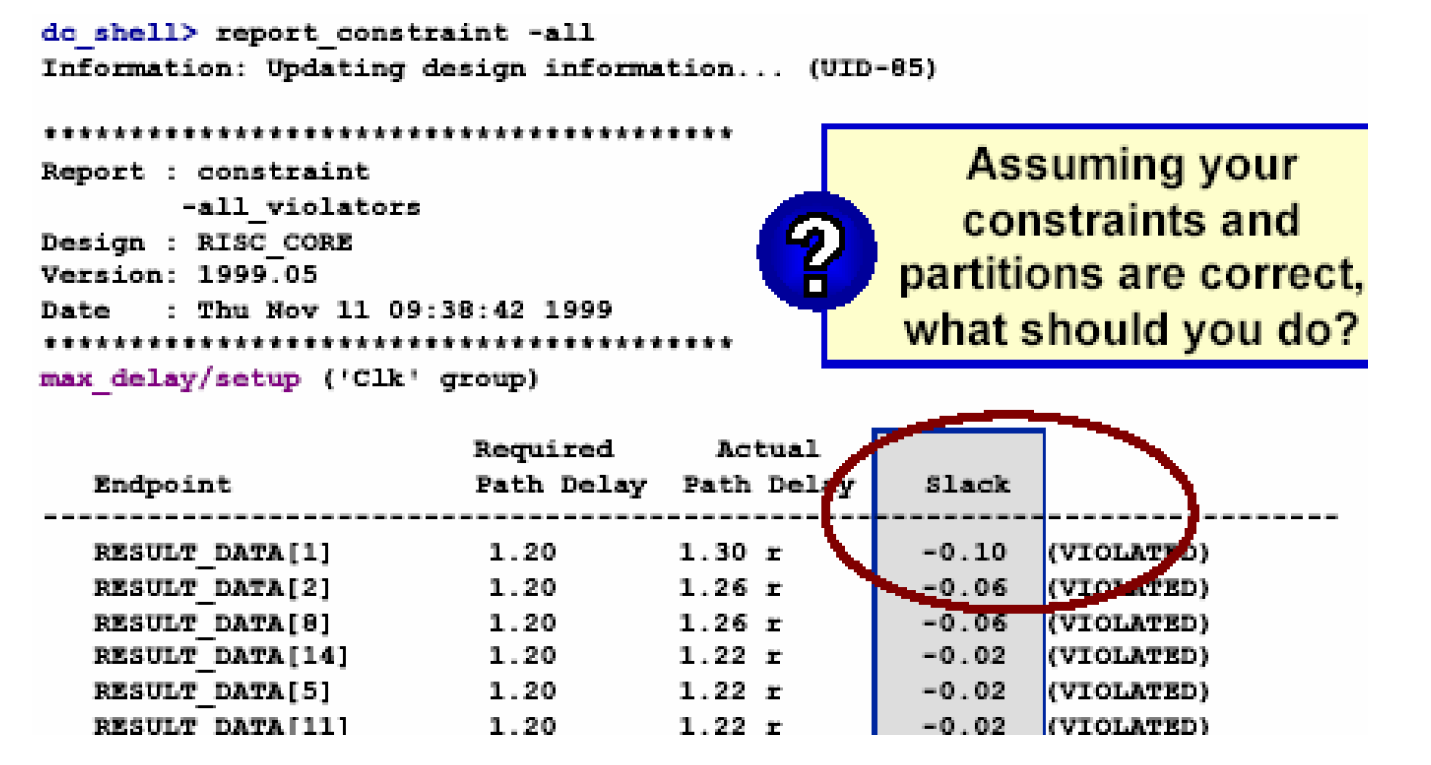
从上图看出,相比较1.20的允许路径延时,0.10的负最大裕量(WNS)是比较小的(小于15%),而且已经认定了约束和模块划分都是正确的,那么应该怎样修复这个错误呢?
这里主要讲一下Incremental Mapping——
compile -incremental_mapping,这个开关告诉DC,在重新编译的时候不需要把网表返回到GTECH结构,因此也不需要作逻辑级优化,速度也较一般的编译更省时间。这里DC所要作的是进行门级单元的替换,即在不违反设计规则的情况下用延时小的单元替换延时较大的单元。另外,如果读入的是db格式的网表,在这个阶段也可以进行DesignWare的替换。
compile -inc -map high,这里多加了一个-map high的开关,-map high开关前面已经提到过,它是让DC使用更多的优化算法优化电路,与上面的优化不同,这里需要把层次提高到结构级。
需要注意的一点是:这里所指的优化仅仅优化电路中的关键路径(critical path),也就是说,如果电路中的一个路径组中有多条路径违反,优化后也不可能全部满足时序。
如果要同时优化多条路径,需要使用另外一个命令——set_critical_range
这个命令设置的critical_range是以WNS的值为基准的,优化的是和这个值的绝对值差设置值的那些路径。因此,如果设置值为0,那么就仅仅优化一条关键路径。
例如,假设电路中的WNS为-3.4ns,如果设置了
set_critical_range 2 [current_design]
那么,当前设计中的所有负裕量的绝对值大于1.4的路径都将被优化掉。
有些时候的时序违反是由于设计规则违反引起的,比如说一个单元的扇出(fanout)过大,导致它的transition time的时间迅速增加。对于这种情况,我们可以通过
report_net -connections -verbose
report_timing -net (for fanout)
两个命令审查连线的连接和负载情况。
要修正设计规则的错误,可以使用一个编译的开关
compile -only_design_rule
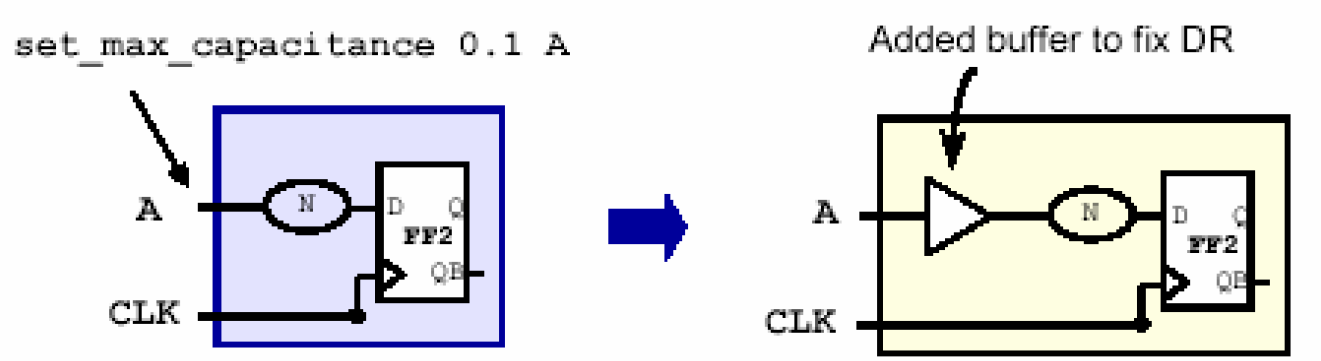
如下面这个例子,为了满足最大电容的规则,在A端口的内部加上了一个buffer,用于缓冲N路径对A的负载。
一个时序电路要想正常工作,除了必须满足建立时间要求之外,也需要满足保持时间要求。
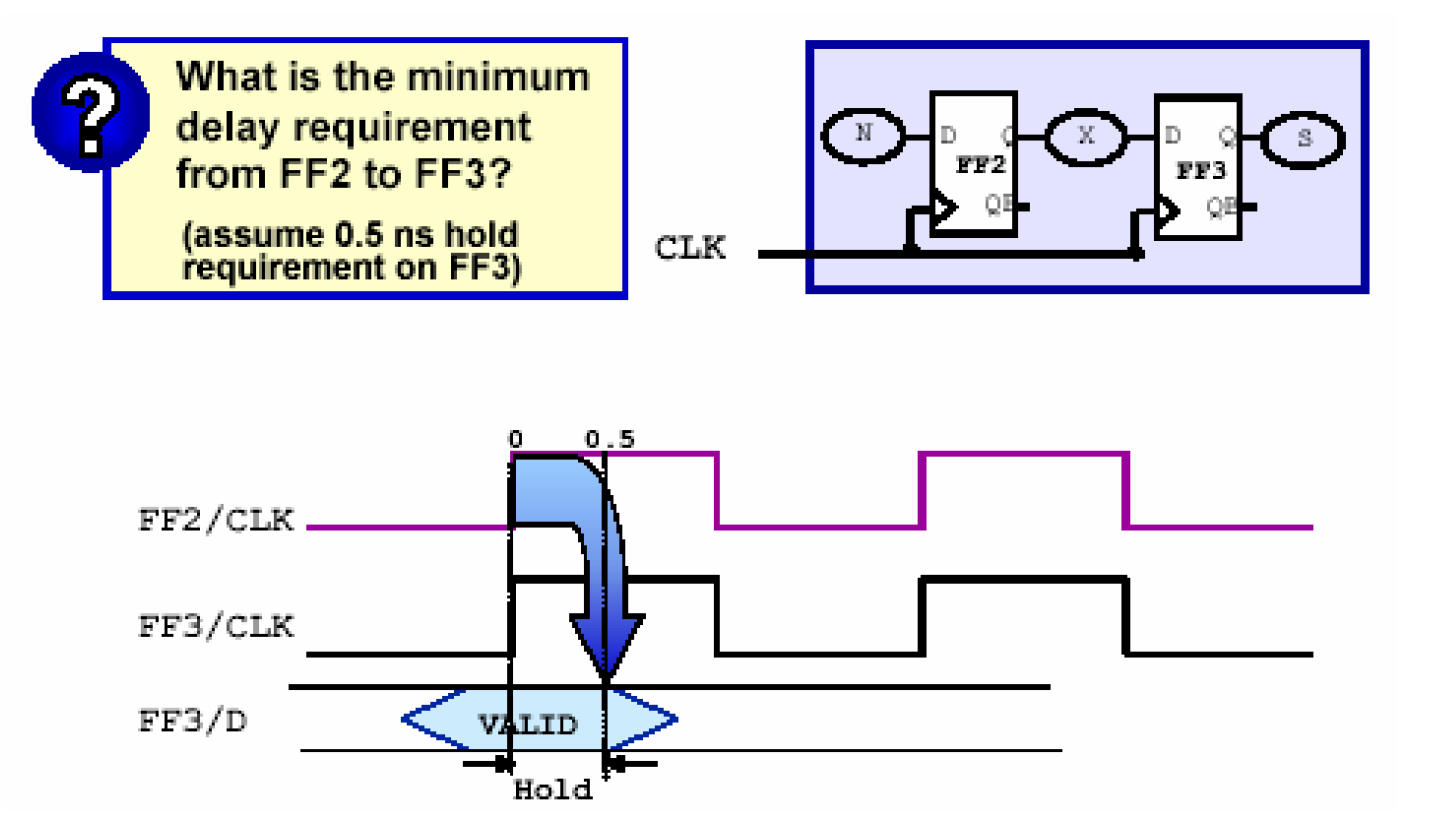
从前面的文章可以知道,为了满足建立时间,X路径的延时加上FF3的建立时间必须小于CLK一个周期的时间。这样做可以保证从FF2触发的数据能在一个周期后被FF3捕捉到。
同样,触发器还有一个保持时间,它是指在时钟边沿过后的一段时间触发器输入必须稳定,否则就会出现数据异常。为了满足这个条件,就必须要使得触发器在一个时钟边沿触发数据后必须等待一段保持时间才能接收新的数据。上图中假设FF3的保持时间为0.5ns,可见,在图示的上升沿,FF2触发新的数据,FF3捕捉了FF2在前一个周期触发的数据,如果X路径延时足够小,那么有可能在0.5ns之内FF2触发的新数据也到达了FF3的输入端,这样就引起了保持时间违反。
从上面的分析不难看出,保持时间容易出现在组合路径延时较小的路径中。下面我们分析时钟偏移(Clock Skew)对保持时间的影响。
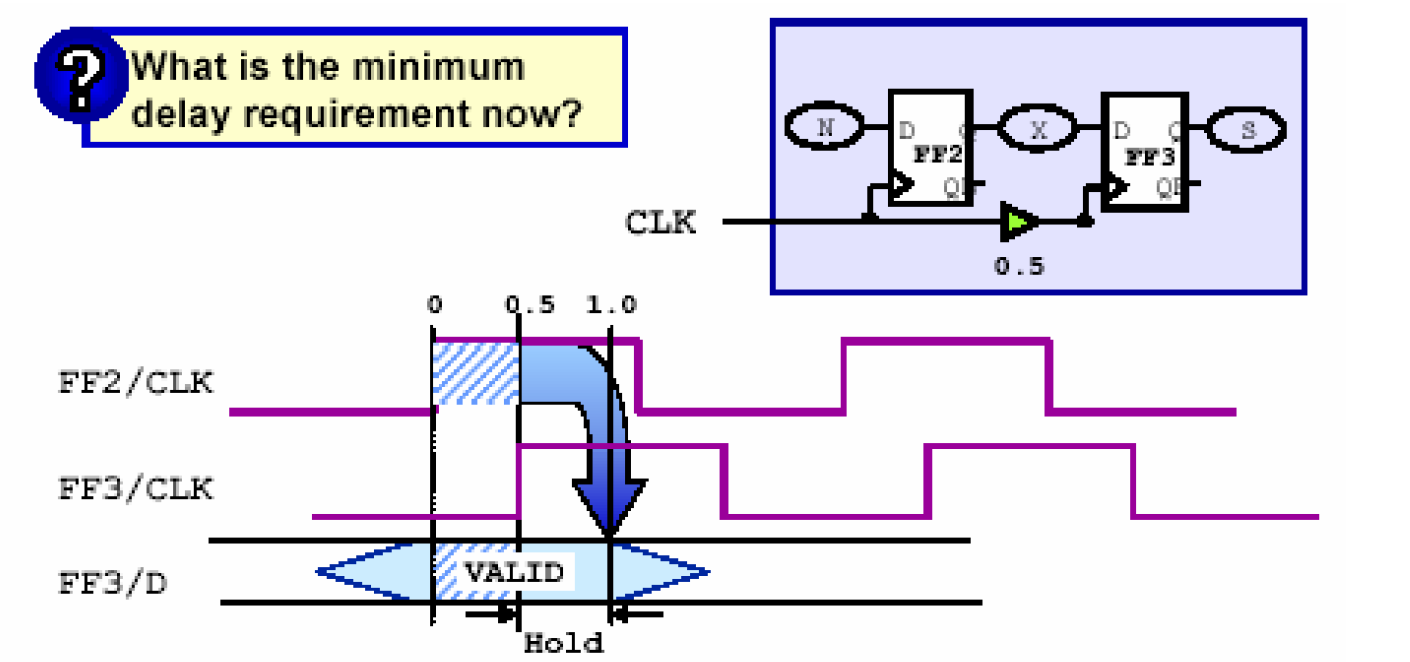
假设CLK到达FF3比FF2晚0.5ns,那么从上图可以看出,FF2的新数据到达FF3的可能性会比没有Skew增加。它现在的保持时间要求也从05ns提高到1.0ns。
