mysql字符集
character_set_client:character_set_client:客户端来源数据使用的字符集(告知服务器自己发来的数据是什么格式编码的)
character_set_connection:连接层字符集
character_set_results:查询结果字符集
以上三个变量的设置只对当前的客户端生效,打个比方,比如我在win命令行中连接了mysql,我设置了set character_set_connection = utf8;
当我再启动另一个命令行连接了数据库,这个character_set_connection不一定是utf8,这个命令行里的character_set_connection变量为默认设置gbk.
character_set_results为服务器直接返回给客户端的字符的编码(注意,客户端通往服务器需要经过连接层中转,而服务器却不经过中转直接到客户端)。所以,这个要与character_set_client
保持一致。
下面这句: SET NAMES 'utf8';它相当于下面的三句指令:
SET character_set_client = utf8;
SET character_set_results = utf8;
SET character_set_connection = utf8;
除上面三个只对当前客户端生效的变量以外,还有以下定义服务器编码的变量,这些对所有客户端有效:
character_set_server:默认的内部操作字符集
character_set_database:当前选中数据库的默认字符集
character_set_database:当前选中数据库的默认字符集
关于字符序:
• 字符序(Collation)是指在同一字符集内字符之间的比较规则;
• 确定字符序后,才能在一个字符集上定义什么是等价的字符,以及字符之间的大小关系;
• 每个字符序唯一对应一种字符集,但一个字符集可以对应多种字符序,其中有一个是默认字符序(Default Collation);
• MySQL中的字符序名称遵从命名惯例:以字符序对应的字符集名称开头;以_ci(表示大小写不敏感)、_cs(表示大小写敏感)或_bin(表示按编码值比较)结尾。例如:在字符序“utf8_general_ci”下,字符“a”和“A”是等价的;
MySQL中的字符集转换过程
1. MySQL Server收到请求时将请求数据从character_set_client转换为character_set_connection;
2. 进行内部操作前将请求数据从character_set_connection转换为内部操作字符集,其确定方法如下:
- 使用每个数据字段的CHARACTER SET设定值;
- 若上述值不存在,则使用对应数据表的DEFAULT CHARACTER SET设定值(MySQL扩展,非SQL标准);
- 若上述值不存在,则使用对应数据库的DEFAULT CHARACTER SET设定值;
- 若上述值不存在,则使用character_set_server设定值。
3. 服务器返回给客户端的时候,将操作结果从内部操作字符集转换为character_set_results直接发给客户端。
由于字符集设计有误带来数据错误的案例:
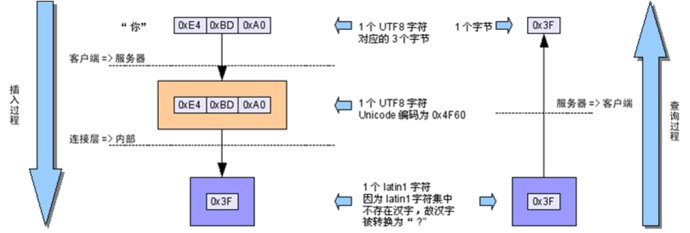
character_set_client、character_set_connection为utf8.服务器字符集为默认latin1
插入数据将经过utf8=>utf8=>latin1的字符集转换,若原始数据中含有\u0000~\u00ff范围以外的Unicode字符,会因为无法在latin1字符集中表示(latin1字符集没有汉字)而被转换为“?”(0×3F)符号,以后查询时不管连接字符集设置如何都无法恢复其内容了
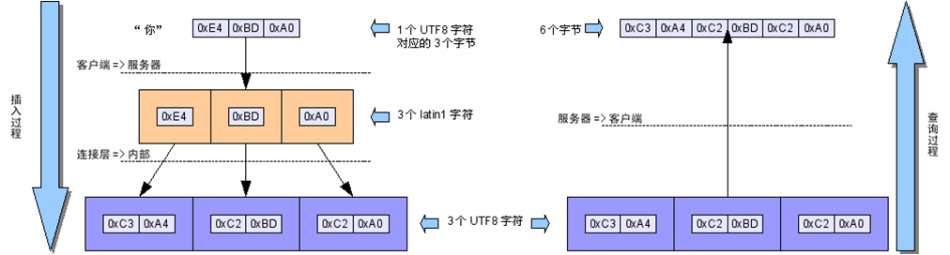
character_set_client、character_set_connection为latin1,character_set_results为utf8,服务器字符集为utf8,
插入操作的数据将经过latin1=>latin1=>utf8的字符集转换过程,这一过程中每个插入的汉字都会从原始的3个字节变成6个字节保存;
查询时的结果将经过utf8=>utf8的字符集转换过程,将保存的6个字节原封不动返回,产生乱码……,如下图
建议,我们解决我们遇到问题应该使用什么方法大家心里应该比较清楚了。对,就是在创建database的时候指定字符集,不要去通过修改默认配置来达到目的,当然你也可以采用指定表的字符集的形式,但很容易出现遗漏,特别是在很多人都参与设计的时候,更容易纰漏。
以上内容参考自http://www.cnblogs.com/discuss/articles/1862248.html
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
针对字符集的转换过程,我们产生了疑问,为什么客户端连接数据库要比数据库返回客户端多一个中间层character_set_connection呢?这是必须的吗,意义何在?
以下观点来源于某网友https://www.cnblogs.com/lazyno/archive/2015/02/07/4278544.html:
google时,http://stackoverflow.com/questions/16082480/what-is-the-purpose-of-character-set-connection
老外也提到过样的问题,本人英语差得很,也没怎么看完,最后转而去看手册去了。
在手册中发现一句话:转换时,服务器使用character_set_connection和collation_connection系统变量。它将客户端发送的查询从character_set_client系统变量转换到character_set_connection(除非字符串文字具有象_latin1或_utf8的引介词)。collation_connection对比较文字字符串是重要的。对于列值的字符串比较,它不重要,因为列具有更高的 校对规则优先级。
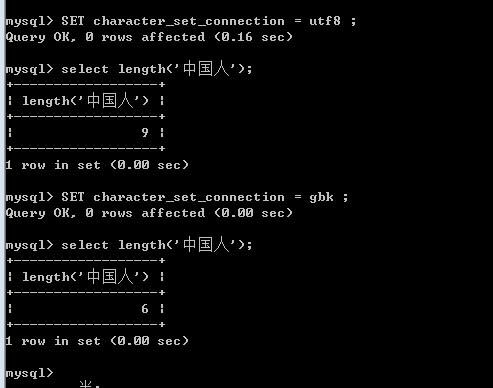
请反复读下这段话,尤其是红色部分。现在说下我的理解:我们操作数据库时,大多于表有关,但是并不是说操作数据库一定要于表有关,如果使用表,则表和字段的字符集有优先,比如直接select length('中国人'),如果character_set_connection是utf8的则输出9,如果是gbk则输出6。各位可以通过修改字符集变量测试下。我想character_set_connection存在的意义大多是类似于此类用法吧。
如有说的不对的地方,请指正下,或者有更多的说法,也请说下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号