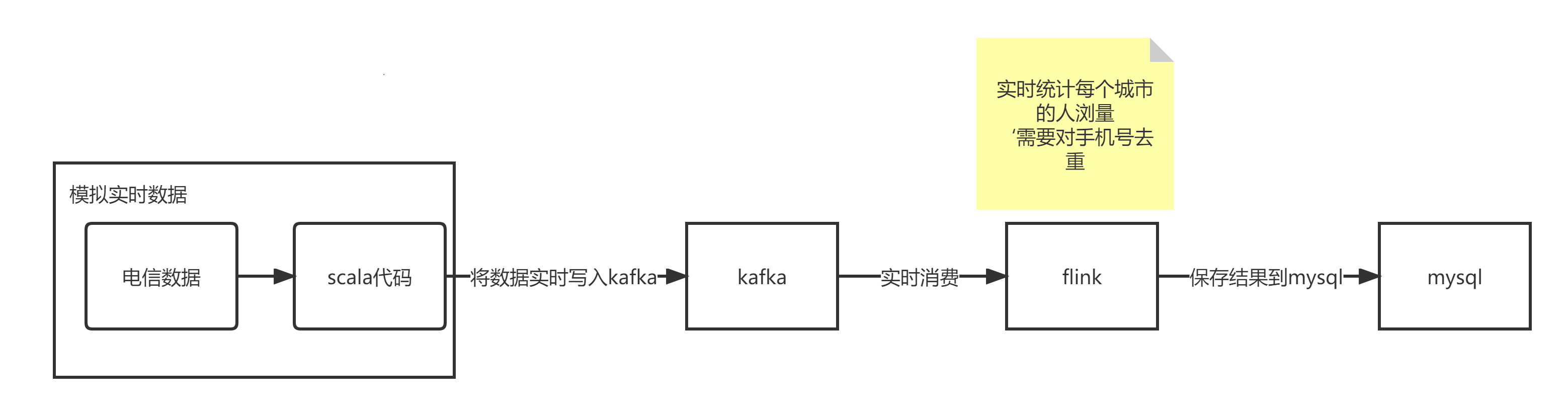
数据案例----数据写入Kafka、flink消费
![image]()
1、创建生产者,将数据写入Kafka
package com.shujia.flink.dx
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import scala.io.Source
object Demo1DataToKafka {
def main(args: Array[String]): Unit = {
/**
* 1、创建生产者
*/
val properties = new Properties()
//1、kafka broker列表
properties.setProperty("bootstrap.servers", "master:9092,node1:9092,node2:9092")
//2、指定kv的序列化类
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
val kafkaProducer = new KafkaProducer[String, String](properties)
//读取电信数据
val data: List[String] = Source.fromFile("data/dianxin_data").getLines().toList
for (line <- data) {
val record = new ProducerRecord[String, String]("dianxin", line)
kafkaProducer.send(record)
kafkaProducer.flush()
//设置100ms一条数据
Thread.sleep(100)
}
kafkaProducer.close()
}
}
2、创建消费者来消费kafka中的数据,并将需求的结果保存到MySQL
package com.shujia.flink.dx
import java.sql.{Connection, DriverManager, PreparedStatement}
import java.util.Properties
import org.apache.flink.api.common.functions.{ReduceFunction, RuntimeContext}
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.common.state.{MapState, MapStateDescriptor, ReducingState, ReducingStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.util.Collector
object Demo2CityFlow {
def main(args: Array[String]): Unit = {
/**
* 实时统计每个城市的人浏量
* 需要对手机号去重
*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
* 读取kafka中的数据
*/
val properties = new Properties()
//broler地址列表
properties.setProperty("bootstrap.servers", "master:9092,node1:9092,node2:9092")
//消费者组,同一条数据在一个组内只处理一次
properties.setProperty("group.id", "asdasdsa")
//创建消费者
val flinkKakfaConsumer = new FlinkKafkaConsumer[String](
"dianxin", //指定topic
new SimpleStringSchema(), //指定数据格式
properties //指定配置文件对象
)
flinkKakfaConsumer.setStartFromEarliest() // 尽可能从最早的记录开始
val dianxinDS: DataStream[String] = env.addSource(flinkKakfaConsumer)
/**
* 取出城市编码和手机号
*/
val kvDS: DataStream[(String, String)] = dianxinDS.map(line => {
val split: Array[String] = line.split(",")
val mdn: String = split(0)
val city: String = split(2)
(city, mdn)
})
//按照城市分组
val keyByDS: KeyedStream[(String, String), String] = kvDS.keyBy(_._1)
//统计人流量
val cityCountDS: DataStream[(String, Int)] = keyByDS.process(new KeyedProcessFunction[String, (String, String), (String, Int)] {
/**
* map 状态
* 使用map的key保存手机号,map的value不用
*/
var mapState: MapState[String, Int] = _
var reduceState: ReducingState[Int] = _
override def open(parameters: Configuration): Unit = {
val context: RuntimeContext = getRuntimeContext
//用于手机号去重的状态
val mapStateDesc = new MapStateDescriptor[String, Int]("mdns", classOf[String], classOf[Int])
mapState = context.getMapState(mapStateDesc)
//用于统计人流量的状态
val reduceStateDesc = new ReducingStateDescriptor[Int]("count", new ReduceFunction[Int] {
override def reduce(x: Int, y: Int): Int = x + y
}, classOf[Int])
reduceState = context.getReducingState(reduceStateDesc)
}
override def processElement(
value: (String, String),
ctx: KeyedProcessFunction[String, (String, String), (String, Int)]#Context,
out: Collector[(String, Int)]): Unit = {
val (city, mdn) = value
//1、判断当前手机号是否出现过
//如果手机号出现过,不需要做任务处理
//如果没有出现过,在之前的统计基础上加1
if (!mapState.contains(mdn)) {
//将当前手机号保存到状态中
mapState.put(mdn, 1)
//人流量加1
reduceState.add(1)
//获取最新的人流量
val count: Int = reduceState.get()
//将数据发送到下游
out.collect((city, count))
}
}
})
/**
* 将结果保存到mysql
*/
cityCountDS.addSink(new RichSinkFunction[(String, Int)] {
override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {
val (city, num) = value
stat.setString(1, city)
stat.setInt(2, num)
stat.execute()
}
var con: Connection = _
var stat: PreparedStatement = _
override def open(parameters: Configuration): Unit = {
//1、加载驱动
Class.forName("com.mysql.jdbc.Driver")
//创建链接
con = DriverManager.getConnection("jdbc:mysql://master:3306/bigdata?useUnicode=true&characterEncoding=utf-8", "root", "123456")
//编写sql
stat = con.prepareStatement("replace into city_count(city,num) values(?,?)")
}
override def close(): Unit = {
stat.close()
con.close()
}
})
env.execute()
}
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号