CIM技术经典导读之数字SRAM CIM技术
CIM技术经典导读之数字SRAM CIM技术
序言
啊哈,挖个新坑,计划把我这边自己感觉比较classic的一些CIM工作给整理出来,和读者们一起分享讨论,论文的主要来源会挑选ISSCC,VLSI上的文章,如何评价是否classic这个主要是根据我自己的感觉来,可能也会参照一下highlight paper或者引用量这些指标,如果读者们觉得有classic的,希望我加上的,也欢迎在评论里指教。
那么这次的数字SRAM CIM技术,我挑选的是TSMC在ISSCC上21年到24年连续发表的三篇论文以及22年VLSI上的论文。
作为全球Foundry的No.1,TSMC的这几个工作代表了工业界对CIM Macro技术的先进探索,TSMC在22年和23年ISSCC发表的CIM Macro使用了最先进的工艺节点(5nm,4nm)。我在这里斗胆预测TSMC内部也在计划将先进的SRAM CIM Macro给IP化,产品化,并在未来提供给设计厂商。
那么闲话少叙,我们开始品鉴一下TSMC的这几篇文章。
An 89TOPS/W and 16.3TOPS/mm2 All-Digital SRAM-Based Full-Precision Compute-In Memory Macro in 22nm for Machine-Learning Edge Applications
首先是这篇2021的文章,我称之为ISSCC上的数字SRAM CIM的开山之作。尽管在工艺上使用的是并不先进的22nm,但这篇工作毫无疑问在数字SRAM CIM技术领域具有奠基性,启发了大量后续的数字SRAM CIM工作。
开篇就叙述了Digital CIM的动机,第一点是不像Analog CIM那样存在accuracy loss,此外更适合高工艺节点的scaling。合情合理。
如下图所示,整个CIM Macro的结构实际上非常简单,6T SRAM四个一组形成对4bit weight的存储,每个SRAM Cell旁边紧密耦合一个4T或非门的1b*4b乘法器。activation从IN<255:0>上以bit serial的方式送入,每四个SRAM Cell+或非门完成1b*4b的计算,得到一个4b的部分积。然后这256个部分积被送入到一个多级的Adder Tree中进行累加。形成256*1b*4b的部分积,并送入累加器中。然后下一个cycle再送入下一位的activation,再次得到新的256*1b*4b的部分积,然后送入累加器,直到activation全部送完。整个Macro的规模是256*4*64=64Kb。
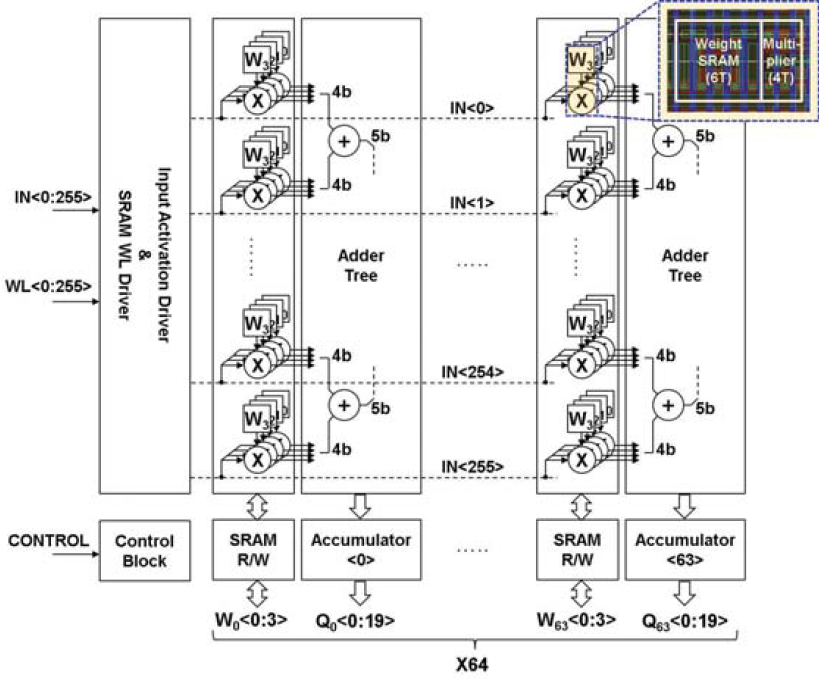
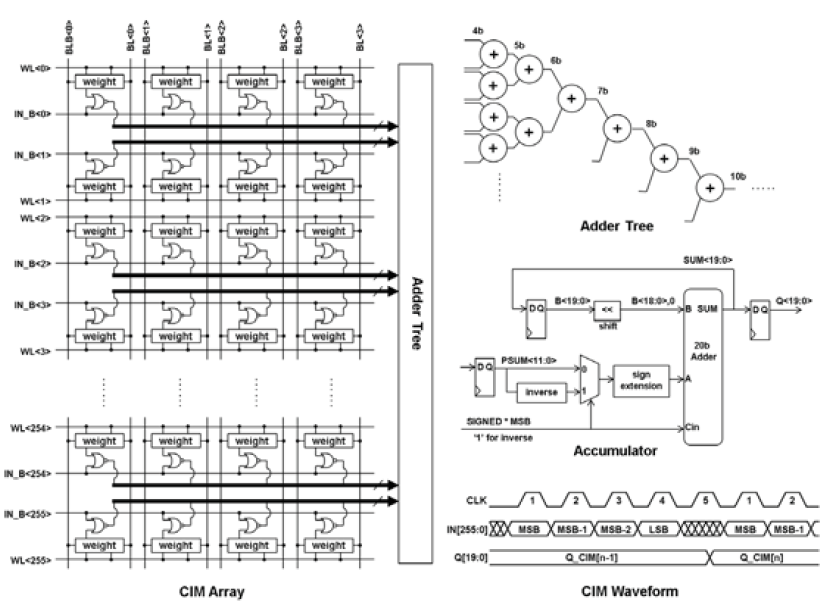
具体结构上,可以看到SRAM Array仍然保留正常的WL,BLB和BL,主要的修改是增加了IN_B,意思是对activation的正常比特位做取反。这是因为比特乘法使用的是或非门,而不是与门。利用德摩根律,我们知道\(\overline{A\cdot B}=\overline{A}+\overline{B}\),因此\(A\cdot B=\overline{\overline{A}+\overline{B}}\),所以只要对activation和weight均作取反(对weight的取反非常简单,因为SRAM存储时本来就会留一个原值和一个取反值,只要把取反值拿出来用就行了),然后送入或非门就可以等效成与门,这样做的好处是MOS管与门实现一般需要6T,而或非门只需要4T,一下子省掉1/3的管子。Adder Tree的结构就是一个基本加法树,可以算出需要log2(256)=8级的加法器。这个是一个比较大的问题,这么大的一个多级加法树显然会比连接它的256*4个SRAM bit cell大很多,在电路布局时怎么解决这个问题?这篇文章没有给出答案,不过耐心点往下看,后面的文章里会解答这个疑惑。累加器就是一个正常的移位累加结构,主要是注意一下对符号位的处理机制,显然这里是补码机制,如果符号位是0就直接原码做符号位拓展后加进去,如果符号位是1就按照补码规则,取反加一原码转成补码之后再加进去。看波形可知道对于4bit的activation需要4个cycle算一个结果,第5个cycle开始结果有效。另外一个需要注意的问题是,对于水平方向上的出线,每4b cell就需要出4根线,一共256行4b cell就需要256*4根线,如果进一步拓展到n列的话,那么线数继续比例增大,变成256*4*n根线,至少4*n要挤在两行cell之间的狭小空间里,可想而知很容易会造成走线的阻塞问题,这也是为什么这个设计里一列4b cell配一套加法器树,而不是多列cell去配一个。
