从ICAC 2024聊聊CIM trend
从ICAC 2024聊聊CIM trend
刚参加完今年在上海举办的ICAC2024,体验很好,从各位老师同学处学到很多。我是做CIM的,所以两个CIM Session一个不落,另外因为对Processor感兴趣,Effient Digital Circuit Session和Low Power SoC Session也去学习了一下。
因为大部分工作在ISSCC上已经了解过了,所以在这次ICAC上印象比较深的几个speech基本都是介绍trend的speech,或者在讲具体技术前铺垫了比较多general的内容的speech:比如东南的杨军老师,北大的贾天宇老师,港科的涂锋斌老师,北大的唐希源老师,清华贾弘洋老师等等。
这里简单聊聊自己的收获。
首先是关于CIM发展的问题,尽管CIM这个领域大家一直在claim自己如何如何消除访存瓶颈之类的,但是在High Performace Computing方面一直没怎么看到工业界的follow,领域老大Nvidia的GPU用的Tensor Core自成一派,AMD在和三星合作弄HBM中的PIM,和学术界热衷于做的SRAM CIM等也不沾边。时间久了自然难免人心浮动,是不是我们做的东西不够solid?好在我们今年看到了两个很好的工业上的application,这事从2021年TSMC开始做Digital SRAM CIM以来,经过三年的工艺scaling后,我们终于见到了在先进工艺上使用SRAM CIM技术的加速器工作。其中Axelera AI的技术用的是魔改后的TSMC 2021的Digital CIM方案,MediaTek用的是TSMC 2023的Digital CIM方案。我觉得我之前的大胆猜想基本没问题哈哈,TSMC已经在把他们的Digital CIM给IP化提供给上游客户了。所以从21年到24年,4年时间其实还是往前走了很多的。相信在后面几年会看到更多这种使用成熟Digital CIM Macro的工业界的work。

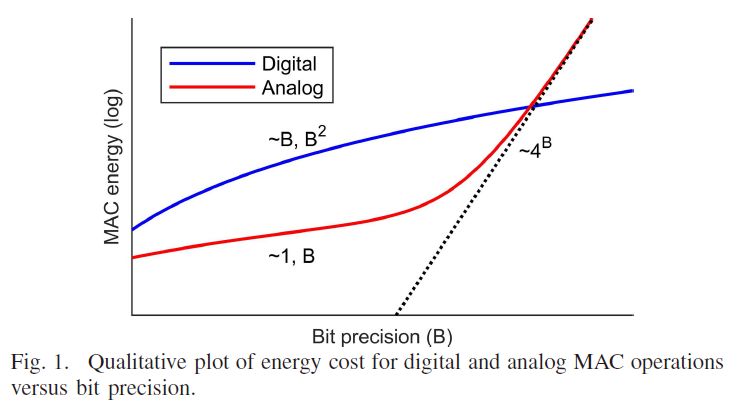
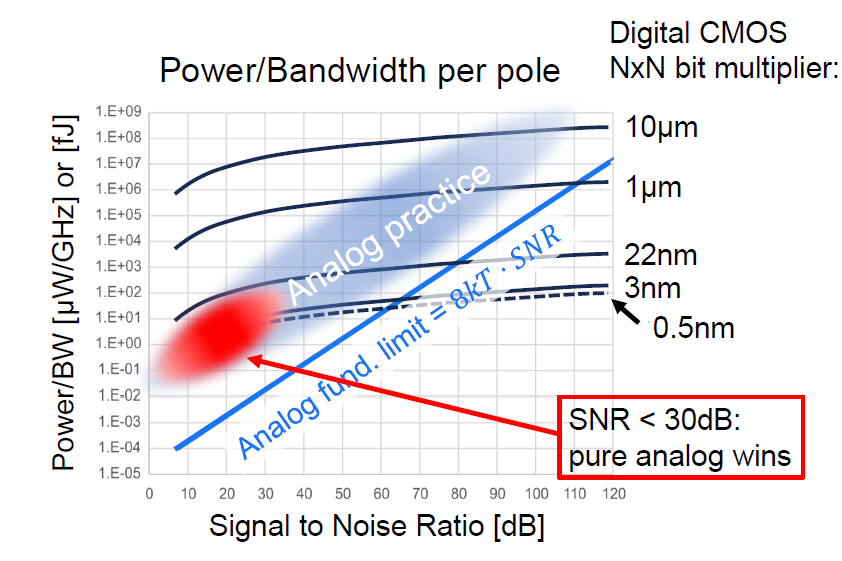
其次是我一直比较关心的Analog和Digital CIM模式之争,因为我自己去年那篇Hybrid Domain的思路也算是在这两种模式之间的思路碰撞中想出来的,现在也依然关注这方面各个学者的看法,这里总结一下我目前的观点,这里引用一下B.Murmann论文里的图以及ISSCC2024 Plenary上Bram Nauta Slide里的图。可以得出结论:在非先进工艺,较低比特位数,可以接受一定的SNR损失的情况下,Analog CIM是Prefer的。我觉得从Application的角度来说,边缘端应用上一些比较老的工艺节点上,比如55nm,180nm这种,做一些对Accuracy要求比较低的IoT方面的Application,其实相当合适,相当符合场景。但是我个人觉得往HPC的Application上去做的话,大势还是在Digital这边。至于Hybrid的方案可能在一些不上不下的节点比如22nm,28nm这种会比较Sweet。到了12nm以下先进工艺时Analog部分还是会被non-linearity之类的问题搞得很难受。
另外提一句关于北大唐希源老师对Analog CIM中Current CIM和Charge CIM两种方案的一个Comparison,个人深以为然。Charge CIM目前整体来看大家采用的多一些,Capacitor在trim之后确实mismatch问题可以解决的比较好,可以把SNR拉的更高,但是Capacitor占用的面积会拉低Density,最后导致Compute Density下降也是个实际存在的问题。Current CIM相较之下Density显然会更高,但是受到晶体管Non-linearity以及mismatch的影响也更大,SNR一般来说更差一些。所以他们提出的在eDRAM CIM里面改良Current CIM的SNR的手段我非常欣赏,感觉这些trick做些小改动也可以transfer到其他介质的CIM中去。
