DRAM PIM综述
DRAM PIM综述
简介
前不久去上海参加了CCF Chip会议,听到了一些ISCA上关于DRAM PIM的工作,感觉非常有趣。ISSCC上除了DRAM PIM,还能见到很多eDRAM CIM类的工作,但是大体思路和目前架构那边做的DRAM PIM的思路差别还是挺大的,eDRAM主要还是片上集成,DRAM是单独的内存。从设计的角度来说主要的区别集中在电路的修改程度上,I会上的eDRAM CIM工作往往涉及到了对存储阵列的修改(存储单元或驱动电路)[1][2],而DRAM PIM,无论是商业产品的UPMEM[3],Samsung的HBM-PIM[4],SK Hynix的AiM[5],还是学术界的DRAM PIM工作[6][7],主要的思路是以类似近存计算的模式,在不修改DRAM存储本身结构的基础上,在DRAM Bank外集成计算单元。
这里简单讨论一下DRAM PIM的一般范式,目前面对的一些challenge,以及我对DRAM PIM的一些看法。
DRAM PIM的范式
在PIM的做法上大家大同小异,都是DRAM Bank旁边耦合计算单元,以Samsung的HBM-PIM为典型来介绍,这里用Samsung自己酷炫的图:
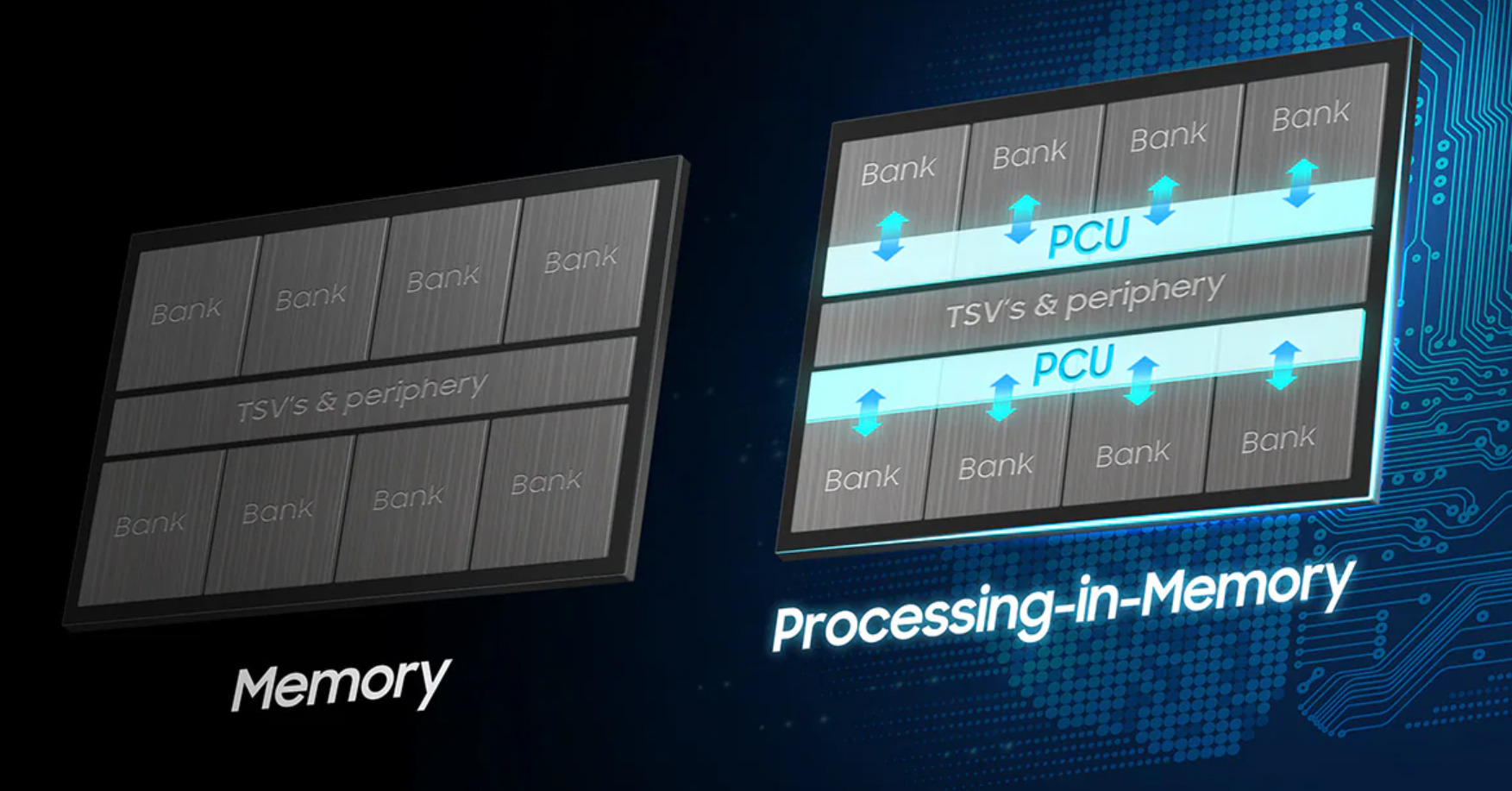
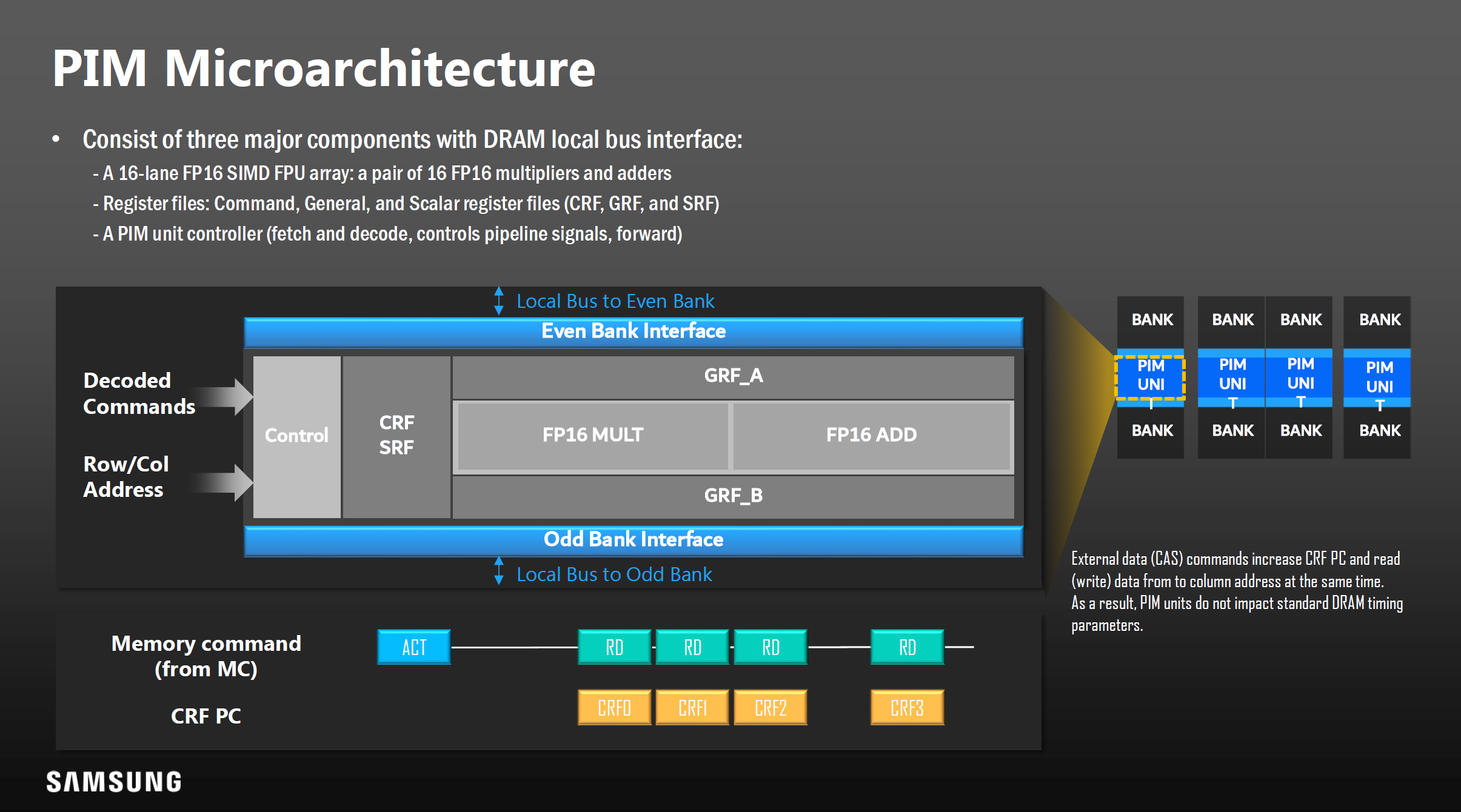
