对大模型技术与可能的社会影响的思考(一)
1. 简介
22年11月底OpenAI发布了ChatGPT这一应用,随后ChatGPT的话题不断发酵,人们惊叹于其展现出的强大的语言能力,各种讨论铺天盖地,但技术层面的讨论主要集中在简单的原理科普,社会层面的讨论主要围绕对于工作岗位的影响,并未透视到其深层次的技术趋势和更深远的社会影响。本文的主要目的在于从技术层面对大模型的起源及其后续发展趋势做出一定的研判。本文的写作依赖于本人有限的知识储备,凡有异议者欢迎留言讨论。
2. 大模型的起源
本节我们将对神经网络模型的大规模化进行追根溯源,并说清楚什么是大模型,大模型到底有什么不同,大模型是否有其能力上限这三个问题。目前火热的ChatGPT实际上是自然语言处理领域(Natural Language Processing,NLP)中大语言模型(Large Language Model,LLM)研究方向的技术成果,这里包含两个关键词,一个是语言模型,一个是大模型,语言模型的发展沿革可以参考我之前写的语言模型发展综述,本文不再费笔墨,仅针对大模型展开讨论。
大模型之路始于2017年6月,Google提出Transformer架构[1],这种架构采用自注意力(Self-Attention)机制,相比卷积神经网络(Convolutional Neural Network,CNN)具有更强的长距离捕捉能力,相比循环神经网络(Recurrent Neural Network,RNN)有更高的并行度,因此提高了训练的速度。Transformer打破了此前神经网络语言模型受限于CNN有限的捕捉能力,和RNN串行结构的低效率的情况,因此迅速被采用于后续的神经网络语言模型的开发,为未来的大模型确定了架构基础。
2018年6月,OpenAI提出GPT(Generative Pre-Training Transformer)[2],即生成式预训练Transformer,这包括三个关键点,生成式,预训练和Transformer,首先GPT为生成式模型而非判别式模型,这两者对于问题的建模差别极大,直接导致了训练方法的区别:依赖有便签数据的监督训练方法对数据集要求很高,而制作大规模便签数据集的成本非常大,因此进而限制了其训练集规模的扩大,而自监督预训练不依赖标签数据,因此可以快速扩大数据集规模,对于生成式模型来说,其一般采用生成学习的自监督方法,而判别式模型则采用对比学习的方法[3]。
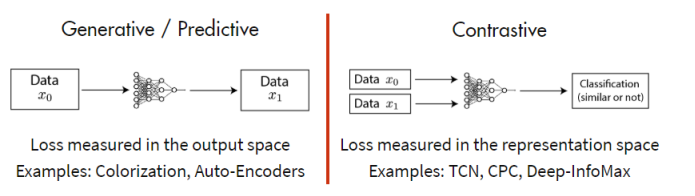
在语言任务的情景中,前者显得更加具有优势,因为给定一段无标注的语料的情况下,阅读前面的语句并预判后面的语句,是一件非常自然的行为,这也符合语言模型本身的马尔可夫链的条件概率定义公式。GPT通过Transformer中的Decoder来建立语言模型,通过自监督预训练+有监督调优(fine-tuning)的方式完成了模型的训练。并在与LSTM的baseline进行对比后,确定了自身的优势。而GPT系列的基调也被定下,尽管后续模型又经历了数度调整,但生成式(Generative),预训练(Pre-train),Transformer这三个关键词始终不离不弃。
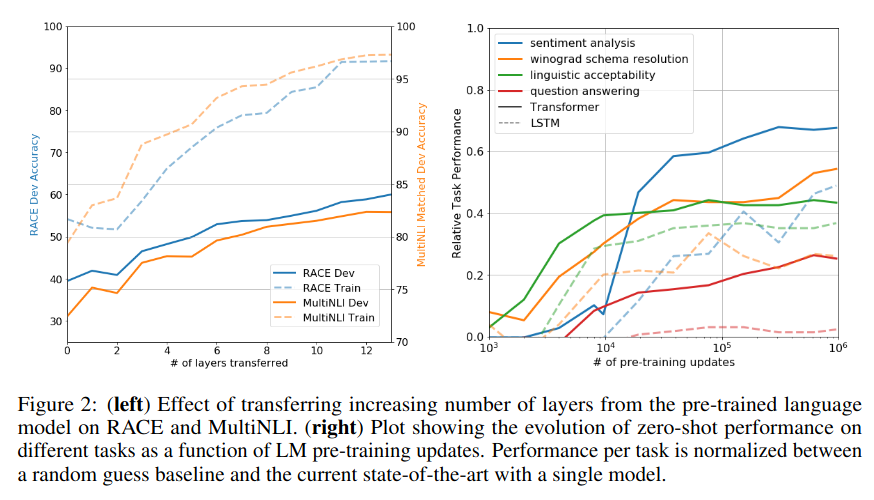
