SRAM CIM的后续发展之我见
SRAM CIM的后续发展之我见
目前CIM技术已经应用在诸多存储器上,如主流存储器SRAM,DRAM,Flash,以及新型NVM,如RRAM,PCM,FeRAM,MRAM等。其中SRAM CIM是一个进展较快的方向,主要受益于其工艺上的成熟性,与CMOS先进工艺的高度兼容,并且SRAM的高速度也是SRAM CIM性能上的一个重要优势。
工业界对于SRAM CIM技术的关注度也是很高的,TSMC已经连续四年在ISSCC和VLSI上介绍先进的Digital SRAM CIM工作[1][2][3][4][5],使用Digital CIM的动机被阐述的非常清楚,对于目前日益增长的AI计算需求来说,与先进工艺的兼容性与高性能是需要重点关注的特性,而在先进工艺节点下,Analog CIM方案受到器件匹配,二级效应,寄生参数等诸多限制因素。因此他们在Digital CIM方案上持续深耕,并与MediaTek合作发表了一个用于超分辨率应用的芯片[6]。
我在之前的博客中谈过,采用先进工艺与否,以及应用对位数和精度上的要求,是判断Analog CIM和Digital CIM哪个Prefer的主要分野。对于不需要先进工艺且对位数和精度要求低的应用,如边缘端的一些IoT应用,Analog CIM是更好的选择,而对先进工艺或位数和精度要求高的应用,如目前的LLM等,Digital CIM是更好的选择,在两者的边界上,Hybrid CIM是可以考虑的重要方案,当然现在的Analog CIM本身也在引入Accumulator,Adder Tree之类的部件来实现某种意义上的Hybrid,另外依据高低位,或计算环节对最终计算精度的影响,来决定Digital和Analog的分配,也是Hybrid CIM设计的一个重要关注点[7][8][9]。
但回到SRAM CIM技术本身来说,作为一个尚未完全成熟的技术,目前我认为主要的限制来源于两个方面,一个是整体软硬件栈的不完善,另一个是SRAM的密度/容量限制。
先从软硬件栈的角度来说,软件上[10]为了与现有的成熟代码库兼容,需要对驱动层和中间层做出修改,以适配框架层进而支持应用层,幸运的是目前已经有一些开源编译栈来帮助减少这部分的造轮子工作量,如TVM:
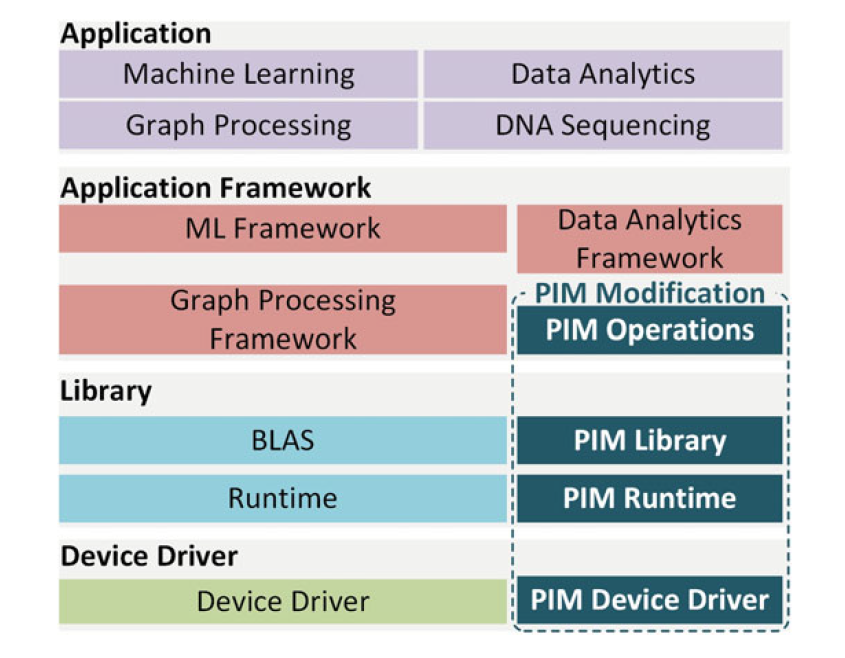
但硬件也需要对软件做出相应的适配,从目前大部分CIM的设计上来看,并没有从BLAS(基础线性代数程序集)的角度来反思CIM的结构设计,更多集中在GEMV和GEMM两类运算上,而转置,交换,加法,实数点积,求秩等操作并没有被纳入考量。当然,从专用性的角度,对于完全面向AI推理应用的CIM设计来说,GEMV和GEMM已经可以满足几乎全部的需求,但从长远来看,CIM想要面对未来增长的计算负载复杂度,解决功能上的局限性是一个非常重要的问题(当然难度也是显著的)。