下到具体技术上来说,其实也并无神秘之处,在PIM Unit中实际上是一个究极简化的小"CPU",包含了取指译码的控制器,寄存器,以及FP16格式的SIMD乘加单元,麻雀虽小五脏俱全。
并采用尽可能精简的RISC指令集:
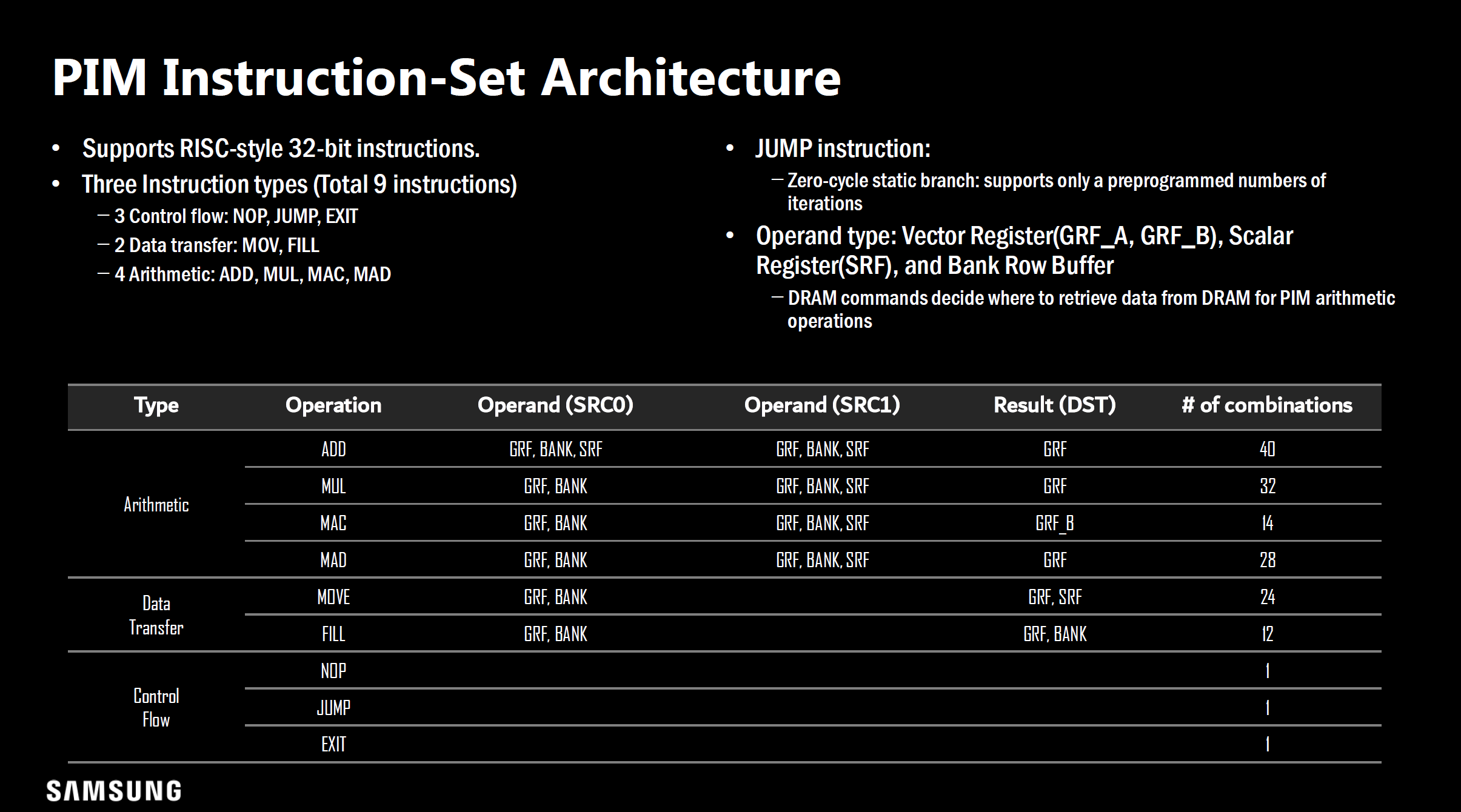
尽管各家在处理单元的具体设计上略有差异(例如SK Hynix的处理单元由乘法器和加法树构成,并插入了激活函数单元),以及对应的ISA上的差异,但整体上展现的思想相同。
DRAM PIM的挑战
总体上来看,DRAM PIM面临的挑战集中在架构应用级,因为电路结构本身已经相对成熟,工艺方面Samsung和HK Hynix都没有透露太多DRAM和逻辑工艺集成的问题(I会上有人现场提问,结果报告人支支吾吾的说不清楚糊弄过去了)。
两个可以思考的切入点分别是DRAM PIM如何良好的融入当前计算机体系结构中并发挥良好性能,以及DRAM PIM本身在面对复杂的应用负载时可能还有哪些不足。
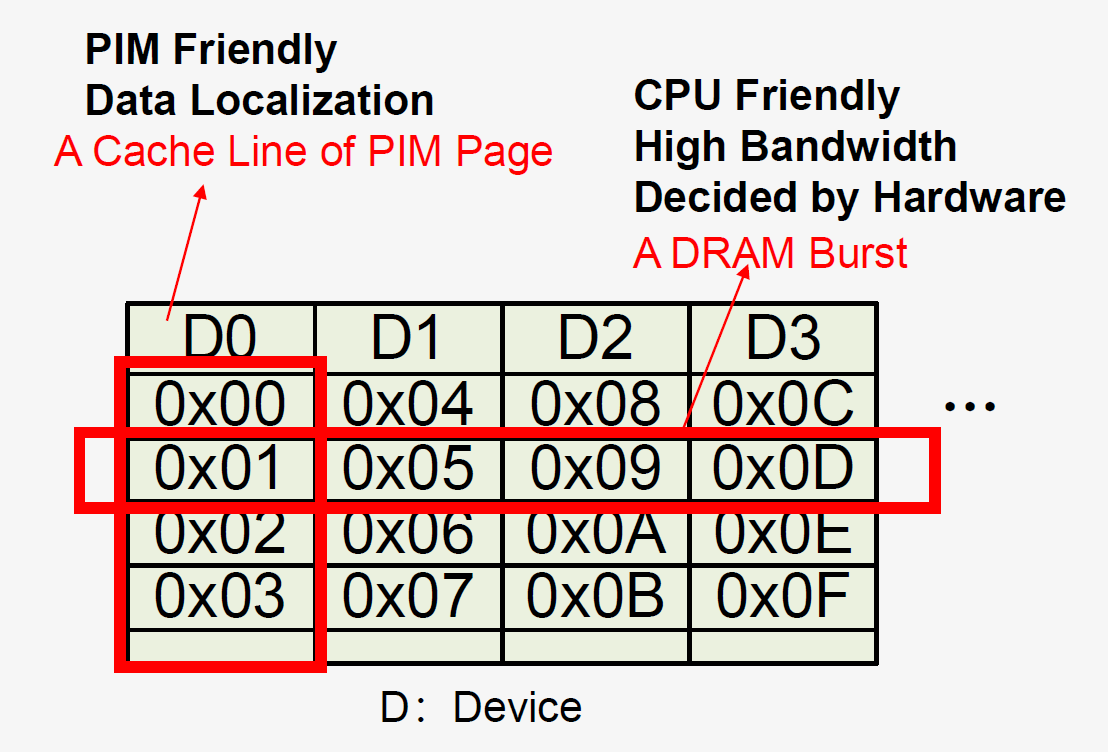
从当前学术界的研究来看,以今年ISCA会议上的两个工作为例,分别研究了DRAM PIM如何设计与CPU统一的内存空间[6:1],以及DRAM PIM如何优化来解决跨Bank数据交互需求[7:1]。前者提出的主要挑战是,CPU为了访存带宽,倾向于将数据在不同的Bank中做读写,从而利用到多个Bank带来的带宽提升,但DRAM PIM想要高效计算则极度依赖数据的集中(是要乘加的相关数据集中在同一个Bank内),如果用两个分立的DRAM空间分别满足CPU和PIM的需求,那么DRAM空间之间仍然需要进行数据搬运,不符合PIM的初衷。