图片懒加载
图片懒加载
是一种反爬机制,图片懒加载是一种网页优化技术。图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间。为了解决这种问题,通过前后端配合,使图片仅在浏览器当前视窗内出现时才加载该图片,达到减少首屏图片请求数的技术就被称为“图片懒加载”。
图片懒加载是一种网页优化技术。图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间。为了解决这种问题,通过前后端配合,使图片仅在浏览器当前视窗内出现时才加载该图片,达到减少首屏图片请求数的技术就被称为“图片懒加载”。
网站一般如何实现图片懒加载技术呢?
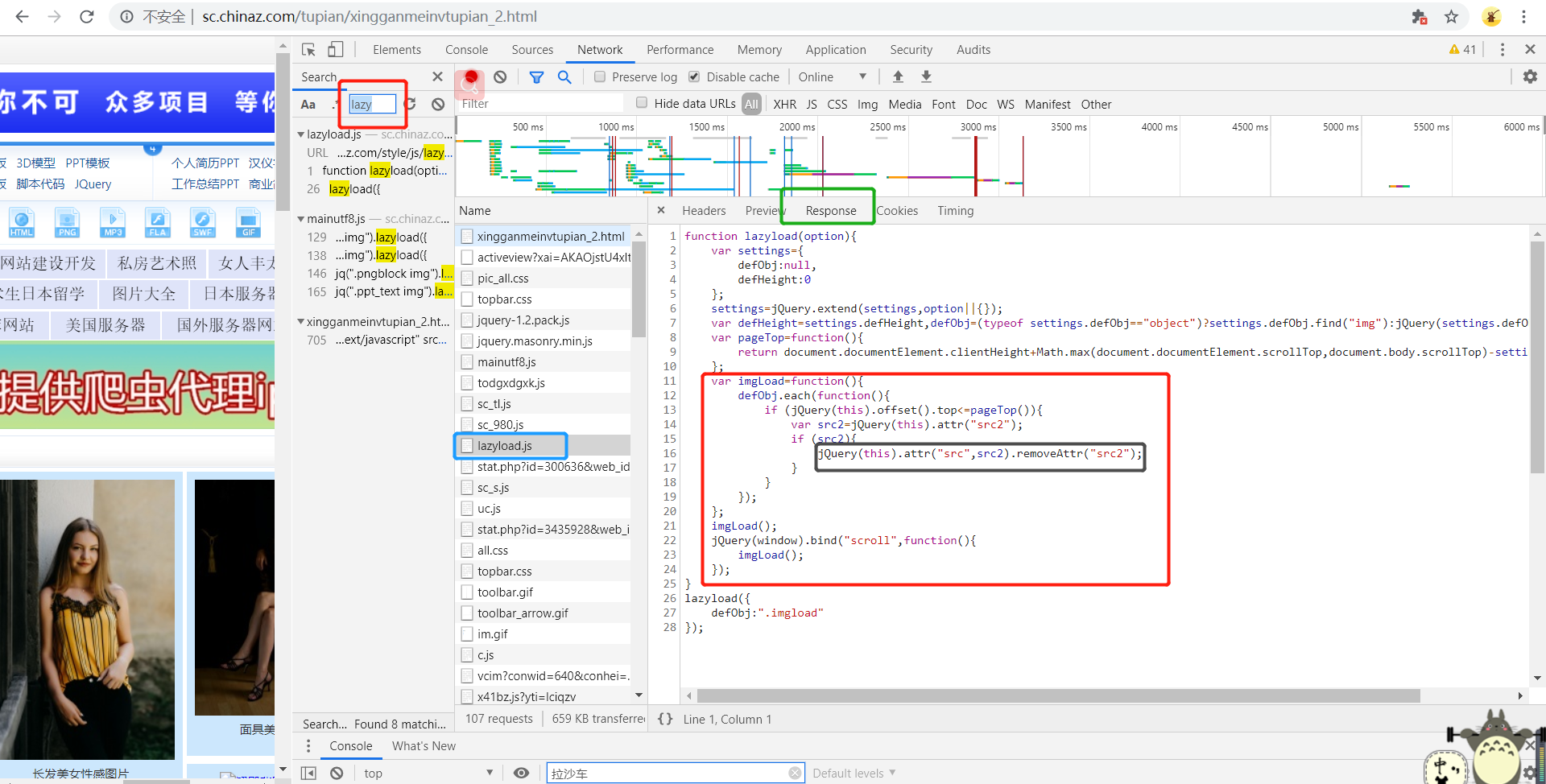
在网页源码中,在img标签中首先会使用一个“伪属性”(通常使用src2,original......)去存放真正的图片链接而并非是直接存放在src属性中。当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的加载。
如何实现图片懒加载技术
在网页源码中,在img标签中首先会使用一个“伪属性”(通常使用src2,original…)去存放真正的图片链接而并非是直接存放在src属性中。当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的加载。
