大模型的推理加速综述
大模型的推理加速综述
这次在CCF Chip会议还听到了许多对于大模型的研究报告,感觉非常有趣,现就几个比较有趣的技术点来阐述一下大模型推理加速时的细节问题。这里姑且对量化稀疏等基础通用方法不作太多论述,更多集中在大模型推理本身的一些有趣的加速技术上。
重点关注三个重要技术,Prefill & Decode;KV Cache以及并行推理。
Prefill & Decode
对于大模型来说,从技术上将其分为两个Phase,可以实现更高效的推理。具体来说,研究者们发现[1],对于一个完整的推理过程来说,从过程上实际上可以区分为Prompt phase和Token generation phase,前者需要处理一大长短的用户输入(Prompt),后者则是Token by token的挨个产生输出,如下图所示:
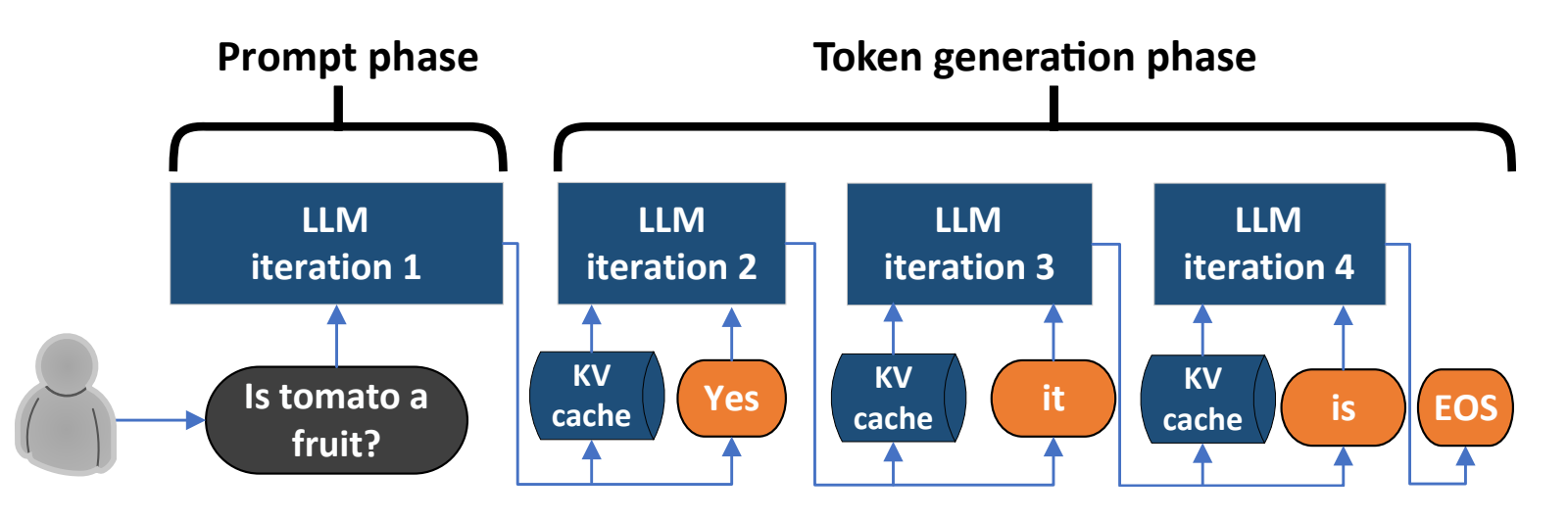
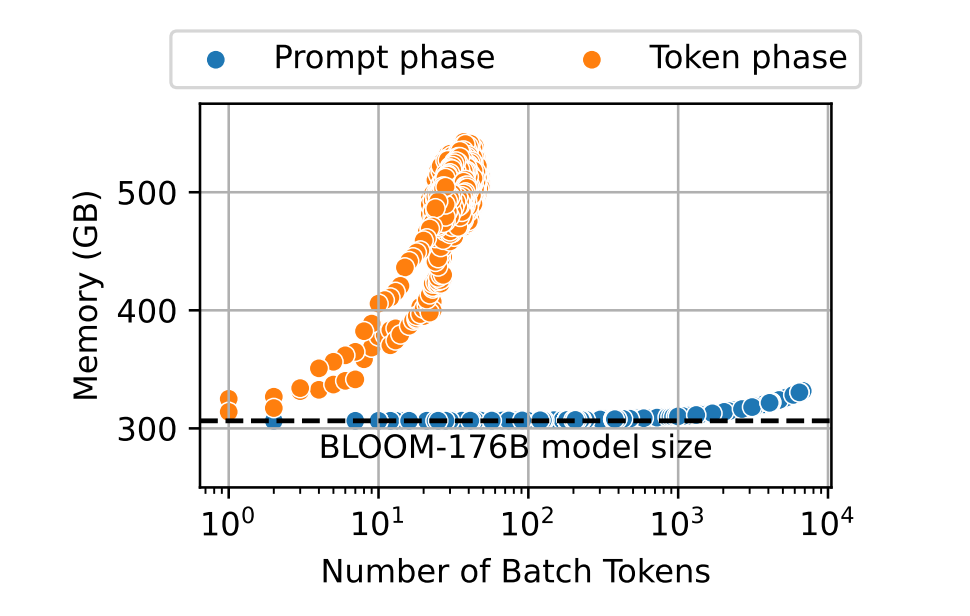
两个Phase的目标区别导致其访存和访存特性上展现出极大的差距,以下图为例,从访存角度来说Token phase的访存需求量远大于Prompt phase,在Batch Tokens接近\(10^2\)时,Token phase的访存量达到了接近Prompt phase的两倍。
而对于计算来说,情况完全相反,Prompt phase的Throughput远超Token generation phase。
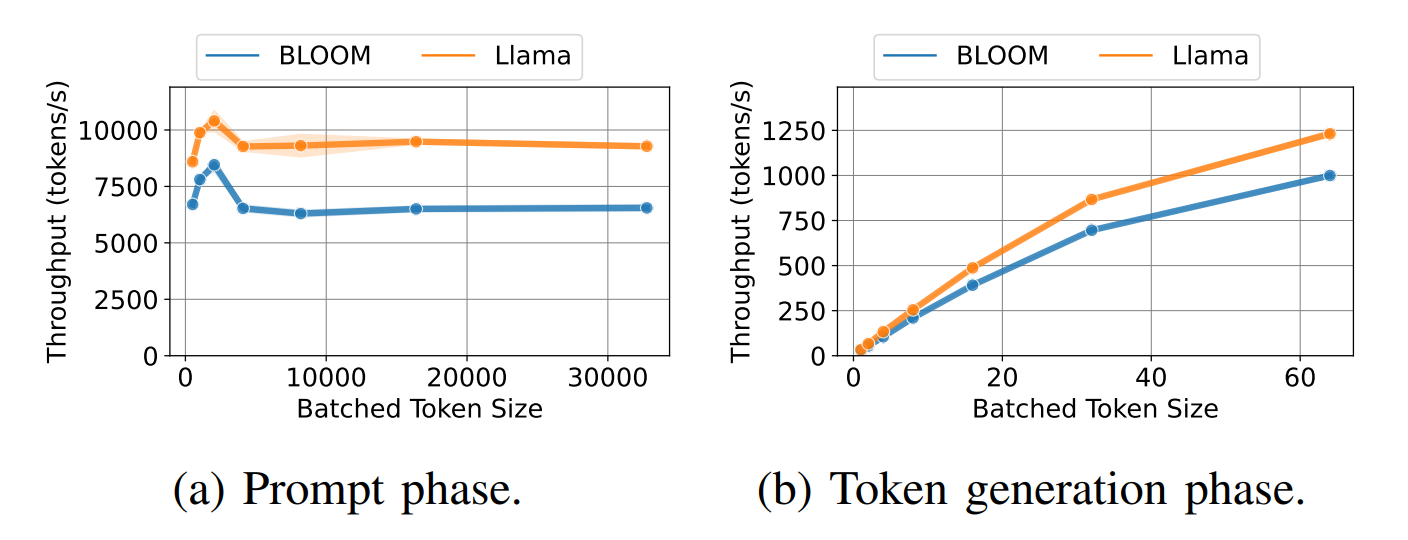
因此可以看出尽管归属于同一个任务,但两者在访存和计算特性上区别是很大的,对于Prompt phase来说是典型的计算受限场景,计算的瓶颈占据主导。而到了Token generation phase,就是典型的访存受限场景,访存的瓶颈占据主导。
