中国科学院大学数字集成电路作业开源——时序逻辑与存储器章节
中国科学院大学数字集成电路作业开源——第6-8章
1、基础概念问题
1.1 请简要描述Mealy状态机与Moore状态机的特性及它们之间的联系?
Moore状态机:输出仅仅与当前状态有关;
Mealy状态机:输出不仅取决于当前状态,还和输入有关;
Mealy和Moore机之间可以相互转化,对于每个Mealy机,都有一个等价的Moore机,Moore机状态的上限为所对应的Mealy机状态的数量和输出数量的乘积。
1.2 请简要描述SRAM的特点以及实际应用中与寄存器堆逻辑的优缺点比较?
SRAM的特点是工作速度快,只要电源不撤除,写入SRAM的信息就不会消失,不需要刷新电路,同时在读出时不破坏原来存放的信息,一经写入可多次读出,但集成度较低,功耗较大。
寄存器堆逻辑实现上更为简单,但性能远不如工艺优化后的SRAM。而SRAM性能虽强,但是实现上略微复杂。
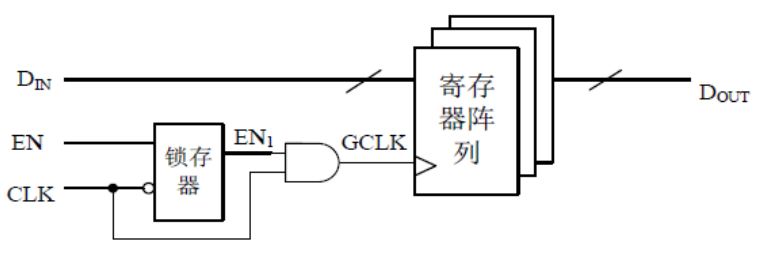
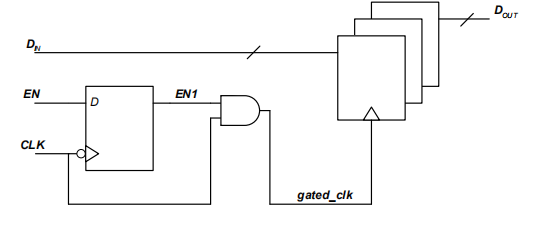
1.3 请简要描述门控时钟常见电路结构以及适用范围?
门控时钟电路结构包括直接将控制信号与时钟信号进行与操作(会产生毛刺,因此实际中很少使用)
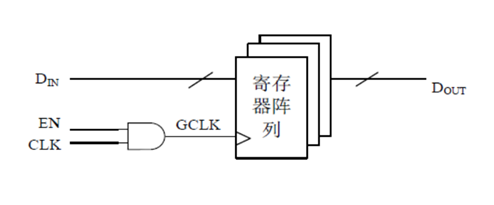
基于锁存器的时钟门控方案(常用于ASIC设计)
基于触发器的时钟门控方案(常用于FPGA设计)
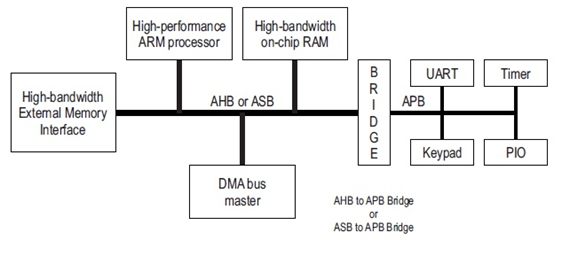
1.4 请简要描述AHB总线与APB总线的基本特性以及在实际SoC系统中它们的适用场合?
AHB(Advanced High-performance Bus), 为高速总线,一般用来连接高速外设。APB (Advanced Peripheral Bus) 为低速总线,一般用来接低速外设。
在SoC系统中,AHB总线会挂载ARM处理器,RAM,DMA控制器等设备,通过AHB2APB Bridge与APB总线连接,APB上挂在UART,Timer等低速设备。
2 基于Verilog HDL进行逻辑电路设计
2.1平方根计算
设计一个时序逻辑电路,计算32位非负整数的平方根。对于输入x,计算y = floor(sqrt(x)),即y是平方后不超过x的最大非负整数。例如:
l 输入x = 256,输出y = 16
l 输入x = 255,输出y = 15
l 输入x = 2147483648,输出y = 46340
l 输入x = 4294967295,输出y = 65535
顶层模块名为sqrt_u32,输入输出功能定义:
| 名称 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| clk | I | 1 | 系统时钟 |
| rst_n | I | 1 | 系统异步复位,低电平有效 |
| vld_in | I | 1 | 输入数据有效指示 |
| x | I | 32 | 输入被开方数据 |
| vld_out | O | 1 | 输出数据有效指示 |
| y | O | 16 | 输出结果数据 |
设计要求:
l Verilog实现代码可综合,给出综合以及仿真结果。
l 能够处理多组数据输入,且从数据输入到结果输出延迟周期数尽量少。
设计思路:
一开始想到的思路是cordic算法或者牛顿迭代法,测试后发现的问题是:对于32位数的输入,cordic算法会存在不能收敛的问题(c语言测试,16次迭代,0-4的输入可以精确的开方,更大的数可以通过归一化然后处理,一直到256都能正确工作,但测试到32位的时候发现数据小的部分已经算不对了,如果非要用cordic的话就得写很复杂的小数位数转换逻辑了,所以我最后还是放弃了)牛顿迭代法中要用到除法,但我不想调用除法器ip,最后采用了逐次逼近法(其实可以理解成逆向的牛顿迭代)
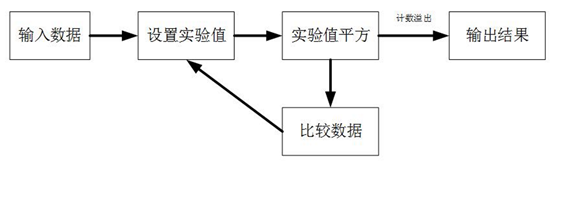
逐次逼近算法流程如图 所示,首先数据输入data[7:0],接着设置实验值D_z[3:0]和确定值D_q[3:0],然后按照从高往低的顺序,依次将每一位置1(如D_z[3]置1),再将实验值平方后与输入数据比较,若实验值的平方大于输入值(D_z^2 > data),则此位为0(D_q[3]为0),反之(D_z^2 ≤ data)此位为1(D_q[3]为1);以此迭代到最后一位。
可见,如果是n bit的数据,那么需要n/2次迭代,每次计算如果一个周期,则需要n/2个周期。
借鉴:https://blog.csdn.net/qq_39507748/article/details/115468883
代码实现:
module sqrt_u32 (
input clk,
input rst_n,
input vld_in,
input [31:0] x,
output reg vld_out,
output reg [16:0] y
);
parameter d_width = 32;
parameter q_width = 16;
reg [d_width-1:0] D [q_width:1];
reg [q_width-1:0] Q_z [q_width:1];
reg [q_width-1:0] Q_q [q_width:1];
reg valid_flag [q_width:1];
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
D[q_width] <= 0;
Q_z[q_width] <= 0;
Q_q[q_width] <= 0;
valid_flag[q_width] <= 0;
end
else if(vld_in)
begin
D[q_width] <= x;
Q_z[q_width] <= {1'b1,{(q_width-1){1'b0}}};
Q_q[q_width] <= 0;
valid_flag[q_width] <= 1;