除了时钟偏移之外,工作条件也会对保持时间产生一定的影响。工作条件的变化直接影响到的是各个单元(时序和组合)的延时。前面讨论过,最差情况(Worst case)下组合电路的延时最大,所以检查建立时间时用的都是最差情况。相反的,在最佳情况(Best case)情况下,组合电路的延时会变小,产生保持时间违反的可能性也增加了。
虽然保持时间检查和建立时间检查是同样重要的,但是我们在实际综合的过程中却不是把它们同时考虑,而是更多的把保持时间的检查放到布局后。这是因为——
- 时钟偏移必须要到布局完成后才能得到准确值
- 修正保持时间的通常做法是插入buffer,而这可能会增加建立时间违反的可能性,并且增大了组合电路的面积
- 保持时间检查用的一般都是电路工作的最佳条件,而在这个条件下,连线延时往往是被忽略的,连线延时也是必须在布局后才准确
如果确定要同时作建立和保持时间检查,那么在施加电路约束的时候要加入相应的开关,比如——
set_clock_uncertainty -hold
set_input_delay -min
set_output_delay -min
set_opertating_conditions -min -max
以及设置各自的工艺库——
set_min_library max_library -min_version min_library
下面详细谈一下设置保持时间的输入/输出延时——
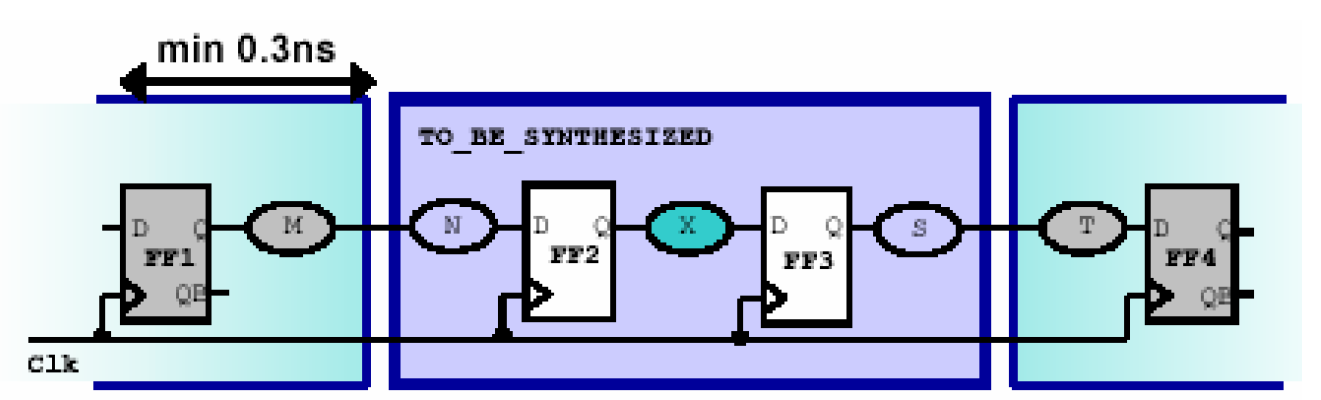
上面描述的是基于保持时间的输入延时set_input_delay -min,需要设置外围输入电路最快到达被综合模块输入端口的时间,假设CLK周期10ns,FF2的保持时间为1ns,输入最小延时0.3ns,那么可以写成——
create_clock -period 10 [get_ports Clk]
set_input_delay -min 0.3 clock Clk $all_in_ex_clk
可以推断出,此时N路径必须满足的最小延时为1ns-0.3ns=0.7ns。
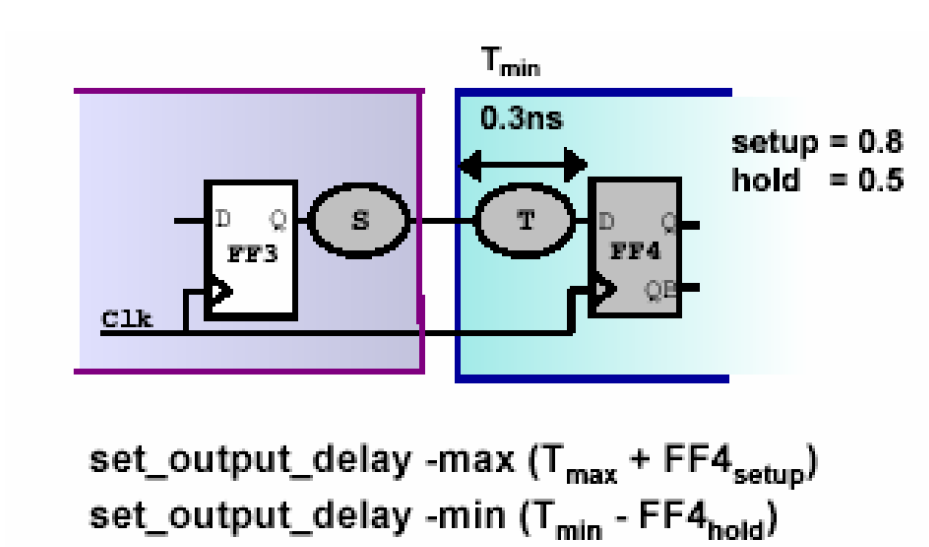
对于set_output_delay -min,图中所示,FF4是输出电路外围的一个触发器,它的保持时间是0.5ns,T路径的最小延时是0.3ns,那么得到FF3所在电路的输出最小延时(set_output_delay –min)就要比较小心,它的计算公式不是0.5-0.3=0.2ns,而是0.3-0.5=-0.2ns。这一点需要引起大家的注意,此时留给S路径的最小延时为0.2ns。
设置最小输出延时的命令如下——
create_clock -period 5 [get_clocks Clk]
set_output_delay -min [expr 0.3-0.5] -clock Clk [all_outputs]
默认情况下,DC不修正保持时间的违反。如果确定要作修正,需要先设置一个变量再作检查——
set_fix_hold [all_clocks]
compile -only_design_rule
加上only_design_rule的开关后,编译过程中仅仅更换单元大小,并增加buffer,以便修正设计规则违反和保持时间违反
下面是一个设置保持时间约束和修正保持时间违反的脚本——
read_db Top_meetsSetup.db
source TimingConstraints_max.tcl
set_operating_conditions -max WORST -min BEST
set ALL_IN_EX_CLOCK [remove_form_collection [all_inputs] [get_ports Clk]]
set_input_delay -min 0.2 -clock Clk $ALL_IN_EX_CLOCK