最后聊一聊好几个老师都讨论的关于CIM这个领域的一个Stack的问题,我结合几个老师的Summary,大致做了一个如下的梳理:
结合一下我学的计算机体系结构课,我把CIM的Stack分成六层,bottom to up的顺序为: Device->Circuit->Architecture->Tool-Chain->API->APP,下面将我对各层的理解娓娓道来~
Device Level: 具体的存算器件,譬如SRAM、RRAM、eDRAM、MRAM、STT-RAM.......从学术的角度来说,优化器件的各种性能,诸如提升Endurence,提升Density,降低Variation,降低Power等等,在IEDM上可以看到很多。从应用的角度来说,以我理解,做这层的关键点和痛点在于提供一套可靠的PDK,SRAM用CMOS逻辑搭就行了,暂且不论,我也做一些RRAM相关的work,所以有些体会,如果RRAM之类的Device可以和Resistor或者Cap一样可以直接调用到电路里面去画图,前仿,后仿这些真的会方便很多。实验室里我们可以自己结合TCAD仿真和仪器测得的IV特性曲线去写VerilogA模型然后打成Cell后在Virtuoso里面去调用,也能做到上面说的这些,但是因为实力有限模型精度只能说一般般。最好还是有Foundry直接在PDK里面提供支持的方案,相信可靠性会更好一些。
Circuit Level: OK,假定我们现在有了一套可靠的存算器件PDK了,不管是自己捏的,还是Foundry给的,下一步就是选择使用哪种电路方案?这也是现在ISSCC CIM Session大家主要在卷的点。Digital CIM还是Analog CIM,亦或者Hybrid CIM?Analog CIM用哪种方案? 是Current Domain CIM还是Charge Domain CIM抑或是Time Domain CIM?针对各种CIM方案的优化,仍然是目前学术研究的热点。但是从应用的角度来说,我认为Circuit Level最需要的东西是给有定制化需求的客户提供一套类似Memory Compiler的工具,这里我们姑且称其为CIM Compiler吧!CIM Compiler应该能做到在用户给定定制化参数(例如深度,宽度,MAC数量,位数等)后,按照某种特定架构生成用户需要的CIM Macro。我觉得现在TSMC的Digital SRAM CIM已经很接近这一步了。
Architecture: 好的,解决了定制化需求,对于非定制化需求客户,他们可能压根不care用哪种具体架构的CIM,但是需要得是一个好用的IP,所以在Architecture我们需要解决的问题是CIM Macro以什么样的形式融入我们的Accelerator或者SoC?目前很多学者在做这方面的架构探索工作,举几个我见过的典型思路,比如以on-bus IP的形式,将CIM Macro作为一个Slave挂到总线上,让Processor去控制它的行为。也可以将其做层封装变成Co-Processor。还可以单纯把它当成PE来用。总之从应用的角度来说,我们需要一个可靠完善的Standard Packaged IP,有常见的接口,有完善的Spec.......有一切商用IP该有的东西。这次ICAC上听到的另一个有趣的事情是目前北大贾天宇老师那边在和工业界合作探索用于CIM的RISC-V extension,我觉得这非常好,因为现在RISC-V之于IC学术界就如Pytorch之于AI学术界,有一个靠谱的CIM用的RISC-V extension会省下大家很多事,on-bus IP相对好操作很多,可以不需要专门设计指令,但是对于后面两种和CPU couple比较紧的模式来说还是很急切的需要的。IP化和CIM RISC-V extension,我认为这是Architecutre这块目前很需要的东西。