end
else
begin
D[q_width] <= 0;
Q_z[q_width] <= 0;
Q_q[q_width] <= 0;
valid_flag[q_width] <= 0;
end
end
generate
genvar i;
for(i=q_width-1;i>=1;i=i-1)
begin:U
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
D[i] <= 0;
Q_z[i] <= 0;
Q_q[i] <= 0;
valid_flag[i] <= 0;
end
else if(valid_flag[i+1])
begin
if(Q_z[i+1]*Q_z[i+1] > D[i+1])
begin
Q_z[i] <= {Q_q[i+1][q_width-1:i],1'b1,{{i-1}{1'b0}}};
Q_q[i] <= Q_q[i+1];
end
else
begin
Q_z[i] <= {Q_z[i+1][q_width-1:i],1'b1,{{i-1}{1'b0}}};
Q_q[i] <= Q_z[i+1];
end
D[i] <= D[i+1];
valid_flag[i] <= 1;
end
else
begin
valid_flag[i] <= 0;
D[i] <= 0;
Q_q[i] <= 0;
Q_z[i] <= 0;
end
end
end
endgenerate
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
y <= 0;
vld_out <= 0;
end
else if(valid_flag[1])
begin
if(Q_z[1]*Q_z[1] > D[1])
begin
y <= Q_q[1];
vld_out <= 1;
end
else
begin
y <= {Q_q[1][q_width-1:1],Q_z[1][0]};
vld_out <= 1;
end
end
else
begin
y <= 0;
vld_out <= 0;
end
end
endmodule
testbench
module testbench ();
reg clk,rst_n,vld_in;
reg [31:0] x;
wire vld_out;
wire [15:0] y;
initial begin
clk <= 1'b0;
rst_n <= 1'b0;
vld_in <= 1'b0;
x <= 0;
#30
rst_n <= 1'b1;
vld_in <= 1'b1;
x <= 256;
#20
x <= 255;
#20
x <= 2147483648;
#20
x <= 4294967295;
end
always #10 clk <= ~clk;
sqrt_u32 u_sqrt_u32(
.clk(clk),
.rst_n(rst_n),
.vld_in(vld_in),
.x(x),
.vld_out(vld_out),
.y(y)
);
endmodule
仿真结果:
结果距离输入延迟了16个周期
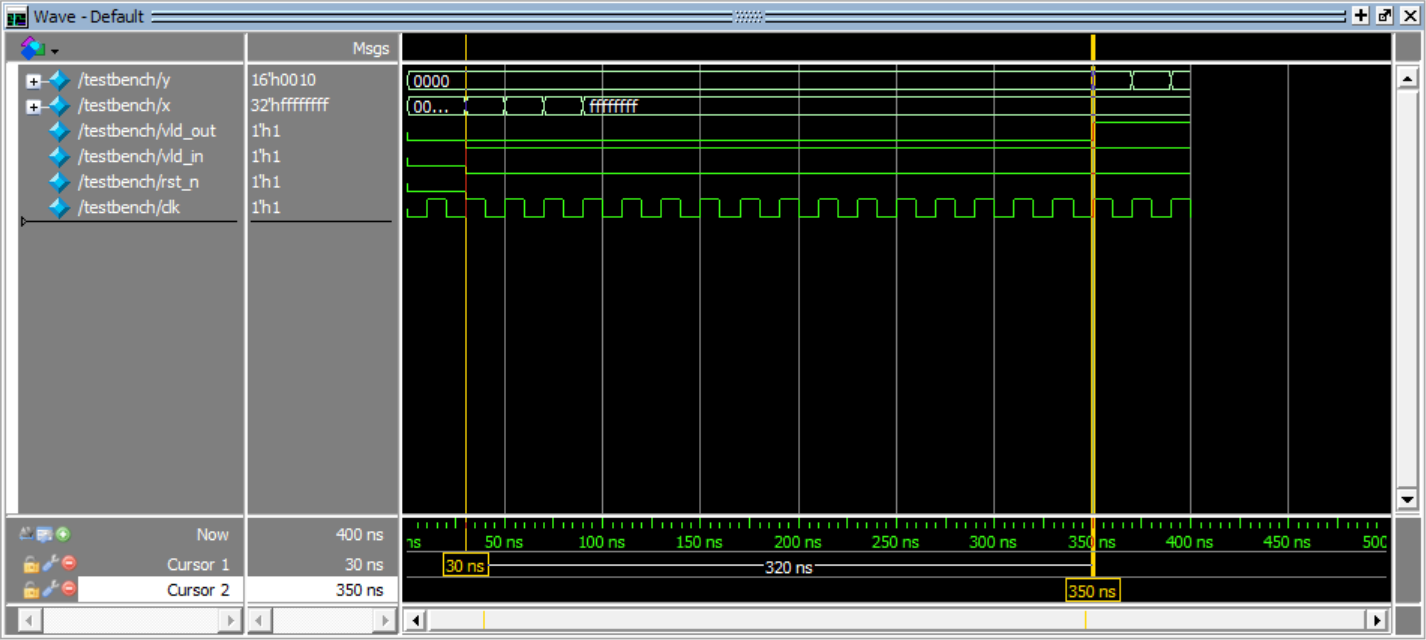
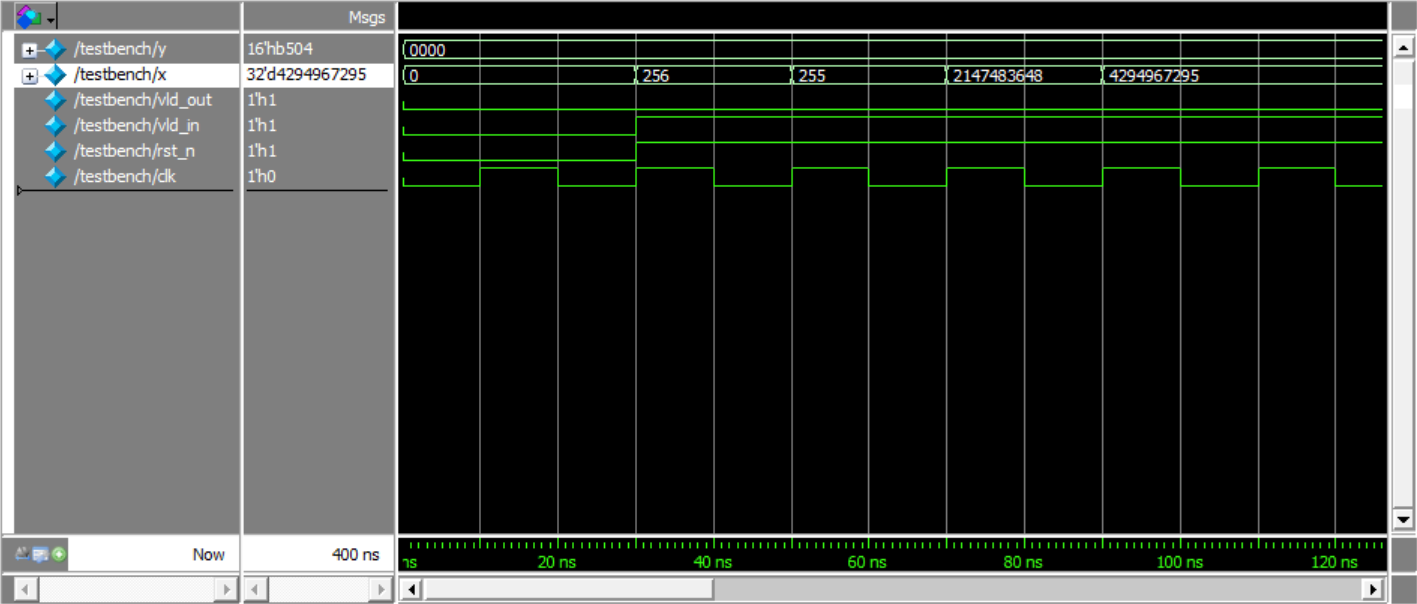
输出值
输入值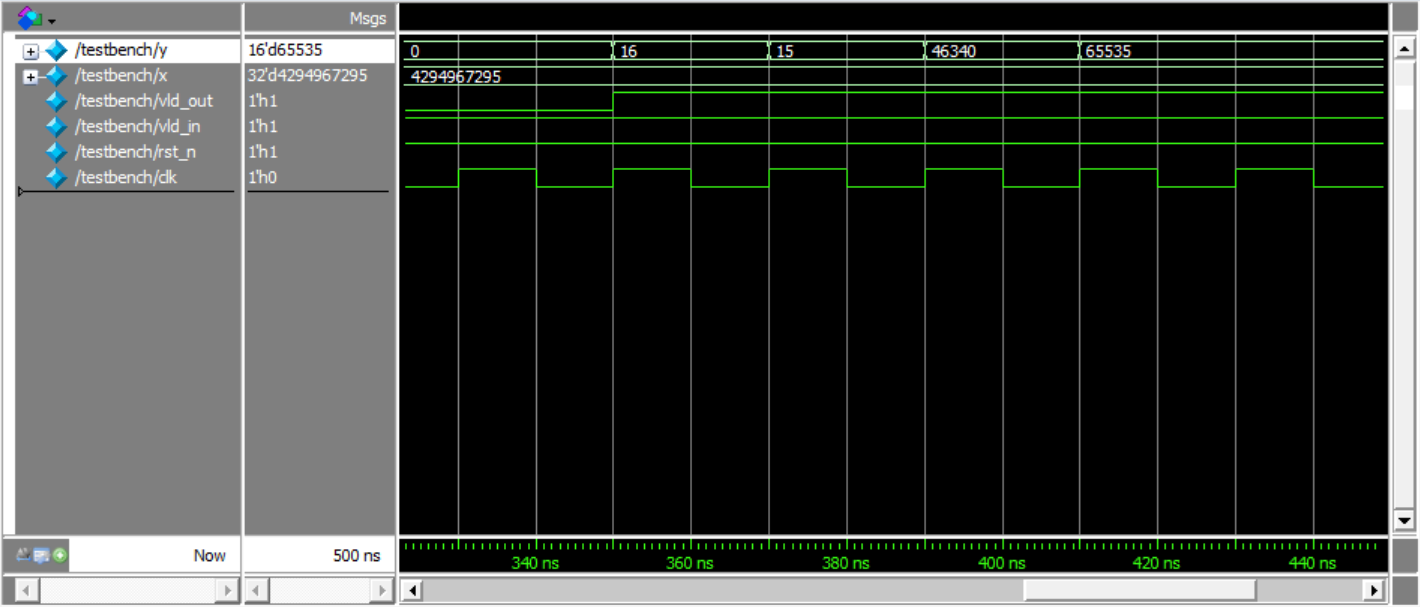
2.2数据排序
设计一个时序逻辑电路,对输入32个8位无符号整数从小到大进行排序(若存在多个数据值相等,则不分先后,见例子)。例如:
l 输入32个数据依次为:31, 29, 27, 25, 23, 21, 19, 17, 15, 13, 11, 9, 7, 5, 3, 1, 2, 2, 4, 4, 4, 4, 8, 16, 8, 16, 32, 32, 0, 10, 20, 30
l 输出32个数据依次为:0, 1, 2, 2, 3, 4, 4, 4, 4, 5, 7, 8, 8, 9, 10, 11, 13, 15, 16, 16, 17, 19, 20, 21, 23, 25, 27, 29, 30, 31, 32, 32
顶层模块名为sort_32_u8,输入输出功能定义:
| 名称 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| clk | I | 1 | 系统时钟 |
| rst_n | I | 1 | 系统异步复位,低电平有效 |
| vld_in | I | 1 | 输入数据有效指示 |
| din_0, din_1, … …, din_31 | I | 8 | 输入数据0,输入数据1,……, 输入数据31 |
| vld_out | O | 1 | 输出数据有效指示 |
| dout_0, dout_1, … …, dout_31 | O | 8 | 输出数据0,输出数据1,……, 输出数据31 |
注:din_0 ~ din_31共32个输入端口,dout_0~ dout_31共32个输出端口。输出数据dout_0 ~ dout_31的值从小到大排列。
设计要求:
l Verilog实现代码可综合,给出综合以及仿真结果。
l 逻辑资源和延迟需要做权衡,使得数据输入到结果输出延迟周期数尽量少。
设计思路:
原先的思路是使用双调排序,但双调排序只能排单调增和单调减的,题目里面的有重复数的情况调不了。
采用冒泡排序,导致排序时间非常长,消耗资源比较少,不符合题目要求的延迟尽可能小。本来想再写个全比较排序,但别的作业太多了,姑且算了,其实逻辑也挺简单的。
冒泡实际上就是两层循环反复比较,循环变量换成计数器就行了,使用了状态机进行控制。
参考:http://www.manongjc.com/detail/19-ezdqhndvpyqmqjx.html
代码实现:
module sort_32_u8 (
input clk,
input rst_n,
input vld_in,