2019年2月,OpenAI在GPT的基础上进一步提出GPT-2[4],相对于GPT的一个重大的范式转换(同时也是语言模型发展中的一个重大范式转换)在于尝试将多种自然语言处理任务进行统合,包括阅读理解、机器翻译、问答和文本概括等。以往这些任务都是通过不同的模型,或者在一个大的预训练模型上增加针对不同下游任务的小网络来完成的,也是在1代GPT中除了自监督预训练外还采用了fine-tuning的原因,就是针对不同的下游任务再训练一个linear+softmax层。但GPT-2认为多任务的问题同样可以泛化为条件概率的形式,因为具体的任务类型的要求往往也包含在了自然语言中,因此无需再进行独立的fine-tuning,而是只通过预训练就能直接用于完成多任务——只要模型足够大。这里我将论文原文粘贴如下,我认为这是一种重要的思维转变,也是GPT系列和其他语言模型正式拉开差距的地方:
Learning to perform a single task can be expressed in a probabilistic framework as estimating a conditional distribution p(output|input). Since a general system should be able to perform many different tasks, even for the same input, it should condition not only on the input but also on the task to be performed. That is, it should model p(output|input, task). This has been variously formalized in multitask and meta-learning settings.
此外,GPT-2的论文中专门对模型的zero-shot迁移能力(即自发的学会一种训练集中没有的映射关系的能力)进行了讨论,并认为语言模型的容量对于zero-shot任务迁移的成功至关重要,并且增加容量可以以对数线性方式提高跨任务性能。这种理念支撑了下一代更庞大的GPT-3的出现。
2020年5月,OpenAI发布了GPT-3,从技术上来说,GPT-3主要是对GPT-2进行了参数量和训练集大小的极大提升,而我认为到GPT-3才真正标志着大模型的诞生,因为从GPT-3开始,发生了真正意义上的从量变到质变,大模型的一些“神奇的能力(Emergent Ability)”开始出现[5]。在人们对于神经网络模型的传统理解中,训练集中数据的真实概率分布被神经网络在训练的过程中不断拟合,最终当神经网络的梯度下降到达损失函数的最小值后,权重表征的概率分布就高度接近训练集的真实概率分布,这也是神经网络学习能力的来源,可以说对于之前的神经网络来说,权重决定了其一切的能力,当训练结束,权重确定以后,神经网络的能力就被固定了,不会再获得任何新的知识。
但对于大模型来说,这种范式也动摇了,GPT-3表现出了情景学习(in-context learning)的能力,即通过设计的输入变化(prompting),其输出也会展现出惊人的性能改善,仿佛在权重固定的情况下,模型从输入中学习到了新的知识。这里我同样贴上论文原文中的描述:
The success of large language models (LLMs) is often attributed to (in-context) few-shot or zero-shot learning. It can solve various tasks by simply conditioning the models on a few examples (few-shot) or instructions describing the task (zero-shot). The method of conditioning the language model is called “prompting”
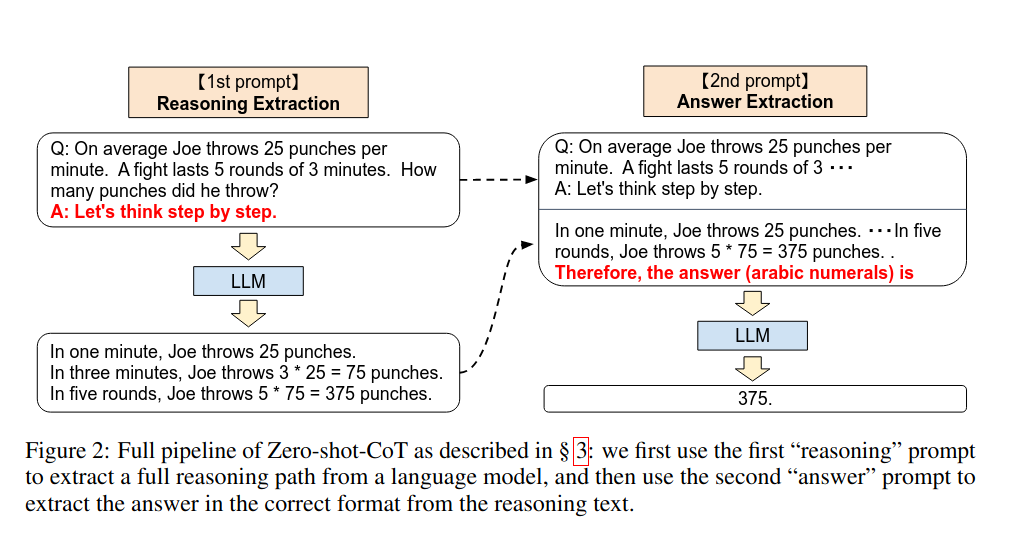
我们通过论文中的例子来看这个问题,在Few-shot场景中,通过从直接给模型展示同类问题的答案,变成给模型展示同类问题的解题思路,即所谓的思维链(Chain of Thought,CoT),模型就能够解决一道原本无法正确解答的问题。而在Zero-shot-CoT场景中,更是仅仅通过一句“魔咒”——Let's think step by step,GPT-3的输出从左边的错误答案变成了右侧的正确答案,并且给出了详细的分析过程。

在论文中展现了Zero-shot-CoT的两阶段prompt的具体过程:在第一阶段(Reasoning Extraction)中,输入是要提问的问题+魔咒“Let's think step by step”,大模型会给出自己的分析。接着在第二阶段(Answer Extraction)中,将第一阶段的输入和第一阶段中大模型自己分析出的结果拼接在一起,再加一句追问“Therefore,the answer (arabic numerals) is”,大模型会直接给出正确答案:375。这个过程是否很像小学老师在教一个小朋友如何一步步解开一道数学题的过程?但需要注意的问题是,如我们前面所述,一般我们认为神经网络的学习过程只发生在其训练并改变权重的时候,而不可能在保持权重固定的情况下,仅仅通过输入变化就仿佛“学会”了之前不理解的问题。因此这种In-context learning被认为是Emergent Ability,其背后的原理仍然是未解之谜。
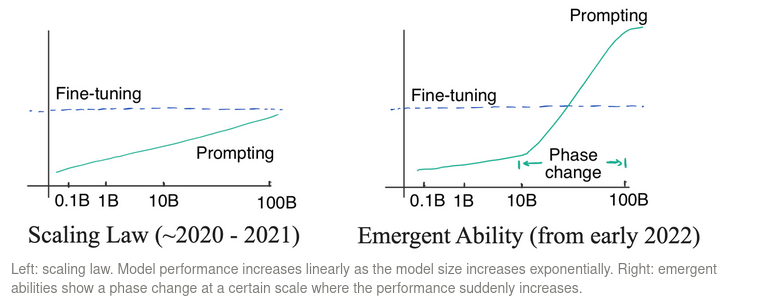
这一范式转变的结果就是Prompting模式在大模型上完全甩开了Fine-tuning,有力的宣告了大模型的合理性,因为只有对于大模型来说,当越过一个参数量级的分水岭后,通过设计Prompting,模型的zero-shot能力突然打破了GPT-2的论文中描述的对数线性关系(模型参数量指数增加一倍,性能线性增加一倍),只要使用合适的Prompting,立马性能飙升,甚至超过有监督学习的fine-tuing模式。这带来的改变是,在对数线性定律(Scaling Law)[6]生效的时代,以模型参数量去换取性能是一件非常不值当的行为——付出指数的参数量增加的代价,仅仅只能换来线性的提升,而且还不能够战胜Fine-tuning模式带来的性能提升。如果这样的话,我们为什么不采用成本更低的小模型+Fine tuning模式,就像BERT那条技术路线一样呢?然而当Prompting能够仅仅以改变输入的低成本方式就实现了超越Fine tuning模式的性能飞跃后,人们终于承认了大模型技术路线的正确性[7]。