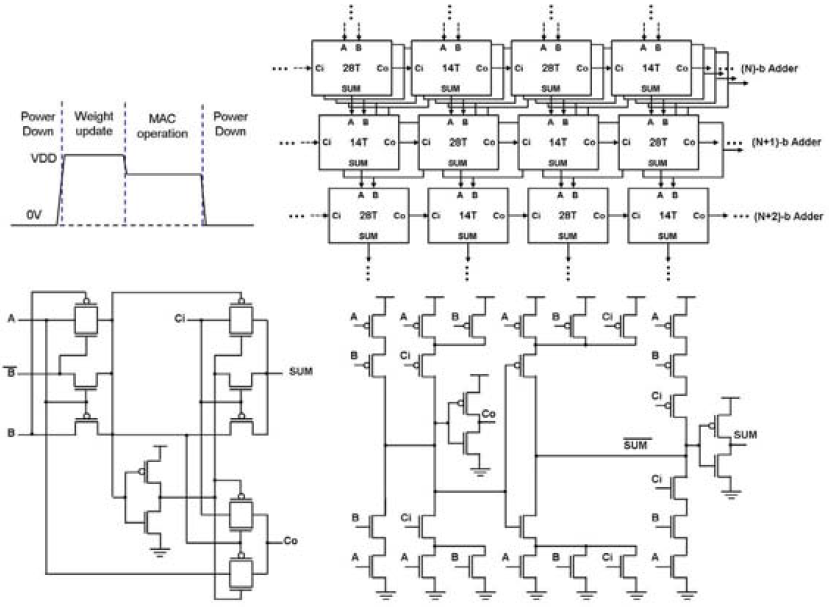
为了减少功耗使用了DVS技术,再Weight update时使用VDD电压,MAC时使用低于VDD的电压。在Adder Tree中使用了两种不同的Full Adder[1],14T和28T,来实现节省能耗。基于静态逻辑门的28T加法器具有传统的上拉下拉CMOS结构,能够提供全摆幅输出和良好的驱动能力,14T加法器则具有更少的晶体管数量,更小的面积,更低的功耗和延迟。在TSMC这篇的Adder Tree中选择了将两类加法器交替使用。
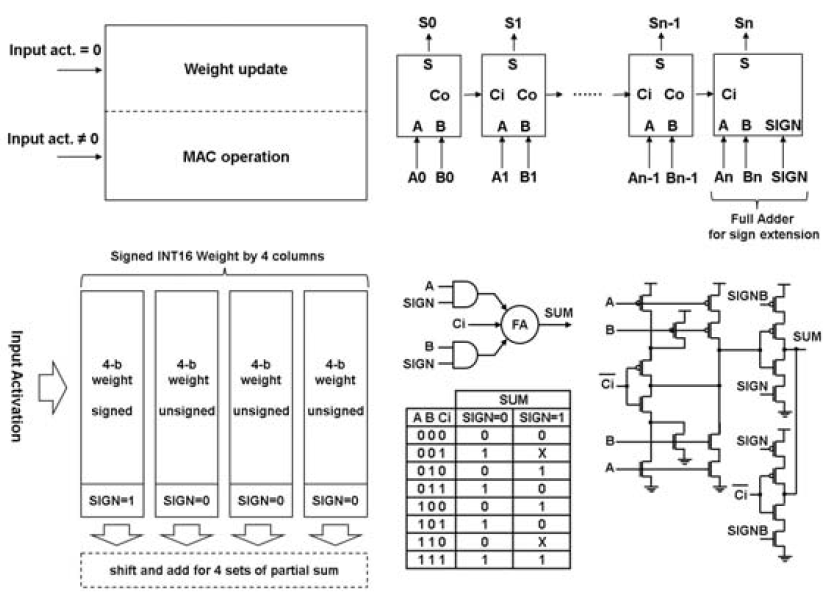
理论上来说,对于这个设计,activation=0的cell都是可以进行weight update的,而activation不等于0的cell进行MAC操作。当然我个人对这个点有些怀疑,因为bit serial输入时,总会出现IN_B线上电压为0的情况,这时做写入的话是否会对正在做MAC操作的cell造成误写入呢?我觉得完全是有这种可能的。这个数字SRAM CIM结构是可以实现比特拓展的,activation的拓展不必多少,bit serial想灌几位灌几位,只要累加器对应的增加周期就行。对于weight来说,可以通过将多个4b weight组合成8b/12b/16b等多位结构。只需要在外部计算时进行移位累加即可。这是很好理解的,以8b*8b为例:
这里\(A[7:0]*W[7:4]\)和\(A[7:0]*W[3:0]\)分别是第一列4b cell和第二列4b cell产生的部分积。
为了处理有符号数累加的问题,他们使用了一个带有符号位拓展的全加器。
这里展示了电路的基本结构,主要就是PLL,时钟产生和控制电路,CIM IN SRAM和CIM OUT SRAM,shmo plot,不同电压下的TOPS vs TOPS/W曲线以及不同toggle rate下的TOPS/W vs VDD曲线。没有太多好说的,符合一般常识,电压降低主频降低TOPS会下降,但是TOPS/W反而会提升,因为功耗的降低速度是快于频率的降低速度的(频率跟电压呈线性关系,功耗跟电压呈三次方关系)。另外toggle rate越低,动态翻转越少,功耗越小,TOPS/W自然越高。从shmoo plot上来看TOPS(同时也是frequency)和VDD呈现的也是线性关系,电压从0.52拉到0.92,TOPS能够涨10x。
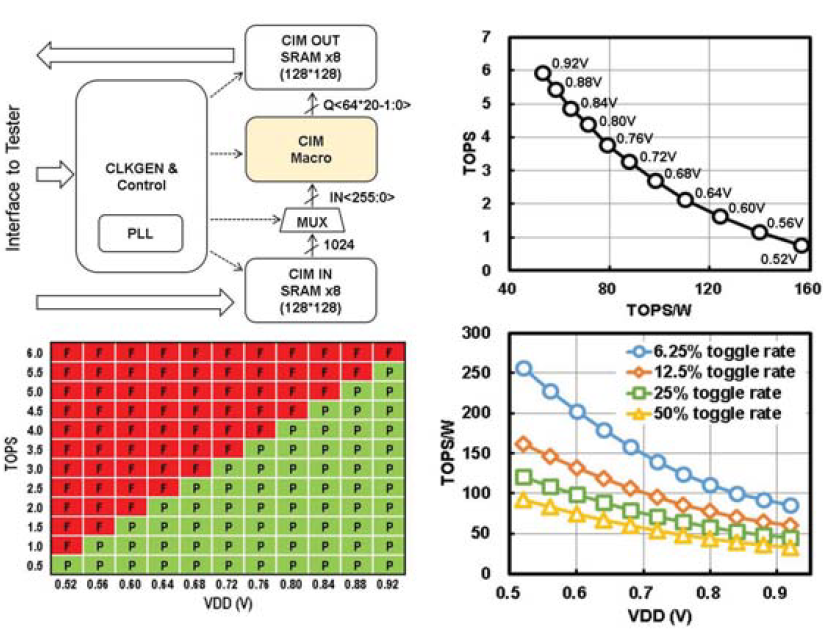
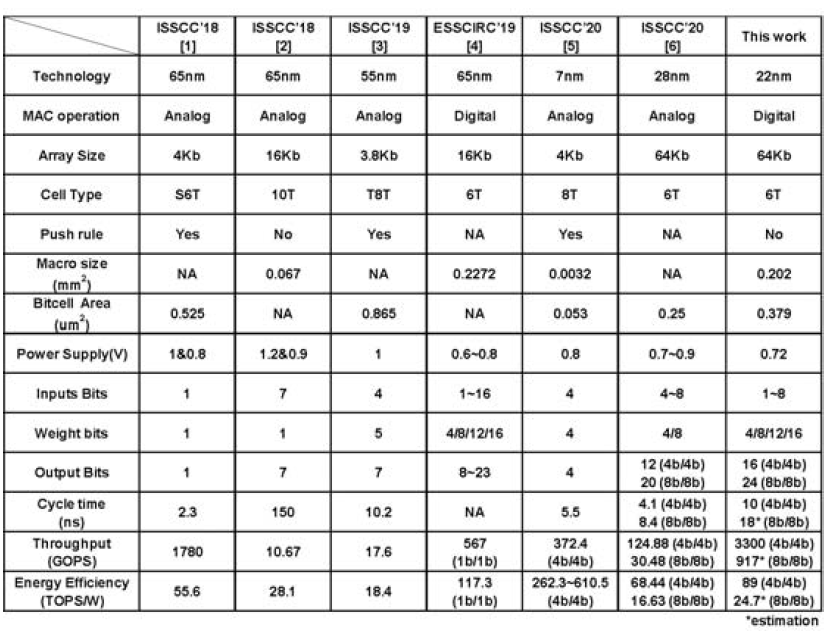
最后是比较结果,从结果上来看从Throughput,Energy efficiency几个重要指标上来说基本上拉爆了之前的analog CIM工作。这里在比较时没有根据工艺把指标scaling一下是个小缺点,不过不是太大的问题。
A 5-nm 254-TOPS/W 221-TOPS/mm2 Fully-Digital Computing-in-Memory Macro Supporting Wide-Range Dynamic-Voltage-Frequency Scaling and Simultaneous MAC and Write Operations
然后来到这篇2022年的文章,这次直接放大招,5nm工艺甩在脸上,我是ISSCC组委会我也抵抗不了。
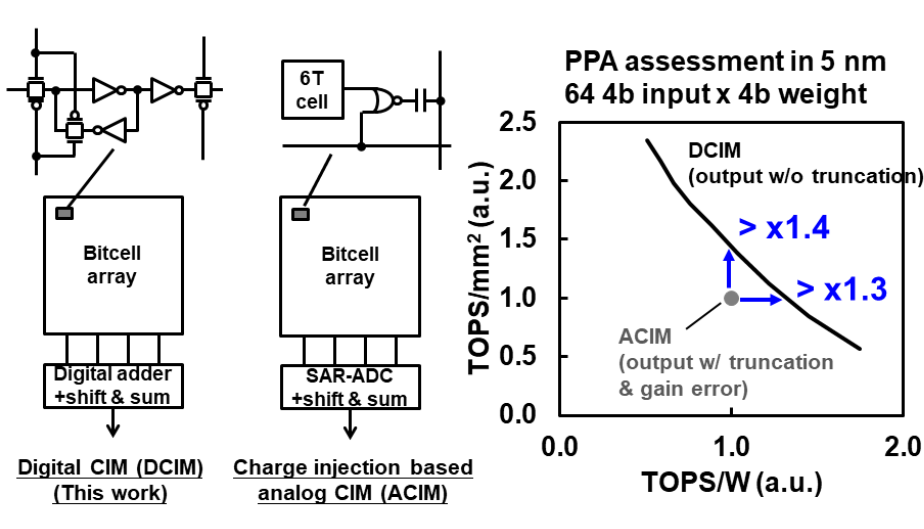
工作动机还是阐述了一下和Analog CIM的对比,这里比的是电荷式的Analog CIM,Analog CIM在先进工艺下ADC的动态范围很成问题,首先供电电压缩小,其次MOS的\(I_{DS}\)具有更强的非线性,最后电容也变小了,在5nm下benchmark了64 4b input*4b weight的PPA。比较结果上来看,数字CIM有1.4x的TOPS/mm2算力密度提升和1.3x的TOPS/W能效提升。Digital CIM对比Analog CIM没有accuracy loss这个是老生常谈了,最后Digital CIM还可以搞DFT。
这里用的Digital CIM的bit cell和21年的很不一样,之前是一个6T SRAM cell加一个4T或非门,这次是12T bit cell,对于这个bit cell,这就是一个普通SRAM,并不包含乘法器的功能,乘法器实际上在阵列外头(所以严格来说这应该算是近存计算了)。
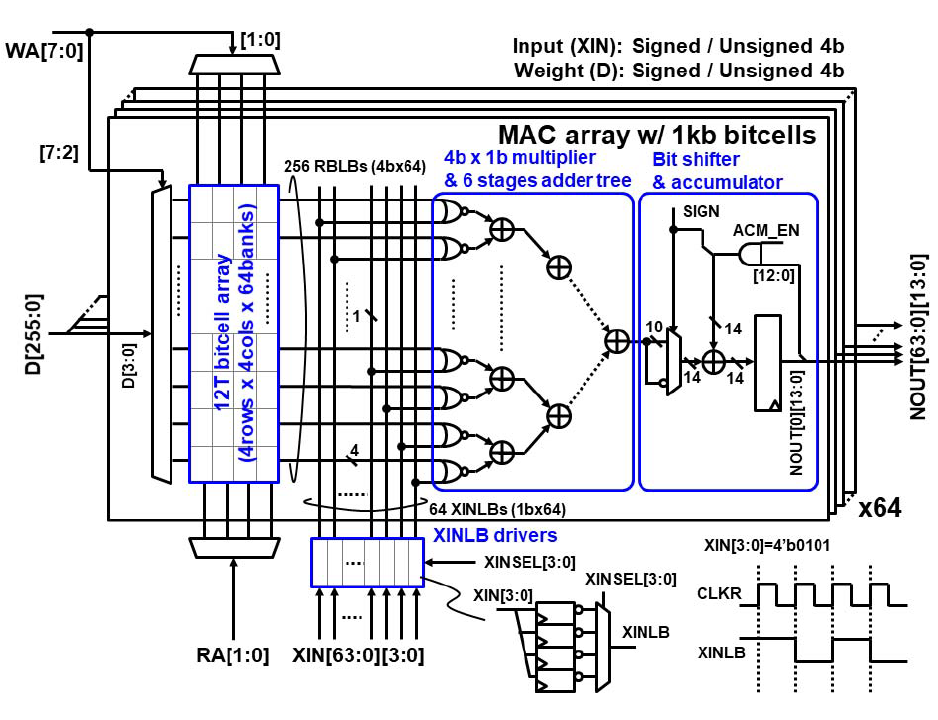
