语言模型发展综述
语言模型发展综述
摘要
语言模型(language model)是自然语言处理中非常基础且重要的问题。本文首先介绍了语言模型的定义及其应用场景,接着说明了语言模型的发展历史,本文将语言模型分为统计语言模型和神经网络语言模型两个大阶段,对各个阶段中出现的语言模型的特点、数学原理、对之前模型的改进,以及存在的缺点进行了详细的说明。最后,本文对目前先进的大规模预训练语言模型进行了评价,指出了其存在的根本性问题,并对语言模型的未来做出了展望。
问题定义
语言模型是定义在单词序列上的概率模型。通过将一个句子或者一段文字视作单词序列,可以运用概率论,统计学,信息论,机器学习等方法对语言进行建模,从而实现对单词序列的概率进行计算。
一般来说,概率更大的单词序列意味着其在语言交流中出现的可能性更大,也即其可能更加符合语言习惯和会话逻辑。
例如将原始句子
"美联储主席本 伯南克昨天告诉媒体7000亿美元的救助资金将借给上百家银行,保险公司和汽车公司。"
调整语序变为
"本 伯南克美联储主席昨天7000亿美元的救助资金告诉媒体将借给银行,保险公司和汽车公司上百家。"
其可读性就下降了很多,出现在日常对话中的概率就下降了。
而倘如进一步将其打乱为一个完全不通顺的句子
"联主美储席本 伯诉南将借天的救克告媒咋助资金70元亿00美给上百败百家银保行,汽车险公司公司和。"
则其概率会进一步下降。[1]
语言模型可以应用于分词,搜索引擎,输入法,机器翻译等任务中。例如,在分词时,我们可以认为其本质上就是求得一种分割方式,使得分词后得到的单词序列的语言模型概率最大化;搜索引擎和输入法通过应用语言模型预估用户要输入的单词,从而提高用户的使用体验;机器翻译任务可以通过语言模型来检查翻译后的句子的通顺程度,从中选最优秀的翻译结果等。
总而言之,语言模型是自然语言处理中非常重要的一块基石,其发展历史也象征了整个自然语言处理学科的发展历史,值得我们的深入研究和思考。
发展历史与主要方法分类
发展历史
语言模型的发展可以分为两个大的阶段,分别是使用n-gram语言模型的统计语言模型阶段,和后来居上的神经网络语言模型阶段。神经网络语言模型又可以分为早期的以设计神经网络结构为主的阶段和目前的通过巨量语料进行训练,再通过微调进行部署的预训练语言模型阶段。
统计语言模型
顾名思义,统计语言模型是运用统计学方法对语言进行建模而得到的模型。数学家马尔科夫(Andrey Markov)以马尔科夫链的形式对单词序列进行了建模[2]。
如前文所说,一个语言模型通常构建为句子\(s\)的概率分布 \(p(s)\) ,这里 \(p(s)\)试图反映的是单词序列 \(s\) 作为一个句子出现的频率。
假设\(s\)由\(m\)个基元(可以为字、词或短语等)构成,为了方便以下均默认为"词",即\(s=w_1,w_2,...,w_n\)。则其概率公式可以表示为
上式中,\(p(w_i|w_1,...,w_{i-1})\)表示第\(i(1\leqslant i\leqslant m)\)个词的概率由前\(i-1\)个词来决定,通过将每个词的概率连乘,就能计算出 \(p(s)\)。但这一理论在实际应用中存在一巨大的问题,假设一门语言的词汇量为\(V\),根据句子的长度\(m\),其能组合出的句子总数为\(V^m\),这意味着随着句子长度呈几何级数增长的数据量。一门语言的词汇量本就很大,当句子长度较长时,其数据量很显然不是当前的计算机能够处理的。
