

Memcache的使用
一、Memcached ClientLib For .Net
首先,不得不说,许多语言都实现了连接Memcached的客户端,其中以Perl、PHP为主。 仅仅memcached网站上列出的语言就有:Perl、PHP、Python、Ruby、C#、C/C++以及Lua等。
那么,我们作为.Net码农,自然是使用C#。既然Memcached客户端有.Net版,那我们就去下载一个来试试。
下载文件:http://pan.baidu.com/s/1w9Q8I
memcached clientlib项目地址:http://sourceforge.net/projects/memcacheddotnet/
解压该包,里面有1.1和2.0两个版本的,这里我们使用2.0版本的。(在压缩包中的目录地址为:\memcacheddotnet_clientlib-1.1.5\memcacheddotnet\trunk\clientlib\src\clientlib\bin\2.0\Release)

上面的这四个dll就是我们需要引入项目中的程序集,有了他们,我们就可以和Memcached服务器进行通信了,爽歪歪啊。
二、在.Net中进行Memcached基本操作
2.1 基本的Memcached客户端操作
(1)首先,打开Windows Server 2003虚拟机,开启Memcached服务;(非必要操作,如果您是在本机,则可跳过这一步,只需开启Memcached服务即可)

(2)①打开VS,新建一个C#的控制台应用程序,取名为:MemcachedClientDemo。
②新建一个文件夹,取名为Lib,然后将上面下载的客户端程序集dll拷贝到这个文件夹中,并添加对这几个dll的引用。

(3)开始写代码,通过Memcached客户端与服务器进行通信,请参阅下面的代码:

[STAThread]
static void Main(string[] args)
{
// Memcached服务器列表
// 如果有多台服务器,则以逗号分隔,例如:"192.168.80.10:11211","192.168.80.11:11211"
string[] serverList = { "192.168.80.10:11211" };
// 初始化SocketIO池
string poolName = "MyPool";
SockIOPool sockIOPool = SockIOPool.GetInstance(poolName);
// 添加服务器列表
sockIOPool.SetServers(serverList);
// 设置连接池初始数目
sockIOPool.InitConnections = 3;
// 设置连接池最小连接数目
sockIOPool.MinConnections = 3;
// 设置连接池最大连接数目
sockIOPool.MaxConnections = 5;
// 设置连接的套接字超时时间(单位:毫秒)
sockIOPool.SocketConnectTimeout = 1000;
// 设置套接字超时时间(单位:毫秒)
sockIOPool.SocketTimeout = 3000;
// 设置维护线程运行的睡眠时间:如果设置为0,那么维护线程将不会启动
sockIOPool.MaintenanceSleep = 30;
// 设置SockIO池的故障标志
sockIOPool.Failover = true;
// 是否用nagle算法启动
sockIOPool.Nagle = false;
// 正式初始化容器
sockIOPool.Initialize();
// 获取Memcached客户端实例
MemcachedClient memClient = new MemcachedClient();
// 指定客户端访问的SockIO池
memClient.PoolName = poolName;
// 是否启用压缩数据:如果启用了压缩,数据压缩长于门槛的数据将被储存在压缩的形式
memClient.EnableCompression = false;
Console.WriteLine("----------------------------测试开始----------------------------");
// 01.简单的添加与读取操作
memClient.Set("test1", "edisonchou");
Console.WriteLine("test1:{0}", memClient.Get("test1"));
// 02.先添加后修改再读取操作
memClient.Set("test2", "jacky");
Console.WriteLine("test2:{0}", memClient.Get("test2"));
memClient.Set("test2", "edwin");
Console.WriteLine("test2:{0}", memClient.Get("test2"));
memClient.Replace("test2", "lousie");
Console.WriteLine("test2:{0}", memClient.Get("test2"));
// 03.判断Key值是否存在
if (memClient.KeyExists("test2"))
{
Console.WriteLine("Key:test2 is existed");
}
// 04.删除指定Key值的数据
memClient.Add("test3", "memcached");
Console.WriteLine("test3:{0}", memClient.Get("test3"));
memClient.Delete("test3");
if (!memClient.KeyExists("test3"))
{
Console.WriteLine("Key:test3 is not existed");
}
// 05.设置数据过期时间:5秒后过期
memClient.Add("test4", "expired", DateTime.Now.AddSeconds(5));
Console.WriteLine("test4:{0}", memClient.Get("test4"));
Console.WriteLine("Please waiting the sleeping time");
System.Threading.Thread.Sleep(6000);
if(!memClient.KeyExists("test4"))
{
Console.WriteLine("test4 is expired");
}
Console.WriteLine("----------------------------测试完成----------------------------");
// 关闭SockIO池
sockIOPool.Shutdown();
Console.ReadKey();
}
这里,我们来细细分析下这段神奇的代码:
①首先定义了一个string类型的数组来记录Memcached服务器的IP与端口信息,这里需要注意的是如果有多台Memcached服务器,需要使用逗号分隔开,例如:"192.168.80.10:11211","192.168.80.11:11211","192.168.80.12:11211";
②SockIOPool是一个基于Socket(套接字)的连接池,换个方式理解:Memcached其实就是一个Socket的服务器端,它不停地接收Memcached客户端发来的读写请求命令。这里使用了SockIOPool.GetInstance("MyPool")来获取一个名为MyPool的连接池实例,看到GetInstance()这个静态方法,我们便知道这是采用了单例模式。后面我们为其配置了可访问的Memcached服务器列表、连接数、套接字超时时间等配置,最后调用Initialize()方法正式地初始化连接池,等待后面客户端的连接;
PS:神马是Socket?我们可以通过一个生活中的场景来理解:假如你要打电话给一个朋友,拿起电话先拨号,朋友听到电话铃声后提起电话,这时你和你的朋友就建立起了连接,就可以讲话了。等到你们的交流结束,挂断电话以结束此次交谈。So,这里的电话就是一个Socket,你打电话相当于申请了一个Socket,告诉了Socket你要打给谁(对方的电话号码你事先知道)。然后,你和对方进行聊天通话,相当于在向Socket发送数据和从Socket接收数据。最后,通话结束后,一方挂掉电话则相当于关闭Socket,撤销连接。
在计算机网络的连接过程中,客户端Socket一般会记录服务器主机的IP地址、端口号,然后向服务器端进行连接并发送和接受数据。而服务器端开启一个监听的服务,则是相当于使用Socket指定监听的端口,然后等待客户端的连接,客户端连接后则产生一个会话。会话完成后,则关闭连接。
③创建一个新的MemcachedClient(Memcached客户端)对象,并指定要连接的套接字连接池的名称,设置是否启用压缩(这里设置为false)。这里我们了解一下为什么要设置是否起用压缩: 在Memcached中,数据是以Key/Value对的形式进行存储,Key的长度是有限制的,Memcached服务端内部限制Key为250字符,这个长度绝对是够用了,建议不要超过最大长度,尽量控制在200个字符以下。其实,我们最关心的还是Value的限制长度,Value的限制大小为1MB,那么如果有时候超过了1MB怎么办呢?这时候也许就可以使用压缩了,使用压缩后如果小于1Mb还是可以存储到该Key中。但如果即使压缩后还是超过1Mb,那可能会拆分到多个Key中去了。
PS:Key不能有空格和控制字符。推荐使用较短的Key,可以节省服务器内存和网络带宽。另外,最重要的一点是:Key不能重复!
④使用客户端为我们提供的各种读写API方法进行读写测试,如Set、Get、Replace、Add可以进行数据的添加和修改,而KeyExists则可以判断服务器中是否含有指定Key的数据,Delete则提供了删除指定Key的接口。这里,大家可以通过看代码就可以理解,我就不多废话了。大家可以注意到有个数据过期时间的可选参数,当数据在服务器中存储了一定时间后就会失效,这个参数相当有用。
(4)现在我们通过调试,查看这段代码的结果:

2.2 进阶的Memcached客户端操作
(1)在虚拟机中克隆已存在的Windows Server,并设置这两台服务器名称为:MemcacheServer1和MemcachedServer2,IP地址设置为:192.168.80.10与192.168.80.11,测试两台虚拟机与宿主机是否能够互相Ping通,为构建Memcached服务器集群做一个最小化的准备;