下图是整个Digital SRAM CIM的具体架构,就像之前所说,乘法器和加法树被移动到了阵列之外,这是最主要的架构改动。其他的与21年的设计没有什么很显著的区别,仍然是以4b cell为一个单位,输入XIN也分到了阵列外,通过并转串后送入到64根XINLB上,连接到或非门的乘法器上,而不再和21年的一样从阵列中的IN_B线输入。仍然做1b*4b的计算,从XIN来的线的位宽只有1,从SRAM来的线位宽是4。一共有256条RBLBs出线,除以4之后就是64个或非门乘法器,产生64个1b*4b的部分积,再通过log2(64)=6级的加法树将这些部分积全部累加,最后通过移位累加器将bit serial产生的多个部分积累加在一起。这套流程和21年的工作是完全一样的。唯一的区别可能只有多了个ACM_EN的累加器使能信号。从规模上来说,刚才我们讲的这个64*4b*1b的MAC array一共有64个,每个MAC Array里面有4*4*64个SRAM Cell,即1Kb的小sub-array,总的容量就是64*1Kb=64Kb,和21年的工作相同。
接着看看电路细节,首先是加法器上使用了Reversed-polarity full-adder,这次Full Adder又不一样了,按照这里的说法,这种Full Adder对比standard-cell里的可以节省12.5%的面积和15%的MAC功耗,每个Full Adder用了24根管子,并且仍然是完全上拉/下拉的,只是在真值上输入/输出的极性是反转的,即输入输入不取反,那么输出(S,CO)就是正常FA的取反,如果要想要和FA一样的输出,那么输入(A,B,CI)就得取反。对于这个12T bit cell,可以看到有WBLB,WWL,WWLB,RWL,RWLB和RBLB一共六根控制线,当WWL为低,WWLB为高时,数据锁存在SRAM内部,RWL和RWLB一个为高一个为低时,数据被读出到RBLB上。而进行写入操作时,WWL为高,WWLB为低,写入的传输门打开,WBLB的数据被写入到SRAM中,随后WWL拉低,WWLB拉高,数据锁存在SRAM内。12T SRAM cell的RWL,RWLB是每两个bank之间share的,而WWL和WWLB是分离的,这样的排布可以起到减少走线阻塞的作用,这里我的理解是在21年的工作里WL和IN_B是平行的,导致这个方向上的线过多会引发阻塞,而这次的工作里WL和RBLB之间相互垂直,所以不存在这方面的问题,同时RWL/RBLB在两个bank之间共享,也可以减少一部分这个方向上的走向,避免阻塞。最后是整个结构的floorplan,大部分的工作对这个问题其实不怎么重视,但我觉得这里的问题实际上还是挺值的关注的,也是我觉得整个工作最有意思的部分,可以看到第一级和第二级adder和四个SRAM bank以及乘法器耦合在一起,形成bank+adder的块,每两个这样的块再去share一个第三级的adder,每四个share了第三级adder的块再一起去share第四级adder,然后每8个一起share了第四级adder的块再一起去share第五级adder,最后两个share了五级adder的一共16个块再一起去share第六级加法器与移位累加器还有写入电路结构。这样算下来16个块,每个块里4个bank,所以总共是64个bank。这样的floorplan使得整体结构上不存在一大块独立的巨型多级加法树,使得布局变得更加的规整。
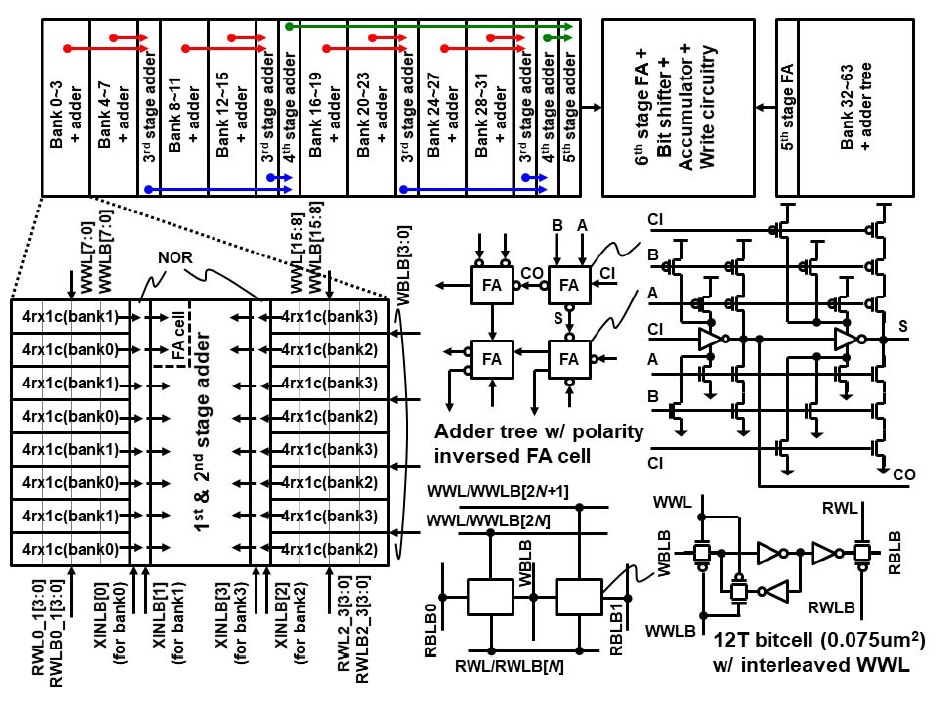
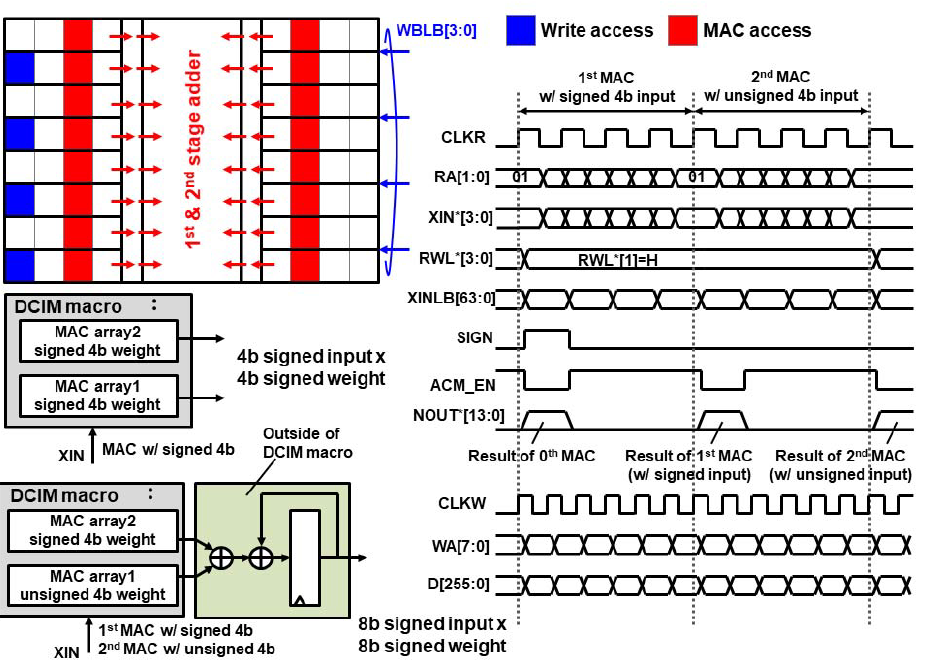
从时序上来看,读和写采用分离的时钟,和21年一样,是4个CLKR cycle完成4b*4b的计算。在写入时使用独立的CLKW时钟,并且可以比CLKR更快。由于12T SRAM cell结构的使用,这次的结构可以实现互不干扰的写入和读出。因为RWL/RWLB只对要读出的cell打开,WWL/WWLB只对要写入的cell打开,同时写入的cell的RWL/RWLB是关闭的,所以写入的内容也不会干扰到读出的cell上。最后是8b计算的结果如何组合出来,和21年的工作一样,只需要对两个4b MAC阵列的部分积再做移位累加即可。
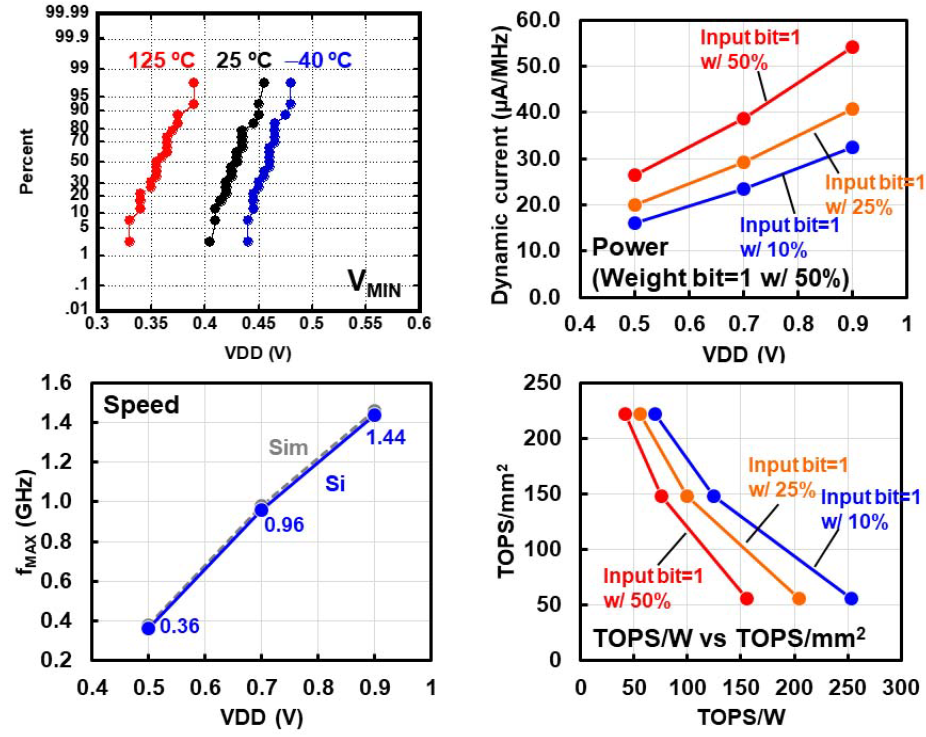
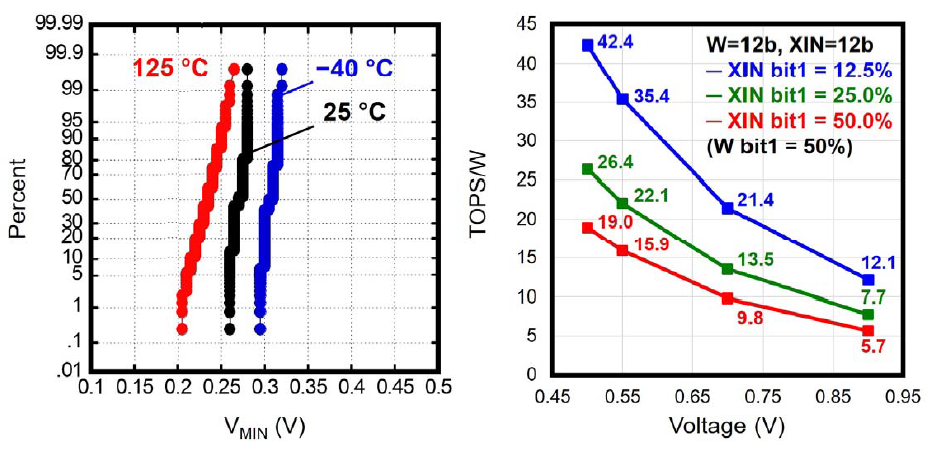
在数据测试结果上,最小操作电压\(V_{MIN}\)和阈值电压相关,由于阈值电压随着温度升高而减小,因此高温度下阈值操作电压会更小,在-40℃时,低于0.5V的电压就可以实现95%的操作成功率,属于是秀了一波工艺的肌肉。动态电流(\(\mu A/MHz\))和电压VDD成正比例关系,在权重稀疏度固定为50%的情况下,输入激活值的比特稀疏度越高那么动态电流就越小。频率\(f_{MAX}\)和电压VDD呈正比例关系。
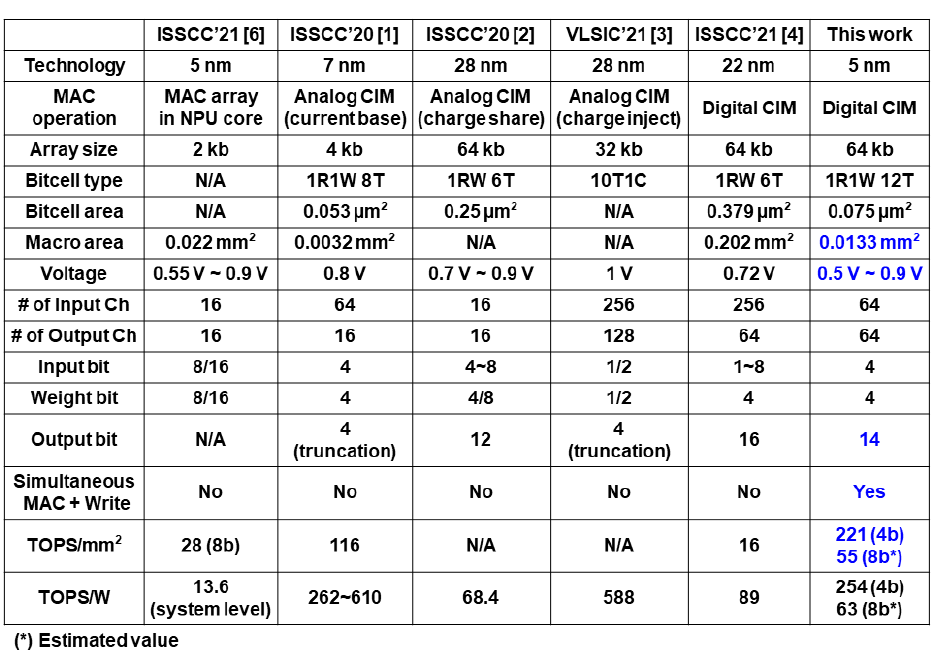
