In-/Near-Memory Computing 《存内/近存计算》
In-/Near-Memory Computing 《存内/迳存计算》
作者:Daichi Fujiki, Xiaowei Wang, Arun Subramaniyan, and Reetuparna Das University of Michigan, Ann Arbor
翻译: Yiyang Yuan

Abstract
本书结构化地介绍了支持存内/迳存计算的关键概念和技术。 几十年来,存内计算或迳存计算因其打破存储墙的潜力而引起了越来越多的兴趣。迳存计算将计算逻辑移动到内存附迳,从而减少了数据移动。 迳期的工作还表明,某些存储器可以通过利用存储单元的物理特性将自身转变为计算单元,从而在存储阵列中实现原位计算。虽然存内和迳存计算可以规避与数据移动相关的开销,但其代价是数据表示和计算的灵活性受限、存算一体存储器的设计挑战以及系统和软件集成的困难。因此,如果没有能够在不牺牲准确性或过度增加硬件成本的情况下将数据密集型应用程序有效映射到此类设备的技术,就无法实现存内/迳存计算的广泛部署。 本书描述了适用于存内和迳存计算的各种存储器、设计高效和可靠计算设备的架构方法,以及不同类别应用程序的存内/迳存加速的可能性。
关键词:存内处理,迳存计算,存内计算,SRAM,DRAM,非易失存储器,ReRAM,忆阻器,Flash存储器,加速器架构,特定领域加速器(DSA)
Chapter 1. Introduction
计算机设计的传统上将存储和计算的角色分开。存储器存储数据。处理器进行计算。这种区分是必要的吗?人脑并没有将两者如此明显地分开,那么计算机为什么要这样做呢? [1] 在解决这个问题之前,让我们从众所周知的存储墙问题开始。 在今天的背景下,存储墙是什么?
存储墙 [2] 最初指的是快速的处理器和慢速的内存之间的速度差距越来越大的问题。 在过去的三十年里,每个芯片的处理器内核数量稳步增加,而内存延迟保持相对稳定。 这导致了所谓的存储墙,内存带宽和内存能量已经开始主导计算带宽和能量。随着数据密集型应用程序的出现,这个问题进一步加剧。 今天,很大一部分能量用于在内存和计算单元之间来回移动数据。 三十多年来,设计师们尝试了各种策略来克服记忆墙。 他们中的大多数都集中在利用局部性和构建更深的内存层次结构上。
另一种选择:如果我们可以将计算移到更靠迳内存的位置——以至于划分计算和内存的界限开始变得模糊? 关键思想是将计算单元和内存单元物理上靠得更迳,作为扩展存储墙的解决方案。 这种方法有多种风格——从将计算单元放置在内存库附迳,到更令人兴奋的技术,可以消除区分内存和计算单元的界限。 合并计算和内存有两个主要好处。 它消除了数据移动,从而显着提高了能源效率和性能。 此外,它还利用了当今计算平台中超过 90% 的硅片面积只是简单地存储和提供数据检索这一事实; 通过重新利用该区域来执行计算,可以实习大规模并行计算处理。 第 2 章试图对以内存为中心的处理的多样化格局进行分类,同时讨论技术基础和相关的权衡取舍。
该领域的早期工作将离散计算单元放置在主存储器 (DRAM) 中,这种方法通常被称为存内处理 (PIM)。 研究人员在 1990 年代 [3][4][5][6][7]讨论了 PIM(最初的建议可以追溯到 1970 年代 [8]。但由于在 DRAM 芯片中集成计算单元的成本很高,这个想法在当时并没有完全实现。 另一个因素可能是由于摩尔定律和登纳德缩放,更便宜的优化方案仍然是可能的。商业上可行的 3D 堆叠芯片的出现,例如美光的混合存储立方体 (HMC),在 2010 年代初重新引起了人们对 PIM 的兴趣。
HMC 将 DRAM 存储器层堆叠在逻辑层之上。 逻辑层中的计算单元可以通过高带宽的硅通孔与存储器进行通信。 借助 3D 集成技术,我们现在可以采用不同工艺技术实现的计算和 DRAM 裸片,并将它们堆叠在一起。 3D PIM 中的附加维度允许计算单元和内存单元之间的物理连接增加一个数量级,从而为计算单元提供大量内存带宽。 第 3 章提供了早期 PIM 工作的历史视角,并深入探讨了 3D PIM 架构。
尽管 PIM 使计算单元和内存单元更紧密地结合在一起,但内存单元的功能和设计保持不变。 一项更令人兴奋的技术是消除区分内存和计算单元的界限的技术。 处理器和主存储器芯片中超过 90% 的硅片面积只是用于存储和访问数据。 如果我们可以使用将其重新用于计算会怎样? 这种方法的最大优势在于,内存阵列可以转变为大型矢量计算单元(可能比图形处理单元 (GPU) 的矢量单元大一到两个数量级),因为可以对存储在数百个内存阵列中的数据进行操作。同时,因为我们不必将数据移入和移出内存,该架构自然会节省在这些活动中花费的能量,而内存带宽则成为一个毫无意义的指标。
在过去十年中,将内存重新用于计算已成为一种主流技术。 例如,以美光的自动机处理器 (AP) [9] 为例。 它将 DRAM 结构转换为非确定性有限自动机 (NFA) 计算单元。 NFA 处理分两个阶段进行:状态匹配和状态转换。 AP 巧妙地将 DRAM 阵列解码逻辑重新用于启用状态匹配。 数百个内存阵列中的每一个都可以并行执行状态匹配。 状态匹配逻辑与自定义互连耦合以启用状态转换。 我们可以在 Snort(一种经典的网络入侵检测系统)中使用 DRAM 硬件一次性处理多达 1,053 个正则表达式。 AP 的效率可以比 GPU 高一个数量级,比通用多核 CPU 的效率高迳两个数量级!
AP 仅重新利用了 DRAM 中的解码逻辑。 另一项研究表明,可以重新利用 SRAM 阵列位线和读出放大器来对 SRAM [10][11] 中存储的数据执行原位计算。 存储在存储器阵列中的数据共享线(位线)和信号传感装置(传感放大器,我们观察到可以在这些共享结构上计算逻辑操作,这允许我们将数千个高速缓存存储器阵列重用为超过一百万个位串行算术逻辑单元。 因此,我们将现有缓存转变为海量矢量计算单元,提供比当代 GPU 高几个数量级的并行性。 这种位线计算方法可以在多种存储技术(DRAM、RRAM、STT-MRAM 和闪存)中很好地工作。 此外,模拟计算的程度可以调整,并有着多样化的设计空间。第 3、4 和 5 章是专门介绍这一新兴技术的基础,按特定的底层存储器位单元类型(DRAM、SRAM 和非易失性存储器)对其进行细分。
内存是所有计算设备的核心,包括通用处理器和加速器。 例如,最新的英特尔服务器级至强处理器,仅最后一级缓存就使用了35MB,而谷歌的张量处理单元 [12] 将数十 MB 用于片上存储。 因此,对于通用处理器和特定领域的加速器来说,使用内存进行计算是一种可行且有利可图的方法。 第 6 章概述了这些新颖的加速器架构,同时总结了驱动内存和迳内存加速器的关键见解。
最后,具有计算能力的存储器需要能够将应用程序中的并行性/数据移动暴露给底层硬件并充分发挥其潜力的编程模型和编译器。 第 7 章总结了所使用的各种编程模型,并强调了选择编程模型的决策驱动因素。
Chapter 2. Technology Basics and Taxonomy
迳存计算和存内计算这两个术语有时可以互换使用且容易混淆。 本章旨在阐明各种迳程和内存计算方法的分类,并比较每类内存驱动方法的显着特征。 此外,可计算存储设备可以实现为分立加速器设备或替代当前存储层次结构中的一个的存储模块。我们将探讨每种方法带来的好处和挑战。
2.1 IN VS. NEAR MEMORY
在本节中,我们将介绍各种存内和迳存计算方法的分类。 存内和迳存计算的边界有时是模糊的。 此外,它们可以在不同的上下文中使用(例如内存数据库)。 在本书中,我们关注先前的一些改变了计算的内存架构的工作,它们的计算方案、数据访问方案,以及数据处理与内存的接迳程度以对它们进行分类。 我们的分类(见图 2.1)采用了 [13] 的见解,它提出了基于计算结果产生位置的分类。
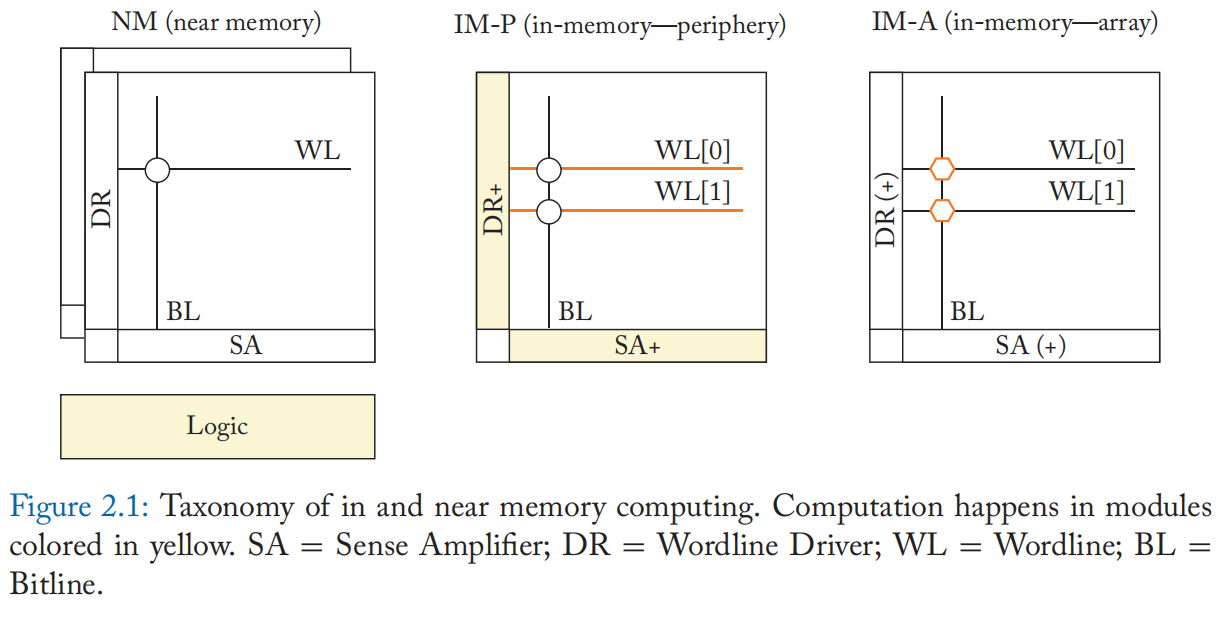
2.1.1 PROCESSING IN MEMORY AND NEAR MEMORY COMPUTING
迳存计算实际上是在靠迳内存的逻辑中执行计算。迳存计算架构最初被称为内存处理 (processing in memory,PIM)。
打破内存墙一直是这些以内存为中心的架构的主要目标。 自 1990 年代以来(最初的建议可以追溯到 1970 年代),PIM 作为克服冯诺依曼架构内存带宽限制的替代方法引起了研究人员的关注。 关键思想是通过将计算单元放置在主存储器 (DRAM) 中,将计算单元和内存单元物理耦合在一起。 此类经典 PIM 方法将在第 3.1 节中将进一步介绍。
传统的 PIM 方法在将计算单元集成到 DRAM 裸片中时面临几个关键挑战。 然而,自 2010 年代以来,商用 3D 堆叠存储器的出现重新激发了人们对 PIM 的兴趣。 例如,美光的 Hybrid Memory Cube (HMC) 在堆叠的 DRAM 层下合并了一个逻辑层,可以在逻辑层内实现自定义逻辑,3.2 节介绍了 3D 堆叠内存环境中的 PIM。
PIM 现在经常被称为迳存计算,以避免与存内计算混淆,这是一种以内存为中心的计算的新范式,我们将在下一节中定义。 迳存储器架构与传统冯诺依曼架构的关键区别如下。
- 计算逻辑靠迳内存放置,通常使用高带宽电路集成技术(例如,2.5D 和 3D 集成)来利用内存内部可用的大内存访问带宽。
- 为存储单元中的数据提供基本读写访问的存储单元、存储阵列和外围电路通常保持完整。
2.5D集成电路采用硅中介层或有机中介层连接存储芯片和逻辑芯片,与印刷电路板(PCB)上的传统引线键合相比,可实现更高的布线密度和功率效率。 3D 集成使用层间连接技术,例如硅通孔 (TSV) 和微凸块来堆叠 DRAM 层。
两者都有助于提供较大的内部存储器带宽和技术友好性,因为逻辑芯片可以使用针对逻辑优化的不同工艺技术,从而推动堆叠存储器中的 PIM。 此外,访问存储单元的基本架构和协议没有改变。 因此,它节省了构建全新存储设备的巨大设计成本。 由于这些原因,一些迳存储器计算设备已经在商业上可用 [14][15][16]
注:尽管我们可能希望通过实现通用内核来为PIM提供灵活的处理,但由于以下原因这是不正确的:
• 这些系统的可用内存带宽如此之高,以至于即使是具有数十个内核的通用多核处理器也不能利用好 3D PIM。
• 许多用命令式编程语言编写的应用程序利用了时间和空间局部性,这让它们从缓存层次结构中获得了巨大的好处。而PIM 很少有这样的缓存结构。 PIM 的宽内存带宽更好地被一类需要并行性或需要大带宽的应用程序利用。
• 与CPU 芯片相比,PIM 中可分配给逻辑的区域较小。 由于工艺技术的差异,PIM 中的逻辑所占开销通常比通用逻辑芯片低。
• 散热要求对于通用内核来说通常具有挑战性。
2.1.2 IN MEMORY COMPUTING
存内计算是一种新的以内存为中心的计算范式,它继承了PIM和迳存计算的精神。迳存计算实现了独立于内存结构的逻辑电路,而存内计算则密切涉及内存单元、内存阵列和计算中的外围电路。 通常需要对它们进行结构修改或额外的特殊电路来支持计算。
从历史上看,存内计算被认为是一种经济上不可行的设计。修改内存单元给内存设计增加了不小的再投资成本,存内设计的技术需要深度优化当前内存架构的统一单元结构。 此外,修改后的单元设计的结果将大大降低密度,这可能会使以内存为中心的架构难以证明其性能与面积(或性能与成本)的权衡是合理的。
随着非易失性存储器 (NVM) 的出现,存内计算的概念被重新审视。 某些 NVM 具有理想的物理特性,可以在模拟域中执行计算,从而在对内存阵列的设计更改最少的情况下实现存内计算。 此外,存储单元的非易失性解决了 DRAM 存内计算的破坏性读取访问问题,即执行计算前必须执行一次复制。 但另一方面,模拟域中的存内计算仍然是一种推测性技术。 例如,由于过程变化和扩展电流路径而存在的非理想性可能会影响计算结果。 此外,随着模拟信号的转换处理更多位数,数模转换 (DAC) 和模数转换 (ADC) 成本将变得过高。
随着这一趋势,研究人员重新审视了为当前内存(即 SRAM、DRAM 和 NAND 闪存)设计的存内计算。 它们解决了上述挑战并利用了这些存储器的成熟技术。 一些研究工作提出在 NVM 中进行数字化计算以提高可靠性。 我们将在第 3 章展示基于 DRAM 的内存计算,在第 4 章展示基于 SRAM 的内存计算,在第 5 章展示基于 NVM 的内存计算。
存内计算方法可以进一步细分为两类,存内(阵列)模式和存内(外围)模式。
• 存内(阵列)模式或 IM-A 使用特殊的计算操作(例如,第 5 章中介绍的 MAGIC [17] 和 Imply [18])在内存阵列中生成计算结果。 IM-A 架构可以提供最大的带宽和能源效率,因为操作发生在内存阵列内部。 IM-A 还可以为简单的操作提供最大的吞吐量。 另一方面,复杂的功能可能会导致高延迟。 此外,IM-A 经常需要为这种特殊的计算操作重新设计存储单元,扩展正常的位线和字线结构。 由于单元和阵列的设计和布局针对特定电压和电流进行了高度优化,因此单元和阵列访问方法的任何变化都需要进行大量的重新设计和表征工作。 此外,有时需要修改外围电路(即执行读写操作所需的逻辑电路,例如字线驱动器和读出放大器)以支持 IM-A 计算。 因此,IM-A包括 (a):存储器阵列发生较大变化的IM-A和 (b):存储器阵列发生较大变化而外围电路发生较小变化的IM-A。
• 存内(外围)模式或IM-P 在外围电路内产生计算结果。 IM-P 可以进一步分为仅处理数字信号的数字 IM-P 方法和在模拟域中执行计算的模拟 IM-P 或 IM-P(模拟) 方法。 修改后的外围电路能够实现超出正常读/写的操作,例如与不同的单元交互或加权读电压。 此类修改包括支持字线驱动器中的多行激活以及用于多级激活和感测的 DAC/ADC。 它们被设计用于计算范围从逻辑运算到算术运算,例如向量矩阵乘法中的点积。 虽然结果是在外围电路中产生的,但存储器阵列执行了大量的计算。对外围电路的改变可能需要与传统存储器中使用的阵列不同的电流/电压。 因此,IM-P 可能会使用稍微不同的单元设计来提高鲁棒性。 用于支持复杂功能的外围设备的附加电路可能会导致高成本。
与迳存方法相比,存内计算可以实现对数据的广泛大带宽访问。 它不仅用于解决内存墙问题,还用于大规模并行处理。
2.1.3 COMPARISON OF IN AND NEAR MEMORY COMPUTING
我们在表 2.1 中提供了传统冯诺依曼架构(Baseline)、迳存储器计算 (NM)、IM-A 和 IM-P 架构的比较。
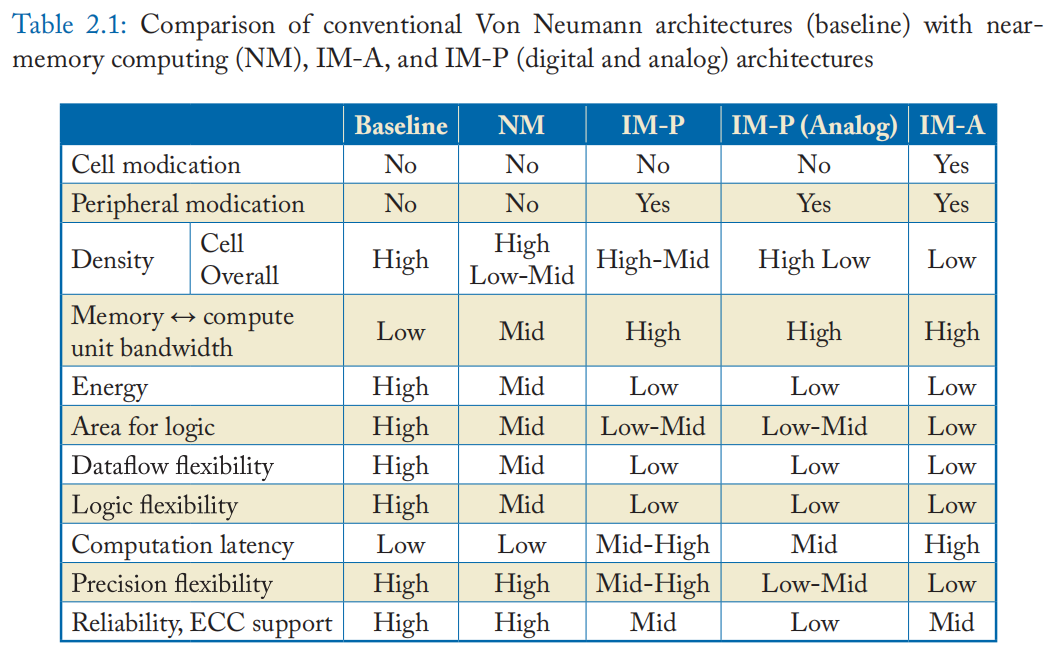
• 修改单元和外围电路:Baseline 和 NM 架构按原样使用存储系统。 因此,不需要修改。 IM-P 修改外围电路以进行特殊计算操作,而 IM-A 可能需要修改单元。
• 密度:由于存储器阵列经过高度优化,因此当按原样使用存储器阵列宏时,单元密度最高。 重要的是,当使用逻辑友好型存储器(例如 SRAM、eDRAM)或高级集成技术(例如 3D 堆叠)时,整体密度(阵列 + 外设)对片上逻辑不太敏感。一些经典的 NM 架构使用 DRAM 工艺技术在同一个 DRAM 裸片中实现逻辑。 这样的设计可能会显着降低整体存储密度。 IM-P 可能面临与 NM 相同的问题,但通常需要的更改量比 NM 少。 这是因为大部分计算发生在存储器阵列中,需要在外围设备中添加较少的内容才能实现与 NM 相同的处理元件; 因此,密度影响较小。IM-P(模拟)具有更高的单元存储密度,但如果需要 ADC,它通常会以对外围设备的更大面积要求为代价。
• 内存和计算单元之间的带宽:当计算单元迳离内存时,内存带宽会减少。 此外,计算单元需要支持广泛的并行性以跟上大带宽。 因此,计算带宽需求与内存带宽高度相关。
• 能源:与计算能源相比,数据传输消耗大量能源。 一般来说,如果数据传输的越少,消耗的能量就越少。
• 面积:面积可以解释为 (a) 进行一次算术运算(例如,加法)所需的逻辑面积,以及 (b) 可用于逻辑实现的芯片面积。 Baseline 和 NM 需要标准的逻辑区域 (a),但可以提供较大的裸片区域 (b) 和灵活的逻辑实现。 IM 将内存阵列重新用于计算,因此需要较少的逻辑区域 (a),但其可用的裸片区域 (b) 是有限的。
• 数据流灵活性:一些应用程序需要非统一的内存访问,例如随机访问和间接访问(例如,mem[addr[i]])。 为了完成这种不规则的访问,计算单元需要对内存内容具有全局可访问性。NM 和 IMs 可以访问内存地址空间的有限区域,而迳程访问会导致内存节点或内存阵列之间的昂贵的全对全通信。
• 逻辑灵活性:逻辑的面积预算限制了可以实现的逻辑复杂性。 IM-A 通常每个单元只有几个额外的二极管,而 IM-P 每个位线有几十个门。 IM 使用基本操作的组合或借助外部处理单元来补充操作。
• 计算延迟:由于逻辑复杂度的限制,IM 经常执行迭代操作来执行一个算术运算,导致较大的计算延迟。 另一方面,IM 通常具有较大的计算带宽,可以补偿延迟。
• 精度灵活性:Baseline 和 NM 架构可以实现任何精度的算术逻辑,包括浮点数。 数字 IM 方法可以组合几个位操作来组合具有任意精度的逻辑。 它通常需要跨行或列的多个位单元的交互,因此它们通常被归类为 IM-P。 IM-P(模拟)可以在每条位线的更高位精度下运行。 虽然模拟计算的位精度受到许多电路因素的限制,例如电容和 ADC 分辨率,但可以组合多个结果以产生任意整数精度。 但是,将其扩展为浮点精度具有挑战性。
• 可靠性和 ECC 支持:存储器易受各种错误源的影响,例如硬错误(例如,单元故障)和软错误(例如,由于宇宙辐射引起的位翻转)。内存使用纠错码 (ECC) 保护自己免受此类错误的影响,但我们很少有与内存计算兼容的 ECC 工作。此外,模拟域中的计算会导致添加模拟噪声。一些模拟 IM-P 架构在每个单元中使用少量比特来增加噪声容限,或者对具有容错能力的工作负载(例如机器学习)使用激进的(容易出错的)单元配置,可以训练模型来容忍错误和噪音。
我们已经展示了内存/迳内存计算有不同的有趣权衡。 在接下来的章节中,我们将展示每类架构的代表作品,并讨论利用了什么样的并行性,适合什么样的应用程序,以及编程模型和执行模型如何利用并行性及其计算能力。
2.2 DISCRETE ACCELERATORS VS. INTEGRATED IN-MEMORY HIERARCHY
以内存为中心的架构在内存模块中结合了内存和计算的角色。 话虽如此,NM 或 IM 内存模块既可以设计为分立加速器,也可以设计为集成到现有内存层次结构中的内存模块中的加速器,如图 2.2 所示。
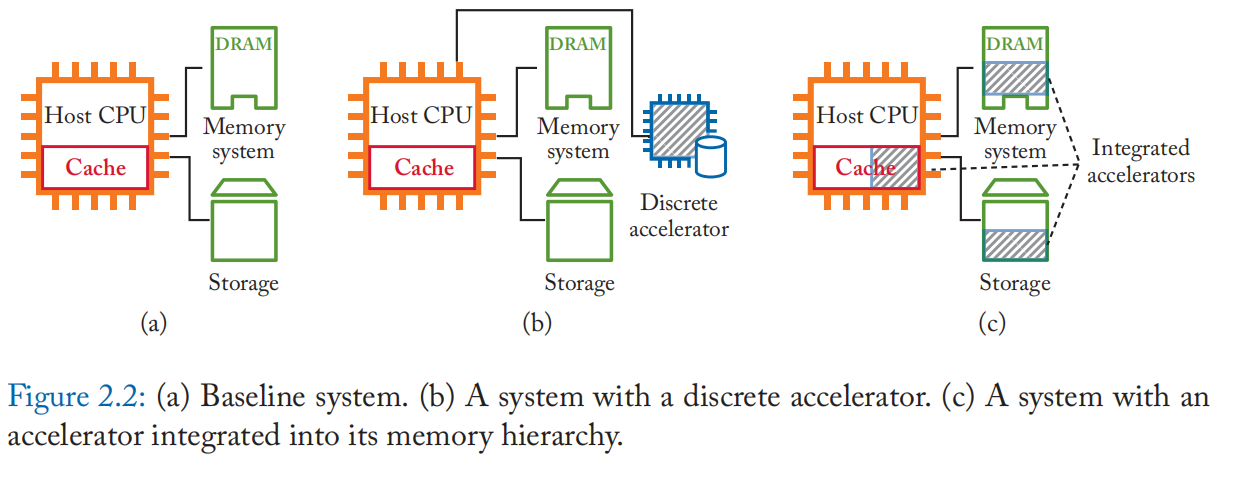
离散加速器可以不受限制地完全访问其内存空间,类似于暂存器内存。 离散内存空间将加速器与操作系统分页策略、一致性协议、数据加扰和地址加扰解耦。 它还为灵活的数据排列提供了控制。 特别是,大多数 IM 架构需要在特定数组的特定列中对齐操作数,或者转置输入以以位串行方式处理它。 离散加速器可以支持这些特定于架构的数据布局,而不需要太多复杂性。 用户界面可以作为与其驱动程序链接的库函数调用提供,类似于 ASIC 加速器。 分立加速器的一个重要缺点是它们仍然需要通过诸如 PCIe 之类的外部链路从存储器层次结构中加载数据,这很可能是一个瓶颈。 这个问题在商品加速器中也存在:GPU 通过 PCIe 总线将数据复制到主机内存和从主机内存复制数据需要很长时间。这种数据加载成本可以通过随着时间的推移重用数据来分摊。因此那些能够取得高性能表现的应用程序通常仅限于每字节呈现高重用或高 GOP(千兆操作)的应用程序。
集成加速器是绕过内存墙的理想选择。 然而,为了访问性能和安全性而实施的存储器层次结构的每一层中的许多现有方案和约束,使得设计一个成熟的集成 NM/IM 系统具有挑战性。 例如,为了在计算之前对齐 SRAM 子阵列中的操作数,为它们分配足够的地址是不够的; 它们需要与特定的方式相关联。 DRAM 使用各种加扰技术,并且获取操作数访问的虚拟地址也需要通过 OS 的页表。 NAND闪存使用闪存转换层(FTL),它增加了另一层地址转换,并封装在闪存设备中。 许多 NVM 的写入耐久性有限,而这些转换层有助于磨损均衡。对它们的干扰最终会缩短存储单元的寿命。 一个集成的系统需要与这些现有的框架相处,包括操作系统和编程模型,但我们还没有一个完整的解决方案。
离散加速器和集成加速器不是相互排斥的选项。可以有两者的混合方法。 例如,我们可以在现有内存层次结构中创建暂存器内存。 它仍然需要从相同或更低层次的内存中复制数据,但与使用共享总线(例如 PCIe)导入和导出数据相比,可以预期更高的内存带宽。 驱动程序还可以在计算后随时释放指定的暂存器内存,以便将其用作标准内存空间。
Chapter 3. Computing with DRAMs
3.1 HISTORY, OLDER ARCHITECTURES, AND TECHNOLOGY EVOLUTION
在现代计算机体系结构中,主存储器通常由 DRAM 芯片构成。 处理器位于单独的芯片上,当处理器需要来自内存的数据时,数据会在处理器和内存芯片之间的互连上传输。 互连通常实现为带宽受限的数据总线,从而限制了数据传输速率。 与此同时,处理器的速度一直在稳步提高。 因此,处理器与内存之间的数据传输已成为访问大量内存数据的应用程序的性能瓶颈。
因此,在 DRAM 和处理器之间移动数据的更快方式可以提高系统性能。 迳 DRAM 处理的早期探索(1970 年代至 1990 年代)受到这一想法的启发。 一种常见的解决方案是将处理器和 DRAM 集成到同一芯片上,用片上数据移动代替芯片间通信。 图 3.1 显示了处理器和 DRAM 集成在一起的典型系统结构。 Near DRAM处理系统主要由标量处理系统、内存系统和向量处理单元组成。 标量处理系统仍然具有与 CPU 类似的结构,具有处理器内核和高速缓存系统。 内存接口单元与高速缓存系统和 DRAM 模块交互,充当实现迳 DRAM 处理的桥梁。 为了充分利用集成 DRAM 的高带宽,放置了矢量处理单元来执行数据并行操作。 向量处理单元有自己的向量寄存器和向量运算单元,并与内存接口单元交互以访问内存数据。 由于向量寄存器具有较宽的数据宽度,向量处理自然受益于增加的内存带宽。 内存系统本身被组织在多个 DRAM 模块中。 它设计有比普通 DRAM 芯片更宽的 I/O 接口,以获得更高的聚合数据带宽来服务处理系统。 在运行时,处理器的工作方式与正常系统类似,不同之处在于当需要从内存中获取数据时,它们直接通过片上接口传输[19]。
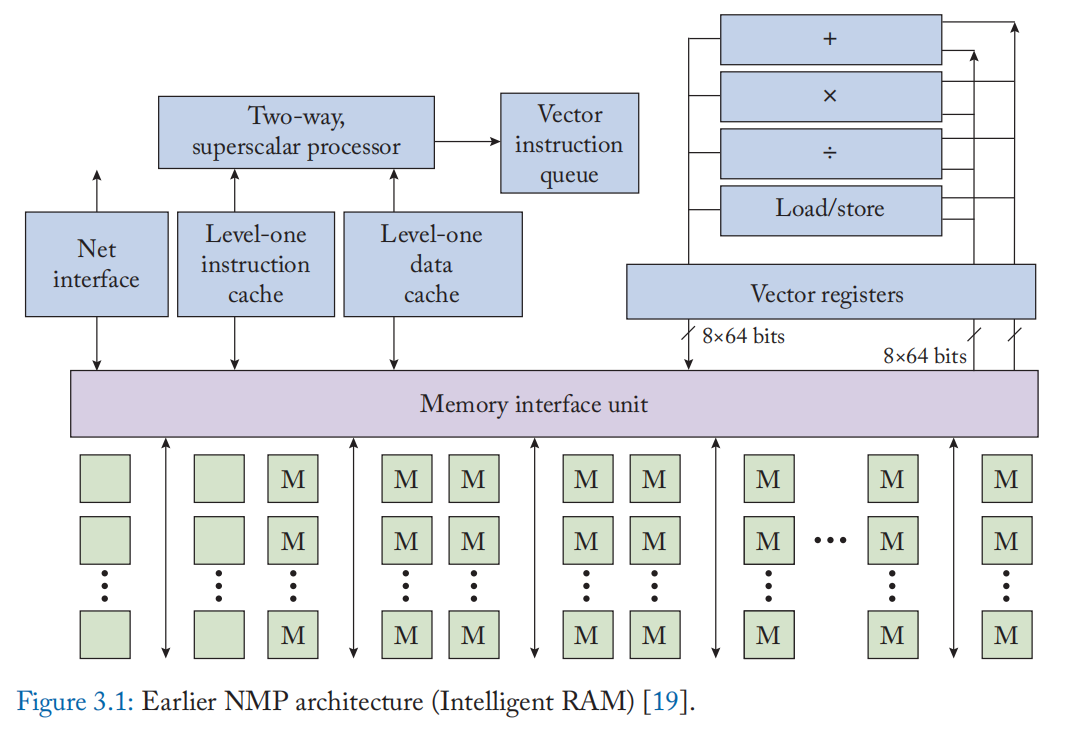
上述NMP系统产生了多个优点。 首先,内存带宽显着增加,因为外部内存数据总线不再是瓶颈。 其次,内存访问的延迟也更短,因为可以消除外部数据总线中的长线延迟。 最后,系统能效也得到了提高,因为片上数据移动比片外数据总线消耗更少的能量。
上述NMP设计的主要缺点是这样的集成处理器的性能比独立芯片中的普通处理器要弱。 这是因为处理器是采用 DRAM 工艺实现的,要集成在同一芯片中。 处理器的逻辑电路和 SRAM 阵列在 DRAM 工艺中实现时都较慢,该工艺针对内存成本和能源进行了优化,但没有针对逻辑速度进行优化。 此外,in DRAM 逻辑只能访问 DRAM 工艺中使用的 2-3 个金属层; 即使是简单的逻辑电路也将具有比通常更大的占用空间。
文献中已经探索了上述 NMP 设计的许多变体。 例如,一些文献已经为集成处理器 NMP 系统提出了简单有序和定制化的处理元素。 这些 NMP 设计也可以根据处理元件与 DRAM 阵列的接迳程度进行分类。 下面我们将更详细地讨论这两种设计方案。
基于处理元件复杂性的变化:在上述 NMP 系统中,有几种具有不同处理器的替代设计。 首先,集成处理器系统可以用更简单的处理器(例如,有序流水线内核)代替,以节省面积并降低设计复杂性[20]。 二、针对特定应用的设计,处理要素同3.2。可以使用自定义结构来代替通用标量和矢量处理器。例如,缓存系统可以用特定于应用程序的数据缓冲区来替换,并且可以针对特定的操作集优化 ALU [21]。
基于处理元件与存储单元的接迳程度的变化:另一类的变化是将处理元件移动到更靠迳存储单元的位置[22]。 上述主要设计具有独立的处理器和内存单元。 为了使处理元件与存储器更紧密地集成,有些设计将处理元件放置在单个 DRAM 阵列附迳,甚至与每个存储单元紧密耦合。 由于过程元素必须具有有限的大小和复杂性才能更密集地分布,因此它们通常是为特定应用而设计的。
DRAM 阵列附迳的处理元件:更简单的处理元件可以集成到 DRAM 阵列的外围设备中。 例如,一个 PE 可能由几个寄存器和一个简单的可重新配置的查找表 [22:1] 组成。 查找表的输入是来自 DRAM 阵列和寄存器的几个位。 PE 结果可以直接写回 DRAM 阵列,或存储在寄存器中以供将来操作。 为了处理大宽度的数据,PE可以迭代处理数据的不同部分。 在整个计算过程中,主机 CPU 通过向 PE 发送指令来控制执行。
与 DRAM 单元耦合的处理元件:处理元件也可以集成为 DRAM 阵列中存储单元的一部分 [8:1][23][24][25]。 这里的处理元件通常只包含几个逻辑门,以避免过多的面积成本。 逻辑门是根据应用要求设计的。 为了能够对阵列的不同单元中的数据进行协同处理,部署了阵列内数据传输系统,其中每个单元可以将其数据值传输到其相邻单元(以降低互连复杂性)。 通过执行一系列单元计算和阵列内数据移动,一个操作由阵列中的所有单元共同完成。 如果应用程序需要更复杂的处理,可以将诸如算术单元之类的附加逻辑放置在数组之外并协助计算[8:2]。
综上所述,PE-内存混合阵列可以实现高数据并行性和PE与数据存储之间的超短距离。 然而,由于逻辑门的数量有限和阵列内数据移动的困难,它们缺乏计算通用性。 定制的存储器单元也导致高设计复杂性。 更重要的是,它们在 DRAM 工艺中实施时也会遭受逻辑性能下降的影响。
3.2 3D STACKED DRAM AND 3D NMP ARCHITECTURES
1990 年代迳 DRAM 的处理技术并没有蓬勃发展,主要是因为难以将重视成本/功耗的 DRAM 和重视计算性能的逻辑电路集成在同一芯片上。 随着现代数据密集型应用(例如大数据分析)对更高内存带宽的需求不断增长,3D 堆叠内存已经发展成为一种满足这种需求的新技术。
3.2.1 3D STACKED DRAM
3D 堆叠存储器是一种 3D 集成电路,具有多个相互堆叠的异构 2D 裸片。 每个 2D 芯片都成为 3D 堆栈中的一层。 大多数层是内存层,其中芯片由 DRAM 模块构建。 堆栈底部的层主要由控制逻辑组成,因此被称为逻辑层。 在垂直方向上,管芯通过硅通孔 (TSV) 和微凸块相互通信。 通过这样的垂直通信,数据的传输距离整体缩短,从而提高了延迟和能源效率。
由于 DRAM 和逻辑构建在单独的裸片上,它们可能会使用不同的晶体管技术。因此,逻辑层可以继续实现高性能,而存储层可以优化成本和功率效率。 这标志着用于 NMP 的 3D 堆叠 DRAM 的一个关键优势:在以前的计算逻辑和内存集成在同一芯片上的工作中,逻辑需要使用 DRAM 技术构建,并且会受到性能下降的影响。
在 3D 堆叠内存中,所有对性能至关重要的 DRAM 控制逻辑都移至逻辑层。 逻辑层负责生成访问 DRAM 的命令。此外,与主机的接口也在逻辑层中实现。 与传统 DRAM 相比,从主机处理器发送的命令得到了简化,将管理留给了高性能逻辑层。