隐藏在技术背后的故事是,在GPT-3刚提出的2020年,其初步展现出的zero-shot能力仍然符合Scaling Law,也导致大模型路线备受质疑,直到2022年初,大模型展现了通过Prompting暴增性能的Emergent Ability,这才扭转了局面。GPT-3进一步挖掘大模型本身的潜能,从逆境之中彻底走出,并在22年底抛出了震撼全球的ChatGPT。
回顾2020的GPT-3发布之后,OpenAI没有急于进一步提升模型规模,而是开始研究通过改进训练方法进一步挖掘大语言模型的潜力。并在2022年3月发表了重要的InstructGPT[8],这一工作直接促成了后续的ChatGPT。登入ChatGPT的发布页,其上赫然写着:
ChatGPT: Optimizing Language Models for Dialogue
We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests. ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.
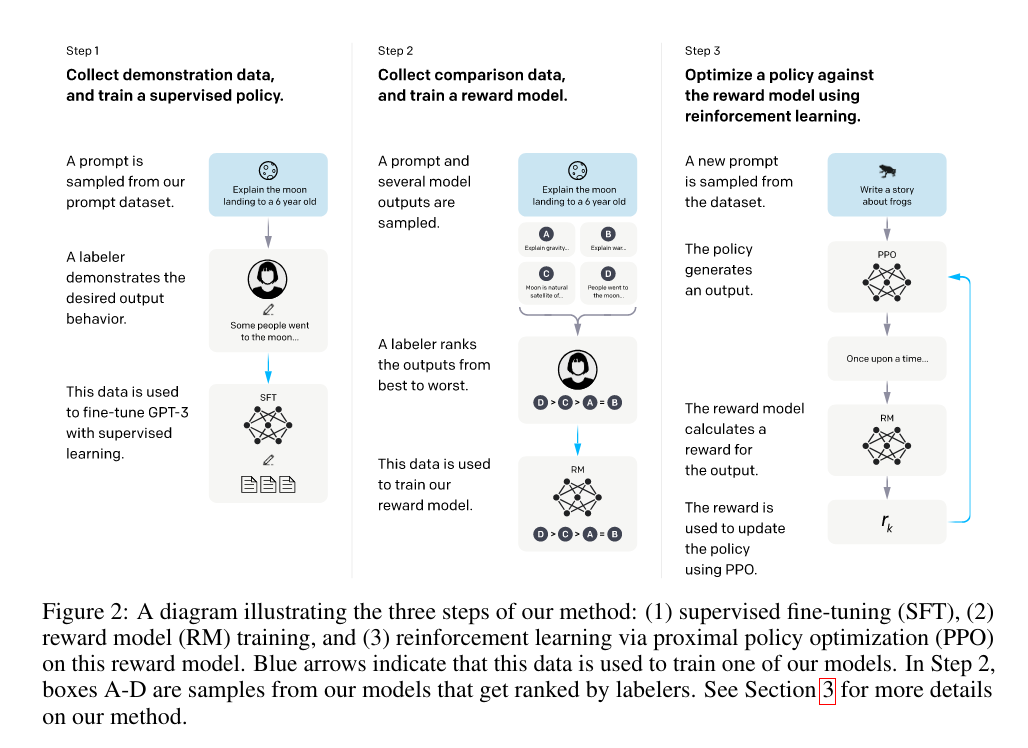
InstructGPT的主要目的是在GPT-3预训练模型上发掘模型理解指令的能力,因此在原始的GPT-3模型上又实施了三个步骤:1. 手动选择一些问题,并手动给出答案,以这个数据集来有监督的调优(Supervised Fine-Tuning,SFT) GPT-3模型。 2. 用训练好的SFT模型回答一些问题,人工对答案进行评分排序,然后用这部分数据集来训练奖励模型(Reward Model)。 3. 根据奖励模型的评分结果,运用近端策略优化(Proximal Policy Optimization,PPO)进一步优化SFT模型,同时他们也尝试了将预训练梯度和PPO梯度进行融合,称为(PPO-ptx)。
论文原文中对这一过程的描述是:
Reinforcement learning (RL). Once again following Stiennon et al. (2020), we fine-tuned the SFT model on our environment using PPO (Schulman et al., 2017). The environment is a bandit environment which presents a random customer prompt and expects a response to the prompt. Given the prompt and response, it produces a reward determined by the reward model and ends the episode.