因此有必要提出一个统一的存储空间来满足两边的差异化需求,具体的实现上,这个工作通过软件和硬件手段,对CPU到DRAM的地址映射进行了重排,当CPU写入到PIM的地址空间时,CPU仍然是对分散的Bank做读写,但从单个Bank内部来看,数据具有集中性,如下图所示:
第二个工作提出的挑战是,对于特定任务(如需要大量数据Gather或Scatter的应用),在当前PIM结构下,当不同Bank之间的数据需要交互时,由于Bank之间缺少通信方式(实际上从目前PIM的设计上来看,处理单元只能简单的进行所属Bank和处理单元内部寄存器之间的数据交互),需要CPU作为中介来进行数据搬运,导致额外的开销。因此他们提出了一种”桥“电路来实现同一Rank下,不同DRAM Bank之间的数据交互能力,这个交互不需要CPU作为中介,可以直接在Rank内部就完成各个Bank之间的数据交互。
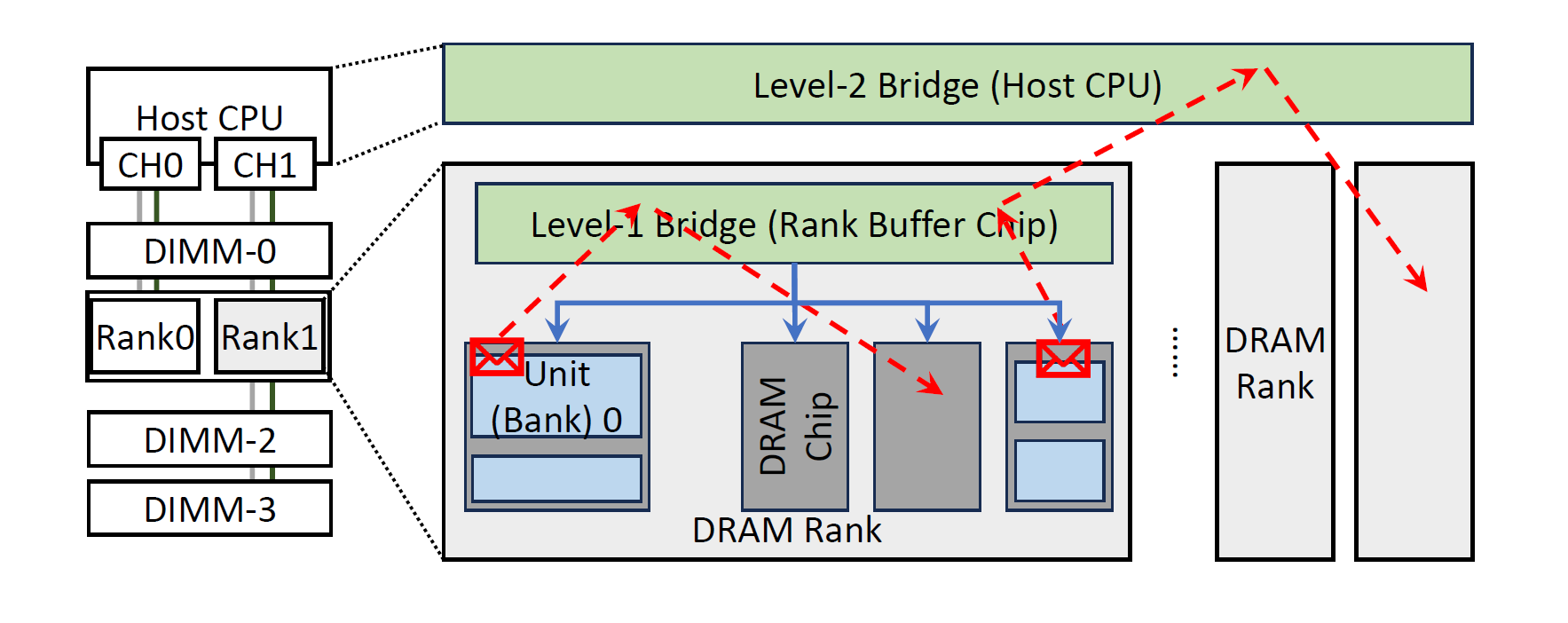
这里只是以这两个工作作为例子。实际上DRAM PIM也仍处于发展阶段,从最开始提出的两个切入点还能衍生出许多的挑战和问题。
我对DRAM PIM的思考
