MapReduce原理深入理解1----shuff过程
MapReduce原理深入理解
1、主要原理
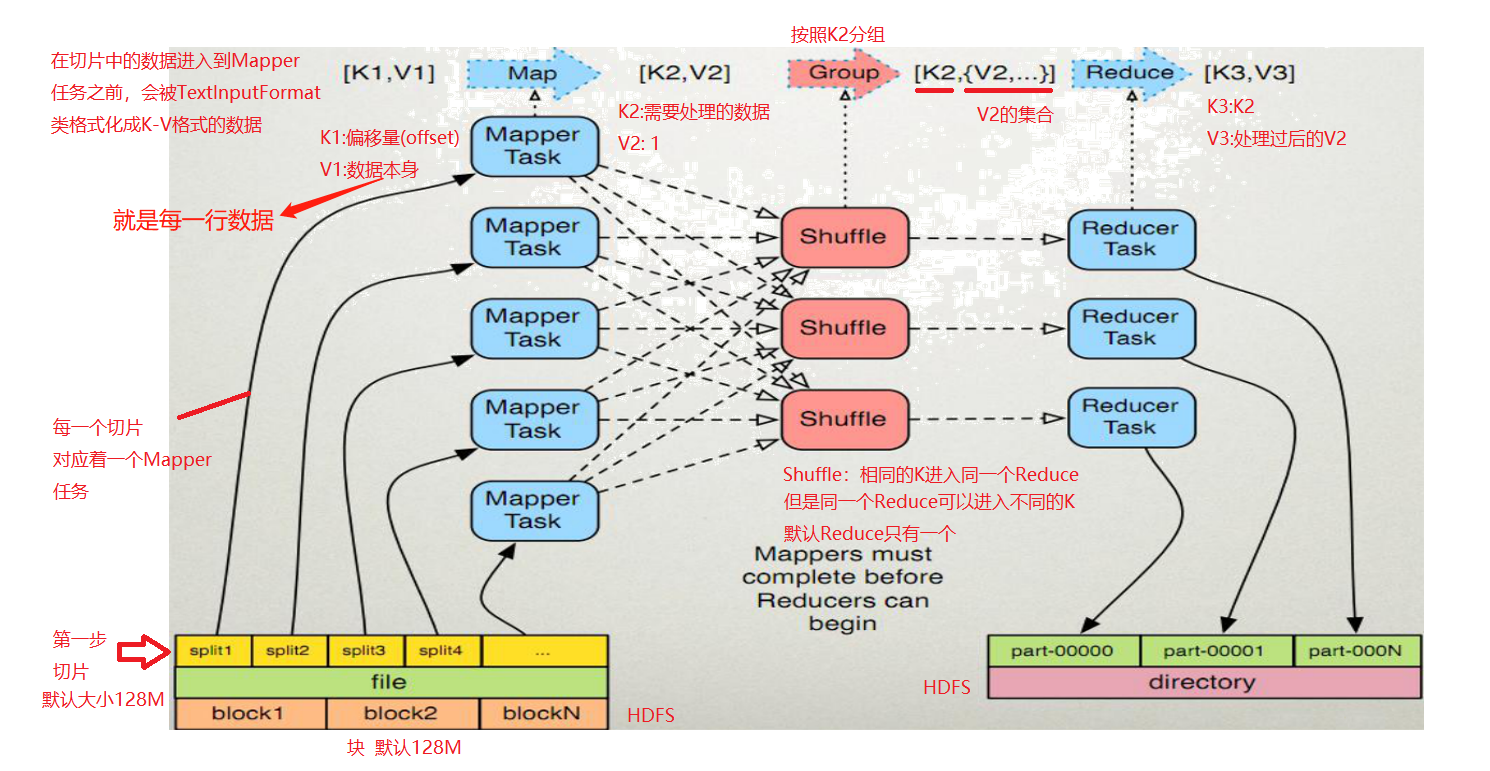
(1)Map任务的数量由切片splite决定;Reduce的数量默认是一个,但是可以手动设置
(2)MapReduce的输入和输出是基于HDFS的文件;
切片splite使用类TestInputFormat将文件中的数据转化为<k1,v1>格式,
此时的k1表示数据的偏移量offset,v1表示的是行数据;
<k1,v1>进入Map,Map将其构造成<k2.v2>,
此时的k2表示需要处理的数据(单词/班级/性别...),v2表示为1,
Map通过context.write将<k2.v2>发送出去;
(3)相同的k2的所有v2,构成[k2,{v2,...}],{v2,...}表示迭代器;
进入Reduce的时候,数据还是<k,v>格式,此时的v比较特殊,为迭代器;
经过Reduce将数据构造成<k3,v3>格式,
Reduce使用类TextOutputFormat将<k3.v3>转换为文件输出到HDFS
