
软工作业2:实现论文查重
| 软件工程 | 计科1班 |
|---|---|
| 作业要求 | (https://edu.cnblogs.com/campus/gdgy/CSGrade21-12/homework/13014) |
| 作业目标 | 个人项目 通过python编程来实现论文查重。 |
GitHub地址:
(https://github.com/Kklvu6/3121004665)
psp表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 90 |
| Estimate | 估计这个任务需要多少时间 | 600 | 730 |
| Development | 开发 | 300 | 400 |
| Analysis | 需求分析 (包括学习新技术) | 200 | 280 |
| Design Spec | 生成设计文档 | 40 | 20 |
| Design Review | 设计复审 | 40 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| Design | 具体设计 | 10 | 5 |
| Coding | 具体编码 | 200 | 220 |
| Code Review | 代码复审 | 20 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 40 | 40 |
| Reporting | 报告 | 30 | 20 |
| Test Repor | 测试报告 | 20 | 10 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 5 | 5 |
| Total | 总计 | 1560 | 1860 |
计算接口与实现过程
-
流程图:
![]()
-
整体流程:
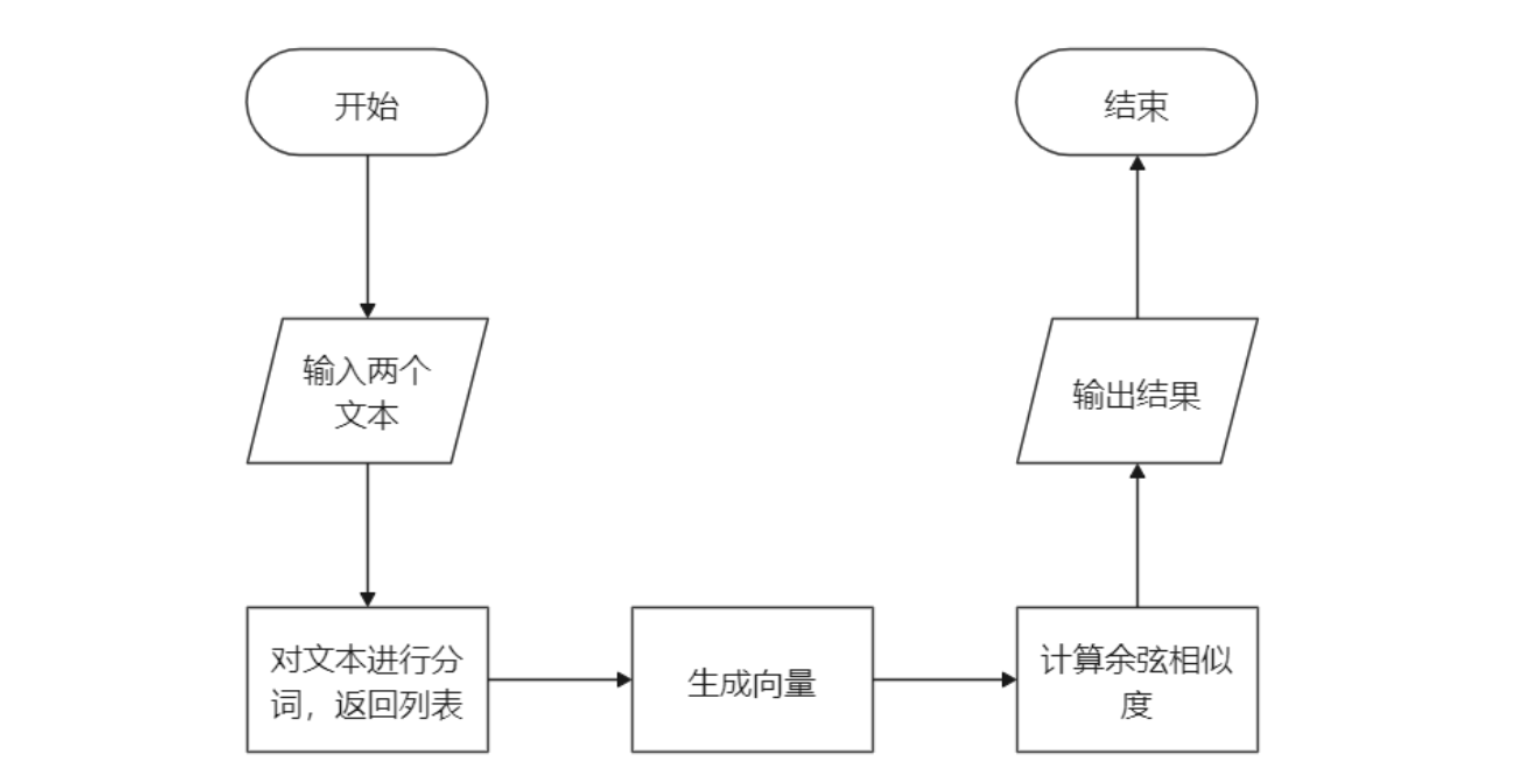
-
建立了一个Text类和两个函数(get_word_vector和cos_dist)
-
创建Text实例,调用Text类中的get_word_list函数分割字符串
-
使用get_word_vector函数将字符列表转换为向量
-
使用余弦相似度函数(cos_dist)计算两个字符列表的余弦相似度
-
函数方法
-
main函数:主函数
-
get_word_list函数:将字符串转换为字符列表
