io多路复用
io多路复用就是单个线程能处理多个socket连接了,
从前一个线程要么只能处理连接请求,要么只能处理已经建立的连接的交互。先是主线程负责处理连接请求,收到连接请求后,就开启一个线程,这个线程再专门负责这个连接的交互,比如聊天什么的。。
from threading import thread import socket sk=socket.socket() sk.bind(('127.0.0.1',8888)) def func(con): '''处理已经建立好的连接的消息,比如聊天,con.recv,con.send什么的''' pass sk.listen() while True: con,addr=sk.accept() thread(target=func,args=(con,))
因为切换线程很耗费资源,建立的连接一多了,时间都浪费在切换线程上了。
于是,就发明了一种机制,可以在一个线程内,处理多个socket连接,叫做io多路复用
上个例子,我们使用sk对象来接收请求(sk.accept),而用con来接收(con.recv)或发送信息(con.send),但是本质上,他们都可以视为是一种文件描述符,就好比f=open('xx')的f对象一样,都是进行读(sk.accept con.recv f.read)写(con.send f.write())操作,不同的是,sk和con是网络io,而f是磁盘io
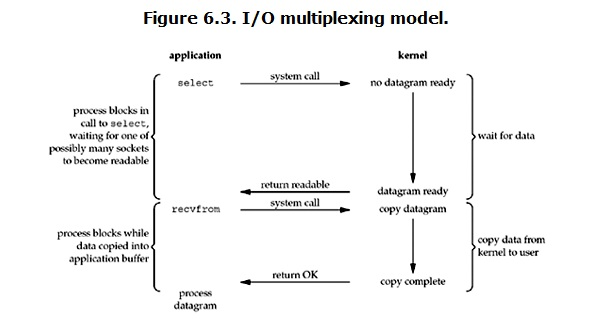
而io多路复用,就是将所有的网络io都放入一个列表中,传给select.select()方法,这个方法就负责观册列表中的所有io,如果有io得到消息了,对于sk来讲就是有新的连接请求了,对于con来讲就是建立好的这个连接发来消息了。那么他就返回这些io,然后我再编写程序,在具体判断这是sk,还是con,如果是sk则执行accept,并将得到的新的连接加入到那个列表中,以方便以后让这个select.select()方法监测。如果是con则recv消息。而如果监测列表中没有io得到消息,则会一直阻塞,直到有io
产生消息为止在循环执行之前的步骤
具体的代码是这样:
import select import socket sk = socket.socket() sk.bind(('127.0.0.1',8003)) sk.setblocking(False) sk.listen() print(sk) read_lst = [sk] while True: # [sk,conn] r_lst,w_lst,x_lst = select.select(read_lst,[],[]) for i in r_lst: if i is sk: conn,addr = i.accept() read_lst.append(conn) else: ret = i.recv(1024) if ret == b'': i.close() read_lst.remove(i) continue print(ret) i.send(b'goodbye!')
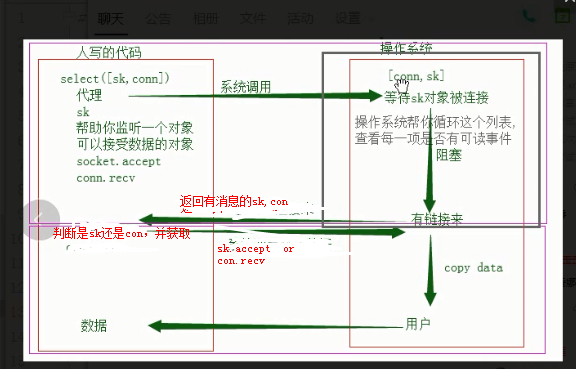
注意,在io多路复用中,sk.accept和con.recv不同于线程里的accept recv,后者是阻塞的,因为消息还没有到达内核态,而前者阻塞非常小,因为消息已经到达内核了,只差从内核复制到用户态了 。
from socket import * import selectors sel=selectors.DefaultSelector() def accept(server_fileobj,mask): conn,addr=server_fileobj.accept() sel.register(conn,selectors.EVENT_READ,read) def read(conn,mask): try: data=conn.recv(1024) if not data: print('closing',conn) sel.unregister(conn) conn.close() return conn.send(data.upper()+b'_SB') except Exception: print('closing', conn) sel.unregister(conn) conn.close() server_fileobj=socket(AF_INET,SOCK_STREAM) server_fileobj.