MapReduce原理深入理解2----Map、Shuffle、Reduce过程详解
1、MR执行过程-map阶段
map任务处理
1.1 框架使用InputFormat类的子类--FileInputFormat把输入文件(夹)划分为很多InputSplit,
默认,每个HDFS的block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析成一个个<k1,v1>。
默认,框架对每个InputSplit中的每一行,解析成一个<k1,v1>。
1.2 框架调用Mapper类中的map(...)函数,map函数的形参是<k1,v1>对,输出是<k2,v2>对。
一个InputSplit对应一个map task。程序员可以覆盖map函数,实现自己的逻辑。
1.3
(假设reduce存在)框架对map输出的<k2,v2>进行分区。不同的分区中的<k2,v2>由不同的reduce task处理。默认只有1个分区。
(假设reduce不存在)框架对map结果直接输出到HDFS中。
1.4 (假设reduce存在)框架对每个分区中的数据,按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。注意:分组不会减少<k2,v2>数量。
1.5 (假设reduce存在,可选)在map节点,框架可以执行reduce归约。
1.6 (假设reduce存在)框架会对map task输出的<k2,v2>写入到linux 的磁盘文件中。
至此,整个map阶段结束
TextInputFormat类继承FileInputFormat类,FileInputFormat类继承InputFormat类;
FileInputFormat类负责读取文件并切片,是InputFormat类实现的基类;
TextInputFormat类将每一行数据格式化为<k,v>格式;
在进行切片的时候相当于调用了FileInputFormat类的getsplits方法;
一个切片生成一个map任务。
只有map任务,没有reduce任务程序示例
//需求:过滤出文科三班的学生(只有map任务,没有reduce任务)
//过滤出文科三班,就是将文科三班的所有学生输出
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Demo5MRFilter {
public static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
// 过滤出文科三班的学生
String clazz = value.toString().split(",")[4];
if ("文科三班".equals(clazz)) {
context.write(value, NullWritable.get());
}
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
// 设置MapReduce输出的K-V的分隔符
conf.set("mapred.textoutputformat.separator", ",");
Job job = Job.getInstance(conf);
job.setJobName("Demo5MRFilter");
job.setJarByClass(Demo5MRFilter.class);
job.setMapperClass(MyMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 配置输入输出路径
FileInputFormat.addInputPath(job, new Path("/student/input"));
// 输出路径不需要提前创建,如果该目录已存在则会报错
// 通过HDFS的JavaAPI判断输出路径是否存在
Path outPath = new Path("/student/filter/output");
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
// 等待job运行完成
job.waitForCompletion(true);
/**
* hdfs dfs -mkdir -p /student/filter/output
* hadoop jar Hadoop-1.0.jar com.shujia.MapReduce.Demo5MRFilter
*/
}
}
执行结果:
1500100066,惠耘涛,22,男,文科三班
1500100088,田德明,21,男,文科三班
1500100095,尹宛秋,23,女,文科三班
1500100109,从振强,24,男,文科三班
1500100120,桓浩邈,24,男,文科三班
1500100129,容寄南,23,女,文科三班
1500100139,左代萱,24,女,文科三班
1500100160,云冰真,24,女,文科三班
1500100196,汤浩博,21,男,文科三班
1500100199,陆慕易,24,女,文科三班
1500100202,干曜瑞,23,男,文科三班
1500100229,逯冬萱,22,女,文科三班
1500100231,桂痴安,22,女,文科三班
...
2、MapReduce默认输入处理类
(1)InputFormat
抽象类,只是定义了两个方法。
(2)FileInputFormat
FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,FileInputFormat处理作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类——TextInputFormat进行实现的。
(3)TextInputFormat
是默认的处理类,处理普通文本文件
文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value
默认以\n或回车键作为一行记录
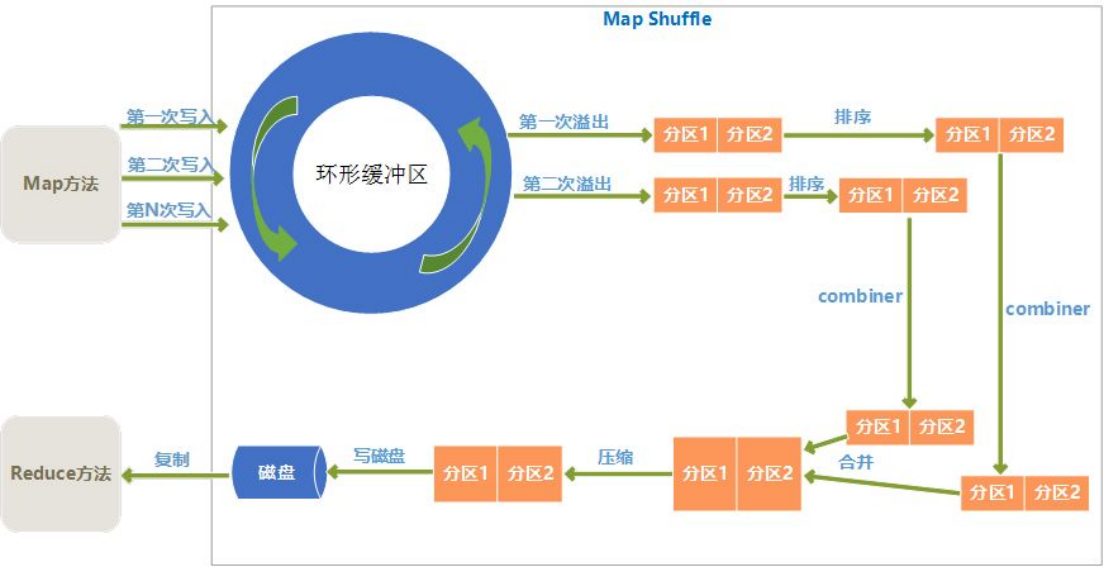
3、shuffle过程
shuffle的Write阶段:在Map端
1.每个map有一个环形内存缓冲区,用于存储map的输出。默认大小100MB(io.sort.mb属性),
一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容溢写到(spilt)磁盘的
指定目录(mapred.local.dir)下的一个新建文件中。
2.写磁盘前,要partition,sort。如果有combiner,combiner排序后数据。
3.等最后记录写完,合并全部文件为一个分区且排序的文件。
shuffle的Read阶段:在Reduce端
1.Reducer通过Http方式得到输出文件的特定分区的数据。
2.排序阶段合并map输出。然后走Reduce阶段。
3.reduce执行完之后,写入到HDFS中。
![image]()
4、MR执行过程-reduce阶段
reduce任务处理
2.1 框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
这个过程称作shuffle。
2.2 框架对reduce端接收的[map任务输出的]相同分区的<k2,v2>数据进行合并、排序、分组。
2.3 框架调用Reducer类中的reduce方法,reduce方法的形参是<k2,{v2...}>,输出是<k3,v3>。
一个<k2,{v2...}>调用一次reduce函数。程序员可以覆盖reduce函数,实现自己的逻辑。
2.4 框架把reduce的输出保存到HDFS中。
至此,整个reduce阶段结束。
例子:实现WordCountApp

 浙公网安备 33010602011771号
浙公网安备 33010602011771号