MapReduce读写HBase架构图及其示例代码
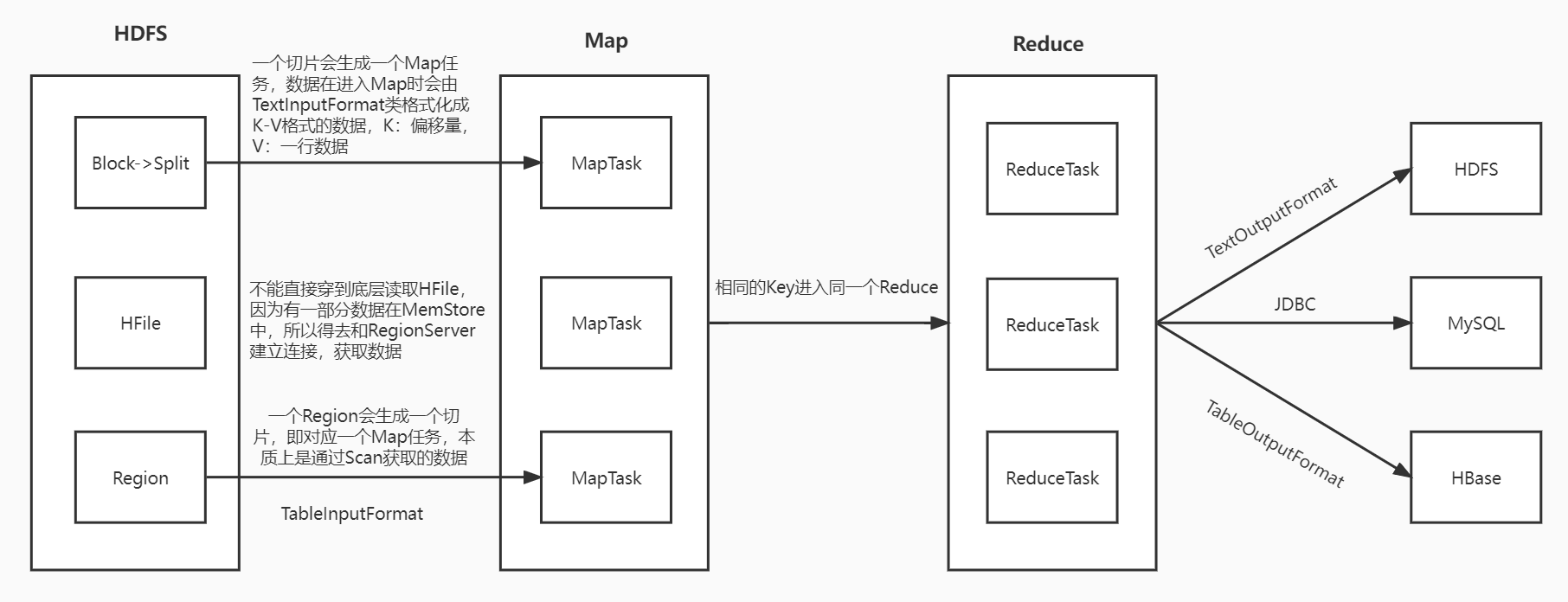
1、MapReduce读写HBase架构图
![]()
2、MapReduce读HBase代码示例
package com.shujia;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
// 读取stu表,统计班级人数
public class Demo05MRReadHBase {
// Map端
public static class MRReadHBase extends TableMapper<Text, IntWritable> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//将rowkey获取出来,并转换为字节数组
String rowkey = Bytes.toString(key.get());
//将班级获取出来
String clazz = Bytes.toString(value.getValue("info".getBytes(), "clazz".getBytes()));
// 以班级作为KeyOut,1作为ValueOut发送出去
context.write(new Text(clazz), new IntWritable(1));
}
}
// Reduce端
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int cnt = 0;
//遍历values
for (IntWritable value : values) { //values.for
cnt += value.get();
}
context.write(key, new IntWritable(cnt));
}
}
// Driver端
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
conf.set("fs.defaultFS", "hdfs://master:9000");
Job job = Job.getInstance(conf);
job.setJobName("Demo05MRReadHBase");
job.setJarByClass(Demo05MRReadHBase.class);
// 配置Map任务
TableMapReduceUtil.initTableMapperJob(
"stu",
new Scan(),
MRReadHBase.class,
Text.class,
IntWritable.class,
job
);
// 配置Reduce任务
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 配置输入输出路径
Path path = new Path("/MR/HBase/output/");
FileSystem fs = FileSystem.get(conf);
if (fs.exists(path)) {
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
job.waitForCompletion(true);
/**
* 1、因为Hadoop内没有运行HBase的依赖,需要我们手动配置Hadoop运行时的依赖环境
* 2、在Linux中配置一个临时的依赖即可
* export HADOOP_CLASSPATH="$HBASE_HOME/lib/*"
* 3、提交代码任务,打包成jar包,上传到Linux
* 4、进入jar包所在路径,执行命令,提交任务:
* hadoop jar HBase-1.0.jar com.shujia.Demo05MRReadHBase
* 5、执行完之后,可以查看一下
* hdfs dfs -cat /MR/HBase/output/*
* 结果:
文科一班 72
文科三班 94
...