最后是和其他工作的对比,这次是比较了TOPS/mm2和TOPS/W的算力密度指标和能效指标,这次还是没做工艺和比特位数的归一化比较,哈哈。有趣的是和一个同样是5nm的NPU中的MAC阵列做了对比,在两个指标上都体现出了优势(虽然能效上NPU写的是系统级能效,使得这个指标的对比有点unfair哈哈),这也是证明了Digital SRAM CIM是可以在先进工艺芯片里作为一个高效的MAC计算电路使用的。
A 4nm 6163-TOPS/W/b 4790-TOPS/mm2/b SRAM Based Digital-Computing-in-Memory Macro Supporting Bit-Width Flexibility and Simultaneous MAC and Weight Update
23年这篇工作,工艺升级,来到4nm。秀肌肉行为,但是无法拒绝。
一眼可以看出是对22年工作的改进,对比了22年的12T SRAM cell+或非门乘法器的方案,换成了更紧凑的8T SRAM cell+OAI的方案。总管子数量从28T减少到了24T,同时垂直方向上的信号数量从9根减少到了6根,这显然会带来面积和走线上的提升。比特位数上仍然是以4b为单位,可以组织成8b/12b/16b等更高的位数。配合硬件上的量化和反量化,在ImageNet数据集上,MobileNet_v2和ResNet-50上INT16可以展现出非常接近FP16的精度,而INT8的精度掉点在1%-2%,但是能效可以做到INT16的四倍,INT12则是一个相对折中的方案,这算是解释了为什么这篇工作只做了8b和12b权重。
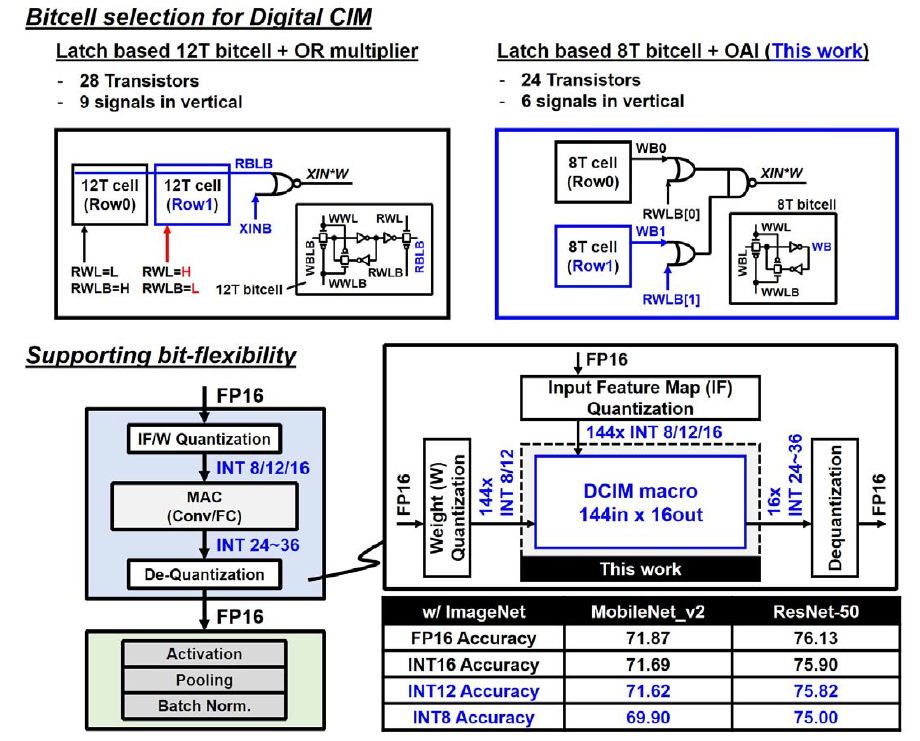
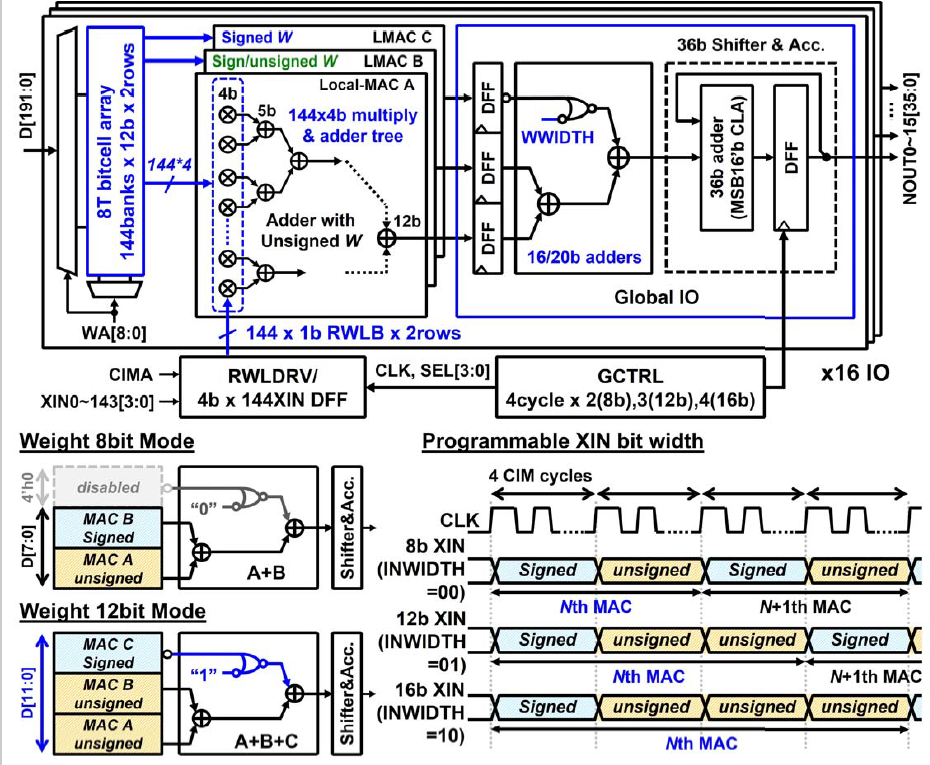
在整体结构上可以看出与22年工作的相似性。仍然是一个SRAM sub-array去连接外部乘加器的近存结构。SRAM sub-array一共有144个bank,12b cell,即三组4b cell,两行,总共有16个sub-array,这样可以计算出规模是16*144*12*2=54Kb。在一个sub-array及其乘加电路中,由于Local-MAC一共做了三个,所以出线时是144*12,分到每个Local-MAC上的是144*4。乘法器仍然是1b*4b结构,144*1*2根RWLB上将144个4b的XIN并转串后输入上来。Local-MAC有144个1b*4b乘法器,后面跟着加法树,一共ceil(log2(144))=8级。最后的Global IO包含了一套加法树,处理三个Local MAC的求和以及移位累加。对于8b权重的情况,使用两个Local-MAC进行组合,第三个Local-MAC被disable掉以节省功耗(通过一个或非门实现),12b权重的情况使用三个Local-MAC组合。所以权重实际上只有8b和12b两种位宽模式。有符号8b时第二个Local-MAC的4b weight是Signed,有符号12b时第二个Local-MAC的4b weight是unsigned,第三个Local-MAC的4b weight是signed。对于XIN来说,有8b/12b/16b三种可选的位宽模式,和之前的两个工作一样,4个cycle算完4b的MAC,之后的8b/12b/16b就对应的8 cycle/12 cycle/16 cycle。
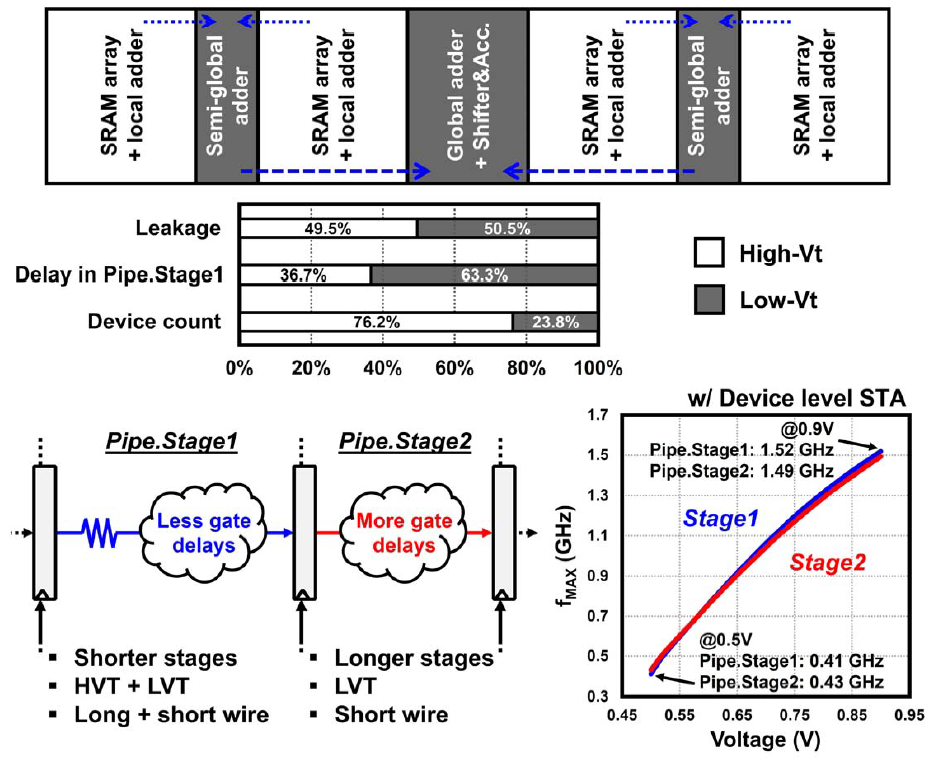
在floorplan上仍然延续22年的思路,SRAM array和Local adder耦合在一起形成一个块,两个块share一个semi-global-adder,四个块再去share Global adder和移位累加器。这里讨论了mix-Vt设计的问题,即混用高Vt管子和低Vt管子,高Vt管子漏电小但是速度慢,低Vt管子漏电大但是速度快,混用两种管子来平衡速度和漏电,这是后端常识。采用mix-Vt方案可以做到比纯低Vt管子可以减少38.6%的漏电。最后分配上,在Stage1中高Vt和低Vt产生的漏电是49.5%与50.5%,基本对半分;造成的延迟是36.7%与63.3%,说明在延迟链上更多的使用了低Vt管子来提高速度,在总的器件数量上来说高Vt管子对比低Vt管子是76.2%比23.8%。电路采用了pipeline结构来提高吞吐率,为了使得pipeline之间的延迟近似相等,Stage1采用了mix-Vt方案和使用长线(线延迟更大)的情况下减少了延迟链上的门数量,从而获得更小的门延迟,而Stage2选择全用低Vt管子,更短的线,但有更多的门来增大门延迟。最后的静态时序分析STA曲线上可以看到两个Stage的延迟在不同电压域下保持基本相同,最高在0.9V下可以飙到1.5GHz频率。
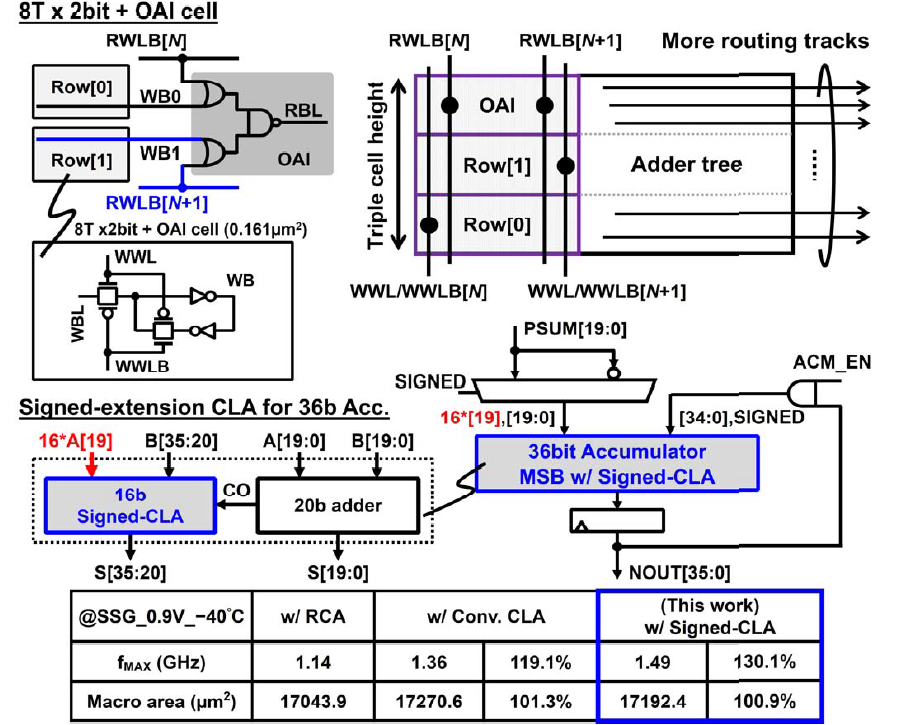