而SRAM的容量/密度限制是另一个重要的问题,存算最初的动机就是尽可能的减少内存数据搬运,从而减少这部分带来的功耗,但从实际情况来看,目前发表的论文,其容量基本上限制在数十到数百Kb的量级,并不能看到大容量的SRAM CIM工作,这方面固然有芯片面积限制的因素(目前的论文还没有出现大型SRAM CIM芯片,基本都是几mm乘几mm的小芯片),但也是SRAM本身容量/密度限制的一个体现,因为即使是商用CPU/GPU,其片上Cache容量依旧不大,L1 Cache往往只有32KB或64KB,但L2和L3 Cache得容量扩张是迅速的,可以到数十M的量级。如果SRAM容量小,那么大批量的数据仍然需要流进/流出SRAM,这样以存算的初衷来说,实际上并没有达到目标。但SRAM本身结构带来的密度/容量限制,使得大容量的片上SRAM的实现并非易事。
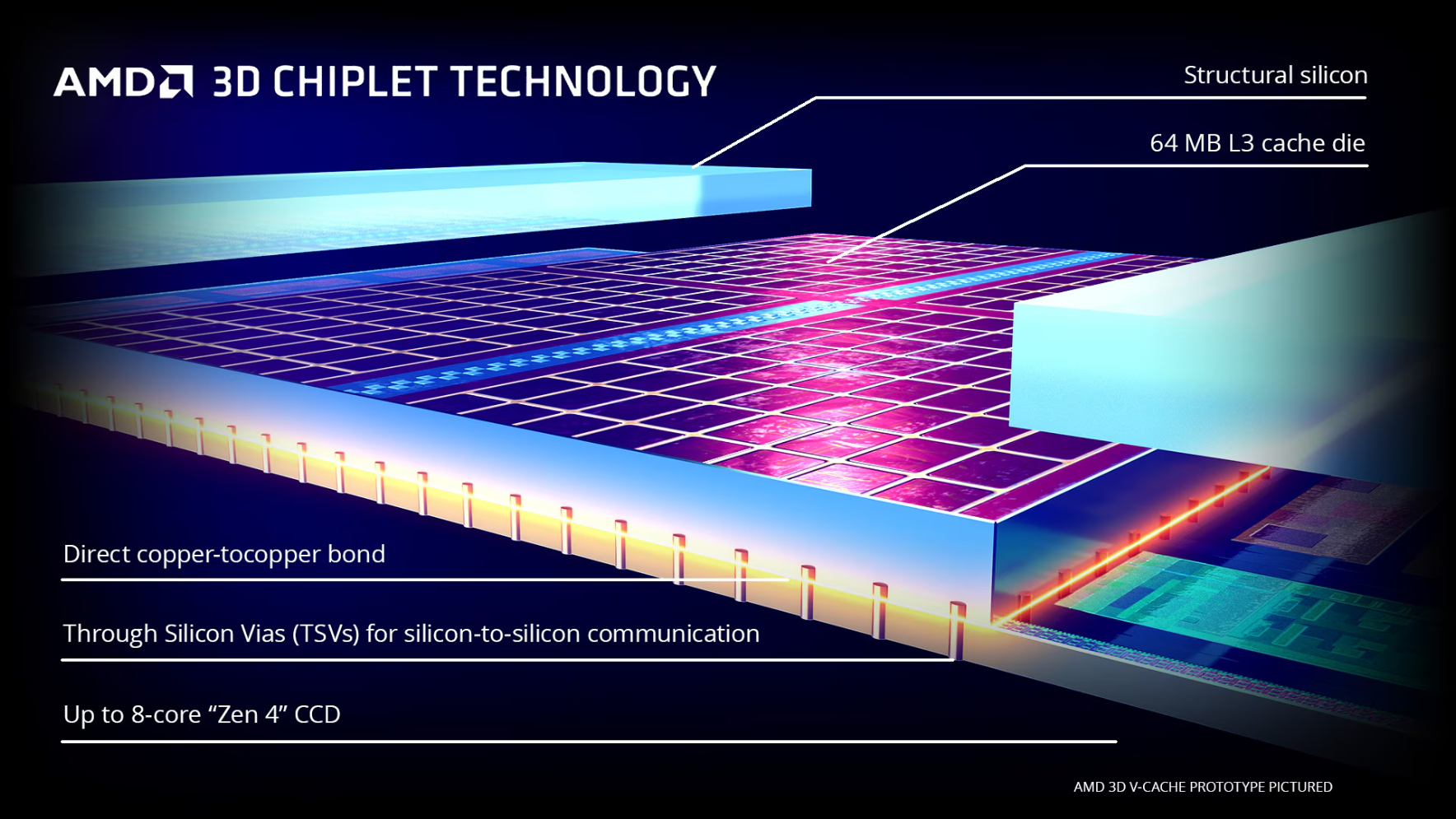
一个破局的角度是通过先进封装的方式,例如AMD的3D V-Cache的思路[11]。
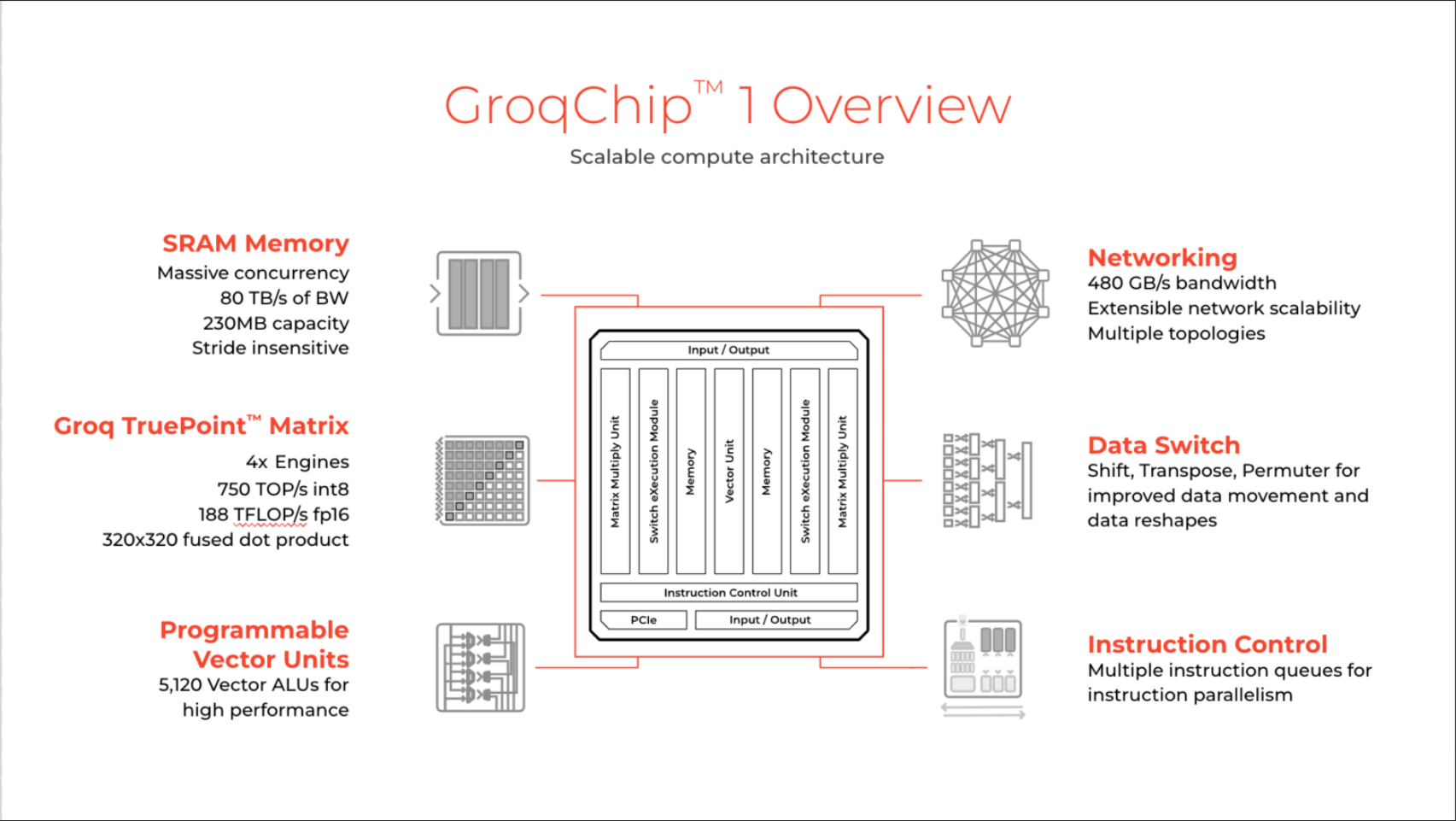
另一个是类似Cerebras,Dojo或者Groq一样,想尽一切方法榨干片上面积去堆SRAM容量,其他的设计部分为SRAM让道,采用完全偏向专用设计的思路。说到这里,我觉得Groq其实已经在采用类似于近存计算的思想设计芯片了。
综上所述,我想这是两条并行的路径,从短期的视角来看,SRAM CIM技术乘着AI的浪潮,通过专用化的方法提升容量,且只关注于AI运算所需要的算子进行设计,是一条清晰且行人繁多的宽阔大路。但从长期的视角来看,如果CIM技术想要拓宽应用,而并非只作为AI技术的一个子集,真正想要成为未来计算机体系结构经典技术的一份子的话,完整的对BLAS的硬件支持,以及通过先进封装之类的方式融入现有的memory hierachy是必要的,这是一条小路,但小路上也可能会有好的风景。
引用
Y. -D. Chih et al., "16.4 An 89TOPS/W and 16.3TOPS/mm2 All-Digital SRAM-Based Full-Precision Compute-In Memory Macro in 22nm for Machine-Learning Edge Applications," 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2021, pp. 252-254, doi: 10.1109/ISSCC42613.2021.9365766. ↩︎
H. Fujiwara et al., "A 5-nm 254-TOPS/W 221-TOPS/mm2 Fully-Digital Computing-in-Memory Macro Supporting Wide-Range Dynamic-Voltage-Frequency Scaling and Simultaneous MAC and Write Operations," 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 1-3, doi: 10.1109/ISSCC42614.2022.9731754. ↩︎