为了解决参数呈指数级增长的问题,n-gram模型引入了马尔科夫假设:当前词的出现概率仅与前\(n-1\)个词有关。基于此,单词序列\(s\)概率的计算公式可近似如下:
当n取1、2、3时,n-gram模型又分别可称为unigram、bigram、trigram。在n-gram模型中,模型参数为 \(V^n\),n越大,模型在理论上越准确,但也越复杂,需要的计算量和训练语料数据量也就越大,因此\(n>4\)的情况非常少。
通过上面的分析,我们知道通过n-gram模型计算句子概率最主要的就是求得参数\(p(w_i|w_{i-n+1},...,w_{i-1})\)。在给定了训练语料的情况下,我们可以通过最大似然估计的方法对参数进行求取。
即训练语料中,给定\(w_{i-n+1},...,w_{i-1}\)的条件下,\(w_i\)出现的相对频度。
使用最大似然估计的方法计算参数会由于数据稀疏导致零概率问题,即部分少见的单词序列在训练语料中没有出现,导致通过最大似然估计方法求得的参数为0,进而导致整个句子的概率直接变为0。
为解决这一问题,引入了数据平滑(data smoothing)的方法,其基本思想为调整最大似然估计的概率值,使零概率增值,使非零概率下调,“劫富济贫”,消除零概率,改进模型的整体正确率。具体方法有Good-Turing法,Katz后退法,绝对减值法,线性减值法等。
在优化n-gram统计语言模型时,以困惑度作为其评价指标。香农(Claude Shannon)发表了奠基性论文《通信的数学理论》,开创了信息论领域。在论文中,香农提出了熵的概念,研究了n元模型的性质[3]。我们可以利用交叉熵刻画一个统计语言模型在测试集上的表现。
对于一个平滑后的n-gram模型,其概率为\(p(w_i|w_{i-n+1},...,w_{i-1})\),通过其可以计算整个句子的概率\(p(s)=\prod_{i=1}^m p(w_i|w_{i-n+1},...,w_{i-1})\)。假设测试语料\(T\)由\(l_T\)个句子构成\((t_1,t_2,...,t_{l_t})\),则可以求得整个测试集的概率(测试集中每个句子的概率的连乘)\(P(T)=\prod_{i=1}^{l_t}p(t_i)\)。
从而概率统计模型对于测试语料的交叉熵为:
其中,\(W_T\)是测试文本 \(T\) 的词数。模型 \(p\) 的困惑度 \(PP_p(T)\) 定义为:\(PP_p(T)=2^{H_p(T)}\)
对于交叉熵,可以将其理解为统计语言模型所学习到的统计概率分布与测试集中的实际概率分布之间的差别程度,交叉熵越大,意味着统计概率分布和实际概率分布的差别越大,即统计语言模型的表现越差。困惑度与交叉熵成正相关,因此统计语言模型的优化目标就是尽量减小困惑度。
至此,统计语言学方法已经大致介绍完毕,其通过简洁的形式对语言进行了建模,得到了n-gram模型,并被广泛的应用到了如搜索引擎、输入法等各种场景中,取得了良好的成效。但其存在两大根本性的问题:
1,过强的独立性假设,每个单词只与少数的前n个的单词具有关联,不具备长距离捕捉信息的能力
2,在训练语言模型时所采用的语料往往来自多种不同的领域,这些综合性语料难以反映不同领域之间在语言使用规律上的差异,而语言模型恰恰对于训练文本的类型、主题和风格等都十分敏感