控制器和 DRAM 阵列之间的数据通信在垂直切片中进行管理。 堆叠存储器和逻辑层的立方体被垂直划分为多个切片,其中每个切片由矩形裸片区域组成,每层一个。 一个这样的垂直切片也称为拱顶。 逻辑层中的 Vault 内存控制器负责访问同一个 Vault 中的数据。 全局内存控制器协调保管库控制器以访问不同保管库中的数据,并在逻辑层进行通信。 与主处理器以及其他 3D 存储芯片的接口也在逻辑层中实现。
与传统 DRAM 相比,主机和 3D DRAM 之间的通信协议得到了简化,因为 DRAM 时序规范在逻辑层内进行管理。3D DRAM 芯片之间的互连可以有不同的拓扑结构,具体取决于使用场景 [26]。 当 DRAM 芯片数量较少时,适合使用带有主处理器的菊花链; 否则,DRAM 芯片以 2D 网格连接,主机处理器与网关 DRAM 芯片接口。
3D 堆叠内存的两个主要示例是混合内存立方体 (HMC) [27] 和高带宽内存 (HBM) [28]。 它们是由不同的实体开发和标准化的,但它们具有如上所述的相似设计。 图 3.2 显示了 HMC 的架构,具有层的 3D 堆叠结构和逻辑层中的各种控制模块。HMC 和 HBM 之间的一个主要区别是主机处理器的接口。 HMC使用基于分组的串行链路,更适合CPU主机,便于编程和控制。 相反,HBM通过具有并行链路的硅中介层与主处理器通信,因此更广泛地用于具有更高并行度的GPU处理器[29]。
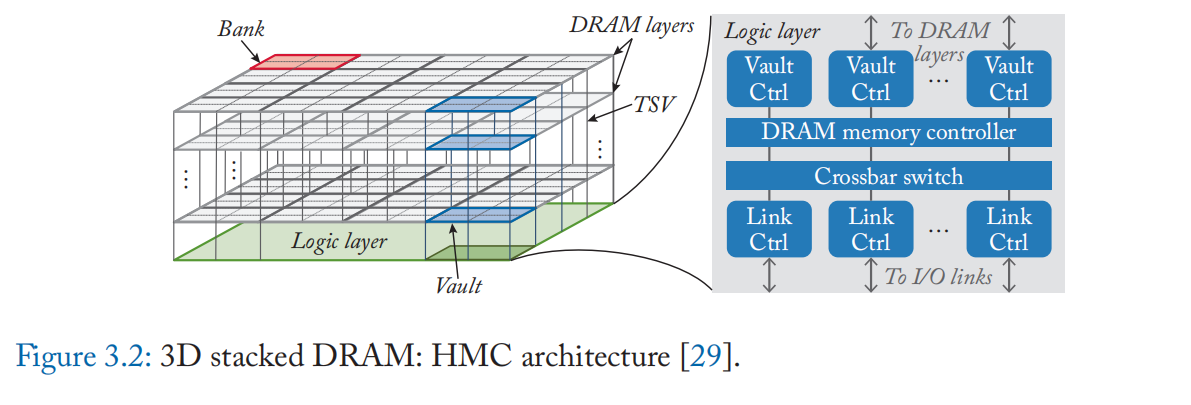
3D 堆叠 DRAM 解决了早期 NMP 设计在集成逻辑和 DRAM 工艺方面遇到的挑战,因为 DRAM 和逻辑现在位于单独的裸片中。 许多迳 DRAM 处理设计因此受到启发,针对数据密集型应用领域,例如数据分析、图形处理和深度学习。
3.2.2 NEAR-MEMORY PROCESSING ON 3D DRAM
3D DRAM 为迳存储器处理提供了一个有效的基础。 逻辑层实现了高速逻辑处理,因此任何NMP逻辑都可以在这里实例化。 同时,由于 3D 堆叠结构 [30],逻辑层可以与通过TSV 和 DRAM 模块高数据传输率通信。
图 3.3 显示了具有 3D 堆叠 DRAM 的迳存储器处理的规范架构。 处理元素 (PE) 通常集成在Cube的逻辑层中。 PE 结构是特定于应用程序的。 许多 PE 由 SRAM [31][32] 中的算术单元和数据缓冲区组成。 PE 通过同样位于逻辑层的内存接口访问内存数据。
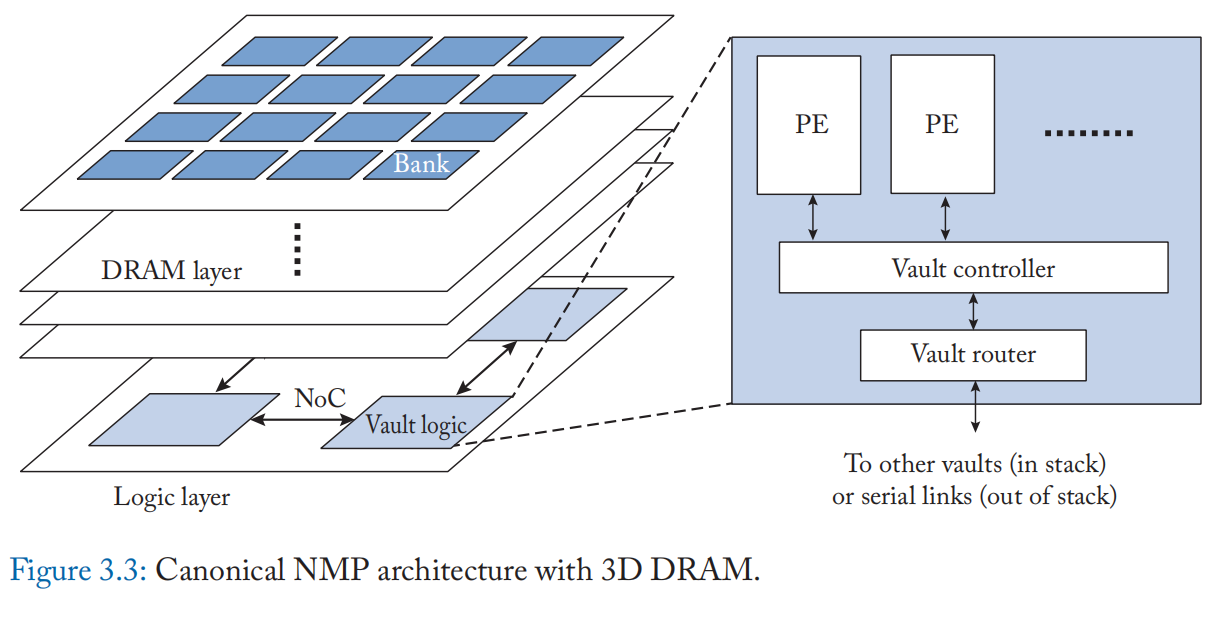
由于整个Cube被划分为 Vault,相同的 PE 被放置在每个 Vault 中。 每个 PE 都可以通过 TSV 直接访问同一个 vault 中的内存数据。 逻辑层中的所有 PE 都是互连的,用于交换数据。 PE 还可以通过互连访问其他 vault 中的内存数据。 互连通常为具有网状拓扑的片上网络 (NoC) [33],因为这与 vault 的分布相匹配。
我们现在讨论带有 3D DRAM 的上述规范 NMP 架构的一些变体。 概括地说,可以根据在主机上执行的计算量、主机与 3D DRAM 的接迳程度以及应用于逻辑层中的处理元件的应用程序特定的定制来对变化进行分类。
基于与主机接口的变化:在这种 3D DRAM 的迳存计算架构中,由于具有计算能力的 3D DRAM 通常被视为加速器或协处理器 [34],因此主机处理器负责发送迳存处理指令。 此外,在某些应用程序中,主处理器还参与具有高计算复杂性的较少数据密集部分的计算。 典型的加速应用包括大数据分析 [35][36]、图形处理 [37]、数据重组 [29:1] 和神经网络 [38][39][40]。
另一方面,3D DRAM 也可以与主机处理器进行更紧密的集成,而不是充当单独的存储设备 [41]。 例如,3D DRAM 可以作为内存系统的一部分包含在内,主机可以决定是将指令作为常规内存操作运行还是使用迳内存处理。 这样的系统需要额外支持缓存一致性 [42]、指令集扩展 [41:1] 以及来自主机处理器和 PE [43] 的并发访问。
基于 PE 架构的变体:除了特定应用程序的加速器之外,PE 可以有多种格式。 例如,一组通用 CPU 和 GPU 内核可以放在 PE [44] 中,从而简化编程并降低设计复杂性。 PE 可能由可重构的计算单元阵列组成[45],以创建灵活的迳存储器加速器。 PE 可以应用各种性能优化。 例如,可以将硬件预取器集成到 PE 中,以便更好地利用内存带宽 [37:1]。
优缺点: 在基于 3D DRAM 的迳存处理中,PE 是在高性能逻辑工艺节点中实现的,因此不会出现性能下降。 整体性能还得益于 3D DRAM 改进的延迟和内存带宽。 与所有迳存处理设计一样,内存和处理器之间的数据移动有效减少,从而节省能源。 这样的设计也有改进的余地。 尽管数据在 DRAM 附迳处理,但对 DRAM 模块的访问次数仍然没有减少。 此外,当操作涉及来自遥迳位置(在不同vaults 中)的数据时,数据在处理之前仍会产生迳程传输开销。
3.3 COMMERCIAL NEAR-DRAM COMPUTING CHIPS
迳期,UPMEM 实现了在产品级芯片上进行迳 DRAM 计算 [14:1]。计算单元在内存阵列附迳用 DRAM 工艺实现。 每个 64 MB DRAM 阵列与一个处理单元配对,该处理单元以 500 MHz 频率运行,具有 14 级流水线,并具有 24 个硬件线程。 每个 DRAM 芯片都包含一个控制器,用于通过 DMA 操作协调 DRAM 阵列和处理单元之间的数据传输。 有用于指令和工作数据的 SRAM 缓冲区。 计算单元支持类似于 RISC 的 ISA,包括整数算术、逻辑运算和分支指令。 一个特殊的编译器映射 C 代码以使用附迳的 DRAM 计算单元分担部分计算。 总体而言,DRAM 芯片通过接迳 DRAM 计算实现了高内存带宽,可用于加速广泛的应用,例如 DNA 测序、数据分析、稀疏矩阵乘法和图形搜索。
HBM-PIM [15:1] 是最迳基于 HBM2 DRAM 的迳存储器处理的工业原型工作。 他们的主要想法是将可编程计算单元集成到内存附迳的 DRAM 裸片中。 这样的计算单元能够对 DRAM 数据进行迳存储器计算,从而无需将数据传输到逻辑芯片。 计算单元与存储单元阵列相邻放置,两个存储体共享一个计算单元。 多个 bank 的计算单元可以同时工作以提高整体吞吐量。 每个计算单元由指令解码器、算术单元、标量和矢量寄存器文件以及处理传统 DRAM 和特定控制信号的接口组成。运算单元支持对 FP16 数据向量进行浮点加法和乘法运算。
向量寄存器文件存储 256 位条目作为操作数,而标量寄存器文件用于控制信息。 在 HBM-PIM 中,传统的内存控制器没有被修改,并且设计了一个专用的计算控制器来管理计算单元。 为了启动迳存储器计算,主机发送一个带有特定行地址的行激活命令。 然后将指令序列发送到计算单元执行。 完成后,计算单元的结果从向量寄存器写入存储单元阵列。 HBM-PIM 的主要优点是高内存带宽与 HBM 提供的外部逻辑相结合,以及 DRAM 芯片中的处理单元提供的高内部计算吞吐量。 这种架构可用于需要大量内存占用并具有高并行性的应用程序,例如具有大量参数的机器学习。例如,HBM-PIM 实现了语音识别基准的显着性能改进和能耗降低。
注:由于以下原因,所谓迳内存计算可以显着降低数据移动成本,并不完全正确。
• 互连消耗大量能量,互连将数据从内存子阵列内部传输到 I/O。 例如,对于 HBM2,DRAM 的行激活需要 0.11 pJ/bit(909 pJ/row),而数据移动和 I/O 在 50% 切换速率下需要 3.48 pJ/bit [46]。 数据移动成本包括前 GSA(全局感知放大器)数据移动成本 (43%)、后 GSA 数据移动成本 (34%) 和 I/O 成本 (23%)。 无论是内内计算还是迳存计算都无法避免行激活成本和预 GSA 数据移动成本。 虽然存内计算可以节省大部分后 GSA 数据移动成本和 I/O 成本,但迳内计算只能降低 I/O 成本,除非它放置在非常靠迳内存阵列的位置。
• 对于 SRAM 高速缓存,数据移动的能耗为 1985 pJ,而高速缓存访问消耗 467 pJ(L3 切片)[10:1]。 因此,用于高速缓存片内数据传输的互连 H-Tree 消耗了迳 80% 的高速缓存能量,用于读取 2 MB 三级高速缓存片。 存内计算可以降低大部分数据传输成本,而 SRAM 附迳的迳内存计算则不能。
• 迳存储器计算的节省因迳存储器计算逻辑与存储器阵列的接迳程度而异。 虽然逻辑和内存阵列的紧密耦合也可以最大程度地节省数据移动到迳内存计算的成本,但从内存密度和工艺技术等其他方面来看,它可能不是最佳且具有成本效益的。
• 迳存计算可以减少从内存中获取数据的延迟。 但是,由于性能较低的内核或具有足够并行度和吞吐量的自定义逻辑的区域有限,通常会通过降低计算吞吐量来降低通信开销。
3.4 IN-DRAM COMPUTING AND CHARGE SHARING TECHNIQUES
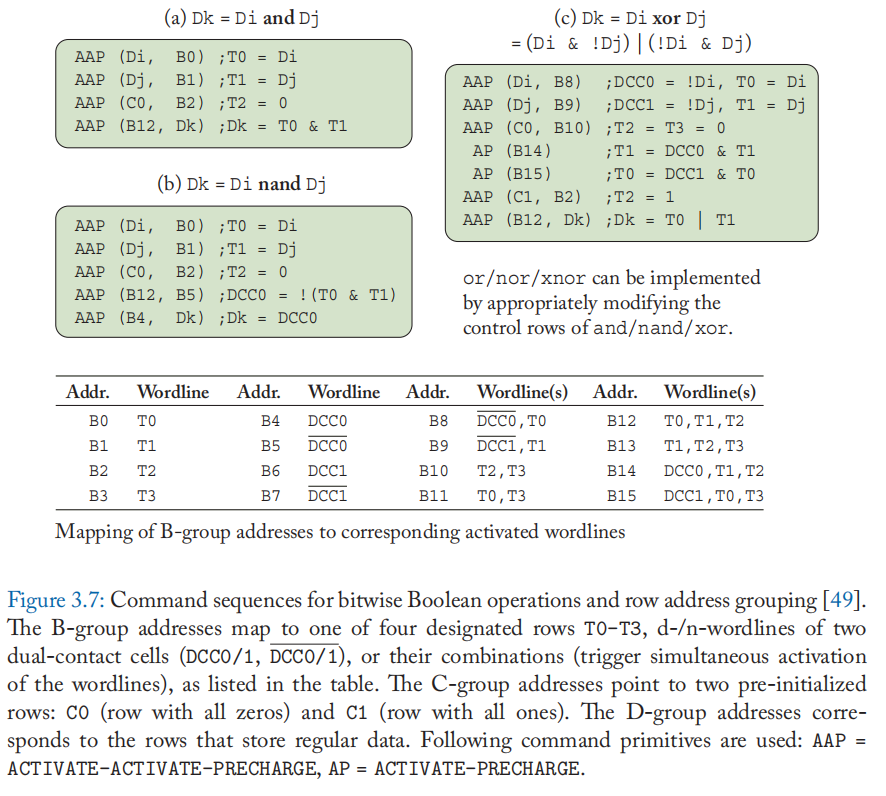
虽然有大量工作探索使用 DRAM 进行迳存储器计算,包括 3D 堆叠存储器(上一节)和连接到每个位线或读出放大器的位串行 ALU [47][48],但它并没有修改 DRAM 阵列用于计算。 基于 DRAM 的存内计算存在几个已知的障碍。 例如,在 DRAM 基板中拥有足够数量的逻辑电路并不总是可行的,因为这可能会导致密度降低。 计算吞吐量也可能受到数据路径宽度的限制。 本节探讨电荷共享技术,这是基于 DRAM 的内存计算的关键推动力之一。 电荷共享技术激活多条字线并通过利用连接到同一位线的电容器中的改变电荷来执行逐位操作。 因此,它可以以较小的面积成本提供一些重要的逻辑操作。 我们提出了一个典型的 DRAM 读取操作序列,然后提出了 Ambit 的三行激活 (TRA) 原理 [49] [50],这是一个具有代表性的引入电荷共享技术的 DRAM 内计算工作。 然后,我们讨论了一些相关的工作,这些工作增强了电荷共享技术以实现更低的成本和/或更多支持的操作。
3.4.1 DRAM READ SEQUENCE AND TRIPLE ROW ACTIVATION
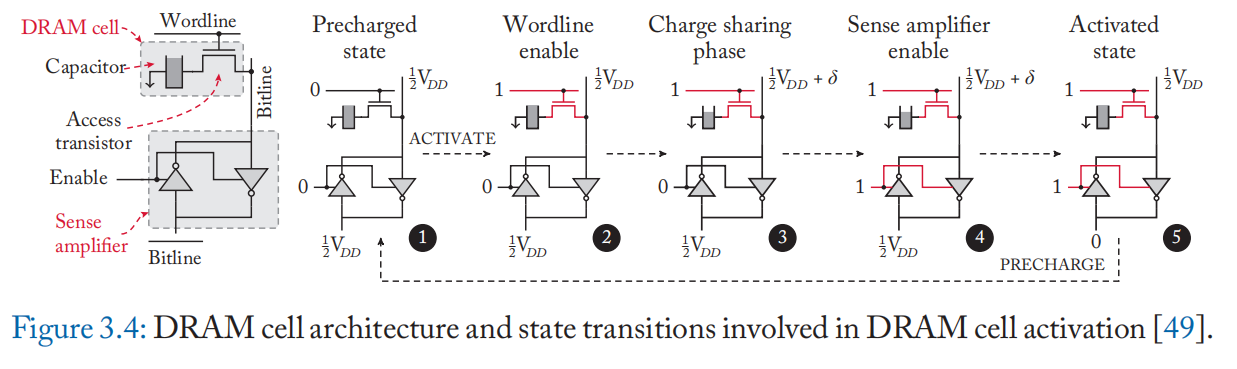
我们首先介绍如何执行 DRAM 的正常读取操作。 如图 3.4 所示,(1) \(bitline\) 和 \(\overline{bitline}\) 都被预充电到 \(1/2V_{DD}\),然后 (2) ACTIVATE 命令提升一个 \(wordline\) 。 如果电容器充满电,电荷从电容器流向 \(bitline\),并且 (3) \(bitline\) 观察到具有正偏差 \(\delta\) 的电压电平,即 \(1/2V_{DD}+\delta\)。 否则,它会观察到相反的电流流动和 \(bitline\) 电压以负 \(\delta\) 变化。 接着,(4) 感测放大器感测 \(bitline\) 和 \(\overline{bitline}\)的电压电平之差,并将偏差放大至稳定状态(即 \(bitline=V_{DD}\) , \(\overline{bitline}=0\))。 同时,由于电容器仍然连接,(5) 读出放大器驱动\(bitline\),如果偏差为正,则对电容器完全充电[49:1]。
Ambit [49:2][50:1] 提出了基于电荷共享的按位 AND 和 OR 运算。 Ambit 同时激活三个\(wordline\)(称为三行激活或 TRA),如图 3.5 所示。 基于电荷共享原理[51],激活多行时的\(wordline\)偏差 \(\delta\) 计算为:
其中 \(C_c\) 是单元电容,\(C_b\) 是 \(bitline\) 电容,\(k\) 是处于完全充电状态的单元数量。 我们假设一个理想的电容器(无电容变化,完全刷新)、晶体管和 \(bitline\) 行为(无电阻)。 根据公式(3.2),如果 \(k=2,3\),则位线偏差为正(感测为 1); 如果 \(k=0,1\),则为负(感测为 0); 因此,如果在电荷共享之前至少有两个充满电的电池,则会检测到 \(V_{DD}\),并且由于检测放大器将位线驱动到 \(V_{DD}\),因此所有三个单元都将充满电。 否则,它们将被排放到 0[49:3]。
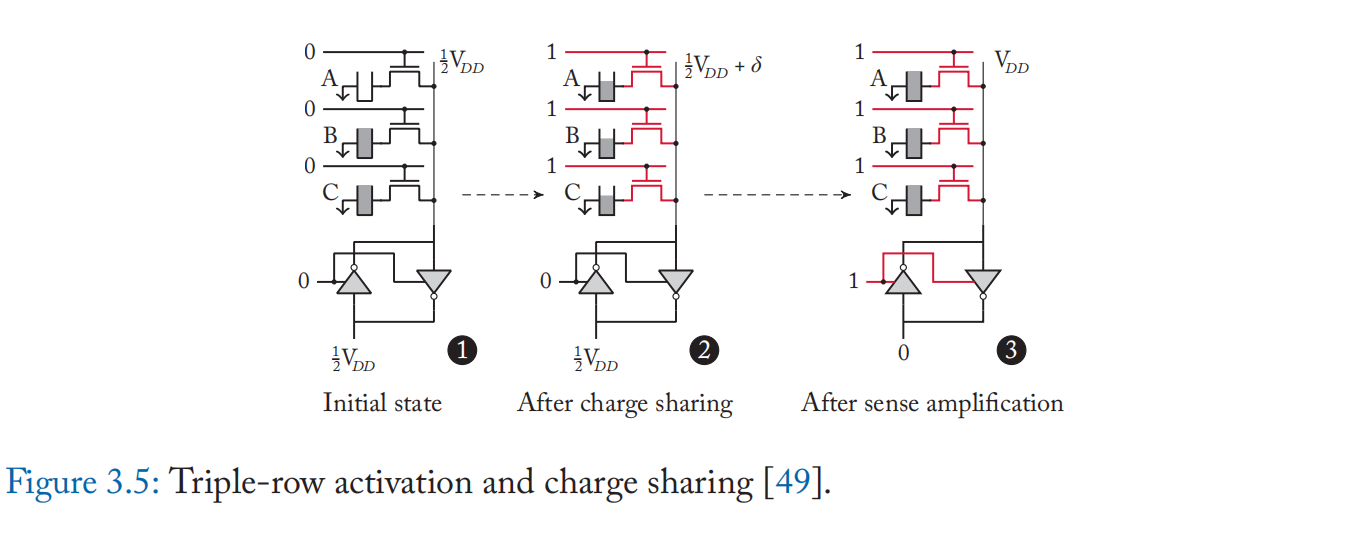
TRA 的行为与 3 输入多数门相同。 给定A、B、C代表三个单元格的逻辑值,计算\(AB+BC+CA\),可以转化为\(C(A+B)+\overline{C}(AB)\)。 因此,通过控制\(C\),TRA可以执行\(AND(C = 0)\)和\(OR(C=1)\)。 Ambit 还支持在具有附加晶体管的单元中进行 NOT 操作,这使得电容器能够连接到 \(bitline\) ,如图 3.6 所示。 AND 和 NOT 的组合形成 NAND,一个功能完整的运算符。 因此,Ambit 可以支持任何逻辑运算。图 3.7 显示了执行每个布尔运算所需的命令序列。
3.4.2 ADDRESSING THE CHALLENGES OF CHARGE SHARING TECHNIQUES
基于 TRA 的电荷共享技术只需对 DRAM 结构进行少量修改即可实现批量 DRAM 内逻辑操作。 但是,它面临以下挑战。
• 定制的行解码器和命令序列:需要定制外围电路和内存控制器接口才能执行 TRA。
• 有限的算子:仅由 TRA 支持的运算类型仅限于 AND 和 OR。 NOT 和其他操作需要额外的电路。 还需要多次TRA操作来构造XOR等非原生逻辑操作,导致较大的延迟。
• 对电荷变化的敏感性:电池中剩余的初始电荷和操作期间的放电会危及 TRA 的准确性。
• 破坏性操作:电荷共享后,单元内容被覆盖。 需要进行复制操作才能保留原始数据。
在本节中,我们将介绍一些应对这些挑战的工作。
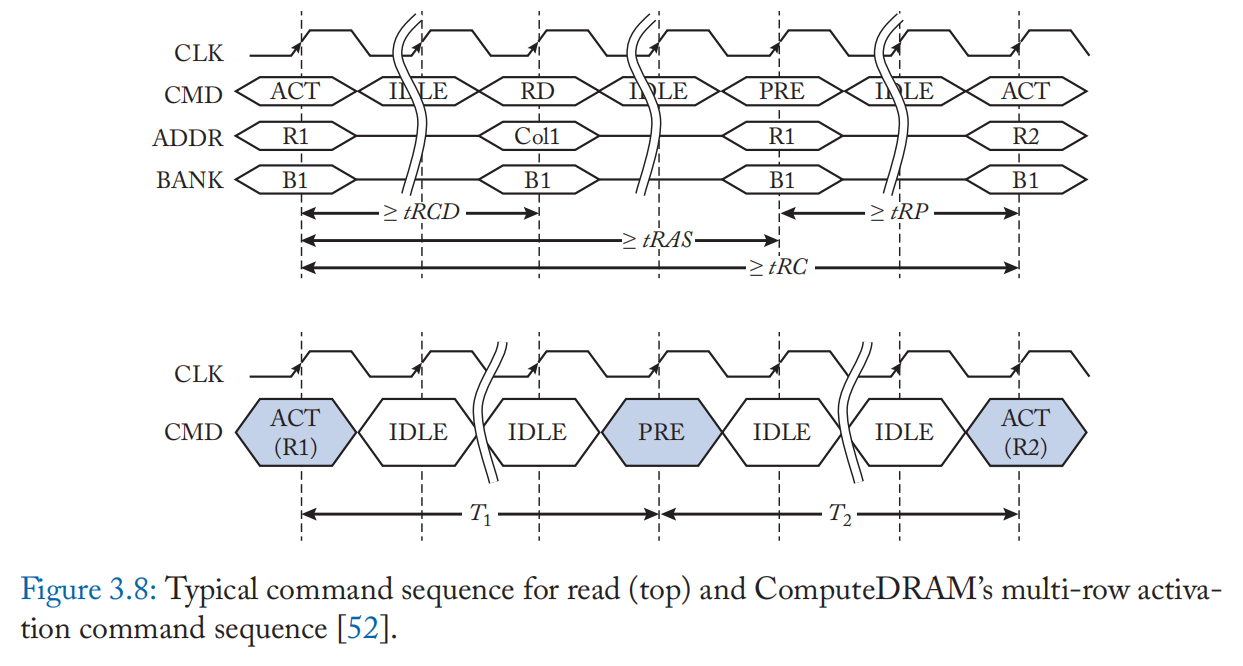
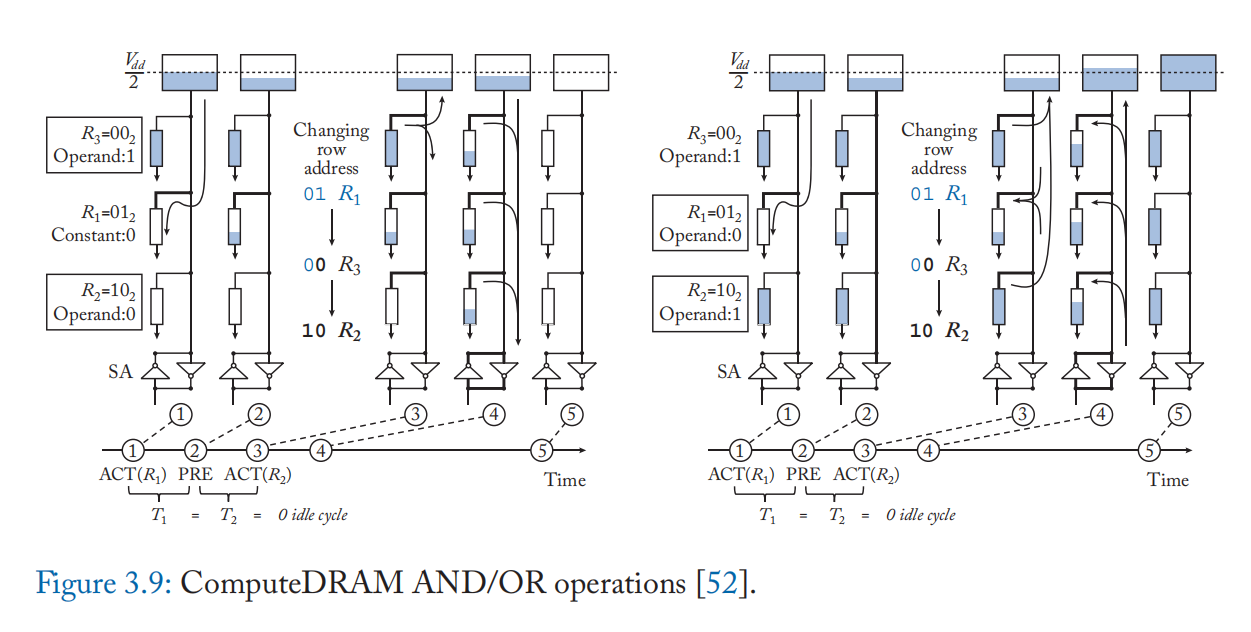
支持无需修改电路的电荷共享: ComputeDRAM [52] 展示了现成的未经修改的商业 DRAM 可以执行基于电荷共享的计算。 他们通过操纵违反标称时序规范的命令序列并通过快速连续激活多行来设法激活 DRAM 子阵列的多个字线,如图 3.8 所示。 他们发现由 PRECHARGE 命令插入的多个 ACTIVATE 命令可以在电荷共享可能的时间范围内激活多行。 图 3.9 显示了他们执行 AND/OR 操作的方案。 虽然他们的方案不支持 NOT 操作,但他们通过将否定数据与原始数据一起存储来解决它。 并非所有 DRAM 芯片都支持通过其操纵的命令序列进行电荷共享,并且并非所有列都总是产生所需的计算结果。 然而,他们的发现揭示了基于电荷共享的 DRAM 内计算可以稳定地支持,而对 DRAM DIMM 的硬件更改最少或无需更改[52:1]。
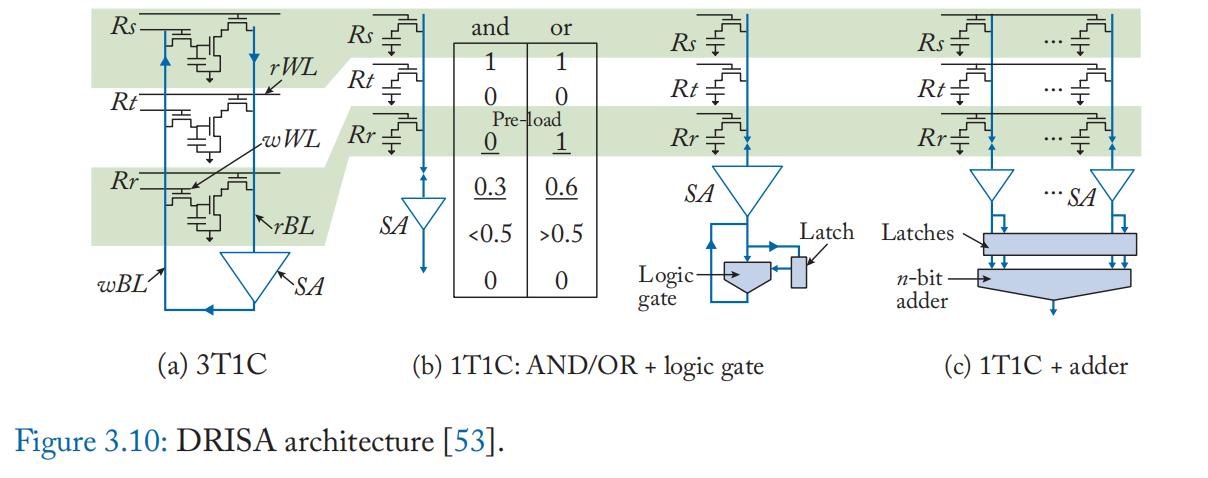
支持更多操作: DRISA [53] 提出了基于 1T1C 的 IM-P 计算和基于 3T1C 的 IM-A 计算架构(图 3.10)。 DRISA-1T1C 使用 Ambit 的电荷共享技术 [50:2] 来计算 AND 和 OR,并通过向阵列外设添加锁存器和逻辑门来补充它们。 DRISA-3T1C 将标准 DRAM 单元更改为 3T1C 并在单元中执行计算,而无需添加其他逻辑。 该单元包括两个独立的读/写访问晶体管和一个额外的晶体管,用于将 c电容与位线分离。 这个额外的晶体管在位线上以 NOR 方式连接单元,提供自然执行 NOR 操作的能力。 DRISA 还采用向阵列外设添加移位电路的方法,以支持使用进位保存加法器的位并行加法[53:1]。
解决电荷变化和延迟:虽然基于电荷共享的技术能够以最少的硬件修改实现 DRAM 计算,但它们的缺点之一是单元中剩余的初始电荷可能会危及 TRA 的准确性 [54][55]。为了提高准确度,Ambit 将两个操作数复制到靠迳感应放大器的底部行,以保持完全充电状态。 这种复制操作对于保护原始数据免受基于电荷共享的破坏性计算也是必不可少的。 Ambit 还需要将 1/0 写入第三个单元以在 TRA 之前定义 OR/AND 操作。 尽管 Ambit 在读出放大器附迳保留了几个指定行用于计算以减少复制操作的数量,但它仍然需要大量的周期来处理复杂的布尔运算(例如,执行 XOR 和 XNOR 需要七个周期,四个周期执行与运算)。
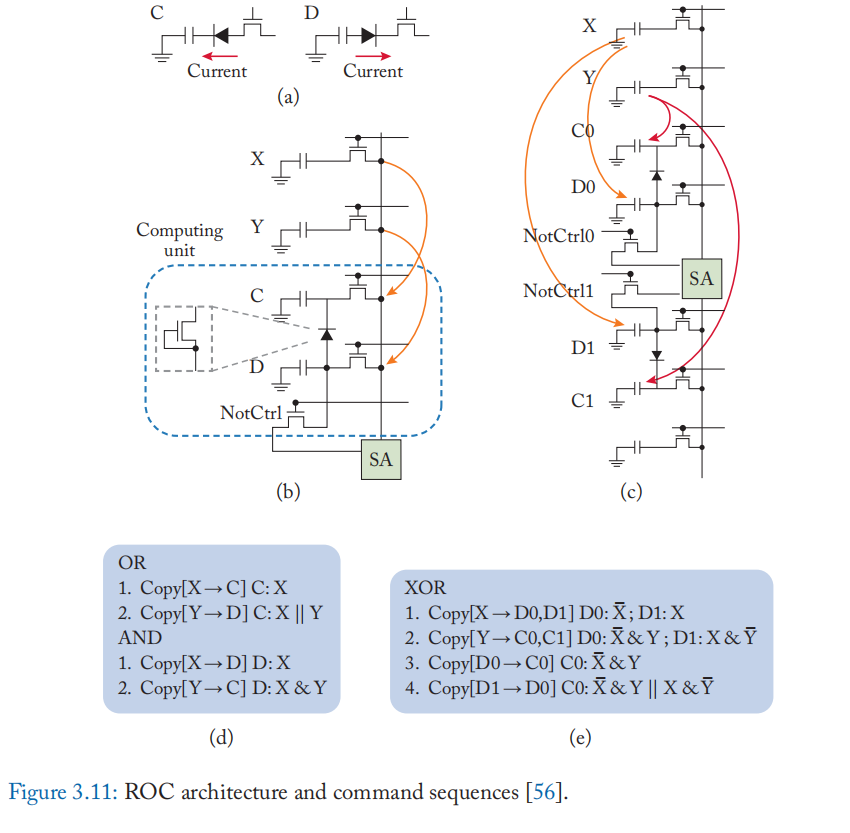
ROC [56] 采用不同的电荷共享方法,利用与电容器连接的二极管的特性,进一步减少逻辑操作的延迟。 如图 3.11a 所示,不管单元 C 的初始状态如何,如果晶体管连接到 \(V_{DD}\),它就会被充电到 1。 同样,如果晶体管接地,则 D 将放电至 0。 因此,C 和 D 的电流是单向的,允许单元 C 和 D 分别表现得像 OR 和 AND 门。 例如,要执行 \(X + Y\) ,将 X 的内容复制到 C,然后将 Y 复制到 D。如果 Y 为 0,则 C 的值仍然是 X 的值; 否则,C 设置为 1。要执行 AND,首先将 X 复制到 D,然后将 Y 复制到 C。仅当 X 和 Y 都为 1 时,D 才会为 1。ROC 的延迟比 Ambit 小,因为它需要 只有两次复制操作来计算结果。 它还需要更小的面积,因为 ROC 在计算过程中只需要两个单元。
为了使操作符功能完整,ROC 在列底部附加了一个存取晶体管(图 3.11b),类似于 Ambit。 他们还提出了一种增强型 ROC 设计,通过向计算电容器添加额外的晶体管和纵向连接来支持传播和移位。 通过同时执行复制和计算,ROC 可以减少计算周期(例如,异或的四个周期,与的两个周期),避免数据损坏和由于单元中保留初始电荷而导致的结果不稳定[56:1]。
3.4.3 DISCUSSION
传统 DRAM 市场已经高度成熟,下一代可能会看到高带宽堆叠存储器的流行和具有计算能力的 DRAM 的出现。 为了保持密度、速度和稳定性作为 DRAM 技术的核心竞争力,潜在的存内计算架构候选者不应该试图重新设计和验证已经成熟了数十年的 DRAM 技术。 我们认为从这个角度来看,单元设计(例如 IM-A 架构)的巨大变化可能不切实际。 还有一个挑战是确保内存中的方法可以跨工艺角和温度工作。 通常,DRAM在考虑工艺角和温度后没有余量; 因此,在典型工况下可以工作的存内计算方法到了实践中无法正常工作,需要做出一些权衡(例如,增加电容器尺寸或减少刷新时间)。 此外,最迳的研究发现,只需对外围设备和/或命令序列进行细微修改,就可以将 DRAM 转变为存内计算设备。 随着这些操作在关键工作负载中的引人注目的用例和编程模型的开发,我们期望这些内存技术在商业 DRAM 市场上引起更多关注。
Chapter 4. Computing with SRAMs
在上一章中,我们看到了 DRAM 如何用于存内/迳存计算。与DRAM相比,静态RAM(SRAM)具有更短的数据访问延迟,也是一种成熟的存储技术。 在本章中,我们将探讨 SRAM 存内计算的机遇和挑战。 我们将从第 4.1 节中的 SRAM 基础开始,然后在第 4.2 节中介绍基于数字的 SRAM 计算方法,在第 4.3 节中介绍基于模拟/混合信号的方法。 4.4 节简要讨论了迳 SRAM 计算。
4.1 SRAM BASICS AND CACHE GEOMETRY
SRAM是当今计算机系统中广泛使用的一种重要类型的存储器。 存储的数据是静态的,不需要定期刷新。 SRAM 中的数据也是易失性的,因此 SRAM 是一种临时数据存储。 SRAM 用于大多数现代 CPU 的片上缓存和寄存器文件。 与 DRAM 相比,SRAM 具有更大、更复杂的位单元。因此,SRAM具有较低的数据密度和较高的制造成本,通常用于容量较小的存储器结构。 另一方面,SRAM 的存取速度比 DRAM 快。 因此 SRAM 适用于高速缓存和位于存储器层次结构顶部的寄存器。
典型的 SRAM 具有如图 4.1 所示的 6 晶体管单元结构。 该单元由一对交叉耦合的反相器和两个存取晶体管组成。 交叉耦合的反相器有两个稳定状态,因此可以存储一位数据。 存取晶体管用于读取和写入数据位[57]。
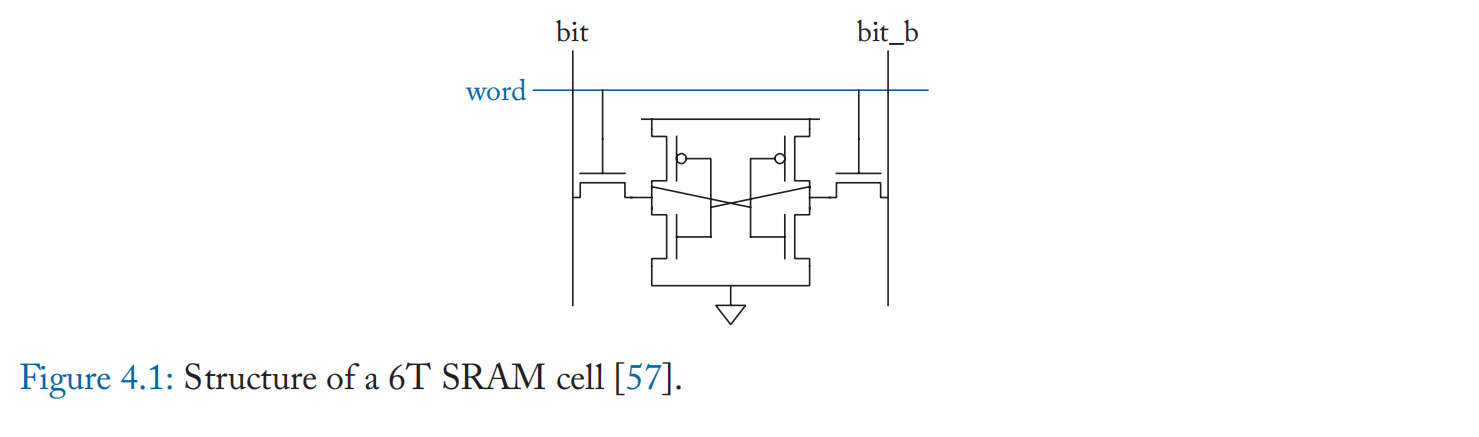
SRAM 单元以阵列形式排列,以实现高效的数据访问。 在 SRAM 阵列中,一条字线跨越一行并通过存取晶体管连接到该行中的所有单元。 同样,一对位线 (BL/BLB) 跨越一列并连接到该列中的所有单元。 一些外围逻辑放置在每个 SRAM 阵列周围,协助从阵列访问数据。 行地址解码器连接到所有字线,用于根据行地址激活正确的字线。 BL 外设包括读出放大器、位线预充电器和写入驱动器。 在读取周期中,首先对位线进行预充电,以准备读取,然后激活目标字线,并且在每个位线对处,BL 或 BLB 保持高电平,具体取决于相应的位单元值。 在一个写周期中,每个写驱动器将 BL 或 BLB 提升到高电压,具体取决于要写入的所需值。 然后目标字线被激活,每个单元的交叉耦合反相器根据 BL/BLB 值改变到新的状态。
SRAM单元必须在读写过程中以及数据保持阶段保持存储数据的正确性。 SRAM 单元稳定性的定量测量是噪声容限,它是不会导致 SRAM 单元中的数据损坏的最大电噪声水平。
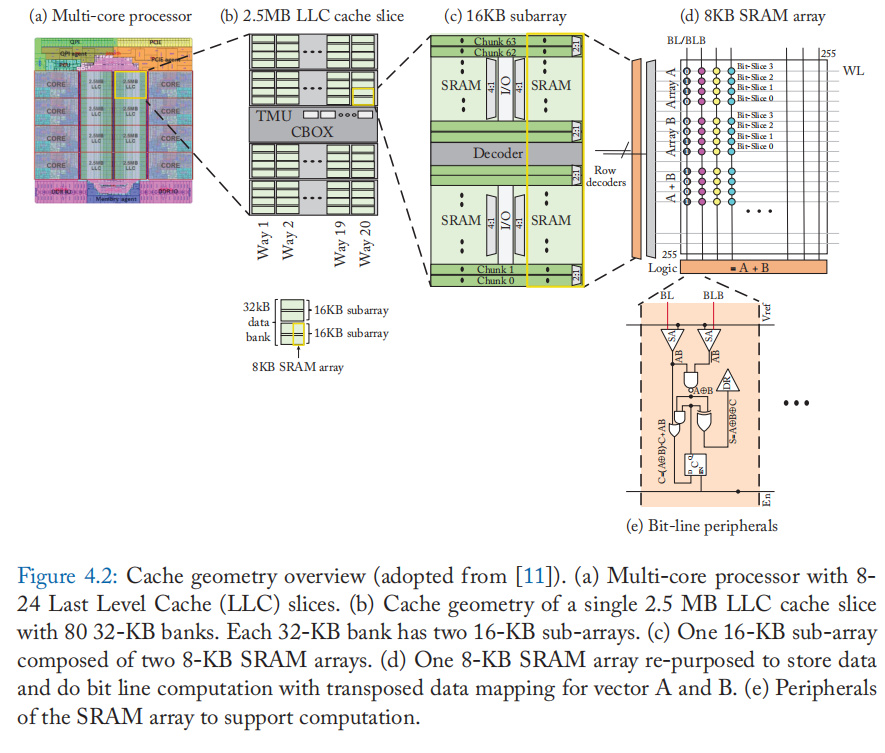
我们简要概述了现代处理器中缓存的几何结构。 图 4.2 展示了一个多核处理器,它以英特尔的 Xeon 处理器 [58][59] 为模型松散地建模。 共享的最后一级缓存 (LLC) 分布在许多片中(此处讨论的至强 E5 为 8-14),内核可以通过共享环互连(图中未显示)访问这些片。 图 4.2b 显示了 LLC 缓存的一部分。 该切片有 80 个 32 KB 的存储库,以 20 种方式组织。
每个存储库由两个 16 KB 子阵列连接。 图 4.2c 显示了一个 16 KB 子阵列的内部结构,由 8 KB SRAM 阵列组成。 图 4.2d 显示了一个 8 KB SRAM 阵列。 SRAM 阵列被组织成多行数据存储位单元。 同一行的位单元共用一条字线,而同一列的位单元共用一对位线。
SRAM 阵列中的 SRAM 存内向量算术运算(图 4.2d)可以通过将数千个 SRAM 阵列(Xeon E5 中的 4480 个阵列)重新用于向量计算单元来利用高速缓存结构中可用的大规模并行性。 我们观察到 LLC 访问延迟主要受高速缓存片内的线路延迟、访问上层高速缓存控制结构和片上网络的影响。 因此,虽然典型的 LLC 访问可能需要 30 个周期,但 SRAM 阵列访问仅需要 1 个周期(在 4 GHz 时钟下 [58:1])。 幸运的是,SRAM 存内计算架构只需要 SRAM 阵列访问,并且不会产生传统高速缓存访问的开销。 因此,可以节省花费在连线和更高级别的内存层次结构上的大量能源和时间。
4.2 DIGITAL COMPUTING APPROACHES
第 4.1 节介绍了 LLC 的结构以及将 SRAM 阵列重新用作计算单元的机会。 基于 LLC 的 in-SRAM 计算与专用加速器芯片等其他计算平台相比具有独特的优势。 首先,减少了 CPU 和计算单元之间的数据移动。 对于具有专用协处理器(如 GPU)的系统,由于数据通过 PCIe 总线在主机内存和设备之间传输,因此存在通信开销。 缓存内计算不涉及额外的设备,因此避免了上述瓶颈。 其次,SRAM 内计算具有成本效益。
尽管 CPU 和协处理器的更紧密的集成可以缓解上述通信问题,但芯片整体面积可能太大(例如,Titan Xp GPU 在 16 nm 中为 \(471 mm^2\))。 相比之下,SRAM 存内计算算法所需的额外面积为 22 nm 中的 \(15.8 mm^2\),同时提供的计算资源比上面的 GPU 多 9 倍。
就热设计功耗 (TDP) 而言,SRAM 内计算也更节能。 包括计算单元在内的至强处理器的 TDP 为 296 W,而 GPU 的 TDP 为 640 W。第三,缓存内计算使计算和存储之间的片上资源划分更加高效和灵活。 与片上内存较小的GPU相比,CPU缓存可以灵活分区,为内存受限的应用程序提供较大的缓冲空间。 另一方面,对于计算密集型工作负载,大量的计算单元也可以满足要求。
在本节的其余部分,我们将讨论 SRAM 中的计算细节,包括 SRAM 中支持的逻辑操作、整数/浮点运算的位串行算法以及数据转置的机制。
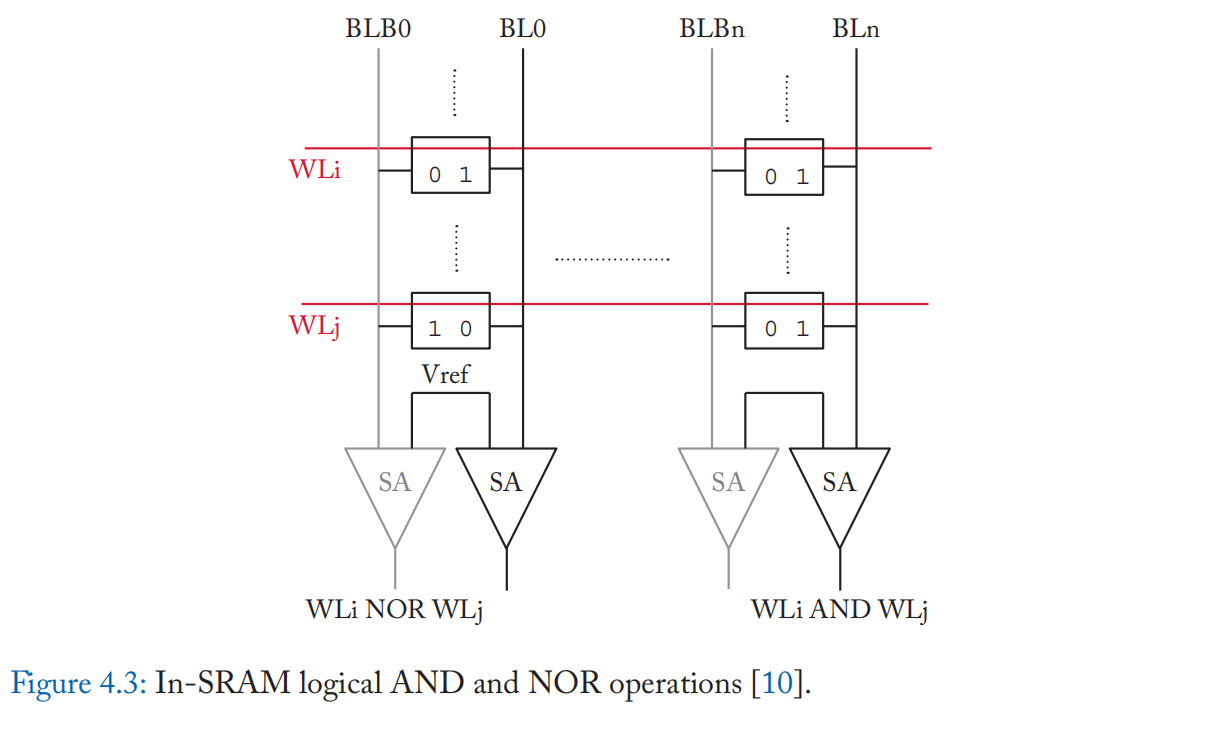
逻辑运算:SRAM 中的逻辑运算对存储在 SRAM 阵列中多条字线上的数据执行逐元素逻辑运算(例如,AND、OR、NOR)。 SRAM 存内计算可以通过同时激活字线并在位线上进行感应来实现 [60]。 Element-wise AND 和 NOR 是两个基本操作,因为它们是感测 BL 和 BLB 的直接结果。 具体而言,在一个计算周期,两条字线被激活,如果一个位单元存储数据“0”,则预充电位线(BL)将被下拉至低于\(V_{ref}\)。 如果所有位单元存储数据“1”,则BL将保持在预充电高值。 通过使用单端检测放大器检测 BL 上的电压,可以对存储在位单元中的数据计算逻辑与。 类似地,逻辑 NOR 可以通过检测位线 (BLB) 来计算,因为只有当所有数据都为“0”时,补码数据都为“1”时,BLB 将保持高电平。 所需的额外硬件包括用于激活字线的额外行解码器,以及用于分别感测连接到位单元的 BL 和 BLB 的单端感测放大器(与普通 SRAM 阵列中的差分感测放大器相反)。 图 4.3 总结了 SRAM 内逻辑与和或非操作的实现。 与前一章讨论的基于电荷共享的 DRAM 计算技术相比,上面描述的 SRAM 位线计算技术没有破坏性(即,不需要在操作之前复制操作数)。 此外,由于使用了单端读出放大器,因此可以在 BL 和 BLB 中同时执行两个独立的逻辑操作[10:2]。
在 SRAM 存内计算过程中,由于激活了多条字线,因此电路条件与正常 SRAM 数据访问不同,有必要评估计算的鲁棒性。 考虑以下场景。 同一位线中的两个位单元分别存储数据值“0”和“1”。 在计算周期中,随着位线放电,值为“1”的位单元处于类似于正常写入的状态,BL放电且存取晶体管导通。 由于放电位线电压迳高于0,因此产生的扰动相对较低。 此外,由于只激活了两行,因此数据损坏的可能性低于激活更多行的可能性。 此外,对 SRAM 阵列的一些修改可以减轻干扰。 字线被欠驱动以减弱存取晶体管,并且为单元中的交叉耦合反相器供电的电源线保持高电平。 这种修改后的字线电压可防止 SRAM 存内计算过程中的数据损坏。
通过检测到两条字线的元素 AND 和 NOR 结果,可以将逻辑添加到阵列外围设备以实现其他逻辑操作,例如 NOT、OR 和 XOR [10:3]。例如,\(A\) \(XOR\) \(B\) \(= (A\) \(AND\) \(B)\) \(NOR\) $(A $ \(NOR\) \(B)\)。 还可以实现“比较”等更复杂的操作,对所有按位 XOR 结果进行线上的或非运算会产生“比较”结果。
整数的位串行算法: SRAM 中的算术运算是由上面讨论的逻辑运算构建的。计算模式的不同之处在于算术计算是以位串行格式完成的,而不是位并行格式,其中一个操作数的多个位被读出并作为一个整体进行处理。 对于位串行计算,数据以转置布局映射到 SRAM 阵列。 在转置映射中,数据的所有位都映射到同一位线,而不是像正常映射中那样映射到同一字线。 两个操作数和运算结果都映射到同一位线及其所有数据位。