H. Mori et al., "A 4nm 6163-TOPS/W/b 4790-TOPS/mm2/b SRAM Based Digital-Computing-in-Memory Macro Supporting Bit-Width Flexibility and Simultaneous MAC and Weight Update," 2023 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2023, pp. 132-134, doi: 10.1109/ISSCC42615.2023.10067555. ↩︎
C. -F. Lee et al., "A 12nm 121-TOPS/W 41.6-TOPS/mm2 All Digital Full Precision SRAM-based Compute-in-Memory with Configurable Bit-width For AI Edge Applications," 2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), Honolulu, HI, USA, 2022, pp. 24-25, doi: 10.1109/VLSITechnologyandCir46769.2022.9830438. ↩︎
H. Fujiwara et al., "34.4 A 3nm, 32.5TOPS/W, 55.0TOPS/mm2 and 3.78Mb/mm2 Fully-Digital Compute-in-Memory Macro Supporting INT12 × INT12 with a Parallel-MAC Architecture and Foundry 6T-SRAM Bit Cell," 2024 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2024, pp. 572-574, doi: 10.1109/ISSCC49657.2024.10454556. ↩︎
M. -E. Shih et al., "20.1 NVE: A 3nm 23.2TOPS/W 12b-Digital-CIM-Based Neural Engine for High-Resolution Visual-Quality Enhancement on Smart Devices," 2024 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2024, pp. 360-362, doi: 10.1109/ISSCC49657.2024.10454482. ↩︎