尽管可以通过语言模型的自适应方法,如基于缓存的语言模型 (cache-based LM),基于混合方法的语言模型,基于最大熵的语言模型等加以改善,但始终无法彻底解决上述的两大问题。
统计语言模型发展的后期,其根本问题无法得到解决,各种方法带来的提升越来越少,在这样的困境下,神经网络语言模型为语言模型的发展注入了新的动力。
神经网络语言模型
前馈神经网络语言模型
最早的前馈神经网络语言模型——NNLM(Neural Network Language Model)在Bengio于2003年发表的《A Neural Probabilistic Language Model》中被提出[4]。
其对于统计语言模型的颠覆之处在于
1,将词以抽象符号的表示方法转变为了语义空间下的向量表示
2,以向量表示的单词序列作为神经网络的输入,求取\(p(w_i|w_{i-n+1},...,w_{i-1})\)
统计语言模型的视角下,每个词都是独立的抽象符号,忽略了词之间的语义关联性,也带来了数据稀疏的问题。将词汇表\(V\)中所有词按照出现的顺序排序,每个词语将对应唯一的下标,这样每个词都可以视作为大小为\(|V|\)的one-hot表示的向量,任意两个one-hot向量之间的向量内积都为0,都是完全正交的。
然而在实际的语言中,存在很多意思相近或者有着语义关联的单词,例如"枯燥"和"无聊","这个"和"那个"等。我们希望在低维、稠密的连续实数空间中对这些词进行表示,语言关联度高的单词在空间中具有更近的几何距离,更大的向量内积,而语义关联性小的单词在空间中几何距离远,向量内积小。
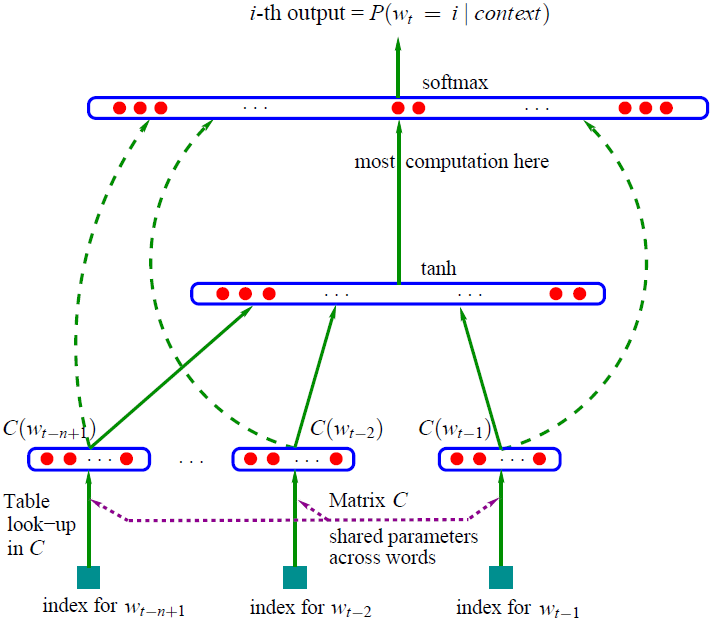
在神经网络的输入层,将大小为\(|V|\times m\)的look-up table参数矩阵\(C\)与one-hot向量表示的词汇表\(V\)中的单词\(w_i\)相乘,得到该词的稠密向量表示\(C(w_i)\),神经网络的输入向量\(x=(C(w_{t-n+1}),...,C(w_{t-2}),C(w_{t-1}))\)为将输入序列对应的所有向量进行拼接。
在神经网络的隐藏层,设置\(h\)个隐藏单元,权重矩阵\(H \in \mathbb{R}^{h\times(n-1)m}\),偏置向量\(d \in \mathbb{R}^h\),采用tanh作为激活函数。
在神经网络的输出层,将隐藏层到输出层的运算结果(权重矩阵\(U \in \mathbb{R}^{|V|\times h}\),偏置向量\(b \in \mathbb{R}^{|V|}\))和从输入层直接到输出层的运算结果(权重矩阵\(W \in \mathbb{R}^{|V|\times(n-1)m}\))相加,得到:
再将\(y\)通过softmax函数,便得到了以概率表示的\(p(w_i|w_{i-n+1},...,w_{i-1})\)
前馈神经网络语言模型通过用实数向量表示一个单词或单词的组合,提高了语言表示的效率、泛化性和可扩展性。在使用词向量的基础上,通过神经网络来表示语言模型,大幅减少了模型的参数。尽管其仍然受到n-gram模型的局限,使用定长的句子作为输入,但却为语言模型带来了彻底的变革,并启发了大量的后续研究。此外将单词转换为稠密向量的word embedding技术成为了后续神经网络语言模型的基础。