set_output_delay -min -0.1 -clock Clk [all_outputs]
set_clock_uncertainty -hold 0.5 [get_clocks Clk]
report_timing -delay min
set_fix_hold [all_clocks]
compile -only_design_rule
redirect top.rpt {report_constraint -all_violators}
3.3.3 层次化
一个层次化设计的编译过程包含两个阶段——
- 将所有的子模块映射到门级
- 优化
在第一个阶段,从下图可以看出,D_design含有三个不同的模块,在编译的这个阶段,U1、U2、U3分别由RTL级映射到门级,并且各个模块之间的层次关系保持不变。在映射的过程中,设计约束都暂时没有考虑。
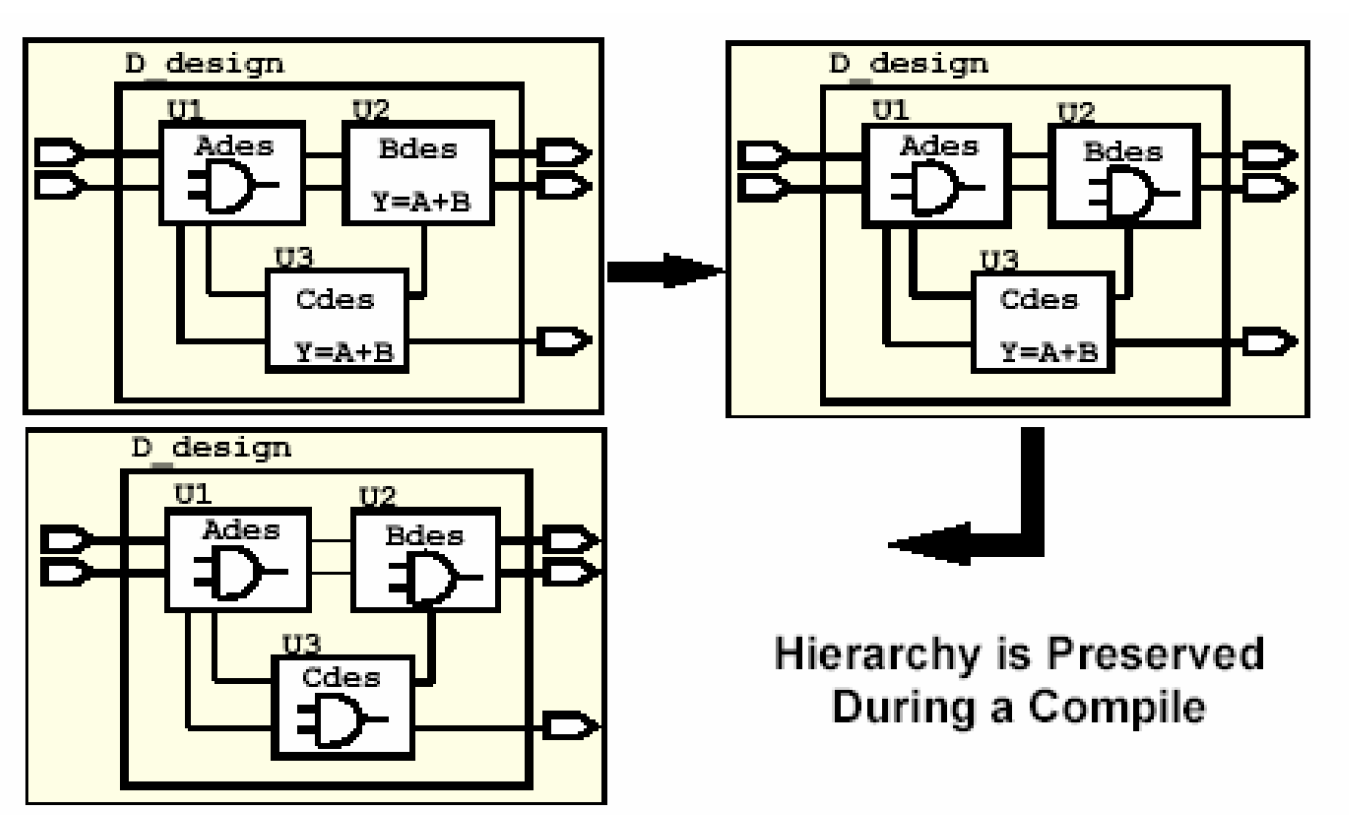
到了第二个阶段,Design Compiler根据各个子模块的时序和面积约束对它们分别进行优化,并且在优化的过程中要考虑到不同子模块周围的环境,修正产生的错误。
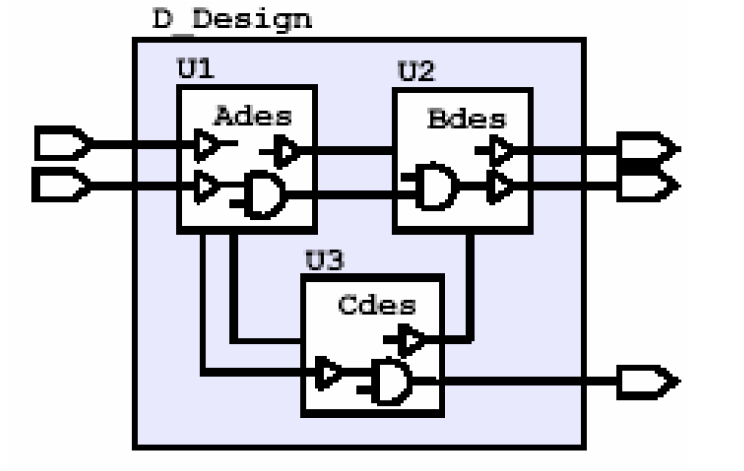
在一个层次化的设计中,我们可能会遇到下面这种情况——
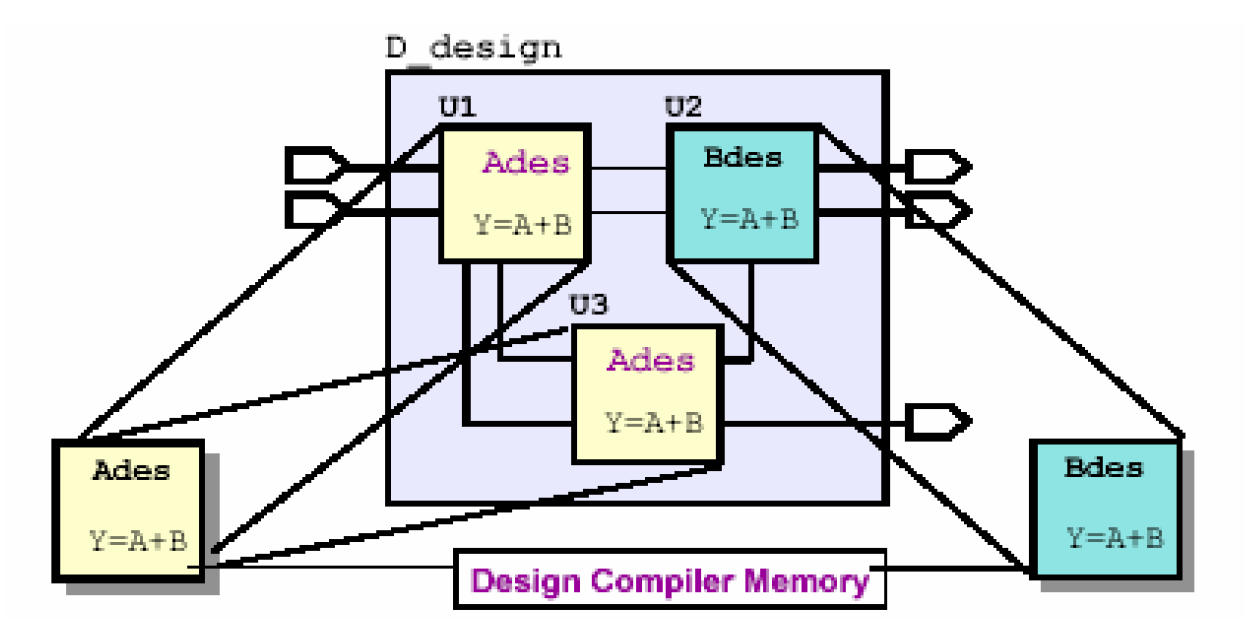
上图中,被综合的模块中D_design中含有三个子模块U1、U2和U3,其中U1和U3都是由模块Ades例化而来,这里的Ades称为多次例化的模块。对于这样一个设计,在compile之前使用check_design作检查的时候会报一个warning,即设计中存在多次例化的模块(multiple instantiations),如果在这种情况下,我们不考虑多次例化的模块(Ades),那么在继续的compile时候程序会终止退出。因此,必须对它进行处理,这一节里我们介绍两种方法——uniquify和compile + dont_touch。
方法一:uniquify
使用uniquify,DC会对每个例化的模块作一份拷贝,然后对它们分别取一个名字,即把不同的例化模块当作不同的两个模块处理——
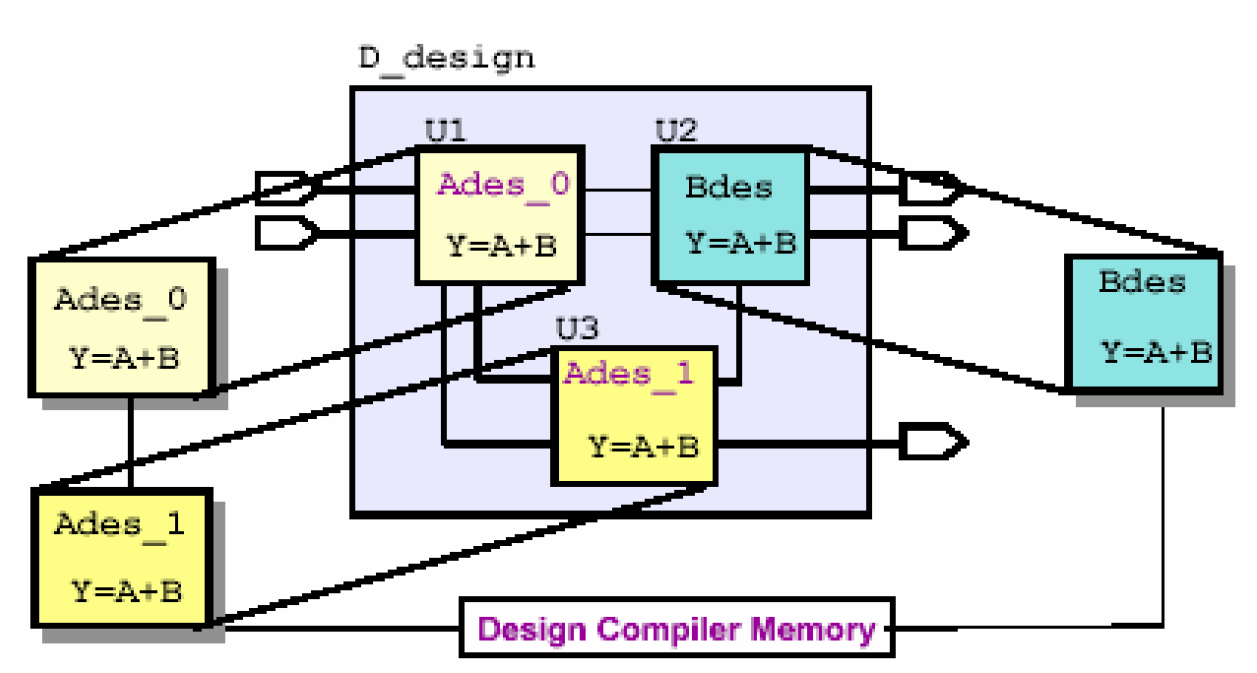
注意看上图,U1和U3两个模块的设计名分别由原来的Ades变成了Ades_0和Ades_1,因此在编译时,DC会将它们当作两个不同的模块,这样就可以根据它们不同的周围环境作优化。
使用uniquify的具体实现方法如下——
current_design D_design
source D_constraint.tcl
uniquify
compile
这段脚本与以前的脚本只有一处不同,即在compile之前加上uniquify这一行。
方法二:compile + dont_touch
这种方法先将多次例化的模块作单独的约束和编译,然后在整合到上一级模块的过程中将它的属性设置为dont_touch,再编译。
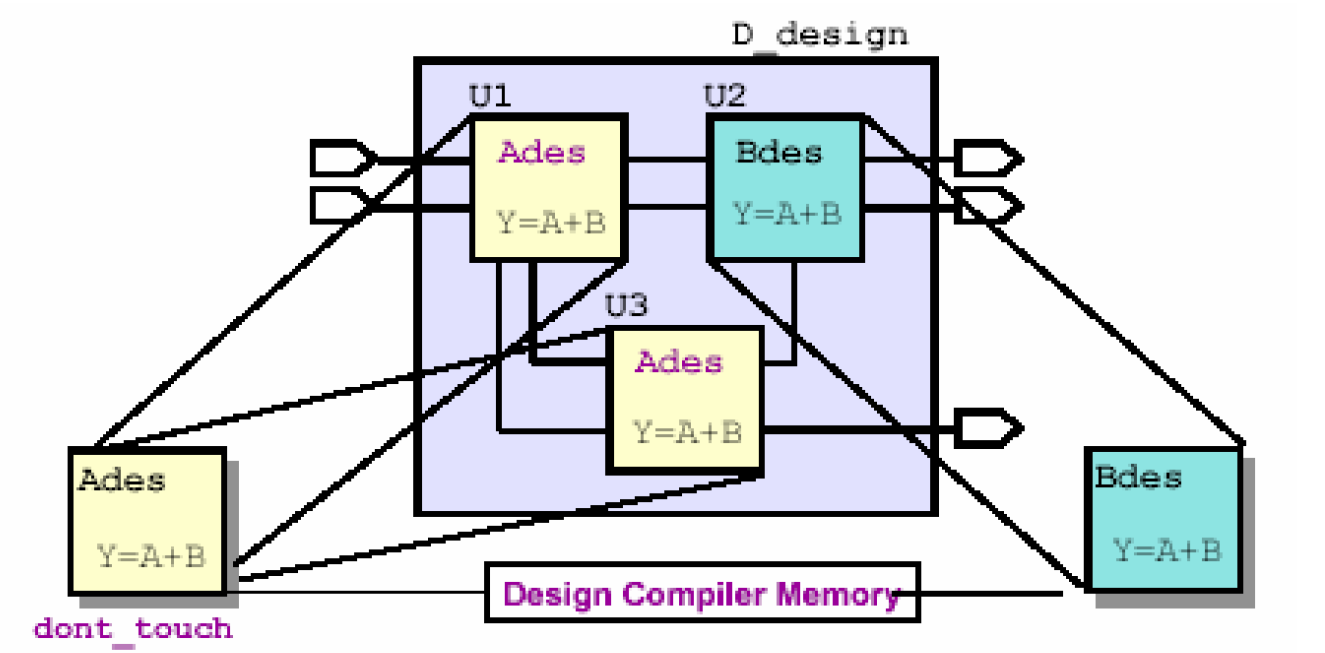
上图中,U1和U3两个模块的设计名都没有变化,只是在编译D_design之前先将Ades编译一次。这样U1和U3实际上是一模一样的模块。
compile+dont_touch的实现方法如下——
read_db unmapped/Ades.db
current_design Ades
link
source Aconstraint.tcl
compile
read_db unmapped/D_design.db
current_desgin D_design
link
set_dont_touch [get_designs Ades]
source Dconstraint.tcl
compile