-
get_word_vector 函数:将字符列表转换为向量
-
cos_dist函数:计算余弦相似度(核心算法)
-
-
模块:
![]()
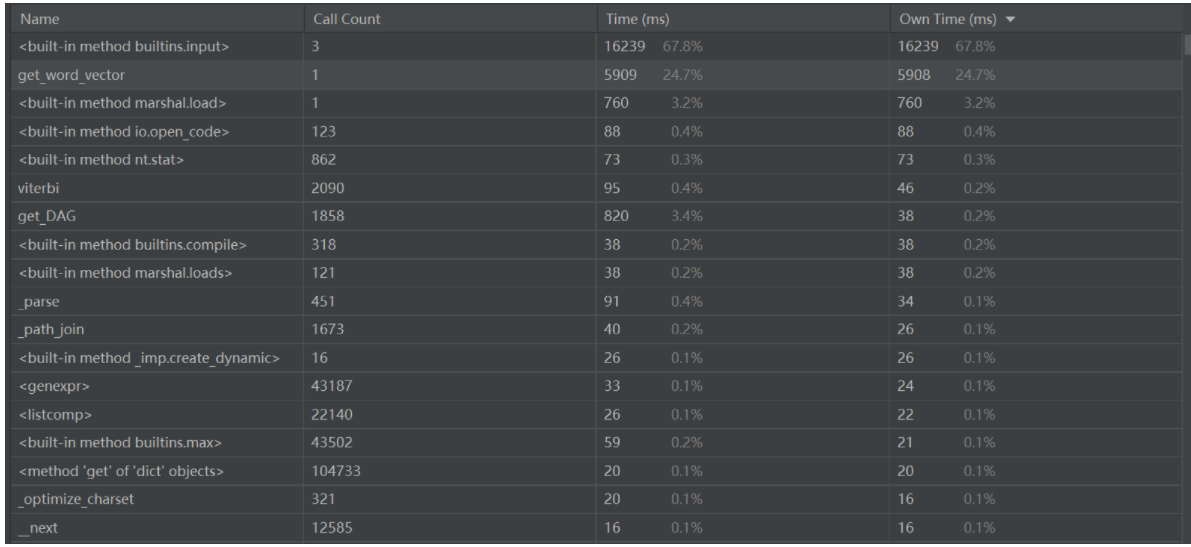
性能分析
- 使用内置profile来进行性能分析
![]()
- get_word_vector中获取向量需要使用双重for循环,占了程序大部分的时间
def get_word_vector(word_list1, word_list2):
key_word = list(set(word_list1 + word_list2))
# 给定形状和类型的用0填充的矩阵存储向量
word_vector1 = np.zeros(len(key_word))
word_vector2 = np.zeros(len(key_word))
# 计算词频
# 依次确定向量的每个位置的值
for i in range(len(key_word)):
# 遍历key_word中每个词在句子中的出现次数
for j in range(len(word_list1)):
if key_word[i] == word_list1[j]:
word_vector1[i] += 1
for k in range(len(word_list2)):
if key_word[i] == word_list2[k]:
word_vector2[i] += 1
return word_vector1, word_vector2
代码实现
- main:
def main():
# D:\pycode\lunwen查重\测试文本\orig.txt
# D:\pycode\lunwen查重\测试文本\orig_0.8_add.txt
# D:/pycode/lunwen查重/result.txt
try:
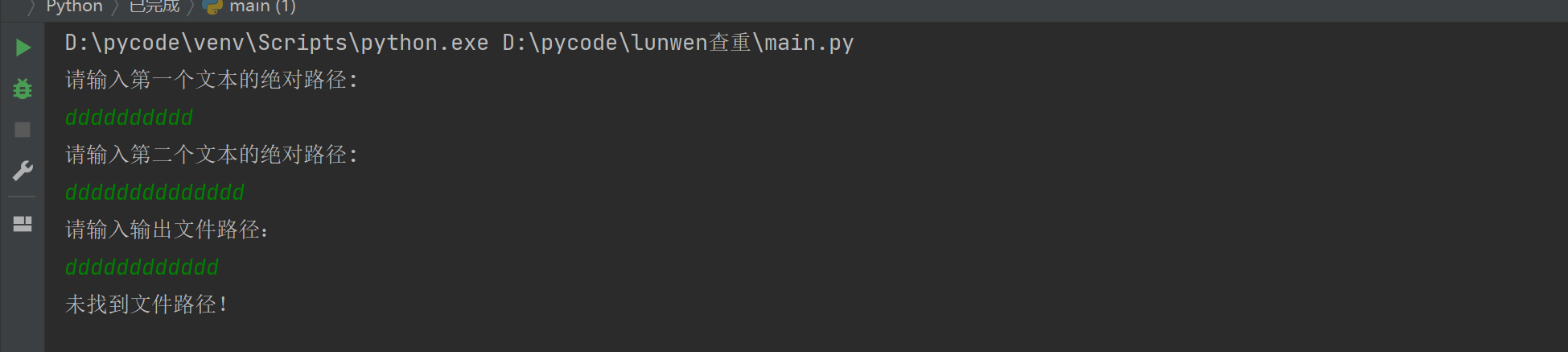
text1 = Text(input('请输入第一个文本的绝对路径:\n'))
text2 = Text(input('请输入第二个文本的绝对路径:\n'))
filename = input('请输入输出文件路径:\n')
a = text1.get_word_list(1)
b = text2.get_word_list(1)
except FileNotFoundError:
print('未找到文件路径!')