循环神经网络语言模型
循环神经网络语言模型在Tomas Mikolov于2010年发表的《Recurrent neural network based language model》中被提出[5],通过运用循环神经网络彻底解决了语言模型不能捕捉长距离信息的问题。
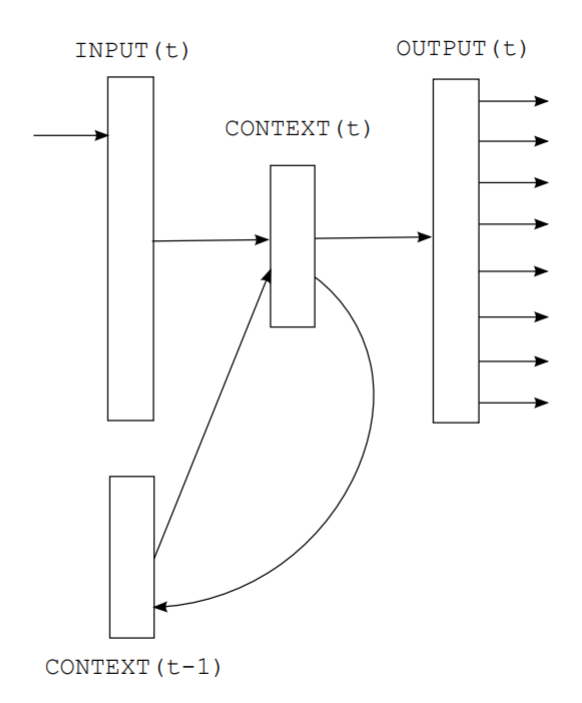
在循环神经网络的输入层,输入向量\(x(t)\)由当前输入词向量\(w(t)\)和上一隐藏层向量\(s(t-1)\)相加得到。
在循环神经网络的隐藏层,权重矩阵\(U\),采用sigmoid作为激活函数。
在循环神经网络的输出层,权重矩阵\(V\),采用softmax作为激活函数,得到\(p(w_i|w_{i-n+1},...,w_{i-1})\)
循环神经网络的当前隐藏层反复捕捉当前输入的词向量和上一隐藏层(包含了前文中所有词向量的信息),从而实现任意长度的句子的全句信息捕捉。
但循环神经网络存在参数经过多次传递后,易发生梯度消失或爆炸的问题,且其平等的对待所有的输入单词,但是在实际的语言中,不同的单词对于句子的重要性其实是不一样的。
后续提出的长短期记忆(Long short-term memory,LSTM)神经网络能够通过某种策略有选择地保留或者遗忘前文的信息,在没有改变循环神经网络基本结构的基础上,很好的解决了循环升级网络的问题,同时也保留了其可以捕捉全文信息的优点。
Qian Chen等人在2016年发表的《Enhanced LSTM for Natural Language Inference》将LSTM应用于自然语言处理[6]。相比循环神经网络,LSTM神经网络引入了遗忘门(forget gate),并且通过\(C_t\)(Cell State)而非隐藏层\(h_t\)来维护从句子中学习的记忆。
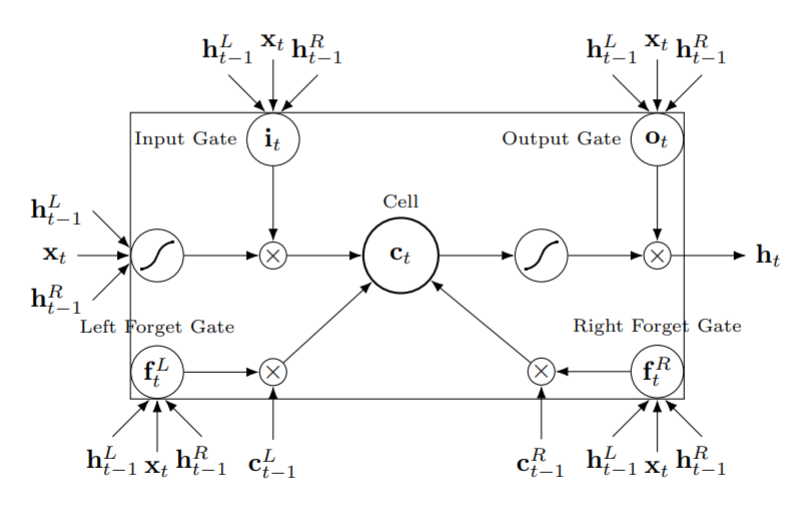
尽管循环神经网络语言模型(以及LSTM)具备了捕捉全句信息的能力,但由于其串行的结构(下一次输出的计算依赖于上一次输出),导致训练速度非常的慢,对于庞大语料库,训练循环神经网络语言模型所需要的时间过于漫长,而无法应用大规模语料库又会导致模型对于训练文本的敏感。
自我注意机制语言模型
谷歌团队在2017年发表的《Attention Is All You Need》中提出Transformer,在自然语言处理问题中引入了自注意力(Self-Attention)机制,在保证模型全文捕捉能力的同时,改变了循环神经网络语言模型的串行结构,使得模型可以并行化地在大规模语料库上训练[7]。
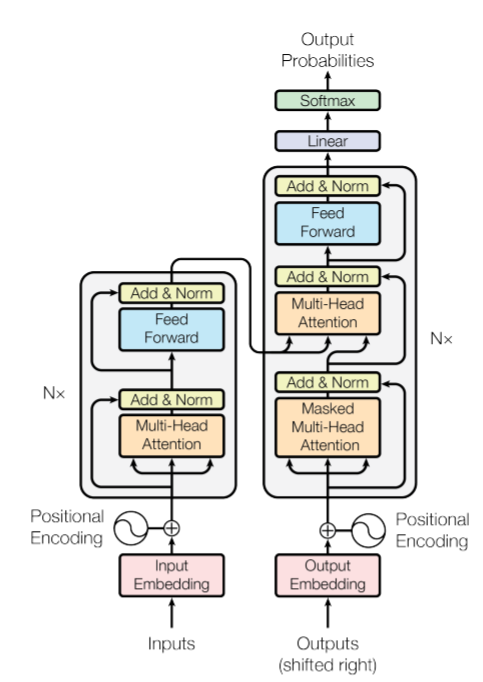
Transformer应用于翻译任务时,有Encoder和Decoder两个部分。其Encoder和Decoder部分实际上都可以单独提取出来应用于语言模型。
Transformer的输入层将word embedding后的词向量和单词在句子中的位置进行position embedding后的位置向量相加,得到输入向量序列\(X\),通过position embedding,transfomer可以获得单词的位置信息。
Transformer的自注意力机制非常关键,首先通过线性变换矩阵\(W_Q\),\(W_K\),\(W_V\)与输入向量序列\(X\)相乘,得到查询向量序列\(Q\)、键向量序列\(K\)和值向量序列\(V\),通过自注意力机制得到输出值