案例
爬取站长之家的图片素材
import scrapy
import requests
headers={
'USER_AGENT':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
class ImgzzSpider(scrapy.Spider):
name = 'imgzz'
start_urls = ['http://sc.chinaz.com/tupian/']
def parse(self, response):
src = response.xpath('//*[@id="container"]/div/div[1]/a/img/@src').extract()
print(src) # 打印结果为空,这里的图片属性就应用的图片懒加载技术,其实图片的真正的src不是图片真正的属性
for url in src:
name = url.split('/')[-1]
img = requests.get(url=url,headers=headers).content
with open(name,'wb') as f:
f.write(img)
分析:
正常访问时:
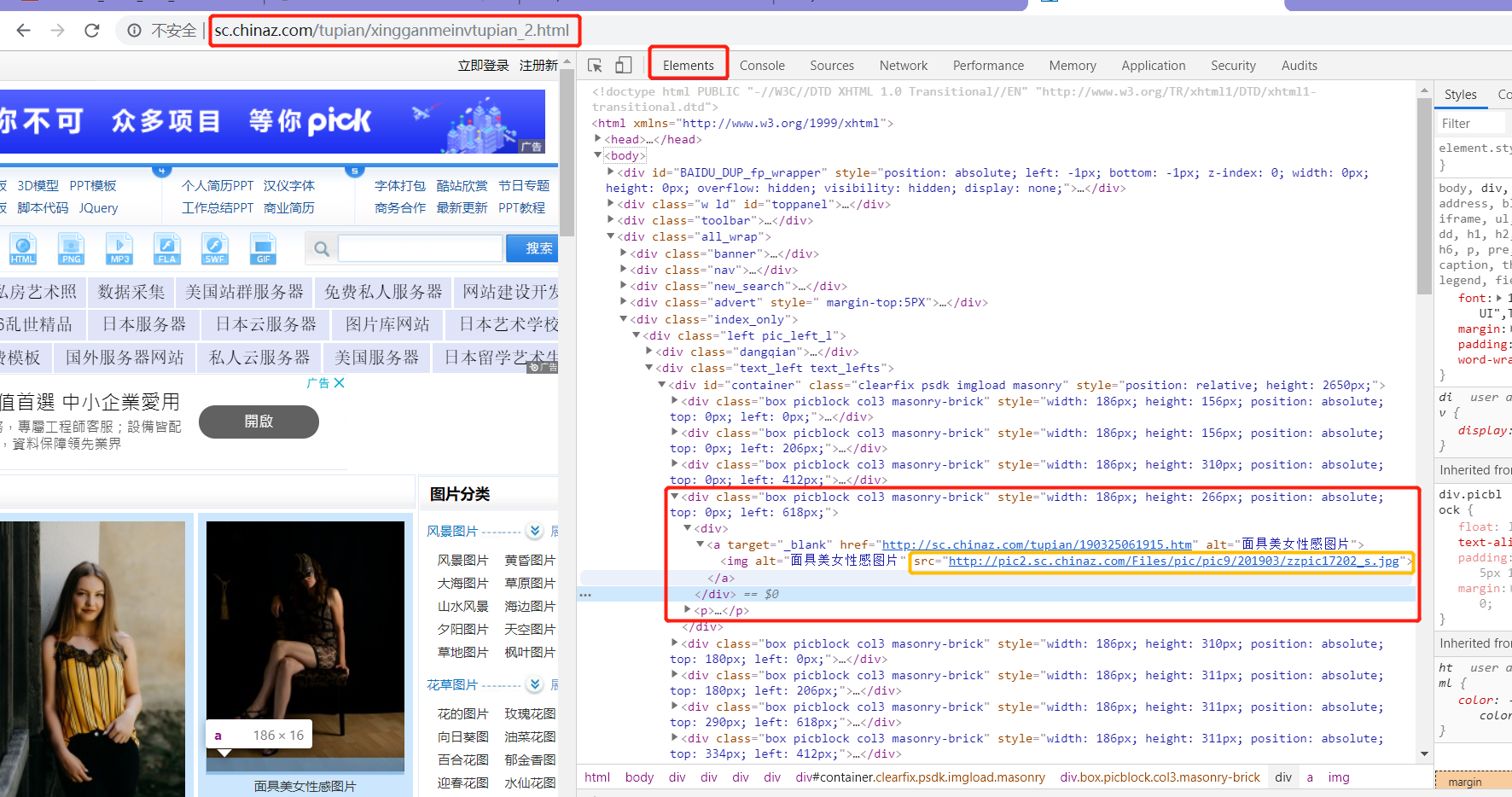
这样直接写xpath表达式定位标签的话获取的值为空
