Hardnet论文阅读
1.主要思路
本文主要是提出了新的 loss 用于特征 metric 的学习。提出的 loss 可以最大化一个 training batch 中最近的正负样本之间的距离,而且对浅层以及深层的 CNN 网络都有作用。本文基于之前的 L2-Net 工作,把 loss 更换成本文提出的 loss,这里叫做 HardNet。
2.基本流程
采样和 loss
本文的目标函数模仿 SIFT 的匹配规则。采样过程如下图所示:
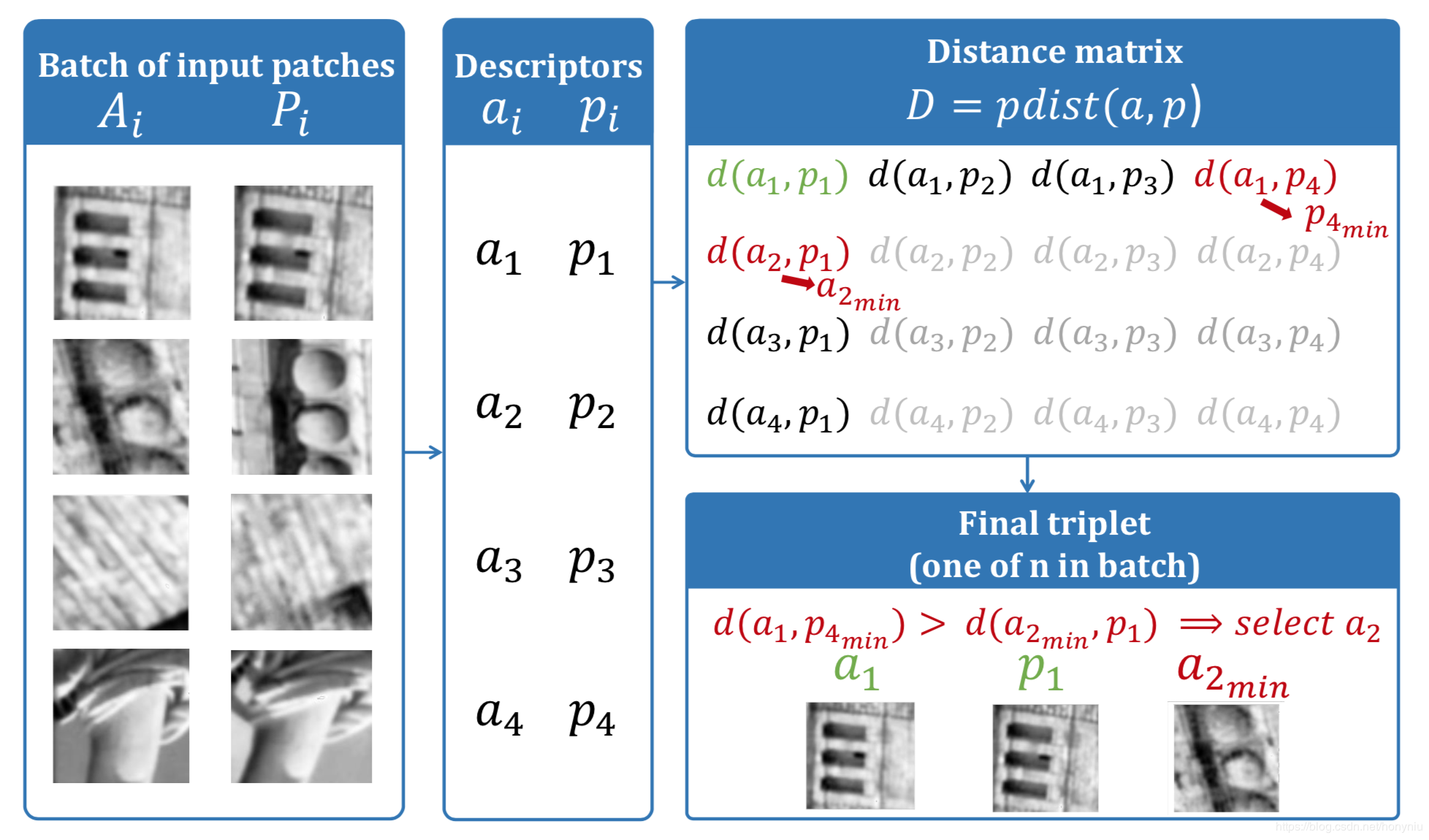
首先,生成一匹局部匹配块:\(\mathcal{X}=\left(A_{i}, P_{i}\right)_{i=1 \ldots n}\)其中
\(A_{i}\)表示 anchor
\(P_{i}\)表示 positive
L2 pairwise 距离矩阵是\(D=\)cdist\((a,p)\),其中\(d\left(a_{i}, p_{j}\right)=\sqrt{2-2 a_{i} p_{j}}, i=1 . . n, j=1 . . n\)
\(a_{i}\)表示 anchor 描述符
$ p_{i}$表示 positive 描述符
\(p_{j_{min}}\)表示距离\(a_{i}\)最近的非匹配描述符,其中\(j_{\min }=\arg \min _{j=1 \ldots n, j \neq i} d\left(a_{i}, p_{j}\right)\)
\(a_{k_{min}}\)表示距离\(p_{i}\)最近的非匹配描述符,其中\(k_{\min }=\arg \min _{k=1 \ldots n, k\neq i} d\left(a_{k}, p_{i}\right)\)
对于每一个四元描述符\(\left(a_{i}, p_{i}, p_{j_{m i n}}, a_{k_{m i n}}\right)\)都可以生成一个三元描述符,然后根据情况生成相应三元组如下:
我们的目的是最小化匹配的描述子和最近邻非匹配描述子之间的距离。所以每个 training batch 都生成了 n个三元组用于计算最后的 loss 函数,具体如下:
其中\(\min \left(d\left(a_{i}, p_{j_{m i n}}\right), d\left(a_{k_{m i n}}, p_{i}\right)\right.\)在上边构建三元组的时候已经算出来了。
和 L2-Net 不同,本文没使用学习过程中间的 feature maps 进行额外的监督也没现在描述符各个维度直接的关联性,利用上面的 loss 函数没有导致 overfitting 情况。
3.网络架构
本文是直接采用的是L2-Net的网络结构,这里把它展开了,如下图所示:
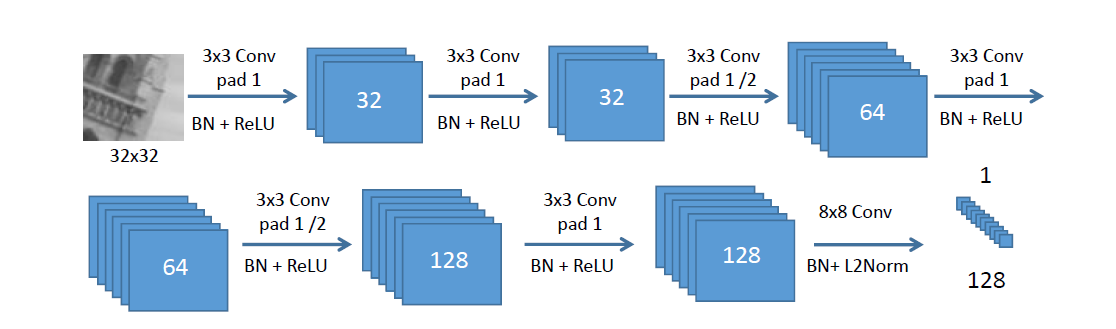
1)Padding 应用于除了最后一层的所有卷积层,为保证空间大小,填零
2)没有使用pooling层,本文中实验发现使用 pooling 层降维会降低描述符性能。这也是为什么要通过strided卷积来减小空间大小的原因。
3)Batch normalization层+Relu应用于除最后一层的所有层。
4)网络的输出用L2归一化,产生128维的单位长度描述符。
5)输入是 32×32 灰度图,利用每个 patch 的 mean 和 标准差去归一化。
6)优化通过随机梯度下降,学习率是0.1,动量是0.9,权重衰减是0.0001。文中的实验里,学习率在10周期内下降为0。
7)权重初始化为增益为0.6的正交向量,偏差设为0.01。用pytorch进行训练。
8)学习率提高到10,droupout率提高到0.3效果更好。
4.实验
本文使用 Brown 数据集训练和测试。Brown 数据集包含 Liberty,Notre Dame 和 Yosemite 三个子集,每个子集包含 400k个 64×64的 patches。每个子集包含 100k的匹配和非匹配 patch pairs 用于测试,然后在该测试集上比较 FPR95(false positive rate at 95% recall),结果如下图所示:

其中也比较了 FDR((false discovery rate),主要是被比较的文中给出该指标,这里为了公平,在该基础上计算了 FPR 进行统一比较。
其中都是在一个子集上训练然后在另外两个子集上测试,后面试验比较的话都是在 Liberty 集合上训练。