接下来看一下电路的细节部分,首先是8b bit cell,相比之前的12b bit cell少掉了读出的非门和传输门构成的4根管子,只保留了写入时用的8根管子,控制线也一下子减少了3根,只剩下WBL,WWL和WWLB,而存储反相数据的WB则直接接触连到了OAI上。RWLB是input的输入线,两row的两个cell每个配一根,在进行计算时一次只会用一个cell的数据,另一个的RWLB始终拉高,从而使得或门的输出始终为1,这时与非门由于一个输入被固定为1,其功能就相当于是一个非门,再和前面的或门组合一下,这实际上就仍然是一个或非门,还是最后还是回到了21年和22年的或非门乘法器的思路。为了减少水平方向上的走线负担,这里用了一个叫做Triple cell height的技术,即把ROW[0],ROW[1]的Bit cell和OAI垂直的垒起来,这样水平上有了更多的走线空间,从而就减小了阻塞的问题。对于36b的有符号累加器,采用了20b无符号adder和16b有符号超前进位加法器的组合,来减少这个大加法器上的时延。在以行波进位加法器为基准的情况下,对比传统超前进位加法器,这里优化后的超前进位加法器可以达到更快的速度和更小的面积,并在面积接近行波进位加法器的情况下做到了30.1%的速度提升。可惜这篇文章里没有解释具体对CLA怎么优化的,只能大概知道应该利用了符号位拓展时,16位A[19]都是相等的这么一个特性。
数据上可以看到由于工艺的升级,对比22年的工作,最小操作电压在同等温度下可以达到更低的水平,在-40℃时仍然可以降低到接近0.3V。TOPS/W vs Voltage没啥好说的,电压越高TOPS/W越低,固定了weight sparsity为50%,输入Sparsity越高TOPS/W就越高。
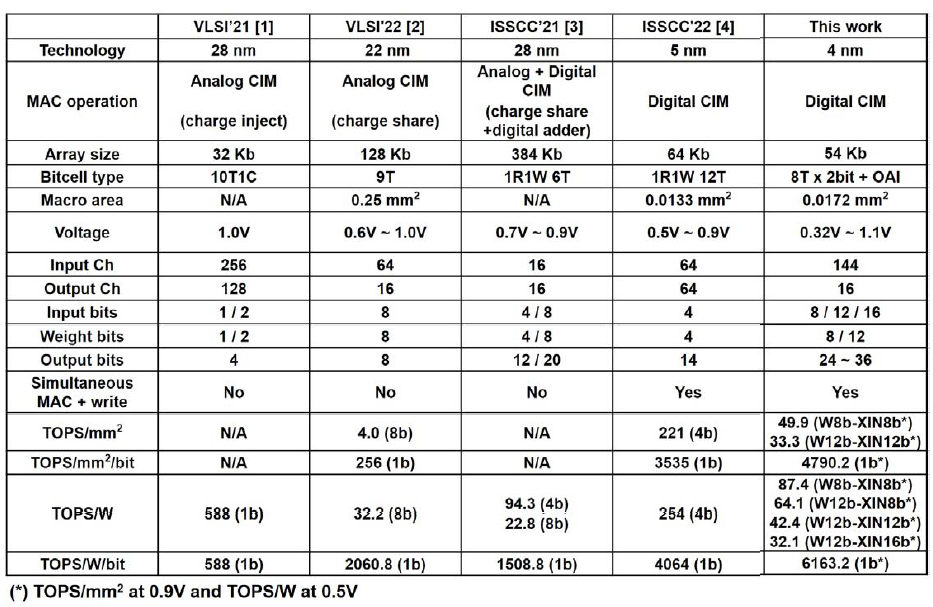
对比就不多说了,不过这次居然终于舍得将结果在比特位数上做归一化来对比了,除了标准的TOPS/mm2和TOPS/W指标,还增加了TOPS/mm2/bit和TOPS/W/b指标,虽然工艺还是没做归一化,总之结果显著拉爆之前的工作。
A 12nm 121-TOPS/W 41.6-TOPS/mm2 All Digital Full Precision SRAM-based Compute-in-Memory with Configurable Bit-width For AI Edge Applications
ISSCC 21到23的几篇文章都介绍完了,这里讲一下VLSI 2022这篇文章。
这篇文章使用的12nm的工艺,相比ISSCC 2021的文章在工艺上没有很激进的变化,但是架构上的变化还是不小的。这个工作的动机非常简单,在ISSCC 2021的数字CIM架构中,1b*4b的操作是通过4b或非门乘法器完成,然后再通过4b加法器两两相加。但是从真值表上来看,2个4b或非门乘法器加1个4b加法器完成的工作实际上可以通过一个由加法器和两比特IN控制的四选一Mux(或者说LUT)来完成。这样做的话可以直接节省掉21%的功耗。
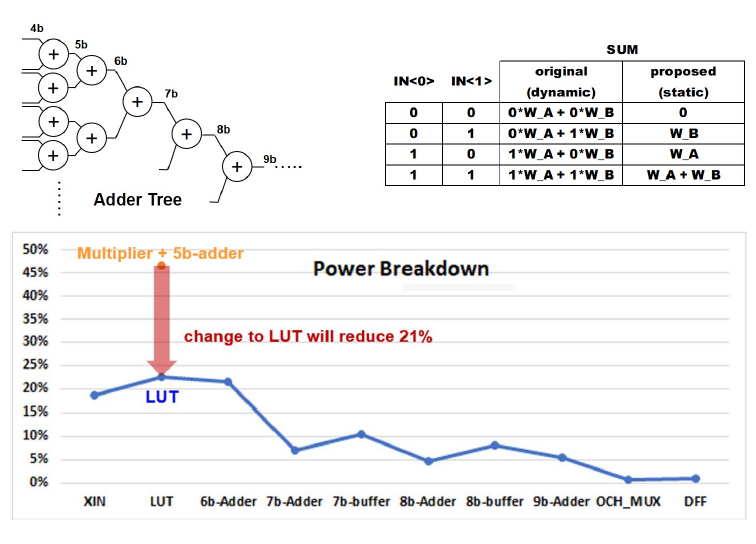
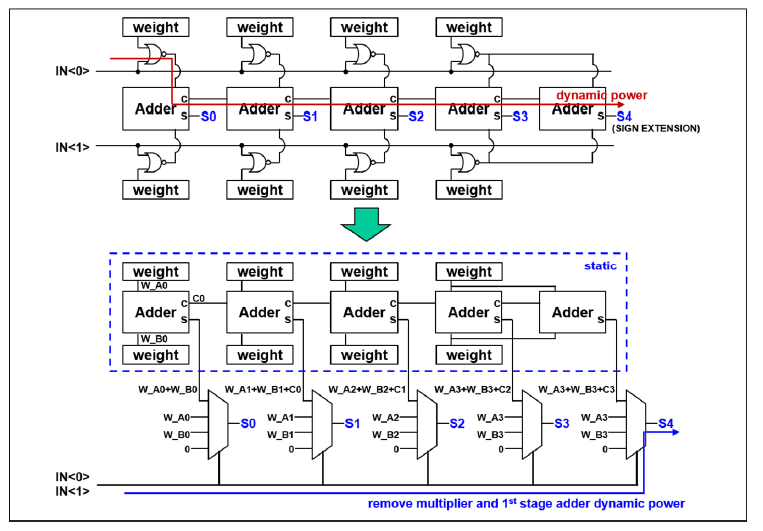
这里展示了电路上的具体变化,如之前所说,将或非门和4b加法器替换为了加法器和LUT,在原来的或非门和加法器的方案中,由于或非门输出结果随着输入值的变化而动态变化,因此加法器的输入也是不断动态变化的,这就使得或非门和加法器(尤其是加法器)上产生大的动态功耗。使用LUT的方案中,加法器的输出是预先计算好后固定的,消除了加法器上的动态功耗。LUT的输入都是静态的,只有输出会跟随IN的变化而变化。当然这里是展示原理的一种画法,看过21年的论文,我们知道实际上Adder没有嵌入到array里面去,嵌入的只有或非门乘法器,4b加法器还是在外面的。此外由于采用了预计算,不需要即时计算结果和进位,延时肯定是减小的,吞吐率增大。
这里其实是我觉得这个工作对之前所有工作的一个重大变动,左边是原来我们比较熟悉的乘法器+加法器树结构,右边是用LUT替换之后的方案,但是需要注意的是,首先,在他提出的这个并行多位输入结构下(即并非bit serial的输入4b数,而是并行的把4个4b输入给送进去,从而提升吞吐率),由于要1cycle算完4个4b和4个4b的乘累加,所以电路复制了四套,从数学上来说就是:
由于在LUT方案下可以加法器可以share,不像原来的方案那样加法器也要做复制,尽管在1b-input情况下LUT方案会比原来的方案Macro Size大出7%(Mux比或非门乘法器大导致的),但是在并行多位输入的4b-input的情况下,Macro Size反而会减小,比原方案少16%的面积。
