


自动化测试基础篇--Selenium框架设计(POM)
感谢木棉花的漂泊分享,内容转自链接:http://www.cnblogs.com/fengyiru6369/p/8053035.html
1.什么是自动化测试框架
简单来说,自动化测试框架就是由一些标准,协议,规则组成,提供脚本运行的环境。自动化测试框架能够提供很多便利给用户高效完成一些事情,例如,结构清晰开发脚本,多种方式、平台执行脚本,良好的报告去跟踪脚本执行结果。
框架具有以下一些优点:
1)代码复用
2)最大覆盖率
3)很低成本维护
4)很少人工干预
5)简单报告输出
2.常见的测试框架分类
好多Selenium自动化测试开发人员是有QTP那边转过来的,所以,他们在早期设计的框架大致可分为以下几类:
1)基于模块的测试框架
2)基于库(Library)结构测试框架
3)数据驱动测试框架,和QTP很像
4)关键字驱动测试框架,也是QTP过来的
5)混合测试框,3 4和综合
6)行为驱动开发测试框架
这里我们不一一介绍这些框架,字面意思可以想象一些这些框架的背景和组件,本文只是对框架有一个基本了解。
3.框架基本组件
我们来思考下框架组成部分:
1)需要配置文件管理
2)业务逻辑代码和测试脚本分离
3)报告和日志文件输出
4)自定义的库的封装
5)管理、执行脚本方式
6)第三方插件引入
7)持续集成
解释:
我们需要一个配置文件去控制一些,环境信息,开关,配置文件可以是txt/xml/yaml/properties/ini,一般.properties使用较多在JAVA里,本文是Python系列,我可能会选择ini文件。
业务逻辑代码和测试脚本分离,不像我们刚开始学习Selenium那样,代码和脚本在一个类文件里演示。我们根本没有用到代码重构,复用。代码和用例文件分离后,更加清晰,去多人开发脚本,方便调试。
报告和日志文件输出,你执行了多少case,case结果如何,这都需要报告来展示,一般采用第三方插件来实现这个功能,好多报告格式是html,简单,明了的风格。日志输出也很重要,如果发生报错,脚本执行失败,通过日志快速定位发生问题位置。
用户自定义库,这个很好理解,我们很多功能需要重复调用,这样我们就写成一个公用方法,放到工具包下,每次方便调用,例如浏览器引擎类和basepage.py的封装。
管理和执行脚本的方式,例如Python中单元测试框架unittest使用率非常高。
第三方插件,有时候,我们一些功能,需要借助第三方插件,能够更好实现,例如AutoIT,来实现文件上传和下载。还有利用第三方报告插件生成基于html格式的测试报告。
持续集成,git,svn,ant,maven,jenkins,我们会把这整合到jenkins,达到持续集成,一键执行测试脚本。
根据以上的特点介绍,我大致用以下图来描述一下,一个简单的自动化测试框架,可能包含哪些组成部分。

框架的简单介绍就到这里,有些人把框架想得太复杂了,框架无非就是一些软件的集合,达到特定的目的。这里我们上图画出来的框架,就是一个简单的自动化测试框架,别笑,这确实是一个简单但又包含必要的组件的自动化测试框架设计实例,如果你学会了这个设计思路和思想,那么,你已经达到了自动化测试第二个阶段的水平:能够简单设计自动化测试框架和维护框架的能力。
unittest是一个单元测试框架,是Python编程的单元测试框架。
unittest支持测试自动化,共享测试用例中的初始化和关闭退出代码,在unittest中最小单元是test,也就是一个测试用例。要了解unittest单元测试框架,先来了解以下几个重要的概念。
测试固件(test fixture)
# coding=utf-8 import time import unittest from selenium import webdriver class BaiduSearch(unittest.TestCase): def setUp(self): """ 测试固件的setUp()的代码,主要是测试的前提准备工作 :return: """ self.driver = webdriver.Chrome() self.driver.maximize_window() self.driver.implicitly_wait(8) self.driver.get("https://www.baidu.com") def tearDown(self): """ 测试结束后的操作,这里基本上都是关闭浏览器 :return: """ self.driver.quit() def test_baidu_search(self): """ 这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。 :return: """ self.driver.find_element_by_id('kw').send_keys('selenium') time.sleep(1) try: assert 'selenium' in self.driver.title print ('Test Pass.') except Exception as e: print ('Test Fail.', format(e)) if __name__ == '__main__': unittest.main()
POM,中文字母意思是,页面对象模型,POM是一种最近几年非常流行的自动化测试模型,或者思想,POM不是一个框架,就是一个解决问题的思想。采用POM的目的,是为了解决前端中UI变化频繁,从而造成测试自动化脚本维护的成本越来越大。下图,形象描述了POM的好处。
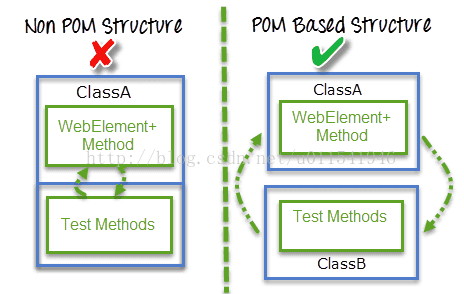
从上图看出,采取了POM设计思路和不采取的区别,左侧把测试代码和页面元素都写在一个类文件,如果需要更改页面,那么就要修改页面元素定位,从而要修改这个类中测试代码,这个看起来和混乱。右侧,采取POM后,主要的区别就是,把页面元素和业务逻辑和测试脚本分离出来到两个不同类文件。ClassA只写页面元素定位,和业务逻辑代码操作的封装,ClassB只写测试脚本,不关心如何元素定位,只写调用ClassA的代码去覆盖不同的测试场景。如果前端页面发生变化,只需要修改ClassA的元素定位,而不需要去修改ClassB中的测试脚本代码。
POM主要有以下优点:
1. 把web ui对象仓库从测试脚本分离,业务代码和测试脚本分离。
2. 每一个页面对应一个页面类,页面的元素写到这个页面类中。
3. 页面类主要包括该页面的元素定位,和和这些元素相关的业务操作代码封装的方法。
4. 代码复用,从而减少测试脚本代码量。
5. 层次清晰,同时支持多个编写自动化脚本开发,例如每个人写哪几个页面,不影响他人。
6. 建议页面类和业务逻辑方法都给一个有意义的名称,方便他人快速编写脚本和维护脚本。