return -1
if text1.get_size() == 0 or text2.get_size() == 0:
print('文件为空!')
return -2
vec1, vec2 = get_word_vector(a, b)
distance = cos_dist(vec1, vec2)
with open(filename, 'w') as f:
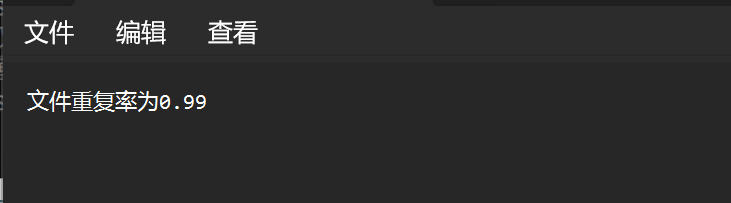
f.write(f'文件重复率为{distance:.2f}')
print(f'答案文件的路径为:{filename}')
print(f'文件重复率为{distance:.2f}')
input('press to quit')
- text:
- jieba分词
import re
import os
import jieba
class Text(object):
def __init__(self, text_route):
self.text_route = text_route
def get_size(self):
return os.path.getsize(self.text_route)
def get_word_list(self, num=0):
with open(self.text_route, 'r', encoding='utf-8') as file:
text = file.read()
if num == 1:
res = re.compile(r"([\u4e00-\u9fa5])") # 正则包根据单个中文文字分割字符串
text_list_init = res.split(text)
else:
text_list_init = jieba.lcut(text) # jieba包根据词语分割字符串
text_list_result = []
for literacy in text_list_init:
if '\u4e00' <= literacy <= '\u9fa5': # 除去非中文的列表元素
text_list_result.append(literacy)
return text_list_result
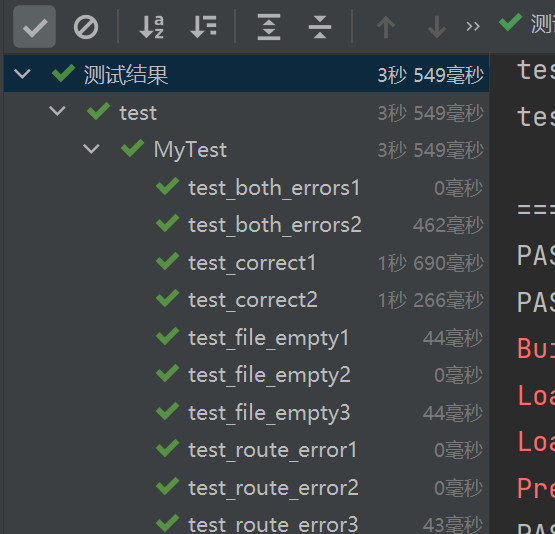
测试结果
======================== 10 passed, 1 warning in 3.95s ========================
PASSED [ 10%]未找到文件路径!
PASSED [ 20%]未找到文件路径!
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\31260\AppData\Local\Temp\jieba.cache
Loading model cost 0.420 seconds.
Prefix dict has been built successfully.
PASSED [ 30%]答案文件的路径为D:/pycode/lunwen查重/result.txt
文件重复率为0.99
PASSED [ 40%]答案文件的路径为D:/pycode/lunwen查重/result.txt
文件重复率为0.99
PASSED
-
![]()
-
![]()
-
错误路径
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号