(2)既然我们有了两台Memcached服务器,那我们得试试Memcached集群啊,由于Memcached的集群是在客户端实现,所以我们只需要将服务器的IP地址和端口号加入服务器列表的string数组就可以了。于是,我们修改上面的代码:
①首先新建一个App.config文件,新增一个AppSetting项如下:一般来说,服务器的地址信息都是写在配置文件中的,为了追求标准,我们也写在配置文件里边

②将serverList重新定义:使用配置文件里边的Value;这里需要注意的是,要使用ConfigurationManager这个类,需要在引用中添加对System.Configuration这个dll的引用;
string[] serverList = ConfigurationManager.AppSettings["MemcachedServers"].Split(',');
(3)现在我们先重启Memcached1(192.168.80.10)的Memcached服务,清空已经缓存的数据内容,确保两台服务器现在都没有数据;然后,重新运行代码,再次完成代码测试,测试结果还是如下图,说明我们配置的两台Memcached集群已经配置成功。
(4)在虚拟机中使用telnet查看每台服务器具体保存了哪个Key/Value对,这里由于test3和test4均被删除或已失效,所以只需查看前两个Key/Value对:
①MemcacheServer1(192.168.80.10):保存了第二个Key/Value对,<test2:lousie>

②MemcacheServer2(192.168.80.11):保存了第一个Key/Value对,<test1:edisonchou>

(5)到此,我们已经完成了一个最小化的memcached集群读写测试Demo。但是,在实际的开发场景中,远不仅仅是存储一个字符串,更多的是存储一个自定义的类的实例对象。这就需要使用到序列化,下面我们来新加一个类MyObject,让其作为可序列化的对象来存储进Memcached中。注意:需要为该类加上[Serializable]的特性!
[Serializable]
public class MyObject
{
public int ID
{
get;
set;
}
public string Name
{
get;
set;
}
}
然后,在主代码中添加以下几行代码,增加对自定义对象的读写测试:
// 06.自定义对象存储
MyObject myObj = new MyObject();
myObj.ID = 12138;
myObj.Name = "爱迪生周";
memClient.Set("test5", myObj);
MyObject newMyObj = memClient.Get("test5") as MyObject;
Console.WriteLine("Hello,My ID is {0} and Name is {1}", newMyObj.ID, newMyObj.Name);
最后,运行代码,查看结果如下:

(6)怎么样,圆满完成对自定义对象的读写操作吧?现在,我们再看看这个自定义对象是存到了哪台服务器上:经查询,test5是存储到了MemcacheServer2(192.168.80.11)上。
三、回头再看Memcached数据访问模型
经过了刚刚一系列的实践操作,我们在一个最小化的由两台Windows Server搭建的Memcached集群上进行了读写操作测试。那么,我们不由得想要去看看到底Memcached是怎样进行数据访问的呢?别急,现在我们就来看看,由实践到理论,深入理解一下。
(1)添加新的键值对数据

从图中可以看出,Memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能,而是完全由客户端程序库实现的。服务端之间没有任何联系,数据存取都是通过客户端的算法实现的。当客户端要存取数据时,首先会通过算法查找自己维护的服务器哈希列表,找到对应的服务器后,再将数据存往指定服务器。例如:上图中应用程序要新增一个<'tokyo',data>的键值对,它同过set操作提交给Memcached客户端,客户端通过一定的哈希算法(比如:一般的求余函数或者强大的一致性Hash算法)从服务器列表中计算出一个要存储的服务器地址,最后将该键值对存储到计算出来的服务器里边。
(2)获取已存在的键值对数据