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) server_fileobj.bind(('127.0.0.1',8088)) server_fileobj.listen(5) server_fileobj.setblocking(False) #设置socket的接口为非阻塞 sel.register(server_fileobj,selectors.EVENT_READ,accept) #相当于网select的读列表里append了一个文件句柄server_fileobj,并且绑定了一个回调函数accept while True: events=sel.select() #检测所有的fileobj,是否有完成wait data的 for sel_obj,mask in events: callback=sel_obj.data #callback=accpet callback(sel_obj.fileobj,mask) #accpet(server_fileobj,1)
sel_obj.obj则是有消息的这个io,所绑定的回调函数
sel_obj.fileobj则是有消息的这个io本身
selector模块能帮我们根据操作系统自动选择使用那种多路复用,epoll select poll
具体能实现Io多路复用的有三种
# IO多路复用
# select机制 Windows linux 都是操作系统轮询每一个被监听的项,看是否有读操作
# poll机制 linux 它可以监听的对象比select机制可以监听的多
# 随着监听项的增多,导致效率降低
# epoll机制 linux
select和poll都是轮询列表中的每个项,看看是否有可读操作,这样列表中的项一朵了,效率就下降,而epoll比selet和poll高端太多。高效很多,他已经不是
以下转载自知乎
链接:https://www.zhihu.com/question/28594409/answer/74003996
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先,要从你常用的IO操作谈起,比如read和write,通常IO操作都是阻塞I/O的,也就是说当你调用read时,如果没有数据收到,那么线程或者进程就会被挂起,直到收到数据。
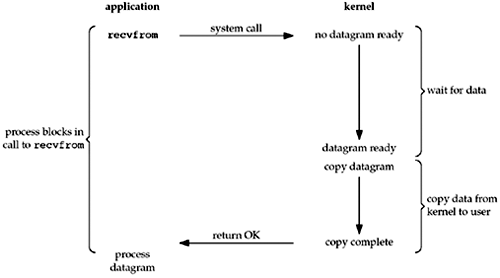
(图片来源:http://www.masterraghu.com/subjects/np/introduction/unix_network_programming_v1.3/ch06lev1sec2.htmll)
这样,当服务器需要处理1000个连接的的时候,而且只有很少连接忙碌的,那么会需要1000个线程或进程来处理1000个连接,而1000个线程大部分是被阻塞起来的。由于CPU的核数或超线程数一般都不大,比如4,8,16,32,64,128,比如4个核要跑1000个线程,那么每个线程的时间槽非常短,而线程切换非常频繁。这样是有问题的:
- 线程是有内存开销的,1个线程可能需要512K(或2M)存放栈,那么1000个线程就要512M(或2G)内存。
- 线程的切换,或者说上下文切换是有CPU开销的,当大量时间花在上下文切换的时候,分配给真正的操作的CPU就要少很多。
那么,我们就要引入非阻塞I/O的概念,非阻塞IO很简单,通过fcntl(POSIX)或ioctl(Unix)设为非阻塞模式,这时,当你调用read时,如果有数据收到,就返回数据,如果没有数据收到,就立刻返回一个错误,如EWOULDBLOCK。这样是不会阻塞线程了,但是你还是要不断的轮询来读取或写入。
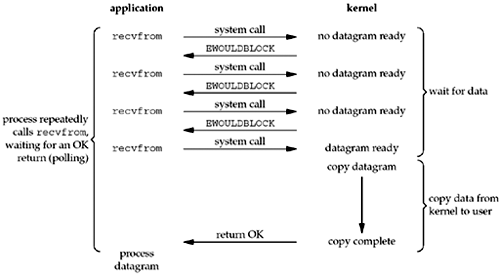
(图片来源:http://www.masterraghu.com/subjects/np/introduction/unix_network_programming_v1.3/ch06lev1sec2.htmll)
于是,我们需要引入IO多路复用的概念。多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。
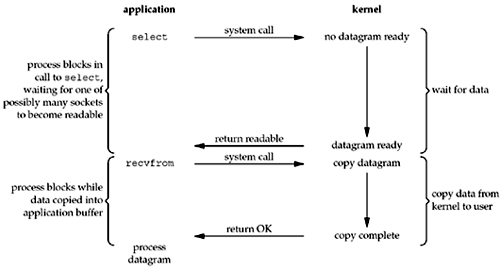
(图片来源:http://www.masterraghu.com/subjects/np/introduction/unix_network_programming_v1.3/ch06lev1sec2.htmll)
这样在处理1000个连接时,只需要1个线程监控就绪状态,对就绪的每个连接开一个线程处理就可以了,这样需要的线程数大大减少,减少了内存开销和上下文切换的CPU开销。
使用select函数的方式如下图所示: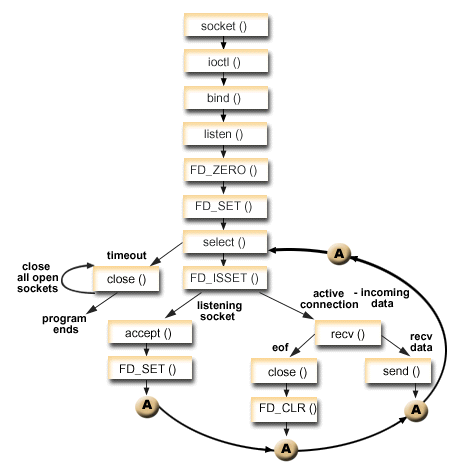

 浙公网安备 33010602011771号
浙公网安备 33010602011771号