*
*/
}
}
手动配置Hadoop运行时的依赖环境步骤:
# 第一步 在 Linux 中切到 HBase 的目录下 的 lib 目录下
# lib 目录下存放的都是 jar 包(依赖)
cd /usr/local/soft/hbase-1.4.6/lib/
# 第二步 通过 HADOOP_CLASSPATH 指定 Hadoop 运行时的依赖环境
export HADOOP_CLASSPATH="$HBASE_HOME/lib/*"
# 注 这样的配置是临时的,只在当前会话生效
3、MapReduce写HBase代码示例
package com.shujia;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
// 读取stu表,统计性别人数,并将结果写回HBase的表 stu_gender_cnt
public class Demo06MRReadAndWriteHBase {
// Map
public static class MRReadHBase extends TableMapper<Text, IntWritable> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String rowkey = Bytes.toString(key.get());
String gender = Bytes.toString(value.getValue("info".getBytes(), "gender".getBytes()));
// 以班级作为KeyOut,1 作为ValueOut
context.write(new Text(gender), new IntWritable(1));
}
}
// Reduce
// create 'stu_gender_cnt','info'
public static class MRWriteHBase extends TableReducer<Text, IntWritable, NullWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, NullWritable, Mutation>.Context context) throws IOException, InterruptedException {
int cnt = 0;
for (IntWritable value : values) {
cnt += value.get();
}
Put put = new Put(key.getBytes());
put.addColumn("info".getBytes(), "cnt".getBytes(), (cnt + "").getBytes());
context.write(NullWritable.get(), put);
}
}
// Driver
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
conf.set("fs.defaultFS", "hdfs://master:9000");
Job job = Job.getInstance(conf);
job.setJobName("Demo06MRReadAndWriteHBase");
job.setJarByClass(Demo06MRReadAndWriteHBase.class);
// 配置Map任务
TableMapReduceUtil.initTableMapperJob(
"stu",
new Scan(),
MRReadHBase.class,
Text.class,
IntWritable.class,
job
);
// 配置Reduce任务
TableMapReduceUtil.initTableReducerJob(
"stu_gender_cnt",
MRWriteHBase.class,
job
);
job.waitForCompletion(true);
/**
* 先创建stu_gender_cnt表
* create 'stu_gender_cnt','info'
* 使用Maven插件将依赖打入Jar包中
* hadoop jar HBase-1.0-jar-with-dependencies.jar com.shujia.Demo06MRReadAndWriteHBase
*/
}
}
# 使用Maven插件将依赖打入Jar包中
# 在项目的 pom.xml 文件中添加 Maven 插件的依赖 然后重新导一下依赖
<!-- 将依赖打入Jar包-->
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- 带依赖jar 插件-->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
# 之后打 jar 包的时候就会将所需依赖一并打入

 浙公网安备 33010602011771号
浙公网安备 33010602011771号