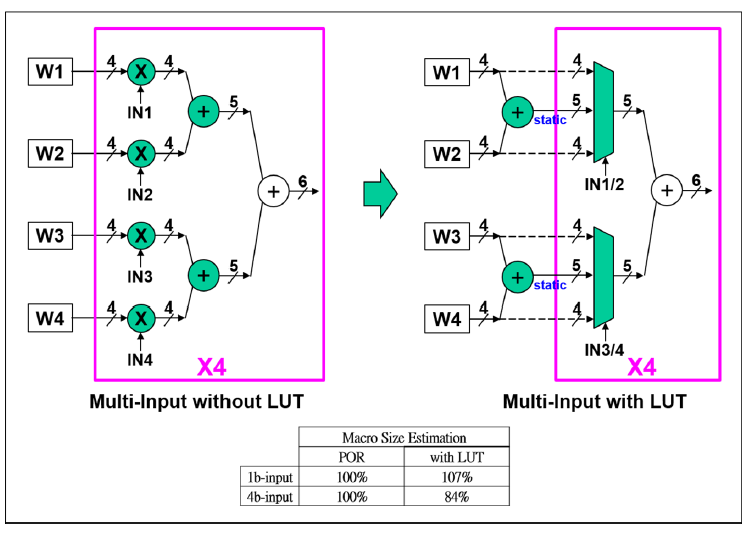
它比较了256个1b input(即21年的bit serial方案)和并行输入方案4*64,从power consumption来看,增大并行位数对于这种方案能够形成相对提升,在64*1的情况下,对比256*1,相比25%(因为输入数量只有256的1/4)要大出20%,64*2时,对比256*1的50%要大出7%,到了64*4,和256*1并行度相等的情况下,功耗反而能低7%。因为并行输入显著减少了移位累加上的开销,由于对加法器的复用,加法树上的开销也有所减小。对于bit serial方案,并行输入方案做到了能效,速度,面积,算力密度四个指标上的全面提升。

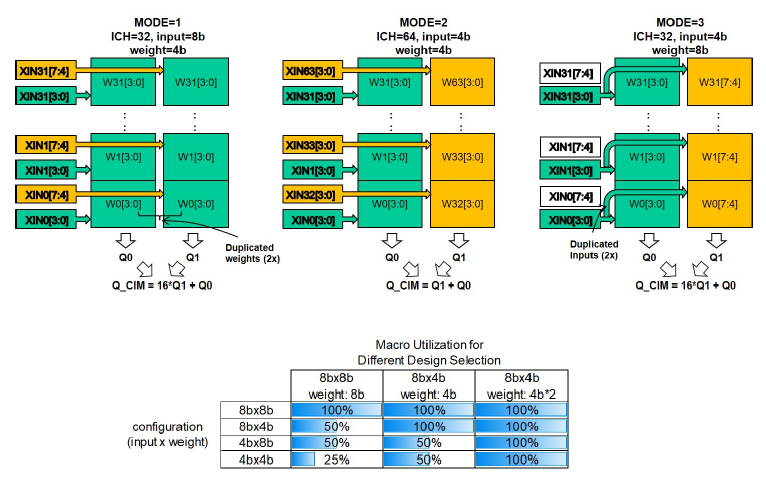
这里展示了位宽的可配置性,针对输入和权重4b/8b共4种组合,权重和输入都是以4b为单位,单个MAC单元处理4b*4b,这是理论上利用率最高,在四种比特位数配置组合下都可以达到MAC单元100%利用率的方案。这里讨论了三种MODE,实际上还有个输入和权重都是8b的情况没讨论,实际部署时根据:
如果要一拍算掉那么就需要用到四个MAC块,对权重和输入都需要做出一份复制,并且要有4个部分积要做移位加。另一种思路是在MODE3的基础上用两拍搞定计算,即:
每拍算掉一个4b input乘8b weight的部分积,然后再移位累加。
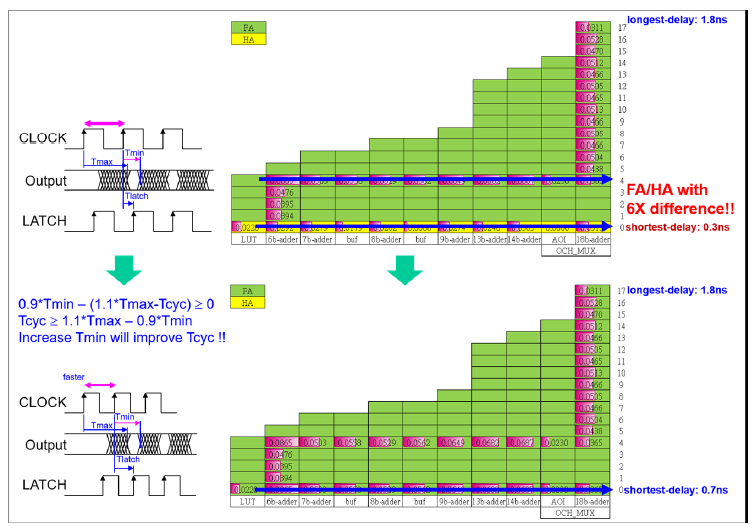
MAC计算速度的主要限制是在加法树延迟上,为了加快MAC的速度,他这里用了一个所谓的time-stealing技术,在前一个周期的最长延迟和当前周期的最短延迟之间锁存数据,因此用全加器FA取代半加器HA来实现加速,其原理可以看一下这个时序图定义\(T_{max}\),\(T_{min}\),\(T_{latch}\),\(T_{cycle}\)分别是前一个周期的最长延迟(数据开始时刻减去前一个CLOCK时钟上升沿的时刻),当前周期的最小延迟(数据结束时刻减去当前CLOCK上升沿的时刻),数据到来后被锁存的时间(LATCH时钟上升沿时刻减去数据开始时刻),以及CLOCK时钟周期,因此满足关系式\(0.9*T_{min}-(1.1*T_{max}-T_{cyc})\geq 0\),这里的0.9和1.1应该是考虑了这两个时间可能存在10%的波动情况下的worst case,看时序图就知道这里计算出的就是一个到来的数据结束的时间减去到来数据的开始时间,即一个到来数据持续的时间,这个时间自然是大于等于0的。把这个公式变形后得到\(T_{cyc}\geq 1.1*T_{max}-0.9*T_{min}\),从而知道如果保持\(T_{max}\)同时增大\(T_{min}\)就可以实现降低最小\(T_{cyc}\)的作用。从右边的图中可以看出用FA替换了HA之后,当前周期最短时间延迟\(T_{min}\)从0.3ns增加到了0.7ns,而上周期最大延迟\(T_{max}\)则保持1.8ns不变,因此根据前面的不等式\(T_{cyc}\)减小。这个技术还是巧妙的,因为如果按照只有一个时钟控制采用的情况的话,我们必须得要数据有效后一直要保持到这个时钟的下一个上升沿采样了之后继续变化,而time-stealing技术引入了一个LATCH时钟,与CLOCK时钟有一定的相位差,在数据开始有效后就立马锁存,从而“偷”到时间,但是这就用到了异步时钟,在时序问题感觉会变得更复杂。
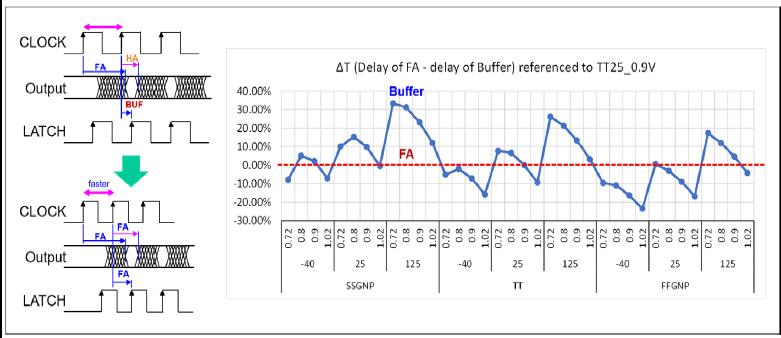
使用FA的另一个好处是其作为一个latch的信号延迟相对于传统buffer能够更好的跟踪PVT,并且由于其跟踪加法树结构,所以不存在PVT offset,具体体现在这个图例可以看到FA的延迟在不同的工艺角,温度和温度下仍然保持一个固定的延迟(红色虚线),而buffer的延迟则不断波动(蓝色实现)。并且根据左边的时序图,使用FA代替HA和buffer可以实现更快的时钟频率。
最后是数据结果,可以看到速度与电压之间近似线性的关系,在最低温度-40℃的情况可以在0.9V达到900MHz的速度。
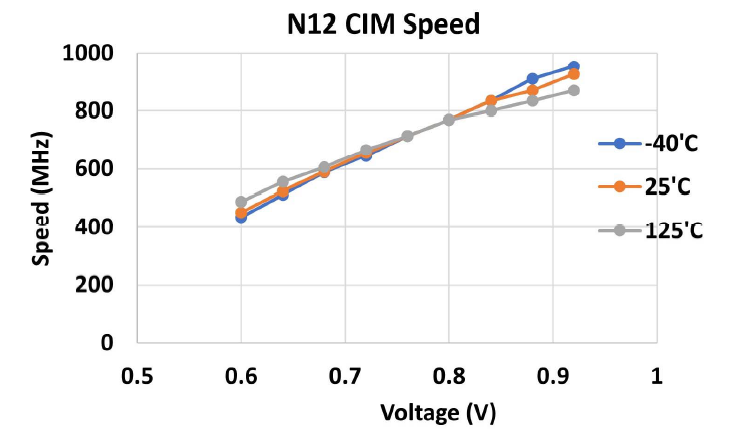
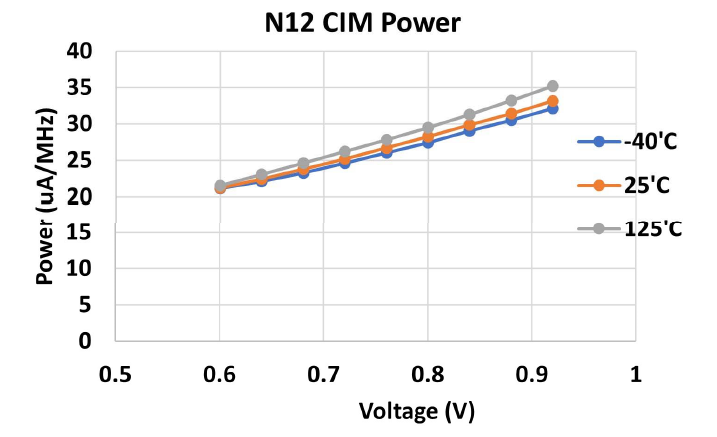
功耗(\(\mu A/MHz\))随着电压升高而近似线性升高,-40℃下最低电压0.6V在20左右,0.9V在30左右。如果把这个量纲转换到\(\mu W\)下,那么就是\(\mu A/MHz * MHz*V\),计算能效时\(TOPS/W=OPS*MHz/(\mu A/MHz*MHz*V)\),分子分母中把\(MHz\)一同约掉,\(OPS\)由硬件结构决定,视作常量,又考虑到\(\mu A/MHz \propto V\),因此\(TOPS/W \propto 1/V^2\),即能效与电压呈现倒二次关系,这也和我们之前对其他工作指标的观察相符。以上测量是在权重稀疏度为50%和输入稀疏度10%的条件下进行的。