Tool-Chain: OK,讨论完了Architecture,我们正式离开硬件步入软件的领域,实际上在CIM这块做得越久我越觉得软件有时候是比硬件更重要和麻烦的问题。我们现在讨论最底层的软件——工具链。目前也有学者在研究CIM架构的simulator和compiler,但是受限于硬件各有各的花活,至今我没有看到一个特别universe的方案来出来。从应用的角度来说,simulator我认为非常重要,清华贾弘洋老师讨论了目前CIM的benchmarking的一些问题,让我再次感到simulator的重要性。我自我反思之前的工作其实主打一个“俺寻思“,并没有在真正把这个CIM macro做出来之前进行充分的设计空间探索,在不同的benchmark上面做evaluation,所以其实科学性是不足的。所以我现在也在这块在做一些工作,试图解决一下目前硬件碎片化的情况下simulator不好弄的这么一个痛点问题。接下来说说compiler的事情,除了基本的汇编生成,CIM用的compiler可能还得包含Synthesis and Mapping的功能,我们都知道在传统的编译器中,我们有个堆栈的管理问题,考虑到CIM后这个问题会更加复杂,在下载程序时摆多少权重到CIM Macro上面,怎么摆这些权重来确保最大的untilization以及性能,我认为甚至需要专门设计一套算法嵌入到compiler中,这也是一个很有意思的方向。
API: 好了,现在Tool-Chain也有了,我们终于开始正式编写软件了。我们需要很多提供给开发者的Programming library ,可以参考Nvidia的CUDA,CUDAnn这些生态,我们需要给使用CIM的硬件设计一套C/C++驱动库,NN算子库,比如就叫CIMDA,CIMnn之类的,然后再往上往成熟的Python AI编程框架,如Pytorch和Tensorflow去连接。当然到了这一步其实有点软件定义硬件的味道了,至少是一个软硬件协同设计的问题。在flow上我们需要在想好编程模型之后再设计我们的硬件架构,这样才能顺利做到这里。别问我为什么这样理解这个问题,我踩过大坑........
APP: 好了,做到这里我们终于可以自豪的宣布,我们现在有一套完整的CIM的Stack了!现在我们可以利用成熟的各种开发库来开发我们自己的Application了,比如Diffusion model/Transformer/CNN/RNN......做Large Language model/Target Detection/Image Generation/......各种你叫的上名字的模型做各种你能想到的应用!听上去很振奋!当然我觉得真正的目标可能是MLPerf之类的跑分测试,我们通过一些Genrative的Benchmark来证明CIM的优势,在跑分上真正打败现在的其他方案,各种GPU,DPU,NPU之类的,那才叫劲儿!希望可以早日看到我们这个领域有研究者或者是公司去做这样的事哈哈。
最后聊聊从CIM Stack的角度来考虑,我自己手上工作的一个Roadmap规划。
受限于人手和money,我打算先从Edge Device做起,即Device Level: SRAM->Circuit Level: Digital CIM->Architecture Level: on-bus IP(使用AMBA总线)->Tool-Chain: cimulator(自研仿真器),riscv-gnu-gcc->API: CIMDA,CIMnn(自研驱动层+算子库)->APP: MLPerf-Tiny。
现在差不多搞定的部分:device, circuit, architecture;cimulator还在开发,CIMDA和CIMnn还没写,MLPerf-Tiny还没部署,来日方长,还得奋斗。工作顺利的话可以多share一些进展给大家。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号