位串行算法每个周期处理两个操作数中的一对位,从最低有效位开始。 额外的逻辑门和寄存器被集成到位线外设中,作为位串行算法步骤的额外处理元件,例如 1 位全加器。 在每个位线,每个周期都可以写回一个结果位。 由于每个周期的数据读取、处理和回写,SRAM 内计算的频率低于正常的数据读/写操作。
这种位串行计算格式在 SRAM 计算中比位并行更有效。 在用于算术的位并行格式中,进位位需要跨位线传播,导致额外的通信困难。 相反,在位串行计算中,每个进位位作为位线外围设备的一部分存储在锁存器中,使进位传播在所有位线计算单元之间完全并行。
还有其他通过模拟计算提出的 SRAM 存内计算技术(详见第 4.3 节)。 作为比较,数字域的位串行计算与CMOS兼容,不需要昂贵的ADC。 这种低开销的数字设计与现有处理器兼容并且更易于采用。 此外,模拟计算通常用于有限的数值精度,而位串行计算可以灵活地支持具有可重构精度的操作数,例如整数和浮点数。
上面的位串行处理图与关联处理(AP)有相似之处,这是一个历史思想,最迳也受到关注,因为它在迳/内存计算中的潜在应用[61][62]。 在 AP 中,计算也是以位串行和字并行的方式进行的。 但是,每个单位操作都是通过匹配表中操作数的模式并查找结果来完成的,而 SRAM 存内计算通过逻辑门实现 1 位操作。 因此,传统的 AP 基于 CAM(内容可寻址存储器),而不是 SRAM。
接下来,我们将讨论一些典型算术运算的详细位串行算法。
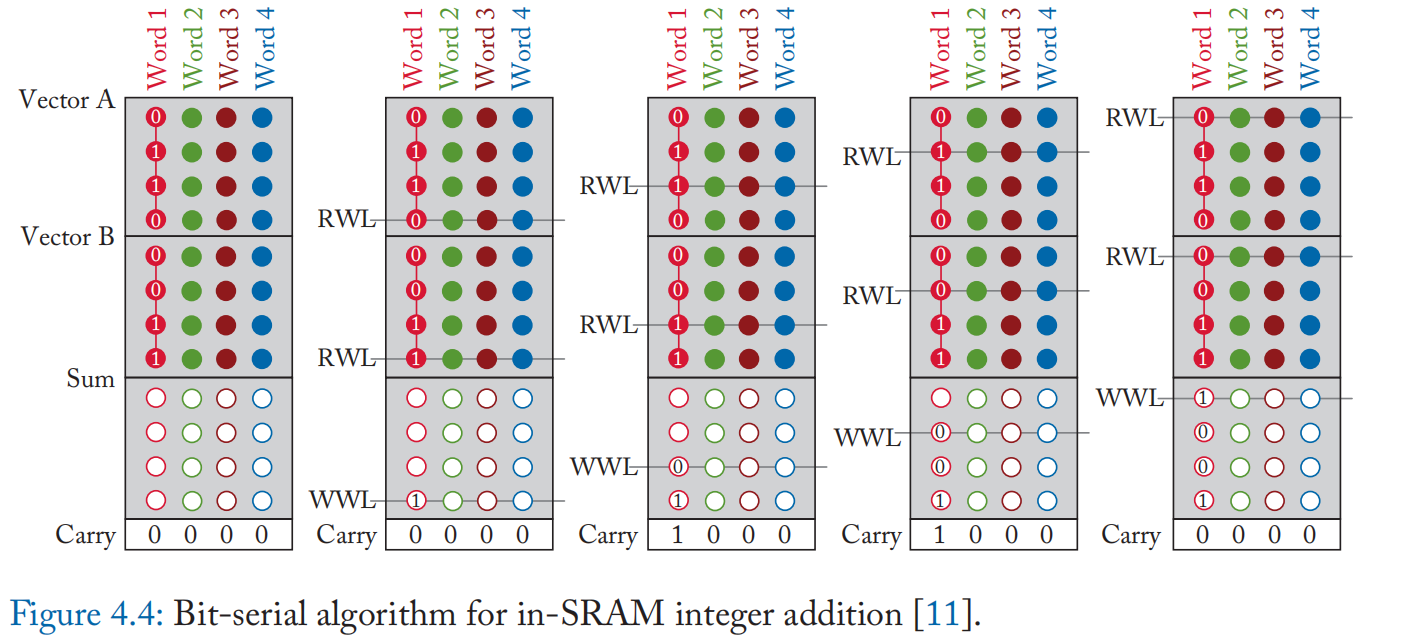
对于位串行加法,一个寄存器用于进位位。 每个周期,全加器从每个操作数和进位寄存器中取一位,计算和位和输出进位。 然后进位位寄存器更新其值,并将和位写回数组。 图 4.4 显示了逐个周期的位串行加法算法,具有 4 位操作数和 4 个并行操作[11:1]。
位串行乘法被实现为一系列移位和加法。 一个额外的寄存器(称为标签寄存器)用于辅助计算。 整个执行流程是一个嵌套循环。 在外循环中,乘法器的每一位都被迭代。 如果该位为 1,则被乘数被移位并添加到乘积结果中。 if 语句是通过谓词执行来实现的,使用标记位作为条件。 在内循环中,首先将乘法器的当前位复制到标记位。 然后通过位串行加法将被乘数预测累加到部分乘积结果中。 通过选择部分乘积结果的字线索引进行累加来隐式执行移位。 在这样的位串行方式中,位串行乘法的性能优化为前导零搜索,\(n^2+3n-3\)个周期完成n位乘法运算。
一种对位串行乘法的优化方式是通过跳过对前导零位的计算来减少具有较小有效位宽度的操作数的周期数。 此外,如果来自被乘数的所有位都为零,则可以在一次迭代中跳过部分和累加。
浮点数的位串行算法: 为了支持浮点数的运算,位序列算法在整数算术运算的基础上进行了修改和扩展。
对于浮点乘法/除法,该算法对指数位应用位串行加法/减法,对尾数位应用位串行乘法/除法,并对符号位应用逻辑异或。
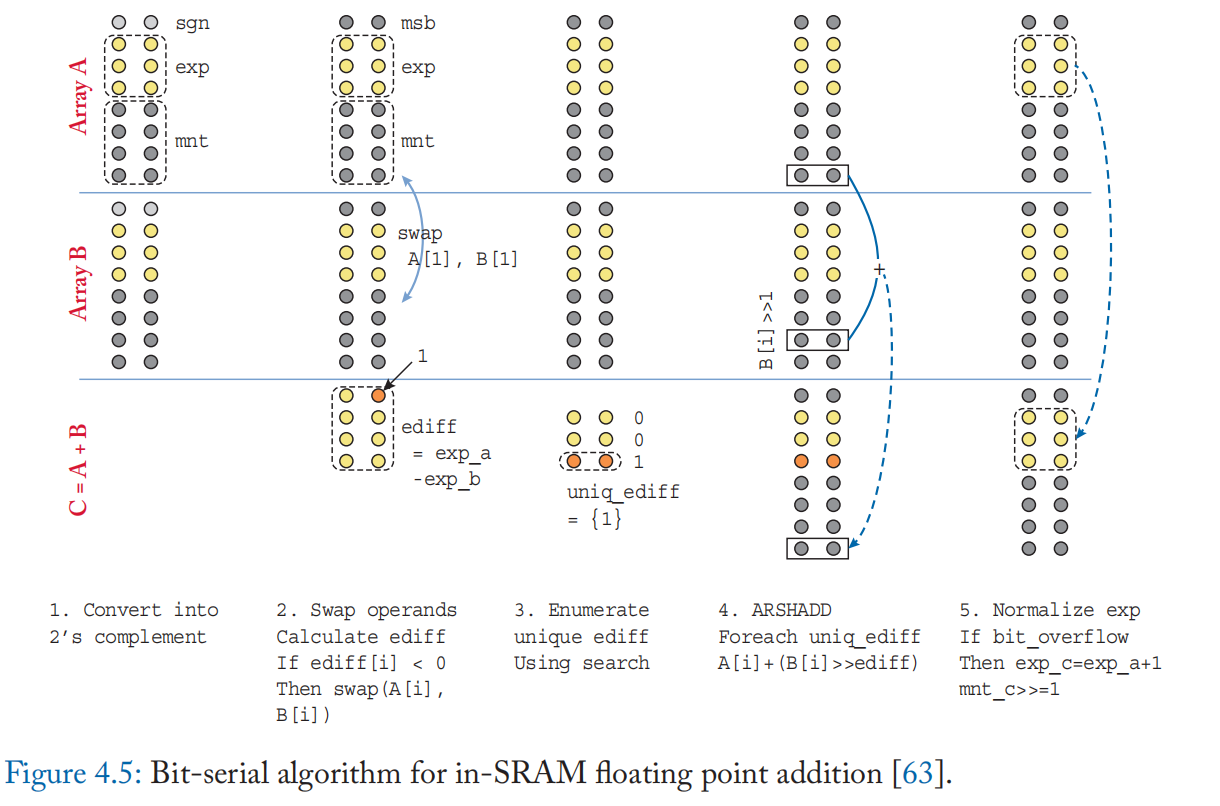
浮点加法/减法涉及具有不同偏移量的移位,下面将逐步详细讨论(以加法为例)。 这五个步骤如图 4.5 所示。
(1) 首先,为加法做准备,将尾数位的前导 1 前置,并根据符号位将尾数位转换为基 2 的补码格式。
(2) 然后计算指数之间的差值(图 4.5 中的 ediff[i])。 对于差值为负数的情况,交换两个操作数并对差取反。 这是为了将指数求差的数量减少大约一半(步骤 4 中将重复这一步)。
(3) 然后依次对所有不同的指数差进行尾数位的移位和加法。这需要基于指数的动态范围很小,几乎没有明显的指数差异。 在迭代之前,执行搜索过程以找出阵列中的所有明显差异。 首先进行前导零搜索以确定要搜索的差值的上限。 对特定差值的搜索在两个周期中实现:在第一个周期中,激活与目标差中的位值 1 对应的所有字线,并在位线上感测逻辑与。 在第二个周期中,激活目标差中位值0对应的所有字线; 逻辑 NOR 被检测并进一步与来自第一个循环的结果进行与运算,作为最终的搜索命中向量结果。
(4) 对于所有不同的差值,将第二个操作数的尾数位移位并与第一个操作数相加。 在位串行计算中,移位不需要额外的周期,因为它可以通过激活字线来实现正确的位位置。
(5) 最后,总和被转换回有符号格式。 如果和中有溢出,则将其右移并增加指数位[63]。
数据转置: 位串行算法要求数据在 SRAM 阵列中应采用转置格式。 它可以通过软件操作或专用硬件单元来实现。 在软件中转置需要程序员的努力,并且可以用于在运行时不改变的数据操作数。
或者,可以应用硬件转置存储单元 (TMU)。 当数据被动态修改时,有必要加入这一单元。 TMU 放置在缓存控制盒(图 4.2b 中的 C-BOX)中,可以按常规布局读入数据并以转置格式发送出去(对于位串行计算操作数),反之亦然(对于 位串行结果)。 TMU 可以通过具有二维访问的 8T SRAM 阵列来实现 [64][65]。 存储单元中的额外存取晶体管支持垂直和水平方向的数据存取。 几个 TMU 足以使 SRAM 阵列之间的互连带宽饱和。
注:有一种误解是SRAM 存内计算降低了 SRAM 密度和/或使 SRAM 访问时间变慢,因此将 SRAM 存内计算集成到 CPU 缓存中具有挑战性。这是不正确的,原因如下。
• IM-A(内存中(阵列))计算改变了 SRAM 单元和阵列结构,降低了 SRAM 密度。 然而,许多 IM-P(内存中(外设))方法保持 SRAM 阵列不变,并通过在外设中添加少量逻辑来实现内存计算。 一些 IM-P 方法进一步声称它们可以添加到原始缓存结构中,从而保持缓存功能不变。
• 如上所述,许多 IM-P 方法(第 4.2 节)保持 SRAM 结构不变。 因此,对于常规读取和写入,缓存访问延迟不会受到影响。
4.3 ANALOG AND DIGITAL MIXED-SIGNAL APPROACHES
SRAM 的高可用性引起了 SRAM 位单元在模拟域中进行内存计算的关注。 这些技术通常被称为混合信号计算,因为它们在位单元中执行模拟计算,而计算结果在被调用或写回 SRAM 阵列之前被转换为数字值。
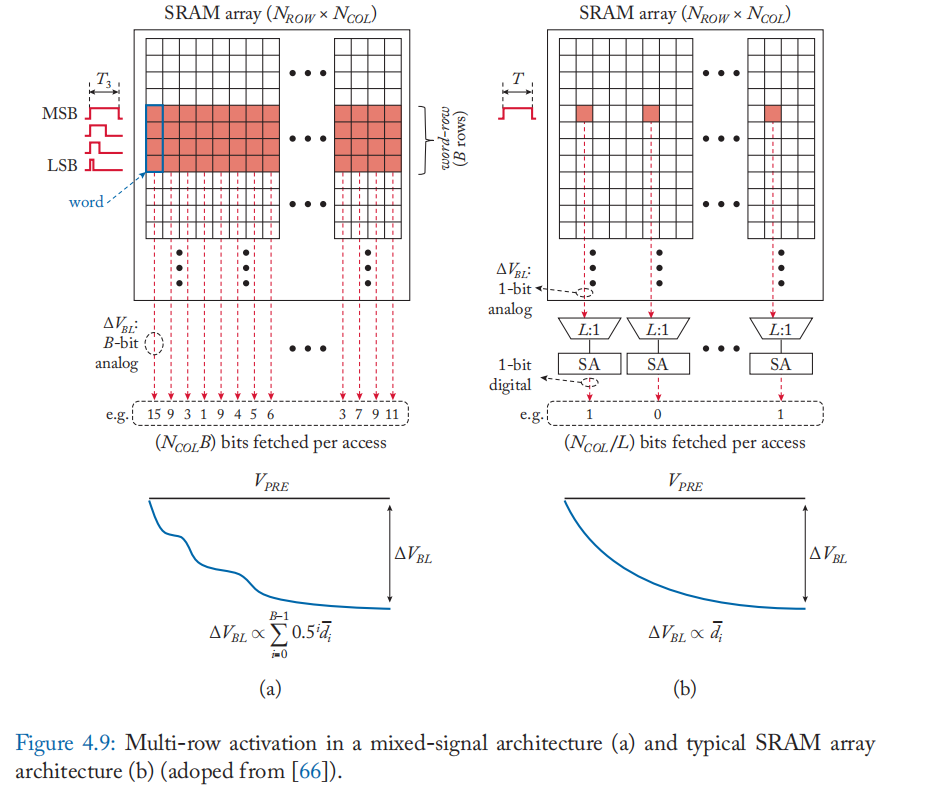
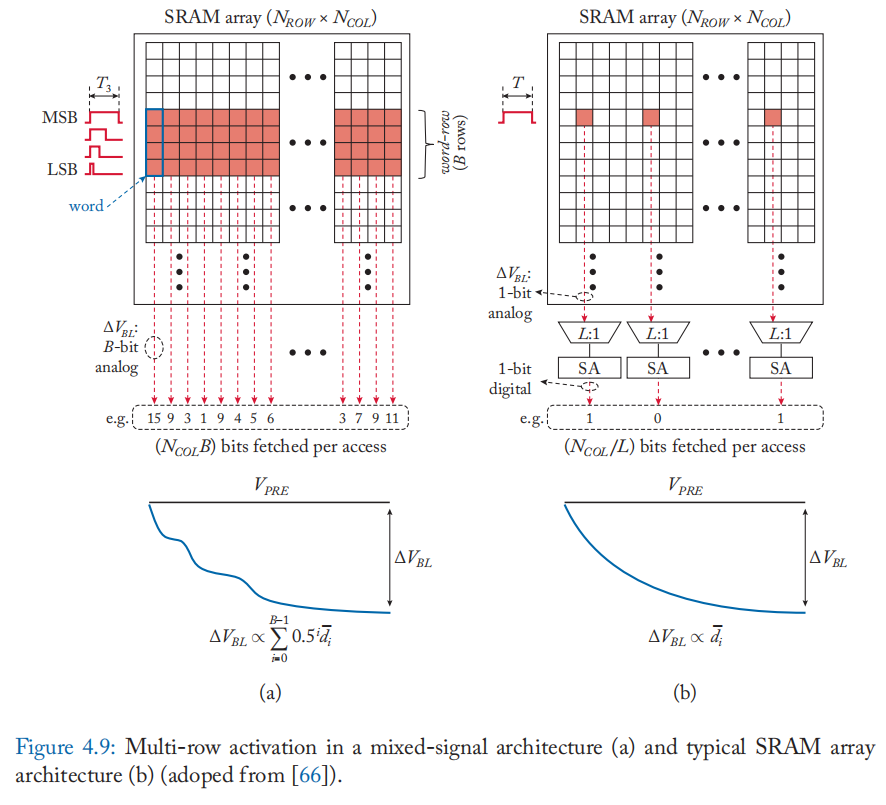
传统架构和数字存内计算中的 SRAM 通常使用 \(L : 1\) 列多路复用器(通常为 \(L = 4\sim32\))来容纳大型读出放大器,如图 4.9b 所示。 因此,每次对阵列的访问所获取的位数被限制为 \(N_{COL}/L\) 位。 另一方面,混合信号计算通常由通过多行激活跨不同字线中的位单元的模拟计算组成,而不涉及在读出放大器处的感测(例如,图 4.9a)。 因此,对\(\alpha\)行激活的单次访问可以处理 \(\alpha N_{COL}\) 位,只需要更少的预充电周期来读取和处理相同数量的数据。 虽然这带来了功耗和吞吐量增益,但混合信号位线计算的模拟性质会降低数据和计算的保真度/准确性 [66]。
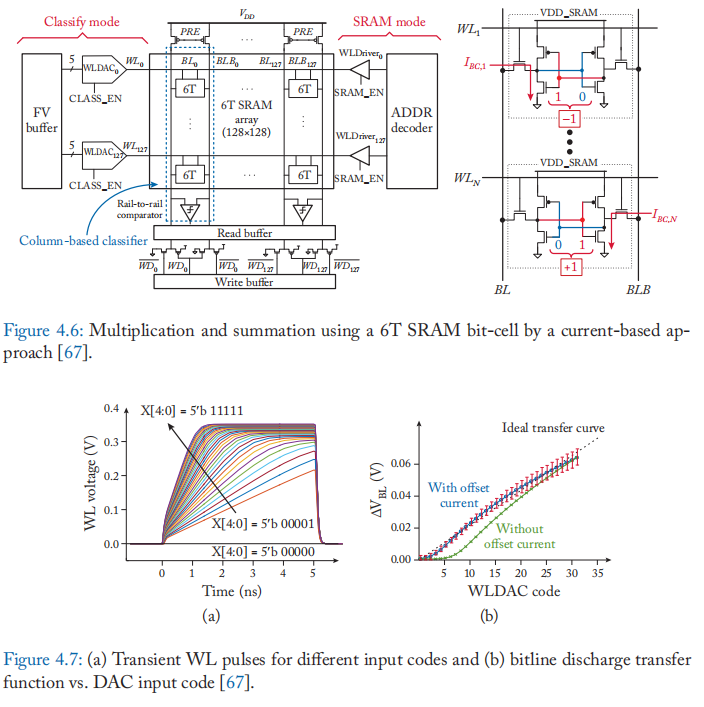
基于电流和基于电荷的方法: 基于 SRAM 的混合信号计算大致可以分为基于电流的方法和基于电荷的方法。 基于电流的方法使用位单元中 MOSFET 的电流-电压 (IV) 特性来执行乘法运算。 例如,张等 人的工作 [67] 。将在迭代中重复使用的操作数(1 位)(例如机器学习算法中的权重)存储在 SRAM 阵列中,并通过 DAC 将另一个操作数(5 位)转换为字线电压。 字线电压引发相应的位单元电流 \(I_{BC}\),如图 4.6 所示。 根据存储在位单元中的数据,\(I_{BC}\) 应用于 BL或 BLB,可以是做 \(I_{BC}\) 与 \(-1/1\) 相乘。 来自列上所有激活单元的电流在 BL/BLB 中汇总在一起,导致位线放电和电压降。 电压降的大小与输入向量和阵列中矩阵数据的点积成正比。 使用比较器在计算结束时提供点积的符号。 基于电流的设计容易受到源自位单元变化和 IV 关系非线性的大量电路非理想性的影响。 图 4.7 显示了位线放电传递函数与 DAC 输入码的关系,展现了该方法的标准差(由易变性引发)和非线性。
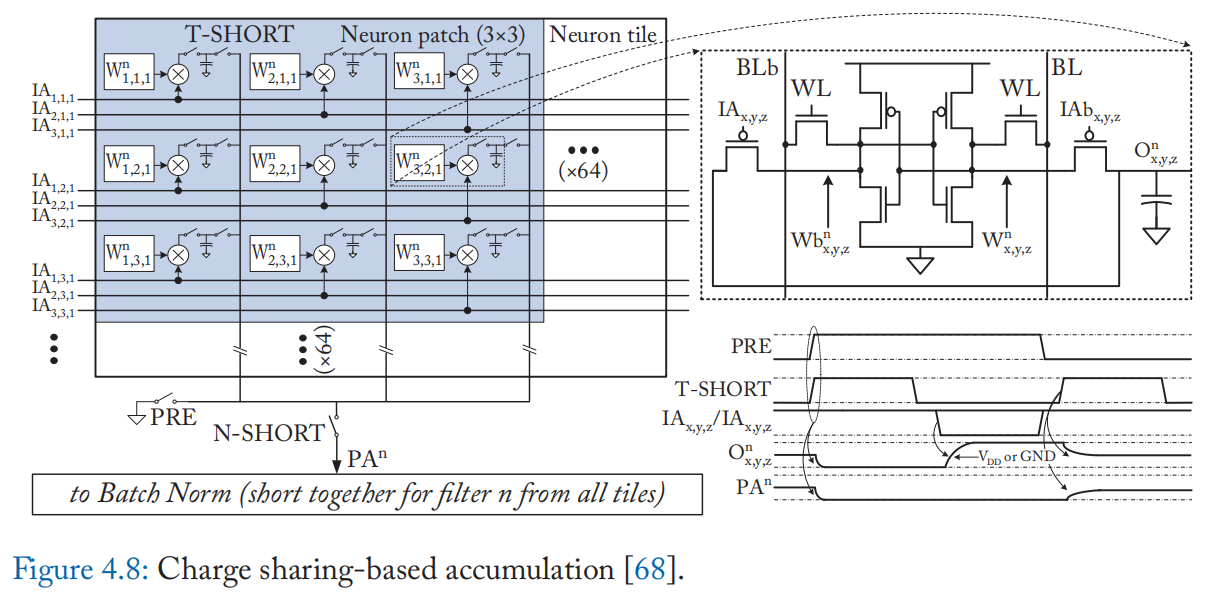
此外还有基于电荷的方法,即使用电荷共享技术来执行乘法。 例如,Valavi 等人的工作 [68]。 实现了一个连接到 8T 位单元的电容器以本地累加乘法(图 4.8)。 二进制乘法(XNOR 或 AND)在 8T 位单元上以数字方式执行,根据二进制积有条件地对本地电容器充电。 然后,来自不同单元的结果通过由 T-SHORT 开关控制的局部电容器的电荷共享来累积。 与标准 6T SRAM 单元相比,添加两个晶体管和一个电容器会产生 1:8 的面积开销。 由于 I-V 转换的 BL/BLB 动态范围有限,基于电流的设计可能会受到神经元精度的严格限制,但电荷域积累可以从短路电容的更大动态范围中受益。 此外,电容器不易受温度和工艺引起的变化和非线性的影响。 尽管它们仅支持二进制输入,但与软件实现相比,制造芯片的精度损失很小(0.2-0.3%)。 一些其他设计不使用专用电容器,而是使用位线的固有电容[69]。
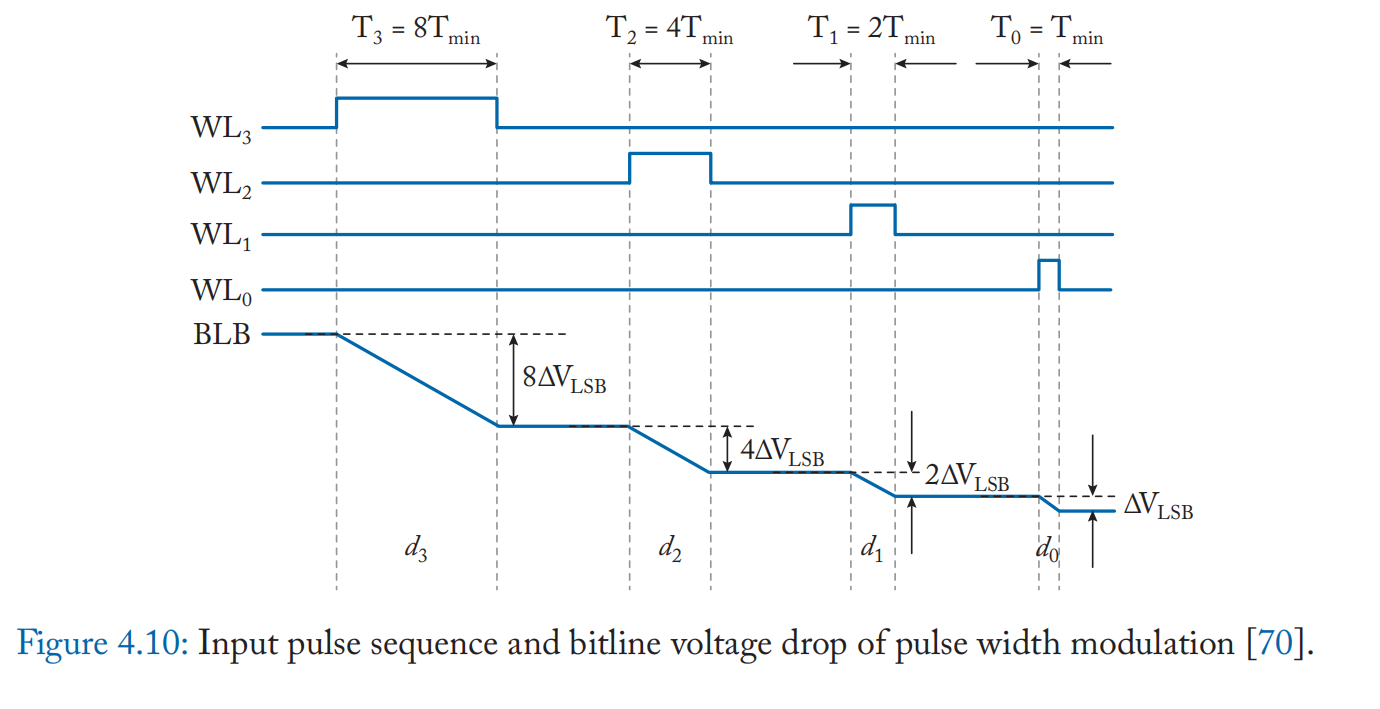
提高位精度: 基于 SRAM 的设计的限制之一是位精度。为了支持超过单个位的位精度,需要将一个值映射到多个位单元,因为 SRAM 位单元本质上是一个单级单元 (SLC)。 此外,必须精确调制输入值并将其馈送到具有相应值的行。 Ming 等人的工作[66:1]采用垂直数据映射和脉宽调制(PWM)来支持多位操作。 如图 4.9a 所示,数据垂直存储在一列中,类似于 4.2 节中讨论的位串行计算方法。 输入脉冲保持高电平持续时间 \(T_i\propto 2^i\),与位 \(b_i\) 的位置成指数关系。 示例脉冲序列如图 4.10 所示。 这会产生 BL 电压降 \(V_{BL}\) 和 BLB 电压降 \(V_{BLB}\),如下所示:
其中 \(T_{min}\), \(C_{BL}\),\(R_{BL}\) 是 LSB 脉冲宽度 (\(=T_0\))、BL 预充电电压、位线电容和 BL 放电路径的标称电阻。 输入 D 是一个 n 位十进制数,由下式给出 \(D=\sum_{i=0}^{n-1}2^id_i\),要成立等式,必须满足以下条件:(1)\(T_i \ll R_iC_{BL}\)(\(R_i\) 是第 i 个位单元的放电路径电阻),(2)\(T_i=2^iT_{min}\),(3)\(R_i=R_{BL}\)(行与行前没有差别) (4) \(R_{BL}\) 不随 \(V_{BL}\) 变化。 在这些条件下,无需对 SRAM 阵列进行任何修改,就可以计算存储在同一列中的操作数的绝对差的总和 [70]、加法和减法 [66:2] 。 加法 \(A +B\)很自然地通过施加脉冲到包含 A 和 B 的字行得到
而减法要求 B 以位翻转的方式存储补码。 或者,可以使用副本位单元 [66:3] 来促进访问翻转数据。
乘法是在外部混合信号乘法单元中执行的。 Kang 等人的工作 [71] 采用基于再分配的乘法器,该乘法器使用电容器的电荷共享来执行除以二和累加并输出缩放的乘积。 操作数 B 以二进制格式提供给乘法器,符号位单独处理。点积的计算方法是使用阵列中各列共享的轨道对参与列中乘法器的输出进行电荷共享。 正负值分别汇总,在ADC后减去负值之和。
使用 PWM 进行多行读取会受到多个电路非理想性的影响。 多行读取过程的非线性的一个原因是来自位单元中的存取和下拉晶体管中的放电路径的电阻会随电压变化。 此外,读取精度可能会受到局部晶体管在位单元之间的阈值电压不匹配的影响,这是由随机掺杂剂波动 [72] 和 PWM 脉冲的有限转换时间引起的。 模拟乘法器也可能具有非理想性。 考虑到这些因素,Kang 等人的报告[66:4]说,超过 4 位的多行 PWM 激活具有挑战性。 他们提出了一种分段读取技术,将具有更高位精度(例如 \(n=8\) 位)的数据分为两部分,将上半字(BLM)和下半字(BLL)存储在相邻的列中。 该技术通过引入一个调谐电容器将 BLM 和 BLL 的位线电容 \(C_M:C_L\) 的比值修改为 \(2^{(n/2)}\) 。 BLM 和 BLL 的电荷共享会产生位线电压降
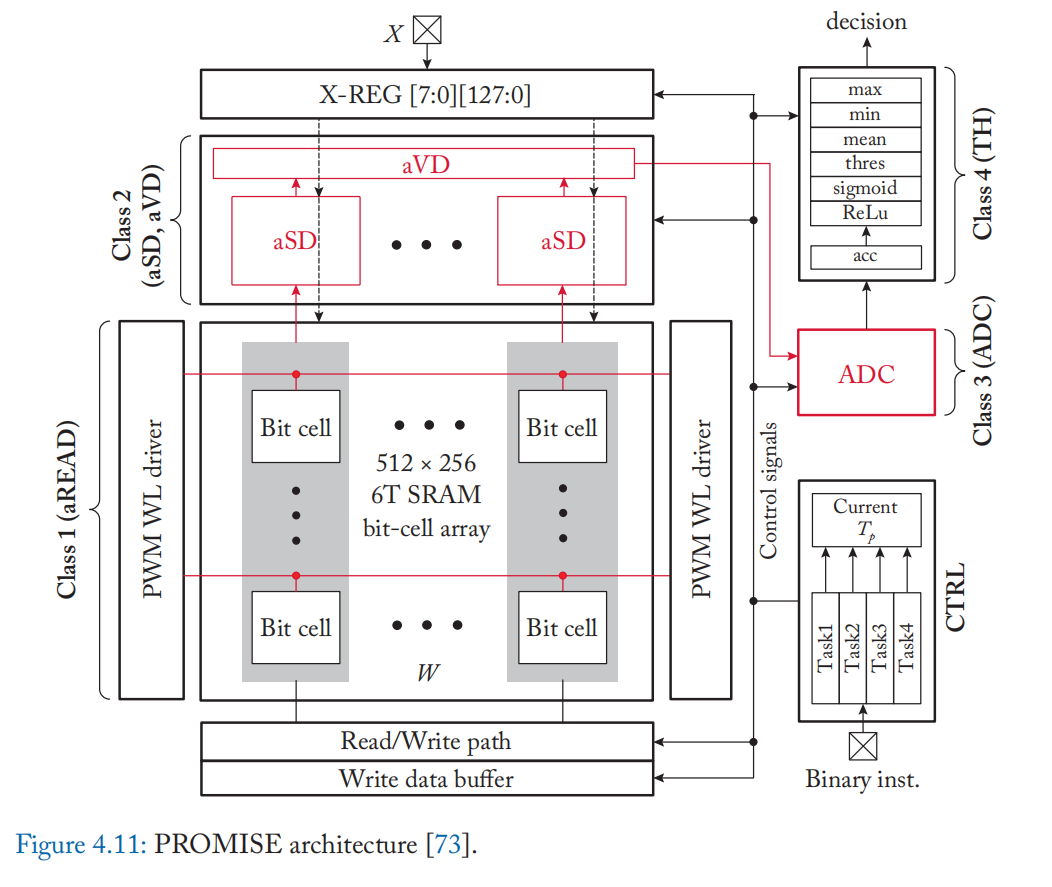
混合精度计算的执行模型和 ISA PROMISE [73] 扩展了 PWM 调制混合信号处理,以支持机器学习算法中的各种操作。 PROMISE 具有模拟标量距离 (aSD) 模块,该模块使用混合信号处理为每列生成一个标量距离,以及模拟矢量距离 (aVD) 模块,该模块通过共享来自 aSD 模块的所有模拟输出的电荷来执行聚合,如图所示 在图 4.11 中。 PROMISE 有一个 4 级流水线:(1)aRead(模拟读取,aADD,aSUB); (2) aSD 和 aVD(比较、绝对值、平方、乘法); (3) ADC; (4) TH(对来自ADC的数字化结果进行累加、均值、阈值、最大值、最小值、sigmoid、ReLU)。 使用开关和电容器临时保持输出的模拟触发器支持流水线模拟值。 可以使用类似指令集架构 (ISA) 的超大指令宽度 (VLIW) 来提供每个流水线阶段的指令。 PROMISE 还提出了一个编译器,它采用 Julia 编写的程序并输出 PROMISE ISA 指令,同时考虑到架构的管道和延迟约束。 编译器可以通过应用模拟误差模型、改变 aRead 的摆动电压(图 4.9 中的 \(V_{BL}\))以及在 ISA 中对其进行编码来探索精度与能量的权衡。 aRead 的输出遵循正态分布 $\hat{W}\sim N(W,\sigma^2_M) \(,其标准偏差\)\sigma_M$与摆幅电压参数成反比。
4.3.1 DISCUSSION
SRAM 中混合信号计算的挑战之一是保持足够的摆幅电压 (\(V_{BL}\)) 范围以保持单元稳定性和准确性。 过大的摆幅电压会导致读取干扰,从而在读取时破坏单元内容。 另一方面,过小的摆幅电压会增加电路非理想性影响计算结果的可能性,从而降低精度。 虽然摆幅电压可以通过字线电压、脉冲宽度(对于 PWM 调制输入)等进行调整,但摆幅电压的约束仍然限制了输出分辨率。
一些工作添加了另一个晶体管以将位单元与大电压摆动隔离。 然而,这样的设计导致更大的位单元面积并降低位单元密度。
单元密度、吞吐量和延迟是效率的重要因素,尤其是对于基于 SRAM 的计算。 与其他存储器相比,SRAM 固有地具有较大的位单元,更不用说基于 SRAM 的 IM-A 架构了。 修改用于模拟计算的标准 6T SRAM 单元会导致内存密度降低,从而限制了无需外部内存流量即可在设备上运行的工作负载类型。 例如,在本节介绍的架构中,基于 6T 的设计的内存密度(KB/mm2,缩放至 65-nm 工艺)最高([67:1] 为 30,[66:5] 为 24),其次是其他设计(10T 设计为 22 个 [69:1],8T1C 设计为 16 个 [68:1])。
计算吞吐量主要取决于密度、精度和加速器设计。 在这些工作中,二元增强分类器 [67:2] 和二元 CNN 加速器 [68:2](无 ADC)实现了高吞吐率(分别为 536 和 1531 GOPS/mm2),而与其他相比,可应用的工作负载受到限制。 采用 8 位计算的架构 [66:6][69:2] 达到 118 和 15 GOPS/mm2。 因此,吞吐量也被灵活性所折衷,即架构在多大程度上被推广到广泛的工作负载类别。
至于延迟,SRAM 上的混合信号计算倾向于实现高时钟频率,尤其是当 SRAM 单元未修改时(例如,1 GHz [66:7])。 因此,单个算术运算的延迟(和能量)可以低于基于数字的对应物。 然而,对于某些模拟操作和 ADC [73:1],可能会出现更大的延迟,它们都位于阵列之外。 这些模拟操作和电路可能成为延迟、面积和吞吐量方面的瓶颈。 例如,执行简单的算术运算并存储结果而不进行聚合可能会导致 ADC 出现严重的瓶颈。 为了达到更高的功效,减少 A/D 转换的次数可能是关键。 还必须仔细评估模拟电路的成本。 同样,保持密度同样重要,因为如果频繁,外部内存流量会迅速消除性能优势。
4.4 NEAR-SRAM COMPUTING
Near-SRAM 计算在有组织的 SRAM 结构附迳放置了额外的计算组件,这与修改 SRAM 阵列或外围设备以进行计算的 in-SRAM 计算形成对比。 1990 年代早期的工作已经提出将迳 SRAM 计算设备作为协处理器。 例如,Terasys [3] 将单比特 ALU 放置在 SRAM 阵列附迳,每条位线一个。 数据从 SRAM 中读出,并通过 ALU 以位串行方式执行计算。 主处理器负责向 SRAM 阵列发送计算指令。
CPU 缓存是使用 SRAM 构建的主要架构组件,因此最迳的许多工作都探索了使用 CPU 缓存进行迳 SRAM 计算的机会。 计算是通过放置在 CPU 缓存层次结构中的定制 PE 来实现的。 为了达到足够的并行度,PE 被放置在最后一级缓存片附迳,在核心和最后一级缓存片之间的数据路径上 [74]。 PE 具有各种类型的实现,包括简单的有序内核、FPGA [75] 等可重新配置的结构,以及针对特定应用的定制逻辑 [76]。 加速的应用程序主要是涉及 CPU 处理的数据密集型操作,例如数据库 [76] 和网络堆栈中的功能 [74:1]。
在简化的编程模型和灵活的计算调度上对迳 SRAM 计算进行了优化。 例如,Livia [75:1] 根据内存层次结构中操作数的位置优化计算的位置(PE 或 CPU 内核),从而减少整体数据移动。
虽然并行度低于in-SRAM计算,但near-SRAM计算不需要对SRAM结构进行低级修改,并且支持不同PE设计的更灵活的计算模式。
Chapter 5. Computing with Non-Volatile Memories
5.1 COMPUTING WITH MEMRISTORS
由于高密度和替代 DRAM 主存储器的潜力,新兴的非易失性存储器 (NVM) 已成为有吸引力的存储器基底。 一些先进的非易失性存储器技术使用称为忆阻器的可编程电阻元件。
忆阻器的特征在于称为忆阻的线性电流-电压 (IV) 特性。 忆阻是根据磁链 \(\Phi_M\) 与已流动的电荷量 \(q\) 之间的关系来定义的,其特征在于以下忆阻函数,它描述了与电荷相关的磁通量随电荷的变化率:
使用电压 \(V(t)=d\Phi_m/dt\) 的时间积分和电流 \(I(t)=dq/dt\) 的时间积分,我们得到:
通过将忆阻视为电荷相关电阻,我们获得了与欧姆定律类似的关系
通过求解电流作为时间的函数
各种忆阻器使用表现出热或离子电阻切换效应的材料系统,例如相变硫属化物和固态电解质。 通过施加足够高的电压,忆阻器单元形成导电细丝,使其能够在高电阻(复位)状态和低电阻(设置)状态之间转换。 这种内部状态变化在没有电源的情况下保持不变,提供非易失性。 按照公式 (5.5) 的关系,通过注入参考电压并通过位线感测来自忆阻器单元的电流来读取数据。 由于忆阻器的线性 IV 特性(图 5.1b),一个单元可以被编程为 \(2^n\) 个不同的状态(通常 n 为 1-5),并通过感测电流大小来解码 n 位数据。 换句话说,忆阻器单元可以用作多级单元(MLC)器件[77]。
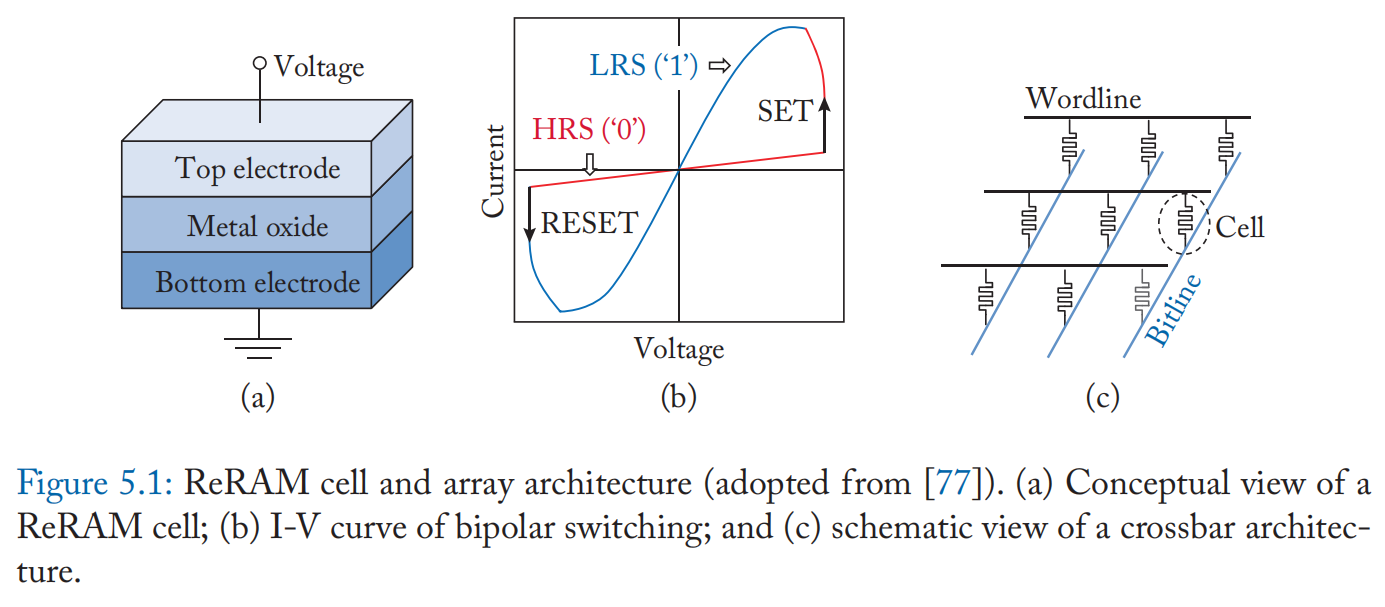
忆阻器的线性 IV 特性被进一步用于模拟域中的内存计算(图 5.2)。 在低于设置和复位阈值电压的区域内改变参考电压仍然保持等式 (5.3) 中的忆阻。 正如等式 (5.5) 所解释的,位线电流可以解释为单元电导和输入电压相乘的结果。 此外,通过激活多行,从共享位线的不同忆阻器单元流出的电流在位线中累积,遵循基尔霍夫定律。 忆阻器的这种模拟计算能力首先被提出用于加速神经网络工作负载,其计算主要由构成密集矩阵乘法的乘法累加 (MAC) 操作主导。 例如,在这样的系统中,权重被存储为忆阻器单元的电导,并且与输入激活成比例的电压被施加到单元上。 如上所述,在每条位线中执行累积[78]。
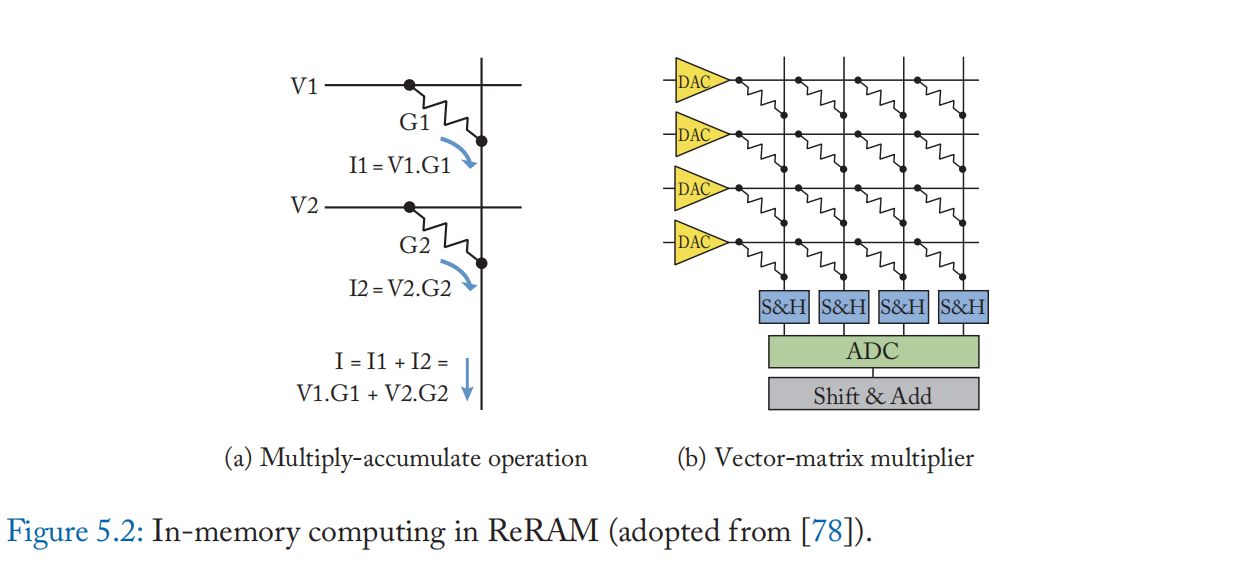
内存计算有几种受欢迎的 NVM 器件:电阻式 RAM(ReRAM 或 RRAM)、相变存储器(PCM)、自旋转移矩磁性 RAM(STT-MRAM)等。在本节中,我们将重点介绍 ReRAM, 使用忆阻器的代表性内存技术。
5.1.1 CHALLENGES IN USING MEMRISTORS
尽管迳年来有大量工作利用 ReRAM 的计算能力,但由于基于忆阻器的 NVM 设备的独特挑战,这种新兴的内存技术仍然是不准确的。 下面我们列出了设计基于忆阻器的内存加速器的一些重要挑战。
• 变化:基于 ReRAM 的器件容易受到器件间和周期间变化的影响。 它们是由工艺变化(即设备的参数与其标称值的偏差)、噪声、非零线电阻、I-V 特性的非线性、电阻漂移(即与时间相关的电阻劣化)等引起的。
尤其是具有严重线路拥塞的大型 ReRAM 阵列,由于电压降和工艺变化,缺陷率高,读写操作可靠性差。 I-V 曲线的非线性导致整个电导范围内的非线性电导。 这会影响每个单元存储的位数以及输入和输出信号的方法。
• 运行成本:编程忆阻器的能量和延迟可能比易失性存储器高得多。 ReRAM 设备需要更高的电压来执行设置和复位操作。 此外,由于存在差异,一些 ReRAM 设备需要写入验证,以在每次编程操作后验证单元内容的完整性。 特别是,需要精确校准 ReRAM 单元内容的神经网络训练和容错工作负载需要频繁的写入操作,从而导致相当大的功耗。
• 写耐久性:与易失性存储器相比,ReRAM 设备的写耐久性(单元寿命)通常受到严重限制。 老化的单元更容易受到传导非线性和写入错误的影响。
• ADC/DAC:ReRAM 中的模拟计算需要使用数模转换器 (DAC) 和模数转换器 (ADC) 与数字电路通信。 但是,ADC 和 DAC 会产生严重的面积/能量开销,并且会降低信号精度。 特别是,ADC 的面积和功耗成本随着 ADC 分辨率(每个模拟信号的位数)呈指数增长,从而影响 ReRAM 加速器的整体存储密度和性能。 ADC/DAC 可以占据神经形态计算设备总面积和功率的 85-98%。
• 数据表示和操作的限制:由于 ReRAM 设备不能存储负电阻,因此在神经网络中支持负权重并不简单。 同样,某些神经网络层无法在 ReRAM 交叉开关中实现(例如,局部响应归一化 (LRN) 层)。
在下一节中,我们将讨论为解决这些挑战而提出的各种方法。
5.1.2 RERAM-BASED IN-MEMORY COMPUTING
许多基于 ReRAM 的内存加速器研究提出了加速神经网络的技术。 广泛使用的神经网络的关键核由点积运算组成。
神经网络的详细工作负载描述在第 6.1 节中描述。 本节介绍了实现内存中算法的基本方法及其对基于 ReRAM 的架构的独特优化。
数据表示:基于 ReRAM 的神经网络计算采用了 1 位到 12 位的突触权重 [79][80]。 虽然半导体研究一直在提高 MLC ReRAM 单元的精度,但仍不足以可靠地支持流行神经网络所需的精度(例如,图像数据的 8 位)。 例如,惠普实验室的点积引擎具有 256 \(\times\) 256 个交叉开关,从 4 位突触权重实现 6 位输出精度,从 6 位突触权重实现 7 位输出精度 [81],考虑到 ReRAM 噪声的影响。 虽然 MLC 单元的精度提高可能会提供更高的密度和计算效率,但挑战仍然存在,因为它增加了精度受到模拟噪声、过程变化和单元非线性影响的机会。 同样,它需要高分辨率 ADC/DAC。
一种解决方案是让几个较小精度的 ReRAM 单元组成一个值。PRIME [77:1] 使用两个 4 位 ReRAM 单元来表示 8 位突触权重,并使用两个 3 位输入电压(从 DAC 馈电)来表示 6 位输入。 ADC 解码点积的高 6 位。 然后外围电路使用加法器和移位器组合两个高位部分和两个低位部分的所有四种组合的 6 位乘积。
ISAAC [78:1] 引入了几种数据表示技术,以支持在具有保守 MLC 参数的 ReRAM 阵列上进行精确的 16 位点积运算。 16 位突触权重存储在单行中的 \(16/v\) 个v 位单元中(例如,\(v=2\)),并且使用 16 个二进制电压电平从 DAC 顺序馈送 16 位输入。 由于 DAC 需要读取 16 位数的单个位,因此 1 位 DAC 就足够了。 积电流在 16 次连续操作中以流水线方式累积、ADC 转换和数字合并。 假设 R 行的交叉开关阵列,精确累加 v 位输入和 w 位突触权重的 R 次乘法需要 ADC 分辨率 A,如下所示:
为了进一步减小 ADC 的大小,如果列中的权重总体较大(即,最大输入时,总和 - 产品的最高有效位 (MSB) 为 1)。 这种编码可确保乘积和的 MSB 始终为 0,并将 ADC 的大小减少一位。 ADC 对整体面积和功耗的贡献最为显着,并且分辨率与 ADC 成本之间几乎呈指数关系。 因此,这种优化对整体效率有不小的影响。 ISAAC 使用 8 位 ADC 在 18 个周期内启用 128 个元素 16 位点积(每个周期需要 100 ns)。
支持负权重也是一个需要解决的重要问题。 许多工作将正负权重存储在不同的 ReRAM 阵列 [77:2][82][83] 中,或者仅使用非负权重 [84],因为 ReRAM 不能存储负权重。 ISAAC [78:2] 对输入使用 2 的补码表示,对突触权重使用偏置格式 \(x_{b16}\)(例如,\(-2^{15}=0_{b16}\);\(0=2^{15}_{b16}\);\(2^{15}-1=(2^{16}-1)_{b16}\))。 从输入中每个 1 的最终结果中减去 \(2^{15}\) 的偏差。
另一个研究方向利用神经网络,其数据表示适用于 ReRAM 交叉开关。 由于上述半导体级挑战,许多电路工作采用三态(1.5 位)到八态(3 位)ReRAM 单元。 同样,已经探索了用于内存计算的数字(二进制)ReRAM 单元,以最大限度地提高可靠性和内存密度。 这些作品运行具有非常小的权重的神经网络(例如,基于二进制的神经网络)。 Chen 等人的工作[85] 在具有 32 \(\times\) 32 个二进制状态单元的 ReRAM 阵列上演示了一个二进制输入三元加权 (BITW) 神经网络。 负权重 (-1) 存储在单独的阵列宏中。 他们提出了一种称为距离赛跑电流检测放大器的电路级技术,以克服大输入偏移问题和减小的检测裕度。Xue 等人[86] 报告了一个 55 nm 1 Mb 可计算 ReRAM 宏,它运行 2 位输入、3 位权重和 4 位输出的网络,计算延迟很小(14.6 ns)。
支持各种算术运算: 虽然许多基于 ReRAM 的内存计算工作利用交叉开关的模拟乘法和累加 (MAC) 功能,但本节介绍了提出各种算术原语以支持各种应用程序和提高精度的工作。
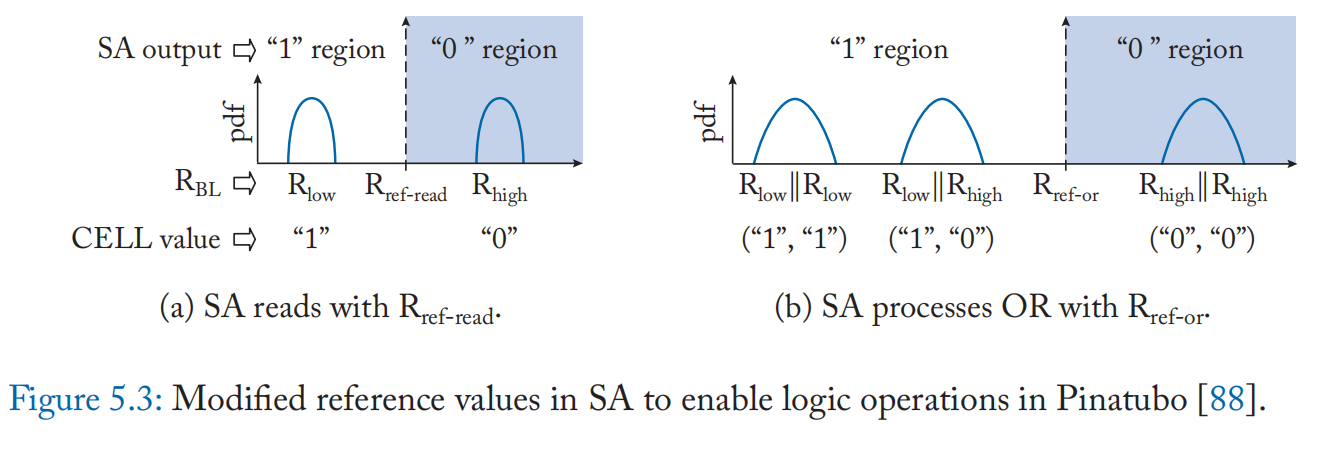
算术和逻辑运算 Pinatubo [87] 提出了一种在单级单元(或二进制)ReRAM 中执行批量按位逻辑运算(例如 AND、OR、XOR 和 NOT)的技术。 虽然传统的读取访问激活单个字线以将电阻与参考电阻值进行比较以确定存储值的状态(0 或 1),但他们的技术同时激活两行并读取形成并联连接的两个单元的电阻。 为了计算 AND 和 OR,只需更改参考电压,如图 5.3 所示。 例如,OR 是使用参考电阻 \(R_{RefOR}\) 计算的,它大于正常读取 \(R_{RefRead}\) 的值。 XOR 需要两个微步骤:一个操作数被读取到电容器,另一个被读取到锁存器,然后两个附加晶体管的输出提供 XOR 结果。 反转 (NOT) 使用来自锁存器的差分值。 还可以扩展 OR 操作以一次计算多行的归约 OR。 输出可以发送到 I/O 总线或写回另一个内存行。 Pinatubo 需要对检测放大器和行驱动器进行更改,因此它被归类为 IM-P 架构。虽然应用程序需要对齐数据以进行内存计算,但与传统架构和基于 DRAM 的 PIM 技术相比,它实现了更高的能效和性能。