这里Prompt phase也可以被称为Prefill,即预填充(大模型计算并存储原始输入token的KV Cache,并生成第一个输出token),而Token generation phase被称为Decode,即解码(大模型利用KV Cache逐个输出token,并用新生成的token的K,V(键-值)对进行KV Cache更新)。
理解了这两个Phase的特性之后,我们就可以通过合理的分配计算与访存资源来实现高效的大模型推理。
KV Cache
在讲Prefill & Decode时我们提到了KV Cache,这也是大模型推理加速中的一项非常重要的技术。
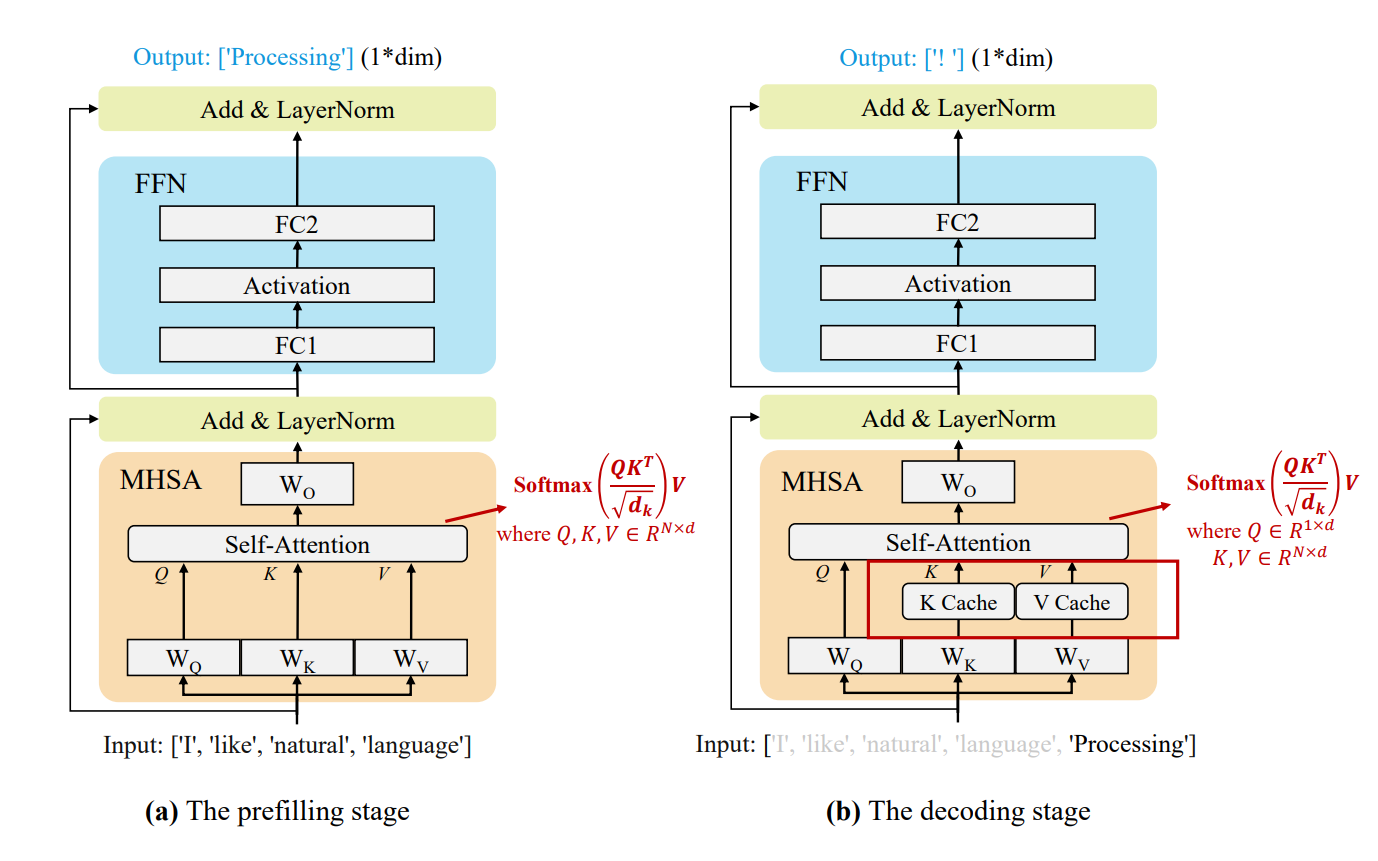
KV Cache基于的原理其实非常简单,这里回顾一下注意力机制的公式:
对于Decode阶段来说:
由于大模型本身的自回归结构,在每次计算一个新token时,都需要用到前文的Key和Value向量,但由于token是一个一个生成的,所以实际上我们并不需要每一次都计算所有token的向量,而是可以对已经生成好的Key和Value做复用。这样可以减少大量的计算开销。
这种缓存要复用的Key和Value值的技术就是KV Cache,KV Cache仅在每次算一个新的token时做更新(当然\(q\)因为本身就不涉及记忆,所以也不存在Q Cache的概念)。
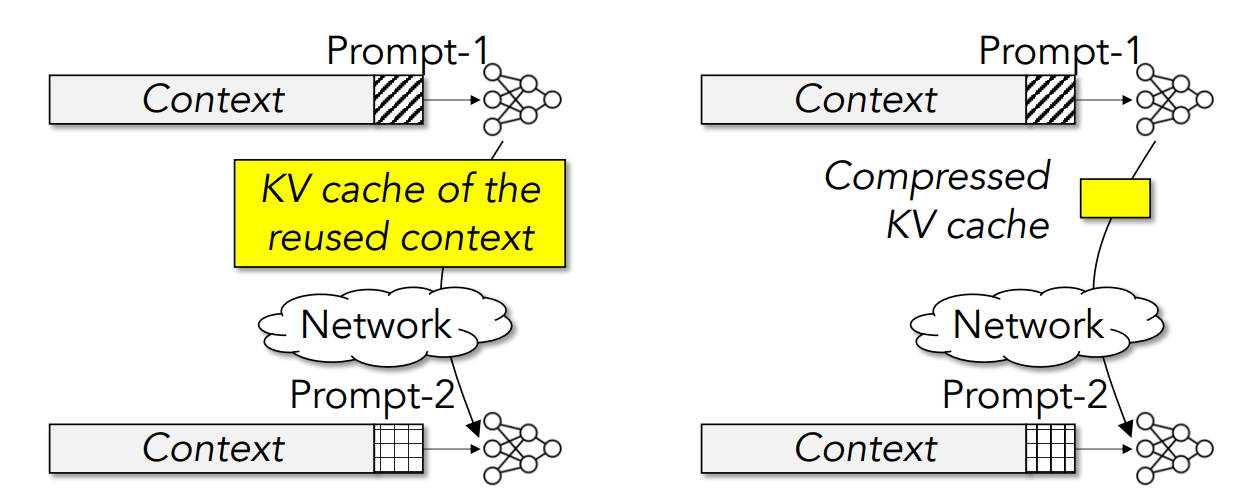
KV Cache的优化现在也是研究者们关注的热点,例如研究如何对KV cache进行压缩以减小存储开销以及降低需要通信时的网络传输开销[2]。
并行推理
并行推理用于实现在多个设备节点上并行运行大模型推理以提供加速,现在可以分类为三种经典方法:数据并行[3],模型并行[4]和流水线并行[5]。