DRAM PIM目前来看是所有CIM类应用中最”落地“的方案,其思路值得学习。第一个可以学习的点是DRAM PIM对内存阵列保持不动,采用类似于近存的模式做实现,这样做的好处有二,一个是可以直接复用成熟的存储器电路结构,不需要像修改存储单元或外围电路的其他方案一样需要大动干戈,第二个是存储器本身作为memory的行为对整体的计算机体系结构来说是没有变化的,这样融入现有体系结构的成本也大大降低。实际上目前的SRAM CIM可以看到类似的感觉,TSMC的Digital SRAM CIM的思路就是将SRAM阵列切成小Bank然后将计算单元耦合在Bank旁边:
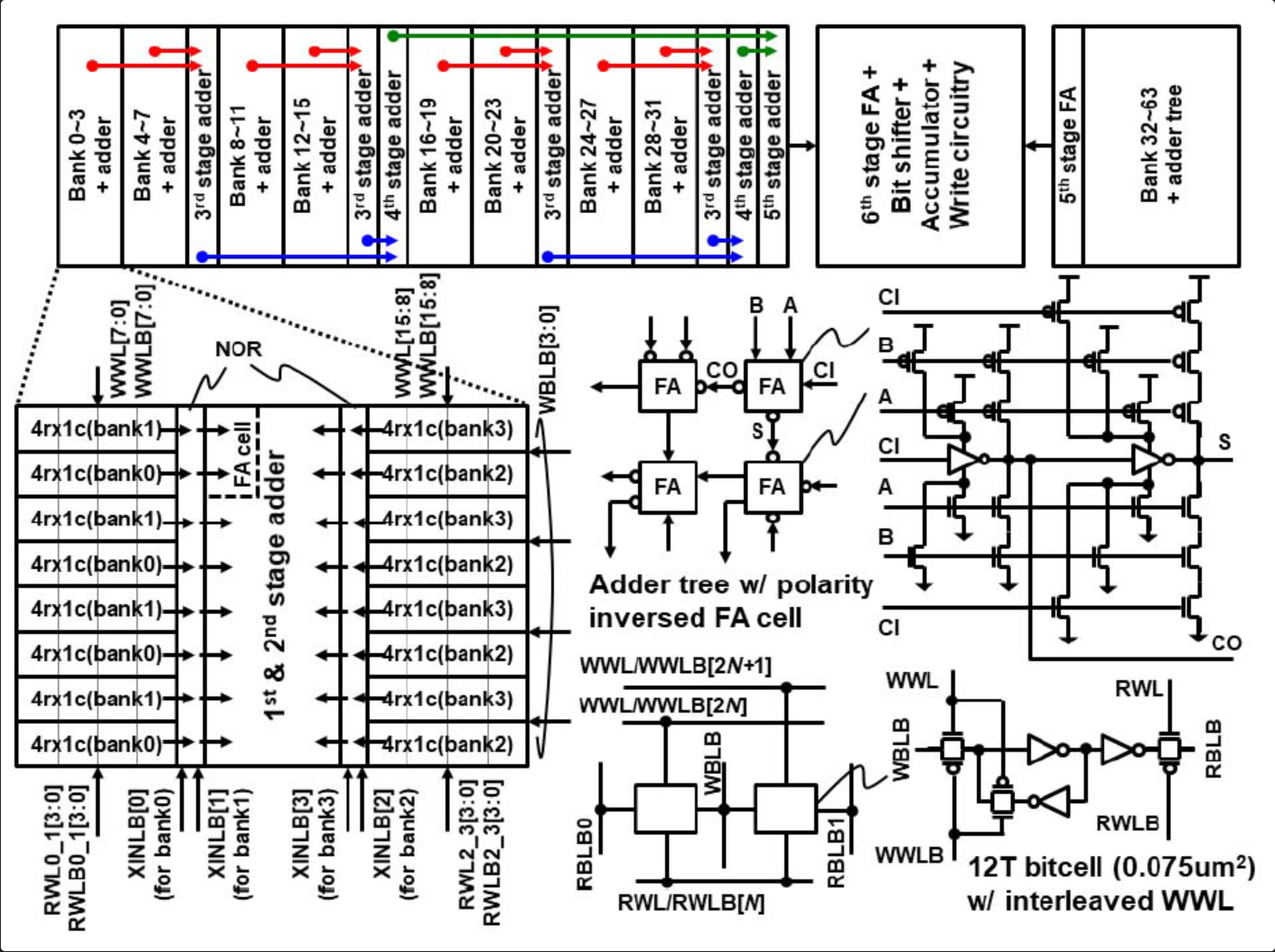
当然DRAM PIM的处理单元的可编程性在SRAM CIM上是否适用是另一个问题,毕竟Bank的尺寸规模上有很差的差距,处理单元如果太庞大,甚至远超了Bank,那也是不合理的。
另外DRAM PIM所碰到的问题也是其他方案可以吸收借鉴的,之前所说的如何良好的融入当前计算机体系结构中并发挥良好性能以及面对复杂的应用负载时可能还有哪些不足是所有方案都在面对的问题,只是由于hierarchy不同所以具体的问题会有所区别。
而对于DRAM PIM做调研的时候,我个人的感受是,实际上现在基于不同存储介质的CIM之间更多是合作而非竞争的关系,由于所处存储层级不同,具备特性也不同,我们实际上大可在不同的memory hierarchy中都使用CIM方案,就像SRAM,DRAM,Flash在过去的计算机发展过程中达成的和谐一样。
参考文献
