Hadoop的分布式计算----MapReduce概述
Hadoop的分布式计算----MapReduce
什么是MapReduce?
你想数出一摞牌中有多少张黑桃。直观方式是一张一张检查并且数出有多少张是黑桃。
MapReduce方法则是:
1.给在座的所有玩家中分配这摞牌
2.让每个玩家数自己手中的牌有几张是黑桃,然后把这个数目汇报给你
3.你把所有玩家告诉你的数字加起来,得到最后的结论
1、MapReduce的概述
(1)MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
(2)MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,Map阶段是一个独立的
程序,有很多个节点同时运行,每个节点处理一部分数据。Reduce阶段是一个独立的程序,
有很多个节点同时运行,每个节点处理一部分数据【在这先把reduce理解为一个单独的聚合程序即可】。
(3)MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()两个函数,即可实现分布式计算,非常简单。
(4)这两个函数的形参和返回值都是<key、value>,使用的时候一定要注意构造<k,v>
举例:
想要统计扑克牌每个花色的数量,花色为K,每个花色的数量为V
想要统计每个班级人数,班级为K,每个班级人数为V
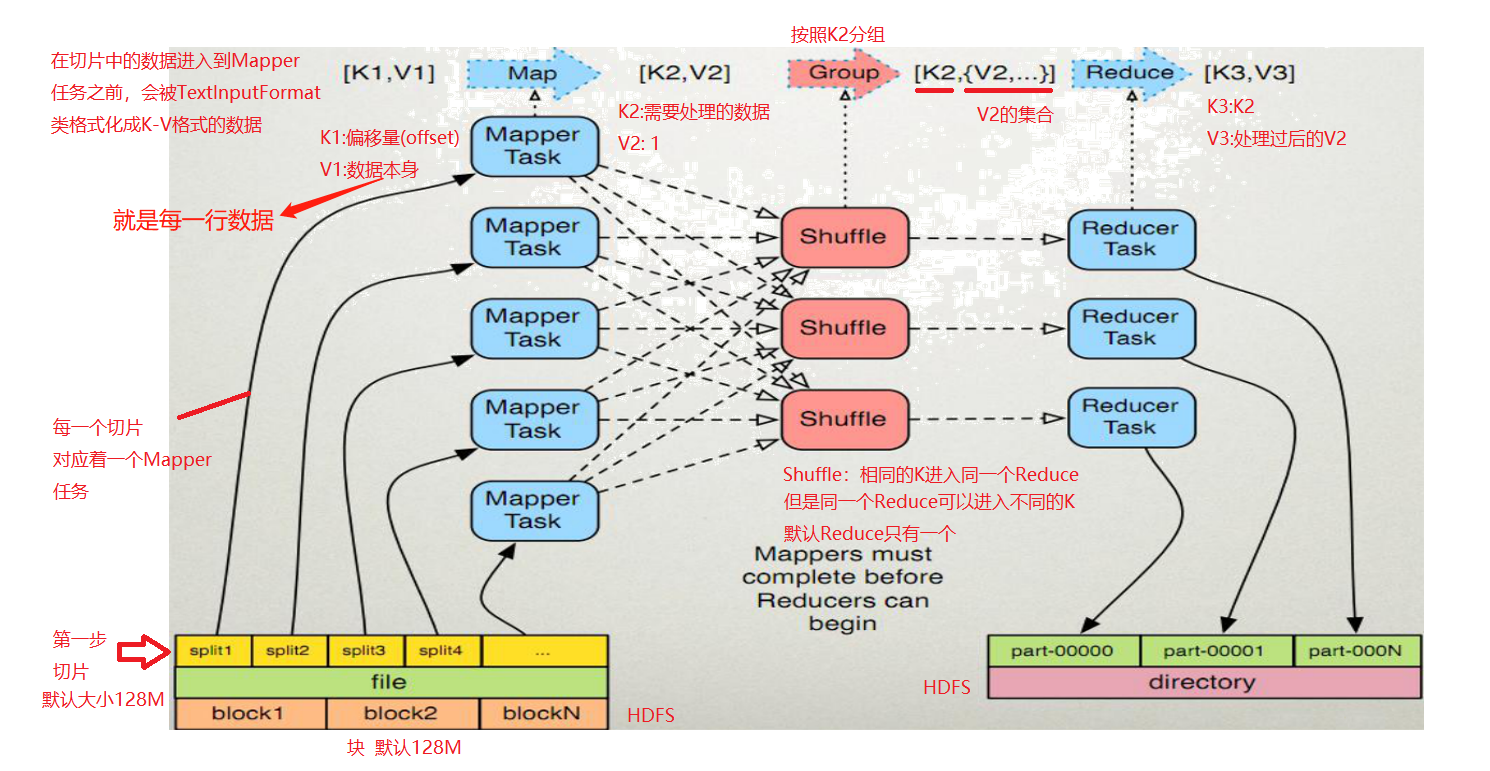
2、MapReduce原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号