其中\(d_k\)表示查询向量的维度。
为何叫做 Self-Attention机制呢?我们不妨先忽视线性变换矩阵对于输入向量序列\(X=[x_1,...,x_{j-1},x_{j}]\)的影响。则 Self-Attention机制可以表示为
其中\(q\)为输入向量\(x_j\),\(K=V=X\)
从上面的式子中可以看出,Self-Attention计算的结果为权重乘输入的累加的形式——类似于卷积神经网络中的卷积运算。而权重的来源是当前词和整个序列的向量内积,而我们知道在稠密向量空间中,向量内积表征了词之间的关联度,关联度高的词之间会具有更大内积,从而赋予输入值更大的权重,而无关的词则被赋予小的权重。
Multi-Head Attention 是由多个 Self-Attention 组合形成,通过将多个 Self-Attention计算得到的矩阵拼接,再进行全连接,得到 Multi-Head Attention 的输出。
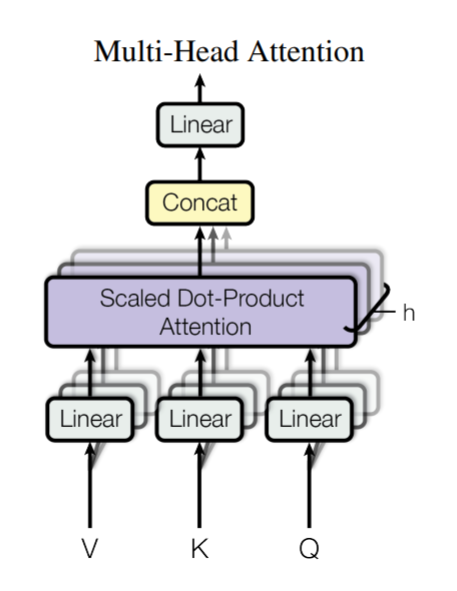
Transformer的诞生使得全句信息的捕捉和大规模语料库上的训练两大问题都得到了解决,也使得语言模型进入了一个全新的阶段。
预训练语言模型
随着神经网络语言模型的发展,语言模型的准确度得到了持续的提升。但构成神经网络语言模型基石的word embedding,由于其通过look-up table矩阵计算得到的向量表示是唯一的,导致难以区分一词多义的问题。
预训练语言模型使用词向量在神经网络模型中的隐藏层向量作为word embedding,从而对不同上下文环境下的词在编码上能够实现区分。
ELMo
ELMo(Embeddings from Language Models)在AllenAI于2018年发表的《Deep contextualized word representations》中被提出[8]。
ELMo使用双向LSTM模型对上下文信息进行捕捉,使用双向语言模型作为优化目标。通过在语料库上的训练得到参数后,使用多个网络前向层和后向层隐藏层拼接后的向量加权和作为输入词向量的embedding。
这个word embedding的结果可以作为下游任务的词向量的输入。
ELMo创造性的解决了一词在不同上下文下如何实现区分的问题,但由于其采用了较浅的两层双向LSTM,这使得其难以学习文本数据的所有语言规律,因此其潜力是有限的。此外,双向LSTM并不是捕获长距离依赖性的最佳方法,由于其串行的结构,会受到梯度消失的影响,且无法并行计算。最后,预训练模型的能力还未得到充分的挖掘,因为ELMo仅用于获取隐层表示,并作为额外的特征应用到下游任务里。也就是说,下游监督任务中的微调模型是从头开始学习的,并且不共享预训练模型的参数。
GPT系列
GPT(Generative Pre-Training)在OpenAI于2018年发表的《Improving Language Understanding by Generative Pre-Training》中被提出[9]。
模型主体采用了Transformer的Decoder(去除了中间的一个sub-layer:Multi-Head Attention),训练目标是单向语言模型,使得其只有捕捉上文信息的能力。