In addition, we add a per-token KL penalty from the SFT model at each token to mitigate over-optimization of the reward model. The value function is initialized from the RM. We call these models “PPO.”
We also experiment with mixing the pretraining gradients into the PPO gradients, in order to fix the performance regressions on public NLP datasets. We call these models “PPO-ptx.”
这里的又一重大范式变化在于将强化学习的思路引入了语言模型的训练过程,通过人类协助构筑Reward Model,并将SFT模型视作被优化的Policy。至此有监督学习,自监督学习,强化学习三种手段都被应用在了InstructGPT的训练过程中。
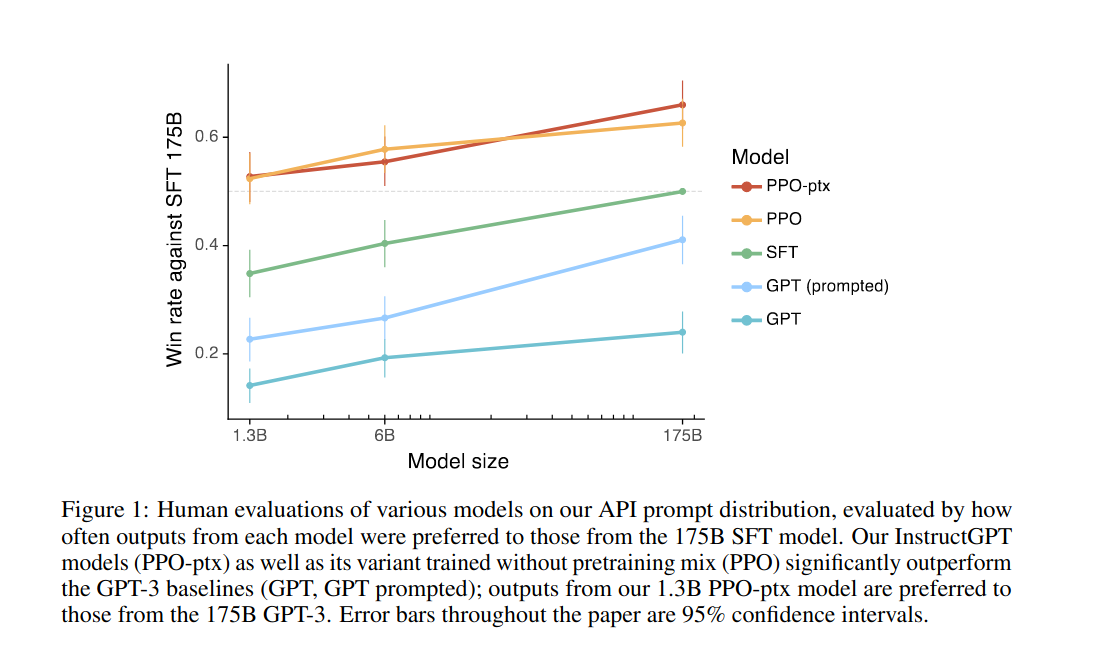
这样训练的结果是,在不改变模型结构和规模的情况下,模型就具有了成倍数的更强大的理解人类指令的能力,也预示着大语言模型的潜能仍然有充分的挖掘空间,Prompting,RLHF等都是在尝试“解锁”这些隐藏的能力。
需要指出的是在InstructGPT中,为了更好的理解人类指令,模型不得不付出一些在多任务上的性能下降,这可以算作是在模型性能和用户感受上作出的trade-off,称为“对齐税”,这里的“对齐”是指模型的输出更真实、更无害,而且更好地遵循用户意图,论文原文中的描述如下:
Our proposal for mitigating the alignment tax, by incorporating pretraining data into RLHF fine-tuning, does not completely mitigate performance regressions, and may make certain undesirable behaviors more likely for some tasks (if these behaviors are present in the pretraining data). This is an interesting area for further research. Another modification that would likely improve our method is to filter the pretraining mix data for toxic content (Ngo et al., 2021), or augment this data with synthetic instructions.