这里的约束文件有两个,一个是Ades的Aconstraints.tcl,另一个是D_design的Dconstraints.tcl,并且在source后一个约束文件之前要对编译过的Ades设置成dont_touch。
在设置了dont_touch属性之后,编译D_design的时候就会忽略Ades,这样有好处也有坏处,好处是可以保护模块不被修改,但是这样同时也限制了DC对U1和U3的进一步的优化。
通过对上述两种方法的介绍,我们不难看出它们各自的优缺点——
compile+dont_touch由于只需要对多次例化的模块编译一次,因此可以减少整个设计的编译时间,也可以减少内存的使用量。在多次例化的模块很复杂并且工作站的硬件条件有限的情况下,使用这种方法的优越性的比较明显的。还有,如果这个Ades是一个第三方提供的硬核(hard-core),那么我们也只能使用这种方法。
使用这种方法的缺陷也是显而易见的:由于顶层模块在编译的时候Ades设置了dont_touch,这就妨碍了DC针对Ades的各个实例周围环境的不同的进一步优化,从而使得结果不能真实的反映各个实例周围的环境变化。
uniquify由于把各个多例化模块作为独立的模块来看,因此DC可以分别针对它们作出更好的优化,从而得到的结果也是比较理想的。缺点就是编译的时间稍微较长,但是对于一些不大的模块来说,这些是可以忽略的。
正因为uniquify可以综合出更好的结果,所以如果一般推荐使用uniquify解决多例化模块的综合问题。
更深入的介绍一下uniquify:
在design中,一个模块会在不同的module进行多次引用或者说实例化。uniquify就是在设计中使子模块的实例和子模块的定义一一对应,消除一个模块的定义被多次引用的现象。具体实现方法就是,uniquify 命令会将多次引用的模块的个数拷贝需要的数目,然后对他们分别命名而得到不同的模块名。
如果Non_uniquified 网表,多次实例化模块在网表中只有一个定义,而多次引用同一定义的各个实例内部的flop都需要各自的时钟,从而时钟树上这些模块的clock_net名是不同的,来自layout 工具的时钟树的信息和DC中原网表无法对应,所以会出现两个不同的net和一个相同的port连结,这是不允许的。
DC 会认为存储区中的模块都只是被引用一次的,uniquefy之后,如果各个模块的引用的工作环境各不相同,则使用这种方法可以使得模块的各个引用可以针对他们不同的环境分别进行优化,达到最好的效果。
DC 中compile_ultra会自动进行uniquify。
需要补充的是,首先这个问题是一个在RTL编写时即可规避的问题,在编写时我们就可以手动避免出现在多个模块中例化模块出现同名的问题,这是可以在编码规范中就解决的问题。
其次一点是,相比一般的compile指令,DC提供的compile_ultra指令有着更好的性能以及一些默认的功能选项,因此在实际进行综合时,我们常见的操作是:
compile_ultra
compile_ultra -incremental
即先使用compile_ultra获得一个网表,再通过-incremental的参数来对网表进行增量优化。
3.4 后综合过程
在这一章里,我们着重讨论使用Design Compiler综合大型设计时要注意的一些问题,比如怎样调整综合方法,出现约束违反后怎样修正,怎样给不同的子模块作时序和负载预算,以及给整个设计在具体综合之前先作一个预估(Design Exploration)等等。
对于一个大型设计而言,由于模块规模的扩大,编译时间也相应的变长,要长达几个小时甚至超过一天,这样的时间对于讲究”Time to market”的设计者是比较重要的。因此就更加注重编译的技巧,本节我们主要讨论下面三个方面的技巧——
-
编译层次化设计的技巧
-
第二次(Second-pass)编译技巧
-
characterize