input [7:0] din_0,din_1,din_2,din_3,din_4,din_5,din_6,din_7,din_8,din_9,din_10,din_11,din_12,din_13,din_14,din_15,din_16,din_17,din_18,din_19,din_20,din_21,din_22,din_23,din_24,din_25,din_26,din_27,din_28,din_29,din_30,din_31,
output reg vld_out,
output [7:0] dout_0,dout_1,dout_2,dout_3,dout_4,dout_5,dout_6,dout_7,dout_8,dout_9,dout_10,dout_11,dout_12,dout_13,dout_14,dout_15,dout_16,dout_17,dout_18,dout_19,dout_20,dout_21,dout_22,dout_23,dout_24,dout_25,dout_26,dout_27,dout_28,dout_29,dout_30,dout_31
);
parameter s_rst = 2'b00;
parameter s_load = 2'b01;
parameter s_sort = 2'b10;
parameter s_out = 2'b11;
reg [4:0] cnt_i,turn;
reg [7:0] data_fifo [31:0];
reg [1:0] cur_state,next_state;
reg reset,load_data,swap;
always @(posedge clk or negedge rst_n) begin
if(rst_n == 1'b0) begin
cur_state <= s_rst;
end
else begin
cur_state <= next_state;
end
end
always @(posedge clk) begin
if(reset == 1'b1) begin
data_fifo[0] <= 0;
data_fifo[1] <= 0;
data_fifo[2] <= 0;
data_fifo[3] <= 0;
data_fifo[4] <= 0;
data_fifo[5] <= 0;
data_fifo[6] <= 0;
data_fifo[7] <= 0;
data_fifo[8] <= 0;
data_fifo[9] <= 0;
data_fifo[10] <= 0;
data_fifo[11] <= 0;
data_fifo[12] <= 0;
data_fifo[13] <= 0;
data_fifo[14] <= 0;
data_fifo[15] <= 0;
data_fifo[16] <= 0;
data_fifo[17] <= 0;
data_fifo[18] <= 0;
data_fifo[19] <= 0;
data_fifo[20] <= 0;
data_fifo[21] <= 0;
data_fifo[22] <= 0;
data_fifo[23] <= 0;
data_fifo[24] <= 0;
data_fifo[25] <= 0;
data_fifo[26] <= 0;
data_fifo[27] <= 0;
data_fifo[28] <= 0;
data_fifo[29] <= 0;
data_fifo[30] <= 0;
data_fifo[31] <= 0;
turn <= 0;
cnt_i <= 0;
end
else if(load_data == 1'b1) begin
data_fifo[0] <= din_0;
data_fifo[1] <= din_1;
data_fifo[2] <= din_2;
data_fifo[3] <= din_3;
data_fifo[4] <= din_4;
data_fifo[5] <= din_5;
data_fifo[6] <= din_6;
data_fifo[7] <= din_7;
data_fifo[8] <= din_8;
data_fifo[9] <= din_9;
data_fifo[10] <= din_10;
data_fifo[11] <= din_11;
data_fifo[12] <= din_12;
data_fifo[13] <= din_13;
data_fifo[14] <= din_14;
data_fifo[15] <= din_15;
data_fifo[16] <= din_16;
data_fifo[17] <= din_17;
data_fifo[18] <= din_18;
data_fifo[19] <= din_19;
data_fifo[20] <= din_20;
data_fifo[21] <= din_21;
data_fifo[22] <= din_22;
data_fifo[23] <= din_23;
data_fifo[24] <= din_24;
data_fifo[25] <= din_25;
data_fifo[26] <= din_26;
data_fifo[27] <= din_27;
data_fifo[28] <= din_28;
data_fifo[29] <= din_29;
data_fifo[30] <= din_30;
data_fifo[31] <= din_31;
turn <= 31;
cnt_i <= 0;
end
else if(swap == 1'b1) begin
if(cnt_i < turn) begin
cnt_i <= cnt_i + 1;
if(data_fifo[cnt_i+1] < data_fifo[cnt_i]) begin
data_fifo[cnt_i+1] <= data_fifo[cnt_i];
data_fifo[cnt_i] <= data_fifo[cnt_i+1];
end
end
else begin