A. Guo et al., "34.3 A 22nm 64kb Lightning-Like Hybrid Computing-in-Memory Macro with a Compressed Adder Tree and Analog-Storage Quantizers for Transformer and CNNs," 2024 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2024, pp. 570-572, doi: 10.1109/ISSCC49657.2024.10454278. ↩︎
Y. Yuan et al., "34.6 A 28nm 72.12TFLOPS/W Hybrid-Domain Outer-Product Based Floating-Point SRAM Computing-in-Memory Macro with Logarithm Bit-Width Residual ADC," 2024 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2024, pp. 576-578, doi: 10.1109/ISSCC49657.2024.10454313. ↩︎
P. -C. Wu et al., "A 22nm 832Kb Hybrid-Domain Floating-Point SRAM In-Memory-Compute Macro with 16.2-70.2TFLOPS/W for High-Accuracy AI-Edge Devices," 2023 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2023, pp. 126-128, doi: 10.1109/ISSCC42615.2023.10067527. ↩︎
J. Kim, B. Kim, and T. Kim, Processing-in-Memory for AI: From Circuits to Systems. Springer International Publishing, 2022. [Online]. Available: https://books.google.co.jp/books?id=S0V6EAAAQBAJ ↩︎
J. Wuu et al., "3D V-Cache: the Implementation of a Hybrid-Bonded 64MB Stacked Cache for a 7nm x86-64 CPU," 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 428-429, doi: 10.1109/ISSCC42614.2022.9731565. ↩︎



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具