上图中应用程序想要获取Key为‘tokyo’(东京这么热,还要取它的值是干神马呢?)的Value,于是它向Memcached客户端提交了一个Get请求,Memcached客户端还是通过算法从服务器列表查询哪台服务器存有Key为‘tokyo’的Value(即选择刚刚Set到了哪台服务器),如果查到,则向查到的服务器请求返回Key为‘tokyo’的数据。
(3)Memcached分布式的核心—一致性Hash算法
一致性Hash算法是分布式缓存的核心理论,我也学习得不深入,也只是刚刚了解了一下,后面我有空深入学习一下,再单独写一篇博文来介绍它,并使用C#来粗略地实现一下这个算法。现在我就简单地介绍一下,其实这部分内容我之前写入了我的另一篇博文《大型网站技术架构读书笔记之网站的可伸缩架构》中,有兴趣的朋友也可以去看看这篇文章。
首先,简单的路由算法(通过使用余数Hash)无法满足业务发展时服务器扩容的需要:缓存命中率下降。例如:当3台服务器扩容至4台时,采用普通的余数Hash算法会导致大约75%(3/4)被缓存了的数据无法正确命中,随着服务器集群规模的增大,这个比例会线性地上升。那么,可以想象,当100台服务器的集群中加入一台服务器,不能命中的概率大概是99%(N/N+1),这个结果显然是无法接受的。那么,能否通过改进路由算法,使得新加入的服务器不影响大部分缓存数据的正确性呢?请看下面的一致性Hash算法。
一致性Hash算法通过一个叫做一致性Hash环的数据结构实现KEY到缓存服务器的Hash映射,如下图所示:
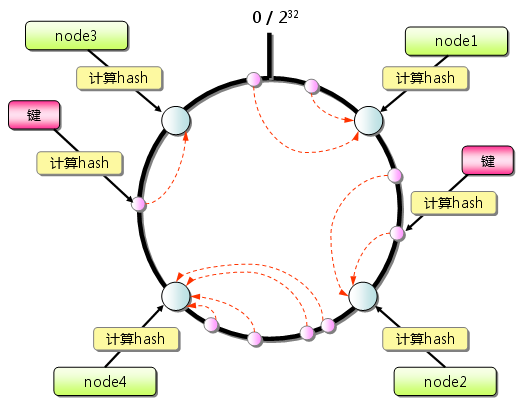
具体算法过程是:
①先构造一个长度为0~2^32(2的32次幂)个的整数环(又称:一致性Hash环),根据节点名称的Hash值将缓存服务器节点放置在这个Hash环中,如上图中的node1,node2等;
②根据需要缓存的数据的KEY值计算得到其Hash值,如上图中右半部分的“键”,计算其Hash值后离node2很近;
③在Hash环上顺时针查找距离这个KEY的Hash值最近的缓存服务器节点,完成KEY到服务器的Hash映射查找,如上图中离右边这个键的Hash值最近的顺时针方向的服务器节点是node2,因此这个KEY会到node2中读取数据;
当缓存服务器集群需要扩容的时候,只需要将新加入的节点名称(如node5)的Hash值放入一致性Hash环中,由于KEY总是顺时针查找距离其最近的节点,因此新加入的节点只影响整个环中的一部分。如下图中所示,添加node5后,只影响右边逆时针方向的三个Key/Value对数据,只占整个Hash环中的一小部分。
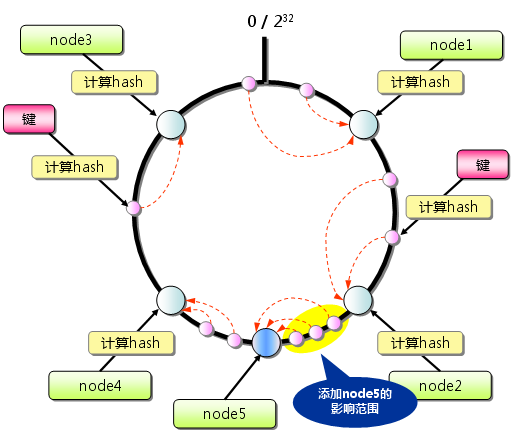
因此,我们可以与之前的普通余数Hash作对比:采用一致性Hash算法时,当3台服务器扩容到4台时,可以继续命中原有缓存数据的概率为75%,远高于普通余数Hash的25%,而且随着集群规模越大,继续命中原有缓存数据的概率也会随之增大。当100台服务器增加1台时,继续命中的概率是99%。虽然,仍有小部分数据缓存在服务器中无法被读取到,但是这个比例足够小,通过访问数据库也不会对数据库造成致命的负载压力。