cnt_i <= 1;
turn <= turn - 1;
if(data_fifo[1] < data_fifo[0]) begin
data_fifo[1] <= data_fifo[0];
data_fifo[0] <= data_fifo[1];
end
end
end
end
always @(cnt_i,cur_state,turn,vld_in) begin
next_state <= s_rst;
case (cur_state)
s_rst : begin
reset <= 1'b1;
vld_out <= 1'b0;
next_state <= s_load;
end
s_load : begin
reset <= 1'b0;
if(vld_in == 1'b1) begin
load_data <= 1'b1;
vld_out <= 1'b0;
next_state <= s_sort;
end
else begin
next_state <= s_load;
end
end
s_sort : begin
swap <= 1'b1;
load_data <= 1'b0;
if(turn == 1 && cnt_i ==1 ) begin
next_state <= s_out;
vld_out <= 1'b1;
end
else begin
next_state <= s_sort;
end
end
s_out : begin
next_state <= s_load;
swap <= 1'b0;
end
default : begin
next_state <= s_rst;
end
endcase
end
assign dout_0 = data_fifo[0];
assign dout_1 = data_fifo[1];
assign dout_2 = data_fifo[2];
assign dout_3 = data_fifo[3];
assign dout_4 = data_fifo[4];
assign dout_5 = data_fifo[5];
assign dout_6 = data_fifo[6];
assign dout_7 = data_fifo[7];
assign dout_8 = data_fifo[8];
assign dout_9 = data_fifo[9];
assign dout_10 = data_fifo[10];
assign dout_11 = data_fifo[11];
assign dout_12 = data_fifo[12];
assign dout_13 = data_fifo[13];
assign dout_14 = data_fifo[14];
assign dout_15 = data_fifo[15];
assign dout_16 = data_fifo[16];
assign dout_17 = data_fifo[17];
assign dout_18 = data_fifo[18];
assign dout_19 = data_fifo[19];
assign dout_20 = data_fifo[20];
assign dout_21 = data_fifo[21];
assign dout_22 = data_fifo[22];
assign dout_23 = data_fifo[23];
assign dout_24 = data_fifo[24];
assign dout_25 = data_fifo[25];
assign dout_26 = data_fifo[26];
assign dout_27 = data_fifo[27];
assign dout_28 = data_fifo[28];
assign dout_29 = data_fifo[29];
assign dout_30 = data_fifo[30];
assign dout_31 = data_fifo[31];
endmodule
testbench
module testbench ();
reg clk,rst_n,vld_in;
reg [7:0] din_0,din_1,din_2,din_3,din_4,din_5,din_6,din_7,din_8,din_9,din_10,din_11,din_12,din_13,din_14,din_15,din_16,din_17,din_18,din_19,din_20,din_21,din_22,din_23,din_24,din_25,din_26,din_27,din_28,din_29,din_30,din_31;
wire vld_out;
wire [7:0] dout_0,dout_1,dout_2,dout_3,dout_4,dout_5,dout_6,dout_7,dout_8,dout_9,dout_10,dout_11,dout_12,dout_13,dout_14,dout_15,dout_16,dout_17,dout_18,dout_19,dout_20,dout_21,dout_22,dout_23,dout_24,dout_25,dout_26,dout_27,dout_28,dout_29,dout_30,dout_31;
initial begin
rst_n <= 1'b0;
clk <= 1'b0;
vld_in <= 1'b0;
din_0 <= 31;
din_1 <= 29;
din_2 <= 27;
din_3 <= 25;
din_4 <= 23;
din_5 <= 21;
din_6 <= 19;
din_7 <= 17;
din_8 <= 15;
din_9 <= 13;
din_10 <= 11;
din_11 <= 9;
din_12 <= 7;
din_13 <= 5;
din_14 <= 3;
din_15 <= 1;
din_16 <= 2;
din_17 <= 2;
din_18 <= 4;