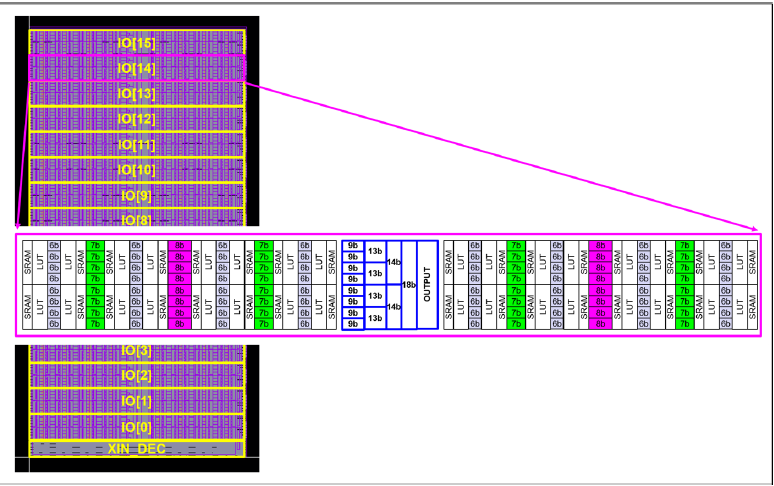
在floorplan上使用了与之前介绍的22年类似的技术,SRAM和LUT耦合成一个块,两个块share一组6b加法器,四个块再去share一组7b加法器,以此类推。最后16个块一起share最后几级的加法器(9b,13b,14b,18b)以及Output。所以可以计算出整个阵列的规模为4*4*2*16*16=8Kb。
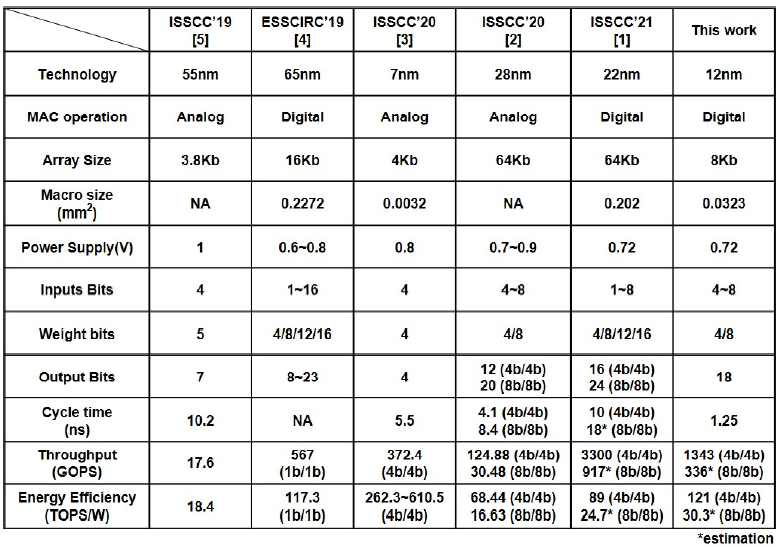
最后的参数比较了Throughput和TOPS/W的指标,结果上来看还是有优势的,但相比21年的工作,能效提升感觉并不是那么明显,另外由于规模的缩小,实际上Throughput反而是更低的。
A 3nm, 32.5TOPS/W, 55.0TOPS/mm2 and 3.78Mb/mm2 Fully-Digital Compute-in-Memory Macro Supporting INT12 × INT12 with a Parallel-MAC Architecture and Foundry 6T-SRAM Bit Cell
这是TSMC在24年ISSCC上的新作,相比之前的论文,这篇论文上的技术细节少了很多。感觉更多是对之前工作的一个整合,具体的内容我们下面慢慢介绍。
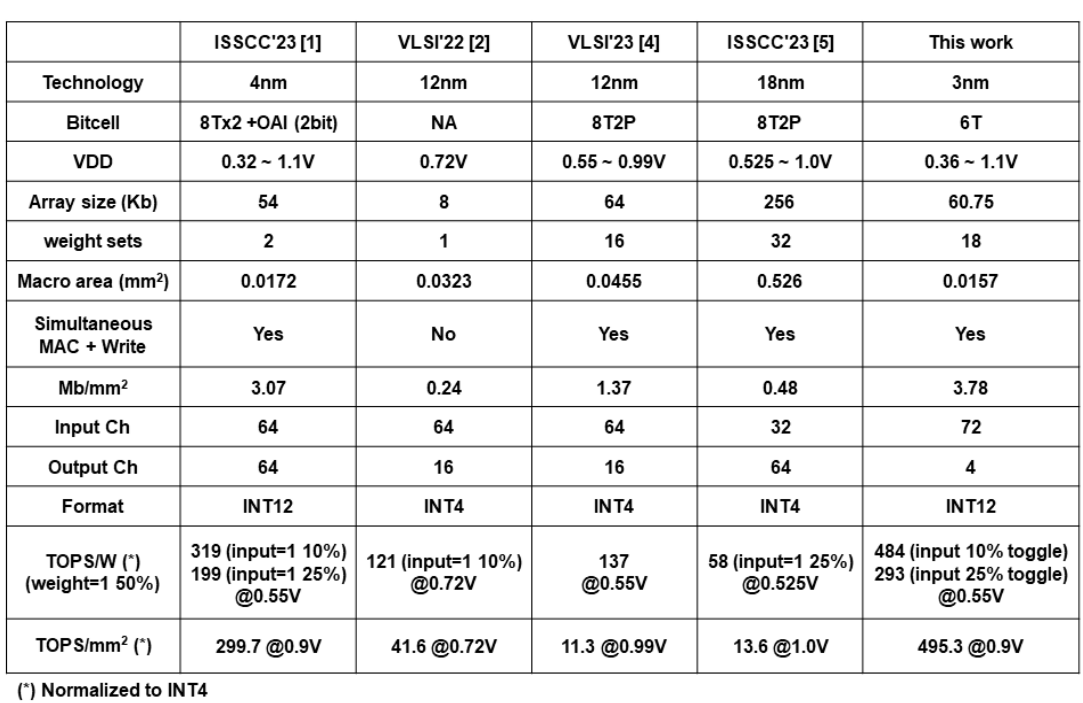
从标题上我们看到几个主要Feature,首先是工艺继续Scaling Down到了3nm,然后是对三个指标的强调:能效(Energy Efficiency)TOPS/W,算力密度(Compute Density)TOPS/mm2以及存储密度(Storage Density)Mb/mm2,前两者是老生常谈,存储密度虽然以前的其他单位的工作也有过强调,但是在TSMC这边是第一次,我觉得这是个很重要的insight,因为我们知道存算一体的主要目的是减少数据搬运的开销,如果一味的堆计算单元而损失存储密度,那么虽然整体的计算吞吐率(TOPS)可以做到很大,相应的对计算密度也会有提升,但是由于需要频繁给CIM Macro刷新数据,从系统能效的角度上来说反而是下降的。这几个指标的关系可以做一次量化的讨论,但是下次再说吧。INT12乘INT12这个位数和23年的工作保持一致。Parallel-MAC这个技术,实际上是采用了VLSI 22上的方法,最后是使用的SRAM类型变成了Foundry 6T-SRAM。
首先是整体架构图,这里先纠正一个图里的小bug,SRAM Array的列数应该是12*4*4=192,图里误标成了196。当时ISSCC现场也有人提问了这个问题,作者承认了这里是个小的mistake哈哈。我们可以看到这次的框图整体来说很简单,甚至可以说看起来不像是个CIM,更像是个近存计算宏NMC,但是熟悉之前工作的都知道在布局时其实计算单元还是与存储单元比较紧密耦合的,TSMC从22年开始的CIM工作一向如此,看着像NMC但是就是管它叫做CIM。
这次的SRAM Array的行数做到了远超之前工作的宽度,之前的工作的row都做的非常小,也就个位数的水平,这次直接做到了18,并且有18个segments,也就是18*18=324,直接拉开了两个数量级的差距。MAC with LUT就是VLSI 22上的Bit parallel乘加方案。Decode电路进行行列解码以支持Load/Store操作,最后一个亮点是Interface+CTRL+DFT模块,除了一般CIM都有的存储器接口以及控制电路,还增加了DFT功能,根据论文描述是一个BIST电路,学术界论文一般不会重视这个,但是对于工业应用,BIST电路是必要的。此外和23年工作一样,区分了VDD和VDDM两个电压域,并使用了低Vt和高Vt的两类管子,这是在工业SRAM设计中很Practical的做法。
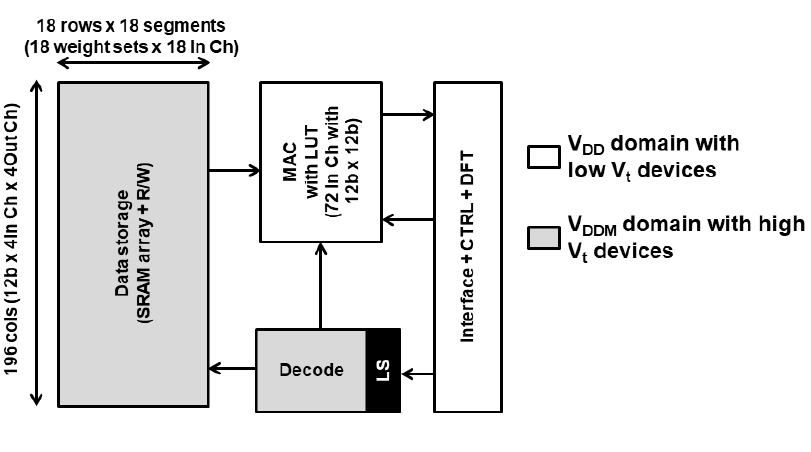
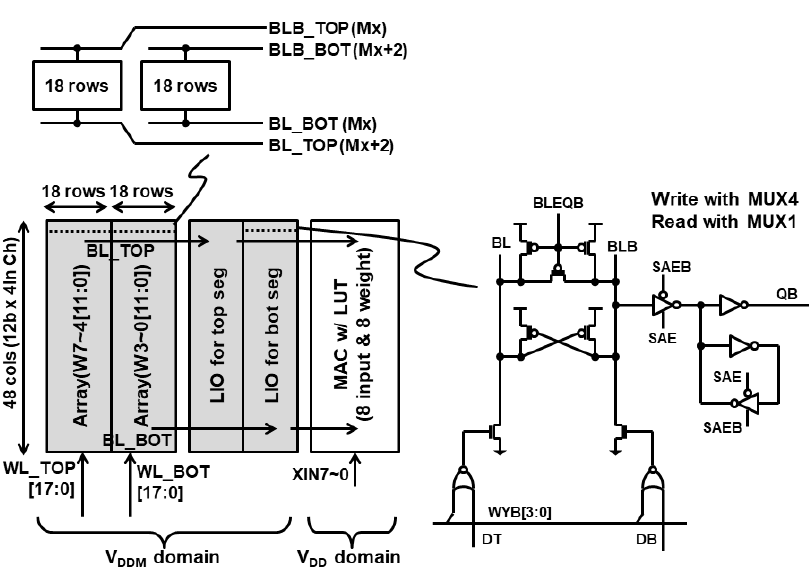