3.4.1 编译层次化设计
对一个大型设计来讲,有两种层次化编译技巧——自上而下(Top-down)以及自下而上(Bottom-up)。自上而下的方法是指将整个设计一次性读入,施加顶层约束后直接进行编译;自下而上的方法则先一个个编译比较底层的子模块,给它们加入时序和负载预算,然后在顶层将各个子模块整合起来。
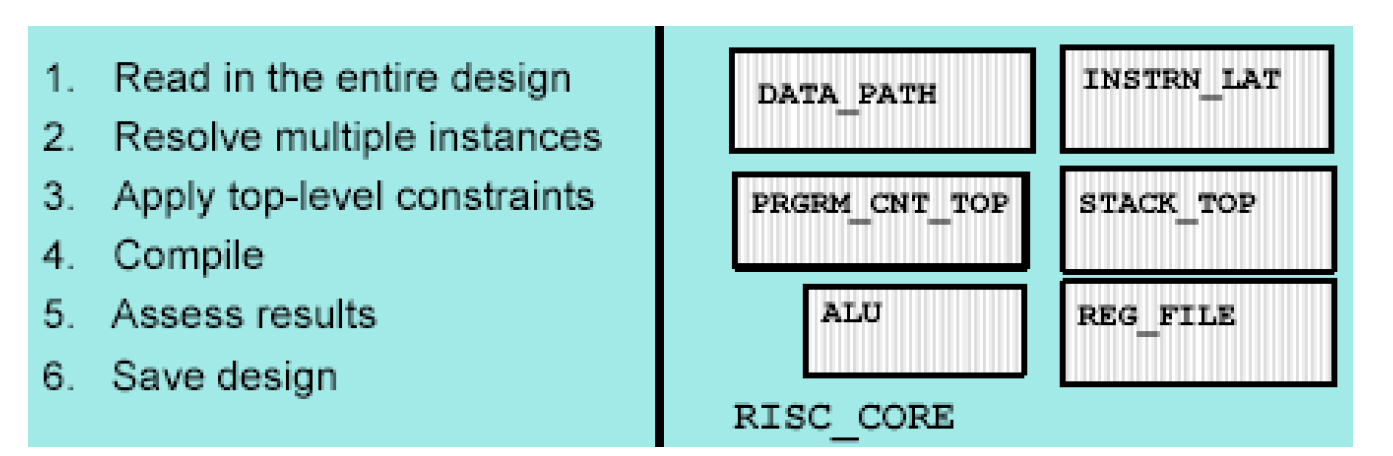
上图是自上而下编译方法的具体步骤,可以看出假如顶层设计是RISC_CORE这个模块,则先直接将它读入,然后处理多次例化的模块,施加顶层约束后就直接编译。它的代码基本上如下所示——
analyze -format vhdl {alu.vhd reg_file.vhd ... risc_core.vhd}
elaborate RISC_CORE
uniquify
source scripts/top_level.tcl
compile
report_constriant -all
write -format ddc -hierarchy -output mapped/RISC_CORE.ddc
quit
自上而下的编译方法有一个明显的优点,即它使得设计者无需考虑各个子模块之间的依赖关系,也就不需要制定子模块之间的时序和负载预算,这一切都由Design Compiler自动考虑。另外,使用这种方法也使得设计者编写脚本变得简单,维护起来也比较方便。
在介绍自上而下的编译方法的时候,我们还要顺便提及DC编译的一种模式——Simple Compile Mode(简单编译模式)
这种模式在设计没有严格的约束的情况下能取得较快的编译速度,另外多例化模块的处理也自动进行。下面是RISC_CORE的Simple Compile Mode脚本——
analyze -format vhdl {alu.vhd reg_file.vhd ... risc_core.vhd}
elaborate RISC_CORE
source scripts/top_level.tcl
set_simple_compile_mode true
compile
set_simple_compile_mode false
可见,使用这种模式省去了uniquify这句,同时编译之前要先设置一个变量set_simple_comile_mode
自下而上的编译方法其步骤如下图所示——
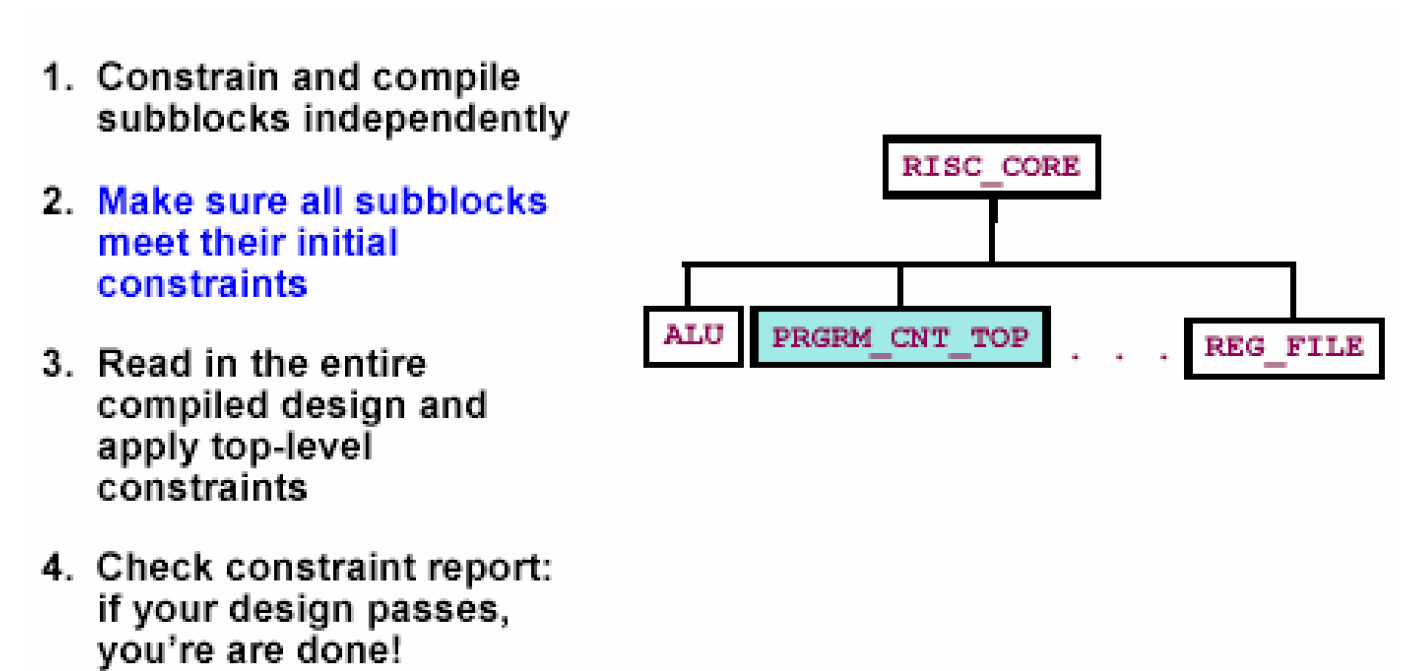
和前一种方法不同,自下而上的编译方法需要先单独编译各个子模块,在编译子模块的同时要考虑到与其它模块之间的关系,看是否满足约束,然后再读入顶层文件,施加顶层约束,顶层编译完成之后还必须看顶层约束是否满足。下面是单个模块编译的脚本——
analyze -format vhdl {PRGRM_CNT.vhd ... PRGRM_CNT_TOP.vhd}
elaborate PRGRM_CNT_TOP
compile
redirect ./reports/PRGRM_CNT_TOP.rpt {report_constraint -all}
write -format ddc -hierarchy -output mapped/PRGRM_CNT_TOP.ddc
下面是顶层模块编译脚本——
read_vhdl source/RISC_CORE.vhd
link
source Top_level.tcl
redirect ./reports/RISC_CORE.rpt {report_constraint -all}
write -format ddc -hierarchy -output mapped/RISC_CORE.ddc
从上面的过程不难看出Bottom-Up方法的一些特点——