din_19 <= 4;
din_20 <= 4;
din_21 <= 4;
din_22 <= 8;
din_23 <= 16;
din_24 <= 8;
din_25 <= 16;
din_26 <= 32;
din_27 <= 32;
din_28 <= 0;
din_29 <= 10;
din_30 <= 20;
din_31 <= 30;
#30
rst_n <= 1'b1;
vld_in <= 1'b1;
#20
vld_in <= 1'b0;
end
always #10 clk <= ~clk;
sort_32_u8 u_sort(
clk,
rst_n,
vld_in,
din_0,din_1,din_2,din_3,din_4,din_5,din_6,din_7,din_8,din_9,din_10,din_11,din_12,din_13,din_14,din_15,din_16,din_17,din_18,din_19,din_20,din_21,din_22,din_23,din_24,din_25,din_26,din_27,din_28,din_29,din_30,din_31,
vld_out,
dout_0,dout_1,dout_2,dout_3,dout_4,dout_5,dout_6,dout_7,dout_8,dout_9,dout_10,dout_11,dout_12,dout_13,dout_14,dout_15,dout_16,dout_17,dout_18,dout_19,dout_20,dout_21,dout_22,dout_23,dout_24,dout_25,dout_26,dout_27,dout_28,dout_29,dout_30,dout_31
);
endmodule
仿真结果:
花了将近500个周期排序(真的太慢了,我选算法的没注意到要求延迟周期尽可能少)
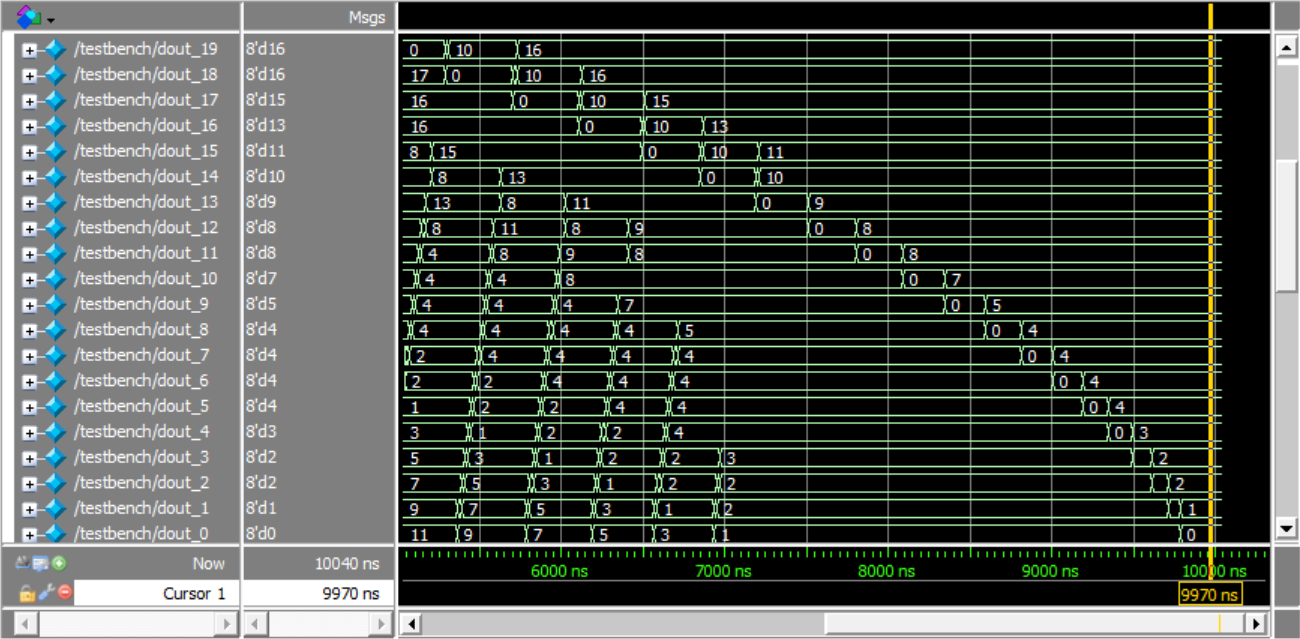
dout_15到dout_31
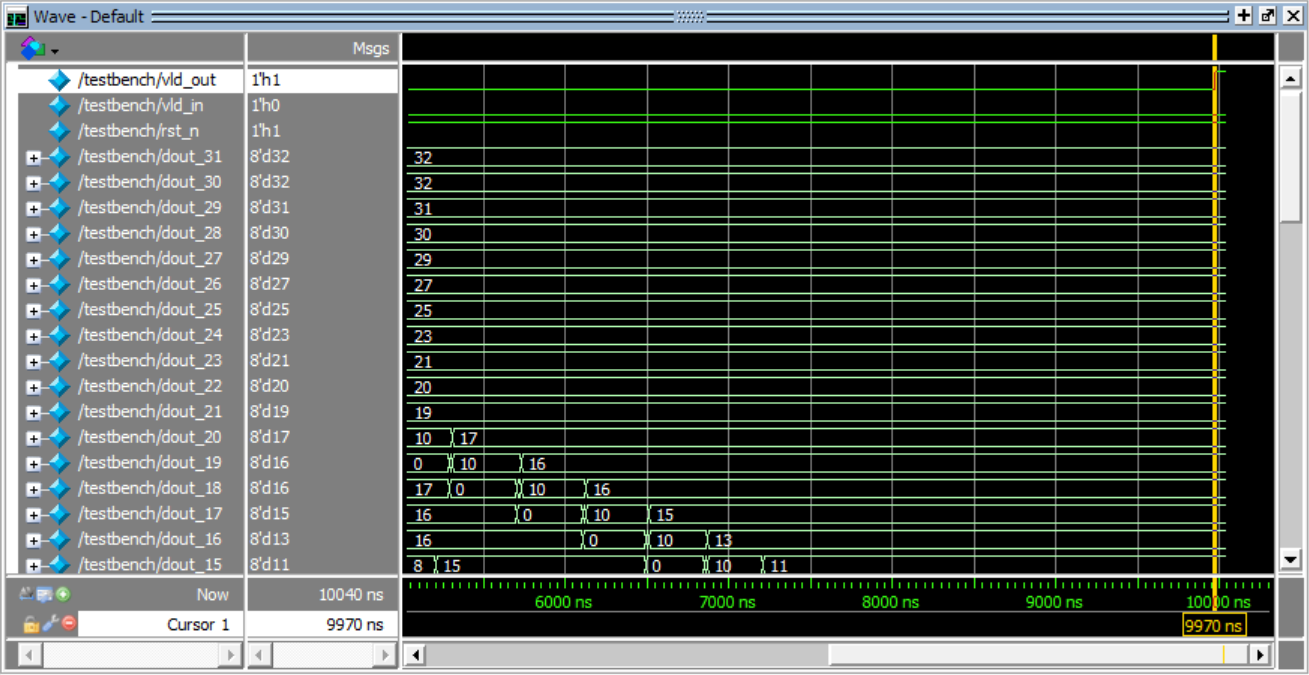
dout_0到dout_19
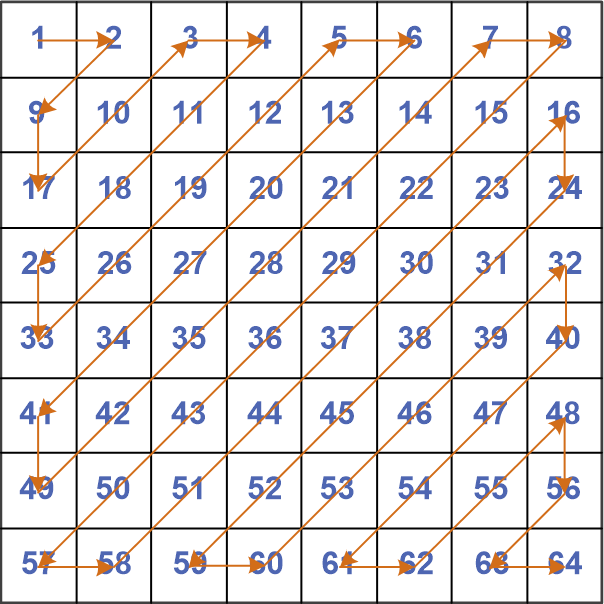
2.3 矩阵扫描
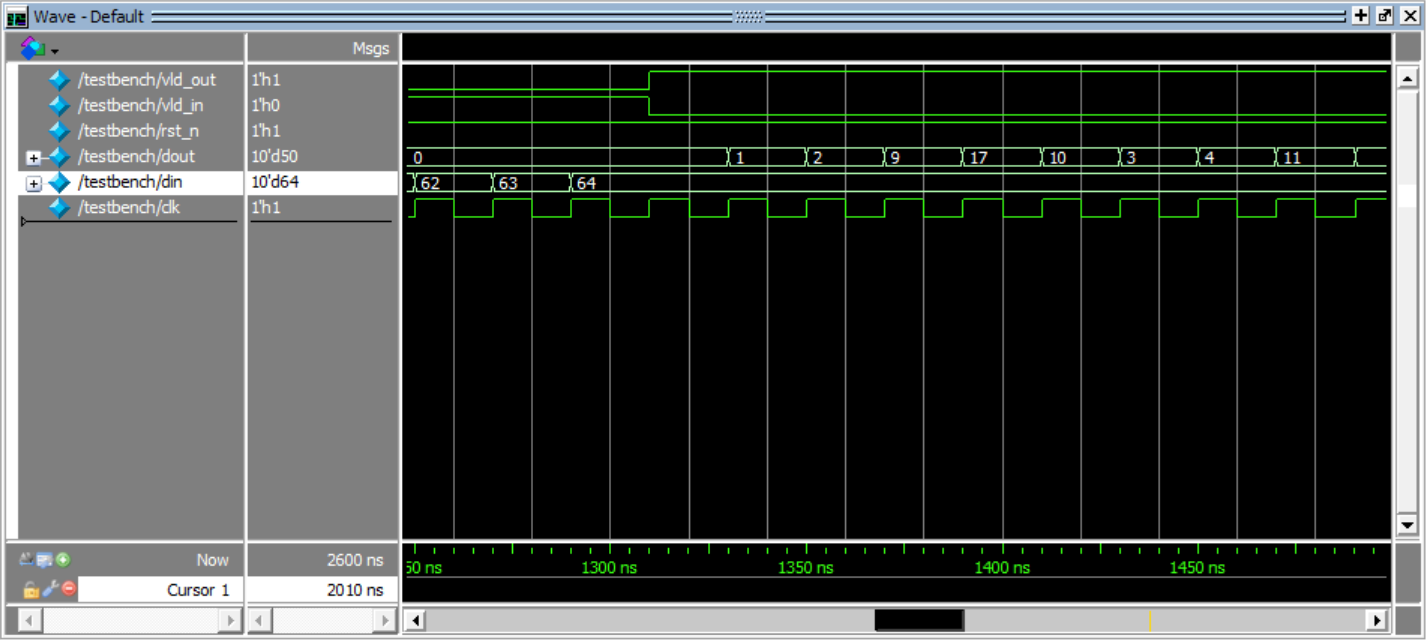
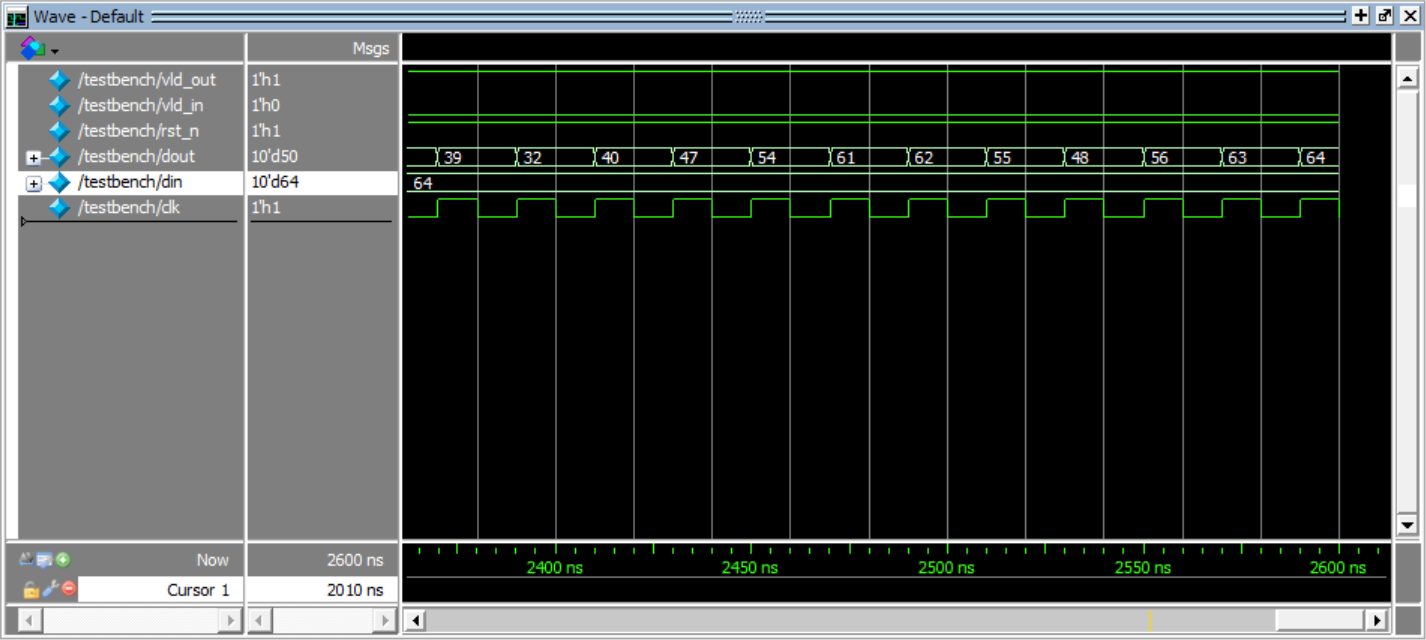
如图所示,ZigZag扫描就是将8x8的矩阵块按照箭头运动方向重新排列(从1开始到64结束):
设计一个时序逻辑电路,对输入64个整数(按照行优先方式构成8x8的矩阵块)按照ZigZag扫描方式依次输出。例如:
l 输入64个数据依次为:1, 2, 3, 4, ..., 61, 62, 63, 64
l 输出64个数据依次为:1, 2, 9, 17, 10, 3, ..., 62, 55, 48, 56, 63, 64
顶层模块名为mat_scan,输入输出功能定义:
| 名称 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| clk | I | 1 | 系统时钟 |
| rst_n | I | 1 | 系统异步复位,低电平有效 |
| vld_in | I | 1 | 输入数据有效指示 |
| din | I | 10 | 输入数据 |
| vld_out | O | 1 | 输出数据有效指示 |
| dout | O | 10 | 输出数据 |
注:每组输入数据连续64个周期输入,即vld_in连续64个时钟周期有效;每组输出数据连续64个周期输出,即vld_out连续64个时钟周期有效。
设计要求:
l Verilog实现代码可综合,给出综合以及仿真结果。
l 使用SRAM缓存输入数据,SRAM使用bit数尽量少。
l 从数据输入到结果输出延迟周期数尽量少。
设计思路:
用sram存64个数,输入的时候地址顺序增加,读出的时候用状态机实现zigzag要求的顺序对应的地址变化。(我查了一下zigzag自动扫描的c语言实现,感觉在verilog里面实现太困难,所以就这样暴力解决了)
代码实现:
module mat_scan (
input clk,
input rst_n,
input vld_in,
input [9:0] din,
output reg vld_out,
output [9:0] dout
);
reg cs_n, w_en, r_en;
reg [5:0] addr;
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
addr <= 6'b11_1111;
cs_n <= 1'b1;
w_en <= 1'b0;
r_en <= 1'b0;
vld_out <= 1'b0;
end
else if (vld_in) begin
w_en <= 1'b1;
cs_n <= 1'b0;
addr <= addr + 1'b1;
end
else begin
vld_out <= 1'b1;
r_en <= 1'b1;
case (addr)
6'b11_1111 : addr <= 6'b00_0000;
6'b00_0000 : addr <= 6'b00_0001;
6'b00_0001 : addr <= 6'b00_1000;
6'b00_1000 : addr <= 6'b01_0000;
6'b01_0000 : addr <= 6'b00_1001;
6'b00_1001 : addr <= 6'b00_0010;
6'b00_0010 : addr <= 6'b00_0011;
6'b00_0011 : addr <= 6'b00_1010;
6'b00_1010 : addr <= 6'b01_0001;
6'b01_0001 : addr <= 6'b01_1000;
6'b01_1000 : addr <= 6'b10_0000;