其思想与ELMo的区别是,不再使用隐藏层加权和的结果作为下游模型的word embedding,而是直接通过在预训练模型的输入输出上增加任务导向的小型网络结构,通过小参数训练和预训练模型参数的微调(fine-tuning)搭建下游任务。
2019年的GPT-2在GPT的基础上,扩大了了训练数据的数量,同时开始尝试将任务建模为\(p(output|input,task)\)的形式,从而将多种自然语言处理任务统一到语言模型的形式下。2020年的GPT-3则在GPT-2的基础上大大提升了训练数据的数量和模型规模。
BERT
BERT(Bidirectional Encoder Representations from Transformers)在Google于2018年发表的《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中被提出[10]。
其模型主体采用了Transformer的Encoder,与GPT不同的是BERT能够双向的采集句子的信息,从而获得更强的信息获取能力,其与GPT系列模型一样,采用微调(fine-tuning)方式搭建下游任务,为了避免前后文信息穿越的问题,其训练目标并非双向语言模型,而是采用了掩码语言模型。
BERT训练中的掩码(MASK)机制仍存在一些缺点。首先其仅采用静态MASK机制、随机MASK单个词;此外,其预训练和微调之间存在着严重差异,在预训练过程中大量使用的MASK几乎不会出现在下游任务的微调过程中;最后,BERT假设输入序列中遮盖的词汇之间互相独立,但实际上这些被遮盖的词很可能是存在相互依赖的。
后续的RoBERTa,SpanBERT,ERNIE等模型针对BERT的MASK机制进行了改进。
未来方向
语言模型的发展脉络令人印象深刻,当历史推动主流范式从统计语言模型转向神经网络语言模型时,其过程既令人惊愕却又是如此自然,使得我在学习课程时深深的为之震撼。如今的超大规模预训练语言模型已经能够用于生成以假乱真的文章、诗词,机器译文也非常流畅,我们不由的期待将更多的自然语言处理的任务通过超大规模预训练模型进行统合(实际上GPT系列正有此意),同时通过进一步扩大模型和数据量从而实现性能的进一步提升,一切都看上去非常promising。
但歌舞升平的同时,我们也得看到神经网络方法的一些根源性的问题:可解释性差,我们无法像传统方法那样追究每一个结构,每一个步骤的具体数学原理,这导致其难以应用于一些要求高可靠性的系统,并且难以debug;极度依赖于数据集,质量差的数据集对神经网络的性能会产生严重的影响,甚至导致其彻底无法工作,而数据量不足同样对神经网络有着致命的影响;有知识而无智慧,尽管学习了海量的信息,但仍然缺乏架构化的知识,甚至缺乏常识。
当前知识图谱的研究受到了很多人的关注,人们希望将结构化的知识图谱和数据驱动的深度神经网络相结合,从而使得新一代的人工智能能够具备强大的自我思考和推理能力。
也许神经网络也会像传统方法那样,有朝一日来到它的尽头,而届时另一种全新的方法将会引领学科步入下一个新的纪元。
引用文献
本文章主体结构借鉴了
https://zhuanlan.zhihu.com/p/90741508
部分例子和观点借鉴了
https://zhuanlan.zhihu.com/p/257031088
https://zhuanlan.zhihu.com/p/43453548