优点是利用了”分而治之”的策略,这对于大型的不可能一次编译的设计是十分有用的;另外它也摆脱了Top-down方法的对工作站硬件条件的限制,使得大型设计也能在一般的机器上编译完成。
缺点是实现步骤比较多,尤其对各个模块之间的时序和负载预算要求很高,如果不注意会很容易造成违反。
综合上述两种方法,我们可以做一个小结:对于规模不算太大的设计,我们推荐使用Top-down的编译方法,这样可以在不长的时间内得到满意的结果。
对于其他需要Bottom-Up的设计,我们必须确认时序负载预算能很好的反映实际的工作情况。
3.4.2 第二次编译
第二阶段(Second-Pass)编译是指当第一阶段(First-Pass)编译出现违反之后,分析违反原因从而重新编译的过程,对应的还有第零(Zero-Pass)阶段编译。
关于第二阶段编译,前面的编译策略一章中有比较详细的介绍,前一章介绍的Top-down的第二阶段编译的步骤主要有——
- 检查模块划分
- 检查约束脚本
- 用更高的map_effort编译——
compile –inc –map_effort high
这一节中,我们主要讨论用Bottom-Up方法编译后出现违反的情况——
- 重新编译顶层模块
这种方法是在Bottom-Up出现顶层模块时序违反的情况下采用的,具体的命令为compile -top:
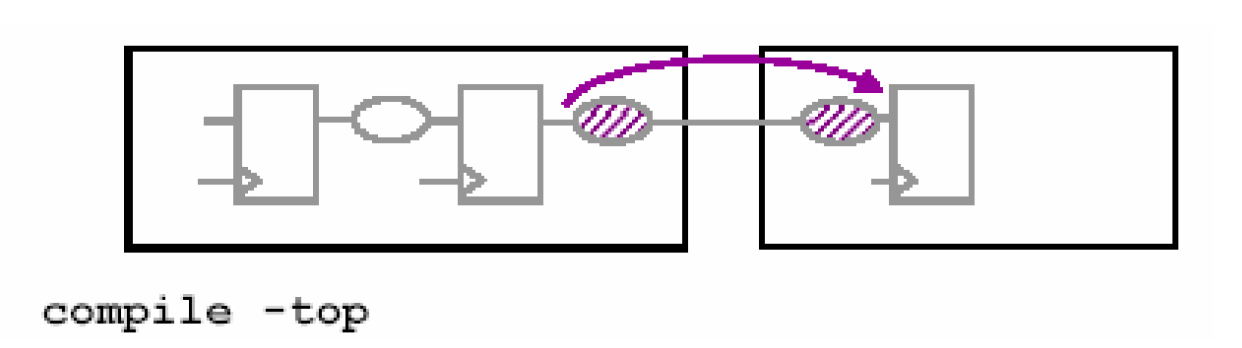
这个命令仅仅修正顶层子模块之间的路径,因此速度会比compile –inc更快。
设计预算对于Bottom-Up的方法来说是至关重要的,在预算的时候,我们都尽量能收紧(Tighten)每一个子模块时序、负载和驱动的预算,例如我们在最初介绍设计预算的时候,举的例子是给本模块留整条路径的40%,因此模块之间能够空出20%的裕量。在编译子模块的时候能尽量做到满足预算的要求。这样最后整合顶层设计的时候就不会出现大的问题。
如果出现问题了,一个方法就是调整预算脚本。看看施加的约束是否与综合后的电路相吻合。下一节,我们将介绍调整设计预算的一个很有用的命令——characterize。
3.4.3 Characterize
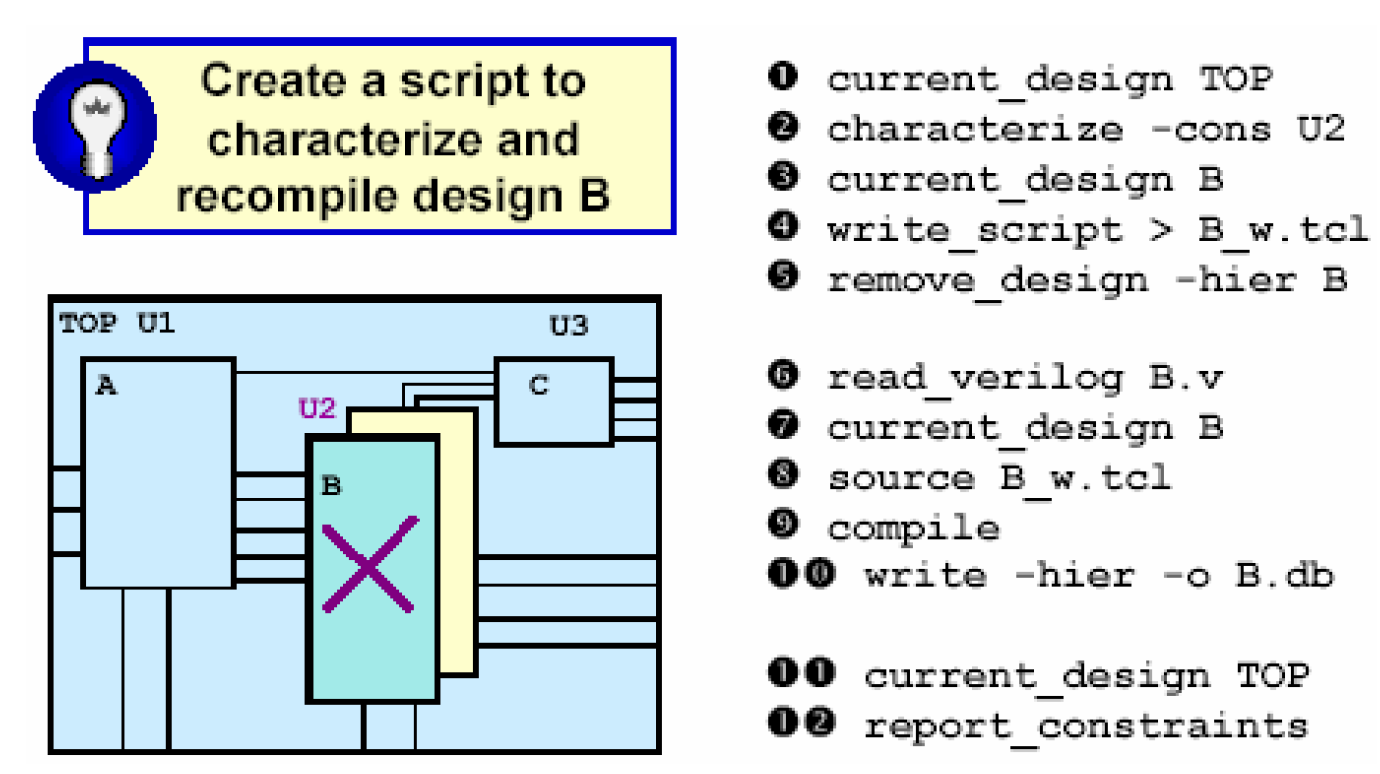
characterize这个命令用于映射到门级的子模块,作用是计算出该子模块周围的环境(延时、负载和驱动),并将得到的实际值作为该子模块的新的约束。如下图一个例子——
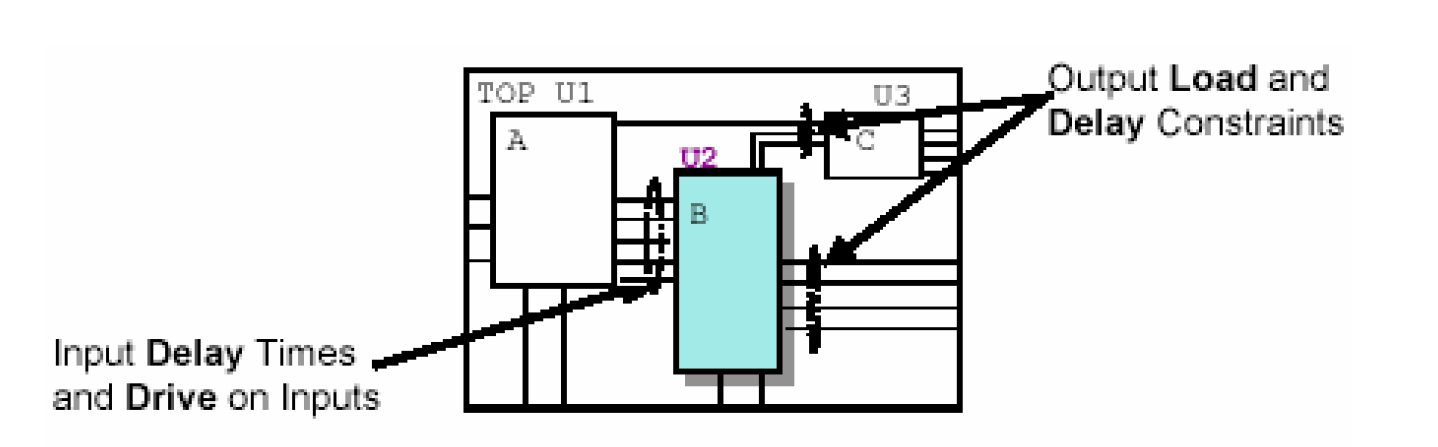
current_design TOP
characterize -constraints [get_cells U2]
current_design B
compile -inc -map high
由于整个设计已经映射到了门级,因此这个例子可以计算出子模块U2周围的输入输出延时、输入驱动和输出负载的实际值。然后将这些实际值施加在U2模块中,作为U2的新的约束。这种方法有点类似于给U2的周围照了一张照片。U2施加了新的约束之后,就可以在这个基础上做一次高级别的编译。
通过write_script命令,我们可以看到characterize之后到底照下了哪些信息——
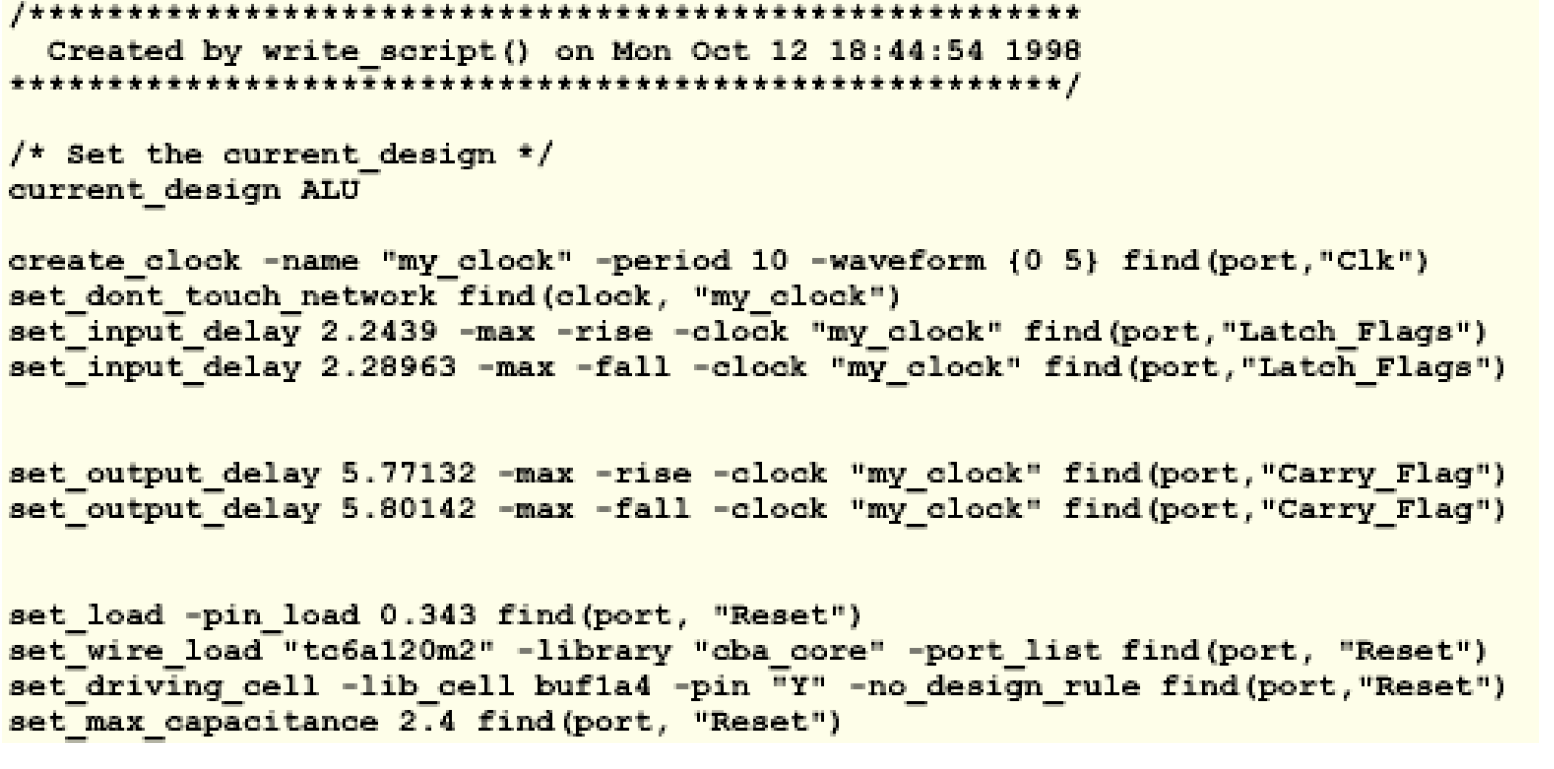
characterize给我们提供了一种比较好的第二次编译的方法,加入一个子模块所占的延时很重,就可以在保持其他模块不动的情况下将这个子模块重新编译一次,当然重新编译可以从HDL代码开始,下面是一个例子——
这个例子和前一个例子的不同在于,它没用compile –inc high,而是直接将它从内存中删除,读入它的源文件重新编译,这样可以取得较上一种方法更好的结果。
characterize无疑向我们提供一种较好的子模块二次编译方法,但是同时它也有一定的局限性,在使用的时候务必要注意——
首先,它要求所有的模块必须映射到门级,这是使用characterize的一个前提。