6'b10_0000 : addr <= 6'b01_1001;
6'b01_1001 : addr <= 6'b01_0010;
6'b01_0010 : addr <= 6'b00_1011;
6'b00_1011 : addr <= 6'b00_0100;
6'b00_0100 : addr <= 6'b00_0101;
6'b00_0101 : addr <= 6'b00_1100;
6'b00_1100 : addr <= 6'b01_0011;
6'b01_0011 : addr <= 6'b01_1010;
6'b01_1010 : addr <= 6'b10_0001;
6'b10_0001 : addr <= 6'b10_1000;
6'b10_1000 : addr <= 6'b11_0000;
6'b11_0000 : addr <= 6'b10_1001;
6'b10_1001 : addr <= 6'b10_0010;
6'b10_0010 : addr <= 6'b01_1011;
6'b01_1011 : addr <= 6'b01_0100;
6'b01_0100 : addr <= 6'b00_1101;
6'b00_1101 : addr <= 6'b00_0110;
6'b00_0110 : addr <= 6'b00_0111;
6'b00_0111 : addr <= 6'b00_1110;
6'b00_1110 : addr <= 6'b01_0101;
6'b01_0101 : addr <= 6'b01_1100;
6'b01_1100 : addr <= 6'b10_0011;
6'b10_0011 : addr <= 6'b10_1010;
6'b10_1010 : addr <= 6'b11_0001;
6'b11_0001 : addr <= 6'b11_1000;
6'b11_1000 : addr <= 6'b11_1001;
6'b11_1001 : addr <= 6'b11_0010;
6'b11_0010 : addr <= 6'b10_1011;
6'b10_1011 : addr <= 6'b10_0100;
6'b10_0100 : addr <= 6'b01_1101;
6'b01_1101 : addr <= 6'b01_0110;
6'b01_0110 : addr <= 6'b00_1111;
6'b00_1111 : addr <= 6'b01_0111;
6'b01_0111 : addr <= 6'b01_1110;
6'b01_1110 : addr <= 6'b10_0101;
6'b10_0101 : addr <= 6'b10_1100;
6'b10_1100 : addr <= 6'b11_0011;
6'b11_0011 : addr <= 6'b11_1010;
6'b11_1010 : addr <= 6'b11_1011;
6'b11_1011 : addr <= 6'b11_0100;
6'b11_0100 : addr <= 6'b10_1101;
6'b10_1101 : addr <= 6'b10_0110;
6'b10_0110 : addr <= 6'b01_1111;
6'b01_1111 : addr <= 6'b10_0111;
6'b10_0111 : addr <= 6'b10_1110;
6'b10_1110 : addr <= 6'b11_0101;
6'b11_0101 : addr <= 6'b11_1100;
6'b11_1100 : addr <= 6'b11_1101;
6'b11_1101 : addr <= 6'b11_0110;
6'b11_0110 : addr <= 6'b10_1111;
6'b10_1111 : addr <= 6'b11_0111;
6'b11_0111 : addr <= 6'b11_1110;
6'b11_1110 : addr <= 6'b11_1111;
endcase
end
end
sram #(
.ADDR_DEPTH(6),
.DATA_WIDTH(10),
.DATA_DEPTH(64)
) u_sram (
.clk(clk),
.rst_n(rst_n),
.cs_n(cs_n),
.w_en(w_en),
.r_en(r_en),
.addr(addr),
.din(din),
.dout(dout)
);
endmodule
sram
module sram #(
parameter ADDR_DEPTH = 4,
parameter DATA_WIDTH = 8,
parameter DATA_DEPTH = 16
)(
input clk,
input rst_n,
input cs_n,
input w_en,
input r_en,
input [ADDR_DEPTH-1:0] addr,
input [DATA_WIDTH-1:0] din,
output reg [DATA_WIDTH-1:0] dout
);
reg [DATA_WIDTH-1:0] mem [DATA_DEPTH-1:0];
integer i;
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
for (i = 0; i < DATA_DEPTH; i=i+1) begin
mem[i] <= (1'b0 << (DATA_WIDTH-1));
end
end
else if (w_en == 1'b1 && cs_n == 1'b0) begin
mem[addr] <= din;
end
end
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
dout <= (1'b0 << (DATA_WIDTH-1));
end
else if (r_en == 1'b1 && cs_n == 1'b0) begin
dout <= mem[addr];
