spark的介绍
spark的介绍
1、什么是spark?
分布式计算引擎,也是快速通用的大规模数据处理引擎
2、spark的特点
(1)速度快
spark的计算是基于内存的;spark具有优秀的作业调度策略
(2)易使用
spark提供了支持多种语言的API(scala、python、javan、R等;
scala的使用最为广泛(spark是基于scala语言开发的)
(3)通用性
spark提供了Spark SQL 、Spark Streaming 、Mlib、Graghx组件
(4)代码简洁
缺点:不稳定
3、Spark的组件
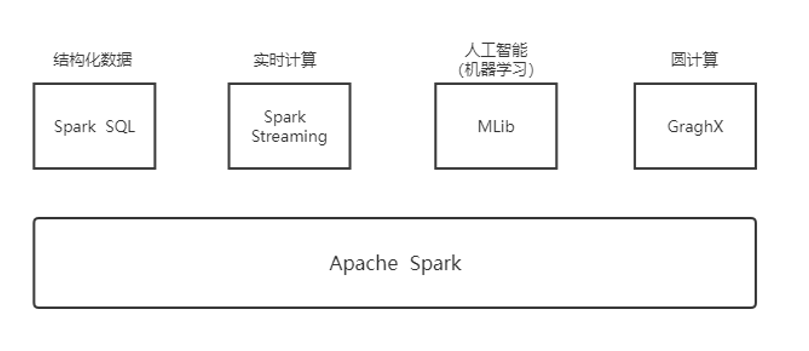
1、Spark Core(Spark的核心):算子
实现了 Spark 的基本功能(任务调度、内存管理、错误恢复、与存储系统交互等模块);
提供了很多的API来创建和操作RDD;
内部定义 了RDD(spark通过RDD将各组件联系在一起)
2、Spark SQL 是:Spark 用来操作结构化数据的程序包,可以用SQL语句进行数据查询
3、Spark Streaming : 实时数据流处理组建,提供了用来操作数据流的 API
4、MLlib:提供了很多种机器学习算法(分类、回归、聚类、协同过滤等)
5、GraphX :用来操作图的程序库,可以进行并行的图计算。
4、Spark与Hadoop的区别
(1)hadoop是基于磁盘的,它的运算结果保存在磁盘当中;而spark的运算是基于内存的。
(2)spark的运算速度是hadoop的100倍(官方公布);即使在磁盘当中运算,spark也是hadoop的10倍左右
spark比hadoop速度快的两个原因:
(1)spark是基于内存,hadoop基于磁盘
(2)spark具有优秀的作业调度策略(使用了有向无环图DAG)
(3)hadoop有额外的复制,序列化,磁盘IO开销
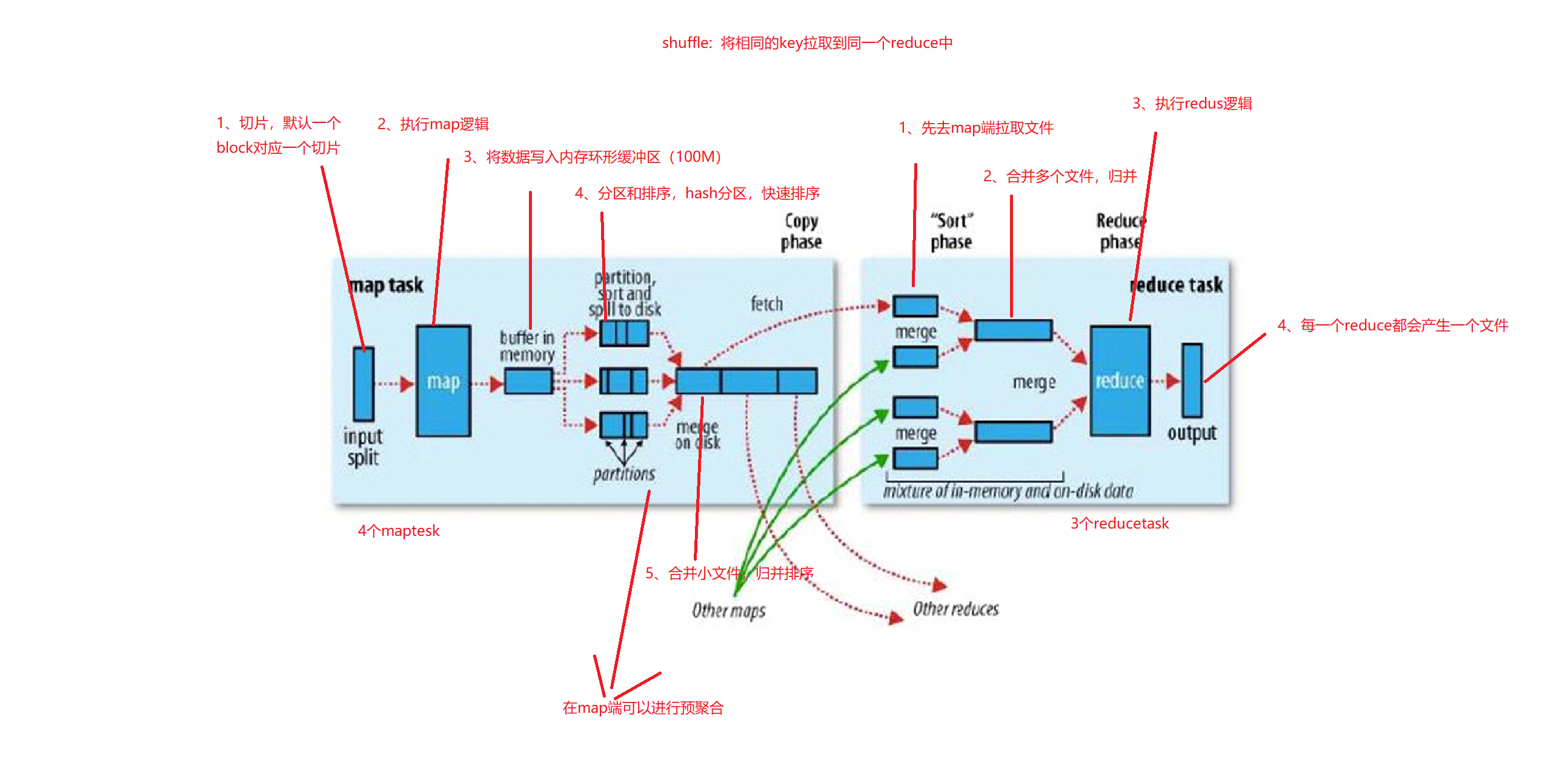
5、Spark也是一个MapReduce模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号