数据并行方法的思路是将大的数据集切分为小的batch,分散到独立运行模型的多个节点上,再将结果汇总。其特点是结构简单,但是限制了模型的参数量不能够超过单个节点的容量上限。
模型并行方法的思路是对于一个大模型,将其中无法容纳在单个节点上的大型模型层或模块分散到多个节点运行。其特点是可以显著减少单个节点的容量/计算需求,但实现上相对复杂。
流水线并行方法的思路是将同一个模型的不同层次分散到不同的节点,以流水线的形式进行并行工作,这样可以在高效通信的同时处理大规模模型,但是流水级之间的计算时间和通信时间需要精确控制。
在实际应用中三种并行方法往往相互灵活组合。
总结
大模型本身的经典推理加速技术对于应用于大模型推理的存算架构设计有很强的指导意义,例如Prefill&Decode两阶段的划分,意味着架构要具备计算与访存的资源分配能力,KV Cache需要在芯片架构上做出专用的结构以支持,而三种并行推理手段要求芯片在数据流分配与控制上要具有灵活性。
参考文献
Patel, P., Choukse, E., Zhang, C., Shah, A., Goiri, Í., Maleki, S., & Bianchini, R. (2024). Splitwise: Efficient generative LLM inference using phase splitting. https://arxiv.org/abs/2311.18677 ↩︎
Yuan, J., Liu, H., Shaochen, Zhong, Chuang, Y.-N., Li, S., Wang, G., Le, D., Jin, H., Chaudhary, V., Xu, Z., Liu, Z., & Hu, X. (2024). KV Cache Compression, But What Must We Give in Return? A Comprehensive Benchmark of Long Context Capable Approaches. https://arxiv.org/abs/2407.01527 ↩︎
Li, S., Zhao, Y., Varma, R., Salpekar, O., Noordhuis, P., Li, T., Paszke, A., Smith, J., Vaughan, B., Damania, P., & Chintala, S. (2020). PyTorch Distributed: Experiences on Accelerating Data Parallel Training. https://arxiv.org/abs/2006.15704 ↩︎
Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., & Catanzaro, B. (2020). Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. https://arxiv.org/abs/1909.08053 ↩︎
Huang, Y., Cheng, Y., Bapna, A., Firat, O., Chen, M. X., Chen, D., Lee, H., Ngiam, J., Le, Q. V., Wu, Y., & Chen, Z. (2019). GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. https://arxiv.org/abs/1811.06965 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号