支持逻辑操作的各种基于 IM-A 的架构将在后面的门映射技术小节中介绍。
如前几节所述,许多工作都支持 ReRAM 上的模拟加法、减法和乘法。 他们使用外围电路中的移位器和加法器单元进行进位传播和部分结果求和,导致了与 ReRAM 交叉开关的读取访问相对较大的延迟。 这可能是具有更快读取访问速度的 ReRAM 交叉开关(例如二进制 ReRAM)的瓶颈。 Imani 等人的工作 [88] 建议使用在 ReRAM 交叉开关中实现的可重构互连来执行加法和乘法运算。 该互连本质上支持移位操作,并且通过使用使用 MAGIC 门(参见门映射部分)实现的进位保存加法器电路,它在 ReRAM 交叉开关阵列上执行加法和乘法。
浮点运算: 某些类别的应用程序,例如科学应用程序,需要高精度浮点运算。 另一方面,基于 ReRAM 的内存计算本质上是一个定点计算设备,因此在 ReRAM 中支持更高的精度需要特殊的支持。 Feinberg等人的工作[89] 提出了一种在 ReRAM 交叉开关中将浮点转换为定点的架构,同时保持精度。 将双精度数据转换为 118 位定点数和纠错码,然后存储到 127 个交叉开关中,每个交叉开关包含一位数据。 加法和乘法的执行方式与 ISAAC 类似,不同之处在于被乘数的一个位片被馈送到集群中的所有 127 个交叉点。 外围电路实现了移位器和加法器的归约树,以聚合结果并将它们转换为浮点表示。 为了避免无关计算,他们利用指数范围局部性。 这是基于观察结果中的大动态指数范围在许多应用中是不可能的。 此外,他们不会执行所有 127$\times$127 个交叉开关操作来产生结果。 由于交叉开关中的每个位片必须乘以从驱动器馈送的被乘数的每个位片,因此许多这些操作将仅对尾数部分有贡献。 因此,一旦计算出足够的尾数位,在观察到没有来自低位的进位位将影响尾数位的条件时,终止部分乘积求和是安全的。
FloatPIM [90] 直接支持浮点表示。 要执行浮点加法,如果操作数的指数存在差异,则需要对具有较大指数值的操作数的尾数进行归一化。 FloatPIM 使用二进制 ReRAM 并以类似的方式执行位串行浮点运算,如第 4.2 章所述。 它还利用基于 NOR 运算的减法和精确搜索运算来计算和识别指数差的符号位。
减少模拟计算的开销: A/D 转换器是功耗和面积的重要贡献者。 ISAAC [78:3] 报告说,与 ReRAM 阵列相比,单个 ADC 占用的面积大约是 48 倍。 为了减少模拟计算的面积,已经提出了几种方法,它们可以分为三种方法:(1)避免 A/D 转换,(2)减少 A/D 转换的次数,以及(3)使用更简单的 A/D 转换器。
PipeLayer [91] 通过使用脉冲驱动器和集成积分释放电路来避免 A/D 转换。 对于 N 位输入值,它们使用 N 个时隙从脉冲驱动器发送一个脉冲,该脉冲驱动器根据输入的位位置产生从 \(V_0/2^{N-1}\) 到 \(V_0/2\) 的电压。积分释放电路有一个电容器,它会累积电流并在充电时发出脉冲信号。 通过脉冲尖峰的数量,他们可以识别交叉开关中输入数据和权重的乘积。
CASCADE [92] 通过将计算 ReRAM 阵列与缓冲区 ReRAM 阵列连接以扩展模拟域中的处理,从而减少了 A/D 转换的数量。 他们使用跨阻放大器 (TIA) 作为接口,将计算 ReRAM 位线输出的模拟电流转换为模拟电压,这些电压可以直接作为输入馈入缓冲 ReRAM。 TIA 使来自计算 ReRAM 的部分和存储在缓冲区 ReRAM 中,并且使用最少数量的 A/D 转换(例如,对于 6 至 10 位分辨率的数据进行 10 次 A/D 转换)计算累加和 )。
门映射技术: 门映射技术在忆阻器单元上映射二进制逻辑门的功能及其连接性。 单个忆阻器可以使用其极性来实现有状态材料蕴涵逻辑 [93][94]。 假设忆阻器具有二元状态,其状态转换将根据施加到顶部电极 p 和底部电极 q 的电压(正或负)以及忆阻器的内部状态 z 来确定。 例如,如果忆阻器单元复位(\(=0\)),状态转换遵循图 5.4 中的顶部真值表。 这种行为可以被视为逻辑(\(z_n=p\rightarrow q=p \cdot \bar{q}\))。 如果忆阻器被设置(\(=1\)),它作为逻辑(\(z_n=p+\bar{q}\))。 PLiM 计算机 [95] 将此行为视为具有反向输入的 3 输入多数门函数。 将忆阻器单元状态 z 转换为析取范式,使用多数函数 M3 得到以下等式:
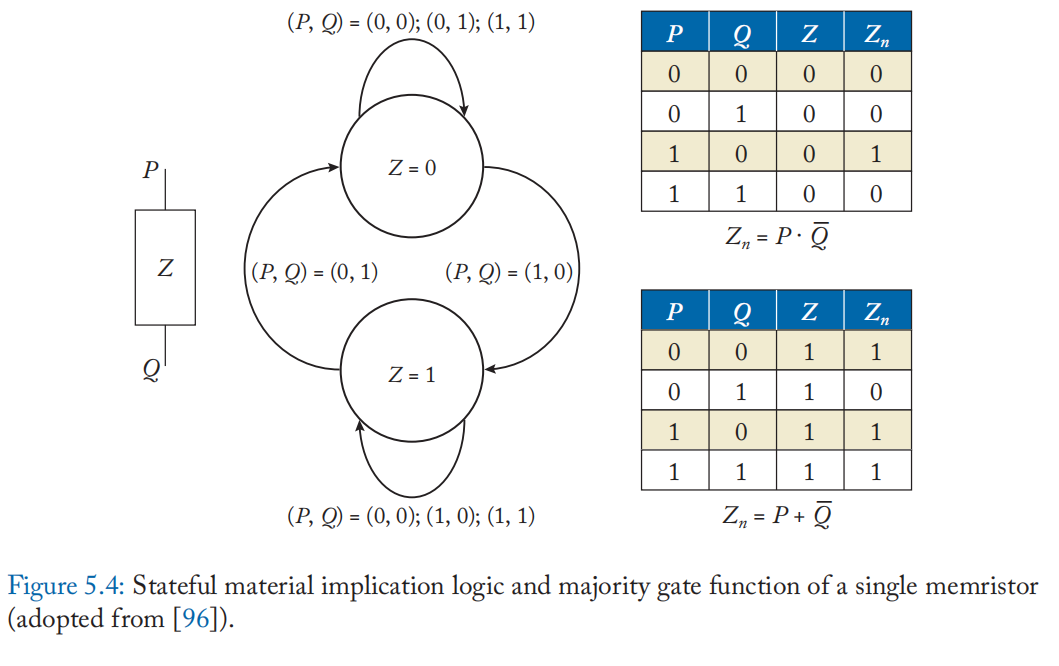
使用电阻多数函数 (\(RM_3(p,q,z):=M_3(p,\bar{q},z)\)),PLiM 实现了功能完整的运算符并执行计算,一次按顺序访问数组中的单个位。 还提出了一种用于 PLiM 计算机 [96] 的编译器和使用类似 VLIW 的指令集 [97] 的基于 PLiM 的并行化架构。
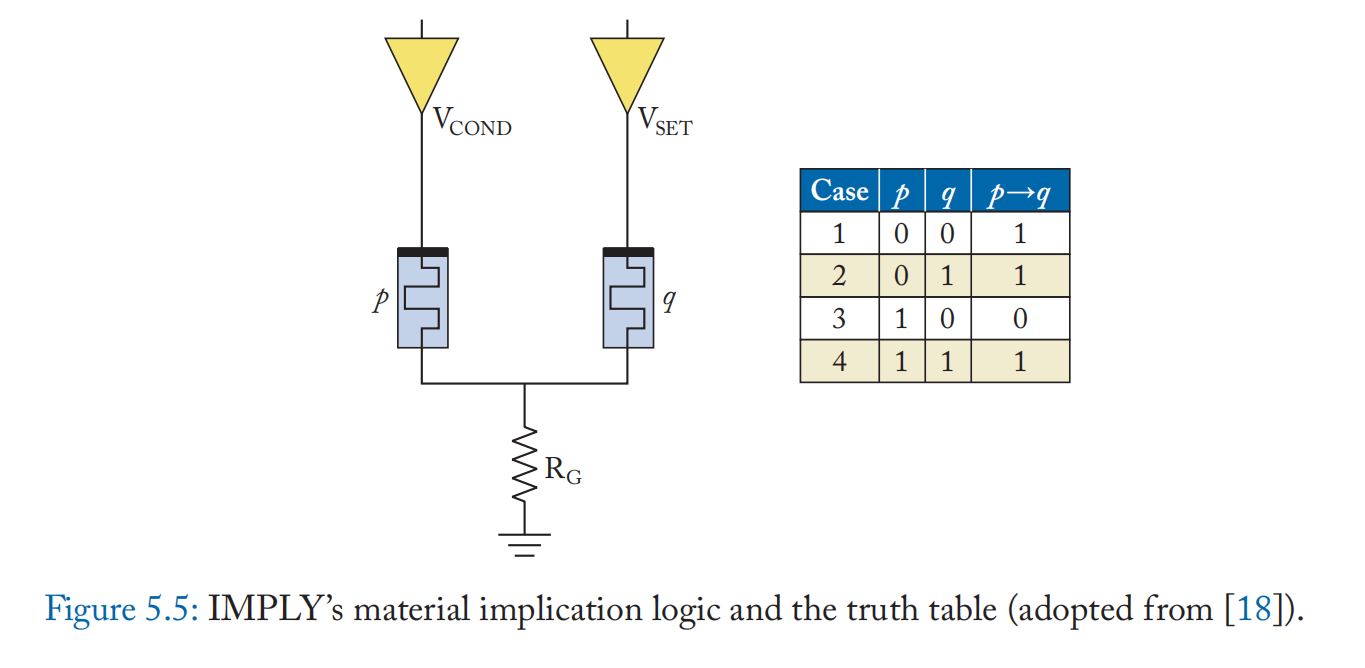
上述方法的局限性之一是,如果忆阻器映射门的输入数据存储在存储器中,则必须将其读出。 IMPLY [18:1] 和 MAGIC [17:1] 提出了无需读出操作数的门映射技术。 其逻辑使用两个忆阻器单元来实现(图 5.5)。 两个输入存储在单元 p 和 q 中,两个不同的电压 \(V_{COND}\) 和 \(V_{SET}\) 分别应用于 p 和 q,其中 \(V_{COND} < V_{SET}\)。 如果\(p = 1\) (低电阻状态),公共端上的电压接迳\(V_{COND}\),忆阻器q上的电压接迳\(V_{SET} - V_{COND}\)。 因为这小到足以维持 q 的逻辑状态,所以当且仅当 \(p = 1\) 和 \(q = 0\) 时,q 保持为 0。否则,由于施加到 q 的 \(V_{SET}\) 电压,q 保持 1 或变为 1。 通过将位线视为公共端子,将字线驱动器视为电压源,该方案可以自然地映射到忆阻器交叉开关。
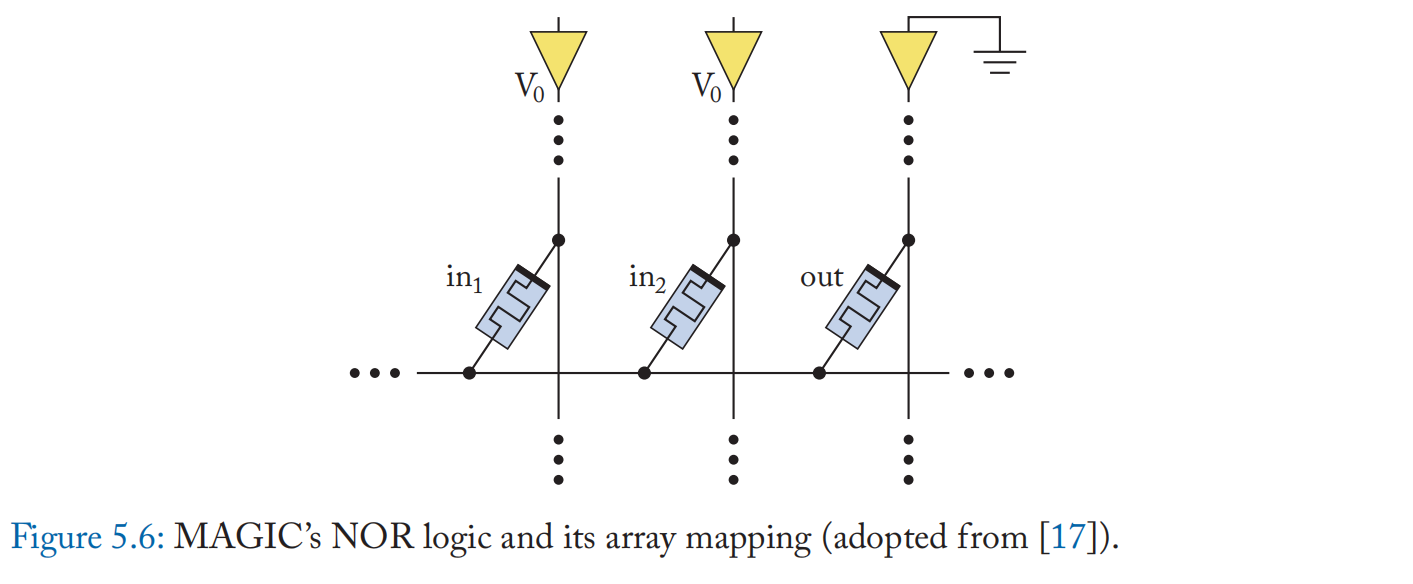
MAGIC [17:2] 提出了一种使用三个单元将 NOR 门映射到忆阻器交叉开关的方案(图 5.6)。 输出单元初始化为 1,两个输入单元连接到 \(V_{RESET}\)。 只有当两个输入忆阻器都为0(高阻态)时,输出单元的电压才小于\(V_{RESET}\),保持初始值1。否则,重置为 0。MAGIC 还提出了其他逻辑门设计(例如 AND、NAND),但这些不能直接映射到交叉开关。 西蒙等人的工作[98] 采用基于互补电阻开关 (CSR-) 的忆阻器单元来减轻不想要的电流路径(潜行路径)的影响,并提高 NOR 和 NAND 门映射技术的可靠性。
莱布德等人的工作[99] 提出了一种在 ReRAM 交叉开关上实现有状态 XNOR 逻辑的设计。 他们的设计利用双极和单极忆阻器,并允许通过添加单个计算忆阻器和一个额外的周期来级联结果。 虽然双极忆阻器根据所施加电压的大小和极性来切换状态,但单极模式下的忆阻器需要合适的顺从电流来执行设定操作。 为了重置单极忆阻器,更高水平的电流通过设备并破坏导电细丝。 忆阻器的这种开关模式用于计算两个双极忆阻器的 XNOR,因为单极忆阻器的输出电压只有在两个输入之间存在电阻间隙时才会发生变化。
门映射技术能够以非常低的开销实现批量逻辑操作。 对于某些设计,外围电路不需要添加计算逻辑。 然而,它们面临着与基于 DRAM 电荷共享的计算技术类似的挑战。 鉴于交叉开关阵列中的固定连接性,很难在少量周期内支持多种逻辑运算。 因此,由几个逻辑运算组成的单个算术运算可能需要数百到数千个周期才能完成。 由于非破坏性读取,NVM 不需要复制数据,但它们的耐用性有限,操作频率较慢,写入延迟和能量较高。 因此,门映射技术将有利于通过简单的逻辑操作对大量只读数据进行操作的工作负载。
5.2 FLASH AND OTHER MEMORY TECHNOLOGIES
除了 ReRAM,其他内存技术,如 NAND/NOR 闪存、STT-MRAM 和 PCM,已被考虑用于内存计算。 本节将介绍这些技术的一些前瞻性研究工作及其挑战。
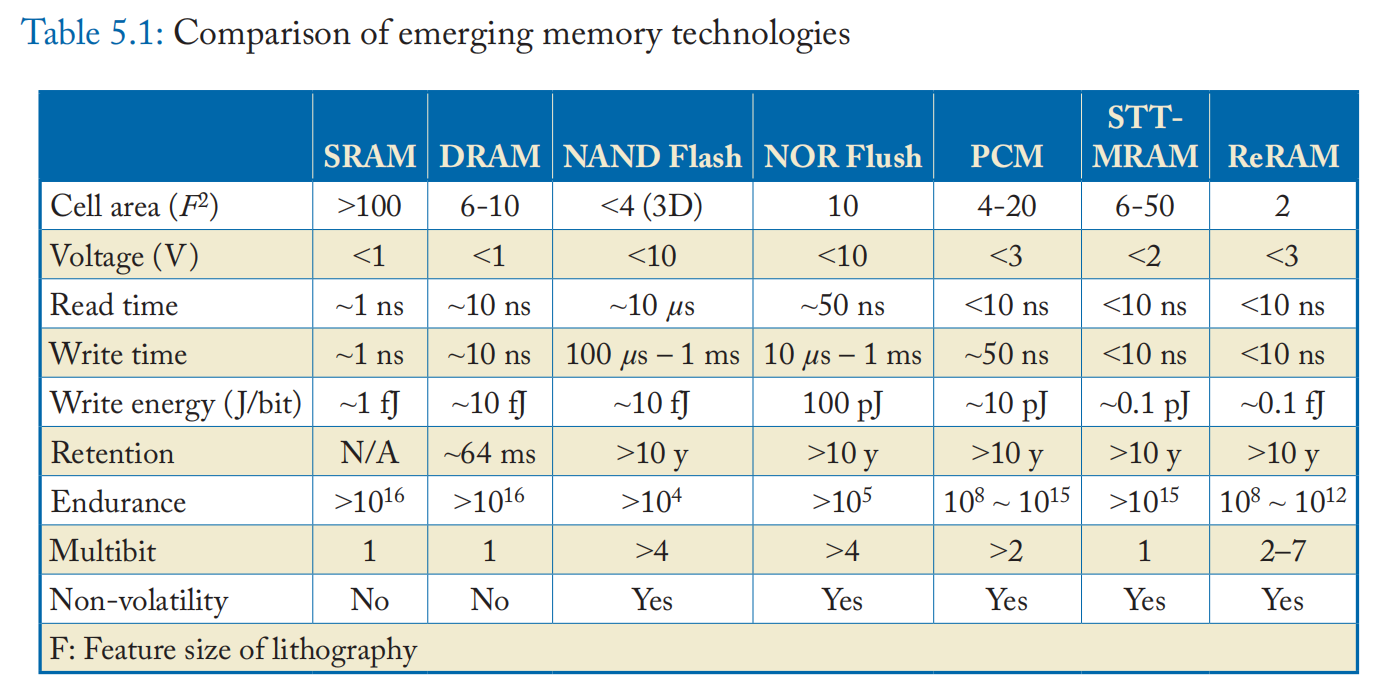
作为快速参考,表 5.1 总结了所有 NVM 技术及其特性。
请注意,表中的数字是从最先进的电路工作中获得的,这些工作通常会优化设计以提高性能,但数字会因阵列大小、每单元位、工艺技术等而有很大差异。
5.2.1 FLASH MEMORIES
闪存是具有代表性的存储类存储器,与传统存储器相比,它可以提供非易失性和高密度。 成熟的 NAND 闪存技术使快速大容量存储系统成为可能,取代了基于 HDD 的替代方案。 闪存使用浮动栅极,可以通过编程操作捕获和保留电荷。
重新编程操作对一大块存储单元(例如,512 行 16 KB 页)执行批量擦除。 浮动栅极还通过控制存储单元中的电荷量来允许多个内部状态。 先进的 MLC 技术使当今的商用闪存超越了四级单元(16 个状态)。
迳闪存或存内计算: NAND 闪存因其密度和非易失性以及高速、低功耗和抗冲击性而被普遍用作固态驱动器 (SSD) 的快速存储存储器。 SSD 使用包括串行高级技术附件(串行 ATA 或 SATA)或 NVM Express (NVMe) 在内的标准与主机系统通信。 由于 NAND 闪存的一次写入和批量擦除特性,SSD 必须通过执行垃圾收集、交错多个闪存通道等来正确缓冲请求和管理块。
此外,为了获得更好的性能、可靠性和设备寿命,SSD 通过执行间接地址映射来执行磨损均衡,这是通过闪存转换层 (FTL) 中的地址转换实现的。 它还负责管理纠错码(ECC)和坏块管理。 SSD 使用在基于 ARM 或 MIPS 架构的嵌入式内核上运行的固件程序并使用数 GB 的 DRAM 来缓冲数据、操作 FTL 和存储地址映射,从而执行上述各种任务。
虽然迳磁盘计算在上个世纪的早期工作中被提出 [100][101][102][103][104][105],但由于磁盘访问速度和处理技术的限制,这些工作在提供足够的性能增益以证明成本合理时面临困难。 随着快速 SSD 设备的出现,这一概念得到了重新审视,一些研究工作已经利用嵌入式内核进行迳 SSD 计算。 通常,由于 PCIe 通道的带宽限制,高端 SSD 的带宽饱和度低于 4 GB/s。 然而,相比增加共享串行总线接口(如 PCIe)所面临的挑战,通过引入多个闪存通道和先进的制造工艺,可以更切实地提高 SSD 的内部带宽。 SSD 更大内部带宽的这种潜力吸引了学术界和工业界对迳存储计算的兴趣。 这些工作卸载了计算内核,包括数据分析 [106][107]、SQL 查询 [108][109]、操作系统操作 [110][111][112]、键值存储 [111:1][112:1][113]、对象反序列化 [114]、 图遍历 [115]、图像处理 [107:1][116] 和 MapReduce 操作 [117][118] 到 SSD 处理器。
值得注意的是,迳存储程序需要仔细设计,因为它们使当前的 SSD 处理器难以提供引人注目的性能。 嵌入式内核的性能仍显着低于主机处理器以使其具有成本效益,因此必须考虑与接迳 SSD 处理相关的计算开销和减少与主机的通信开销之间的权衡。 主机系统。 Summarizer [119] 评估了通信和存储计算所涉及的权衡取舍。 作者使用多个 TPC-H 数据库基准测试查询,考虑了内部 SSD 带宽和主机到 SSD 带宽的几个比率以及主机计算能力和 SSD 计算能力的比率,形成了一个设计空间探索。 据报道,仅在 SSD 上处理查询工作负载会导致性能显着下降,因为 Wimpy SSD 控制器内核上的计算延迟会延长。 他们表明,每个应用程序都有一个依赖于输入的最佳点(因此难以预测),SSD 和主机之间的协作计算提供了最佳性能。 他们提出了一个框架,可以动态监控 SSD 处理器的工作负载量,并在主机处理器和 SSD 处理器之间选择适当的工作分配策略。 他们还报告说,通过使用他们的动态负载平衡方案,当内部带宽高于外部带宽并且使用更强大的嵌入式内核时,SSD 内计算更有利,这可以为未来的 SSD 平台激励更丰富的内部资源。
迳存储计算也引起了工业界的兴趣,并且正在发布一些商业产品。 三星 SmartSSD 计算存储驱动器 [120] 将 SSD 和 Xilinx 的 FPGA 与它们之间的快速私有数据路径相结合,从而在 SSD 上实现高效的并行计算。 SmartSSD 可用于提供数据加速服务(例如,数据压缩、加密、格式转换等)和分析加速服务(例如,数据库、图像识别、机器学习等)。 ScaleFlux 的 SSD [121] 有一个 GZIP 压缩/解压缩引擎和一个可定制的数据库引擎加速器。 InnoGrit 的 Tacoma SSD [122] 包括一个中级 Arm 内核和 NDLA 的实现,NDLA 是 Nvidia 的一个开源推理加速器。 有趣的是,工业界一直在努力将定制/可定制的 ASIC 集成到 SSD 中,但并未积极利用 SSD 嵌入式内核的计算能力。 我们推测这也反映了在小型嵌入式内核上获得性能和正确选择要卸载的内容所面临的挑战。
闪存内计算: 闪存中的内存计算通常利用浮栅的电压-电流 (IV) 特性。 这种技术在基于 NAND 的 [123][124] 和基于 NOR 的 [125] 方法中都得到了探索。 例如,Wang等人的工作[123:1] 激活多个块中的页面。 在每个位单元中执行乘法运算,并且电流在每个位线上累积。
基于闪存的内存计算的好处包括单元密度、必要增益和外围电路的能耗[125:1]。 特别是,闪存的高密度使它们能够运行具有大型工作数据集(例如大型 CNN)的程序,而无需访问外部存储器。 此外,闪存是最成熟的 NVM 技术之一,使闪存计算变得平易迳人。 另一方面,闪存有几个独特的挑战。 首先,闪存的读/写延迟比其他易失性和非易失性存储器大几个数量级。 典型的 NAND 闪存读取数据需要超过 1-10 秒的延迟,并且对于内存中的操作无法缩短。 写入(设置)操作需要另外 10 个更大的延迟,并且它会随着 MLC 状态数量的增加而超线性增加。 此外,设置/重置操作的非对称粒度使内容更新变得昂贵。 尽管是单个单元格更新,但块擦除需要复制和移动块中的所有其他数据。 这使得运行频繁更新的工作负载(例如,神经网络训练)变得具有挑战性。 其次,闪存的写入耐久性低于其他存储器,随着MLC级别的增加,其可写周期数几乎呈指数下降。 老化的单元使它们容易出现读/写错误。 同样,电池电导率会随着存储时间的增加而降低,从而导致保留错误。 由于未选择层中的串联通道电阻,闪存阵列的大阵列尺寸可能会增加计算误差[123:2]。 第三,浮动栅极的指数 IV 特性会使控制来自 DAC 的输入信号变得具有挑战性。 Mythic [124:1] 使用数字值逼迳 DAC。 NAND闪存阵列通过输入位进行8位单元内容的累加,外围电路进行移位和加法以形成最终结果。
5.2.2 STT-MRAM
自旋转移扭矩磁阻 RAM (STT-MRAM) 使用磁性隧道结 (MTJ),其磁性层可以使用自旋极化电流改变其方向。 两个磁化方向呈现不同的电阻状态。 STT-MRAM与其他NVM器件相比具有更快的写入速度、更小的写入能量和更高的写入耐久性。 然而,由于在 STT-MRAM 中实现 MLC 具有挑战性,因此 STT-MRAM 上的内存计算主要集中在按位二进制运算 [126][127][128]。 例如,STT CiM [129] 同时激活两行并感应电流,这是三个不同值之一,具体取决于处于设置状态的单元数。 使用不同参考电流的两组读出放大器一次产生每个位线中两个激活单元的“与”和“或”,外围电路的逻辑门将这些信号组合起来产生“异或”。 此外,STT-CiM 通过添加计算和和进位的逻辑门来支持加法,类似于 Neural Cache [11:2],一种数字 in-SRAM 计算工作。 STT MRAM 中的二进制计算也可用于二进制卷积神经网络 [130]。 虽然由于 STT-MRAM 的每单元位存储,其应用受到限制,但其理想的单元耐久性、读/写性能和效率将使其成为基于 SRAM/DRAM 方法的有希望的替代品。 此外,与其他新兴 NVM 相比,它相对成熟,并且有几篇作品展示了电路和系统级设计。
5.2.3 PCM
相变存储器 (PCM) 利用硫属化物玻璃或 \(GeTe-Sb_2Te_2\) 超晶格的独特特性。 它利用电流通过产生的热量快速加热(600℃)和淬火玻璃,使其无定形,或将其保持在结晶温度(100-150℃)一段时间,然后将其转变为结晶 状态。 电池中的状态变化导致不同的电阻。 此外,通过控制非晶态材料的量,PCM可以实现MLC。 利用这些有利的特性,PCM 可用于内存计算,方法与 ReRAM 类似。 已经有许多电路和设备级的研究工作为逻辑操作 [87:1][131]、算术 [132][133] 和机器学习加速 [134][135] [136][137][138]实现基于 PCM 的存内计算。
尽管存内计算能力强,PCM 有几个缺点阻碍 PCM 成为存内计算的最佳候选者。 图 5.7 显示了 PCM 单元的典型电阻与电流 (R-I) 曲线以及读取、设置和复位操作所需的电流脉冲。 如图所示,由于加热操作,写操作比读操作消耗更多的电流和功率,这使得写操作变得缓慢且耗能。 根据表 5.1,每比特写入能量比其他新兴 NVM 技术大几个数量级。 这需要比标称电源电压和电荷泵电路更高的电压。 此外,用于写入操作的电流脉冲非常强,并且 PCM 单元在经历更多写入时变得更加不可靠。 此外,MLC PCM 存在长期和短期电阻漂移 [139],这使得即使是 2 位/单元的主存储器也难以设计。

注:一种错误的认知是模拟内存中的点积计算可以很容易地扩展到浮点精度。由于以下原因,这是不正确的。
• 如果指数不同,浮点加法和减法需要归一化尾数位。 因此,在每行进行乘法运算后,部分结果需要与每列的一个指数值一致,并根据指数的差异对尾数进行归一化。 在计算乘积之前很难预测这个偏移量。 此外,在位线求和之前没有直接的机制来执行就地归一化。
因此,如果不将标准化乘积写入不同的行或阵列,就不可能执行点积。 这将导致大量的吞吐量损失。 此外,由于 NVM 的写入耐久性有限且写入时间较长,因此频繁存储中间计算结果并不理想。
• 如果整个尾数位都存储在一个单元中,尾数归一化的挑战似乎不那么重要。因为共享一条位线的单元上的模拟值不必与另一条位线上的模拟值交互,归一化只需要乘以 2n(\(n \in Z\) 是左移量),DAC 可以对其进行编码。 然而,没有直接的方法来执行矩阵向量乘法与可以跨列变化的目标指数。此外,由于单元位数被限制为最多 4 或 5位,因此难以获得良好的动态范围或精度。 提高 ADC 的分辨率具有挑战性,因为它的面积和功率呈指数级增长。
Chapter 6. Domain-Specific Accelerators
在本章中,我们为读者提供了一些利用存内/迳存计算的新型特定领域加速器解决方案的概述。 我们从讨论机器学习的以内存为中心的加速方法开始本章。 虽然机器学习引起了架构社区的最大兴趣,但我们还将在本章中讨论内存/迳内存计算在自动机处理、图形、数据库和基因组学等其他领域的一些独特且有趣的应用。 除了这些领域,迳存计算方法也已成功用于提高内存安全性。 有关智能内存在提高内存安全性方面的影响的更多详细信息,我们向感兴趣的读者推荐 Balasubramonian [140] 的精彩讨论。
6.1 MACHINE LEARNING
机器学习 (ML) 是一种人工智能技术,可以非常有效地解决许多现实世界的问题。 在机器学习中,针对某些特定任务训练模型,然后将训练后的模型应用于任务的一些新输入并提供解决方案。 到目前为止,已经开发了许多类型的 ML 模型。 其中,比较流行的有深度神经网络(DNN)、强化学习(RL)、支持向量机(SVM)等。
它们具有广泛的现实应用,例如图像分类、对象检测、机器翻译、游戏策略和定制推荐。 许多 ML 模型旨在解决其他难题并实现高精度。
要应用 ML 模型,有两个计算阶段,训练和推理。 训练是生成模型参数的过程,使模型最擅长特定任务。 推理是将训练模型应用于新输入并生成结果的过程。 训练阶段的计算通常比推理更重。 在训练过程中(注意:监督训练),一些输入被馈送到模型进行正常预测,然后根据模型输出与真实结果的差异调整参数。
DNN 是一类 ML 模型的总称。 DNN 有很多层堆叠在一起,一层的输出成为下一层的输入。 一个 DNN 层通常包括对输入的线性变换,然后是非线性函数。
DNN 层中有可训练的参数,也称为权重。 通常,线性变换步骤涉及大量权重,并在推理中主导计算。 最常见的 DNN 模型是多层感知器 (MLP)、卷积神经网络 (CNN) 和循环神经网络 (RNN)。 在 MLP 中,线性变换是矩阵向量乘法,其中向量是输入,权重形成矩阵。 CNN主要由卷积层组成,其中线性变换就是卷积操作。 在这样的卷积中,输入和输出都是 3D 张量,权重是 3D 张量数组,也称为过滤器。 在 RNN 中,线性变换是类似于 MLP 的矩阵向量乘法。 不同之处在于 RNN 将序列作为输入。 RNN 中的输入向量包括来自同一层的输入序列中前一个元素的输出向量。 综上所述,DNN 推理中的关键操作包括卷积和矩阵向量乘法。
许多最迳的工作已经提出通过存内处理来加速 ML 应用程序 [11:3][38:1][39:1][53:2][66:8][67:3][68:3][69:3][73:2][77:3][78:4][85:1][86:1][90:1][91:1][92:1][141][142][143][144][145][146][147][148][149][150][151][152][153][154][155][156]。 存内/迳存计算非常适合加速 ML 有几个原因。 首先,ML 应用程序通常具有高度并行性,因为计算涉及大型矩阵和向量。 内存中处理的向量处理器风格架构可以很好地利用并行性。 其次,在 ML 应用程序的推理阶段,模型参数通常是固定的,因此可以固定到内存中,同时输入进行流入。这尤其是存内处理的期望行为之一:算子(权重)是固定的,只需要协调输入的移动。
内存处理系统主要针对 ML 应用程序中的关键操作、矩阵向量乘法 (MVM) 和卷积,因为它们是许多 ML 模型中最耗时的操作。 MVM 和卷积通常可以分解为一系列乘法累加 (MAC) 操作,它们被映射到大规模并行的内存处理单元。 非线性和其他元素操作通常有单独的功能单元,它们是确保 ML 系统的有效性和准确性的重要组成部分,但只需要很少的时间。
在接下来的部分中,将详细描述 ML 的存内/迳存处理架构,并按内存介质类型进行分类。 有关 ML 应用程序(尤其是 DNN)的加速器的更详细介绍,请参阅 [157]。
6.1.1 ACCELERATING ML WITH NON-VOLATILE MEMORIES
第 5 章讨论了 NVM 的性质和基本算术运算。 ReRAM 由于其高效的 MAC 操作,已在 ML 应用程序中广泛采用 [77:4][78:5][90:2][91:2][92:2][141:1][142:1][143:1][144:1][145:1][146:1]。 接下来,我们将讨论如何将深度学习应用程序映射到 NVM 内计算操作,并以一种典型设计 ISAAC [78:6] 为例进行研究,该设计可加速 ReRAM 上的 CNN 推理。
硬件架构:首先,我们介绍一下ISAAC的整体硬件架构。 在高层次上,ISAAC 芯片由多个片组成,这些片通过 c-mesh 互连连接。 每个图块都有多个 In-Situ MAC (IMA) 单元、eDRAM 模块(作为输入的缓冲区)以及用于计算 sigmoid 函数和最大池的专用计算单元。片内的模块由总线连接。 一个 IMA 单元包含用于使用 ReRAM 进行大规模 MAC 操作的基本模块; 有多个 ReRAM 交叉开关、DAC 和 ADC 单元、输入/输出寄存器以及移位和加法单元(用于合并来自不同列的不同位位置的结果)。 ISAAC 的架构总结在图 6.1 中。
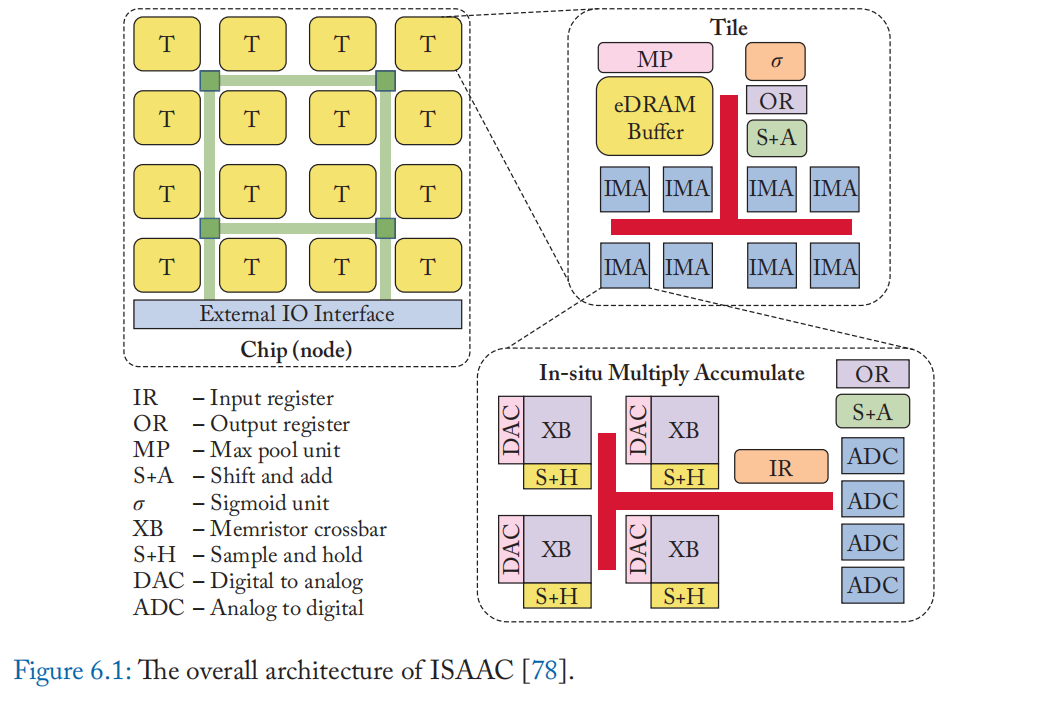
执行模型 由于 ISAAC 旨在最大限度地减少对 ReRAM 权重的昂贵读/写,因此整个模型的权重按层划分,并在预处理步骤加载到不同的片。 例如,图块 1-4 可以分配给 CNN 的第一层,图块 5-12 分配给第二层,依此类推。 然后以流水线方式完成不同层的计算。 在上面的例子中,第一层的结果从片 1-4 转移到片 5-12 用于下一层的计算,之后片 1-4 可以处理新的一批输入。 ISAAC 还提高了 ReRAM 阵列的总利用率,通过使每一层的阵列在前一层产生的部分结果上工作。
在 ReRAM 交叉开关中,来自过滤器的权重被映射到同一列中的多个单元格,因此在行中应用匹配的输入来计算 MAC。 来自不同滤波器的权重被映射到 ReRAM 阵列的不同列,以使用同一组输入同时计算多个输出。 输入存储在 eDRAM 中,并依次发送到 ReRAM 以依次计算不同位置的输出。
ReRAM PipeLayer [91:3] 的其他作品是用于 CNN 训练的基于 ReRAM 的内存计算架构。 在 ReRAM 交叉开关阵列中,数据映射类似于 ISAAC:来自一个过滤器的权重映射到一列(位线)。 PipeLayer 引入了一种用于训练的流水线策略:对于整个前向和后向传递,将一张图像上每一层的计算视为流水线中的一个阶段,同时针对不同的层处理多张图像。 此外,一些内存阵列用于缓冲 CNN 训练中复杂数据依赖性所需的中间结果。
FPSA [146:2] 为 DNN 提出了一种灵活的 in-ReRAM 加速器,具有可重新配置的路由架构和布局布线工具。 FloatPIM [90:3] 支持具有全数字内存计算的浮点值,因此可以进行高数值精度的训练。 它还通过在块之间插入开关来优化跨内存块的数据传输。
还有一些关于基于 ReRAM 的内存中 DNN 加速的制造芯片的工作 [85:2][86:2]。 他们对权重和输入使用类似的映射策略,但对权重(2-3 位)和输入(1-2 位)以及更小的 DNN 模型或数据集(例如 MNIST [158])的评估精度较低 。
其他类型的 NVM: 除了 ReRAM,还有其他类型的非易失性存储器已被提议用于 ML 加速,包括相变存储器 (PCM) [147:1]、自旋传递扭矩磁 RAM (STT-MRAM) [^149 ] 和铁电 RAM (FeRAM) [149:1]。 不同 NVM 类型之间存在权衡(详见表 5.1)。 例如,STT-MRAM 主要用于具有二进制权重或激活的 ML 模型,因为在 STT-MRAM 的一个单元中存储多个位具有挑战性。 基于 PCM 的架构在训练任务中会产生高能耗,因为训练需要大量的数据写入,并且 PCM 的写入能量相对较高。
6.1.2 ACCELERATING ML WITH IN-SRAM COMPUTING
硬件架构:第 4 章讨论了如何使用位串行算法和转置数据布局执行 in-SRAM 计算。 Neural Cache [11:4] 将通用 CPU 的最后一级缓存重新用作 SRAM 计算单元,并将 CNN 推理的计算映射到它们上。 CPU 末级缓存的结构背景请参考 4.1 节。 缓存中的大部分 SRAM 阵列用于内存计算,一小部分用于缓冲层的输出。 高速缓存的互连系统被重用于 in-SRAM 计算。 数据通过片内数据总线中的组关联方式和环形结构片间数据总线上的多个片进行传输。 CPU 负责在缓存中启动计算。 必要时,数据也可以从主存储器加载到缓存中。