end
else begin
dout <= dout;
end
end
endmodule
testbench
module testbench ();
reg clk, rst_n, vld_in;
reg [9:0] din;
wire vld_out;
wire [9:0] dout;
initial begin
clk <= 1'b0;
rst_n <= 1'b0;
din <= 10'b00_0000_0000;
vld_in <= 1'b0;
#20
rst_n <= 1'b1;
vld_in <= 1'b1;
#1290
vld_in <= 1'b0;
end
always #10 clk <= ~clk;
always @(posedge clk) begin
if (vld_in == 1'b1) begin
din <= din + 1'b1;
end
end
mat_scan u_mat_scan(
.clk(clk),
.rst_n(rst_n),
.vld_in(vld_in),
.din(din),
.vld_out(vld_out),
.dout(dout)
);
endmodule
仿真结果:
先顺序递增的将1-64放到SRAM里面去
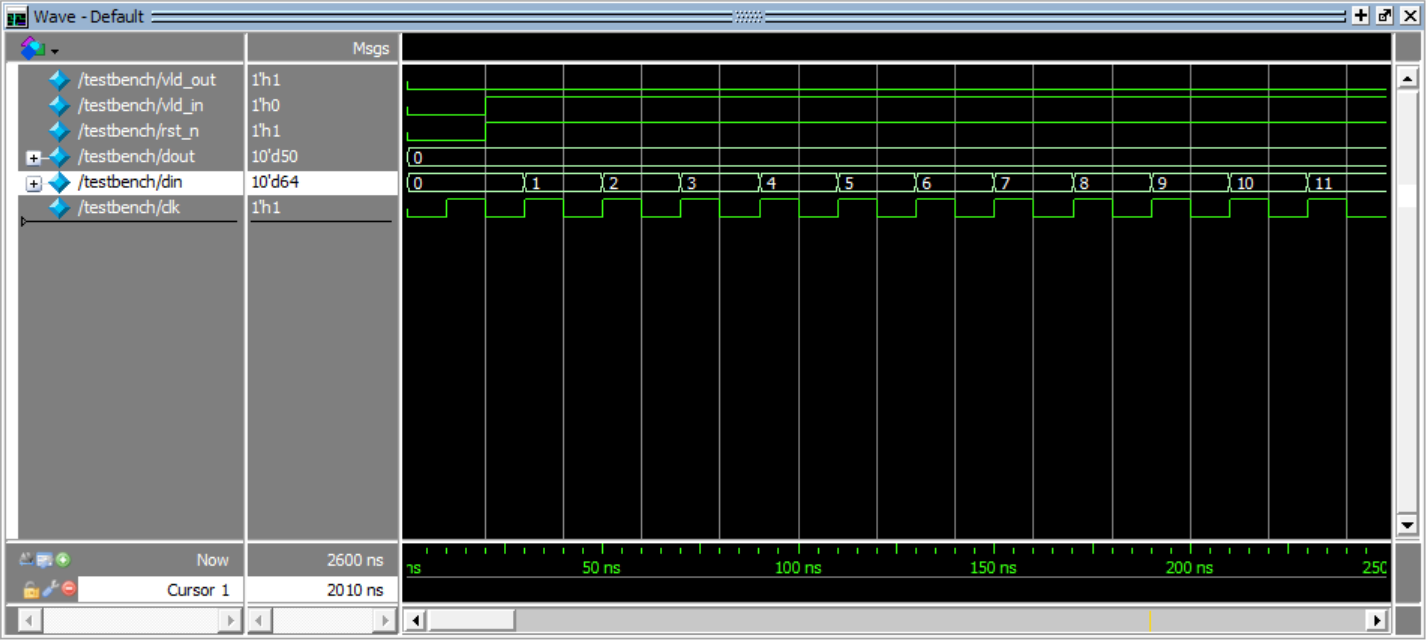
输出的地址用状态机实现,从而搞定zigzag扫描
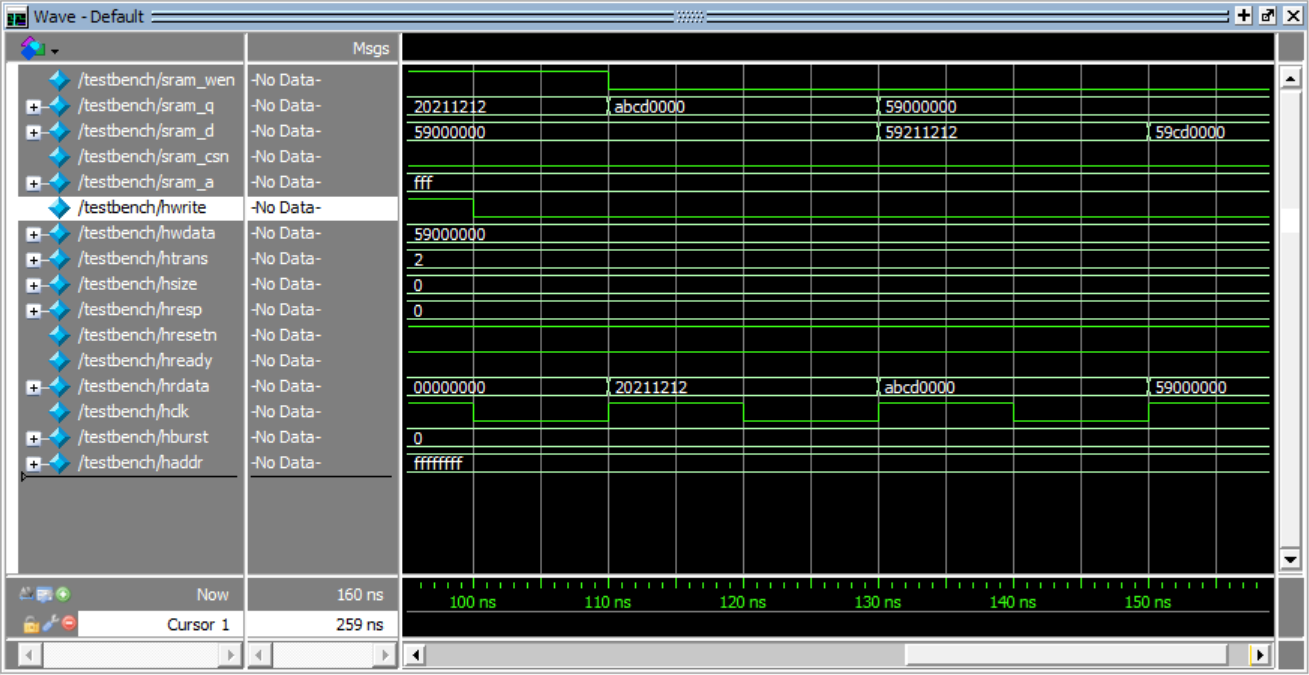
2.4 AHB-SRAM控制器
设计一个基于AHB从接口的单端口SRAM控制器,实现SRAM存储器与AHB总线的数据信息交换,将AHB总线上的读写操作转换成标准SRAM读写操作。
SRAM大小为4096x32-bit,AHB接口数据大小固定为32-bit,AHB接口地址范围为0x00000000 – 0x00003FFC。AHB接口能够实现单次或突发模式的数据读写操作。
顶层模块名为sram_ctr_ahb,输入输出功能定义:
| 名称 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| hclk | I | 1 | 系统时钟 |
| hresetn | I | 1 | 系统异步复位,低电平有效 |
| hwrite | I | 1 | 写有效 |
| htrans | I | 2 | 当前传输类型 |
| hsize | I | 3 | 当前传输大小 |
| haddr | I | 32 | 读写地址 |
| hburst | I | 3 | 当前突发类型 |
| hwdata | I | 32 | 写数据 |
| hready | O | 1 | 传输完成指示 |
| hresp | O | 2 | 传输响应 |
| hrdata | O | 32 | 读数据 |
| sram_csn | O | 1 | SRAM片选,低电平有效 |
| sram_wen | O | 1 | SRAM写使能,低电平有效 |
| sram_a | O | 12 | SRAM读写地址 |
| sram_d | O | 32 | SRAM写数据 |
| sram_q | I | 32 | SRAM读数据 |
注:仿真时SRAM时钟与hclk相同,SRAM可以用FPGA的单端口SRAM IP核仿真模型或者使用单端口SRAM行为级模型代替。
设计要求:
设计要求:
l Verilog实现代码可综合,给出综合以及仿真结果。
仿真时应给出各种典型情况下的数据读写接口信号波形。
设计思路:
作为实际设计并跑过完整ARM SoC的人,我觉得其实这里的输入激励应该由一个ARM CPU或者别的CPU来生成,但是没有这个条件就只能手写了。
在我做ARM SoC时,一个经验之谈是给ARM核写代码的时候(C语言),经常int_8/uint_8,int_16/uint_16或者int_32/int_32这些声明了位宽的变量
例如当时写的外设的寄存器表(基地址+偏移量)
所以很现实的就是存储器的hsize要支持8位,16位和32位(更大的我写的时候没用到)
一个我想多数人意识不到的问题是CPU访存是以字节(Byte)为单位的,即8bit。所以如果存储器的数据宽度和总线宽度对齐,是32位的话,就必须得考虑访存地址在haddr上左移的问题。如果直接是32位的访存,那么haddr就必须左移两位,16位的访存就得左移一位,8位不用移位。或者就是直接用8位宽度的存储器,如果要32位数的话就连续读4个数出来放到总线上,16位数就连续读2个数放到总线上。我用了前者(32位宽的存储器)
代码实现:
module sram_ctr_ahb (
input hclk,
input hresetn,
input hwrite,
input [1:0] htrans,
input [2:0] hsize,
input [31:0] haddr,
input [2:0] hburst,
input [31:0] hwdata,
output reg hready,
output reg [1:0] hresp,
output reg [31:0] hrdata,
output reg sram_csn,
output reg sram_wen,
output reg [11:0] sram_a,
output reg [31:0] sram_d,
input [31:0] sram_q
);
reg [31:0] hwdata_mask;
always @(posedge hclk or negedge hresetn) begin
if(hresetn == 1'b0) begin
hwdata_mask <= 0;
hready <= 1'b1;
hresp <= 2'b0;
hrdata <= 0;
sram_csn <= 1'b0;
sram_wen <= 1'b0;
sram_a <= 0;
sram_d <= 0;
end
else begin
sram_wen <= hwrite & htrans[1];