Y. He et al., "34.7 A 28nm 2.4Mb/mm2 6.9 - 16.3TOPS/mm2 eDRAM-LUT-Based Digital-Computing-in-Memory Macro with In-Memory Encoding and Refreshing," 2024 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2024, pp. 578-580, doi: 10.1109/ISSCC49657.2024.10454323. ↩︎
S. Kim et al., "16.5 DynaPlasia: An eDRAM In-Memory-Computing-Based Reconfigurable Spatial Accelerator with Triple-Mode Cell for Dynamic Resource Switching," 2023 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2023, pp. 256-258, doi: 10.1109/ISSCC42615.2023.10067352. ↩︎
J. Gómez-Luna, I. El Hajj, I. Fernandez, C. Giannoula, G. F. Oliveira and O. Mutlu, "Benchmarking Memory-Centric Computing Systems: Analysis of Real Processing-In-Memory Hardware," 2021 12th International Green and Sustainable Computing Conference (IGSC), Pullman, WA, USA, 2021, pp. 1-7, doi: 10.1109/IGSC54211.2021.9651614. ↩︎
Y. -C. Kwon et al., "25.4 A 20nm 6GB Function-In-Memory DRAM, Based on HBM2 with a 1.2TFLOPS Programmable Computing Unit Using Bank-Level Parallelism, for Machine Learning Applications," 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2021, pp. 350-352, doi: 10.1109/ISSCC42613.2021.9365862. ↩︎
S. Lee et al., "A 1ynm 1.25V 8Gb, 16Gb/s/pin GDDR6-based Accelerator-in-Memory supporting 1TFLOPS MAC Operation and Various Activation Functions for Deep-Learning Applications," 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 1-3, doi: 10.1109/ISSCC42614.2022.9731711. ↩︎
Yilong Zhao, Mingyu Gao, Fangxin Liu, Yiwei Hu, Zongwu Wang, Han Lin, Ji Li, He Xian, Hanlin Dong, Tao Yang, Naifeng Jing, Xiaoyao Liang, Li Jiang, UM-PIM: DRAM-based PIM with Uniform & Shared Memory Space, ISCA 2024 ↩︎ ↩︎
Boyu Tian, Yiwei Li, Li Jiang, Shuangyu Cai, and Mingyu Gao, "NDPBridge: Enabling Cross-Bank Coordination in Near-DRAM-Bank Processing Architectures," in Proceedings of the 51st International Symposium on Computer Architecture (ISCA), pp. 628-643, Buenos Aires, Argentina, Jun 2024. ↩︎ ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号