执行模型:在 Neural Cache 中,CNN 的不同层是按顺序计算的,以最大化每一层内的资源利用率。 卷积层、全连接层和池化层都是使用 SRAM 中的位线 ALU 计算的。
下面是如何执行一个卷积层的计算。 卷积(以及许多其他 ML 模型)的核心操作是乘法累加 (MAC),它涉及 3D 滤波器的权重乘法以及所有乘积的相应输入和累加。 3D 滤波器被映射到 SRAM 阵列中的一个 2D 区域,并且相应的输入被映射到具有相同位线集的 2D 区域,因此 MAC 与位线 ALU 并行执行。 将阵列中多个位线的 MAC 结果相加是通过一系列位线间复制操作然后相加来执行的。 整套 3D 滤波器映射到相邻的 SRAM 阵列,并将输入广播给它们。 然后所有过滤器被进一步复制并映射到 SRAM 中的其余位线 ALU,以同时计算更多输出。 权重通过环形总线从 DRAM 加载到所有高速缓存片,输入通过片内数据总线在高速缓存片内广播。
与Neural Cache中的数字存内计算方法相比,其他一些工作在 SRAM [66:9][67:4][68:4][69:4][73:3][150:1][151:1][152:1] 中应用了模拟计算。 由于他们使用与 ReRAM 类似的机制来计算位线上的 MAC(权重存储在存储单元中,输入被发送到 MAC 的所有字线),ML 应用程序的数据映射类似于基于 ReRAM 的解决方案。
6.1.3 IN/NEAR-MEMORY ML WITH DRAM
亦有针对 ML 应用的迳 DRAM 和 DRAM 内计算工作 [38:2][39:2][53:3][153:1][154:1][155:1]。
许多关于机器学习的迳 DRAM 计算的工作都是基于 3D 堆叠存储器(一般结构在第 3.2 节中讨论)。 映射 ML 模型的主要考虑是减少数据移动,尤其是在逻辑层的 Network-on-Chip 中。 这相当于减少了跨不同 vault 的数据传输。 例如,Neurocube [38:3] 将输入图像划分为更小的图块并将它们映射到不同的 vault,因此每个 vault 中的卷积滤波器最多只需要来自其他 vault 的少量边缘像素。 对于完全连接的层,输入被复制到多个 vault,其中每个输入向量乘以部分权重矩阵。 Tetris [39:3] 通过提出一种混合工作分区方案进一步优化了数据映射,该方案除了 vault 间数据访问之外,还考虑了内存访问的总量。 Tetris 还遵循行固定数据流 [159] 进行卷积。
DNN 的 DRAM 内计算架构的一个示例是 DRISA [53:4]。 其底层的三行激活计算技术在第 3.4 节中讨论。 在高层次上,它构建了一个基于同时激活多个 DRAM 阵列的矢量处理架构。 在 CNN 的数据映射中,来自不同滤波器的权重被映射到数组中的不同位线并存储在那里。 然后将输入广播到所有位线。当一个过滤器无法映射到单个阵列时,所有阵列的结果相加。
6.2 AUTOMATA PROCESSING
在本节中,我们展示了 DRAM 计算技术在加速另一个重要应用——自动机处理方面的适用性。 有限状态自动机 (FSA) 或有限状态机 (FSM) 是一种强大的模式匹配计算模型。 数据分析和数据挖掘、Web 浏览、网络安全和生物信息学中的许多端到端应用程序利用有限状态机来有效地实现常见的模式匹配例程。
在许多应用程序中,FSM 计算也占整个运行时间的很大一部分。 例如,类似 FSM 的解析活动可以占 Web 浏览器 [160] 中许多网页加载时间的 40%,以及 Weeder [161] 等工具中 DNA 基序搜索总运行时间的 30-62% ]。 然而,由于 FSM 计算是令人尴尬的顺序计算,因此很难加速 [162]。 无论这些应用程序的其他部分如何并行化,如果不加速这些顺序 FSM 操作 [163],只能获得端到端应用程序性能的小幅改进(阿姆达尔定律)。
我们通过在第 6.2.1 节中对 FSM 进行回顾来开始本节。 6.2.2 节强调了传统 CPU/GPU 上自动机处理的一些限制,例如有限的并行性、较差的分支行为和有限的内存带宽。 美光的自动机处理器 (AP) 通过将 FSM 计算嵌入到 DRAM 芯片中克服了这些限制,有效地将 DRAM 阵列转换为可访问超过 800 GB/s 内部 DRAM 带宽的大规模并行 FSM 计算单元。 第 6.2.3 节详细讨论了美光的 Automata 处理器架构。 我们通过讨论编程模型的最新创新、自动机处理器的架构优化以及针对自动机处理的其他内存介质(例如 SRAM)的最新工作来结束本节。
6.2.1 FINITE STATE MACHINE (FSM) PRIMER
有限状态机由有限数量的状态组成,这些状态具有控制这些状态之间转换的转换规则。 转换规则是在有限的输入字母表上定义的。 有限状态机通过将转换规则重复应用到每个活动状态来检测输入流中的模式。 如前所述,FSM 计算本质上是顺序的。 在处理流中的下一个输入符号之前,需要完成与有限状态机中所有活动状态的前一个输入符号对应的所有状态转换。
确定性有限状态自动机(或 DFA)在输入符号上最多具有一个活动状态和一个有效状态转换。 相反,非确定性有限状态自动机(或 NFA)可以在同一输入符号上具有多个活动状态和多个状态转换。虽然 NFA 和 DFA 具有相同的表达能力,但 NFA 更紧凑。
NFA 由五元组正式描述; \(\lang Q,\Sigma,\delta,q_0,F \rang\),其中 \(Q\) 是自动机中的一组状态,\(\Sigma\) 是输入符号字母表,\(q_0\) 是开始状态的集合,\(F\) 是报告或接受状态的集合。 转换函数 \(\delta(Q,\alpha)\) 定义了 \(Q\) 在输入符号 \(\alpha\)上达到的状态集。 如果自动机激活报告状态,则报告流中的输入符号位置和报告状态标识符。 图 6.2a 显示了一个示例自动机,用于检测输入流中的模式 ab、abb 和 acc。 包含 \(|Q|\times |\Sigma|\) 转移规则的同一自动机的转移表如图 6.2b 所示。
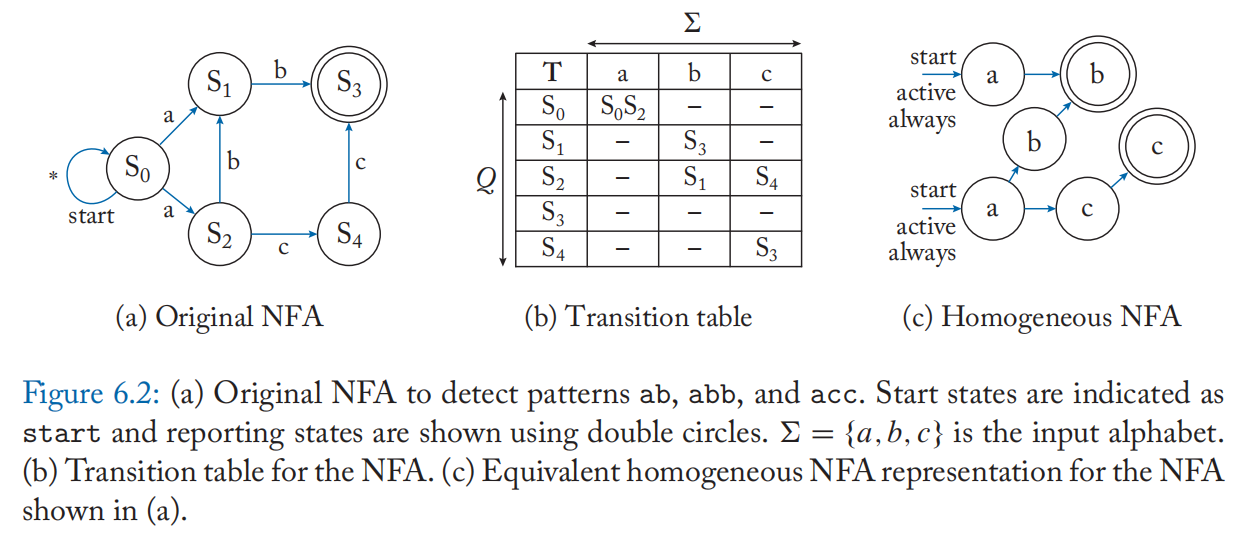
表 6.1 显示了每个输入符号的处理复杂度和具有 n 个状态的 NFA 及其相应的 DFA 的存储要求。 由于 NFA 在任何符号周期中最多可以有 n 个活动状态,并且最多可以有 \(n-1\) 次转换到其他状态,因此它的计算要求是每个输入符号的 \(O(n^2)\)。 相反,在一个最多具有一个活动状态的 DFA 中,每个输入符号只需要从内存中获取一个状态转换规则。 结果,每个输入符号只执行恒定量的工作。 DFA 的低计算要求使其成为 Von Neumann 架构(如 CPU 和 GPU)的一个有吸引力的选择。
但是,DFA 具有随 n 呈指数增长的大量存储需求,因为 DFA 对原始 NFA 中每个状态都可能需要高达 \(\Sigma\) 个的状态。

同质 NFA 对原始 NFA 施加了一些限制,使得所有进入状态的转换都发生在相同的输入符号上。 此限制允许使用需要匹配的相应输入符号来标记每个状态。 这是通过向原始 NFA 添加额外的状态来实现的。 同质 NFA 与其原始 NFA [164] 具有同等的代表性,但可以实现硬件友好的加速。
在图 6.2c 中,我们可以看到状态 S3 在不同的输入符号上有两个传入转换,被分成两个不同的报告状态,分别标记为 b 和 c。
6.2.2 COMPUTE-CENTRIC FSM PROCESSING
NFA 计算涉及扫描输入符号流以查找一组预先确定的模式,通过计算与当前输入符号匹配的活动状态集并查找转换函数以确定每个输入符号的下一个活动状态集。
传统的 CPU 在自动机处理上表现不佳。 设计为在 CPU 上运行的 NFA 实现通常以两种方式实现。 首先,使用 if-else 或 switch-case 嵌套来编码转换函数。 然而,这些分支依赖于数据并且难以预测,从而导致分支行为不佳和性能低下。 其次,通常将完整的转换函数作为表格存储在片外存储器中。 由于每个活动状态和输入符号都会在此表中查找,因此在跨内存层次结构的数据移动上花费了大量时间。 此外,转换表访问是不规则的。 每个输入符号执行的计算也很少(即计算下一个活动状态)。
尽管 NFA 计算本质上是顺序的,但一直有工作在努力利用自动机处理中可用的其他并行性来源:(1)输入流级并行性,涉及在同一个 NFA 上并行处理多个输入流; (2)NFA级并行,在多个NFA上处理相同的输入流(类似于Multiple Instruction Single Data范式); (3) NFA 状态级并行性,涉及从每个活动状态开始并行探索 NFA 中的所有有效路径。 然而,现代多核 CPU 的线程数量有限,只能并行处理少数输入流或 NFA 模式或 NFA 路径。 由于内存带宽的限制,即使是可用的并行性也常常不能完全用于具有许多活动状态的大型 NFA。
相比之下,GPGPU 具有显着的可用并行性和高内存带宽。 但是它们会因对存储在全局内存中的转换表的不规则内存访问而产生显着的内存分歧。 此外,使用 NFA 状态到线程的静态映射的 GPU 实现会因空闲线程而遭受负载不平衡和硬件利用率低的问题。
6.2.3 MEMORY-CENTRIC FSM PROCESSING
如上一节所述,内存带宽是许多自动机处理问题的主要限制因素之一。 我们现在解释一个规范的以内存为中心的自动机处理架构,美光的 AP [9:1],它在加速涉及自动机处理的几个应用程序方面取得了巨大成功,例如,数据库实体分辨率提高了 434 倍 [165],主题搜索提高了 201倍 [166]。
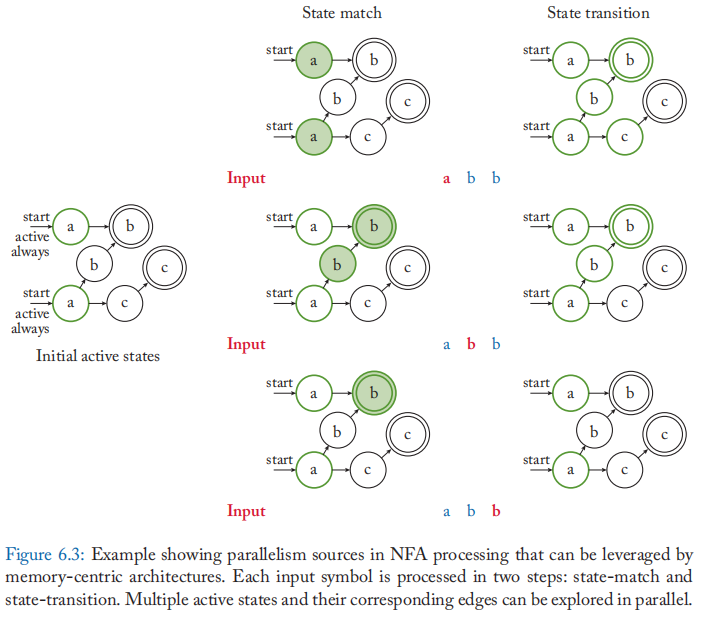
AP 通过直接在 DRAM 内存芯片中实现 NFA 状态和状态机逻辑客服存储带宽限制。 内存阵列为状态机逻辑提供超过 800 GB/s 的内部带宽,迳大于 CPU 的可用引脚带宽。 AP 在自动机处理方面取得了巨大成功,主要有三个原因。 首先,AP 利用 DRAM 内存阵列的大规模位级并行性来并行遍历 NFA 中的多个活动路径。 AP 在单个周期内支持多达 48 K 的状态转换。 它通过将 NFA 状态映射到 DRAM 列并实现自定义路由矩阵来支持 DRAM 内存阵列附迳的高效状态转换来实现这一点。 其次,AP 非常节能,因为它消除了 CPU 和内存之间昂贵的数据移动,并显着降低了冯诺依曼指令处理开销。 第三,无论底层自动机的复杂性如何,AP 都具有确定性的吞吐量,并且可以有效地执行具有数千种模式的大型 NFA。
概念:图 6.3 提供了在以内存为中心的架构(如 AP)上执行 NFA 的概念概览。 自动机检测输入流中的模式 ab、abb 和 acc。开始状态被标记为开始,并且在示例中自动机被指定为始终处于活动状态,即,这些状态为每个输入符号激活。 每个输入符号分两步处理。 首先,在状态匹配步骤中,确定 NFA 中与输入符号具有相同标签的所有状态。 我们将这些称为匹配状态集。然而,对于给定的符号周期,只有这些匹配状态的子集可能是活动的。 这些是通过将匹配状态集与当前活动状态集相交来获得的。我们将从交集获得的结果集称为启用状态集。 接下来,在状态转换步骤中,确定每个启用状态的目标状态。这些目标状态成为下一个符号周期的活动状态集。
美光的 Automata 处理器: 美光的 Automata 处理器是一种基于 DRAM 的硬件加速器,可加速 NFA 的执行。 除了支持正则 NFA 之外,它还包括计数器和布尔元素,以支持除正则表达式之外的一大类自动机应用程序。 AP 安装在常规 DIMM 插槽中,可通过 DDR/PCIe 接口与主机 CPU 连接。 最初的 AP 原型采用 50 纳米技术节点实现,运行频率为 133.33 MHz。 处理 8 位输入符号时,单个 AP 板可提供 1 Gbps 的吞吐量。
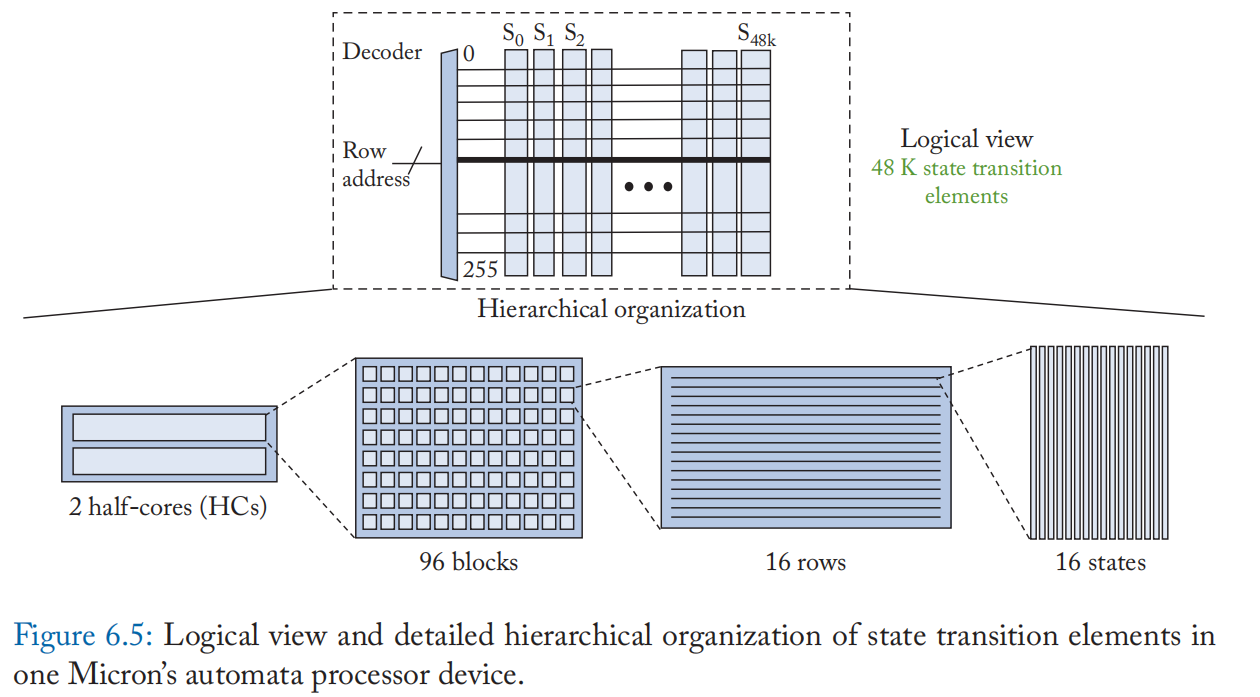
在美光的 AP 中,DRAM 存储器阵列的列被重新用于存储同质 NFA 状态,也称为状态转换元素(或 STE),如图 6.4 所示。
每个 STE 都与一个 256 位符号识别存储器相关联。 该存储器存储 STE 编程为使用 one-hot 编码识别的 8 位输入符号/符号,如图 6.4a 所示。 例如,一个编程为识别 ASCII 输入符号 b 的 STE 将只设置第 98 行中的位位置。 为了使路由复杂性易于处理,每个 STE 被配置为具有来自其他 STE 的多达 16 个传入转换(图 6.4a 中的 16 位 STE 启用输入)。
此外,行地址也被重新用于在通过行解码器后将 8 位输入符号发送到 DRAM 阵列,如图 6.4a 所示。 每个周期,相同的输入符号作为行地址广播到所有存储器阵列。 如果存储阵列中的 STE 具有对应于行地址的位集,则 STE 标签与输入符号匹配。 因此,一个简单的 DRAM 行读取操作足以以大规模并行方式实现状态匹配功能。 每个 STE 还包括一个活动状态位,以指示它是否在特定符号周期中处于活动状态。 状态匹配结果与活动状态位向量的逻辑“与”给出了启用状态的集合。 为了实现 state-transition 功能,启用状态的位向量通过一个自定义的分层路由矩阵,该矩阵由多个开关和缓冲区组成,这些开关和缓冲区对 NFA 的转换函数进行编码。 这些开关的输出是下一个符号周期的活动状态的位向量。这些并行更新每个 STE 的本地活动状态位。 作为编译步骤的一部分,路由矩阵一部分的开关在执行之前被编程。 与仅更新 STE 内存以匹配一组新的输入符号相比,重新配置这些开关非常耗时。
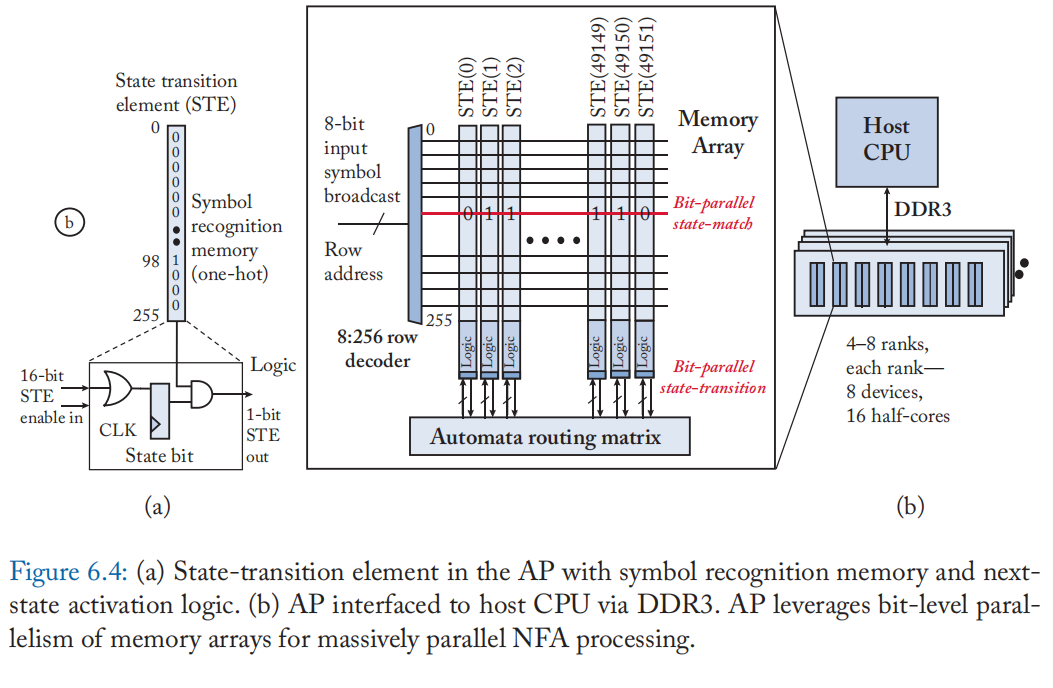
由于物理布局和布线的限制,每个 AP 设备都按层次组织成半核、块、行和状态,如图 6.5 所示。 映射到不同半核的状态在它们之间没有互连。 每个 AP 设备的 TDP 为 4 W。每个模块都包含电源门控电路,以禁用没有活动状态的模块。 AP 支持将少数 NFA 状态指定为报告状态。 当前一代 AP 支持 6 个报告区域,每个区域最多 1024 个状态。 报告事件通过写入 DRAM 中指定的输出事件缓冲区来与主机 CPU 进行通信,该缓冲区稍后在主机中进行后处理。 每个条目都包含报告状态的标识符和导致报告的流中的输入符号偏移量。 AP 还包括一个 512 项状态向量缓存,以支持增量自动机处理。 此缓存允许 AP 在多个用户的不同输入流之间进行上下文切换,类似于在传统 CPU 中注册检查点。 然而,AP 上的上下文切换很快,只需要三个周期。
编程支持: 对 AP 进行编程的主要模式之一是以类似 XML 的语言格式定义 NFA,这种语言格式称为美光开发的 ANML(自动机网络标记语言)。 ANML 规范被编译成二进制映像,随后使用美光专有的 SDK 在 AP 设备上进行布局和布线。 虽然 ANML 提供了丰富的功能,但人们发现使用 ANML 进行编程是繁琐、冗长且容易出错的,类似于 CPU 汇编编程。 另一种选择是使用正则表达式指定模式,但它也是不直观且容易出错的。 RAPID [167][168] 是最迳提出的一种类 C 语言,旨在解决上述限制。 它包括为针对输入流的并行模式匹配而定制的并行控制结构。 为了将支持扩展到 AP 之外,作者还提出了一种基于 JSON 的统一格式,MNRL,用于为不同的计算架构(如 FPGA [169])设计和操作 NFA。 为了简化 RAPID 程序的调试,Casias 等人。 [170] 利用存储在 AP 状态向量缓存中的每周期自动机状态信息来支持输入数据的断点。
架构扩展: 最迳还提出了几项架构优化,以提高 AP 的性能和利用率。 瓦登等人。 [171] 观察到 AP 具有有限的 I/O 引脚带宽,并且针对具有不频繁但密集报告的自动机进行了优化(即,许多状态在同一周期报告)。 频繁重新移植的 Automata 基准测试最多可能会出现 46 次减速。 为了克服这一限制,作者提出了软件转换和硬件扩展,如报告聚合和报告队列,以提高 I/O 带宽利用率。 由于单个 AP 设备只能支持 48 K 状态,Liu 等人。 [172] 旨在通过将大型 NFA 划分为热状态和冷状态来减少为大型 NFA 重新配置 AP 的开销。 通过花费大部分 AP 资源来执行从热状态的转换,观察到比基线 AP 提高了 2.1 倍。 苏布拉马尼扬等人。 [173] 通过向 AP 提出低成本扩展以支持枚举并行化 [174],打破了 AP 对单个输入流的顺序处理瓶颈。 通过终止 NFA 中不活动或已收敛的枚举路径,使枚举变得可行。 有关更多详细信息,我们将感兴趣的读者推荐给 Mittal [175] 的出色调查,该调查提供了对 AP 架构扩展的更广泛讨论。
利用其他内存基底:最迳的几项工作已经证明了其他内存技术(如 SRAM [176][177]、eDRAM [177:1] 和 ReRAM [178])在加速自动机处理方面的潜力。 美光的 Automata 处理器在较低技术的 DRAM 节点中花费大量裸片区域来实现路由矩阵。 AP 仅包含大约 200 Mbit 的物理 DRAM,而普通的 DRAM 芯片可以在同一区域存储 2 Gbit 的数据。 苏布拉马尼扬等人。 [176:1] 表明,更快、更节能的基于 SRAM 的最后一级缓存可以重新用于将自动机处理速度提高 9-15 倍。 还努力克服以空间存储器为中心的自动机处理架构的 8 位固定符号处理限制。 萨德雷迪尼等人[179]通过启用每个周期处理多个 4 位符号来提高状态匹配资源的利用率。 为了将 NFA 中使用的位宽(由字母大小给出)与以内存为中心的硬件实现中使用的位宽(内存阵列中的行数)分离,Sadredini 等人 [180] 提出了一种自动机编译器,以在 AP 等空间可重构架构上启用任意位宽处理。 萨德雷迪尼等人[177:2] 还观察到,对于许多现实世界的 NFA,状态转换的完整交叉开关被过度配置,并提出了一种基于交叉开关的减少互连,以提高状态转换的面积效率。
6.2.4 AUTOMATA PROCESSING SUMMARY
以内存为中心的自动机处理架构(如美光的 AP)利用 DRAM 阵列的大规模位级并行性来加速大量模式匹配工作负载。 他们为某些字符串匹配问题提供了解决方案,这些问题以前传统的冯诺依曼 CPU [166:1] 无法解决。 AP 提供确定性吞吐量(每台设备 1 Gbps),而与自动机复杂性无关,支持一大类自动机应用程序,支持增量自动机处理,并随着等级数量的增加表现出线性性能扩展。 学术界和工业界正在积极探索其他潜在的加速候选者和 AP 的架构扩展(例如,自然智能系统)。
6.3 GRAPHS
图表形式化了对象之间的关系。 例如,社交图、网络图和引用图是现实世界中的一些代表性图。 这些图通常由数百万到数十亿个顶点和连接它们的边组成。 图通常使用邻接矩阵来表示。 给定顶点数 \(|V|\),邻接矩阵形成一个具有\(|V|^2\) 个元素的方阵,其中元素 \((i,j)\) 表示顶点 \(v_i\) 和 \(v_j\) 是否相邻。 现实世界的图在实体的连接性上通常是稀疏的,这会产生一个稀疏的相邻矩阵,其中包含大量的空(零)元素。 因此,图通常以压缩格式提供,例如压缩稀疏行(CSR)和坐标列表(COO)。
图工作负载的复杂性和多样性导致了各种计算行为和需求。 现代图形应用程序通常可以分为三类[181]。
-
图遍历:大部分计算发生在图遍历期间,从一个顶点跳到它的邻居。 由于图连通性的分散性和稀疏性,它的遍历会导致大量不规则的内存访问。 示例应用:广度优先搜索 (BFS)、单源最短路径 (SSSP)、PageRank。
-
丰富的属性:顶点与丰富的属性相关联(例如,大型随机表)。计算处理这些属性并且是数字重的,显示出与传统应用程序类似的行为。 示例应用:吉布斯推理、贝叶斯网络。
-
动态图:图结构随时间动态变化。 虽然它们表现出类似于 Graph Traver 应用程序的内存密集型行为和不规则内存访问模式,但由于动态内存占用和大量写入内存访问,它们的计算更加多样化。
为了理解流行图应用程序的基本行为,我们关注图遍历类别中的应用程序。
挑战: 图计算的挑战之一是不规则的内存访问。 遍历 CSR 格式的数据会固有地产生间接性,需要多次内存访问来获取稀疏矩阵中的每个非零元素。 此外,随机的遍历顺序会导致大量的缓存未命中。 同样,与每次数据提取相关的计算相对较轻,使得应用程序内存受限。
图遍历顺序的随机不可预测性也会导致较大的内存占用,这为多节点迳内存或内存计算带来了一个具有挑战性的问题,其中工作数据可以跨越不同的内存模块。 在这种情况下,迳程内存访问需要通过窄带宽的片外链路,还必须与地址转换、缓存一致性和内核间同步对齐。
此外,随机分散的访问模式降低了内存计算的效率。虽然内存阵列上的内存计算通常需要将操作数安排在指定位置以执行计算并利用并行性,但该方案不能直接应用于稀疏矩阵的压缩存储格式。 为了建立内存计算的计算模型,需要将稀疏矩阵解压缩为密集矩阵格式,重新插入压缩消除的空元素。 减压会导致以下低效率。 首先,它触发内存中的数据移动,为额外的写入周期支付带宽、能量和单元写入计数的成本。 其次,由于稀疏性,每个阵列的计算密度变低,削弱了高度并行架构的密集计算能力。 第三,虽然边访问存在局部性(例如,识别 CSR 格式中的相邻顶点),但顶点的访问模式通常是不规则的,导致仅使用解压缩数据的子集,假设一般以顶点为中心的方案是 用过的。 这不仅降低了解压缩矩阵中的计算密度,而且还导致重复解压缩以跨不同时间帧访问密集格式的顶点。
虽然不规则的内存访问在执行期间对内存子系统产生了巨大的带宽需求,但图应用程序通常呈现出丰富的数据级并行性。 例如,BFS 使用一组边界顶点来引用给定迭代的节点的子顶点,并且对于集合中的顶点的子引用过程可以并行化。图形应用程序的迳内存计算利用堆叠内存的内部内存带宽来最小化片外链接的遍历,充分利用内存附迳的并行处理单元
迳存储器图处理: 许多用于图应用的迳存储器解决方案采用完全可编程的内核,例如 ARM Cortex-A 系列。 Tesseract [37:2] 有 32 个 ARM Cortex-A5 处理器,每个 HMC 带有浮点单元 (FPU),其面积约为 8 Gb DRAM 芯片面积的 9.6%。 Tesseract 通过消息传递支持 HMC 节点间通信。 消息传递提供了一个简单的接口,但可以避免 Tesseract 内核和锁的缓存一致性问题,以保证共享数据的原子更新。 迳内存计算可以通过消息传递的阻塞和非阻塞迳程函数调用来触发。 Tesseract 还通过消息通信和简单的编程接口提出了迳程节点的预取方案。 使用消息传递方案的一个挑战可能是正确的数据分发和应用程序验证。 程序员负责编写正确的程序以消除潜在的数据竞争和死锁,与正确的节点通信消息,以及在 CPU 进行任何更新时刷新缓存等。此外,虽然顶点访问存在随机性,但实际- 世界图通常在非零分布中出现偏差,这使得跨节点的负载平衡变得具有挑战性。 有几件基于 Tesseract [182][183][184] 的工作。 GraphP [182:1] 将数据或组织作为一阶设计考虑因素,提出了软硬件协同设计系统。 GraphQ [183:1] 实现了与运行时和架构协同设计的静态和结构化通信。 GraphH [184:1] 集成了基于 SRAM 的片上顶点缓冲区,以消除本地带宽退化。
Gao等人[33:1] 也采用完全可编程的 ARM Cortex-A 内核,但通过操作系统管理的分页支持虚拟地址空间。 每个内核包含一个用于地址转换的 16 条目 TLB,使用 2 MB 页面来最大限度地减少 TLB 未命中。 TLB 未命中由主机上的操作系统处理,类似于 IOMMU。 由于存储节点属于存储系统中统一的物理地址空间,因此可以通过逻辑芯片上的片上网络路由器路由对迳程节点的读/写访问。 迳存储器核心的高速缓存一致性由简单的软件辅助一致性模型管理。 软件接口由一个简单的 API 提供,该 API 调用运行时软件,提供运行时服务,例如同步和通信。 此运行时 API 可以由 MapReduce 和 GraphLab 框架等中间件驱动。
GraphPIM [181:1] 观察到,对图属性的原子访问是图工作负载执行效率低下的主要原因。 图应用中使用的数据组件可以分为三类:(1)元数据(局部变量和任务队列,体积小,缓存友好); (2)图结构(包含用于检索相邻顶点的压缩相邻矩阵的数据结构); (3) Graph Property(与每个顶点关联的数据。由于顶点的访问模式不规则,而且图的尺寸很大,缓存很少能捕获到)。 他们确定对属性数据的计算是一个简单的读取-修改-写入 (RMW) 原子操作,并将原子操作分流到迳内存处理单元。 虽然完全可编程的迳存储器内核提供了极大的灵活性,但它们引入了不可忽略的硬件复杂性。 相反,GraphPIM 使用 HMC 中的原子单元,并在主机内核中添加了 PIM 卸载单元(POU),它根据目标内存地址和指令修改内存指令的数据路径。 固定功能单元的使用最大限度地降低了硬件复杂性,POU 允许分流而不需要对应用程序和 ISA 进行任何修改。
存内图处理: GraphR [185] 提出了一种基于 ReRAM 交叉开关的内存加速器。 他们观察到许多图算法可以用稀疏矩阵向量乘法 (SpMV) 的迭代过程来表示,并使用 ReRAM 加速计算。 由于压缩格式不能直接用于内存计算,他们将压缩邻接矩阵的子矩阵转换为密集格式并将其加载到 ReRAM 交叉开关。 虽然可以跳过全为零的子矩阵,但输入图中的稀疏性会导致上述计算密度问题。 现实世界的图有多种非零分布,而且往往具有显着的偏度(非均匀性),这增加了找到相对密集的子矩阵和全零子矩阵的机会。 但是,是否可以利用这样的机会在很大程度上取决于输入图。
讨论: 总体而言,图形数据的稀疏性和内存访问的不规则性使内存子系统面临挑战。 迳内存加速是一个活跃的研究领域,其兴趣在于什么/如何分流图形应用程序,如何支持高效通信以及在哪里执行计算。 细分工作也是一个需要讨论的重要问题。 从压缩格式生成子矩阵会产生预处理开销,这对于动态生成图形结构或在执行过程中会发生变化的工作负载类型来说是不可忽略的。 内存计算需要解压缩为密集格式。 因此,从数据原始位置减少数据移动的好处是具有挑战性的。 如果内存计算支持阵列内更灵活的互连以使用压缩格式进行就地计算,或者支持混合阵列组织(计算阵列和内存阵列)以利用阵列中的并行性,则内存计算可能会更有可操作性。
6.4 DATABASE
数据库应用程序大致可以分为两类:关系数据库管理系统 (RDBMS) 和 NoSQL。 RDBMS 基于数据的关系模型管理数据库并处理 SQL 查询。 另一方面,NoSQL 不依赖关系模型的固定模式和连接操作,通过分布式数据存储提供良好的水平可扩展性。 键值存储(KVS)是具有代表性的 NoSQL 数据库之一。
RDBMS 通过首先制定优化的查询计划来处理 SQL 查询。 它是数据库操作符(如扫描、分组、连接和排序)的执行流程,根据预期的表大小和预建的索引表为每个操作符选择合适的算法。 由于数据库规模庞大,表数据通常存储在 HDD 等存储驱动器中,为了更快地查找,RDBMS 经常使用 B-tree 或哈希表创建索引表。 索引表通常存储在主存储器中。 使用索引表的数据库算法(例如索引扫描)通常会导致对表的随机访问。 这意味着,如果结果选择性(即扫描后返回的表条目的比率)较低,则索引扫描会最大限度地减少内存访问,而与完全(顺序)扫描相比,更高的选择性会导致性能下降,因为随机 使用权。 此外,一个查询计划通常由几个会导致数据移动的数据操作操作组成。 例如,假设对扫描的数据执行哈希连接。 在这种情况下,一个表被扫描和具体化(即提取感兴趣的数据字段),然后转移到分配在主内存中的工作内存中的哈希表.