当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的加载。通过js来完成对图片属性的替换
import scrapy
import requests
headers={
'USER_AGENT':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
class ImgzzSpider(scrapy.Spider):
name = 'imgzz'
start_urls = ['http://sc.chinaz.com/tupian/']
def parse(self, response):
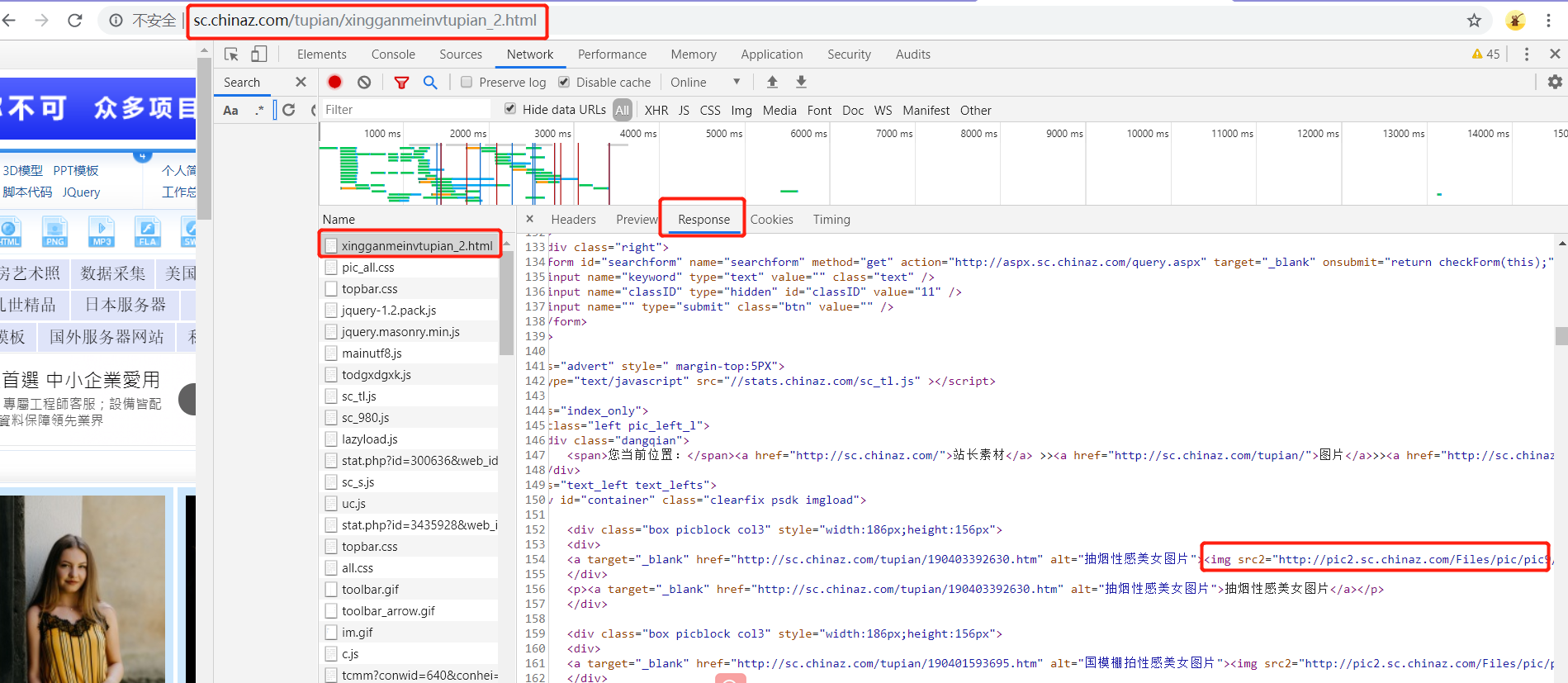
src = response.xpath('//*[@id="container"]/div/div[1]/a/img/@src2').extract() #改为图片的真正属性
print(src)
for url in src:
name = url.split('/')[-1]
img = requests.get(url=url,headers=headers).content
with open(name,'wb') as f:
f.write(img)
非学,无以致疑;非问,无以广识