这里透露了一下SRAM设计的细节,首先是SRAM使用了BL分离的设计,每两个18 Rows的Array分成了BL_BOT/BLB_BOT和BL_TOP/BLB_TOP两套BL线,这个也是SRAM设计里比较Practical的做法,因为BL线太长了会导致Delay增大以及IR Drop产生Read Fail的问题。另外两个Bank的WL也是分离的,分成了WL_TOP和WL_BOT。对于具体的一个存算block的设计上,采用了两个18 Rows Array配两个LIO(分别给BL_BOT/BLB_BOT以及BL_TOP/BLB_TOP)以及一个LUT MAC,LIO即Local IO,还是采用了比较标准的Latch based SRAM读电路设计模式。写入时使用MUX4,读的时候用MUX1。存储单元和LIO用的VDDM域,高Vt器件,MAC电路用的是VDD域,低Vt器件。由于是Bit parallel模式,这里XIN7~0应该是8个12b的输入,刚好对应两个18 Rows Bank,每个的列宽是48=12*4,两个在一块就刚好总共是8个权重。
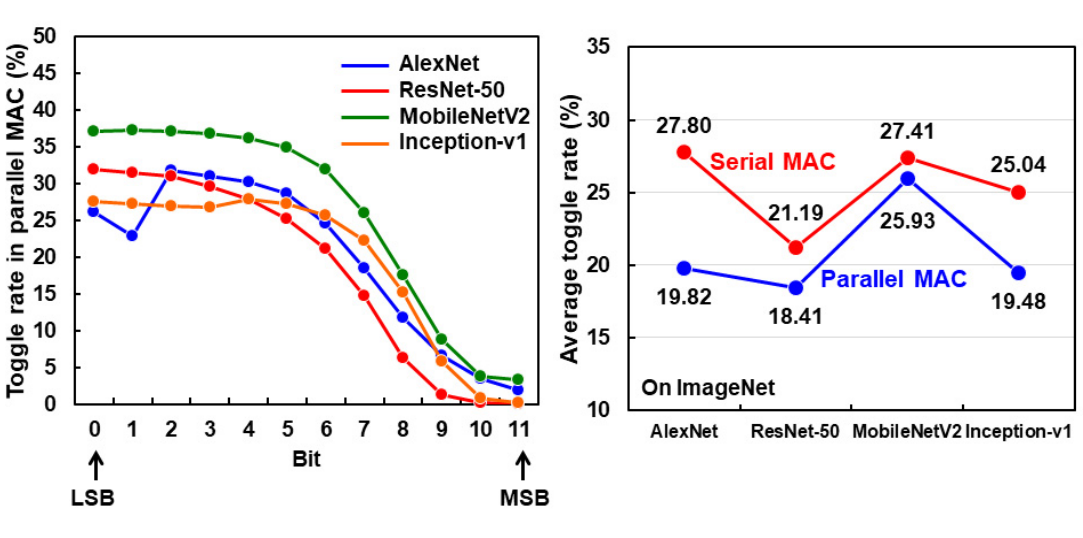
然后设计的细节就只有这么多了......这里就开始比较数据了........这里对Bit serial和Bit parallel两种模式做了一个比较,首先这里的一个insight是,在多个数据集上测试的结果是,对于input来说,MSB的翻转率是远低LSB的,Bit parallel可以利用到MSB低翻转率的特性(论文原文说是data correlation)数据相关性。我理解的意思是这样的,对于Bit parallel来说,下一个Activaion跟上一个Activation从LSB到MSB都是对齐的,所以MSB很可能一起都不翻转。而对于Bit serial来说,下一个Activation是用MSB去跟上一个Activation的LSB,而MSB和LSB之间很大概率会存在数据翻转,所以Bit parallel会有比Bit serial更低的翻转率。他这里也给了在4个CNN Model上的对比,整体上来看Parallel MAC的翻转率是低于Serial MAC的,这也是给他们改用Bit parallel找了一个角度。
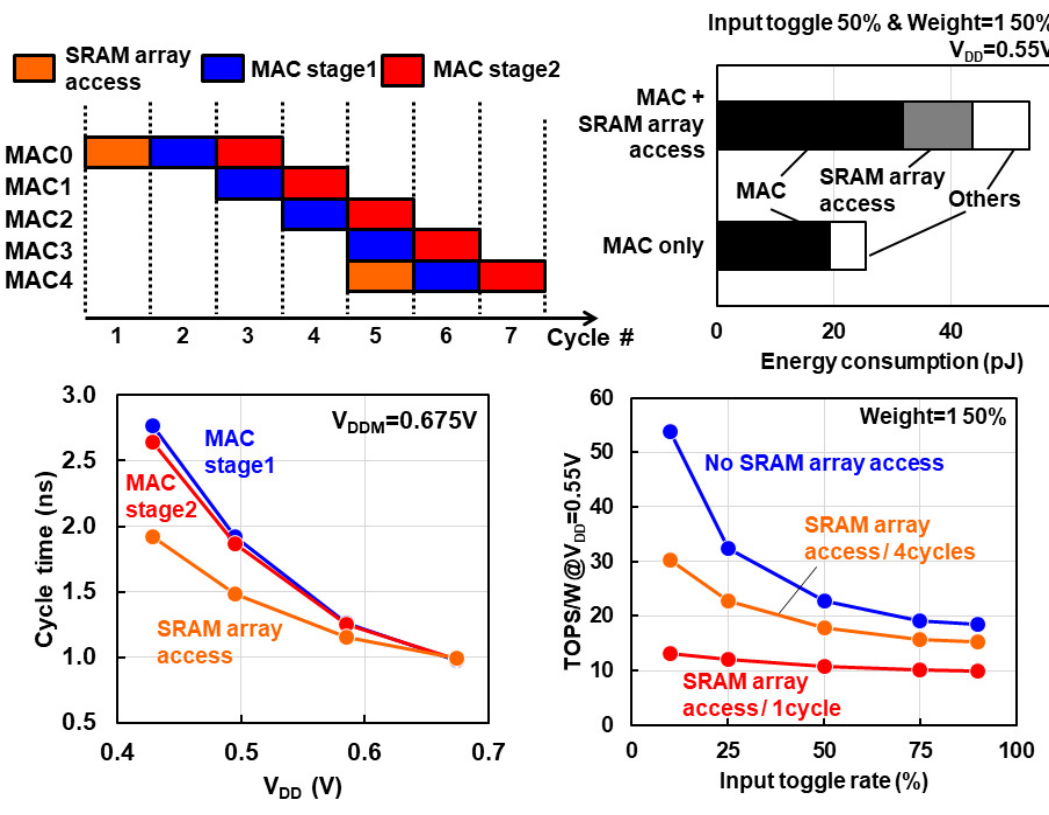
这里是更多的数据,他们采用了类似23年的pipeline的做法,但是这次流水线粒度切得更细了,具体来说,在SRAM array access处做了一个流水,在MAC里面则做了两个stage的流水,总共是三级流水。在进行一次完整MAC时,先进行一次SRAM array access,然后接下来4个cycle里面MAC stage1和stage2交替工作,到了第5个cycle再进行一次SRAM array access。如果是SRAM array access+MAC的情况,由于额外的toggle,整体功耗会大很多,相比如果切了流水线,只有MAC的情况下大概翻了两倍。所以切流水线这个操作还是很有意义的,提升了吞吐率还降低了功耗。和之前的工作一样,流水线切分是基于STA分析再做的,基本上确保了在不同VDD下Cycle time基本一致。这张图还并比较了不同的SRAM array access情况下的能效情况,对切流水线提升能效的说法进行了佐证。
这里是基于BIST电路对芯片进行了测试,频率最高可以飚到1.6GHz。对VDD和VDDM同时扫描时(VDD = VDDM),VMIN 低于 0.6V,良率达 95%。 VDD 被扫描且 VDDM 固定时。我们观察到 VMIN 变为0.36V,良率 95%。

最后的比较表,TOPS/W,TOPS/mm2都达到了很恐怖的值。直呼无法碰瓷。
版图上来看还是之前类似的布局设计。总共摆了9组之前介绍的SRAM+MAC的CIM Block。
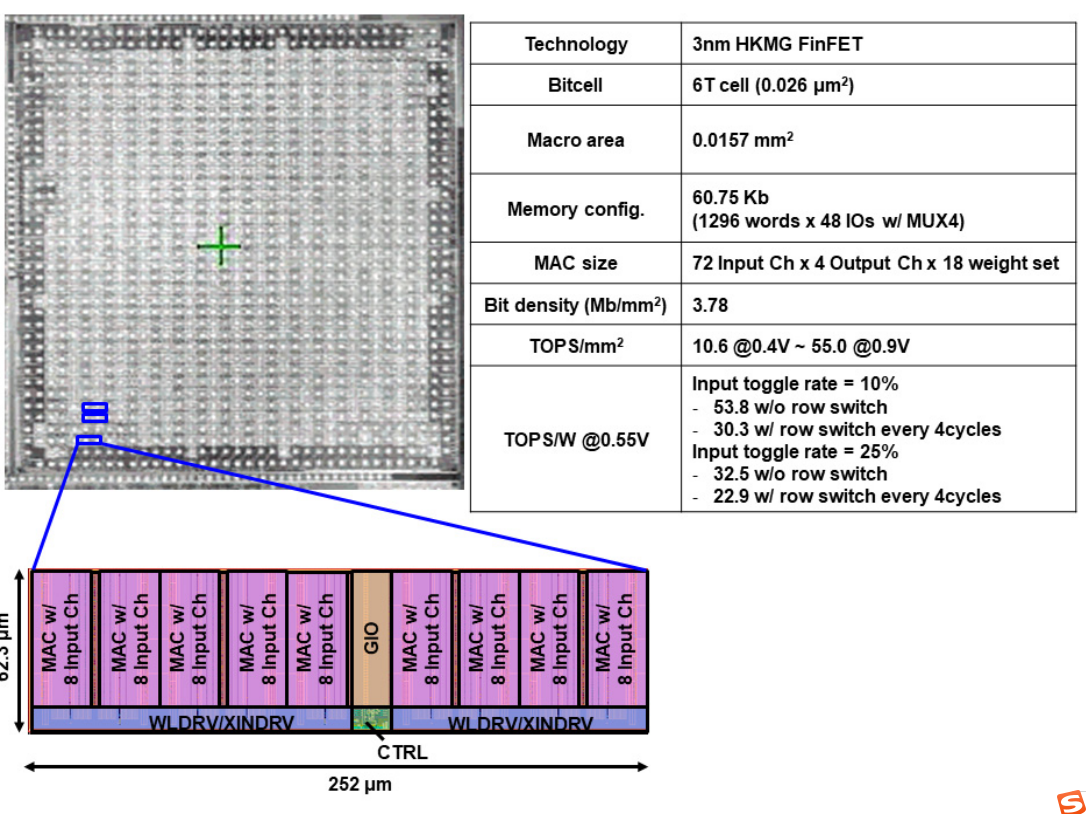
整体上这篇论文我觉得最精华的部分还是在于它的insight,从翻转率的角度分析了Bit parallel和Pipeline的作用,令人耳目一新,当然从工程上来说也有很多值得学习的地方,比如将一些SRAM工业设计上的Practical的技术放进来。
结语
至此个人觉得比较经典的TSMC几篇数字CIM的文章就基本上整理完了,总体来说受益良多,可以看到他们这几年工作的延续性很强,技术上稳中有进,既有新东西,又有对于一些好的技术的保留或改进。从架构趋势的角度来说,TSMC在22年ISSCC就开始改旗易帜,不再像他们自己ISSCC 2021 CIM工作采用将逻辑门嵌入阵列的模式,而是使用多个小的分布式SRAM bank(一般是4*4bit cell)和MAC计算逻辑耦合,这种有点类似于近存计算的模式。在我看来,这种模式有着更好的拓展性,在增大并行度的同时,也能尽可能保证架构的紧凑性,是一种值得follow的架构。
引用
Nigam, Arvind. “Comparative Analysis of 28 T Full Adder with 14 T Full Adder using 180 nm.” (2016). ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号