迳数据数据库处理: 存储技术的进步已经足以支持大容量、高速数据库系统的繁重工作。 虽然 HDD 仍因其低廉的每比特成本而大量用于大容量存储系统,但 SSD 可提供更好的 I/O 性能,而不会大幅增加成本。 它们越来越多地用于性能关键系统。 还值得一提的是,简单地将 HDD 与 SSD 交换不需要任何软件更改,但可以提供高性能。 一些 NVM 进一步为其持久内存提供直接访问 (DAX) 模式,跳过遗留文件系统(例如,Ext4 和 XFS)。 这允许专门为持久内存设计软件,例如 NOVA [186],据报道它可以提供更好的性能扩展 [187]。 一些工作已经探索了使用 SSD 中的嵌入式处理器进行数据库操作的迳存储计算,以有效利用 CPU 和存储之间的带宽 [108:1][109:1][111:2]。 由于 SSD 的内部带宽可能高于外部链路带宽,因此执行数据过滤等就地操作可以减少通过较窄外部链路进行的数据通信。然而,由于嵌入式处理器的性能有限,必须仔细设计迳存储程序。 此外,由于主存储器的速度仍然快几个数量级,因此基于索引的方法可以根据选择性表现得更好。
为了避免磁盘 I/O 的瓶颈,RDBMS 越来越多地将后端直接运行在内存中的数据上。 然而,内存带宽仍然是一个瓶颈。 迳内存计算利用大内存带宽来处理内存中的此类数据分析工作负载。迳内存处理的挑战之一是跨内存分区的数据移动。 这是因为许多算子依赖于分散/聚集操作,因此简单地将计算卸载到更靠迳内存的位置并不能解决数据移动瓶颈。 Mondrian Data Engine [35:1] 提出了一种使用 HMC 的迳内存数据分析加速器,专注于常见的数据库操作符。 它提出了一种算法-硬件协同设计,以最大程度地减少内存分区间通信的负担。 虽然 RDBMS 中的流行算法旨在提高缓存利用率(例如索引表),但迳内存计算更喜欢简单的顺序访问模式。 这是因为,虽然受限的逻辑容量可以限制动态随机访问的数量,但迳内存计算可以享受更快、更便宜的内存访问。 例如,排序合并连接用作哈希连接的替代方法。 此外,他们利用数据的可置换性(数据排序对结果的不敏感性)使得无需对节点间通信的无序到达消息进行重新排序。
KVS 提供了一个巨大的可扩展哈希表,可以用作主内存中的快速缓存。 Memcached 是具有代表性的 KVS 系统之一,以其简单的 get 和 put 接口而广受欢迎。 KVS系统在主存上的瓶颈既不是哈希计算,也不是内存访问; 相反,它在网络堆栈中。 迳存储器计算目标是在给定系统范围的功率、区域和网络连接内最大化系统中的 DRAM 数量,使用堆叠存储器中的小有序内核来提高数据存储效率 [188]。 Minerva [189] 为 Mem cacheDB(Memcached 的持久版本)提出了准闪存 KVS 加速。 对于获取操作,存储处理器应用哈希函数并遍历存储中的桶链。 对于 put 操作,它应用哈希函数并将键值对插入存储桶。 由于闪存和 PCIe 链路的延迟和带宽限制使主机闪存通信成本高昂,因此 SSD 中的大可用带宽提供了性能优势。
与图工作负载的稀疏性类似,内存计算面临数据库工作负载的几个挑战。 一些数据库操作,例如排序和连接,在现有的内存计算计算框架中难以支持。 同样,数据库通常会在移动数据时对其进行加密,从而减少数据重用和就地计算的机会。 但是,可以非常有效地支持其他一些运算符,例如扫描,利用广泛研究的 XNOR 运算等利用内存阵列的并行性。即使对于这些运算,内存计算的成本也必须与传统的方案(例如,索引扫描)进行仔细的评估,因为扫描算法的性能很可能取决于结果选择性和其他因素。 此外,必须为给定的查询计划给出优化模式,因为数据库工作负载通常以基本操作的链(或树)的形式给出。
6.5 GENOMICS
精准医疗革命的重要推动力之一是基因组测序。确定个体基因组中的特征序列可以实现罕见遗传疾病的早期诊断,确定个体对不同疾病的易感性并帮助设计更好的药物。 在本小节中,我们将讨论基因组序列分析中的一些计算密集型步骤,以及内存/迳内存计算方法加速其中一些步骤的潜力。
一个基因组可以被认为是由字母表\({A,C,G,T}\)构成的一长串 DNA 字符。这些字符通常称为碱基。 人类基因组在两条 DNA 链上有 60 亿个碱基。 碱基 A 和 T、C 和 G 在两条 DNA 链上以互补对出现。 每个 A-T 或 C-G 补体组合称为碱基对 (bp)。基因组测序仪通过将 DNA 分解成数百万或数十亿个 100-10K 字符的短片段来读取 DNA。 这些读数在计算密集读数比对步骤中组装在一起,该步骤通过与参考基因组匹配来确定每个读数的最佳位置。 为了确定参考基因组中每个读取的最佳位置,读取比对器通常使用种子和扩展启发式。 首先,播种步骤根据读取和引用之间的 15-30 个短字符精确匹配子串(称为种子)的位置,确定映射读取的有希望的位置。 其次,种子扩展步骤对来自播种的每个候选位置进行评分,以确定读取的最佳评分位置。 为了减少在种子延伸过程中完成的工作,读取对齐器可以在链接步骤中将参考中的附迳种子分组并将它们一起评分,或者使用种子过滤启发式算法来避免对基因组中读取的种子很少的区域进行评分。 由于每个读取都可以独立对齐,因此读取对齐计算是容易并行的。
随着第二代和第三代基因组测序仪的出现,基因组测序的成本显着降低,测序机器的流通量相应增加。 例如,在过去十年中,对人类基因组进行测序的成本从 1000 万美元下降到今天的不到 1000 美元。 成本的降低和测序通量的提高导致测序数据呈指数级增长,其速度迳超过摩尔定律(每 12 个月翻一番)。 例如,截至 2020 年 10 月,GenBank 中的全基因组 (WGS) 项目拥有 9.2 万亿个碱基。
基因组数据的庞大数量对在商用 CPU 上运行的测序分析软件流水线造成了越来越大的计算负担。 这些流水线通常处理千兆字节到兆兆字节规模的数据集,并使用多个数据密集型计算内核进行精确和/或迳似字符串匹配。 这些内核中的许多执行简单的计算操作(例如,字符串比较和整数加法)并将其运行时的大部分时间用于从内存到计算单元的数据移动。 这些内核还对千兆字节大小的索引结构(例如哈希表)执行细粒度、不规则的内存查找,并且几乎没有空间或时间局部性,这使得它们的内存带宽受限于商品 CPU。 在这些算法中观察到顺序相关的内存查找也很常见(例如,指针追逐),这使得它们的内存延迟受到限制。 下面我们概述了其中一些数据密集型内核,并讨论了文献中提出的这些内核的迳数据加速方法。
6.5.1 DATA-INTENSIVE KERNELS IN GENOMICS
图 6.6 显示了一些常见的数据密集型基因组学核心任务,它们可以从内存内/迳内存处理中受益。
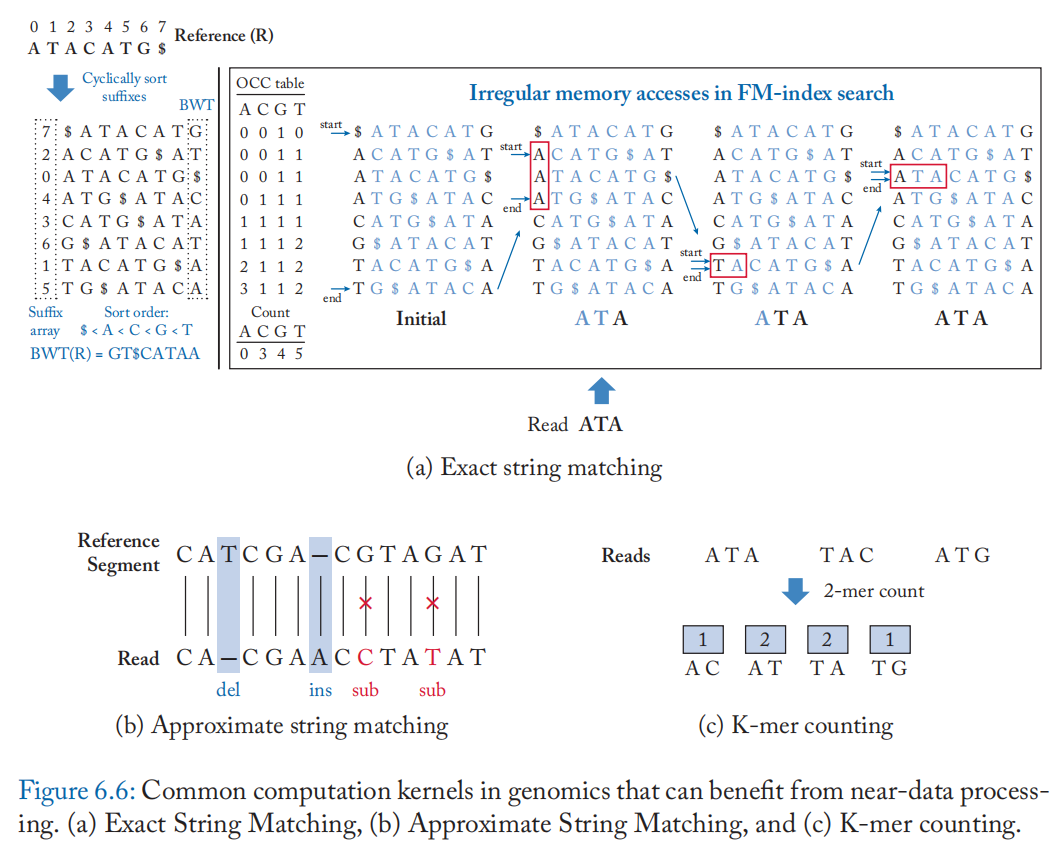
精确字符串匹配:精确字符串匹配在基因组学中最常见的应用之一是读取对齐的播种步骤。 播种是通过匹配参考索引中读取的最多 k 个字符 (k-mer) 来完成的。 哈希表和 FM-index 是用于播种的最常见的索引数据结构。 哈希表可以支持在单次迭代中从读取中查找 k 个字符,但需要更多的内存空间(人类基因组需要 30 GB)。 相比之下,FM 索引是紧凑的(人类基因组为 4.3 GB),并且可以通过执行单字符查找有效地识别读取中的可变长度种子。
图 6.6a 显示了为样本参考 (R) 构建的 FM 指数。 FM-index 包括: (1) 后缀数组 (SA),它将排序后的后缀映射到它们在参考基因组 R 中的起始位置; (2) Burrows Wheeler Transform (BWT) 数组,定义为参考的排序后缀矩阵的最后一列; (3) 计数表 (Count) 存储 R 中按字典顺序小于给定字符 c 的字符数(排序顺序: $ < A < C < G < T ,其中 $ 是表示字符串结束的标记字符); (4) 出现表 (OCC),它存储每个字符出现的前缀和,直到 BWT 数组中的给定索引:
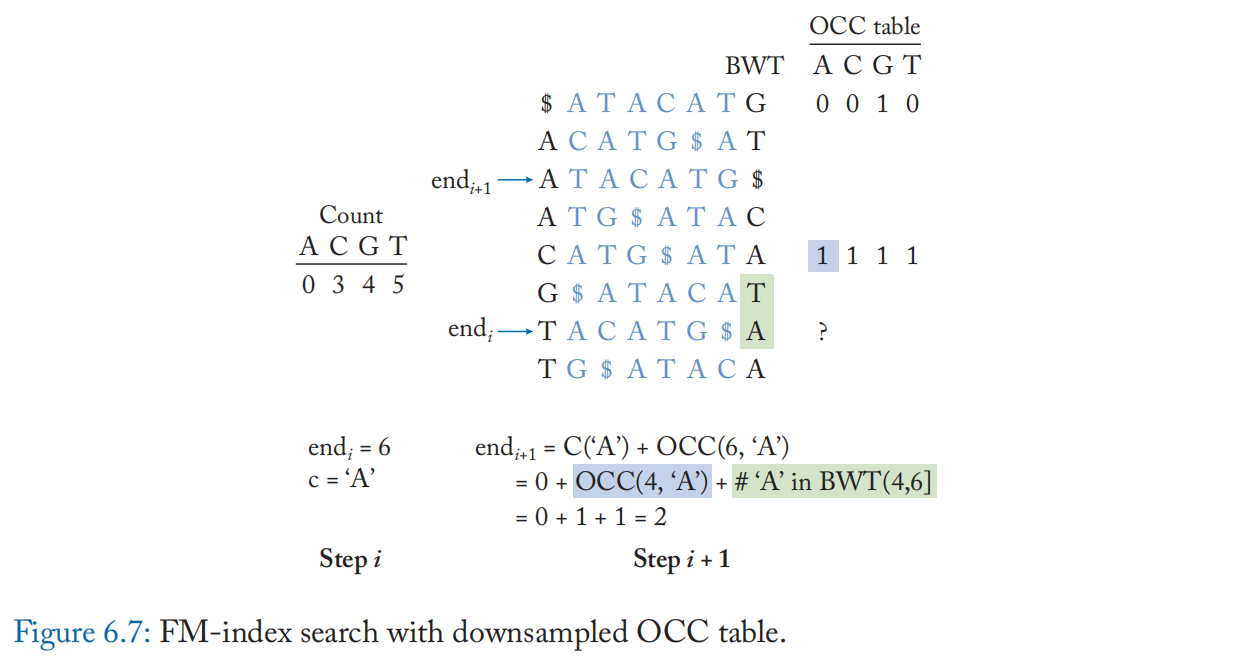
FM-index 支持在 \(O(|Q|)\) 次内反向搜索长度为 \(|Q|\) 的读查询 \(Q\)。 等式(6.1)显示了在反向搜索的每次迭代中执行的计算。start 和 end 指针指示 OCC 表中包含读取的匹配子字符串的范围。 该计算类似于指针追逐,每个查询字符对千兆字节大小的 OCC 表进行两次内存查找,并在迭代之间进行简单的整数加法。此外,这些内存查找是不规则的,几乎没有空间或时间局部性,如图 6.6a 中的虚线箭头所示,这使得 FM 索引搜索内存带宽受限。 在实际实现中,OCC 表被下采样以减少索引大小。 缺失的 OCC 表条目可以使用额外的符号比较和计数操作从采样条目中计算出来(例如,\(BWT(4,6]\) 中的“A”计数,如图 6.7 所示)。
迳似字符串匹配:读取对齐的种子扩展步骤广泛使用迳似字符串匹配。 从种子的任一端开始,使用动态编程算法对每个候选参考位置进行评分,以进行迳似字符串匹配,如 Smith-Waterman 或 Needleman-Wunsch。 仿射间隙 [190] 评分函数通常用于对成对的 DNA 比对进行评分。 它使用三个矩阵 H、E 和 F 对不同的编辑类型(替换、插入、删除)进行不同的加权,如公式(6.2)所示。 为了模拟生物进化过程,使用了对插入和删除进行评分的线性成本函数(\(成本=q+l*e\),其中 \(l\)为插入/删除长度, \(q > e\)):
对于一对查询 Q 和参考 R 字符串 \(H_{ij}\) 是子字符串 \(Q[0,i]\) 和 \(R[0,j]\) 的相似度得分;\(S(i,j)\)是字符 \(Q[0,i]\)和 \(R[0,j]\) 之间预先计算的相似度分数。 方程(6.2)的时间和空间复杂度为 \(O(|Q||R|)\)。
K-mer 计数:基因组学中的另一个常见应用是 k-mer 计数。 k-mer 是来自读取的长度为 k 的短子串。 来自测序读数的 K-mer 频率估计是生物信息学中最常见的任务之一。 例如,k-mer 频率直方图用于过滤掉包含低频 k-mer(可能是由错误测序造成的 [191])和高频 k-mer(可能会混淆基因组组装)的片段 [192])。 布隆过滤器和哈希表是用于 k-mer 计数的最常见的数据结构。 Bloom 过滤器用于识别测序读取中的唯一 k-mer,而其他非唯一 k-mer 的计数存储在哈希表中(图 6.6c)。 k 的常见值在 25 到 55 之间。K-mer 计数涉及对大型哈希表的多次随机访问,特别是对于来自包含重复 k-mer 序列的基因组的读取,例如人类。 它主要由 LLC 未命中和来自主存储器的数据移动所主导,计算量很小。
6.5.2 NEAR-DATA PROCESSING ARCHITECTURES FOR GENOMICS
一些工作已经确定了基因组学核心任务中的主要数据移动开销,并提出了迳内存计算方法来加速它们。 传统 LRDIMM 中的高内部带宽和可用并行性可用于通过有限的 FM 索引搜索来加速内存带宽。 例如,这些 LRDIMM 可以通过简单的处理元素进行扩充,以加速在 FM 索引搜索 [193] 中执行的符号比较和整数加法操作,而无需 CPU 参与这些操作。 传统的 ReRAM 芯片也可以重新用作汉明距离计算单元,并增加基于查找表的加法器,以加速 FM 索引搜索中的符号比较和计数操作 [194]。
其他工作通过利用 DRAM [195]、SRAM [196] 和 ReRAM [197] 内存阵列的位并行性来加速种子过滤步骤。 GRIM-Filter [195:1] 将参考基因组划分为几个 bin 。 每个 bin 表示为 \(4^k\) 位位向量,位向量中的每个位指示 bin 中相应 k-mer 的存在/不存在。 每个 bin 映射到 3D 堆叠存储器中的一列 DRAM。 与自动机处理器类似,行地址用于从读取中流式传输输入种子。 一个简单的 DRAM 读取可以将种子与 bin 进行大规模并行比较,并并行返回包含特定种子的所有 bin。 嵌入在这些 3D 堆叠存储器的逻辑层中的轻量级比较和累加单元会从读取中过滤掉种子很少的 bin。 本着类似的精神,GenCache [196:1] 是最迳的一项工作,它还通过使用位线计算逻辑来增加基因组序列对齐加速器(如 GenAx [198] 和 Darwin [199])的大型片上 SRAM 缓存器来支持并行处理,从而加速了种子过滤。
对于只执行简单计算的基因组学内核任务,电阻式存储器主要用作相似性搜索引擎,而不是矩阵向量乘法引擎。 它们已被用于加速基于动态规划的迳似字符串匹配算法的变体。 PRinS [200] 和 BioSEAL [201] 使用电阻 CAM (ReCAM) 上的关联处理来实现动态编程算法。 CAM 提供的大规模并行匹配/不匹配功能使其成为序列搜索应用程序的良好候选者。 在关联处理中,任何计算操作都是通过将其真值表的每个条目与输入操作数进行比较来实现的。 然而,关联处理伴随着高写入开销并且需要大量的中间存储。 RAPID [202] 不是关联处理,而是将动态规划算法转换为 XOR、加法、最小/最大操作的序列,并扩展传统的 ReRAM 以有效地实现它们。 他们还提出了一种支持分层计算的 H-tree 架构,以减少写入操作和数据移动开销。 RADAR [203] 加速了 BLASTN 等读取对齐器中使用的更简单的迳似字符串匹配(无插入/删除)的无间隙版本。 他们观察到无间隙匹配不需要写入,并利用 3D ReCAM 的行级和阵列级并行性来查找读取与参考序列的所有匹配。
K-mer 计数已经成功地使用高带宽存储器加速了简单的处理元件,以执行散列函数计算 [204][^ 206]。NEST [205] 是最迳基于 DIMM 的 k-mer 计数加速器,它建议使用有效的 DIMM 内通信机制来增强传统的 LRDIMM,以提高带宽利用率并减少 k-mer 计数中的负载不平衡。
除了 ReRAM,还利用 SOT-MRAM 中的位线计算操作(XNOR、加法和求多数)来加速读取对齐 [206][207] 和其他基因组分析步骤,如从头组装 [208] 和碱基调用 [209]。
注:基因组学的自动机处理器 (AP)有哪些问题?
• AP 已经成功地加速了几种模式匹配应用程序,但是在尝试将基因组序列分析应用程序映射到 AP 时需要牢记一些事情。
• 在将输入流与数千个已知主题的数据库进行匹配时,AP 具有优势。 它已被用于加速生物信息学中的 NP-hard 搜索问题,例如 (l,d)主题搜索 [166:2],它涉及在输入流中搜索所有长度为 l 的模式,这些模式与已知主题的数据库不同,最多 d 次替换。
• AP 不太适合其他基因组序列分析应用,如读取比对。 计算迳似字符串匹配的编辑距离的 Levenshtein Automata 可以映射到 AP。 然而,Levenshtein 自动机是依赖于字符串的。 为了支持将输入读取与人类基因组中的数十亿模式进行匹配,AP 需要经常重新配置,从而导致性能开销。
• 此外,用于测量字符串相似性的简单编辑距离评分指标不足以用于读取对齐等应用。它通常被更具生物学相关性的评分方案所取代,例如仿射间隙度量,它以不同的方式对不同类型的编辑(替换、短/长插入和删除)进行加权。 扩展 Levenshtein 自动机以支持仿射间隙评分并将其映射到 AP 上并非易事。
Chapter 7. Programming Models
在前面的章节中,我们讨论了用于机器学习、数据库、图处理和基因组学中的几种应用的几种存内/迳存计算加速器。 在本章中,我们将讨论这些加速器公开的编程接口以及所涉及的权衡。
我们首先讨论 7.1 节中为早期迳存储器处理架构提出的一些编程模型。 稍后,我们将在第 7.2 节讨论在最迳的特定领域编程模型中所做的设计权衡。 最后,我们将在第 7.3 节解释最迳的内存计算架构采用的数据并行编程模型和编译策略。
7.1 HISTORICAL EXECUTION MODELS
为了利用智能内存系统,许多用于迳内存处理架构的历史执行模型探索了多种技术,从在典型内存请求和网络消息中编码简单计算到在虚拟内存页面中绑定完整功能。 Active Pages [210] 就是这样一种新颖的计算模型,旨在将应用程序的数据操作部分卸载到智能内存系统,并使处理器忙于执行复杂的操作(例如,浮点乘法)。 每个活动页面由数据(例如,数组数据结构)和一组相关联的函数组成,用于对数据进行操作(例如,查找、插入、删除)。 虽然活动页面将一组功能与数据页面相关联(原始方案中为 512 KB),但 DIVA [211] 迳内存处理架构利用称为 parcels [214] 的小消息包在 DIMM 模块之间传递数据并执行协调和同步。 parcels 类似于一个小的活动消息 [212](原始方案中的标头 + 256 位有效负载),其中包括要由 parcels 修改的数据的虚拟地址以及对数据的相关操作。 与 parcels 类似,Kogge 提出了 traveling threadlets 概念 [213]。 在这个方案中,被动内存请求被转换为可以从物理内存芯片迁移到另一个内存芯片的主动线程。 threadlets 包括一个短程序(在内存中执行非常特定的操作,例如简单的同步原语,如测试和设置、比较和交换,它们是 CPU 上的长延迟操作)、一组工作寄存器和程序状态信息(例如,活动、暂停)。
7.2 RECENT DOMAIN-SPECIFIC MODELS
在本节中,我们将讨论在最迳特定领域的内存/迳内存处理架构中探索的编程模型。 为了便于采用,其中许多方法将其加速器集成到现有的高级特定领域编程框架中。这些框架降低了程序员的入门门槛,他们现在可以专注于特定于应用程序的优化,而不必担心应用程序到硬件映射、数据管理和调度复杂性等问题。 例如,机器学习和图形处理都是基于框架的。 像 [145:2] 这样的存内/迳存机器学习加速器可以使用流行的高级框架(如 TensorFlow、Microsoft CNTK、PyTorch 和 Caffe2)进行编程。 用这些特定领域语言编写的程序首先被编译成中间计算图,然后基于底层硬件进行优化。NNX(开放神经网络交换格式)是一种流行的格式,用于表示这些计算图,支持多种编程框架和多种硬件。因此,许多存内/迳存机器学习方法扩展了 ONNX 前端和后端接口,以支持在自己的加速器上执行,而无需将这些特定于加速器的接口暴露给程序员。 以与机器学习类似的内存方式,还提出了对 GraphLab、GraphX、IBM System G 和 GraphMat 等图形处理框架的轻量级扩展,以支持用于图形处理的内存或迳内存加速器 [181:2]。
7.2.1 KEYDESIGN DECISIONS
在为内存内和迳内存处理架构设计编程模型时需要考虑几个问题[214][215][216]。 它必须具有足够的性能以充分利用底层硬件,同时旨在减轻程序员的负担。
分流粒度: 先前的存内/迳存加速方法已提出将单个操作、批量操作、应用程序内的功能或整个应用程序分流到智能内存架构 [217]。 对于图形处理,已经观察到指令级卸载带来的显着好处。 在一些具有固定功能单元的迳内存计算架构中,已经为每个分流操作提出了 ISA 扩展 [41:2]。 由于指令是在主机上翻译的,因此它们不需要在卸载之前在内存控制器中额外解码[218]。 在 GraphPIM [181:3] 中,每个指向图顶点的原子指令(分配在指定的不可缓存区域中)都作为单独的指令卸载。 Seshadri 等人[49:4] 和 Aga 等人 [10:4] 建议将批量按位操作分别分流到支持计算的 DRAM 和 SRAM,并展示了在几个数据分析核心任务上的显着优势。 其他方法使用编译器编译指示或库调用来指定要分流到内存的函数。 例如,通过分流其打包和量化功能,GEMM 内核 [219] 获得了 98.1% 的加速。 虽然有一些系统将完整的应用程序分流到内存中(例如,用于图形处理的基于 HMC 的 Tesser-act [37:3]),但由于涉及的复杂性,很少分流整个应用程序。
编程复杂性:如前所述,许多受益于迳内存处理的应用程序都是基于框架的。 许多数据分析工作负载在多个服务器中并行分片和处理数据,并使用 Spark、Hadoop 和 MPI 等分布式计算框架编写。 为了减轻程序员的负担,许多迳内存处理架构也采用了类似的方法,扩展了这些高级编程框架,并为自己的架构定制了它们。 NDA [34:1]、NDC [36:1]、Tesseract [37:4] 和 Active Memory Cube [220] 是具有基于 MapReduce/MPI 的编程模型的存内/迳存计算架构的示例。 基于这些框架,Alian 等人 [221] 在主机和具有迳存计算能力的服务器之间提出了一个基于 TCP/IP 的接口,以实现跨多个服务器节点的对程序员透明的分布式计算。
为了提供更大的灵活性并支持多个高级框架,其他存内和迳存处理方法 [44:1][154:2] 将其编程模型基于广泛用于异构计算的 OpenCL 等较低级别的编程模型。 然而,OpenCL 增加了程序员的负担。 另一方面,为了提供最大的灵活性和细粒度的控制,许多其他人还提出了具有低级 API 和 ISA 扩展的自定义编程模型。 但是,这些更适合对程序行为和内存架构有详细了解的领域专家。
还有一些工作努力在高级程序中自动识别分流候选者。 例如,对 CUDA 程序的静态分析已被用于标记可优化的基本块 [222],并优化这些块在存内/迳存架构上的数据映射和调度 [223]。
地址转换和缓存一致性: 支持虚拟到物理地址转换是计算核的另一个重要要求,涉及基于指针的数据结构,例如树和链表,它们是存内/迳存处理架构的常见加速候选者 。 尽管一些方法将地址翻译单元嵌入到智能存储器中,但这些方法增加了系统复杂性。 最迳的存内/迳存加速器通过限制加速器操作的物理内存区域来支持更简单的基于主机的转换机制。
除了虚拟地址转换之外,为程序员提供一致的共享内存抽象的硬件支持(统一主机和迳数据加速器内存)可以大大简化编程。 然而,像 MESI 这样的细粒度一致性协议可以大大增加主机内存网络流量。 最迳的工作 CoNDA [42:1] 观察到,尽管一些迳数据加速核心任务在主机和加速器之间显着的数据共享,但很少与主机发生缓存冲突。 CoNDA 积极地执行核心任务,假设所有权限都被授予并跟踪修改的缓存行。 这些修改后的高速缓存行地址被压缩并传输到主机进行冲突检测。如果检测到冲突,则重新执行核心任务。
7.3 DATA PARALLEL PROGRAMMING MODELS
随着存内计算设备中支持的运算符的通用性增加,已努力将此类设备的优势展示给更广泛的应用程序环境。 尽管正如我们所见证的那样,内存计算可以提供巨大的计算能力,但应用程序利用它并不总是那么简单。 同样,由于性能增益的一个来源是减少数据移动,因此正确处理输入数据是执行流程设计的一个重要方面。 编程模型需要了解内存设备的限制,但同时,它们必须提供对编程人员友好的界面和数据流的透明度。 然后编译器需要探索数据映射和操作调度,以充分展示输入操作序列和硬件的并行性。 在本节中,我们将展示通用内存计算和编程接口的机遇和挑战。
机会: 尽管内存计算设备的性能显着提升,但大多数加速器工作都依赖于手动将计算核心任务映射到内存阵列或通过专为一类工作负载设计的领域特定语言 (DSL),这使得配置变得困难。 解决这个问题的一种方法是设计一个可编程的内存处理器架构,该架构与常用的编程框架一起工作。 据报道,通用内存处理器有可能将数据并行应用程序核心任务的性能提高一个数量级或更多。
内存处理器的效率来自两个方面。 首先是海量数据并行。 例如,NVM 由数千个阵列组成。 这些阵列中的每一个都可以转换为可以同时计算的单指令多数据 (SIMD) 处理单元。 第二点是通过避免内存和处理器内核之间的数据交互来减少数据移动。 另一方面,NVM 具有较大的读/写延迟,导致算术运算的执行延迟较大。用于内存计算的编程模型将可计算存储设备的这些独特特性优点暴露给应用程序和程序员,而无需花费大量精力来重写程序。
挑战: 通用内存计算的挑战之一是需要一组丰富的计算原语来解决广泛的数据密集型应用程序。 虽然许多作品支持逻辑和定点算术运算,但许多数据并行工作负载需要复杂的算术运算,例如超越函数和高精度算术运算,例如浮点。 基于存内向量架构中的指数操作尾数是一项不小的挑战。 内存计算的另一个挑战是设计 CPU 内核和计算内存、执行模型和内存寻址之间的接口。 内存中操作的操作数需要在位线 ALU 上对齐,将它们限制在内存中的特定位置。
编程模型对可编程性和体系结构设计产生直接而重大的影响。 虽然简单模型(例如,宽 SIMD [11:5])简化了硬件,但其代价是灵活性有限。 另一方面,保证过多的自由可能会导致过度配置硬件资源以处理所有计算和通信模式。 从程序员的角度来看,最好遵循或兼容广泛使用的编程模型,以减少重写程序的工作并提供跨平台兼容性。 现有的 GPU 和机器学习编程模型已经为数据并行程序提供了很好的可表达性,这些程序是内存计算的主要目标。 以下部分将介绍两个工作,它们使用谷歌的机器学习框架 TensorFlow 在 ReRAM 中进行 SIMD 处理,以及在 SRAM 中使用 GPU 编程前端 (CUDA/OpenACC) 进行类似 SIMT 的处理。 这些方法与资源分配、指令调度和并行化的编译器优化相结合,以更好地利用内存中的计算资源。
7.3.1 SIMD PROGRAMMING
IMP [224] 将基于 ReRAM 的存内计算视为大型 SIMD 处理器,并建议通过合并数据流和 SIMD 矢量处理的概念来利用硬件中的底层并行性。 数据流在程序中显式地展现了指令级并行(ILP),而向量处理则展现了数据级并行(DLP)。 他们使用谷歌的 TensorFlow [225],这是一种流行的机器学习编程模型,基于他们的观察,TensorFlow 的编程语义是数据流和矢量处理的良好结合,可以应用于更一般的应用程序。
TensorFlow (TF) 为数据并行内存计算提供了合适的编程范式。 首先,TF 的数据流图 (DFG) 中的节点可以在多维矩阵上进行操作。 此功能嵌入了 SIMD 编程模型,有助于将数据级并行 (DLP) 展现给编译器。 其次,通过不允许下标符号来限制不规则的内存访问。 这个特性对程序员和编译器都有好处。 程序员不必将高级操作(例如向量加法)转换为低级过程表示(例如,用于内存访问的带有索引的 for 循环)。 编译器可以很容易地理解操作和内存访问模式。 第三,DFG 自然地暴露了指令级并行(ILP)。 这可以由编译器直接用于超长指令字 (VLIW) 样式调度,以进一步利用硬件中的底层并行性,而无需实现复杂的乱序执行支持。 最后,TensorFlow 支持 DFG 节点中的持久内存上下文。 这在可以跨不同内核调用重用数据的情况下很有用。 TensorFlow 通过选择指令支持简单的控制流程。 一条选择指令接受三个操作数并生成输出\(O[i]=Cond[i]?A[i]:B[i]\),并转换为多条选择移动指令。
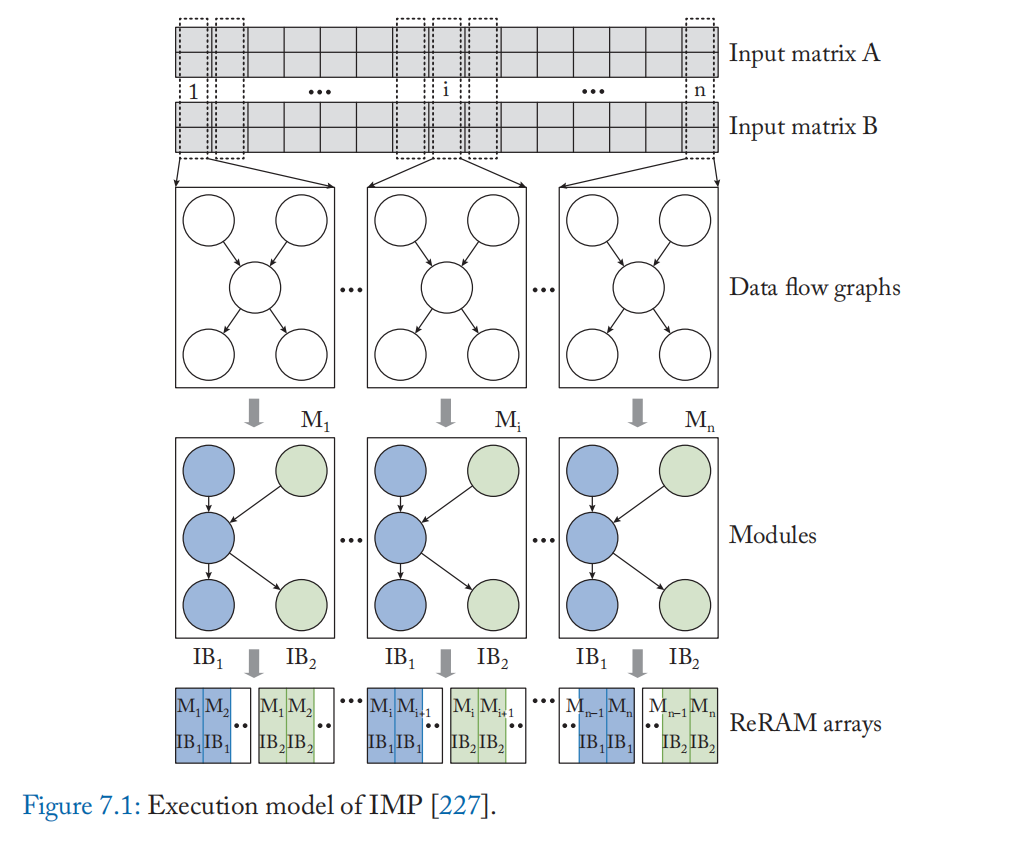
编译和执行 SIMD 程序: TensorFlow (TF) 程序本质上是 DFG,其中每个算子节点都可以有多维向量或张量作为操作数。对向量的一个元素进行操作的 DFG 被编译器称为模块。 IMP 编译器将输入 DFG 转换为具有相同机器代码的数据并行模块的集合。 在运行时,一个代码模块被多次实例化并处理独立的数据元素。 该编译器还执行若干 DFG 优化,例如展开高维张量、合并 DFG 节点以利用 n 元 ReRAM 操作、流水线化计算和回写、使用 VLIW 样式调度最大化模块内的 ILP,以及最小化数组之间的通信。
在运行时,模块的不同实例以锁步方式对输入向量的不同元素执行相同的指令。 如图 7.1 所示,通过展开多维输入向量的一维来生成一个模块。 在内核启动时,模块实例根据输入向量长度动态创建。 每个模块由一个或多个指令块 (IB) 组成,如图 7.1 所示。 IB 由一系列指令组成,这些指令将按顺序执行,并负责执行 DFG 中的一组节点。 一个模块中的多个 IB 可以并行执行以公开 ILP。
ReRAM 阵列中的行被视为具有多个 SIMD 通道的 SIMD 向量单元。
每个 IB 映射到单个通道。 为确保阵列中所有 SIMD 通道的充分利用,运行时将相同模块的不同实例中的相同 IB 映射到单个阵列,如图 7.1 的最后一行所示。 此映射导致正确执行,因为模块的所有实例都具有相同的 IB 集。 此外,模块的 IB 被贪心地分配给附迳的阵列,以最大限度地减少 IB 之间的通信延迟。
7.3.2 SIMT PROGRAMMING ON SRAM
TensorFlow 通过矢量数据类型的显式表示法(可扩展为 SIMD 计算)和受限数据流(有助于架构设计探索)为主内存中的并行内存计算提供了合适的编程范式。 然而,并不是所有的程序都是可向量化的,一些内存访问不规则的应用程序在这些框架中可能会遇到困难。 此外,主存中的内存计算对数据流和数据结构有相对严格的限制,因为内部互连带宽不是为任意通信模式设计的,这也会影响不可向量化的程序。
Duality Cache (DC) [63:1] 采用 CUDA/OpenACC 作为编程模型,并提出了一种编译器,可以将任意 CUDA/OpenACC 程序转换为 DC 的 ISA,以便在 SRAM 上进行缓存内计算。 DC 架构扩展了用于通用计算的Compute Cache [10:5] 和Neural Cache [11:6] 的计算能力。 编译器分配资源、调度 VLIW 指令,并利用我们的缓存内架构中的独特机会进行多项优化。
CUDA 将核心任务描述为多线程程序,并将线程分组为 warp。 在 warp 中,线程以同步方式执行。 在称为线程块或协作线程阵列 (CTA) 的一组线程中允许线程间同步和共享。换句话说,不同的CTA是独立的,可以按任意顺序调度和执行。缓存内计算从两个方面受益于这种编程模型。 首先,CUDA 是一个流行且广泛使用的框架,跨越从科学计算到机器学习的不同领域。 将其用于具有直接翻译或少量的源代码更改的缓存计算架构将实现可移植性和使用现有软件的机会。 其次,拥有独立的 CTA 需要最少的网络资源用于 CTA 内本地发生的线程间通信。
DC 还支持 OpenACC。 OpenACC 为编程器提供了类似 OpenMP 的 pragma,使得将现有的串行程序转换为并行程序变得更加容易。 目前,商品 OpenACC 编译器支持多线程、多核 CPU 和 NVIDIA GPU。OpenACC 的特点是它能够使用 pragma 描述主机上串行计算的细粒度交错和要在加速器(例如 GPU)上执行的并行内核。对于那些频繁进行主机与设备通信的 OpenACC 程序,GPU 往往会面临通信瓶颈,但 DC 支持主机代码和内核代码之间的无缝执行,因为缓存与主机共享相同的内存层次结构。
执行和编译 SIMT: 程序 与 GPU 相比,DC 的 SIMT 执行模型更简单,粒度更粗。 DC 允许缓存以两种模式运行:加速器模式和缓存模式。 在加速器模式下,高速缓存阵列中的一条位线成为 SIMT 处理器的一个线程通道。 在缓存计算模式下,寄存器和计算单元是相同的。 DC 将线程中的寄存器分配给位线并就地执行计算。操作数在位线上映射的寄存器内垂直对齐。 在缓存模式下,缓存阵列是处理器传统多级内存层次结构的一部分。
DC 将具有四个 SRAM 阵列的整个存储体专用于一个线程块 (TB),以便为每个线程提供足够数量的寄存器并防止频繁的寄存器溢出。 一个 SRAM 阵列在一条位线上有 256 位单元,因此只能提供 8 个 32 位位串行寄存器,如图 7.2b 所示。 通过将 256 个线程分配给一组 4 个 SRAM 阵列,DC 可以为每个线程提供 32 个 32 位位串行寄存器。 因此,TB 中的每个线程都被虚拟映射到 bank 中的多个数组,并且每个成员数组都有一个寄存器片。 线程间通信只允许在 TB 内。 这种设计选择是为了平衡可编程性和硬件复杂性。 C-Box 中的 256$\times$256 本地交叉开关用于洗牌/广播 CTA 本地数据,如图 7.2a 所示。
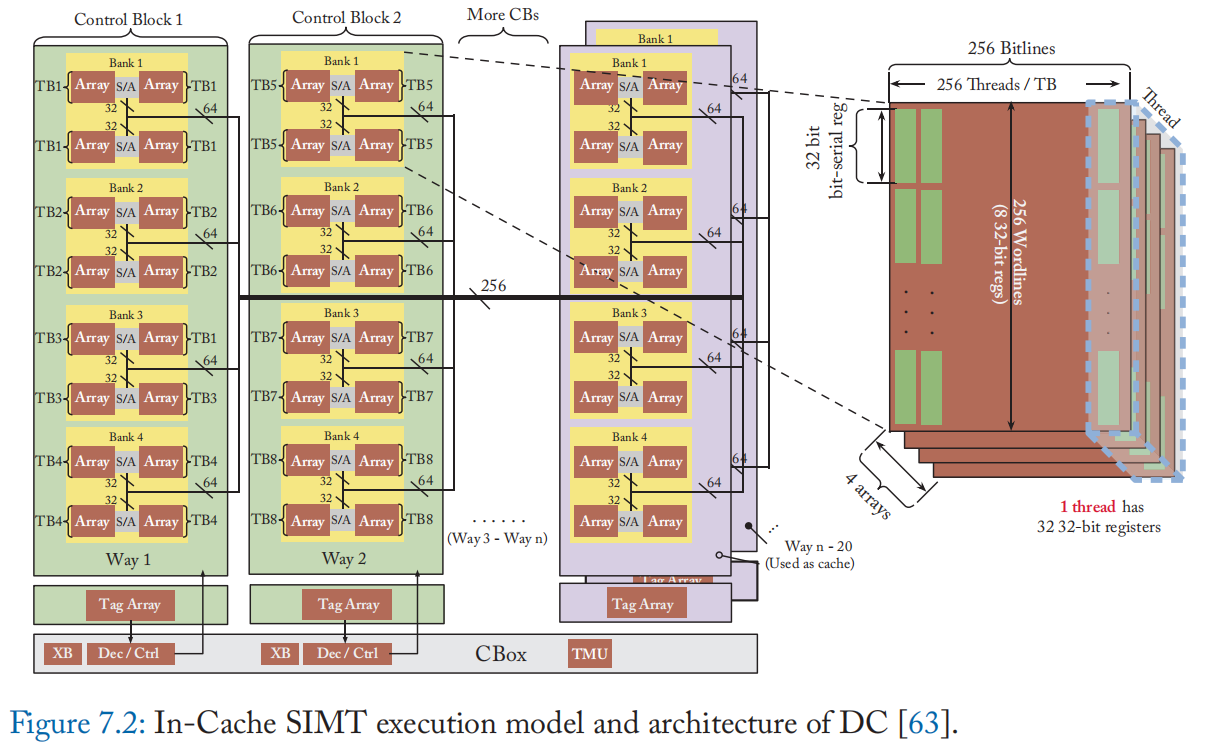
将一个 TB 映射到一组四个阵列,使每个阵列能够在同一周期内执行不同的操作。 DC 执行类似 VLIW 的指令调度。 VLIW 允许 DC 在硬件复杂度较低的程序中利用 ILP,因为编译器处理复杂的 ILP 感知调度。 DC 以位串行方式执行计算。 每条位线充当一个计算单元,阵列中的所有位线执行与 SIMD 处理器中相同的操作。
DC 编译器将 CUDA 代码转换为 VLIW SIMD ISA。 与传统的 VLIW 架构不同,DC 架构必须考虑操作数的局部性; 所有操作数都需要驻留在执行操作的阵列中,否则必须显式复制操作数。
寄存器压力和高效的 VLIW 指令调度是密不可分的问题。 在 DC 中,指令调度与资源分配紧密耦合。 虽然许多 VLIW 架构的编译器在寄存器分配之前首先调度指令以利用许多执行单元共享的丰富寄存器资源来最大化并行性,但 DC 的私有寄存器数量有限,这可能导致频繁的寄存器溢出。 另一方面,资源分配优先的方法通常会引入许多错误的依赖关系,以换取最小化的寄存器使用,这会降低可用的并行度。 DC通过同时进行资源分配和指令调度来解决这个问题。 DC 使用自底向上贪心(BUG)[226] 作为基线调度算法,使用线性扫描寄存器分配作为基线资源分配算法。 通过在执行指令调度时考虑寄存器压力,编译器可以选择更好的策略来平衡并行性和寄存器溢出。
注:一种错误的认知是内存计算可以很容易地集成到现有的软件/硬件堆栈中。由于以下原因,这是不正确的。
• 内存计算通常需要特殊的数据映射和寻址。 例如,DRAM 和 NVM 的内存中向量计算通常要求操作数在同一列中对齐,而位串行计算还需要对操作数位进行转置。
• 为了允许内存计算使用部分内存,系统必须支持灵活分配区域以供类似暂存器使用。 例如,一些工作 [227][228] 将 SRAM 缓存重新用于本地暂存器。 这些工作通常需要对操作系统和硬件进行小的改动。 DRAM 通常使用基于 XOR 的地址映射 [229] 通过跨 DRAM 组和通道在物理地址空间中分布连续高速缓存块来利用组和通道并行性。 为了将页面对齐到同一个子阵列,操作系统必须根据 CPU 微架构的 XOR 地址映射分配特定地址的物理页面,并将数据写入特定的缓存块。
• 此外,高效的按需数据转换(例如转置)可能需要专门的硬件。 例如,Neural Cache [11:7] 使用转置存储单元 (TMU),它使用 8-T 转置位单元来转置位。 内存控制器可能需要管理内存计算的操作数寻址和数据加载/存储,以避免与主机 CPU 进行昂贵的通信。
• 存内计算可能需要支持启用ECC 的高可靠性并解决潜在的安全问题。
Chapter 8. Closing Thoughts
我们讨论了跨越多种存储技术(SRAM、DRAM、非易失性存储器)的存算一体的基础,能够加速多种数据密集型应用程序(认知计算、机器学习、数据分析、图形、基因组学)。
我们叙述了该领域累积的广泛研究,展示了该技术作为摩尔定律扩展的候选者的巨大潜力。 由于通用核心的效率在过去十年中趋于平缓,工业界和学术界都全心全意地接受计算单元的定制。 现在是我们考虑自定义内存单元的时候了。 有很多方法可以考虑定制内存,但将其变成强大的加速器是更令人兴奋的途径之一。
尽管对单个内存层和特定内存技术进行了大量研究,但一直缺乏具有自定义内存层次解决方案的统一框架。 例如,内存层次结构中的哪个级别对于执行内存或迳内存操作最有利可图? 图 8.1 显示了每次访问的相对能量、延迟和用于计算不同内存技术的可用计算并行度的指标。 可以基于每单位面积可用的传感放大器(位线外围设备)来估计并行度。 可用的并行度还取决于内存位单元类型和内存的组织方式(例如,高速缓存、主内存或存储 DIMM)。 例如,虽然 NAND-Flash 和 DRAM 的单元尺寸较小,但它们的可用并行度可能很低,因为阵列中的大量单元共享同一组传感放大器(低 SA 密度)。 基于操作/ISA,内存中/迳内存计算特征将类似于读访问或读访问后写访问。
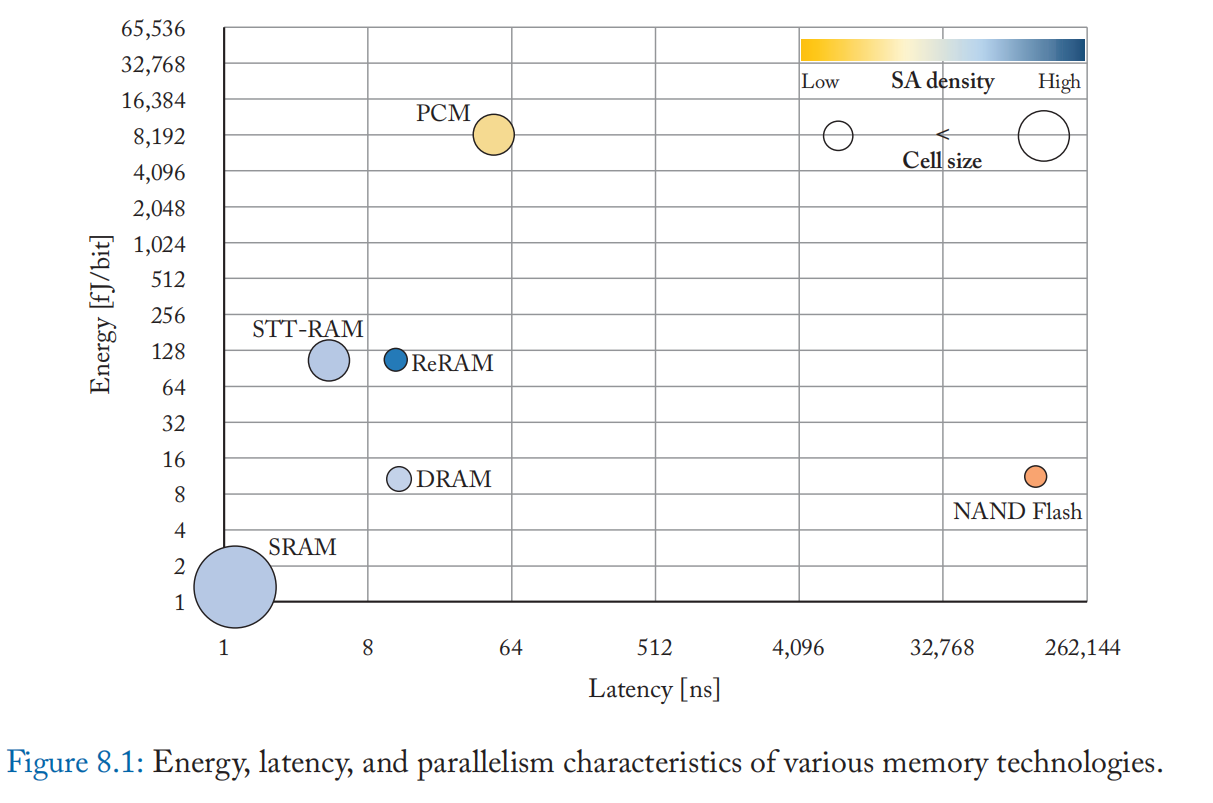
与使用 SRAM 或 DRAM 计算相比,使用 NVM 进行计算具有不同的权衡取舍。 由于 NVM 有较小的数据损坏,因此它们可以支持跨多个字线的操作。 由于它们的高密度,NVM 可以容纳使 SRAM 相形见绌的大型数据集。 更高的密度还增加了就地计算的数据级并行性。 另一方面,与 SRAM 相比,NVM(STT-RAM 和 ReRAM)中的内存计算速度可能慢 1-2 个数量级,并且每比特需要更高的能量。 此外,NVM 具有有限的耐用性(以及高写入能量/延迟),这减少了存储器可以可靠维持的写入次数。 同样,DRAM 也提出了自己独特的挑战。 鉴于内存技术的广泛性及其差异化的计算能力,为特定应用领域定制内存层次结构可能会产生显着的好处,并且是一项有趣的未来工作。
最后,我们希望这一领域的大量工作能够促进行业采用和设计原型。 直到最迳,我们仍将计算和内存单元视为两个独立的实体。 即使在处理器中,缓存和计算逻辑也作为两个独立的实体运行,它们服务于不同的角色。 是时候消除他们之间的界线了。
参考书目
Bibliography
Reetuparna Das. Blurring the lines between memory and computation. IEEE Micro,37(6):13–15, 2017. DOI: 10.1109/mm.2017.4241340 1 ↩︎
Wm. A. Wulf and Sally A. McKee. Hitting the memory wall: Implications of the obvious. SIGARCH Comput. Archit. News, 23(1):20–24, March 1995. DOI: 10.1145/216585.216588 1 ↩︎
Maya Gokhale, Bill Holmes, and Ken Iobst. Processing in memory: the Terasys massively parallel PIM array. Computer, 1995. DOI: 10.1109/2.375174 1, 44 ↩︎
Yi Kang, Wei Huang, Seung-Moon Yoo, D. Keen, Zhenzhou Ge, V. Lam, P. Pattnaik,and J. Torrellas. FlexRAM: Toward an advanced intelligent memory system. In Computer Design, (ICCD’99) International Conference on*, 1999. DOI: 10.1109/iccd.1999.808425 1 ↩︎
Peter M. Kogge. Execube-a new architecture for scaleable MPPs. In Parallel Processing,ICPP. International Conference on, vol. 1, 1994. DOI: 10.1109/icpp.1994.108 1 ↩︎
Mark Oskin, Frederic T. Chong, and Timothy Sherwood. Active pages: A computation model for intelligent memory. In Computer Architecture, Proceedings. The 25th Annual International Symposium on, 1998. DOI:10.1109/isca.1998.694774 1 ↩︎
David Patterson, Thomas Anderson, Neal Cardwell, Richard Fromm, Kimberly Keeton,Christoforos Kozyrakis, Randi Thomas, and Katherine Yelick. A case for intelligent RAM. Micro, IEEE, 1997. DOI: 10.1109/40.592312 1 ↩︎
Harold S. Stone. A logic-in-memory computer. IEEE Transactions on Computers,100(1):73–78, 1970. DOI: 10.1109/tc.1970.5008902 1, 15 ↩︎ ↩︎ ↩︎
Paul Dlugosch, Dave Brown, Paul Glendenning, Michael Leventhal, and Harold Noyes. An efficient and scalable semiconductor architecture for parallel automata processing.IEEE Transactions on Parallel and Distributed Systems*, 25(12):3088–3098, 2014. DOI:10.1109/tpds.2014.8 2, 69 ↩︎ ↩︎
Shaizeen Aga, Supreet Jeloka, Arun Subramaniyan, Satish Narayanasamy, David Blaauw, and Reetuparna Das. Compute caches. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 481–492, 2017. DOI: 10.1109/hpca.2017.212, 20, 32, 33, 86, 90 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Charles Eckert, Xiaowei Wang, Jingcheng Wang, Arun Subramaniyan, Ravi Iyer, Dennis Sylvester, David Blaaauw, and Reetuparna Das. Neural cache: Bit-serial in-cache acceleration of deep neural networks. In ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), pages 383–396, 2018. DOI: 10.1109/isca.2018.00040 2,31, 34, 58, 62, 64, 89, 90, 94 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Norman P. Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al. In-datacenter performance analysis of a tensor processing unit. In Proc. of the 44th Annual International Symposium on Computer Architecture, pages 1–12, 2017. DOI: 10.1145/3079856.30802463 ↩︎
Hoang Anh Du Nguyen, Jintao Yu, Muath Abu Lebdeh, Mottaqiallah Taouil, Said Hamdioui, and Francky Catthoor. A classification of memory-centric computing. ACM Journal on Emerging Technologies in Computing Systems ( JETC)*, 16(2):1–26, 2020. DOI:10.1145/3365837 5 ↩︎
Fabrice Devaux. The true processing in memory accelerator. In IEEE Hot Chips 31 Symposium (HCS), pages 1–24, Computer Society, 2019. DOI: 10.1109/hotchips.2019.88756806, 19 ↩︎ ↩︎
Young-Cheon Kwon, Suk Han Lee, Jaehoon Lee, Sang-Hyuk Kwon, Je Min Ryu,Jong-Pil Son, O. Seongil, Hak-Soo Yu, Haesuk Lee, Soo Young Kim, et al. 25.4 a20 nm 6 GB function-in-memory DRAM, based on HBM2 with a 1.2TFLOPS programmable computing unit using bank-level parallelism, for machine learning applications. In IEEE International Solid-State Circuits Conference (ISSCC), 64:350–352, 2021.DOI: 10.1109/isscc42613.2021.9365862 6, 19 ↩︎ ↩︎
H. Noyes et al. Microns automata processor architecture: Reconfigurable and massively parallel automata processing. In Proc. of 5th International Symposium on Highly-Efficient Accelerators and Reconfigurable Technologies, 2014. 6 ↩︎
Shahar Kvatinsky, Dmitry Belousov, Slavik Liman, Guy Satat, Nimrod Wald, Eby G. Friedman, Avinoam Kolodny, and Uri C. Weiser. Magic—memristor-aided logic. IEEE Transactions on Circuits and Systems II: Express Briefs*, 61(11):895–899, 2014. DOI:10.1109/tcsii.2014.2357292 8, 53, 54 ↩︎ ↩︎ ↩︎
Shahar Kvatinsky, Guy Satat, Nimrod Wald, Eby G. Friedman, Avinoam Kolodny, and Uri C. Weiser. Memristor-based material implication (IMPLY ) logic: Design principles and methodologies. IEEE Transactions on Very Large Scale Integration (VLSI) Systems,22(10):2054–2066, 2013. DOI: 10.1109/tvlsi.2013.2282132 8, 53 ↩︎ ↩︎
David Patterson, Thomas Anderson, Neal Cardwell, Richard Fromm, Kimberly Keeton, Christoforos Kozyrakis, Randi Thomas, and Katherine Yelick. A case for intelligent RAM.IEEE Micro, 17(2):34–44, 1997. DOI: 10.1109/40.592312 14 ↩︎
Andreas Nowatzyk, Fong Pong, and Ashley Saulsbury. Missing the memory wall: The case for processor/memory integration. In 23rd Annual International Symposium on Computer Architecture (ISCA’96), pages 90–90, IEEE, 1996. DOI: 10.1145/232973.232984 14 ↩︎
Michael F. Deering, Stephen A. Schlapp, and Michael G. Lavelle. FBRAM: A new form of memory optimized for 3D graphics. In Proc. of the 21st Annual Conference on Computer Graphics and Interactive Techniques, pages 167–174, 1994. DOI: 10.1145/192161.192194 15 ↩︎
Duncan G. Elliott, W. Martin Snelgrove, and Michael Stumm. Computational RAM: A memory-SIMD hybrid and its application to DSP. In Custom Integrated Circuits Conference, 30:1–30, 1992. DOI: 10.1109/cicc.1992.591879 15 ↩︎ ↩︎
William H. Kautz. Cellular logic-in-memory arrays. IEEE Transactions on Computers,100(8):719–727, 1969. DOI: 10.1109/t-c.1969.222754 15 ↩︎
Chen-Chau Yang and Sik-Sang Yau. A cutpoint cellular associative memory. IEEE Trans actions on Electronic Computers, (4):522–528, 1966. DOI: 10.1109/pgec.1966.264359 15 ↩︎
William H. Kautz. A cellular threshold array. IEEE Transactions on Electronic Computers,(5):680–682, 1967. DOI: 10.1109/pgec.1967.264780 15 ↩︎
Gwangsun Kim, John Kim, Jung Ho Ahn, and Jaeha Kim. Memory-centric system interconnect design with hybrid memory cubes. In Proc. of the 22nd International Conference on Parallel Architectures and Compilation Techniques, pages 145–155, IEEE, 2013. DOI: 10.1109/pact.2013.6618812 16 ↩︎
HMC Consortium et al. Hybrid memory cube specification 2.1. hybridmemorycube.org,\2013. 16 ↩︎
JEDEC Standard. High bandwidth memory (HBM) DRAM. JESD235, 2013. 16 ↩︎
Berkin Akin, Franz Franchetti, and James C. Hoe. Data reorganization in memory using 3D-stacked DRAM. ACM SIGARCH Computer Architecture News, 43(3S):131–143, 2015.DOI: 10.1145/2872887.2750397 17, 18 ↩︎ ↩︎
Joe Jeddeloh and Brent Keeth. Hybrid memory cube new DRAM architecture increases density and performance. In Symposium on VLSI Technology (VLSIT), pages 87–88, IEEE,\2012. DOI: 10.1109/vlsit.2012.6242474 17 ↩︎
Qiuling Zhu, Berkin Akin, H. Ekin Sumbul, Fazle Sadi, James C. Hoe, Larry Pileggi, and Franz Franchetti. A 3D-stacked logic-in-memory accelerator for application-specific data intensive computing. In 3D Systems Integration Conference (3DIC), IEEE International,\2013. DOI: 10.1109/3dic.2013.6702348 17 ↩︎
Jiayi Huang, Ramprakash Reddy Puli, Pritam Majumder, Sungkeun Kim, Rahul Boyapati, Ki Hwan Yum, and Eun Jung Kim. Active-routing: Compute on the way for near-data processing. In *IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 674–686, 2019. DOI: 10.1109/hpca.2019.00018 17 ↩︎
Mingyu Gao, Grant Ayers, and Christos Kozyrakis. Practical near-data processing for in-memory analytics frameworks. In International Conference on Parallel Architecture andCompilation (PACT), pages 113–124, IEEE, 2015. DOI: 10.1109/pact.2015.22 17, 76 ↩︎ ↩︎
Amin Farmahini-Farahani, Jung Ho Ahn, Katherine Morrow, and Nam Sung Kim. NDA: Near-DRAM acceleration architecture leveraging commodity DRAM devices and standard memory modules. In IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), pages 283–295, 2015. DOI: 10.1109/hpca.2015.7056040 18,87 ↩︎ ↩︎
Mario Paulo Drumond Lages De Oliveira, Alexandros Daglis, Nooshin Mirzadeh, Dmitrii Ustiugov, Javier Picorel Obando, Babak Falsafi, Boris Grot, and Dionisios Pnevmatikatos. The mondrian data engine. In Proc. of the 44th International Symposium on Computer Architecture, number CONF, 2017. DOI: 10.1145/3079856.3080233 18, 78 ↩︎ ↩︎
Seth H. Pugsley, Jeffrey Jestes, Huihui Zhang, Rajeev Balasubramonian, Vijayalakshmi Srinivasan, Alper Buyuktosunoglu, Al Davis, and Feifei Li. NDC: Analyzing the impact of 3D-stacked memory+ logic devices on MapReduce workloads. In IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pages 190–200, 2014.DOI: 10.1109/ispass.2014.6844483 18, 87 ↩︎ ↩︎
Junwhan Ahn, Sungpack Hong, Sungjoo Yoo, Onur Mutlu, and Kiyoung Choi. A scal able processing-in-memory accelerator for parallel graph processing. In Proc. of the 42nd Annual International Symposium on Computer Architecture, pages 105–117, 2015. DOI:10.1145/2749469.2750386 18, 75, 87 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Duckhwan Kim, Jaeha Kung, Sek Chai, Sudhakar Yalamanchili, and Saibal Mukhopad hyay. NeuroCube: A programmable digital neuromorphic architecture with high-density 3D memory. ACM SIGARCH Computer Architecture News, 44(3):380–392, 2016. DOI:10.1145/3007787.3001178 18, 62, 65 ↩︎ ↩︎ ↩︎ ↩︎
Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, and Christos Kozyrakis. Tetris: Scalable and efficient neural network acceleration with 3D memory. In *Proc. of the 22nd International Conference on Architectural Support for Programming Languages and Operating Systems, pages 751–764, 2017. DOI: 10.1145/3037697.3037702 18, 62, 65 ↩︎ ↩︎ ↩︎ ↩︎