感谢以上作者
[1] 吴军.数学之美[M].北京:人民邮电出版社,2012
[2] Hayes B. First Links in the Markov Chain[J].American Scientist, 2013, 101(2):92.
[3] Shannon C. A Mathematical Theory of Communication[J].The Bell System Technical Journal, 1948, 27(7): 379-423.
[4] Operationnelle, Departement & Bengio, Y. & Ducharme, R & Vincent, Pascal & Mathematiques, Centre. (2001). A Neural Probabilistic Language Model.
[5] Mikolov, Tomas & Karafiát, Martin & Burget, Lukas & Cernocký, Jan & Khudanpur, Sanjeev. (2010). Recurrent neural network based language model. Proceedings of the 11th Annual Conference of the International Speech Communication Association, INTERSPEECH 2010. 2. 1045-1048.
[6] Chen, Qian, Xiao-Dan Zhu, Zhenhua Ling, Si Wei, Hui Jiang and Diana Inkpen. “Enhanced LSTM for Natural Language Inference.” ACL (2017).
[7] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS'17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010.
[8] Peters, M. E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K. & Zettlemoyer, L. (2018), 'Deep contextualized word representations' , cite arxiv:1802.05365Comment: NAACL 2018. Originally posted to openreview 27 Oct 2017. v2 updated for NAACL camera ready .
[9] Radford, Alec and Karthik Narasimhan. “Improving Language Understanding by Generative Pre-Training.” (2018).
[10] Devlin, Jacob & Chang, Ming-Wei & Lee, Kenton & Toutanova, Kristina. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号