其次,characterize只能一次对一个子模块使用,即给U2作characterize的时候U1和U3模块必须保持不变,否则U2得到的环境就不是确定的值。
再次,characterize将外界环境直接作为它的约束,这使得它和其他的子模块之间不存在任何裕量(margin),这些裕量全部被该子模块吸收。
4. 综合脚本实例
至此,要介绍的部分基本结束,这里附赠一套流片上验证过的综合脚本实例:
run_dc.tcl
# setup dc
source ./scripts/dc_setup.tcl
# read design
source ./scripts/dc_read_design.tcl
# define design environment
source ./scripts/dc_set_env.tcl
# set design constraints
source ./scripts/dc_set_cons.tcl
# synthesis and optimize design
source ./scripts/dc_syn.tcl
# analyze and resolve design problems
source ./scripts/dc_post_syn.tcl
dc_setup.tcl
set design_name ""
# standard cell library
set stdcel_libs "
../../lib/
"
# memory library
set memory_libs "
../../lib/
"
# ip library
set ip_libs "
../../lib/
"
set target_library "$stdcel_libs"
set link_library "* $target_library $memory_libs $ip_libs"
sh mkdir -p ./reports
sh mkdir -p ./outputs
set report_path "./reports"
set output_path "./outputs"
set_svf $output_path/${{design_name}}.svf
dc_read_design.tcl
analyze -f verilog -vcs "-f ../../prj/filelist.f"
elaborate $design_name
current_design $design_name
link
dc_set_env.tcl
set_operating_conditions "" -library ""
set_wire_load_model -name ""
set_wire_load_mode top
set_host_options -max_cores 16
set_dp_smartgen_options -all_options auto -optimize_for speed
set_critical_range 3 [current_design]
set_app_var enable_page_mode false
dc_set_cons.tcl
set sdc_path "../../src/sdc"
read_sdc "$sdc_path/${{design_name}}.sdc"
dc_syn.tcl
check_design > $report_path/check_design_before_compile.rpt
check_timing > $report_path/check_timing_before_compile.rpt
compile_ultra
compile_ultra -incremental
dc_post_syn.tcl