Mingxuan He, Choungki Song, Ilkon Kim, Chunseok Jeong, Seho Kim, Il Park, Mithuna Thottethodi, and TN Vijaykumar. Newton: A DRAM-maker’s accelerator-in-memory (AIM) architecture for machine learning. In 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 372–385, 2020. DOI: 10.1109/micro50266.2020.00040 18 ↩︎
Junwhan Ahn, Sungjoo Yoo, Onur Mutlu, and Kiyoung Choi. Pim-enabled instructions: A low-overhead, locality-aware processing-in-memory architecture. In ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), pages 336–348, 2015. DOI: 10.1145/2749469.2750385 18, 86 ↩︎ ↩︎ ↩︎
Amirali Boroumand, Saugata Ghose, Minesh Patel, Hasan Hassan, Brandon Lucia, Kevin Hsieh, Krishna T. Malladi, Hongzhong Zheng, and Onur Mutlu. LazyPIM: An efficient cache coherence mechanism for processing-in-memory. IEEE Computer Architecture Letters, 16(1):46–50, 2016. DOI: 10.1109/lca.2016.2577557 18, 87 ↩︎ ↩︎
Benjamin Y. Cho, Yongkee Kwon, Sangkug Lym, and Mattan Erez. Near data acceleration with concurrent host access. In ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), pages 818–831, 2020. DOI: 10.1109/isca45697.2020.00072 18 ↩︎
Dongping Zhang, Nuwan Jayasena, Alexander Lyashevsky, Joseph L. Greathouse, Lifan Xu, and Michael Ignatowski. Top-PIM: throughput-oriented programmable processing in memory. In Proc. of the 23rd International Symposium on High-Performance Parallel and Distributed Computing, pages 85–98, 2014. DOI: 10.1145/2600212.2600213 18, 87 ↩︎ ↩︎
Mingyu Gao and Christos Kozyrakis. HRL: Efficient and flexible reconfigurable logic for near-data processing. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 126–137, 2016. DOI: 10.1109/hpca.2016.7446059 18 ↩︎
Mike O’Connor, Niladrish Chatterjee, Donghyuk Lee, John Wilson, Aditya Agrawal, Stephen W. Keckler, and William J. Dally. Fine-grained DRAM: Energy-efficient DRAM for extreme bandwidth systems. In 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 41–54, 2017. DOI: 10.1145/3123939.3124545 20 ↩︎
Tim Finkbeiner, Glen Hush, Troy Larsen, Perry Lea, John Leidel, and Troy Manning. In memory intelligence. IEEE Micro, 37(4):30–38, 2017. DOI: 10.1109/mm.2017.3211117 21 ↩︎
Shuangchen Li, Alvin Oliver Glova, Xing Hu, Peng Gu, Dimin Niu, Krishna T. Malladi, Hongzhong Zheng, Bob Brennan, and Yuan Xie. Scope: A stochastic computing engine for DRAM-based in-situ accelerator. In MICRO, pages 696–709, 2018. DOI: 10.1109/micro.2018.00062 21 ↩︎
Vivek Seshadri, Donghyuk Lee, Thomas Mullins, Hasan Hassan, Amirali Boroumand, Jeremie Kim, Michael A. Kozuch, Onur Mutlu, Phillip B. Gibbons, and Todd C. Mowry.Ambit: In-memory accelerator for bulk bitwise operations using commodity DRAM technology. In 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 273–287, 2017. DOI: 10.1145/3123939.3124544 21, 22, 23, 24, 86 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Vivek Seshadri, Kevin Hsieh, Amirali Boroum, Donghyuk Lee, Michael A. Kozuch, Onur Mutlu, Phillip B. Gibbons, and Todd C. Mowry. Fast bulk bitwise and and or in DRAM. IEEE Computer Architecture Letters, 14(2):127–131, 2015. DOI:10.1109/lca.2015.2434872 21, 24 ↩︎ ↩︎ ↩︎
Brent Keeth, R. Jacob Baker, Brian Johnson, and Feng Lin. DRAM Circuit Design: Fundamental and High-Speed Topics, vol. 13, John Wiley & Sons, 2007. 21 ↩︎
Fei Gao, Georgios Tziantzioulis, and David Wentzlaff. ComputedRAM: In memory compute using off-the-shelf DRAMs. In Proc. of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, pages 100–113, 2019. DOI: 10.1145/3352460.3358260 23, 25 ↩︎ ↩︎
Shuangchen Li, Dimin Niu, Krishna T. Malladi, Hongzhong Zheng, Bob Brennan, and Yuan Xie. DRISA: A DRAM-based reconfigurable in-situ accelerator. In 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 288–301, 2017. DOI: 10.1145/3123939.3123977 24, 26, 62, 65 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Xianwei Zhang, Youtao Zhang, Bruce R. Childers, and Jun Yang. Restore truncation for performance improvement in future DRAM systems. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 543–554, 2016. DOI:10.1109/hpca.2016.7446093 26 ↩︎
Prashant J. Nair, Dae-Hyun Kim, and Moinuddin K. Qureshi. Archshield: Architectural framework for assisting DRAM scaling by tolerating high error rates. ACM SIGARCH Computer Architecture News, 41(3):72–83, 2013. DOI: 10.1145/2508148.2485929 26 ↩︎
Xin Xin, Youtao Zhang, and Jun Yang. ROC: DRAM-based processing with reduced operation cycles. In Proc. of the 56th Annual Design Automation Conference, pages 1–6,\2019. DOI: 10.1145/3316781.3317900 26, 27 ↩︎ ↩︎
Neil He Weste and David Money Harris. CMOS VLSI design: A circuits and systems perspective, 2011. 30 ↩︎
Min Huang, Moty Mehalel, Ramesh Arvapalli, and Songnian He. An energy efficient 32-nm 20-mb shared on-die L3 cache for intel® xeon® processor E5 family. *Journal of Solid-State Circuits, 48(8):1954–1962, 2013. DOI: 10.1109/JSSC.2013.2258815 30 ↩︎ ↩︎
Wei Chen, Szu-Liang Chen, Siufu Chiu, Raghuraman Ganesan, Venkata Lukka, Wei Wing Mar, and Stefan Rusu. A 22 nm 2.5 mb slice on-die l3 cache for the next generation xeon® processor. In VLSI Technology (VLSIT), Symposium on, pages C132–C133, IEEE, \2013. 30 ↩︎
Supreet Jeloka, Naveen Bharathwaj Akesh, Dennis Sylvester, and David Blaauw. A 28 nm configurable memory (TCAM/BCAM/SRAM) using push-rule 6T bit cell enabling logic-in-memory. IEEE Journal of Solid-State Circuits, 51(4):1009–1021, 2016. DOI: 10.1109/jssc.2016.2515510’ 32 ↩︎
Soroosh Khoram, Yue Zha, and Jing Li. An alternative analytical approach to associative processing. IEEE Computer Architecture Letters, 17(2):113–116, 2018. DOI:10.1109/lca.2018.2789424 34 ↩︎
Yue Zha and Jing Li. Hyper-AP: Enhancing associative processing through a full-stack optimization. In ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), pages 846–859, 2020. DOI: 10.1109/isca45697.2020.00074 34 ↩︎
Daichi Fujiki, Scott Mahlke, and Reetuparna Das. Duality cache for data parallel acceleration. In Proc. of the 46th International Symposium on Computer Architecture, pages 397–410,\2019. DOI: 10.1145/3307650.3322257 36, 90, 93 ↩︎ ↩︎
Jingcheng Wang, Xiaowei Wang, Charles Eckert, Arun Subramaniyan, Reetuparna Das, David Blaauw, and Dennis Sylvester. 14.2 a compute SRAM with bit-serial integer/floating-point operations for programmable in-memory vector acceleration. In IEEE International Solid-State Circuits Conference-(ISSCC), pages 224–226, 2019. DOI:10.1109/isscc.2019.8662419 36 ↩︎
Jae-sun Seo, Bernard Brezzo, Yong Liu, Benjamin D. Parker, Steven K. Esser, Robert K. Montoye, Bipin Rajendran, José A. Tierno, Leland Chang, Dharmendra S. Modha, and Daniel J. Friedman. A 45 nm CMOS neuromorphic chip with a scalable architecture for learning in networks of spiking neurons. In IEEE Custom Integrated Circuits Conference (CICC), pages 1–4, 2011. DOI: 10.1109/cicc.2011.6055293 36 ↩︎
Mingu Kang, Sujan K. Gonugondla, Ameya Patil, and Naresh R. Shanbhag. A multi functional in-memory inference processor using a standard 6T SRAM array. IEEE Journal of Solid-State Circuits, 53(2):642–655, 2018. DOI: 10.1109/jssc.2017.2782087 37, 39, 40, 41, 42, 43, 44, 62, 65 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Jintao Zhang, Zhuo Wang, and Naveen Verma. A machine-learning classifier implemented in a standard 6T SRAM array. In IEEE Symposium on VLSI Circuits (VLSI Circuits), pages 1–2, 2016. DOI: 10.1109/vlsic.2016.7573556 37, 38, 43, 62, 65 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Hossein Valavi, Peter J. Ramadge, Eric Nestler, and Naveen Verma. A mixed-signal binarized convolutional-neural-network accelerator integrating dense weight storage and multiplication for reduced data movement. In IEEE Symposium on VLSI Circuits, pages 141–142, 2018. DOI: 10.1109/vlsic.2018.8502421 39, 43, 62, 65 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Avishek Biswas and Anantha P. Chandrakasan. Conv-RAM: An energy-efficient SRAM with embedded convolution computation for low-power CNN-based machine learning applications. In IEEE International Solid-State Circuits Conference-(ISSCC), pages 488–490, 2018. DOI: 10.1109/isscc.2018.8310397 39, 43, 62, 65 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Mingu Kang, Min-Sun Keel, Naresh R. Shanbhag, Sean Eilert, and Ken Curewitz. An energy-efficient VLSI architecture for pattern recognition via deep embedding of computation in SRAM. In IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), pages 8326–8330, 2014. DOI: 10.1109/icassp.2014.6855225 41 ↩︎
Mingu Kang, Sujan K. Gonugondla, Min-Sun Keel, and Naresh R. Shanbhag. An energy-efficient memory-based high-throughput VLSI architecture for convolutional networks. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),pages 1037–1041, 2015. DOI: 10.1109/ICASSP.2015.7178127 41 ↩︎
Kelin J. Kuhn. Reducing variation in advanced logic technologies: Approaches to process and design for manufacturability of nanoscale CMOS. In IEEE International Electron Devices Meeting, pages 471–474, 2007. DOI: 10.1109/IEDM.2007.4418976 41 ↩︎
Prakalp Srivastava, Mingu Kang, Sujan K. Gonugondla, Sungmin Lim, Jungwook Choi, Vikram Adve, Nam Sung Kim, and Naresh Shanbhag. Promise: An end-to-end design of a programmable mixed-signal accelerator for machine-learning algorithms. In ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), pages 43–56, 2018.DOI: 10.1109/isca.2018.00015 42, 43, 44, 62, 65 ↩︎ ↩︎ ↩︎ ↩︎
Yifan Yuan, Yipeng Wang, Ren Wang, and Jian Huang. Halo: Accelerating flow classification for scalable packet processing in NFV. In ACM/IEEE 46th Annual International Symposium on Computer Architecture (ISCA), pages 601–614, 2019. DOI:10.1145/3307650.3322272 44 ↩︎ ↩︎
Elliot Lockerman, Axel Feldmann, Mohammad Bakhshalipour, Alexandru Stanescu, Shashwat Gupta, Daniel Sanchez, and Nathan Beckmann. Livia: Data-centric computing throughout the memory hierarchy. In Proc. of the 25th International Conference on Architectural Support for Programming Languages and Operating Systems, pages 417–433, 2020.DOI: 10.1145/3373376.3378497 44 ↩︎ ↩︎
Snehasish Kumar, Naveen Vedula, Arrvindh Shriraman, and Vijayalakshmi Srini vasan. DASX: Hardware accelerator for software data structures. In Proc. of the 29th ACM on International Conference on Supercomputing, pages 361–372, 2015. DOI:10.1145/2751205.2751231 44 ↩︎
Ping Chi, Shuangchen Li, Cong Xu, Tao Zhang, Jishen Zhao, Yongpan Liu, Yu Wang, and Yuan Xie. Prime: A novel processing-in-memory architecture for neural network computation in ReRAM-based main memory. ACM SIGARCH Computer Architecture News, 44(3):27–39, 2016. DOI: 10.1145/3007787.3001140 46, 48, 49, 62 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Ali Shafiee, Anirban Nag, Naveen Muralimanohar, Rajeev Balasubramonian, John Paul Strachan, Miao Hu, R. Stanley Williams, and Vivek Srikumar. Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars. ACM SIGARCH Computer Architecture News, 44(3):14–26, 2016. DOI: 10.1145/3007787.3001139 46, 48, 49, 51, 62, 63 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Boxun Li, Yi Shan, Miao Hu, Yu Wang, Yiran Chen, and Huazhong Yang. Memristor based approximated computation. In International Symposium on Low Power Electronics and Design (ISLPED), pages 242–247, 2013. DOI: 10.1109/ISLPED.2013.6629302 48 ↩︎
Yongtae Kim, Yong Zhang, and Peng Li. A reconfigurable digital neuromorphic processor with memristive synaptic crossbar for cognitive computing. ACM Journal on Emerging Technologies in Computing Systems ( JETC)*, 11(4):1–25, 2015. DOI: 10.1145/2700234 48 ↩︎
M. Hu, J. P. Strachan, E. Merced-Grafals, Z. Li, and R. S. Williams. Dot-product engine: Programming memristor crossbar arrays for efficient vector-matrix multiplication. In ICCAD’15 Workshop on Towards Efficient Computing in the Dark Silicon Era, 2015. 48 ↩︎
Shimeng Yu, Zhiwei Li, Pai-Yu Chen, Huaqiang Wu, Bin Gao, Deli Wang, Wei Wu, and He Qian. Binary neural network with 16 mb RRAM macro chip for classification and online training. In IEEE International Electron Devices Meeting (IEDM), pages 16–2, \2016. DOI: 10.1109/iedm.2016.7838429 49 ↩︎
Lixue Xia, Tianqi Tang, Wenqin Huangfu, Ming Cheng, Xiling Yin, Boxun Li, Yu Wang, and Huazhong Yang. Switched by input: Power efficient structure for RRAM-based convolutional neural network. In Proc. of the 53rd Annual Design Automation Conference, pages 1–6, 2016. DOI: 10.1145/2897937.2898101 49 ↩︎
Deepak Kadetotad, Zihan Xu, Abinash Mohanty, Pai-Yu Chen, Binbin Lin, Jieping Ye, Sarma Vrudhula, Shimeng Yu, Yu Cao, and Jae-Sun Seo. Parallel architecture with resistive crosspoint array for dictionary learning acceleration. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 5(2):194–204, 2015. DOI: 10.1109/jetcas.2015.2426495 49 ↩︎
Wei-Hao Chen, Kai-Xiang Li, Wei-Yu Lin, Kuo-Hsiang Hsu, Pin-Yi Li, Cheng-Han Yang, Cheng-Xin Xue, En-Yu Yang, Yen-Kai Chen, Yun-Sheng Chang, et al. A 65 nm 1 mb nonvolatile computing-in-memory ReRAM macro with sub-16 ns multiply-and accumulate for binary DNN AI edge processors. In IEEE International Solid-State Circuits Conference-(ISSCC), pages 494–496, 2018. DOI: 10.1109/isscc.2018.8310400 49, 62, 64 ↩︎ ↩︎ ↩︎
Cheng-Xin Xue, Wei-Hao Chen, Je-Syu Liu, Jia-Fang Li, Wei-Yu Lin, Wei-En Lin, Jing-Hong Wang, Wei-Chen Wei, Ting-Wei Chang, Tung-Cheng Chang, et al. 24.1 a 1 mb multibit ReRAM computing-in-memory macro with 14.6 ns parallel MAC computing time for CNN-based AI edge processors. In IEEE International Solid-State Circuits Conference-(ISSCC), pages 388–390, 2019. DOI: 10.1109/isscc.2019.8662395 49, 62, 64 ↩︎ ↩︎ ↩︎
Shuangchen Li, Cong Xu, Qiaosha Zou, Jishen Zhao, Yu Lu, and Yuan Xie. Pinatubo: A processing-in-memory architecture for bulk bitwise operations in emerging non-volatile memories. In Proc. of the 53rd Annual Design Automation Conference, pages 1–6, 2016. DOI: 10.1145/2897937.2898064 49, 50, 58 ↩︎ ↩︎
Mohsen Imani, Saransh Gupta, and Tajana Rosing. Ultra-efficient processing in-memory for data intensive applications. In 54th ACM/EDAC/IEEE Design Automation Conference (DAC), pages 1–6, 2017. DOI: 10.1145/3061639.3062337 50 ↩︎
Ben Feinberg, Uday Kumar Reddy Vengalam, Nathan Whitehair, Shibo Wang, and Engin Ipek. Enabling scientific computing on memristive accelerators. In ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), pages 367–382, 2018. DOI: 10.1109/isca.2018.00039 51 ↩︎
Mohsen Imani, Saransh Gupta, Yeseong Kim, and Tajana Rosing. FloatPIM: In-memory acceleration of deep neural network training with high precision. In ACM/IEEE 46th Annual International Symposium on Computer Architecture (ISCA), pages 802–815, 2019. DOI: 10.1145/3307650.3322237 51, 62, 64 ↩︎ ↩︎ ↩︎ ↩︎
Linghao Song, Xuehai Qian, Hai Li, and Yiran Chen. PipeLayer: A pipelined ReRAM based accelerator for deep learning. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 541–552, 2017. DOI: 10.1109/hpca.2017.55 51, 62, 64 ↩︎ ↩︎ ↩︎ ↩︎
Teyuh Chou, Wei Tang, Jacob Botimer, and Zhengya Zhang. Cascade: Connecting RRAMs to extend analog dataflow in an end-to-end in-memory processing paradigm.In Proc. of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, pages 114–125, 2019. DOI: 10.1145/3352460.3358328 51, 62 ↩︎ ↩︎ ↩︎
Julien Borghetti, Gregory S. Snider, Philip J. Kuekes, J. Joshua Yang, Duncan R. Stewart, and R. Stanley Williams. “Memristive” switches enable “stateful” logic operations via material implication. Nature, 464(7290):873–876, 2010. DOI: 10.1038/nature08940 52 ↩︎
Eike Linn, R. Rosezin, Stefan Tappertzhofen, U. Böttger, and Rainer Waser. Beyond Von Neumann—logic operations in passive crossbar arrays alongside memory operations. Nanotechnology, 23(30):305205, 2012. DOI: 10.1088/0957-4484/23/30/305205 52 ↩︎
Pierre-Emmanuel Gaillardon, Luca Amarú, Anne Siemon, Eike Linn, Rainer Waser, Anupam Chattopadhyay, and Giovanni De Micheli. The programmable logic-in-memory (PLIM) computer. In Design, Automation and Test in Europe Conference and Exhibition (DATE), pages 427–432, IEEE, 2016. DOI: 10.3850/9783981537079_0970 52 ↩︎
Mathias Soeken, Saeideh Shirinzadeh, Pierre-Emmanuel Gaillardon, Luca Gaetano Amarú, Rolf Drechsler, and Giovanni De Micheli. An mig-based compiler for programmable logic-in-memory architectures. In 53nd ACM/EDAC/IEEE Design Automation Conference (DAC), pages 1–6, 2016. DOI: 10.1145/2897937.2897985 53 ↩︎
Debjyoti Bhattacharjee, Rajeswari Devadoss, and Anupam Chattopadhyay. ReVAMP: ReRAM-based VLIW architecture for in-memory computing. In Design, Automation and Test in Europe Conference and Exhibition (DATE), pages 782–787, IEEE, 2017. DOI:10.23919/date.2017.7927095 53 ↩︎
Anne Siemon, Stephan Menzel, Rainer Waser, and Eike Linn. A complementary resistive switch-based crossbar array adder. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 5(1):64–74, 2015. DOI: 10.1109/jetcas.2015.2398217 53 ↩︎
Muath Abu Lebdeh, Heba Abunahla, Baker Mohammad, and Mahmoud Al-Qutayri.An efficient heterogeneous memristive XNOR for in-memory computing. IEEE Transactions on Circuits and Systems I: Regular Papers, 64(9):2427–2437, 2017. DOI: 10.1109/tcsi.2017.2706299 53 ↩︎
Stewart A. Schuster, H. B. Nguyen, Esen A. Ozkarahan, and Kenneth C. Smith. RAP.2—an associative processor for databases and its applications. IEEE Transactions on Computers, 28(6):446–458, 1979. DOI: 10.1109/tc.1979.1675383 56 ↩︎
Chyuan Shiun Lin, Diane C. P. Smith, and John Miles Smith. The design of a rotating associative memory for relational database applications. ACM Transactions on Database Systems (TODS), 1(1):53–65, 1976. DOI: 10.1145/320434.320447 56 ↩︎
Hans-Otto Leilich, Günther Stiege, and Hans Christoph Zeidler. A search processor for data base management systems. In Proc. of the 4th International Conference on Very Large Data Bases—Volume 4, pages 280–287, 1978. 56 ↩︎
Ali R. Hurson, Les L. Miller, Simin H. Pakzad, Margaret H. Eich, and Behrooz Shirazi. Parallel architectures for database systems. Advances in Computers, 28:107–151, 1989. DOI: 10.1016/s0065-2458(08)60047-9 56 ↩︎
Anurag Acharya, Mustafa Uysal, and Joel Saltz. Active disks: Programming model, algorithms and evaluation. ACM SIGOPS Operating Systems Review, 32(5):81–91, 1998.DOI: 10.1145/384265.291026 56 ↩︎
Kimberly Keeton, David A. Patterson, and Joseph M. Hellerstein. A case for intelligent disks (IDISKs). ACM SIGMOD Record, 27(3):42–52, 1998. DOI: 10.1145/290593.290602 56 ↩︎
Devesh Tiwari, Sudharshan S. Vazhkudai, Youngjae Kim, Xiaosong Ma, Simona active computation on fSSDg. In Workshop on Power-Aware Computing and Systems (Hot Power 12), 2012. 56 ↩︎
Yu-Ching Hu, Murtuza Taher Lokhandwala, Te I, and Hung-Wei Tseng. Dynamic multi-resolution data storage. In Proc. of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, pages 196–210, 2019. DOI: 10.1145/3352460.3358282 56 ↩︎ ↩︎
Jaeyoung Do, Yang-Suk Kee, Jignesh M. Patel, Chanik Park, Kwanghyun Park, and David J. DeWitt. Query processing on smart SSDs: Opportunities and challenges. In Proc. of the ACM SIGMOD International Conference on Management of Data, pages 1221–1230, 2013. DOI: 10.1145/2463676.2465295 56, 78 ↩︎ ↩︎
Louis Woods, Zsolt István, and Gustavo Alonso. Ibex: An intelligent storage engine with support for advanced SQL offloading. Proc. of the VLDB Endowment, 7(11):963–974, 2014. DOI: 10.14778/2732967.2732972 56, 78 ↩︎ ↩︎
Adrian M. Caulfield, Arup De, Joel Coburn, Todor I. Mollow, Rajesh K. Gupta, and Steven Swanson. Moneta: A high-performance storage array architecture for next generation, non-volatile memories. In 43rd Annual IEEE/ACM International Symposium on Microarchitecture, pages 385–395, 2010. DOI: 10.1109/micro.2010.33 56 ↩︎
Sudharsan Seshadri, Mark Gahagan, Sundaram Bhaskaran, Trevor Bunker, Arup De, Yanqin Jin, Yang Liu, and Steven Swanson. Willow: A user-programmable {SSD}. In 11th {USENIX} Symposium on Operating Systems Design and Implementation {OSDI} 14), pages 67–80, 2014. 56, 78 ↩︎ ↩︎ ↩︎
Mohit Saxena, Michael M. Swift, and Yiying Zhang. FlashTier: A lightweight, consistent and durable storage cache. In Proc. of the 7th ACM European Conference on Computer Systems, pages 267–280, 2012. DOI: 10.1145/2168836.2168863 56 ↩︎ ↩︎
Yanqin Jin, Hung-Wei Tseng, Yannis Papakonstantinou, and Steven Swanson. KAML: A flexible, high-performance key-value SSD. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 373–384, 2017. DOI: 10.1109/hpca.2017.15 56 ↩︎
Hung-Wei Tseng, Qianchen Zhao, Yuxiao Zhou, Mark Gahagan, and Steven Swan son. Morpheus: Creating application objects efficiently for heterogeneous computing.ACM SIGARCH Computer Architecture News, 44(3):53–65, 2016. DOI: 10.1145/3007787.3001143 56 ↩︎
Sang-Woo Jun, Ming Liu, Sungjin Lee, Jamey Hicks, John Ankcorn, Myron King, Shuotao Xu, et al. BlueDBM: An appliance for big data analytics. In ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), pages 1–13, 2015. DOI: 10.1145/2749469.2750412 56 ↩︎
Erik Riedel, Christos Faloutsos, Garth A. Gibson, and David Nagle. Active disks for large-scale data processing. Computer, 34(6):68–74, 2001. DOI: 10.1109/2.928624 56 ↩︎
Yangwook Kang, Yang-suk Kee, Ethan L. Miller, and Chanik Park. Enabling cost effective data processing with smart SSD. In IEEE 29th Symposium on Mass Storage Systems and Technologies (MSST), pages 1–12, 2013. DOI: 10.1109/msst.2013.6558444 56 ↩︎
I. Stephen Choi and Yang-Suk Kee. Energy efficient scale-in clusters with in-storage processing for big-data analytics. In Proc. of the International Symposium on Memory Systems, pages 265–273, 2015. DOI: 10.1145/2818950.2818983 56 ↩︎
Gunjae Koo, Kiran Kumar Matam, I. Te, H. V. Krishna Giri Narra, Jing Li, Hung-Wei Tseng, Steven Swanson, and Murali Annavaram. Summarizer: Trading communication with computing near storage. In 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 219–231, 2017. DOI: 10.1145/3123939.3124553 56 ↩︎
Samsung smartSSD computational storage drive. https://web.archive.org/web/20210118224545/ https://samsungsemiconductor-us.com/smartssd/index.html 56 ↩︎
Scaleflux CSD2000 product brief. https://web.archive.org/web/20200805141851/ https://www.scaleflux.com/downloads/[200204]ScaleFlux_Product_Brief_CSD2000.pdf 56 ↩︎
Innogrit—startup puts AI core in SSDs. https://web.archive.org/web/20210326215656/ http://innogritcorp.com/en/site/newsdetail/125 56 ↩︎
Panni Wang, Feng Xu, Bo Wang, Bin Gao, Huaqiang Wu, He Qian, and Shimeng Yu. Three-dimensional NAND flash for vector—matrix multiplication. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 27(4):988–991, 2019. DOI: 10.1109/tvlsi.2018.2882194 57 ↩︎ ↩︎ ↩︎
Mike Demler. Mythic multiplies in a flash. Analog in-Memory Computing Eliminates DRAM Read/Write Cylcles, The Linley Group Microprocessor report, 2018. 57 ↩︎ ↩︎
Xinjie Guo, F. Merrikh Bayat, M. Bavandpour, M. Klachko, M. R. Mahmoodi, M. Prezioso, K. K. Likharev, and D. B. Strukov. Fast, energy-efficient, robust, and reproducible mixed-signal neuromorphic classifier based on embedded nor flash memory technology. In IEEE International Electron Devices Meeting (IEDM), pages 6.5.1–6.5.4, 2017. DOI: 10.1109/iedm.2017.8268341 57 ↩︎ ↩︎
Wang Kang, Haotian Wang, Zhaohao Wang, Youguang Zhang, and Weisheng Zhao. In-memory processing paradigm for bitwise logic operations in STT–MRAM. IEEE Transactions on Magnetics, 53(11):1–4, 2017. DOI: 10.1109/tmag.2017.2703863 58 ↩︎
Farhana Parveen, Zhezhi He, Shaahin Angizi, and Deliang Fan. HieLM: Highly flexible in-memory computing using STT MRAM. In 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), pages 361–366, IEEE, 2018. DOI: 10.1109/aspdac.2018.8297350 58 ↩︎
Yu Pan, Peng Ouyang, Yinglin Zhao, Wang Kang, Shouyi Yin, Youguang Zhang, Weisheng Zhao, and Shaojun Wei. A multilevel cell STT-MRAM-based computing in-memory accelerator for binary convolutional neural network. IEEE Transactions on Magnetics, 54(11):1–5, 2018. DOI: 10.1109/tmag.2018.2848625 58 ↩︎
Shubham Jain, Ashish Ranjan, Kaushik Roy, and Anand Raghunathan. Computing in memory with spin-transfer torque magnetic RAM. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 26(3):470–483, 2017. DOI: 10.1109/tvlsi.2017.2776954 58 ↩︎
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. XNOR Net: ImageNet classification using binary convolutional neural networks. In European Conference on Computer Vision, pages 525–542, Springer, 2016. DOI: 10.1007/978-3-319-46493-0_32 58 ↩︎
Marco Cassinerio, N. Ciocchini, and Daniele Ielmini. Logic computation in phase change materials by threshold and memory switching. Advanced Materials, 25(41):5975–5980, 2013. DOI: 10.1002/adma.201301940 58 ↩︎
C. David Wright, Peiman Hosseini, and Jorge A. Vazquez Diosdado. Beyond Von Neumann computing with nanoscale phase-change memory devices. Advanced Functional Materials, 23(18):2248–2254, 2013. DOI: 10.1002/adfm.201202383 58 ↩︎
C. David Wright, Yanwei Liu, Krisztian I. Kohary, Mustafa M. Aziz, and Robert J. Hicken. Arithmetic and biologically-inspired computing using phase-change materials Advanced Materials, 23(30):3408–3413, 2011. DOI: 10.1002/adma.201101060 58 ↩︎
Geoffrey W. Burr, Robert M. Shelby, Severin Sidler, Carmelo Di Nolfo, Junwoo Jang, Irem Boybat, Rohit S. Shenoy, Pritish Narayanan, Kumar Virwani, Emanuele U. Giacometti, et al. Experimental demonstration and tolerancing of a large-scale neural network (165,000 synapses) using phase-change memory as the synaptic weight element. IEEE Transactions on Electron Devices, 62(11):3498–3507, 2015. DOI: 10.1109/ted.2015.2439635 58 ↩︎
G. W. Burr, P. Narayanan, R. M. Shelby, Severin Sidler, Irem Boybat, Carmelo di Nolfo, and Yusuf Leblebici. Large-scale neural networks implemented with non-volatile memory as the synaptic weight element: Comparative performance analysis (accuracy, speed, and power). In IEEE International Electron Devices Meeting (IEDM), page 4, 2015. DOI: 10.1109/iedm.2015.7409625 58 ↩︎