sram_a <= haddr[13:2];
end
end
always @(posedge hclk or negedge hresetn) begin
if(hresetn == 1'b0) begin
hrdata <= 0;
sram_d <= 0;
end
else begin
case (hsize[1:0])
2'b10: hwdata_mask <= 32'hFFFFFFFF; // Word write
2'b01: hwdata_mask <= (32'h0000FFFF << (16 * haddr[1])); // Halfword write
2'b00: hwdata_mask <= (32'h000000FF << (8 * haddr[1:0])); // Byte write
default: hwdata_mask <= 32'hFFFFFFFF;
endcase
sram_d <= (hwdata & hwdata_mask) | (hrdata & ~hwdata_mask);
hrdata <= sram_q;
end
end
endmodule
sram
module sram #(
parameter ADDR_DEPTH = 4,
parameter DATA_WIDTH = 8,
parameter DATA_DEPTH = 16
)(
input clk,
input rst_n,
input cs_n,
input w_en,
input [ADDR_DEPTH-1:0] addr,
input [DATA_WIDTH-1:0] din,
output reg [DATA_WIDTH-1:0] dout
);
reg [DATA_WIDTH-1:0] mem [DATA_DEPTH-1:0];
integer i;
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
for (i = 0; i < DATA_DEPTH; i=i+1) begin
mem[i] <= (1'b0 << (DATA_WIDTH-1));
end
end
else if (w_en == 1'b1 && cs_n == 1'b0) begin
mem[addr] <= din;
end
end
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
dout <= (1'b0 << (DATA_WIDTH-1));
end
else if (cs_n == 1'b0) begin
dout <= mem[addr];
end
end
endmodule
testbench
module testbench ();
reg hclk;
reg hresetn;
reg hwrite;
reg [1:0] htrans;
reg [2:0] hsize;
reg [31:0] haddr;
reg [2:0] hburst;
reg [31:0] hwdata;
wire hready;
wire [1:0] hresp;
wire [31:0] hrdata;
wire sram_csn;
wire sram_wen;
wire [11:0] sram_a;
wire [31:0] sram_d;
wire [31:0] sram_q;
initial begin
hclk <= 1'b0;
hresetn <= 1'b0;
hwrite <= 1'b0;
htrans <= 2'b00;
hsize <= 3'b000;
haddr <= 32'h00000000;
hburst <= 3'b000;
hwdata <= 32'h00000000;
#20
hresetn <= 1'b1;
hwrite <= 1'b1;
htrans <= 2'b10;
hsize <= 3'b010;
#20
haddr <= 32'hfffffffc;
hwdata <= 32'h20211212;
#20
hsize <= 3'b001;
haddr <= 32'hfffffffE;
hwdata <= 32'habcd0000;
#20
hsize <= 3'b000;
haddr <= 32'hffffffff;
hwdata <= 32'h59000000;
#20
hwrite <= 1'b0;
end
always #10 hclk <= ~hclk;
sram_ctr_ahb u_sram_ctrl_ahb(
.hclk(hclk),
.hresetn(hresetn),
.hwrite(hwrite),
.htrans(htrans),
.hsize(hsize),
.haddr(haddr),
.hburst(hburst),
.hwdata(hwdata),
.hready(hready),
.hresp(hresp),
.hrdata(hrdata),
.sram_csn(sram_csn),
.sram_wen(sram_wen),
.sram_a(sram_a),
.sram_d(sram_d),
.sram_q(sram_q)
);
sram #(
.ADDR_DEPTH(12),
.DATA_WIDTH(32),
.DATA_DEPTH(4096)
) u_sram (
.clk(hclk),
.rst_n(hresetn),
.cs_n(sram_csn),
.w_en(sram_wen),
.addr(sram_a),
.din(sram_d),
.dout(sram_q)
);
endmodule
仿真结果:
写三个数(hwdata)(位宽不同),地址分别是fffffffc,fffffffe,ffffffff
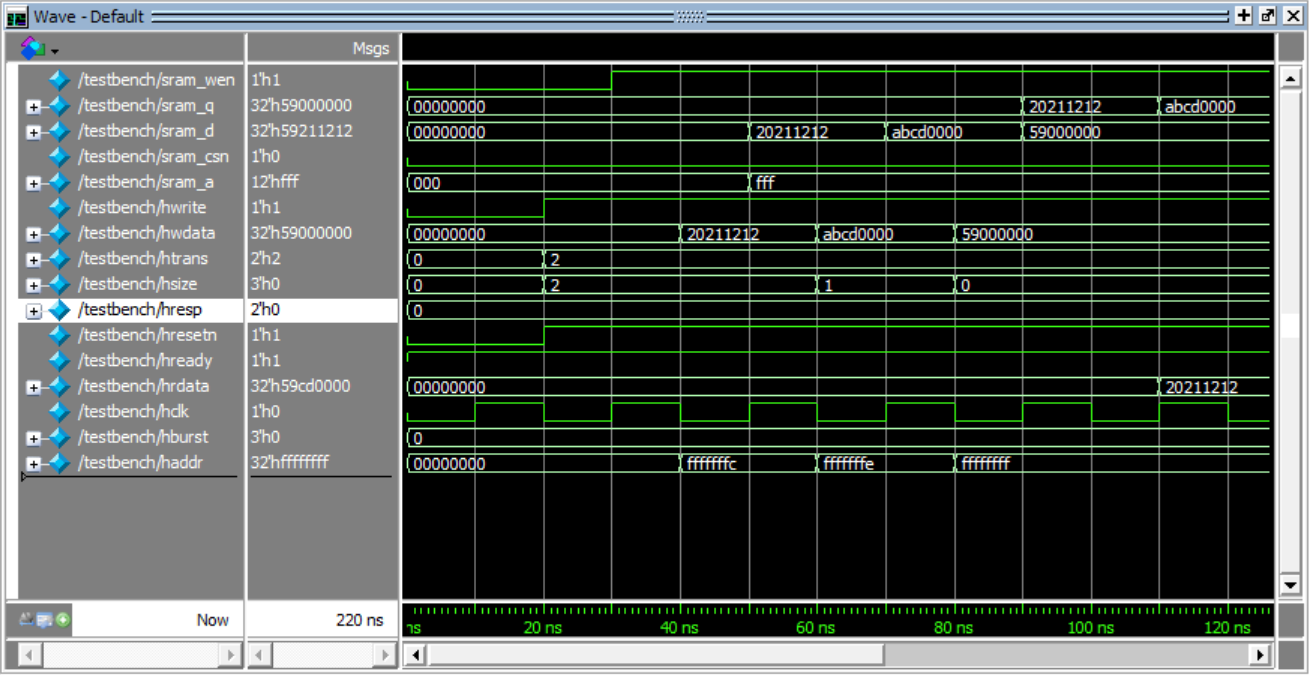
单口sram,sram_wen取消后开始读这三个数(hrdata)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号