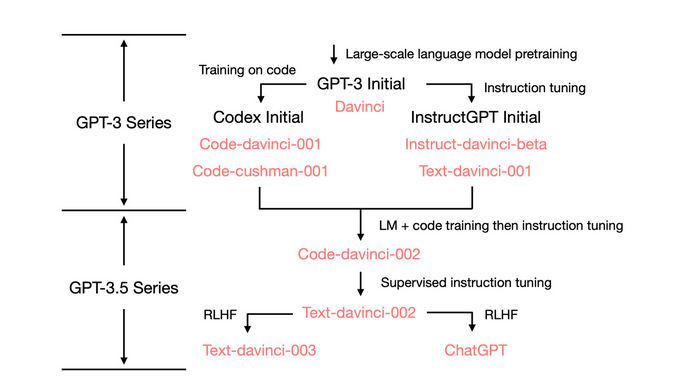
实际上在GPT-3向GPT-3.5进化的过程中,有一些技术路线上的分歧和整合,对于原始的预训练大模型GPT-3,除了上述的针对指令理解进行调优的InstructGPT以外,还有针对代码理解能力的CodeX模型[9](主要是在独立代码数据集上重新训练了GPT-3模型),并催生了编程助手Copilot这一强大的生产力工具。而在同时具备代码能力和指令理解能力的下一代模型Text-davinci-002上又延伸出了两条技术路径,一条是恢复在指令调优过程中丢失的部分In-context learning能力的Text-davinci-003,另一条是牺牲了几乎所有In-context learning能力来换取建模对话历史能力的ChatGPT[10]。
2023年2月,ChatGPT发布后的3个月,OpenAI背后的金主微软宣布将ChatGPT的技术整合入Bing搜索引擎中,并发布了新版Bing搜索引擎(Bing Chat)和 Edge 浏览器,可以通过对话的方式完成信息的检索,相比不能联网检索信息的ChatGPT,Bing Chat具备联网检索信息并标注信息来源的能力(需要强调的是OpenAI在21年12月即发布了依托于GPT-3,具备联网解决问题能力的WebGPT[11]),大大改变了搜索引擎的使用体验。这也为谷歌这一搜索引擎的传统老大带来了前所未有的危机感。各大互联网公司迅速公布自己的人工智能搜索引擎产品计划,新一轮军备竞赛即将开启,虽然微软占有极大的先发优势,但谷歌毕竟在AI领域也深耕许久,究竟鹿死谁手犹未可知,更令人期待的是大语言模型技术在这一过程中又会产生怎样的进化。
至此我们第一节的故事结束了,现在重新回顾本节提出的三个问题:什么是大模型,大模型到底有什么不同,大模型是否有其能力上限。
什么是大模型:大模型的“大”体现在数据集和模型参数量两个方面的迅速增加,对三代GPT进行总结可以发现其每代模型之间数据集和参数量都出现了数量级的提升。但直到GPT-3,OpenAI才正式宣布自己的模型是"大语言模型"。
| 模型 | 预训练数据量 | 参数量 |
|---|---|---|
| GPT | 约 5GB | 1.17 亿 |
| GPT-2 | 40GB | 15 亿 |
| GPT-3 | 45TB | 1,750 亿 |
大模型到底有什么不同:这里的重要转折点是,在模型的“大”到达一定量级之前,Zero-shot任务表现和模型规模遵循对数线性关系,指数倍数的规模增加才能够换取线性倍数的性能提升,而在跨过某个量级后,模型开始展现出Emergent Ability,尤其是In-context Learning能力,即可以通过Prompting完成极大的性能提升,这都是小模型不具备的能力,而In-context Learning能力的来源,划分大模型和小模型的具体规模界限,以及规模是否是唯一的决定性因素,仍有待进一步的研究[7:1]。
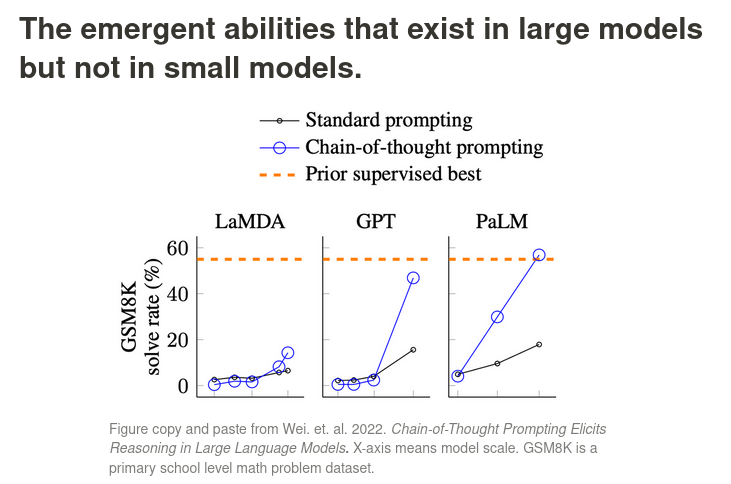
大模型是否有其能力上限:目前还看不到明确的技术层面上的制约因素(经济层面上主要是训练模型要付出的成本),不仅规模增大带来的性能提升尚未看到尽头,而且GPT-3到GPT-3.5的过程中可以看到通过各类优化手段持续挖掘大模型潜力的可能性。
至此本节完成了“大模型的起源”这一问题的论述,但需要强调的是,如本节开篇所述,上述大模型的进程主要发生在神经网络语言模型的范畴之内,而在同样大量应用神经网络模型技术的计算机视觉和多模态(语言+图像)领域中,又在发展各自独立的技术进程。下一节将主要讨论这两个领域中一些吸取了自然语言处理领域大模型发展的经验的工作及其技术趋势。