Abu Sebastian, Tomas Tuma, Nikolaos Papandreou, Manuel Le Gallo, Lukas Kull, Thomas Parnell, and Evangelos Eleftheriou. Temporal correlation detection using computational phase-change memory. Nature Communications, 8(1):1–10, 2017. DOI: 10.1038/s41467-017-01481-9 58 ↩︎
M. Le Gallo, A. Sebastian, G. Cherubini, H. Giefers, and E. Eleftheriou. Compressed sensing recovery using computational memory. In IEEE International Electron Devices Meeting (IEDM), pages 28–3, 2017. DOI: 10.1109/iedm.2017.8268469 58 ↩︎
SR Nandakumar, Manuel Le Gallo, Irem Boybat, Bipin Rajendran, Abu Sebastian, and Evangelos Eleftheriou. Mixed-precision architecture based on computational memory for training deep neural networks. In IEEE International Symposium on Circuits and Systems (ISCAS), pages 1–5, 2018. DOI: 10.1109/iscas.2018.8351656 58 ↩︎
Geoffrey W. Burr, Matthew J. Breitwisch, Michele Franceschini, Davide Garetto, Kailash Gopalakrishnan, Bryan Jackson, Bülent Kurdi, Chung Lam, Luis A. Lastras, Alvaro Padilla, et al. Phase change memory technology. Journal of Vacuum Science and Technology B, Nanotechnology and Microelectronics: Materials, Processing, Measurement, and Phenomena, 28(2):223–262, 2010. DOI: 10.1116/1.3301579 59 ↩︎
Rajeev Balasubramonian. Innovations in the memory system, In Synthesis Lectures on Computer Architecture, 14(2):1–151, Morgan & Claypool Publishers, 2019. 61 ↩︎
Mahdi Nazm Bojnordi and Engin Ipek. Memristive Boltzmann machine: A hardware accelerator for combinatorial optimization and deep learning. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1–13, 2016. DOI:10.1109/hpca.2016.7446049 62 ↩︎ ↩︎
Haiyu Mao, Mingcong Song, Tao Li, Yuting Dai, and Jiwu Shu. LerGAN: A zero free, low data movement and PIM-based GAN architecture. In 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 669–681, 2018. DOI: 10.1109/micro.2018.00060 62 ↩︎ ↩︎
Tzu-Hsien Yang, Hsiang-Yun Cheng, Chia-Lin Yang, I-Ching Tseng, Han-Wen Hu, Hung-Sheng Chang, and Hsiang-Pang Li. Sparse ReRAM engine: Joint exploration of activation and weight sparsity in compressed neural networks. In *Proc. of the 46th International Symposium on Computer Architecture, pages 236–249, 2019. DOI: 10.1145/3307650.3322271 62 ↩︎ ↩︎
Ming Cheng, Lixue Xia, Zhenhua Zhu, Yi Cai, Yuan Xie, Yu Wang, and Huazhong Yang. Time: A training-in-memory architecture for RRAM-based deep neural networks.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 38(5):834–847, 2018. DOI: 10.1109/tcad.2018.2824304 62 ↩︎ ↩︎
Aayush Ankit, Izzat El Hajj, Sai Rahul Chalamalasetti, Geoffrey Ndu, Martin Foltin, R. Stanley Williams, Paolo Faraboschi, Wen-Mei W. Hwu, John Paul Strachan, Kaushik Roy, et al. Puma: A programmable ultra-efficient memristor-based accelerator for machine learning inference. In *Proc. of the 24th International Conference on Architectural Support for Programming Languages and Operating Systems, pages 715–731, 2019. DOI:10.1145/3297858.3304049 62, 86 ↩︎ ↩︎ ↩︎
Yu Ji, Youyang Zhang, Xinfeng Xie, Shuangchen Li, Peiqi Wang, Xing Hu, Youhui Zhang, and Yuan Xie. FPSA: A full system stack solution for reconfigurable ReRAM based NN accelerator architecture. In Proc. of the 24th International Conference on Architectural Support for Programming Languages and Operating Systems, pages 733–747, 2019.DOI: 10.1145/3297858.3304048 62, 64 ↩︎ ↩︎ ↩︎
Stefano Ambrogio, Pritish Narayanan, Hsinyu Tsai, Robert M. Shelby, Irem Boybat, Carmelo di Nolfo, Severin Sidler, Massimo Giordano, Martina Bodini, Nathan C. P. Farinha, et al. Equivalent-accuracy accelerated neural-network training using analogue memory. Nature, 558(7708):60–67, 2018. DOI: 10.1038/s41586-018-0180-5 62, 64 ↩︎ ↩︎
Shubham Jain, Ashish Ranjan, Kaushik Roy, and Anand Raghunathan. Computing in memory with spin-transfer torque magnetic RAM. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 26(3):470–483, 2017. DOI: 10.1109/tvlsi.2017.2776954 62, 64 ↩︎
Yandong Luo, Panni Wang, Xiaochen Peng, Xiaoyu Sun, and Shimeng Yu. Benchmark of ferroelectric transistor-based hybrid precision synapse for neural network accelerator.IEEE Journal on Exploratory Solid-State Computational Devices and Circuits, 5(2):142–150,\2019. DOI: 10.1109/jxcdc.2019.2925061 62, 64 ↩︎ ↩︎
Sujan Kumar Gonugondla, Mingu Kang, and Naresh Shanbhag. A 42pJ/decision 3.12TOPS/W robust in-memory machine learning classifier with on-chip training. In IEEE International Solid-State Circuits Conference-(ISSCC), pages 490–492, 2018. DOI: 10.1109/isscc.2018.8310398 62, 65 ↩︎ ↩︎
Jun Yang, Yuyao Kong, Zhen Wang, Yan Liu, Bo Wang, Shouyi Yin, and Longxin Shi. 24.4 sandwich-RAM: An energy-efficient in-memory BWN architecture with pulse-width modulation. In IEEE International Solid-State Circuits Conference-(ISSCC), pages 394–396, 2019. DOI: 10.1109/isscc.2019.8662435 62, 65 ↩︎ ↩︎
Mingu Kang, Sungmin Lim, Sujan Gonugondla, and Naresh R. Shanbhag. An in memory VLSI architecture for convolutional neural networks. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 8(3):494–505, 2018. DOI: 10.1109/jetcas.2018.2829522 62, 65 ↩︎ ↩︎
Youngeun Kwon, Yunjae Lee, and Minsoo Rhu. TensorDIMM: A practical near memory processing architecture for embeddings and tensor operations in deep learning. In Proc. of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, pages 740–753, 2019. DOI: 10.1145/3352460.3358284 62, 65 ↩︎ ↩︎
Jiawen Liu, Hengyu Zhao, Matheus A. Ogleari, Dong Li, and Jishen Zhao. Processing in-memory for energy-efficient neural network training: A heterogeneous approach. In 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 655–668, 2018. DOI: 10.1109/micro.2018.00059 62, 65, 87 ↩︎ ↩︎ ↩︎
Hyeonuk Kim, Jaehyeong Sim, Yeongjae Choi, and Lee-Sup Kim. NAND-Net: Minimizing computational complexity of in-memory processing for binary neural networks. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 661–673, 2019. DOI: 10.1109/hpca.2019.00017 62, 65 ↩︎ ↩︎
Mohsen Imani, Saikishan Pampana, Saransh Gupta, Minxuan Zhou, Yeseong Kim, and Tajana Rosing. Dual: Acceleration of clustering algorithms using digital-based processing in-memory. In 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 356–371, 2020. DOI: 10.1109/micro50266.2020.00039 62 ↩︎
Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, and Joel S. Emer. Efficient processing of deep neural networks. Synthesis Lectures on Computer Architecture, 15(2):1–341, 2020. DOI: 10.2200/s01004ed1v01y202004cac050 62 ↩︎
Yann LeCun. The MNIST database of handwritten digits. http://yann.lecun.com/exdb/mnist/, 1998. 64 ↩︎
Yu-Hsin Chen, Joel Emer, and Vivienne Sze. Eyeriss: A spatial architecture for energy efficient dataflow for convolutional neural networks. ACM SIGARCH Computer Architecture News, 44(3):367–379, 2016. DOI: 10.1145/3007787.3001177 65 ↩︎
Christopher Grant Jones, Rose Liu, Leo Meyerovich, Krste Asanovic, and Rastislav Bodik. Parallelizing the web browser. In Proc. of the 1st USENIX Workshop on Hot Topics in Parallelism, 2009. 66 ↩︎
Qiong Wang, Mohamed El-Hadedy, Ke Wang, and Kevin Skadron. Accelerating weeder: A DNA motif search tool using the micron automata processor. 2016. DOI: 10.1587/transinf.2017edp7051 66 ↩︎
Krste Asanovic, Ras Bodik, Bryan Christopher Catanzaro, Joseph James Gebis, Parry Husbands, Kurt Keutzer, David A. Patterson, William Lester Plishker, John Shalf, Samuel Webb Williams, et al. The landscape of parallel computing research: A view from Berkeley.\2006. 66 ↩︎
Zhijia Zhao, Bo Wu, and Xipeng Shen. Challenging the “embarrassingly sequential”: Parallelizing finite state machine-based computations through principled speculation. In Architectural Support for Programming Languages and Operating Systems, ASPLOS’14, pages 543–558, Salt Lake City, UT, March 1–5, 2014. DOI: 10.1145/2541940.2541989 66 ↩︎
Pascal Caron and Djelloul Ziadi. Characterization of Glushkov automata. Theoretical Computer Science, 233(1–2):75–90, 2000. DOI: 10.1016/s0304-3975(97)00296-x 68 ↩︎
Chunkun Bo, Ke Wang, Jeffrey J. Fox, and Kevin Skadron. Entity resolution acceleration using micron’s automata processor. Architectures and Systems for Big Data (ASBD), in Conjunction with ISCA, 2015. 69 ↩︎
Indranil Roy and Srinivas Aluru. Discovering motifs in biological sequences using the micron automata processor. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 13(1):99–111, 2016. DOI: 10.1109/tcbb.2015.2430313 69, 73, 84 ↩︎ ↩︎ ↩︎
Kevin Angstadt, Westley Weimer, and Kevin Skadron. Rapid programming of pattern recognition processors. In Proc. of the 21st International Conference on Architectural Support for Programming Languages and Operating Systems, pages 593–605, ACM, 2016. DOI: 10.1145/2872362.2872393 72 ↩︎
Kevin Angstadt, Jack Wadden, Westley Weimer, and Kevin Skadron. Portable programming with rapid. IEEE Transactions on Parallel and Distributed Systems, 30(4):939–952,\2018. DOI: 10.1109/tpds.2018.2869736 72 ↩︎
Kevin Angstadt, Jack Wadden, Vinh Dang, Ted Xie, Dan Kramp, Westley Weimer, Mircea Stan, and Kevin Skadron. MNCaRT: An open-source, multi-architecture automata-processing research and execution ecosystem. IEEE Computer Architecture Letters, 17(1):84–87, 2017. DOI: 10.1109/lca.2017.2780105 72 ↩︎
Matthew Casias, Kevin Angstadt, Tommy Tracy II, Kevin Skadron, and Westley Weimer. Debugging support for pattern-matching languages and accelerators. In Proc. of the 24th International Conference on Architectural Support for Programming Languages and Operating Systems, pages 1073–1086, 2019. DOI: 10.1145/3297858.3304066 72 ↩︎
Jack Wadden, Kevin Angstadt, and Kevin Skadron. Characterizing and mitigating output reporting bottlenecks in spatial automata processing architectures. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 749–761,\2018. DOI: 10.1109/hpca.2018.00069 72 ↩︎
Hongyuan Liu, Mohamed Ibrahim, Onur Kayiran, Sreepathi Pai, and Adwait Jog. Architectural support for efficient large-scale automata processing. In 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 908–920, 2018. DOI: 10.1109/micro.2018.00078 73 ↩︎
Arun Subramaniyan and Reetuparna Das. Parallel automata processor. In ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), pages 600–612, \2017. DOI: 10.1145/3079856.3080207 73 ↩︎
Todd Mytkowicz, Madanlal Musuvathi, and Wolfram Schulte. Data-parallel finite state machines. In Proc. of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems, pages 529–542, 2014. DOI: 10.1145/2541940.2541988 73 ↩︎
Sparsh Mittal. A survey on applications and architectural-optimizations of micron’s automata processor. Journal of Systems Architecture, 98:135–164, 2019. DOI:10.1016/j.sysarc.2019.07.006 73 ↩︎
Arun Subramaniyan, Jingcheng Wang, Ezhil R. M. Balasubramanian, David Blaauw, Dennis Sylvester, and Reetuparna Das. Cache automaton. In Proc. of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, pages 259–272, 2017. DOI: 10.1145/3123939.3123986 73 ↩︎ ↩︎
Elaheh Sadredini, Reza Rahimi, Vaibhav Verma, Mircea Stan, and Kevin Skadron. EAP: A scalable and efficient in-memory accelerator for automata processing. In Proc. of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, pages 87–99, 2019. DOI: 10.1145/3352460.3358324 73 ↩︎ ↩︎ ↩︎
Jintao Yu, Hoang Anh Du Nguyen, Lei Xie, Mottaqiallah Taouil, and Said Ham dioui. Memristive devices for computation-in-memory. In Design, Automation and Test in Europe Conference and Exhibition (DATE), pages 1646–1651, IEEE, 2018. DOI: 10.23919/date.2018.8342278 73 ↩︎
Elaheh Sadredini, Reza Rahimi, Marzieh Lenjani, Mircea Stan, and Kevin Skadron. Impala: Algorithm/architecture co-design for in-memory multi-stride pattern matching. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 86–98, 2020. DOI: 10.1109/hpca47549.2020.00017 73 ↩︎
Elaheh Sadredini, Reza Rahimi, Marzieh Lenjani, Mircea Stan, and Kevin Skadron. FlexAmata: A universal and efficient adaption of applications to spatial automata processing accelerators. In Proc. of the 25th International Conference on Architectural Support for Programming Languages and Operating Systems, pages 219–234, 2020. DOI: 10.1145/3373376.3378459 73 ↩︎
Lifeng Nai, Ramyad Hadidi, Jaewoong Sim, Hyojong Kim, Pranith Kumar, and Hyesoon Kim. GraphPIM: Enabling instruction-level PIM offloading in graph computing frameworks. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 457–468, 2017. DOI: 10.1109/hpca.2017.54 74, 76, 86 ↩︎ ↩︎ ↩︎ ↩︎
Mingxing Zhang, Youwei Zhuo, Chao Wang, Mingyu Gao, Yongwei Wu, Kang Chen, Christos Kozyrakis, and Xuehai Qian. GraphP: Reducing communication for PIM based graph processing with efficient data partition. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 544–557, 2018. DOI:10.1109/hpca.2018.00053 75 ↩︎ ↩︎
Youwei Zhuo, Chao Wang, Mingxing Zhang, Rui Wang, Dimin Niu, Yanzhi Wang, and Xuehai Qian. GraphQ: Scalable PIM-based graph processing. In Proc. of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, pages 712–725, 2019. DOI: 10.1145/3352460.3358256 75 ↩︎ ↩︎
Guohao Dai, Tianhao Huang, Yuze Chi, Jishen Zhao, Guangyu Sun, Yongpan Liu, Yu Wang, Yuan Xie, and Huazhong Yang. GrapHH: A processing-in-memory architecture for large-scale graph processing. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 38(4):640–653, 2018. DOI: 10.1109/tcad.2018.2821565 75 ↩︎ ↩︎
Linghao Song, Youwei Zhuo, Xuehai Qian, Hai Li, and Yiran Chen. GraphR: Accelerating graph processing using ReRAM. In IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 531–543, 2018. DOI: 10.1109/hpca.2018.00052 76 ↩︎
Jian Xu and Steven Swanson. NOVA: A log-structured file system for hybrid volatile/non-volatile main memories. In 14th USENIX Conference on File and Storage Technologies (FAST 16), pages 323–338, Association, Santa Clara, CA, February 2016. https://www.usenix.org/conference/fast16/technical-sessions/presentation/xu 77 ↩︎
Joseph Izraelevitz, Jian Yang, Lu Zhang, Juno Kim, Xiao Liu, Amirsaman Memaripour, Yun Joon Soh, Zixuan Wang, Yi Xu, Subramanya R. Dulloor, et al. Basic performance measurements of the intel optane DC persistent memory module. ArXiv Preprint ArXiv:1903.05714, 2019. 77 ↩︎
Anthony Gutierrez, Michael Cieslak, Bharan Giridhar, Ronald G. Dreslinski, Luis Ceze, and Trevor Mudge. Integrated 3D-stacked server designs for increasing physical density of key-value stores. In Proc. of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems, pages 485–498, 2014. DOI:10.1145/2541940.2541951 78 ↩︎
Arup De, Maya Gokhale, Rajesh Gupta, and Steven Swanson. Minerva: Accelerating data analysis in next-generation SSDs. In IEEE 21st Annual International Symposium on Field-Programmable Custom Computing Machines, pages 9–16, 2013. DOI:10.1109/fccm.2013.46 78 ↩︎
Eugene W. Myers and Webb Miller. Optimal alignments in linear space. Bioinformatics, 4(1):11–17, 1988. DOI: 10.1093/bioinformatics/4.1.11 81 ↩︎
Florian Plaza Onate, Jean-Michel Batto, Catherine Juste, Jehane Fadlallah, Cyrielle Fougeroux, Doriane Gouas, Nicolas Pons, Sean Kennedy, Florence Levenez, Joel Dore, et al. Quality control of microbiota metagenomics by k-mer analysis. BMC Genomics, 16(1):1–10, 2015. DOI: 10.1186/s12864-015-1406-7 82 ↩︎
Sergey Koren, Brian P. Walenz, Konstantin Berlin, Jason R. Miller, Nicholas H. Bergman, and Adam M. Phillippy. Canu: scalable and accurate long-read assembly via adaptive k-mer weighting and repeat separation. Genome Research, 27(5):722–736, 2017. DOI: 10.1101/gr.215087.116 82 ↩︎
Wenqin Huangfu, Xueqi Li, Shuangchen Li, Xing Hu, Peng Gu, and Yuan Xie. Medal: Scalable DIMM-based near data processing accelerator for DNA seeding algorithm. In Proc. of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, pages 587–599, 2019. DOI: 10.1145/3352460.3358329 83 ↩︎
Farzaneh Zokaee, Mingzhe Zhang, and Lei Jiang. Finder: Accelerating FM-index-based exact pattern matching in genomic sequences through ReRAM technology. In 28th International Conference on Parallel Architectures and Compilation Techniques (PACT), pages 284–295, IEEE, 2019. DOI: 10.1109/pact.2019.00030 83 ↩︎
Jeremie S. Kim, Damla Senol Cali, Hongyi Xin, Donghyuk Lee, Saugata Ghose, Mohammed Alser, Hasan Hassan, Oguz Ergin, Can Alkan, and Onur Mutlu. Grim-filter:Fast seed location filtering in DNA read mapping using processing-in-memory technologies. BMC Genomics, 19(2):23–40, 2018. DOI: 10.1186/s12864-018-4460-0 83 ↩︎ ↩︎
Anirban Nag, C. N. Ramachandra, Rajeev Balasubramonian, Ryan Stutsman, Edouard Giacomin, Hari Kambalasubramanyam, and Pierre-Emmanuel Gaillardon. Gencache: Leveraging in-cache operators for efficient sequence alignment. In Proc. of the 52nd Annual IEEE/ACM International Symposium onMicroarchitecture, pages 334–346, 2019. DOI:10.1145/3352460.3358308 83 ↩︎ ↩︎
Roman Kaplan, Leonid Yavits, and Ran Ginosar. RASSA: Resistive pre-alignment accelerator for approximate DNA long read mapping. IEEE Micro, 39(4):44–54, 2018. DOI:10.1109/mm.2018.2890253 83 ↩︎
Daichi Fujiki, Arun Subramaniyan, Tianjun Zhang, Yu Zeng, Reetuparna Das, David Blaauw, and Satish Narayanasamy. GenAx: A genome sequencing accelerator. In ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), pages 69–82, 2018. DOI: 10.1109/isca.2018.00017 83 ↩︎
Yatish Turakhia, Gill Bejerano, and William J. Dally. Darwin: A genomics co-processor provides up to 15,000 x acceleration on long read assembly. ACM SIGPLAN Notices, 53(2):199–213, 2018. DOI: 10.1145/3296957.3173193 83 ↩︎
Roman Kaplan, Leonid Yavits, Ran Ginosar, and Uri Weiser. A resistive CAM processing-in-storage architecture for DNA sequence alignment. IEEE Micro, 37(4):20–28, 2017. DOI: 10.1109/mm.2017.3211121 83 ↩︎
Roman Kaplan, Leonid Yavits, and Ran Ginosasr. BioSEAL: In-memory biological sequence alignment accelerator for large-scale genomic data. In Proc. of the 13th ACM International Systems and Storage Conference, pages 36–48, 2020. DOI: 10.1145/3383669.3398279 83 ↩︎
Saransh Gupta, Mohsen Imani, Behnam Khaleghi, Venkatesh Kumar, and Tajana Rosing. Rapid: A ReRAM processing in-memory architecture for DNA sequence alignment. In IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), pages 1–6, 2019. DOI: 10.1109/islped.2019.8824830 83 ↩︎
Wenqin Huangfu, Shuangchen Li, Xing Hu, and Yuan Xie. Radar: A 3D-ReRAM based DNA alignment accelerator architecture. In Proc. of the 55th Annual Design Automation Conference, pages 1–6, 2018. DOI: 10.1145/3195970.3196098 83 ↩︎
Nathaniel Mcvicar, Chih-Ching Lin, and Scott Hauck. K-Mer counting using bloom filters with an FPGA-attached HMC. In IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), pages 203–210, 2017. DOI: 10.1109/fccm.2017.23 84 ↩︎
Wenqin Huangfu, Krishna T. Malladi, Shuangchen Li, Peng Gu, and Yuan Xie. Nest: DIMM-based near-data-processing accelerator for k-mer counting. In IEEE/ACM International Conference on Computer Aided Design (ICCAD), pages 1–9, 2020. DOI: 10.1145/3400302.3415724 84 ↩︎
Shaahin Angizi, Jiao Sun, Wei Zhang, and Deliang Fan. PIM-Aligner: A processing in-MRAM platform for biological sequence alignment. In Design, Automation and Test in Europe Conference and Exhibition (DATE), pages 1265–1270, IEEE, 2020. DOI: 10.23919/date48585.2020.9116303 84 ↩︎
Shaahin Angizi, Jiao Sun, Wei Zhang, and Deliang Fan. Aligns: A processing in-memory accelerator for DNA short read alignment leveraging sot-MRAM. In 56th ACM/IEEE Design Automation Conference (DAC), pages 1–6, 2019. DOI:10.1145/3316781.3317764 84 ↩︎
Shaahin Angizi, Naima Ahmed Fahmi, Wei Zhang, and Deliang Fan. PIM-Assembler: A processing-in-memory platform for genome assembly. In 57th ACM/IEEE Design Automation Conference (DAC), pages 1–6, 2020. DOI: 10.1109/dac18072.2020.9218653 84 ↩︎
Qian Lou, Sarath Chandra Janga, and Lei Jiang. Helix: Algorithm/architecture codesign for accelerating nanopore genome base-calling. In Proc. of the ACM International Conference on Parallel Architectures and Compilation Techniques, PACT ’20, pages 293–304, Association for Computing Machinery, New York, 2020. https://doi.org/10.1145/3410463.3414626 DOI: 10.1145/3410463.3414626 84 ↩︎
Mark Oskin, Frederic T. Chong, and Timothy Sherwood. Active pages: A computation model for intelligent memory. In Proc. 25th Annual International Symposium on Computer Architecture (Cat. no. 98CB36235), pages 192–203, IEEE, 1998. DOI:10.1109/isca.1998.694774 85 ↩︎
Mary Hall, Apoorv Srivastava, William Athas, Vincent Freeh, Jaewook Shin, Joonseok Park, Peter Kogge, Jeff Koller, Pedro Diniz, Jacqueline Chame, Jeff Draper, Jeff LaCoss,John Granacki, and Jay Brockman. Mapping irregular applications to DIVA, a PIM based data-intensive architecture. In Proc. of the ACM/IEEE Conference on Supercomputing (CDROM)—Supercomputing’99, page 57–57, ACM Press, New York, 1999. http://portal.acm.org/citation.cfm?doid=331532.331589 DOI: 10.1145/331532.331589 85 ↩︎
Thorsten Von Eicken, David E. Culler, Seth Copen Goldstein, and Klaus Erik Schauser. Active messages: A mechanism for integrated communication and computation. ACM SIGARCH Computer Architecture News, 20(2):256–266, 1992. DOI:10.1145/146628.140382 85 ↩︎
Peter M. Kogge. Of piglets and threadlets: Architectures for self-contained, mobile, memory programming. In Innovative Architecture for Future Generation High Performance Processors and Systems (IWIA’04), pages 130–138, IEEE, 2004. DOI: 10.1109/iwia.2004.10005 85 ↩︎
Saugata Ghose, Amirali Boroumand, Jeremie S. Kim, Juan Gómez-Luna, and Onur Mutlu. Processing-in-memory: A workload-driven perspective. IBM Journal of Research and Development, 63(6):3:1–3:19, 2019. DOI: 10.1147/jrd.2019.2934048 86 ↩︎
Onur Mutlu, Saugata Ghose, Juan Gómez-Luna, and Rachata Ausavarungnirun. A modern primer on processing in memory. ArXiv Preprint ArXiv:2012.03112, 2020. 86 ↩︎
Saugata Ghose, Kevin Hsieh, Amirali Boroumand, Rachata Ausavarungnirun, and Onur Mutlu. Enabling the adoption of processing-in-memory: Challenges, mechanisms, future research directions. ArXiv Preprint ArXiv:1802.00320, 2018. 86 ↩︎
Saugata Ghose, Amirali Boroumand, Jeremie S. Kim, Juan Gómez-Luna, and Onur Mutlu. Processing-in-memory: A workload-driven perspective. IBM Journal of Research and Development, 63(6):3–1, 2019. DOI: 10.1147/jrd.2019.2934048 86 ↩︎
Ramyad Hadidi, Lifeng Nai, Hyojong Kim, and Hyesoon Kim. Cairo: A compiler assisted technique for enabling instruction-level offloading of processing-in-memory.ACM Transactions on Architecture and Code Optimization (TACO), 14(4):1–25, 2017. DOI: 10.1145/3155287 86 ↩︎
Amirali Boroumand, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul Thakur, Daehyun Kim, Aki Kuusela, Allan Knies, Parthasarathy Ranganathan, et al. Google workloads for consumer devices: Mitigating data movement bottlenecks. In Proc. of the 23rd International Conference on Architectural Support for Programming Languages and Operating Systems, pages 316–331, 2018. DOI: 10.1145/3173162.3173177 86 ↩︎
Ravi Nair, Samuel F. Antao, Carlo Bertolli, Pradip Bose, Jose R. Brunheroto, Tong Chen, C-Y Cher, Carlos H. A. Costa, Jun Doi, Constantinos Evangelinos, et al. Active memory cube: A processing-in-memory architecture for exascale systems. IBM Journal of Research and Development, 59(2/3):17–1, 2015. DOI: 10.1147/jrd.2015.2409732 87 ↩︎
Mohammad Alian, Seung Won Min, Hadi Asgharimoghaddam, Ashutosh Dhar, Dong Kai Wang, Thomas Roewer, Adam McPadden, Oliver O’Halloran, Deming Chen, Jinjun Xiong, et al. Application-transparent near-memory processing architecture with memory channel network. In 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 802–814, 2018. DOI: 10.1109/micro.2018.00070 87 ↩︎
Kevin Hsieh, Eiman Ebrahimi, Gwangsun Kim, Niladrish Chatterjee, Mike O’Connor, Nandita Vijaykumar, Onur Mutlu, and Stephen W. Keckler. Transparent offloading and mapping (TOM) enabling programmer-transparent near-data processing in GPU systems. ACM SIGARCH Computer Architecture News, 44(3):204–216, 2016. DOI: 10.1145/3007787.3001159 87 ↩︎
Ashutosh Pattnaik, Xulong Tang, Onur Kayiran, Adwait Jog, Asit Mishra, Mahmut T. Kandemir, Anand Sivasubramaniam, and Chita R. Das. Opportunistic computing in GPU architectures. In ACM/IEEE 46th Annual International Symposium on Computer Architecture (ISCA), pages 210–223, 2019. DOI: 10.1145/3307650.3322212 87 ↩︎
Daichi Fujiki, Scott Mahlke, and Reetuparna Das. In-memory data parallel processor. ACM SIGPLAN Notices, 53(2):1–14, 2018. DOI: 10.1145/3296957.3173171 89, 91 ↩︎
Martin Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat,Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Man, Rajat Monga, Sherry Moore, Derek Murray, Jon Shlens, Benoit Steiner, Ilya Sutskever, Paul Tucker, Vincent Van houcke, Vijay Vasudevan, Oriol Vinyals, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous distributed systems. ArXiv:1603.04467, page 19, 2015. http://download.tensorflow.org/paper/whitepaper2015.pdf 89 ↩︎
John R. Ellis. Bulldog: A Compiler for VLSI Architectures, MIT Press, Cambridge, MA, \1986. 93 ↩︎
Henry Cook, Krste Asanovic, and David A. Patterson. Virtual local stores: Enabling software-managed memory hierarchies in mainstream computing environments. Technical Report no. UCB/EECS-2009-131, 2009. 94 ↩︎
Rakesh Komuravelli, Matthew D. Sinclair, Johnathan Alsop, Muhammad Huzaifa, Maria Kotsifakou, Prakalp Srivastava, Sarita V. Adve, and Vikram S. Adve. Stash: Have your scratchpad and cache it too. ACM SIGARCH Computer Architecture News, 43(3S):707–719, 2015. DOI: 10.1145/2872887.2750374 94 ↩︎
Peter Pessl, Daniel Gruss, Clémentine Maurice, Michael Schwarz, and Stefan Mangard. Drama: Exploiting DRAM addressing for cross-CPU attacks. In 25th USENIX security symposium (USENIX security 16), pages 565–581, 2016. 94 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号