2、MapReduce内的shuffle过程
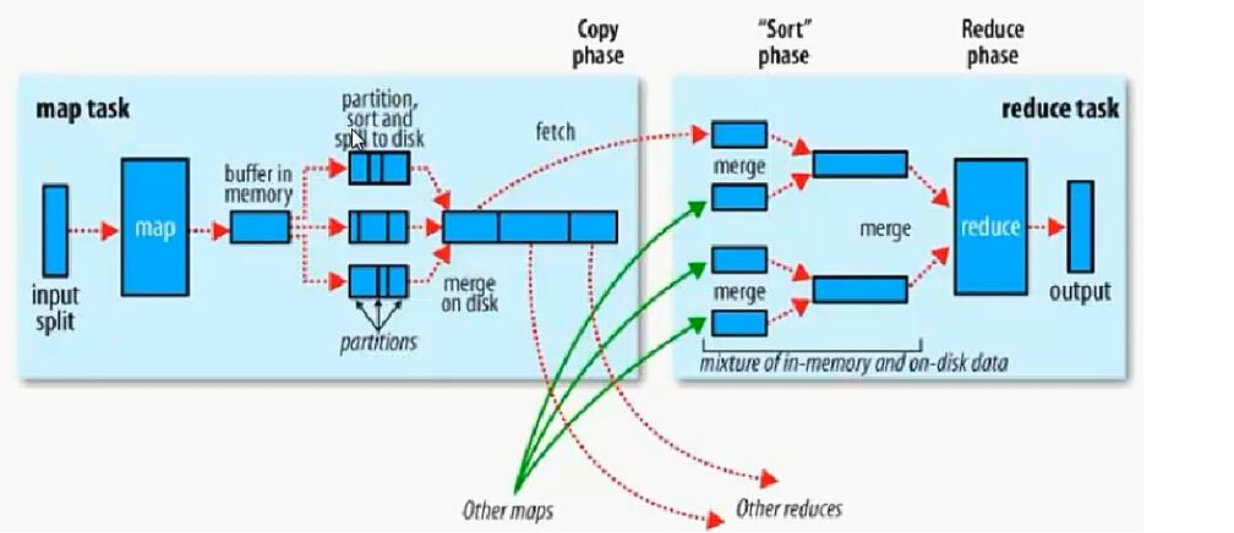
inputsplite:输入切片; partition, sort and splite to disk:隔断,分区和排序
buffer in memory:缓冲区; fetch:拿来,取来
merge:合并
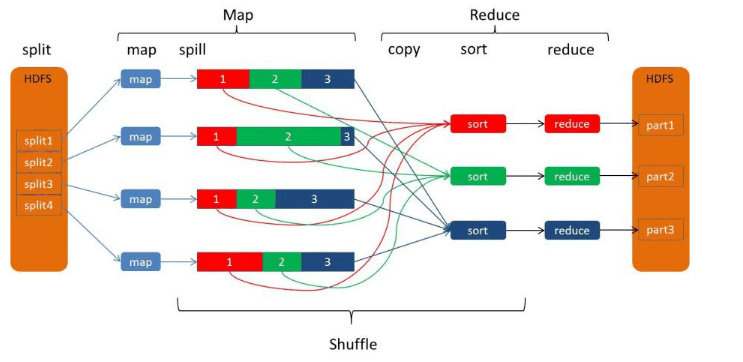
MapReduce是基于磁盘IO的框架,所以Map端的输出存在磁盘里,
若直接写进磁盘里,速度会很慢,所以存在磁盘之前,会加入一个缓冲区(环形),缓冲区的默认大小为100M;
因此会先写入缓冲区,当缓冲区达到80%,会溢出写进磁盘,此时会进行分区和排序,最后再合并
分区的数量=Reduce的数量,Reduce的数量决定分区的数量
理解:怎么分区的?
对Map输出的K,会去求K的Hash值,然后与分区的数量进行取余,每个余数对应着每个分区

 浙公网安备 33010602011771号
浙公网安备 33010602011771号