write_sdf -version 2.1 $output_path/${{design_name}}_post_dc.sdf
write -f ddc -hier -output $output_path/${{design_name}}_post_dc.ddc
write -f verilog -hier -output $output_path/${{design_name}}_post_dc.v
write_sdc $output_path/${{design_name}}_post_dc.sdc
report_constraint -all_violators -verbose > $report_path/constraint.rpt
report_qor > $report_path/qor.rpt
report_power > $report_path/power.rpt
report_area > $report_path/area.rpt
report_cell > $report_path/cell.rpt
report_clock > $report_path/clk.rpt
report_hierarchy > $report_path/hierarchy.rpt
report_design > $report_path/design.rpt
report_reference > $report_path/reference.rpt
report_timing > $report_path/timing.rpt
check_design > $report_path/check_design_post_compile.rpt
check_timing > $report_path/check_timing_post_compile.rpt
sdc
# Definition of Clock
set Tclk 20 ;#50MHz
set clk_name "clk"
set unc_perc 0.05
create_clock -name $clk_name -period $Tclk [get_ports clk]
set_clock_uncertainty -setup [expr $Tclk * $unc_perc] [get_clocks $clk_name]
set_clock_transition 0.4 [all_clocks]
# Set Ideal Network
set_dont_touch_network [get_ports clk]
set_ideal_network [get_port clk]
set_dont_touch_network [get_ports rst_n]
# Definition of IO
set_input_delay [expr $Tclk*1/5.0] -clock $clk_name [all_inputs]
remove_input_delay [get_ports clk]
set_output_delay [expr $Tclk*1/5.0] -clock $clk_name [all_outputs]
# Other Constraint
set_max_transition 0.6 [current_design]
set_max_fanout 64 [current_design]
set_max_capacitance 2 [current_design]
set_input_transition -max 0.5 [all_inputs]
set_load 2 [all_outputs]
set_max_leakage_power 0
set_max_area 0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号