本节的写作亦参考了张俊林的文章[12],在此表达感谢。
3. 参考资料
《Attention Is All You Need》https://doi.org/10.48550/arXiv.1706.03762 ↩︎
《Improving Language Understanding by Generative Pre-Training》https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf ↩︎
《Contrastive Self-Supervised Learning》https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html ↩︎
《Language Models are Unsupervised Multitask Learners》https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf ↩︎
《Large Language Models are Zero-Shot Reasoners》https://doi.org/10.48550/arXiv.2205.11916 ↩︎
《Scaling Laws for Neural Language Models》https://doi.org/10.48550/arXiv.2001.08361 ↩︎
《A Closer Look at Large Language Models Emergent Abilities》https://yaofu.notion.site/A-Closer-Look-at-Large-Language-Models-Emergent-Abilities-493876b55df5479d80686f68a1abd72f ↩︎ ↩︎
《Training language models to follow instructions with human feedback》https://doi.org/10.48550/arXiv.2203.02155 ↩︎
《Evaluating Large Language Models Trained on Code》https://doi.org/10.48550/arXiv.2107.03374 ↩︎
《How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources》https://yaofu.notion.site/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their-Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1 ↩︎
《WebGPT: Browser-assisted question-answering with human feedback》https://doi.org/10.48550/arXiv.2112.09332 ↩︎
《由ChatGPT反思大语言模型(LLM)的技术精要》 https://mp.weixin.qq.com/s/gR9YsYjFVhViuANWFw59fg ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号