HDFS原理深入理解
1、HDFS概述
(1)数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
(2)是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
(3)通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
(4)容错。即使系统中有某些节点宕机,整体来说系统仍然可以持续运作而不会有数据损失【通过副本机制实现】。
(5)分布式文件管理系统很多,hdfs只是其中一种,不合适小文件。
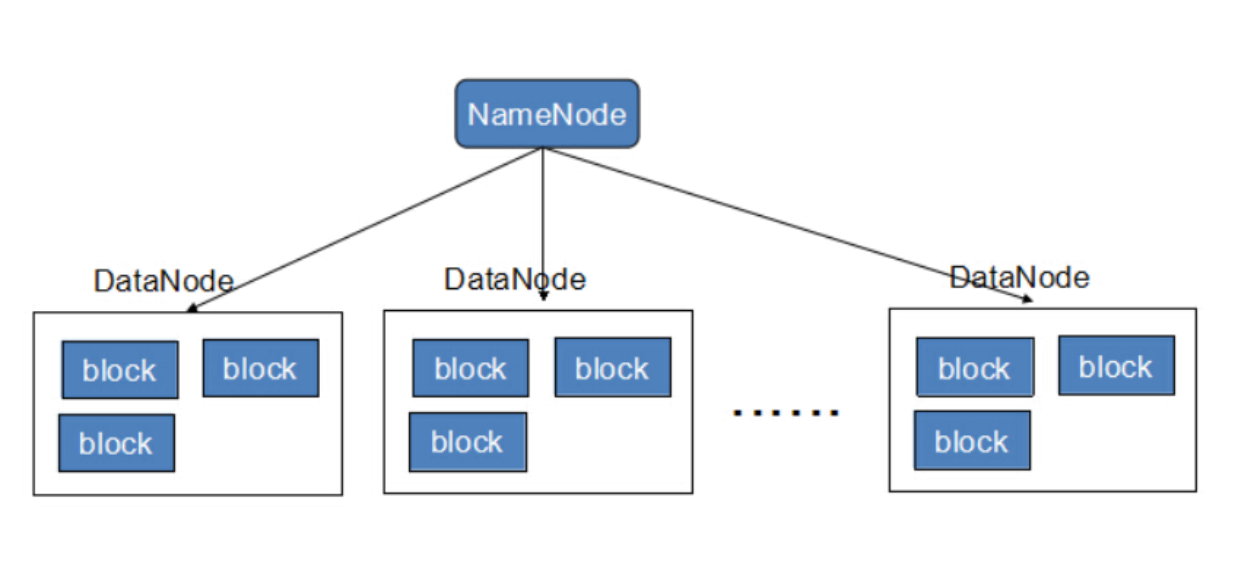
2、HDFS架构
![image]()
3、主节点NameNode的概述
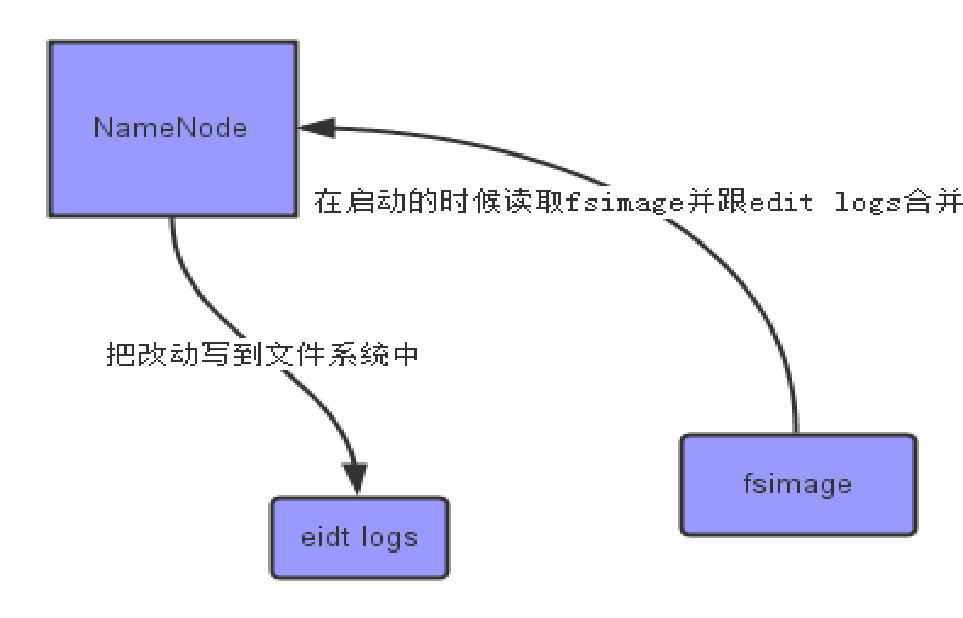
(1)NameNode是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
(2)文件默认包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件,namenode启动后一些新增元信息日志。
fstime:保存最近一次checkpoint的时间
(3)以上这些文件是保存在linux的文件系统中:
hdfs-site.xml的dfs.namenode.name.dir属性
4、Secondary NameNode的描述
![image]()
SNN的工作流程
![image]()
5、从节点DataNode的概述
(1)提供真实文件数据的存储服务。
(2)文件块(block):最基本的存储单位。
对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。2.0以后HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.
hdfs-site.xml中dfs.blocksize属性
(3)不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间
(4)Replication。多复本。默认是三个:
hdfs-site.xml的dfs.replication属性
6、HDFS 的Trash回收站
(1)和Linux系统(桌面环境)的回收站设计一样,HDFS会为每一个用户创建一个回收站目录:/user/用户名/.Trash/,每一个被用户通过Shell删除的文件/目录,fs.trash.interval是在指在这个回收周期之内,文件实际上是被移动到trash的这个目录下面,而不是马上把数据删除掉。等到回收周期真正到了以后,hdfs才会将数据真正删除。默认的单位是分钟,1440分钟=60*24,刚好是一天。
(2)配置:在每个节点(不仅仅是主节点)上添加配置 core-site.xml,增加如下内容
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
(3)注意:如果删除的文件过大,超过回收站大小的话会提示删除失败,需要指定参数 -skipTrash


 浙公网安备 33010602011771号
浙公网安备 33010602011771号